
Информационные технологии управления
| Вид материала | Документы |
- Темы рефератов по курсу «Основы автоматизированного управления», 13.91kb.
- Название Предмет Направление, 921.62kb.
- Информационные технологии в экономике и управлении, 1611.88kb.
- Рефераты по дисциплине «Информационные технологии в скс и Т. Оргтехника» Интернет-реклама,, 15.93kb.
- Вавилова в процессе проведения экзамена и приема зачетов по 2-м модулям дисциплины, 130.51kb.
- Тематический план изучения дисциплины «Информационные технологии управления» по специальности:, 363.97kb.
- Международная конференция «Информационные технологии в образовании и науке», 86.4kb.
- Программа-минимум кандидатского -экзамена по специальности 08. 00., 203.78kb.
- Программа минимум кандидатского экзамена по специальности 08. 00. 13 «Математические, 200.26kb.
- Программа «информатика и икт (информационные и коммуникационные технологии)», 443.93kb.
Системы управления базами данных
В соответствии с концепцией базы данных предполагается, что она представляет собой самостоятельный обобществленный централизованно управляемый ресурс некоторого сообщества пользователей, предназначенный для удовлетворения их информационных потребностей. Создание базы данных, поддержка ее в актуальном состоянии и обеспечение доступа пользователей к ней осуществляются с помощью специального программного инструментария, называемого системой управления базами данных (СУБД). СУБД вместе с управляемой ею базой данных называется системой базы данных. Одна установка СУБД на компьютере может управлять несколькими базами данных. В таких случаях говорят о системе баз данных.
Пользователями системы базы данных являются, прежде всего, специалисты предметной области, выступающие в роли потребителей и/или источников данных, содержащихся в базе данных. Их называют конечными пользователями системы базы данных. Кроме того, в качестве пользователей могут рассматриваться различные прикладные программы или программные комплексы, оперирующие данными, содержащимися в базе данных. Такие программные средства называют приложениями системы базы данных. Конечные пользователи взаимодействуют с системой базы данных с помощью пользовательских интерфейсов СУБД. Что касается приложений, они получают доступ к базе данных, взаимодействуя с СУБД через ее интерфейсы прикладного программирования.
Централизованный характер управления данными в базе данных обусловлен социальным характером ее пользовательской среды и предполагает необходимость существования некоторого лица и группы лиц, на которых возлагаются функции администратора системы базы данных, действующего в интересах всего сообщества ее пользователей. Персонал администратора ответствен, в частности, за поддержку системы в работоспособном состоянии, своевременную актуализацию данных, эффективное использование информационных ресурсов системы и ресурсов памяти, предоставление полномочий пользователям на доступ к данным и т.п.
СУБД - сложный программный комплекс, предназначенный для выполнения всей совокупности функций, связанных с созданием и эксплуатацией систем баз данных, которые используются самостоятельно либо в составе какой-либо более крупной информационной системы.
Для создания базы данных и настройки СУБД разработчик описывает структуру базы данных, организацию хранимых данных в тех рамках, которые допускает используемая СУБД, а также способы видения базы данных пользователями. Такие описания базы данных называются соответственно схемой базы данных (или логической схемой, или концептуальной схемой). В соответствии с заданной схемой базы данных СУБД физически размещает данные в памяти ЭВМ, при этом структурирует данные, корректно интерпретирует хранимые данные при осуществлении доступа к ним, а также поддерживает выполнение заданных ограничении целостности данных.
Функции СУБД
Системные механизмы СУБД выполняют две основные группы функций:
- описание логической структуры базы данных в виде схемы базы данных (или логической схемы, или концептуальной схемы);
- физическое представление данных - организацию хранимых данных на носителе;
- управление данными и поддержание целостности данных;
- предоставления доступа пользователям к базе данных;
2. управление полномочиями пользователей на доступ к базе данных, организация параллельного доступа пользователей к базе данных в социальной пользовательской среде, поддержка деятельности персонала администратора, ответственного за эксплуатацию системы базы данных.
1. управления ресурсами среды хранения с обеспечением логической и физической независимости данных, при этом реализуют:
Принципиально важное свойство СУБД заключается в том, что она позволяет различать и поддерживать два независимых взгляда на базу данных - взгляд пользователя, часто называемы логическим представлением данных, и «взгляд» системы, называемый физическим представлением данных, который характеризует организацию хранимых данных. Пользователя не интересуют при его работе с базой данных байты и биты, представляющие данные в среде хранения, их размещение в памяти, указатели, поддерживающие связи между различными структурными компонентами хранимых данных, выбранные методы доступа. В то же время все эти факторы важны для выполнения функций управления данными самой СУБД. Поддержка двух независимых представлений базы данных фактически сводится к тому, что на СУБД возлагается задача формирования из хранимых данных такого представления данных, которое отражает взгляд пользователя.
Важно отметить, что логическое представление базы данных может по своей структуре существенно отличаться от структуры хранимых данных и синтезироваться не только из фактически хранимых объектов базы данных и их связей, но и с помощью различного рода операций агрегирования данных и различных встроенных программных процедур. Такие механизмы трансформации данных, развитые в разных СУБД в различной степени, помогают в значительной мере сокращать объем работ по программированию прикладных систем, функционирующих в среде системы базы данных.
