
Президенте Российской Федерации по развитию информационного общества межрегиональный семинар
| Вид материала | Семинар |
- Президенте Российской Федерации по развитию информационного общества межрегиональный, 776.07kb.
- Президенте Российской Федерации по развитию информационного общества межрегиональный, 379.69kb.
- Президенте Российской Федерации по развитию информационного общества межрегиональный, 485.27kb.
- Президенте Российской Федерации по развитию информационного общества межрегиональный, 491.14kb.
- Президенте Российской Федерации по развитию информационного общества межрегиональный, 454.31kb.
- Президенте Российской Федерации по развитию информационного общества межрегиональный, 3606.18kb.
- Президенте Российской Федерации по развитию информационного общества. Врамках семинар, 74.59kb.
- Президенте Российской Федерации по развитию информационного общества межрегиональный, 363.15kb.
- Президенте Российской Федерации по развитию гражданского общества и правам человека,, 1162.29kb.
- Методические рекомендации по порядку организации работ по созданию субъектом российской, 34.87kb.
единые способы организации и обработки данных;
независимость ИОС ДО каждого учебного заведения в:
наполнении БД;
педагогических методах обучения;
реализации Web-интерфейса пользователя;
-
административной политики.
Основные эксплуатационные характеристики единой ИОС ДО:
- обеспечивать функционирование системы, как единой системы в целом;
- обеспечивать минимальным сетевым трафиком;
- обеспечивать высокими показателями жизнеспособности;
- быть независимой от платформы и фирмы её производителя.
Для создания такой системы предлагается разработать типовое программное обеспечение (ТПО). ТПО – программный комплекс, предоставляющий функциональные возможности и информационные ресурсы, реализующие единую ИОС ДО в целом. ТПО по назначению делиться на основное ТПО, которое реализует ИОС ДО учебного заведения, и общее ТПО, обеспечивающее взаимодействие между учебными заведениями.
Функционал основного ТПО условно делится на следующие функциональные группы:
-
одинаковые функции для любого учебного заведения, т.е. независимо от дифференциации их деятельности;
одинаковы функции для учебных заведений в рамках определенной дифференциации их деятельности;
-
функции, которые специфичны для конкретного ученого заведения.
Первые две группы функций предназначены для унификации взаимодействия между учебными заведениями, а третья – для реализации собственного функционала.
На основе результатов проведенного анализа существующих способов обработки данных и процессов в распределенных системах, разработаны датологические модели: распределенных данных и распределенных прикладных процессов, для единой ИОС ДО. Эти модели описывают единство данных учебных заведений и единство протекающих в них прикладных процессов.
На основе этих моделей разработаны алгоритмы выборки, создания, изменения и удаления (логическое) распределенных данных для единой ИОС ДО. Эффективность этих алгоритмов обусловлена следующими показателями:
- скорость выполнения, поскольку в рамках общего запроса обращение к каждому учебному заведению осуществляется только один раз;
- минимальный объём передаваемых данных для получения результата общего запроса – это обусловлено логикой алгоритма и отсутствием избыточных данных, передаваемых от одного учебного заведение – к другому;
- надежность получения результата – это во многом обусловлено архитектурой системы и логикой алгоритма;
- прозрачность расположения данных не только для пользователя, но и для разработчика;
- гибкость в настройке общего запроса: возможность адаптировать обработку данных пользователем под свои предпочтения (по скорости/надежности, по определению данных и по критериям их отбора) в рамках определенного функционала.
На основе трехзвенной архитектуры клиент-сервер разработана архитектура единой ИОС ДО, учитывающая ограничения связанные с большой территорией России и с её недостаточно развитой информационно-коммуникационной инфраструктурой. Эффективность данной архитектуры обусловлена следующими показателями:
- надежность функционирования единой системы в целом;
- расширяемость;
- гибкость;
- реализуемость принципов единой ИОС ДО;
- ориентированность на развитие.
