
Документ: информационный анализ
| Вид материала | Документы |
- О публичном отчете образовательного учреждения, 44.82kb.
- Информационный бюллетень анализ динамики наркоманий, хронического алкоголизма и алкогольных, 258.01kb.
- 1. Затвердити державні санітарні правила "Основні анітарні правила забезпечення радіаційної, 3053.42kb.
- Опубликовано: ноябрь 2008, 1823.52kb.
- Функционально-стоимостной анализ и имитационное моделирование, 681.58kb.
- Перечень документов, необходимых для начала проведения аудиторской проверки, 130kb.
- Вопросы к экзамену по дисциплине «Анализ финансово-хозяйственной деятельности», 57.22kb.
- «Россия: ценности современного общества» инсор, 993.55kb.
- План рекламы документ, определяющий порядок проведения рекламных мероприятий в рамках, 151.75kb.
- Генеральный план стратегический документ территориального планирования 4 2 Анализ использования, 369.26kb.
G1 (за счет F [26, 196]) и G11 благодаря компактной расстановке блоков. Идея последнего заключается в том, чтобы ликвидировать полностью или частично проходы, обеспечив доступ к нужному блоку путем его транспортировки.
В одном случае весь фонд переводится на транспортное хранение и при поиске каждый раз приходит в движение (рис. 63, а), что экономически вряд ли оправдывает себя. В других случаях в движение приводятся только один нужный блок (шкаф-транспортер с эскалаторной подачей секций) или же несколько бло-| ков. Последний способ основан на принципе известной игры в «15»: величина L11 соответствует одному блоку и благодаря ей блоки перемещаются таким образом, чтобы в поле обозрения оказался нужный из них (рис. 63,6). В простейшем варианте оставляются один общий проход к торцевым стенкам блоков и один проход между блоками, за счет которого, сдвигая блоки, можно сделать проход между любыми из них; это напоминает известную всем ситуацию, когда, имея на книжной полке место только для одной книги, эту книгу можно поместить между двумя любыми книгами (рис. 63, в).
Еще один способ компактного хранения документов —- диагональный (рис. 64), где вертикальная система ступеней открывает доступ к первому ряду секций, под которым находится второй ряд, к любой секции которого можно попасть, сдвигая секции первого ряда за счет одной отсутствующей в каждой ступени секции.
Переходя к собственно информационным характеристикам, мы должны начать с величины V, которую невозможно оценить, не выяснив, что представляет собой типичный документ (единица хранения) в фонде, и, если имеется несколько форм, по которым фонд делится на составляющие, по каждой из них рассчитываются f и v с отклонениями от среднего, после чего определяют F (8), к (9), V (11) и К (см. раздел 2.1.).
(90)
Значительно большие трудности представляет определение неформальных информационных характеристик. Во-первых, это
В одном случае весь фонд переводится на транспортное хранение и при поиске каждый раз приходит в движение (рис. 63, а), что экономически вряд ли оправдывает себя. В других случаях в движение приводятся только один нужный блок (шкаф-транспортер с эскалаторной подачей секций) или же несколько бло-| ков. Последний способ основан на принципе известной игры в «15»: величина L11 соответствует одному блоку и благодаря ей блоки перемещаются таким образом, чтобы в поле обозрения оказался нужный из них (рис. 63,6). В простейшем варианте оставляются один общий проход к торцевым стенкам блоков и один проход между блоками, за счет которого, сдвигая блоки, можно сделать проход между любыми из них; это напоминает известную всем ситуацию, когда, имея на книжной полке место только для одной книги, эту книгу можно поместить между двумя любыми книгами (рис. 63, в).
Еще один способ компактного хранения документов —- диагональный (рис. 64), где вертикальная система ступеней открывает доступ к первому ряду секций, под которым находится второй ряд, к любой секции которого можно попасть, сдвигая секции первого ряда за счет одной отсутствующей в каждой ступени секции.
Переходя к собственно информационным характеристикам, мы должны начать с величины V, которую невозможно оценить, не выяснив, что представляет собой типичный документ (единица хранения) в фонде, и, если имеется несколько форм, по которым фонд делится на составляющие, по каждой из них рассчитываются f и v с отклонениями от среднего, после чего определяют F (8), к (9), V (11) и К (см. раздел 2.1.).
(90)
Значительно большие трудности представляет определение неформальных информационных характеристик. Во-первых, это
Рис. 63. Три варианта компактного размещения документных блоков в фонде (план)
n
общий тезаурус фонда а0=2аФ«ь причем всегДа Ш < а@ за счет
повторяющейся информации, включая дубликаты документов. CaQ вводится в соответствие VQ— количество поисковых признаков, т. е. язык фонда. Аналогично (27) определяется величина є. Практически же все ограничивается отношением ИИ а для фондов разной глубины комплектования
W § iV/vQ • v7, І If
где v
Определяя у-тезаурус как сумму поисковых образов входящих в фонд документов, получаем
ШШшЕВ (92)
где ciq—число документов с данным поисковым признаком; aQ/N — информационная нагрузка признака (Jq) . Следовательно, вличина -тезауруса зависит и от сумм поисковых образов и от информационной нагрузки признаков. Если же часть VQ фактически бездействует, то объем -тезауруса уменьшится.
