
Учебно-методический комплекс по дисциплине «Анализ данных и прогнозирование экономики» для студентов специальностей: «Экономика» Астана 2010
| Вид материала | Учебно-методический комплекс |
- Учебно-методический комплекс по дисциплине: «анализ проектов» для студентов специальностей, 2311.99kb.
- Учебно-методический комплекс для студентов по дисциплине «оценка бизнеса и инноваций», 4385.11kb.
- Учебно-методический комплекс дисциплины: Прогнозирование национальной экономики Специальность, 345.29kb.
- Учебно-методический комплекс по дисциплине «Экономика и управление в акционерных обществах», 610.54kb.
- Учебно-методический комплекс по дисциплине «Инвестиционная деятельность предприятия», 593.61kb.
- Учебно-методический комплекс по дисциплине «финансы» астана, 2010, 1311.57kb.
- Учебно-методический комплекс по дисциплине «Институциональная экономика» Для специальности:, 1370.37kb.
- Учебно-методический комплекс по дисциплине теневая экономика уфа 2007, 2230.46kb.
- Учебно-методический комплекс по дисциплине «Управление рисками» Для специальности:, 1692.15kb.
- Учебно-методический комплекс по дисциплине «Экономика недвижимости» Астана 2010, 1852.8kb.
Лекция_8
Регрессионный анализ
1. Парная линейная регрессия
1.1. Взаимосвязи экономических переменных
С тех пор как экономика стала серьезной самостоятельной наукой, исследователи пытаются дать свое представление о возможных путях экономического развития, спрогнозировать ту или иную ситуацию, предвидеть будущие значения экономических показателей, указать инструменты изменения ситуации в желательном направлении. С другой стороны, во многих случаях различные экономисты предлагают разные, а зачастую противоположные методы решения той или иной задачи. Политики либо управляющие производством, выбирая одну из возможных стратегий решения, получают определенный результат. Плох он или хорош, и можно ли было получить лучший результат, проверить весьма затруднительно. Экономическая ситуация практически никогда не повторяется в точности, следовательно, нет возможности применить две стратегии при одних и тех же условиях с целью сравнения конечного результата. Поэтому одной из центральных задач экономического анализа являются предсказание либо прогнозирование развития некоторого экономического объекта при создании тех или иных условий. Поняв глубинные движущие силы исследуемого процесса, можно научиться рационально управлять его развитием.
Поведение и значение любого экономического показателя зависят практически от бесконечного количества факторов, и все учесть нереально. Но в этом и нет необходимости. Обычно лишь ограниченное количество факторов действительно существенно воздействуют на исследуемый экономический показатель. Доля влияния остальных факторов столь незначительна, что их игнорирование не может привести к существенным отклонениям в поведении исследуемого объекта. Выделение и учет в модели лишь ограниченного числа реально доминирующих факторов и является серьезной предпосылкой для качественного анализа, прогнозирования и управления ситуацией. Экономическая теория выявила и исследовала значительное число устоявшихся и стабильных связей между различными показателями. Например, хорошо изученными являются зависимости спроса или потребления от уровня дохода и цен на товары; зависимость между уровнями безработицы и инфляции; зависимость объема производства от целого ряда факторов (размера основных фондов, их возрасте, качества персонала и т.д.); зависимость между производительностью труда и уровнем механизации, а также многие другие зависимости.
Любая экономическая политика заключается в регулировании экономических переменных, и она должна базироваться на знании того, как эти переменные связаны с другими переменными, ключевыми для принимающего решения политика или предпринимателя. Так, в рыночной экономике нельзя непосредственно регулировать темп инфляции, но на него можно воздействовать средствами фискальной (бюджетно-налоговой) и монетарной (кредитно-денежной) политики. Поэтому, в частности, должна быть изучена зависимость между предложением денег и уровнем цен.