Выводы:
Проведенные исследования показали сложность и важность информатизации учебных заведений, и что не существует единого решения, не смотря на многолетний опыт внедрения информационных и коммуникационных технологий в образовании. Поэтому необходимо разработать конкурентную единую информационно-образовательную среду дистанционного обучения, объединяющую ресурсы, опыт и функциональные возможности учебных заведений, чтобы развитие данной среды носило не случайный (экспериментальный), а закономерный (необходимый) характер. Для реализации такой системы разработаны соответствующие требования, архитектура, модели и алгоритмы
Система сопровождения Методики игрового обучения
И.С. Игнатьев
Московский Государственный Институт Электроники и Математики (Технический Университет), Россия
Обучение при помощи игр является перспективным методом обучения. Оно позволяет задействовать те аспекты мотивации обучения, которые традиционные методы обучения не используют (и в результате этого повысить эффективность обучения). Однако развитие это не систематизировано и носит характер хаотического внедрения отдельных игр или игровых элементов в курсы обучения. В ходе выполнения диссертационной работы, которая систематизирует внедрение игровых элементов в курс занятий и позволяет анализировать отдачу от этого внедрения, стало понятно, что сама методика процесса обучения может быть изменена с учетом методов игрового обучения.
Предпосылками к этому стало наблюдение того, что студенты испытывают проблемы в учебе из-за резко возросшего количества отвлекающих студента от учебы факторов. Для того, чотбы сосредоточится на учебе на фоне множества других занимательных занятий, легко доступных из окружающей студента среды, требуются определенные душевные качества, сила воли, сильное желание учиться. Однако далеко не все этими качествами обладают. К тому же, требуется достаточно много начальных усилий, которые нужно совершить, чтобы хотя бы немного погрузиться в предмет и понять, что он интересен-таки по-своему.
Также был утерян соревновательный элемент процесса обучения. При приеме на работу учитывается не диплом и вкладыш в него, а резюме, которое от него значительно отличается. Соответственно, для возвращения соревновательного элемента в процесс обучения необходимо привести диплом (или вкладыш в него) в соответствие с требованиями, предъявляемыми работодателем к резюме.
Для решения этих проблем был выбран механизм игры. Игра - это система, в которой участники по своей воле вовлечены в искусственный конфликт, правила которого определены и известны участникам, а результат измеряем, но не определен изначально. Для того, чтобы игра-учеба стала добровольной, надо, чтобы студент был заинтересован в том, чтобы играть. Это достигается либо заинтересованностью в процессе игры, либо в ее результате. Для создания игры надо определить конфликт. Если рассматривать конфликты в общем, то в играх есть два вида конфликтов: конфликт игрока с игроком и конфликт игрока с окружением. Для целей преподавания можно использовать как первый, так и второй тип конфликта. Первый тип возвращает нас к соревнованию между игроками-студентами и поэтому неэффективен. Надо также использовать конфликт игрока с окружением - студента с преподаваемым ему курсом (как Environment). Более того, каждый конфликт должен иметь конкретный результат - так как мы используем также результатную заинтересованность.
Используя терминологию исследований игр, учеба представляет собой структуру типа MMORPG: вся игра (курс) состоит из получения студентом(его персонажем-героем) опыта(и соответственно увеличения его знаний и умений как студента) и получения различных материальных наград-оценок (в игровом случае аналогом являются деньги, оружие и т.п.) путем ответа на различные вопросы (сражения с монстрами - вопросами) и выполнения заданий. Таким образом, корректно и применение различных методик проектирования MMORPG для проектирования процесса учебы.
В ходе работы было проведено проецирование процесса обучения внутрь магического круга игры. В результате была создана методика игрового обучения и ее реализация в виде веб-приложения на языке Python с использованием фреймворка Django. Приложение позволяет создавать и развивать персонажа студента под непосредственным контролем преподавателя при помощи различного вида учебных заданий. На основании развиваемых студентом при помощи учебных заданий навыков создается резюме-подобное описание персонажа студента. Учебные задания разрабатываются преподавателем для своего курса с учетом того, как они должны влиять на развитие студента, и вводятся в систему при помощи специального интерфейса, который увязывает влияние выполнения этих заданий и развитие персонажа студента. Затем по мере выполнения этих заданий они оцениваются преподавателем и соответственно повышают развиваемые навыки персонажа студента. В результате на основании этого постепенно формируется резюме студента, в котором отражены его непосредственные навыки с точки зрения преподавателя. Кроме того, по мере улучшения навыков студент получает все больше возможностей для проявления активности в рамках системы, что, с одной стороны, дает ему больше свободы в выполнении обычных заданий, и с другой – позволяет по мере роста в навыках получать доступ к ранее недоступным функциям системы.
