
Информационные технологии управления
| Вид материала | Документы |
- Темы рефератов по курсу «Основы автоматизированного управления», 13.91kb.
- Название Предмет Направление, 921.62kb.
- Информационные технологии в экономике и управлении, 1611.88kb.
- Рефераты по дисциплине «Информационные технологии в скс и Т. Оргтехника» Интернет-реклама,, 15.93kb.
- Вавилова в процессе проведения экзамена и приема зачетов по 2-м модулям дисциплины, 130.51kb.
- Тематический план изучения дисциплины «Информационные технологии управления» по специальности:, 363.97kb.
- Международная конференция «Информационные технологии в образовании и науке», 86.4kb.
- Программа-минимум кандидатского -экзамена по специальности 08. 00., 203.78kb.
- Программа минимум кандидатского экзамена по специальности 08. 00. 13 «Математические, 200.26kb.
- Программа «информатика и икт (информационные и коммуникационные технологии)», 443.93kb.
3.1.2. Документальные базы данныхДокументальные базы данных хранят документы, т.е. данные неопределенной или переменной структуры и бывают полнотекстовыми или библиографическо-реферативными. Подобные базы данных создаются в рамках документальных систем – систем, предназначенных для обработки, поиска, представления полнотекстовых документов или справочно-реферативной информации. Документальные системы ведут свое происхождение от библиотечно-реферативных служб или информационных центров, выпускающих реферативную информацию (обзоры, экспресс-информация, реферативные журналы). Современные документальные системы часто построены в виде системы гипертекстов (см. раздел 3.3.), реализуют современные модели поиска такие как контекстный, тематический, нечеткий поиск, т.е. обладает свойствами информационно-поисковых систем (см. раздел 3.2.). 3.1.3. Информационные хранилищаОдно из актуальных направлений современной информатики – интеграция данных. Системы интеграции данных должны обрабатывать запросы, для ответа на которые может потребоваться извлечение и обобщение данных из различных источников. При этом трудности интеграции обусловлены следующим:
Наибольшую популярность приобрели два подхода к решению задачи интеграции данных – хранилища данных (Data Warehouse) и виртуальные хранилища. Хранилища данныхХранилище данных - многомерный массив данных, сформированный из баз данных и информационных массивов внешнего экономического окружения за длительный период деятельности предприятия (организации), снабженный процедурами извлечения и использования информации для анализа и прогнозирования. При использовании хранилища данных (ХД):
Процесс обработки данных разделяется на два этапа:
Хранилище данных характеризуется следующими особенностями:
Преимущество хранилища данных заключается в достаточно высокой скорости выполнения запроса, для чего используется эффективный аппарат формирования запросов. Недостаток – в отсутствии синхронизации хранилища с источником данных, что делает невозможным актуализацию данных. При изменении данных в источнике требуется операция по передаче новой порции данных в хранилище, а не их обновления. Несмотря на этот недостаток, хранилища данных являются ядром технологии комплексного использования сведений, находящихся в различных баз данных. Эффективная архитектура хранилища данных должна быть организована таким образом, чтобы быть составной частью информационной системы управления предприятием (или, по крайней мере, иметь связь со всеми доступными данными). При этом необходимо использовать специальные технологии работы с корпоративными базами данных (например, Oracle, Sybase, MS SQL Server). Высокопроизводительная технология хранилищ данных, позволяющая пользователям организовать и эффективно использовать базу данных предприятия практически неограниченной сложности, разработана компанией StatSoft enterprise systems и называется SENS - STATISTICA Enterprise System и SEWSS - STATISTICA Enterprise-Wide SPC System. Рынок СУБД для ХД состоит из продуктов, обеспечивающих программную инфраструктуру для поддержки хранилища любого размера. Небольшим считается хранилище размером меньше 5Тбайт, средним – 5-30Тбайт, а крупное ХД – больше 20Тбайт. В 2006 году среди лидеров названы СУБД, разработанные: Teradata, IBM, Oracle, Sybase, Microsoft. Концепции хранилищ данных дала начало развитию концепциям и технологиям интеллектуального анализа данных - добыча данных. Виртуальные хранилищаПри использовании виртуальных хранилищ:
Рассматривая типичную организацию виртуального хранилища, выделяют два уровня – логический и физический. Логический уровень определяется выбором модели данных и языка запросов для этой модели. Выбранная модель используется далее для представления данных, извлекаемых из всех источников. Таким образом, пользователь получает возможность унифицированного доступа ко всем интегрируемым данным. Архитектура виртуального хранилища основана на распространенной концепции посредников. Согласно этой концепции существует два типа компонентов виртуального хранилища – обертка и посредник:
Двухкомпонентная система виртуального хранилища предоставляет возможность построения сложной сети взаимодействующих между собой посредников, что позволяет обобщать данные различными способами для удовлетворения нужд различных приложений, взаимодействующих с виртуальным хранилищем. Важно отметить, что посредник не содержит данных, а интеграция происходит, как правило, за счет использования техники представлений. Пользователь получает возможность унифицированного доступа ко всем интегрируемым данным, при этом пользователь видит внешние данные как локальные и не заботится об управлении доступом к источнику. Эта возможность обеспечивается специальной моделью данных виртуального хранилища. Задача построения виртуального хранилища сводится к созданию оберток и посредников, для чего необходимо иметь утилиты, позволяющие легко их генерировать. Существуют специальные декларативные языки, на которых описываются обертки и посредники. По этим описаниям происходит их генерация. Преимущество виртуальных хранилищ заключается в гарантии того, что пользователь получает только «свежие» данные. Недостаток – в том, что поскольку источники могут значительно отличаться, возникают трудности, связанные с оптимизацией запросов, и дополнительные расходы на конвертацию данных во время выполнения запроса, что существенно снижает производительность систем, использующих данный подход. Однако, несмотря на недостатки, для построения систем, объединяющих большое количество источников, содержание которых часто изменяется (например, Web-серверы), наиболее предпочтительным является виртуальный подход, поэтому в последнее время активно ведутся исследования именно в этом направлении. Переходя к подробному рассмотрению виртуального подхода, отметим, что многие методы, используемые при решении проблем в контексте этого подхода, часто при небольшой модификации применимы и при реализации хранилищ данных. 3.1.4. Базы метаданныхМетаданныеМетаданные – данные о данных – один из элементов общей информационной культуры, этап или предпосылка всякой успешной информационной деятельности. Метаданные – данные о данных: об их составе и структуре, формате представления, методах доступа и требуемых для этого полномочиях пользователей, о месте хранения, их семантике, источнике, владельце и т.д. Метаданные существуют в виде «бумажные» каталогов, инвенториев, реестров, справочников, баз метаданных. Метаданные могут использоваться как:
БМД представляют интерес с точки зрения проектирования распределенных БД, систем, поддерживающих режим коллективного пользования, а также в плане регламентации эффективного межведомственного и межрегионального обмена данными в национальных и региональных масштабах. Одним из примеров обстоятельного описания национальных информационных ресурсов может служить инвенторий (система инвентаризации) Австралийского бюро минеральных ресурсов, геологии и геофизики. Инвенторий включает стандартизованные и индексированные описания 253 БД, из них 57 библиографических и 196 фактографических, созданных 37 организациями страны. Описание приведено по следующим позициям: имя БД; сокращенное наименование БД; тип БД (библиографическая/фактографическая, закрытая (более не обновляемая), активная (регулярно обновляемая)); тематика БД; территориальная привязка данных; период времени, охватываемый данными; ключевые слова-дескрипторы, относящиеся к тематике и местоположению; тип компьютера, используемой СУБД, магнитного носителя; число единиц хранения; тип выходной документации (текст, таблицы, графика, карты и т.п.); доступ к данным/приобретение на определенных условиях; ссылки на руководства пользователя и другие инструктивные материалы, описания из литературных источников; комментарии и дополнительная информация; адрес для контактов; дата составления описания. Другим примером системы инвентаризации крупных информационных массивов субконтинентального уровня является геоинформационная система CORINE ЕЭС. Формируемый в ней каталог исходных данных обеспечивает доступ к внешним информационным ресурсам всех заинтересованных служб, поскольку данные, аккумулируемые непосредственно системой, составляют лишь небольшую часть всех информационных ресурсов, требуемых для решаемых задач. Каталог реализован средствами интегрированной системы ISIS (программного средства, включающего функции ведения баз данных и рекомендованного