Однако в реальных ситуациях даже устоявшиеся зависимости могут проявляться по-разному. Еще более сложной является задача анализа малоизученных и нестабильных зависимостей, построение моделей которых является краеугольным камнем эконометрики. Здесь следует отметить, что такие экономические модели невозможно строить, проверять и совершенствовать без статистического анализа входящих в них переменных с использованием реальных статистических данных. Инструментарием такого анализа являются методы статистики и эконометрики, в частности регрессионного и корреляционного анализа. Следует иметь в виду, что статистический анализ зависимостей сам по себе не вскрывает существо причинных связей между явлениями, т.е. он не решает вопроса, в силу каких причин одна переменная влияет на другую. Решение такой задачи является результатом качественного (содержательного) изучения связей, которое обязательно должно либо предшествовать статистическому анализу, либо сопровождать его.
В естественных науках большей частью имеют дело со строгими (функциональными) зависимостями, при которых каждому значению одной переменной соответствует единственное значение другой. Однако в подавляющем большинстве случаев между экономическими переменными таких зависимостей нет. Например, нет строгой зависимости между доходом и потреблением, ценой и спросом, производительностью труда и стажем работы и т.д. Это связано с целым рядом причин и, в частности, с тем, что, во-первых, при анализе влияния одной переменной на другую не учитывается целый ряд других факторов, влияющих на нее; во-вторых, это влияние может быть не прямым, а проявляться через цепочку факторов; в-третьих, многие такие воздействия носят случайный характер и т. д. Поэтому в экономике говорят не о функциональных, а о корреляционных, либо статистических, зависимостях. Нахождение, оценка и анализ таких зависимостей, построение формул зависимостей и оценка их параметров являются одним из важнейших разделов эконометрики.
Статистической называют зависимость, при которой изменение одной величины влечет изменение распределения другой. В частности, статистическая зависимость проявляется в том, что при изменении одной из величин изменяется среднее значение другой. Такую статистическую зависимость называют корреляционной.
- Суть регрессионного анализа
- Можно указать два варианта рассмотрения взаимосвязей между двумя переменными
 и
и  . В первом случае обе переменные считаются равноценными в том смысле, что они не подразделяются на первичную и вторичную (независимую и зависимую) переменные. Основным в этом случае является вопрос о наличии и силе взаимосвязи между этими переменными. Например, между ценой и объемом спроса на него, между урожаем картофеля и урожаем зерна, между интенсивностью движения транспорта и числом аварий. При исследовании силы линейной зависимости между такими переменными обращаются к корреляционному анализу, основной мерой которого является коэффициент корреляции. Вполне вероятно, что связь в этом случае вообще не носит направленного характера. Например, урожайность картофеля и зерновых обычно изменяются в одном и том же направлении, однако очевидно, что ни одна из этих переменных не является определяющей.
. В первом случае обе переменные считаются равноценными в том смысле, что они не подразделяются на первичную и вторичную (независимую и зависимую) переменные. Основным в этом случае является вопрос о наличии и силе взаимосвязи между этими переменными. Например, между ценой и объемом спроса на него, между урожаем картофеля и урожаем зерна, между интенсивностью движения транспорта и числом аварий. При исследовании силы линейной зависимости между такими переменными обращаются к корреляционному анализу, основной мерой которого является коэффициент корреляции. Вполне вероятно, что связь в этом случае вообще не носит направленного характера. Например, урожайность картофеля и зерновых обычно изменяются в одном и том же направлении, однако очевидно, что ни одна из этих переменных не является определяющей.
- Другой вариант рассмотрения взаимосвязей выделяет одну из величин как независимую (объясняющую), а другую как зависимую (объясняемую). В этом случае изменение первой из них может служить причиной для изменения другой. Например, рост дохода ведет к увеличению потребления; рост цены — к снижению спроса; снижение процентной ставки увеличивает инвестиции; увеличение обменного курса валюты сокращает объем чистого экспорта и т.д. Однако такая зависимость не является однозначной в том, смысле, что каждому конкретному значению объясняющей переменной (набору объясняющих переменных) может соответствовать не одно, а множество значений из некоторой области. Другими словами, каждому конкретному значению объясняющей переменной (набору объясняющих переменных) соответствует некоторое вероятностное распределение зависимой переменной (рассматриваем как СВ). Поэтому анализируют, как объясняющая переменная(ые) влияет(ют) на зависимую переменную «в средним». Зависимость такого типа, выражаемая соотношением
- М(Y|x)=f(x), (1.1)
- называется функцией регрессии Y на X. При этом X называется независимой (объясняющей) переменной (регрессором), Y — зависимой (объясняемой) переменной. При рассмотрении зависимости двух СВ говорят о парной регрессии.