Для реализации была создана база данных в СУБД MySQL, в которой были отражены задействованные в процессе сущности – задачи(Task), награды(Gain), навыки(Attribute), Назначения(Assign), возможности студента (Stat), преподоваемые курсы (Course) и работающие с системой люди (Person). На основании вышеизложенной методики при помощи веб-фреймворка Django для работы в качестве веб-приложения были реализованы следующие функции:
- Для преподавателей: создание/редактирование курсов, наполнение курсов заданиями с назначением наград за них, назначение заданий студентам (группам студентов), получение ответа на задание, разветвленные комментарии ответа, оценка выполнения задания, создание/редактирование возможностей для студентов, создание/редактирование навыков студентов.
- Для студентов: создание базового персонажа студента при первом заходе в систему, получение заданий, получение напоминания на e-mail, написание ответа на задание, получение комментариев от преподавателя на ответ, исправление задания(с сохранением неисправленной версии), получение наград за выполнение задания, поднятие навыков персонажа, получение новых возможностей при повышении навыков.
- Для всех пользователей системы: персонализованная новостная лента событий.
В результате был создан инструмент для комплексного, а не фрагментарного, в виде отдельных игр, внедрения методики игрового обучения в процесс обучения. Основным направлением развития системы является на данный момент улучшение пользовательского интерфейса и достижение полноты базы навыков и возможностей.
Данная реализация является важным шагом к актуализации процесса обучения и внедрения в него новых технологий. Она позволяет задействовать новые мотивации студента к обучению и тем самым повысить качество его обучения.
СБОР ИНФОРМАЦИИ ДЛЯ БАЗЫ ДАННЫХ ПОИСКОВО-ОБРАЗОВАТЕЛЬНОЙ СИСТЕМЫ С ИСПОЛЬЗОВАНИЕМ ТЕХНОЛОГИИ РАСПРЕДЕЛЕННЫХ ВЫЧИСЛЕНИЙ
Баранов М.А., *Шийко Д.С.
Московский государственный институт электроники и математики, Россия
*НИИ ПМТ, Россия
Аннотация
В работе рассматриваются способы организации сбора информации, необходимой для работы поисково-образовательной системы. В рамках выбранной для сбора информации технологии распределенных вычислений рассматриваются возможные варианты и выбирается наиболее оптимальный.
Введение
Основными средствами поиска в глобальной сети Интернет являются поисковые системы. Хотя поисковые системы прошли длительный путь эволюции, они до сих пор обладают целым рядом недостатков, препятствующих эффективному поиску информации. Часто пользователям приходится использовать достаточно сложный язык поисковых запросов для получения удовлетворительных результатов. Кроме этого, существующие поисковые системы плохо ориентированы на поиск предметов потребления.
В связи с вышесказанным, возникла идея создать поисковую систему с итеративным характером уточнения исходного поискового запроса. На каждой итерации пользователю будут выдаваться ключевые слова (с подробным объяснением их значения), связанные с исходным поисковым запросом, которые могут использоваться для его уточнения.
Для функционирования любой информационно-поисковой системы необходим доступ к хранилищу информации, в котором хранятся данные, необходимые для выдачи результата на запрос. Здесь можно использовать либо собственную базу данных, либо воспользоваться возможностями метапоиска. Для поисково-образовательной системы второй вариант не подходит, поскольку метапоиск возвращает уже готовые результаты на поисковый запрос, и не предоставляет доступ непосредственно к базам данных других поисковых систем.Таким образом, описываемая поисковая система должна обладать собственной базой данных.
Задачей данной работы является определение наиболее эффективного и дешевого способа сбора информации для такой базы данных.
Обоснование выбора технологии индексации
При выборе технологии заполнения информацией базы данных необходимо учитывать, что информация должна поступать в базу данных в достаточно большом объеме и должна регулярно обновляться. Поэтому, необходимо наличие больших вычислительных мощностей. С другой стороны, наличие большого числа серверов, занимающихся сбором информации, приведет к повышению стоимости проекта и, в конечном счете, к невозможности его успешной реализации.