ЮНЕСКО для свободного использования как public domain) и обеспечивает доступ в режиме on-line к коллективным банкам данных. Доступ к каталогу будет производиться с использованием коммуникационного языка CCL (Common Command Language) и графического интерфейса, одним из элементов которого будут видеоэкранные карты, позволяющие представить пространственную локализацию данных, экстрагированных из каталога по запросу пользователя. ДепозитарииДепозитарии относятся к активно развивающимся информационным технологиям управления корпоративными метаданными и играющим ключевую роль в создании надежных высокоразвитых ИС. Депозитарий – компонента СУБД, обеспечивающая формирование словарей - справочников данных информационной системы. Объектами депозитария являются метаданные. Депозитарии обеспечивают:
Обмен информацией в обществе осуществляется главным образом в текстовой форме. Поэтому не случайно, что весьма значительную долю информационных ресурсов современных информационных систем составляет текстовая информация. Созданию эффективных технологий хранения, обработки и поиска текстовой информации стало уделяться большое внимание уже на ранних стадиях развития информационных систем. Активные исследования и практические разработки в этой области начались еще в 50-х годах прошлого века, с того времени, когда средства вычислительной техники обеспечили возможность ввода-вывода текстовой информации. Среди информационных систем, имеющих дело с текстовой информацией, наиболее распространенными являются системы текстового поиска. Их задача заключается в том, чтобы находить в хранимой в компьютере коллекции текстовых документов на естественном языке такие документы, которые интересуют пользователя. «Коллекция документов» - совокупность хранимых в системе документов (раньше использовались термины «поисковый массив», «архив» и т.п.) Каждая система текстового поиска может поддерживать несколько различных коллекций документов. Развитие систем текстового поиска стимулировалось в значительной мере потребностями информационной поддержки научных исследований и образования, разработками автоматизированных библиотечных систем. Однако в последние годы они все активнее используются также в управлении организациями и во многих других сферах деятельности Технологии текстового поиска основаны на тематическом анализе текста и анализе смысловых связей. Основные методы поиска – контекстный поиск, тематический поиск, нечеткий поиск, поиск по подобию – обеспечивают возможность автоматического реферирования и автоматической рубрикации текстов. Технологии текстового поиска поддерживаются средствами лингвистического и программного обеспечения. 3.2.1. Методы поиска текстовой информацииКонтекстный поискСредства контекстного поиска позволяют искать документы по содержащимся в них словам и фразам, которые могут объединяться логическими операциями. Результаты поиска ранжируются по релевантности (соответствия критерию поиска) на основе частоты встречаемости слов запроса в найденных документах и во всей коллекции в целом. Для обеспечения высокой скорости поиска по коллекции документов предварительно создается индекс, в котором для каждого слова устанавливаются ссылки на все документы, где это слово встречалось. Дополнительно в индексе хранится информация о положении слова в документе, частоте встречаемости и т.п. Все слова в текстовом индексе могут храниться в нормальной форме, что уменьшает его объем в несколько раз. Дополнительно из индекса устраняются часто встречающиеся стоп-слова, не участвующие в поиске (союзы, предлоги, наречия и т.п.). В результате учета морфологии (русского и английского языков) находятся документы, содержащие все грамматические формы слов запроса. Использование синтаксического анализатора при индексации документов позволяет снимать морфологическую омонимию в тех случаях, когда различные слова имеют совпадающие грамматические формы. Подключение тезауруса позволяет расширить запрос близкими по смыслу словами, используя разные типы смысловых связей. Тематический поискВозможности тематического поиска опираются на средства автоматического анализа текста и позволяют найти в коллекции документов как документы по заданной теме, так и темы, связанные по смыслу с заданной. Эти возможности могут оказать большую помощь при поиске, например в случае, если пользователь затрудняется точно подобрать ключевые слова, или же, если он хочет сузить область поиска, уточнив тематику, по которой следует искать документы. Поиск по теме обладает более высокой точностью и полнотой по сравнению с простым контекстным поиском. Так, если контекстный поиск находит все документы, содержащие заданные слова, то тематический поиск возвращает лишь те документы, в которых словам запроса соответствует одна из ключевых тем. Кроме того, он позволяет найти документы, вовсе не содержащие слов из названия заданной темы, однако имеющие к ней отношение. Эта возможность оказывается полезна, прежде всего, аналитику, ведущему мониторинг событий, связанных с интересующей темой. Она позволяет определить «смысловое окружение» темы в коллекции документов и, уточнив зарос, выбрать требуемую информацию. Например, в ответ на запрос «нефть» можно получить следующий список тем «добыча нефти», «экспорт нефти», «государственная нефтяная компания Азербайджана», «Азербайджан», «Ангарский НХК», «топливные компании», «ЮКОС» и т.