- Зависимость нескольких переменных, выражаемая функцией
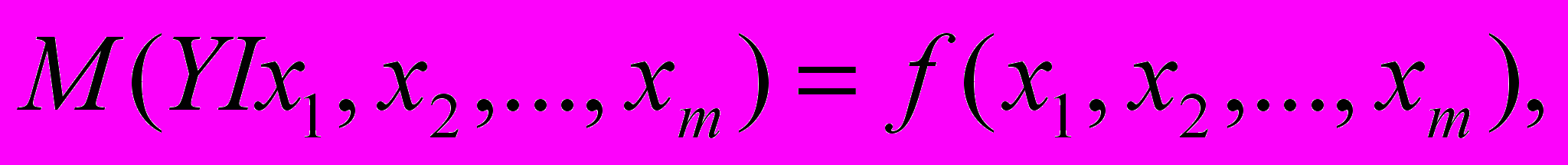 (1.2)
(1.2)
- называют множественной peгрессией.
- Термин "регрессия" (движение назад, возвращение в прежнее состояние) был введен Френсисом Галтоном в конце в XIX века при анализе зависимости между ростом родителей и ростом детей. Галтон заметил, то рост детей у очень высоких родителей в среднем меньше, чем средний рост родителей. У очень низких родителей, наоборот, средний рост выше. И в том, и в другом случае средний рост детей стремится (возвращается) к среднему росту людей в данном регионе. Отсюда и выбор термина, отражающего такую зависимость.
В настоящее время под регрессией понимается функциональная зависимость между объясняющими переменными и условными математическим ожиданием (средним значением) зависимой переменной, которая строится с целью предсказания (прогнозирования) этого среднего значения при фиксированных значениях первых.
Для отражения того факта, что реальные значения зависимой переменной не всегда совпадают с ее условными математическими ожиданиями и могут быть различными при одном и том же значении объясняющей переменной (наборе объясняющих переменных), фактическая зависимость должна быть дополнена некоторым слагаемым, которое, по существу, является СВ и указывает на стохастическую суть зависимости. Из этого следует, что связи между зависимой и объясняющей( ими) переменными выражаются соотношениями
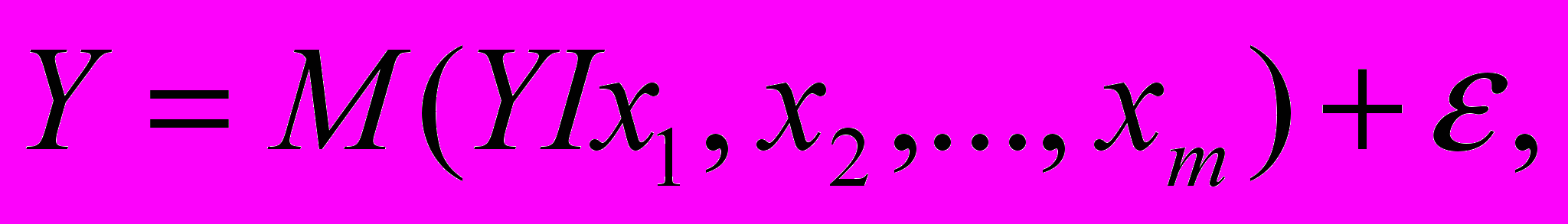
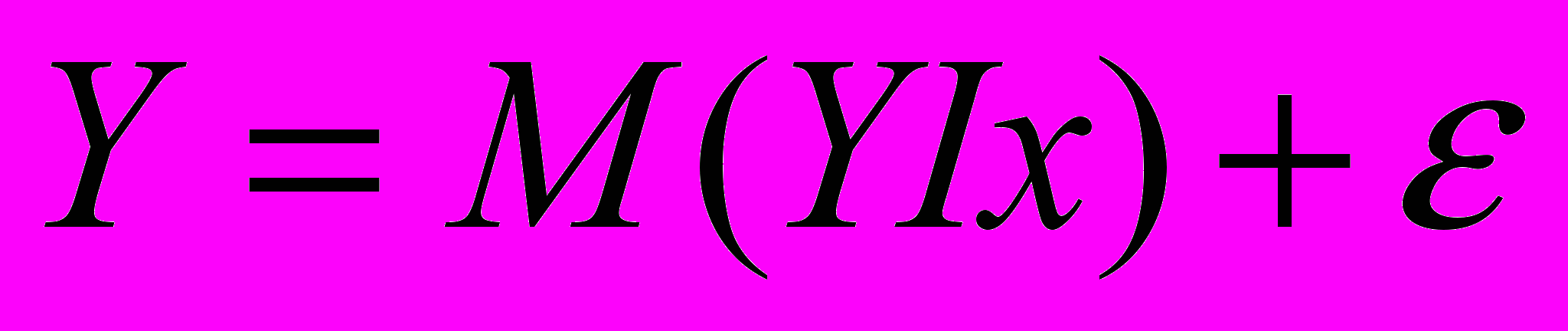 (1.3)
(1.3)называемыми регрессионными моделями (уравнениями).
Обсуждение регрессионных моделей на следующих лекциях поможет глубже изучить данное понятие.
Возникает вопрос о причинах обязательного присутствия в регрессионных моделях случайного фактора (отклонения). Среди таких причин выделим наиболее существенные.
1. Не включение в модель всех объясняющих переменных. Любая регрессионная (в частности, эконометрическая) модель является упрощением реальной ситуации. Последняя всегда представляет собой сложнейшее переплетение различных факторов из которых в модели не учитываются, что порождает отклонение реальных значений зависимой переменной от ее модельных значений. Например, спрос (Q) за товар определяется его ценой (Р), ценой (Рз) на товары заменитель, ценой (Рд) на дополняющие товары, доходов (I) потребителей их количеством (N), вкусами (N), ожиданиями {W) и т. д. Безусловно перечислить все объясняющие переменные здесь практически невозможно. Например мы не учли такие факторы, как традиций национальные или религиозные оособенности, географическое положение региона, погода и многие другие, влияние которых приведет к некоторым отклонениям реальных наблюдений от модельных, которые можно выразить через случайный член