Выходом из описанной ситуации может послужить подход, в основу которого положена технология распределенных вычислений. Его применение позволит:
- Переложить большую часть работы по индексации на компьютеры участвующих в проекте пользователей
- Существенно снизить объем расходуемого разработчиками поисковой системы трафика (в т.ч. за счет сжатия передаваемых на сервера данных)
- Позволит на несколько порядков сократить количество необходимых проекту серверов, поскольку теперь их задача будет сводиться в основном к выдаче новых заданий и приему уже обработанных
Для организации распределенных вычислений необходимо наличие соответствующего программного комплекса. Такой комплекс отвечает за разбиение большой задачи на множество более маленьких, распределение этих задач по вычислительным узлам, прием полученных результатов и их дальнейшую обработку.
Возможны два подхода к созданию такого комплекса:
- Реализация программного приложения «с нуля»
- Использование одной из специально созданных для этого типа задач программных платформ.
В первом случае, помимо реализации собственно расчетного модуля, необходимо реализовать графический интерфейс пользователя для клиентского приложения, устанавливаемого на компьютеры пользователей, участвующих в проекте. Также необходимо самостоятельно разработать модули подготовки, приема и отправки заданий. Все это увеличивает срок разработки проекта распределенных вычислений, что в условиях быстрого развития информационно-поисковых систем и жесткой конкуренции между ними может привести к потере актуальности предложенной идеи.
Поэтому, предпочтительным оказывается второй способ. Наиболее популярной на сегодняшний день платформой для организации распределенных вычислений является платформа BOINC (Berkeley Open Infrastructure for Network Computing — открытая программная платформа (университета) Беркли для распределённых вычислений).
Кроме упрощения разработки непосредственно проекта распределенных вычислений, использование платформы BOINC позволяет получить еще ряд важных преимуществ.
BOINC насчитывает огромное количество участников – на текущий момент их около двух миллионов. Это означает, что не будет недостатка в вычислительных ресурсах. Наличие столь большого сообщества позволяет быстро и дешево сделать рекламу проекта – достаточно дать объявления на нескольких форумах, посвященных данной платформе.
Заключение
Практическая ценность работы состоит в предложенной идее использования программной платформы BOINC для организации процесса индексирования документов сети Интернет, необходимых для эффективной работы представленной выше информационно-поисковой системы.
Кроме этого, в случае успешной реализации возможно предоставление доступа (в частности, на коммерческой основе) к собранной информации другим поисковым системам.
Список литературы
[1] Christopher D. Manning . Introduction to Information Retrieval. Cambridge University Press, 2008
[2] T. Joyce, R.M. Needham. The Thesaurus Approach to Information Retrieval, American Documentation, 1958
[3] Karen Sparck Jones. A Statistical Interpretation of Term Specificity and Its Application in Retrieval, Journal of Documentation, 1972
[4] S.E. Robertson and Sparck Jones K. Relevance Weighting of Search Terms, JASIS, 1976
ПРИМЕНЕНИЕ АССОЦИАТИВНЫХ ПРАВИЛ ДЛЯ ПРЕДСКАЗАНИЯ СЕРДЕЧНОСОСУДИСТЫХ ЗАБОЛЕВАНИЙ.
В.А. Демиденок
Московский Государственный Институт Электроники и Математики, Россия
1. Введение
В последнее время информатизация общества и автоматизация различных сфер деятельности привели к накоплению большого количество различных данных. Возникла потребность в анализе данных, выявлении скрытых закономерностей и правил. Data Mining это направление интеллектуального анализа данных, которое позволяет решать подобный класс задач, а именно обнаружение ранее неизвестных, нетривиальных, практически полезных знаний в данных. Интеллектуальный анализ данных применяют в различных сферах, таких как анализ покупательской корзины, медицина, анализ рисков. Предсказание сердечнососудистых заболеваний является одной из тех задач, где Data Mining может быть успешно применён для улучшения предсказания возникновения заболеваний и предотвращении их возникновения.
Поиск ассоциативных правил является одним из ключевых методов в Data mining и имеет большой потенциал в применении на медицинских данных с целью улучшения принятия решений и предсказании заболеваний.
Данная работа разбита на несколько разделов. Во 2 разделе работы дано классическое определение ассоциативным правилам и общий подход к их поиску. В 3 разделе рассмотрено применение ассоциативных правил в кардиологии. В 4 разделе рассмотрены методы дискретизации, позволяющие сократить потери информации при поиске ассоциативных правил и методы сокращения общего объёма правил.
2. Общие определения
Классическое определение ассоциативного правила выглядит следующим образом:
Пусть I = {i1, i2, i3, ...in} – множество атрибутов. D – множество из n транзакции, такое что D = {T1, T2, …, Tn } и где Ti – набор элементов из I. Ассоциативным правилом называется импликация X
 Y, где X
Y, где X I, YI, X
I, YI, X Y=
Y= .