д. Нечеткий поискТехнология нечеткого поиска позволяет расширять запрос близкими по написанию словами, содержащимися в коллекции документов, по которым ведется поиск. Оригинальный алгоритм способен найти все лексикографически близкие слова, отличающиеся заменами, пропусками и вставками символов. Нечеткий поиск целесообразно применять при поиске слов с опечатками, а также в тех случаях, когда возникают сомнения в правильном написании фамилии, названия организации и т.п. Например, запрос «Инкомбанк» может быть расширен словами: «инкомбан», «инко-банки», «винкомбанке». А если пользователь забыл точное название медицинского препарата «ипрониазид», то можно задать что-нибудь похожее, например «импронизид», нужные документы будут найдены. Алгоритмы, используемые при реализации нечеткого поиска, основаны на оригинальной системе ассоциативного доступа к словам, содержащимся в текстовом индексе. В качестве единиц поиска используются цепочки букв, составляющих слово. Для ускорения поиска предварительно создается отдельный индекс, содержащий фрагменты слов со ссылками на слова, в которых эти фрагменты встретились. Таким образом находятся слова, фрагменты которых совпадают с фрагментами слова в запросе. Задавая длину фрагментов и их количество в слове, можно регулировать полноту поиска — отбирать слова по степени близости к запросу. Поиск по подобиюПоиск документов по подобию позволяет найти документы, близкие по содержанию к заданному. В качестве модели смысла текста при сравнении документов используются семантическая сеть или набор ключевых тем. Семантическая (смысловая) структура коллекция документов строится с использованием средств автоматического анализа текста и нейросетевых алгоритмов, в частности алгоритмов классификации на основе самоорганизующихся тематических карт, тематических сетей и пр. Т  ематическая карта разбита на ряд шестиугольных областей, каждой из которых соответствует множество близких по содержанию документов - тематический класс. При этом близким областям обычно соответствуют близкие классы документов, что является основной особенностью карты. Яркость области пропорциональна количеству отнесенных к ней документов. Встречающиеся на карте названия отражают основные темы документов в соответствующих областях. ематическая карта разбита на ряд шестиугольных областей, каждой из которых соответствует множество близких по содержанию документов - тематический класс. При этом близким областям обычно соответствуют близкие классы документов, что является основной особенностью карты. Яркость области пропорциональна количеству отнесенных к ней документов. Встречающиеся на карте названия отражают основные темы документов в соответствующих областях. Щелкнув мышью по выбранной области, можно просмотреть фрагмент карты в увеличенном масштабе. Для смещения окна увеличения по карте следуют использовать стрелки "компаса", расположенного под картой. Щелчок по центру компаса вызывает возврат к полному виду карты. Для получения подробной информации об интересующей области достаточно щелкнуть мышью шестиугольник карты. При этом справа от карты отображается список основных тем документов в выбранной области. Снизу под картой представляется список всех документов, относящихся к области, с автоматически построенными рефератами. Щелкнув мышью по названию темы, можно получить список документов по теме из области. Посещенные области карты помечаются голубым цветом. Такое отображение позволяет наглядно изобразить тематический состав большой коллекции документов в целом (десятки тысяч текстов) и помочь пользователю сориентироваться в океане информации. Семантическая (тематическая) сеть документов представляется рядом основных тем коллекции с ассоциативными связями между ними. Щелкнув мышью по интересующей теме, можно перейти к следующему фрагменту сети, который содержит темы, наиболее сильно связанные с выбранной. Размер шара, соответствующего теме, пропорционален общему количеству документов по теме. Яркость связи