 :Q=f(P,Рз,Pд,I,N,T,W, ). Проблема еще и в том что никогда заранее не известно, какие факторы при создавшихся условиях действительно являются определяющими, а какими можно пренебречь. Здесь уместно отметить, что в ряде случаев учесть непосредственно какой-то фактор нельзя в силу невозможности получения по нему статистических данных.. Например, величина сбережений домохозяйств может определяться не только доходами их членов, но и, например, здоровьем последних, информация о котором в цивилизованных странах составляет врачебную тайну и не раскрывается. Кроме того, ряд факторов носит принципиально случайный характер (например, погода), что добавляет неоднозначности при рассмотрении некоторых моделей (например, модель, прогнозирующая объем урожая).
:Q=f(P,Рз,Pд,I,N,T,W, ). Проблема еще и в том что никогда заранее не известно, какие факторы при создавшихся условиях действительно являются определяющими, а какими можно пренебречь. Здесь уместно отметить, что в ряде случаев учесть непосредственно какой-то фактор нельзя в силу невозможности получения по нему статистических данных.. Например, величина сбережений домохозяйств может определяться не только доходами их членов, но и, например, здоровьем последних, информация о котором в цивилизованных странах составляет врачебную тайну и не раскрывается. Кроме того, ряд факторов носит принципиально случайный характер (например, погода), что добавляет неоднозначности при рассмотрении некоторых моделей (например, модель, прогнозирующая объем урожая).2. Неправильный выбор функциональной формы модели. Из-за слабой изученности исследуемого процесса либо из-за его переменчивости может быть неверно подобрана функция, его моделирующая. Это, безусловно, скажется на отклонении модели от реальности, что отразится на велечине случайного члена. Например, производственная функция (У) одного фактора (Х) может моделироваться функцией У == а + bХ, хотя должна была исследоваться другая модель: У = аХb (0
3. Агрегирование переменных. Во многих моделях рассматриваются зависимости между факторами, которые сами представляют сложную комбинацию других, более простых переменных. Например, при рассмотрении в качестве зависимой переменной совокупного спроса проводится анализ зависимости, в которой объясняемая переменная является сложной композицией индивидуальных спросов, оказывающих на нее определенное влияние помимо факторов, учитываемых в модели. Это может оказаться причиной отклонения реальных значений от модельных.