.Правило имеет поддержку(support), где supp - процент транзакций из D, которые содержат X
 Y, supp(XY) = supp(XY). Правило справедливо с некоторой достоверностью (confidence), где conf - процент транзакций из D, таких что, если транзакция содержит X, то она также содержит Y, conf(XY) = supp(XY)/supp(X ).
Y, supp(XY) = supp(XY). Правило справедливо с некоторой достоверностью (confidence), где conf - процент транзакций из D, таких что, если транзакция содержит X, то она также содержит Y, conf(XY) = supp(XY)/supp(X ).Существует довольно много алгоритмов поиска ассоциативных правил из которых самыми известными являются Apriori, FP-growth, APACS2. В общем случае задача поиска ассоциативного правила сводится к двум этапам:
1) Осуществляется поиск и генерация наиболее частых наборов элементов, то есть таких наборов, у которых поддержка выше определённого значения.
2) Генерация правил на основе частых наборов с достоверностью выше определённого значения.
Классические ассоциативные правила позволяют работать лишь с категориальными атрибутами, но так как данные в большинстве своём не ограничиваются бинарными значениями в скором времени появились расширения ассоциативных правил.
Так, например обобщённые ассоциативные правила это правила, которые объединяют несколько правил вместе. При построении таких правил, элементы обычно группируются согласно иерархии, и их поиск ведется на самом высоком концептуальном уровне. Другим типом правил является количественные ассоциативные правила, у которых атрибуты могу принимать как категориальные, так и числовые значения. Помимо описанных выше ассоциативных правил существуют косвенные ассоциативные правила, ассоциативные правила c отрицанием, временные ассоциативные правила для событий связанных во времени и другие.
3. Применение в кардиологии.
Впервые применение ассоциативных правил в контексте сердечнососудистых заболеваний было проведено в 1999 году. В этой области были попытки использования и других инструментов, таких как нейронные сети, деревья решений, метод опорных векторов. Применение ассоциативных правил обусловлено тем, что они имеют важные преимущества по сравнению с традиционным машинным обучением или статистическими алгоритмами:
-они дают интерпретацию, основанную на вероятности появления паттерна и условную вероятность между двумя паттернами (например, отношение медицинскими метрик и факторов риска к артериальной узости)
-позволяют связывать комбинации предсказываемых атрибутов (предсказывать существование болезни в одной или двух артериях.)
-могут обрабатывать несколько предсказываемых атрибутов одновременно без необходимости разделения данных на множества или несколько прогонов (предсказания проблем для всех артерий, используя одно множество данных)
-могут находить паттерны, которые существуют на небольшом множестве атрибутов (что важно на небольших, но многоразмерных объёмах данных)
-каждое правило может относиться к перекрывающимся множествам данных, соотносясь с другими правилами (избегая фрагментации данных, где это возможно)
Кроме того, для медицинских данных многие другие методы потребовали бы множество моделей (моделей деревьев решений или регрессионных моделей), дополнительные меры для обработки редких случаев, или для создания адекватных атрибутов цели, и специальные процедуры для нахождения небольших подмножеств атрибутов связанных с определённой формой заболевания.
Однако, использование ассоциативных правил на медицинских данных сопряжено с некоторыми трудностями. Прежде всего это огромный объём получаемых ассоциативных правил, большая часть которых с точки зрения медицины не интересна и большие временные затраты на поиск релевантных правил. Второй проблемой является потеря информации, обусловленная применением чётких границ для численных и категориальных ассоциативных правил.
4. Проблемы использования ассоциативных правил и их решенние
В процессе работы, исследователи столкнулись с рядом проблем использования ассоциативных правил, таких как:
- генерация огромного количества правил при низкой поддержке, многие из которых с медицинской точки зрения бессмысленны;
- потеря информации при дискретизации числовых атрибутов, что ведёт к нахождению не всех «хороших» правил;
a) Сокращение количества правил
Одним их подходов к снижению количества правил является наложение ограничений на генерацию, как частых наборов, так и ассоциативных правил. Такими ограничениями могу быть:
- максимальная длина ассоциативного правила;
- группировка атрибутов;
- задание того, в какой части правила может на- ходиться атрибут;
Применение ограничений позволяет существенно сократить объём генерируемых правил.