Далее, поисковая нагрузка Jz = является косвенным показателем информативности фонда в целом для данного контингента потребителей R. Низкая поисковая нагрузка для части фонда может быть связана с изъянами в языке, неправильным индексированием, наличием устаревшей, непрофильной и даже такой информации, которую потребитель морально не готов воспринять. Поэтому в целом для фонда необходимо знать период полустарения (х и время теоретического устаревания информации т, определяемые по динамике падения спроса на документы ((17), (18)); знать структуру и динамику изменений потребительских интересов; учитывать уровень информационной культуры потребителей и влиять на этот уровень
Чтобы увеличить эффективность системы, нужно разбить фонд на субфонды — активный, с большой эксплуатационной нагрузкой J w и большими расходами EY (не менее 30 коп на единицу хранения ежегодно), и пассивный, с низкими величинами Jw и хз (последнее значительно менее 20 коп) (см. рис. 61). При таком разделении потребители выигрывают в оперативности получения
і наиболее часто спрашиваемой литературы, тогда как запросы на менее важные документы, хранящиеся в инвентарном порядке в менее доступном помещении, удовлетворяются, конечно, не так быстро.
Практически не используемые документы уничтожаются по акту экспертной комиеси [105, 138] либо переводятся на страховое хранение в выделенный для этого субфонд или отдельный фонд, условия хранения в которых зависят от того, какие документы выполняют страховую функцию: негативные микрофильмы, финансовые документы в ожидании истечения срока юридической значимости или же документы, имеющие историческое значение.
В составе активного субфонда рекомендуется в свою очередь, выделить оперативный субфонд с документами преимущественно группы А, имеющими исключительно большую эксплуатационную нагрузки, отчего важно, чтобы они находились всегда «под рукой». В результате подобной дифференциации в первую очередь выдаются оригиналы наиболее значимых документов, во вторую— микро- или макрорепродукции просто значимых и в третью — адреса документов страхового хранения. Дифференцированное хранение приносит пользу на любом уровне информационного обслуживания, начиная от письменного стола и кончая центральным архивом или библиотекой [255].
И еще одно условие правильной организации документных фондов—обеспечение единой системы учета, хранения и использования всех циркулируемых здесь типов документов на основе общего языка или хорошо «увязанных» между собой языков. Это требование распространяется и на документы с негативным грифом (см. 3.1.) разной степени ограничения. При этом одинаково плохо, когда общее ограничение распространяется на фонд или субфонд, далеко не полностью состоящий из таких документов, и когда по этому принципу выделяется особый субфонд. Наилучшим вариантом является система глобального поиска, выдающая все документы по данному запросу и уже затем разделяющая их в соответствии с негативным , грифом.
'Переходя к собственно поисковым задачам, мы сделаем на основании изложенного следующий вывод. Основные показатели поискового процесса: быстродействие, надежность (полнота / и точность), уровень поискового шума — зависят от ряда взаимосвязанных факторов, из которых численный объем фонда благодаря селективному разделению является не самым главным.
Возвращаясь к схеме на рис. 20, мы видим, что эффективность работы поисковой системы зависит от состояния связей a€d—y&d и 0Ш—А- Низкая величина е объясняется, в частности, недостаточной суммой - (поискового образа и ошибками при индексировании. При этом избыточное индексирование
сразу же увеличивает полноту й точность Поиска І уровень поискового шума, который, по видимому, должен быть отнюдь не минимальным.
В связи а—т#г выступают два отмеченных выше момента: умение потребителя рыразить свою потребность и затем сформулировать ее — самому или с помощью специалиста — в терминах системы (поисковый образ запроса).
Потери в (27) и г) (28) находят выражение в б (32), показывая расхождение с величиной І В целом для фонда эти потери определяются путем постановки экспериментов по выборочным поискам заведомо известной, нужной и имеющейся в фонде литературы, с последующей оценкой среднего числа потерь, анализом их причин и рекомендациями по их уменьшению.
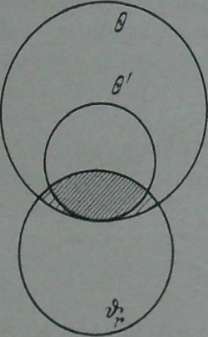
Типичная поисковая ситуация лучше всего представляется на диаграмме Венна. По аналогии с рис. 11 имеем три множества: І — тезаурус фонда; 0'— тезаурус документов, полученных при поиске, где 0'св; Йг — тезаурус данного потребителя (рис. 65). При этом возможны восемь подмножеств:
Рис. 65. Соотношение тезаурусов фонда, потребителя и найденных при поиске документов Частая штриховка показывает объем полученной полезной информации; редкая — потери при поиске
- ©e'flr — область за пределами названных тезаурусов.