4. Ошибки измерений. Какой бы качественной ни была модель, ошибки измерений переменных отразятся на несоответствии модельных значений эмпирическим данным, что также отразиться на величине случайного члена.
5.Ограниченность статистических данных. Зачастую строятся модели, выражаемые непрерывными функциями. Но для этого используется, набор данных, имеющих дискретную структуру. Это несоответствие находит свое выражение в случайном отклонении.
6. Непредсказуемость человеческого фактора. Эта причина может «испортить» самую качественную модель. Действительно, при правильном выборе формы модели, скрупулезном подборе объясняющих переменных все равно невозможно спрогнозировать поведение каждого индивидуума.
Таким образом, случайный член является отражением влияния всех описанных выше причин и не только их. Этот список может быть дополнен.
Решение задачи построения качественного уравнения регрессии, соответствующего его эмпирическим данным и целям исследования, является достаточно сложным и многоступенчатым процессом. Его можно разбить на три этапа:
1) выбор формулы уравнения регрессии;
2) определение параметров выбранного уравнения;
3) анализ качества уравнения и поверка адекватности уравнения эмпирическим данным, совершенствование уравнения.
Выбор формулы связи переменных называется спецификацией уравнения регрессии. В случае парной регрессии выбор формулой обычно осуществляется по графическому изображению реальных статистических данных в виде точек в декартовой системе координат, которое называется корреляционным полем (диаграммой рассеивания) (рис. 1.1).
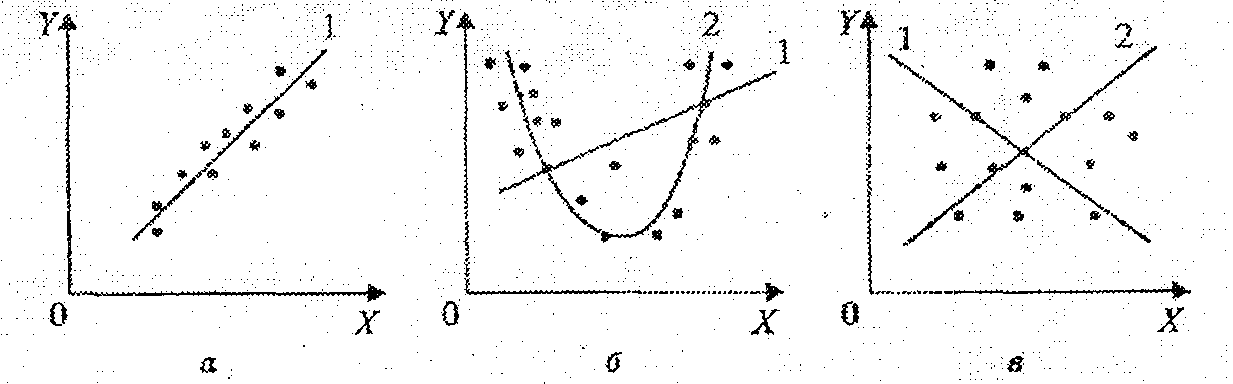
Рис. 1.1
На рис. 1.1 представлены три ситуации. На графике 4.1, а взаимосвязь между Х и Y близка к линейной, и прямая 1 достаточно хорошо соответствует эмпирическим точкам. Поэтому в данном случае в качестве зависимости между X и Y целесообразно выбрать линейную функцию
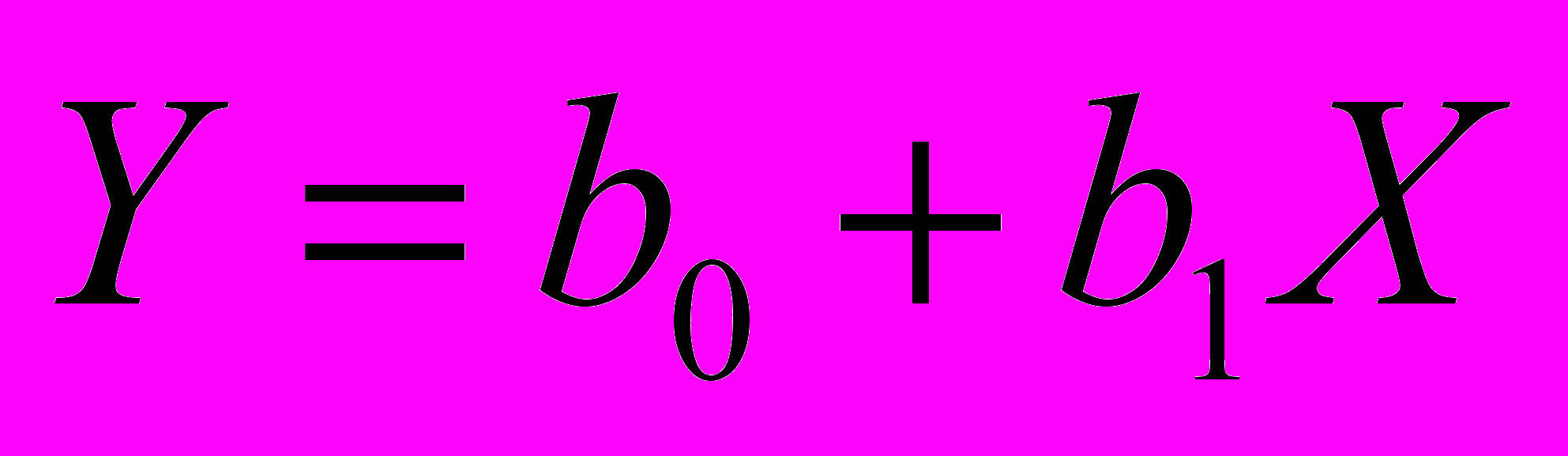 .
.На графике 1.1, б реальная взаимосвязь между X и У, скорее всего, описывается квадратичной функцией
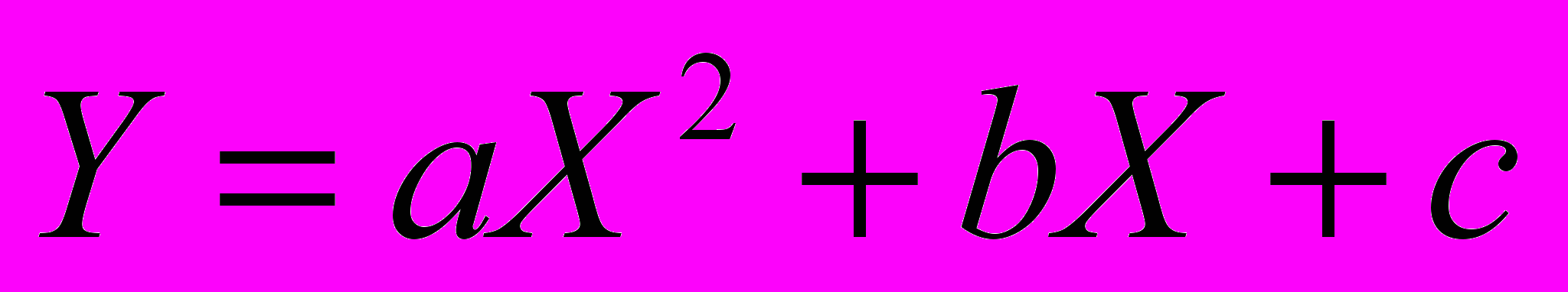 (линия 2). И какую бы мы ни провели прямую (например, линия 1) отклонения точек наблюдений от нее будут существенными и неслучайными.