б) Уменьшение потери информации.
В медицине большая часть информации представлена в виде числовых, категориальных, временных данных и для того чтобы иметь возможность применить классические ассоциативные правила необходимо разбивать числовые и временные атрибуты на интервалы. Такое разделение позволяет перейти к бинарным данным, увеличивая при этом количество атрибутов. Пример такого разбиения представлен на рисунке 1.
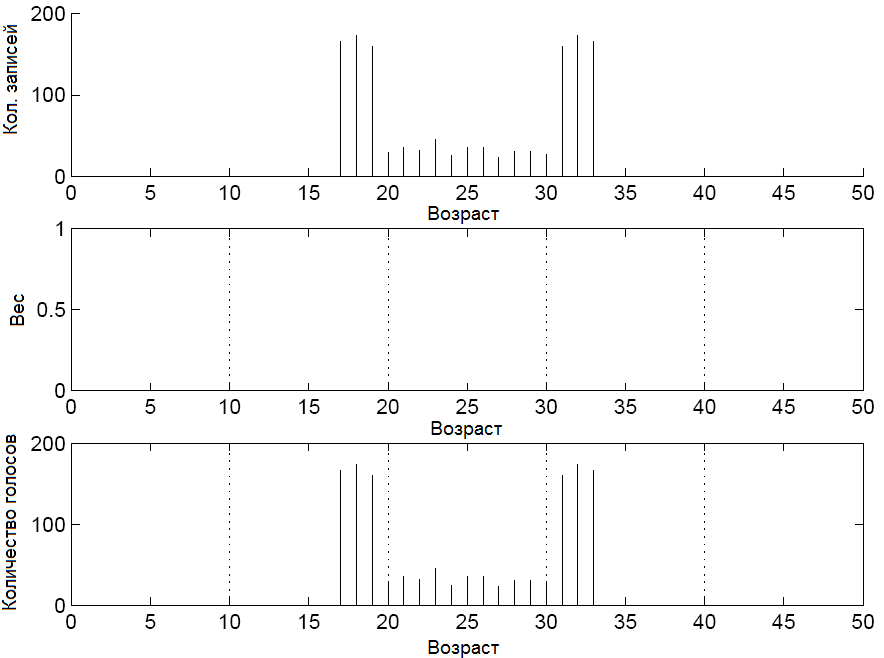
Рисунок 1
Использование такого подхода обладает следующими недостатками:
- если число интервалов для атрибута велико (длина интервала небольшая), то поддержка отдельного интервала будет низкой и некоторые правила не будут найдены.
- если длина интервала будет большой, то может уменьшиться доверие правила, и оно не будет найдено.
Одним из вариантов решения данной проблемы является применение перекрывающихся интервалов, пример которого представлен на рисунке 2.
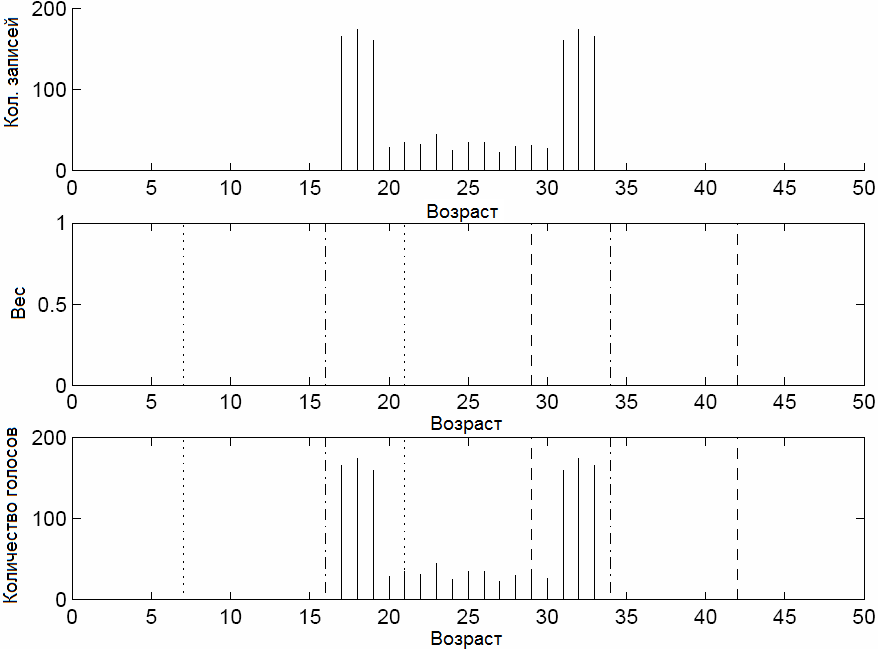
Рисунок 2
Хотя данный подход и позволяет несколько снизить потерю информации, он приводит к появлению огромного количества атрибутом по сравнению с предыдущим подходом и появлению большого числа неинтересных правил.