- 00'ОГ— основная часть фонда, не соответствующая ни тезаурусу извлеченных документов, ни тезаурусу потребителя.
- "0©7ОГ=О
- вв'-ду — часть тезауруса потребителя, не соответствующая тезаурусу фонда.
- вв'дг — часть тезауруса извлеченных документов, не соответствующая тезаурусу потребителя (поисковый шум).
- в0г=О.
- 00'дг — часть пересекающегося множества тезаурусов фонда и потребителя, не извлеченная при поиске (неполнота поиска).
- 00'Ог—полезная информация, полученная при поиске.
Таким образом, по отношению к интересам данного потре-

(94)
где также @/г=в/ ПОу. Причем Фг=(вФг)Л(9'Фг)Л[(вйг)\
(95)
чч(0'Ог) = (00,-Ог)Л(ввг)Л(вёг). Общая полнота получен- ной потребителем информации равна
Ь, = ЬР + Ь2 = (Є'ЬГ)ІЬГ.
При учете поискового шума (в'0г)=9/\(Э/дг) имеем
I=В \ ИИІ при И < (вЧ).
Практически это соотношение можно получить по числу найденных при поиске документов, в том числе не представляющих интереса для потребителя, и по числу всех необходимых документов, определяемых условно путем постановки прогноза ba=NZ) иШи. При этом величина Ьъ определяется экспериментально и поэтому более точно. Когда же определяется средняя полнота поиска (Ьв), учитывают не только все сделанные отказы, но и потенциальные отказы, которые не были сделаны потому, что потребители плохо знают возможности системы (тематику комплектования), либо знают их достаточно хорошо, чтобы не делать запросы, так как они не будут выполнены. Последнее очень важно при анализе эффективности, например, библиотечных фондов, когда создается иллюзия, что каталог вполне обеспечивает нужды читателей.
Касаясь уровня и структуры поискового шума, следует отметить прямую зависимость между разницей в объемах тезаурусов фонда и потребителя и относительным количеством получаемой при поисках информации. Именно поэтому в центральных фондах универсального комплектования поисковый шум всегда больше, чем в специализированных, локальных фондах, с, может быть, относительно меньшей полнотой комплектования (см. примечание на стр. 89—90). Так, функция первых все более становится страховой, где по уже имеющемуся адресу (например, фамилии автора) получают интересуемую документацию. Углубление индексирования, как уже говорилось, увеличивает величину е, при этом Щ также увеличивается, и за счет ЩЙ! резко возрастает ©6'дг. С другой стороны, это также говорилось, При (б'Фг) > (б'Фг) поисковый шум проявляет свойство вообще информационного шума, подавляющего полезную информацию и способствующего ее потерям. В этом отношении очень важно
изучить структуру поискового шума, который вызывается суммой ошибок в ходе документационных процессов І.
Так проявляется взаимозависимость между величиной фонда, полнотой комплектования и поиска и уровнем шума. Можно увеличить полноту сбора, перегрузив при этом фонд бесполезной информацией и увеличив поисковый шум; можно глубоко проиндексировать все документы, и поисковый шум возрастет еще более. Очевидно, необходим оптимум.
В развитии поисковых систем было три этапа: ставились задачи поиска конкретных документов и других объектов, поточ возникла необходимость в их подборках и расстановках, а теперь— необходимость не в документах, а в данных, оформляемых в виде вторичных документов. Исследования в области теории и методологии поиска коснулись в основном первых двух этапов [17, 23, 128, 150, 235]. На базе этой методологии осуществлялась техническая реализация систем [9, 144, 148, 205]. И только в самых последних работах отразился переход к третьему этапу [156, 216, 240].
| | § | ::; щ | 1.1.1.1 |
| | - • U | /./. 1.0. % | |
| | и.о. | 1.1.0.1. | |
| 1 | | 1.1.0.0. | |
| | | 1.0.1.1. | |
| | 1.0. | тт | |
| | 1.0.0. | 1.0.0.1. | |
| | | ЮМ.: ' | |
| | | 0.1.1. | 0.1.1.1. |
| | ол | 0.1.1.0. | |
| | 0.1.0. | 0.1.0.1. | |
| 1 | | 0.1.0.0. і | |
| | 0.0.1. | 0.0.1.1. | |
| | 0.0. | 0.0.1.0. | |
| | 0.0.0. | 0.0.0.1. | |
| | | 0.0.0.0. | |
| | |||