(линия 2). И какую бы мы ни провели прямую (например, линия 1) отклонения точек наблюдений от нее будут существенными и неслучайными.На графике 1.1, в явная взаимосвязь между X и У отсутствует. Какую бы мы ни выбрали форму связи, результаты ее спецификации и параметризации (определение коэффициентов уравнения) будут неудачными. В частности, прямые 1 и 2, проведенные через центр "облака" наблюдений и имеющие противоположный наклон, одинаково плохи для того, чтобы делать выводы об ожидаемых значениях переменной У по значениям переменной X.
В случае множественной peгpeccии определение подходящего вида зависимости является более сложной задачей.
Вопросы определения параметров уравнения {параметризации) и проверки качества (верификации) уравнения регрессии будут обсуждены в следующих лекциях.
1.3. Парная линейная регрессия.
Если функция регрессии линейна, то говорят о линейной регрессии. Модель линейной регрессии (линейное уравнение) является наиболее распространенным (и простым) видом зависимости между экономическими переменными. Кроме того, построенное линейное уравнение может служить начальной точкой эконометрического анализа.
- Например, Кейнсом была предложена формула такого типа для моделирования зависимости частного потребления С от располагаемого дохода I: С = С0+bI, где С0 —величина автономного потребления, b (0
Методы регрессионного анализа рассчитаны, главным образом, на случай устойчивого нормального распределения, в котором изменения от опыта к опыту проявляются лишь в виде независимых испытаний.
Выделяются различные формальные задачи регрессионного анализа. Они могут быть простыми или сложными по формулировкам, по математическим средствам и трудоемкости. Перечислим и рассмотрим на примерах те из них, которые представляются основными.
Первая задача — выявить факт изменчивости изучаемого явления при определенных, но не всегда четко фиксированных условиях. В предыдущей лекции мы уже решали эту задачу с помощью параметрических и непараметрических критериев.
Вторая задача — выявить тенденцию как периодическое изменение признака. Сам по себе этот признак может быть зависим или не зависим от переменной-условия (он может зависеть от неизвестных или неконтролируемых исследователем условий). Но это не важно для рассматриваемой задачи, которая ограничивается лишь выявлением тенденции и ее особенностей.
Проверка гипотез об отсутствии или наличии тенденции может выполняться с использованием критерия Аббе . Критерий Аббе предназначен для проверки гипотез о равенстве средних значений, установленных для 4
Эмпирическое значение критерия Аббе вычисляется по формуле:
 (8)
(8) где
 — среднее арифметическое из выборки;
— среднее арифметическое из выборки; п – число значений в выборке.
Согласно критерию, гипотеза о равенстве средних отклоняется (принимается альтернативная гипотеза), если значение статистики
 . Табличное (критическое) значение статистики определяется из таблицы для q-критерия Аббе, которая с сокращениями заимствована из книги Л.Н. Болышева и Н.В. Смирнова (см. Приложение 3).
. Табличное (критическое) значение статистики определяется из таблицы для q-критерия Аббе, которая с сокращениями заимствована из книги Л.Н. Болышева и Н.В. Смирнова (см. Приложение 3).В качестве таких величин, для которых применим критерий Аббе, могут выступать выборочные доли или проценты, средние арифметические и другие статистики выборочных распределений, если они близки к нормальному (или предварительно нормализованы). Поэтому критерий Аббе может найти широкое применение в психолого-педагогических исследованиях. Рассмотрим пример выявления тенденции с помощью критерия Аббе.
Пример 4. В табл. 5 представлена динамика процента студентов IV курса, на «отлично» сдававших экзамены в зимние сессии на протяжении 10 лет работы одного из факультетов университета. Требуется установить, есть ли тенденция к повышению успеваемости.