Потеря информации происходит из-за так называемой проблемы жёстких границ. Одной из главных проблем предыдущих подходов была в том, что значения, лежащие близко к границам разбиения интервалов не оказывали никакого вклада в поддержку множества и получаемые правила сильно зависели от выбора длин интервалов. Использование подхода нечёткой дискретизации позволяет решить эту проблему. Пример такой дискретизации представлен на рисунке 3.
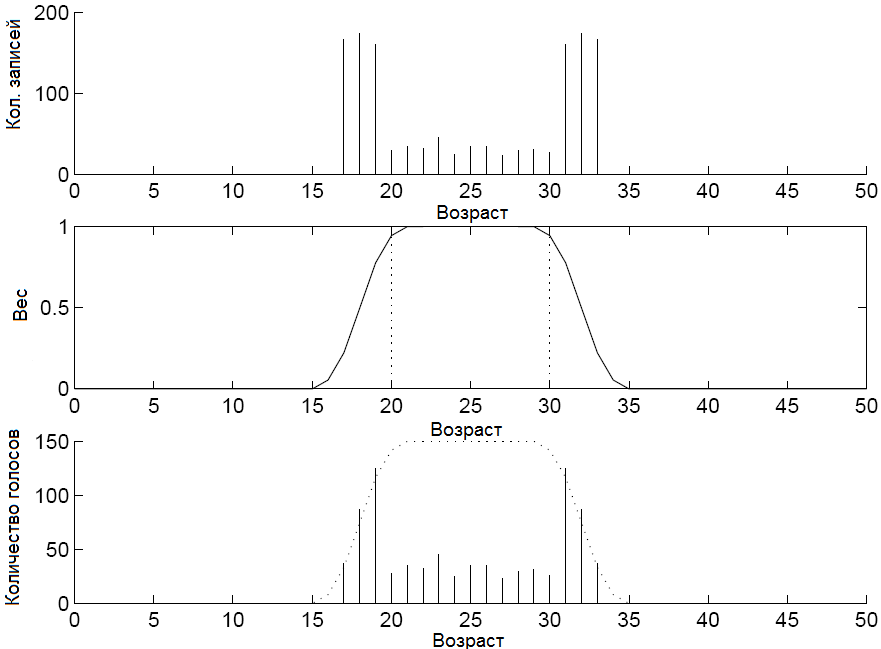
Рисунок 3
Выбор функций принадлежности для атрибутов может быть произведён как экспертом в области кардиологии, так и методом кластеризации. Данный подход известен под названием нечётких ассоциативных правил.
Заключение.
Ассоциативные правила дают широкие возможности в применении на медицинских данных и в частности в кардиологии. Они обладают рядом существенных преимуществ перед остальными методами интеллектуального анализа данных в этой области. Многие существующие проблемы применения ассоциативных правил решаемы. Возникает необходимость использования новых подходов к ассоциативным правилам и разработка качественно нового программного обеспечения.
Список литературы.
1. Kuok, Chan Man; Fu, Ada; Wong, Man Hon: Mining Fuzzy Association Rules in Databases. SIGMOD Record Volume 27, 1998.
2. Association Rule Discovery With the Train and Test Approach for Heart Disease Prediction. Carlos Ordonez IEEE TRANSACTIONS ON INFORMATION TECHNOLOGY IN BIOMEDICINE, VOL. 10, NO. 2, APRIL 2006
3. K. Wang, Y. He, and J. Han, “Pushing support сonstraints into association rules mining,” IEEE Trans. Knowl. Data Eng., vol. 15, no. 3, pp. 642–658, May/Jun. 2
4. Fuzzy Association Rules An Implementation in R. Lukas Helm. Vienna, 2.8.2007. Vienna University of Economics and Business Administration