пропорциональная силе ассоциативной связи между парой тем. При этом стрелкой обозначены связи от темы к подтеме. Д  ля поиска фрагмента семантической сети, относящегося к интересующему запросу, пользователь вводит соответствующие слова в поле формы программного приложения. Яркость окраски шаров, соответствующих найденным темам, пропорциональна релевантности (близости) тем к запросу. Для поиска смысловых цепочек вводятся слова, описывающие пару тем. На рисунке отображается ряд путей, представляющих наиболее сильные связи между заданными темами. Для удобства восприятия на картинке отображается не более двадцати тем, наиболее сильно связанных с введенным запросом или выбранной темой. Программное приложение обеспечивает возможность фильтровать темы, отображаемые на картинке, по частоте встречаемости в документах, фильтровать связи между темами по силе ассоциации в коллекции документов. ля поиска фрагмента семантической сети, относящегося к интересующему запросу, пользователь вводит соответствующие слова в поле формы программного приложения. Яркость окраски шаров, соответствующих найденным темам, пропорциональна релевантности (близости) тем к запросу. Для поиска смысловых цепочек вводятся слова, описывающие пару тем. На рисунке отображается ряд путей, представляющих наиболее сильные связи между заданными темами. Для удобства восприятия на картинке отображается не более двадцати тем, наиболее сильно связанных с введенным запросом или выбранной темой. Программное приложение обеспечивает возможность фильтровать темы, отображаемые на картинке, по частоте встречаемости в документах, фильтровать связи между темами по силе ассоциации в коллекции документов. В нижней части экрана программного приложения отображается список документов по темам запроса, которые упорядочены по релевантности. Дополнительно на каждый документ выдается его реферат, также построенный автоматически, который содержит наиболее информативный фрагмент (или фрагменты) текста. В зависимости от вида поиска (по запросу или по отдельной теме) реферат может быть общий или тематический. В правом окне дополнительно отображается полный список связанных тем. Щелкнув мышью по выбранной теме в списке, можно получить в нижней части экрана список документов, которые относятся и к темам запроса и к выбранной теме - раскрывают смысловую связь. При этом перемещение по навигатору, сопровождающееся сменой фрагмента семантической сети, не происходит. 3.2.3. Лингвистическое обеспечение текстового поискаПри обработке полнотекстовых документов в системах текстового поиска приходится иметь дело со средствами обработки естественного языка. Эти средства представляют собой довольно сложный и важный функциональный компонент таких систем. Средства обработки естественного языка позволяют:
Для выполнения указанных функций в большинстве систем рассматриваемого класса используются комплексы средств лингвистической поддержки. Такой комплекс может включать различные словари, тезаурусы, онтологические спецификации предметной области системы.
3.2.4. Методы управления даннымиХотя некоторые элементы управления данными, используемые в системах баз данных, применимы и для систем текстового поиска, для управления текстовыми данными необходимо использовать иные методы по следующим причинам:
Выход из положения заключается в том, чтобы в процессе обработки пользовательского запроса работать не с самими документами, а с некоторыми структурированными представлениями их содержания, которые называют представлениями документов (представители документа). Использование представления документа вместо непосредственно самого документа позволяет избежать трудоемкого процесса просмотра и анализа полного его содержания на стадии поиска и вместе с тем использовать преимущества структурированного представления для повышения эффективности поиска. В современных системах текстового поиска используются различные подходы к построению представлений хранимых документов. От характера используемых представлений документ существенно зависит качество поиска– его точность, полнота производительность и другие характеристики. Поскольку введенные в систему текстовые документы остаются, как правило, неизменными на протяжении всего времени их существования системе, построение представления каждого имеющегося в системе документа можно осуществлять однократно на этапе его ввода в систему. Автоматическое реферирование документаНа ранних стадиях развития технологий обработки текстов использовалось простейшее представление документов, обеспечивающее, тем не менее, и по сей день высокое качество поиска. В качестве такого представления служила совокупность слов или словосочетаний лексики предметной области системы, характеризующая содержание данного документа. Эти слова и словосочетания называются дескрипторами. Создание дескрипторов может производиться вручную авторами документов, экспертами в предметной области, подготавливающими документ к вводу в систему, или автоматически системными механизмами на основе анализа текста документа. В этом случае формируется реферат документа. Средства автоматического реферирования позволяют выделить наиболее информативные фрагменты текста, либо синтезировать реферат на естественном языке в форме простых предложений, отражающих ключевые отношения между ключевыми понятиями. Функция реферирования может использоваться для построения:
Индексирование документовПредставление документа обычно конструируется на основе множества свойств (атрибутов) этого документа. В простых системах текстового поиска эти атрибуты, как уже указывалось, вообще не являются какими-либо компонентами содержания документа. В качестве таких атрибутов могут использоваться какие-либо внешние (по отношению к тексту документа) его характеристики, и совсем не обязательно, чтобы они идентифицировали его уникальным образом. Можно, например, использовать регистрационный номер документа в архиве, дату его регистрации, название организации — получателя документа, указание места его хранения и пр. В качестве таких внешних атрибутов документов могут также использоваться рубрики классификаторов документов или элементы метаданных Дублинского ядра. Дублинское ядро – это набор элементов метаданных, смысл которых описан вербально и зафиксирован в спецификации определяющего его стандарта. В терминах значений этих элементов можно описывать содержание различного рода текстовых документов и документов, представленных в иных средах. Такое описание будет однозначно пониматься всем сообществом, использующим Дублинское ядро для представления документов и пользовательских запросов. Первоначальная версия Дублинского ядра, которая включала 13 элементов, была предложена на состоявшемся в 1995 г. в Дублине (США) симпозиуме, организованном для описания информационных ресурсов библиотечных систем, в частности информационных ресурсов Веб и т.п. Развитие Дублинского ядра поддерживается специально учрежденной для этой цели организацией — Инициативой по метаданным Дублинского ядра. Текущая версия спецификаций Дублинского ядра была принята в качестве стандарта в 1999 г. Она включает 15 элементов метаданных. Рубрикация документовАвтоматическая рубрикация позволяет создавать иерархические рубрикаторы на основании анализа коллекций документов и классифицировать документы по рубрикам. Рубрикатор (классификатор) может представлять иерархию главных тем и подтем, которые автоматически выделены в коллекции документов. Для построения рубрикатора используются методы статистического анализа, в том числе кластерного анализа, который объединяет в рубрики документы близкого содержания, имеющие общие темы. Получаемые результаты могут служить основой для построения более строгих классификаторов после предварительной корректировки экспертом, или же сразу использоваться в готовом виде - например, в качестве электронного глоссария. Подобный рубрикатор, сформированный на базе эталонных текстов, может использоваться для автоматической классификации новых документов. Множество документов, найденных в результате контекстного поиска, подвергается процедуре иерархической кластеризации, в ходе которой документы близкого содержания объединяются в тематические рубрики и строится дерево. Узлу дерева соответствует множество документов, которые имеют темы, указанные в названии рубрики. Кроме этого, все документы, находящиеся в подрубриках дерева, содержат темы из более высоких рубрик.  Рис. 3.22. Пример построения иерархического рубрикатора 3.2.5. Программное обеспечение текстового поискаПрограммные средства для разработки представлены разнообразными библиотеками анализа русского текста и выделения в них различных сущностей, автоматической классификации и построения иерархических рубрикаторов. Разработанные программные модули встраиваются в информационно-поисковые системы. На российском рынке широко представлены продукты RCO компании "Гарант-Парк-Интернет", предназначенные для внедрения в базы данных и информационно-поисковые системы и позволяющие задействовать широкий арсенал лингвистических и аналитических средств для решения прикладных задач, требующих компьютерной обработки документов на естественном языке. 3.2.6. Информационно-поисковые системыИнформационно-поисковые системы (ИПС) предназначены для хранения, поиска и выдачи текстовой информации по запросу пользователя. Поисковый процесс представлен четырьмя стадиями:
Информационно-поисковые системы - совокупность информационно-поисковых массивов, их носителей, информационно-поискового языка, правил его использования, критерия выдачи, программных и технических средств ИПС основаны на технологиях текстового поиска. При поиске ИПС обеспечивает индексацию всех документов пользователя. В процессе индексации все слова, содержащиеся в документах, разбиваются по следующим семантическим классам:
Разбиение осуществляется на основе соответствующих словарей, которые должны быть составной частью системы. К неизвестным словам будут отнесены в первую очередь многие специальные слова предметной области. Туда же попадут новообразованные термины и слова, содержащие ошибки. На основе индекса осуществляется построение векторного представления документов, после чего ИПС производит иерархическую кластеризацию множества документов, в результате чего получается разбиение этого множества на тематические группы. В ходе диалога с пользователем происходит выбор одного или нескольких наиболее релевантных кластеров документов и задание характеристик поискового процесса. 3.2.7. Информационные языкиВ ИПС используются информационные языки. Информационный язык – формализованный искусственный язык, предназначенный для индексирования документов, информационных запросов и описания фактов с целью последующего хранения и поиска. Ниже приведена классификация информационных языков. 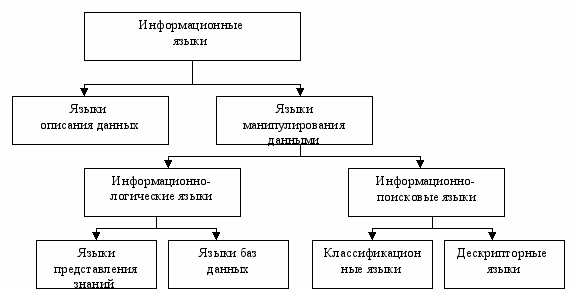 Рис. 3.23. Классификация информационных языков Языки описания данныхОдной из первых попыток создания языка описания данных (ЯОД) был язык DL/1 (Data Language #1) фирмы IBM. В настоящее время в связи с широким распространением SQL, в котором предусмотрена компонента описания БД, стандартом ЯОД является данная компонента SQL. Поскольку этих описательных возможностей, тем не менее, обычно оказывается недостаточно и SQL не является единственным средством разработки АИС, существуют и другие подходы, которые обычно базируются на понятии «словарь данных» (файл или таблица БД), который содержит описания данных и типов их обработки. Языки манипулирования даннымиЯзыки манипулирования данными обеспечивают поиск данных и отображение данных. Поиск данных предполагает наличие критерия смыслового соответствия или решающего правила, определяющего факт формальной релевантности поискового образа документа поисковому образу запроса. В общем случае критерий смыслового соответствия является некоторым условным высказыванием (предикатом), область истинности которого есть множество выдаваемых документов. Эта концепция лежит в основе большинства языков запросов (STAIRS, IRBIS, SQL и пр.). Различают:
Информационно-поисковые языкиВ информационно-поисковых языках выделяют: 1. классификационные языки. Предполагается, что ИПС заранее содержит все классы, к которым может быть отнесен любой документ, закодированный соответствующим индексом. Классификационные языки используются для построения иерархической (древовидная) организация информации, которая называется классификатором. Классификатор – систематизированный перечень объектов, каждому из которых присвоен определенный код. Иерархические классификаторы могут быть разделены на два типа:
Разделы классификатора называются рубриками. Библиотечный аналог классификационной ИПС – систематический каталог. 2. дескрипторные языки, позволяющие приписать каждому документу несколько дескрипторов (совокупность ключевых слов), каждый из которых является именем широкого класса понятий, терминов и, следовательно, помечает множество, в которое данный документ входит. В основе дескрипторных информационно-поисковых языков находятся тезаурусы (рассмотренные ранее). Необходимо заметить, что иерархические классификационные системы также в ограниченных масштабах используют дескрипторные принципы. Между логическими и поисковыми языками нет принципиальной разницы, так как многие информационные языки могут использоваться как в одной, так и в другой системе. Любые информационные языки должны обеспечивать однозначную запись информации и ее последующее распознавание с определённой полнотой и точностью, а информационно-логический язык, помимо этого — формализацию логического вывода. 