Таблица 5. Динамика процента отличников четвертого курса за 10 лет работы факультета
| Учебный год | % |
| 1995-96 | 10,8 |
| 1996-97 | 16,4 |
| 1997-98 | 17,4 |
| 1998-99 | 22,0 |
| 1999-00 | 23,0 |
| 2000-01 | 21,5 |
| 2001-02 | 26,1 |
| 2002-03 | 17,2 |
| 2003-04 | 27,5 |
| 2004-05 | 33,0 |
В качестве нулевой проверяем гипотезу об отсутствии тенденции, т. е. о равенстве процентов.
Усредняем проценты, приведенные в табл. 5, находим, что
=21,5. Вычисляем разности между последующими и предыдущими значениями в выборке, возводим их в квадрат и суммируем:
Аналогично вычисляет знаменатель в формуле (8), суммируя квадраты разностей между каждым измерением и средним арифметическим:

Теперь по формуле (8) получаем:

В таблице критерия Аббе из Приложения 3 находим, что при n=10 и уровне значимости 0,05 критическое значение
 , что больше полученного нами 0,41, следовательно гипотезу о равенстве процента «отличников» приходится отклонить, и можно принять альтернативную гипотезу о наличии тенденции.
, что больше полученного нами 0,41, следовательно гипотезу о равенстве процента «отличников» приходится отклонить, и можно принять альтернативную гипотезу о наличии тенденции.Третья задача – это выявление закономерности, выраженной в виде корреляционного уравнения (регрессии).
Пример 5. Эстонский исследователь Я. Микк [1], изучая трудности понимания текста, установил «формулу читаемости», которая представляет собой множественную линейную регрессию:
 — оценка трудности понимания текста,
— оценка трудности понимания текста, где х1 - длина самостоятельных предложений в количестве печатных знаков,
х2 - процент различных незнакомых слов,
х3 - абстрактность повторяющихся понятий, выраженных существительными.
Сравнивая между собой коэффициенты регрессии, выражающие степень влияния факторов, можно видеть, что трудность понимания текста определяется прежде всего его абстрактностью. Вдвое меньше (0,27) трудность понимания текста зависит от числа незнакомых слов и практически она совсем не зависит от длины предложении.
Лекция_9
Обзор программного обеспечения для статистического анализа данных
Потребность в средствах статистического анализа данных очень велика, что и послужило причиной для развития рынка статистических программ.
Наилучший выбор статистического пакета для анализа данных зависит от характера решаемых задач, объема обрабатываемых данных, квалификации пользователей, имеющегося оборудования.
Число статистических пакетов, получивших распространение в России, достаточно велико (несколько десятков). Из зарубежных пакетов это STATGRAPHICS, SYSTAT, STATISTICA, SPSS, SAS, CSS. Из отечественных можно назвать такие пакеты, как STADIA, ЭВРИСТА, МЕЗОЗАВР, САНИ, КЛАСС-МАСТЕР, СТАТЭксперт и др.
Для пользователей, имеющих дело со сверхбольшими объемами данных или узкоспециальными методами анализа, пока нет альтернативы использованию профессиональных западных пакетов. Среди интерактивных пакетов такого рода наибольшими возможностями обладает пакет SAS.
Если Вам необходимо обработать данные умеренных объемов (несколько сотен или тысяч наблюдений) стандартными статистическими методами, подойдет универсальный или специальный статистический пакет, надо только убедиться, что он содержит нужные методы обработки.
Пакеты STADIA и STATISTICA являются универсальными пакетами, содержащими большинство стандартных статистических методов. Пакеты SPSS и SyStat перенесены на персональные компьютеры с больших ЭВМ предыдущих поколений, поэтому, наряду с представительным набором тщательно реализованных вычислительных методов, они сохраняют и некоторые архаические элементы. Однако имеющиеся в них возможности командного языка (впрочем, очень непростые в изучении и использовании) могут быть весьма полезны для сложных задач обработки данных. Пакеты STADIA и STATISTICA исходно разработаны для ПЭВМ, а поэтому проще в обращении. Эти пакеты, пожалуй, содержат наибольшее количество методов статистического анализа.