3.2.8. Поколения информационно-поисковых системПоиск информации с помощью компьютеров имеет уже почти полувековую историю. Первые автоматизированные информационные системы начали разрабатываться еще в 50-х гг. прошлого века, и главной их функцией был именно поиск информации. Поэтому их назвали информационно-поисковыми системами (ИПС). В зависимости от характера поддерживаемых информационных ресурсов ИПС было принято разделять на две категории: фактографические и документальные. Фактографические ИПС оперировали фактами, представленными в виде сущностей реального мира и их свойств, и позволяли находить сущности, обладающие заданными пользователем свойствами, а также свойства заданных сущностей. Когда в начале 1960-х годов начали зарождаться технологии баз данных, стало ясно, что информационная система этой категории представляет собой частный случай системы базы данных. В результате это направление в области информационного поиска постепенно было «поглощено» технологиями баз данных. Документальные ИПС предназначены для хранения и поиска документов, содержащих тексты на естественных языках. Такие ИПС и представляют собой ранние системы текстового поиска. Первое поколение ИПСПервое поколение ИПС составляли дескрипторные ИПС – это самые ранние системы текстового поиска. В таких системах содержание каждого текстового документа и пользовательских поисковых запросов описывается наборами слов или словосочетаний, называемых дескрипторами. В процессе поиска ИПС оперирует не самими текстовыми документами, а такими их «заместителями», которые в большинстве систем формируются вручную авторами документов, экспертами в предметной области документов и другими лицами. Сопоставление наборов дескрипторов, представляющих в системе документы, с набором дескрипторов, представляющим пользовательский запрос, позволяет находить требуемые пользователю документы. Дескрипторные ИПС обладают относительно несложными механизмами поиска, но качество поиска является сравнительно невысоким. Одной из наиболее распространенных областей применения дескрипторных систем был библиографический поиск. В таких системах хранятся коллекции библиографических описаний документов, и система позволяет находить публикации заданного автора, публикации, выпущенные указанным издательством и/или вышедшие в некотором году и т.п. Многие библиографические дескрипторные ИПС используются до настоящего времени. Втрое поколение ИПСВ процессе развития средств вычислительной техники компьютеры обрели устройства внешней памяти прямого доступа достаточно большого объема, значительно повысилась производительность процессоров. Это позволило создать и практически использовать в документальных ИПС более совершенные технологии, называемые технологиями полнотекстового поиска. Системы полнотекстового поиска представляют второе поколение ИПС. Благодаря возможности хранения и обработки в таких системах полных текстов документов удалось в большой мере автоматизировать процессы лингвистического анализа и поиска документов. Были разработаны подходы к автоматизации составления ряда используемых при этом словарей и тезаурусов. В технологиях полнотекстового поиска важное место занимают статистические методы анализа документов. Первоначально в полнотекстовых системах обеспечивался главным образом контекстный поиск, т.е. поиск документов, тексты которых содержат вхождение заданного в пользовательском запросе контекста. Позднее стал использоваться поиск по булевскому критерию, т.е. с использованием логических операторов И, ИЛИ, НЕ. Были разработаны также различные более тонкие модели поиска. На протяжении всей истории систем текстового поиска активно проводились научные исследования в этой области. Большое влияние на развитие систем текстового поиска оказали новаторские исследовательские проекты и разработки экспериментальных прототипов полнотекстовых поисковых систем, выполненные в 60-х годах прошлого века. Третье поколение ИПСТретье поколение ИПС представляют мультипоисковые системы:
За свою полувековую историю развития технологии текстового поиска сделали огромный шаг от простейших дескрипторных информационно-поисковых систем к изощренным системам полнотекстового поиска, от поисковых систем к системам с более богатой функциональностью. Ресурсы современных вычислительных систем позволяют хранить огромные объемы информационных ресурсов в системах текстового поиска, осуществлять в них не только технические, но и алгоритмически сложные процедуры обработки хранимых коллекций документов — их классификацию, кластеризацию, глубинный анализ текстов, перевод документов с одного языка на другой и т.д. Системы текстового поиска оказали значительное влияние на формирование специфического класса информационных систем называемых системами управления документами, которые широко используются в настоящее время во многих крупных коммерческих компаниях и других организациях. В таких системах важная роль отводится не только методам обработки естественного языка, созданным для работы с текстовыми документами, но и организации групповой разработки документов, их хранения, распространения и конечно же технологиям текстового поиска (см. раздел 3.5.). |