Механизмы управления данными СУБД имеют дело с двумя аспектами проблемы обеспечения целостности базы данных - с поддержкой логической и физической целостности. Основополагающее значение имеет поддержка логической целостности (непротиворечивости) базы данных.
Логическая целостность базы данных – свойство состояния базы данных, характеризующееся отсутствием нарушений всех ограничений целостности, явным образом специфицированных в логической схеме базы данных.
Нарушения логической целостности базы данных могут быть связаны не только с вводом в нее недостоверных данных или с неправомерными действиями процедур обработки данных, выполняемых в среде базы данных и помещающих в базу данных генерируемые ими данные. Они могут являться также следствием несвоевременного прерывания выполнения таких процедур для обработки запроса, выданного другим пользователем. Для исключения таких ситуаций в мультипользовательских СУБД предусматривается механизм транзакций.
Транзакция – это последовательность операций пользователя над базой данных, которая переводит ее из одного логически целостного состояния в другое.
При несвоевременном прерывании выполнения процедур обработки данных происходит аннулирование результатов уже выполненных операций – откат транзакции.
Нарушения физической целостности базы данных возникают в результате сбоев и отказов оборудования вычислительной системы, повреждений машинных носителей данных.
Физическая целостность базы данных – свойство состояния хранимых данных, характеризующееся отсутствием нарушений спецификаций схемы хранения, а также физического размещения данных на носителях.
Развитые СУБД располагают средствами восстановления разрушенной базы данных, основанными чаще всего на использовании ее контрольных копий и журнализации изменений.
Механизмы управления доступом обычно основываются на использовании паролей и ключей для разных групп пользователей, либо неявного определения полномочий доступа к различным структурным элементами базы данных.
Языковые средства СУБД
Функциональные возможности поддерживаемой средствами СУБД модели данных становятся доступными пользователю благодаря воплощению ее в виде комплекса языковых средств.
Языки описания данных. Обеспечивают построение схемы базы данных. Схема включает описание структуры базы данных и налагаемых на нее ограничений целостности в рамках правил, регламентированных моделью данных, которая поддерживается рассматриваемой СУБД. Языки описания данных не всегда синтаксически оформляется в виде самостоятельного языка. На ранней стадии развития технологий баз данных такие языки назывались языками данных.
Языки манипулирования данными. Позволяют запрашивать предусмотренные в системе операции над данными из базы данных. Не обязательно выступаю в форме синтаксически самостоятельного языка СУБД. Играют больше методическую роль.
Языки запросов. Предоставляют полные функциональные возможности для операций над базой данных, в том числе вставку новых данных, обновление, удаление и выборку данных. Разработаны вслед за появлением интерфейсов конечных пользователей. Первоначально роль таких языков выполняли декларативные языки высокого уровня, которые обеспечивали выборку требуемых данных из базы данных. Однако впоследствии их функции значительно трансформировались. Современные языки запросов:
- Язык SQL – Structured Query Language – непроцедурный язык, используемый для взаимодействия с данными в реляционных СУБД. Стандартный SQL не объявляется полноценным языком программирования (процедурным языком), в нем нет операторов проверки условий и ветвления, перехода, циклов и т.д. Запрос к базе данных не содержит конкретных инструкций, как выполнить действие, а содержит лишь информацию о желаемом результате. Язык SQL характеризуется как непроцедурный (описательный, декларативный). Но операторы SQL могут встраиваться в базовый язык, например, Pascal, Fortran, C, и дают возможность получать доступ к базам данных из прикладных программ.
SQL включает около 30 команд. Четыре базовые команды (SELECT, UPDATE, DELETE и INSERT) соответствуют четырем базовым функциям манипулирования данными (выбора данных, модификация данных, удаление данных и вставка данных соответственно). Результаты запроса отображает таблица данных, состоящая из столбцов (соответствующих полям данных) и строк (соответствующих записям данных). Например, по команде к таблице «Сотрудники» (см. рис. 3.5.):
SELECT ФИО, Год рождения, Должность
FROM Сотрудники
WHERE (Должность LIKE ‘Инженер’)
будут выбраны следующие записи:
-
ФИО
Год рождения
Должность
Дроздов М.Д.
1959
Инженер
Львов А.Е.
1965
Инженер
Рис. 3.6. Результаты выборки данных
В силу своего широкого использования является международным стандартом языка запросов. Официальный стандарт языка был опубликован в 1986 г. Американским институтом национальных стандартов (ANSI) и Международной организацией по стандартам (ISO). Язык SQL предоставляет развитые возможности как конечным пользователям, так и специалистам в области обработки данных. SQL является на сегодняшний день единственным стандартным языком для работы с реляционными базами данных.
- Язык QBE. В реляционных СУБД широко распространен также другой подход, при котором для обращения к СУБД нет необходимости выписывать операторы системных языков в виде строк литер. В середине 1970-х годов сотрудником компании IBM M. Злуфом был разработан табличный язык запросов Query-By-Example (QBE). Формулировка запроса на этом языке сводится к заполнению столбцов и строк некоторых таблиц, которые система показывает пользователю на экране монитора. Например, аналогичный вышеописанному запрос по выборке данных из таблицы «Сотрудники» будет иметь вид:
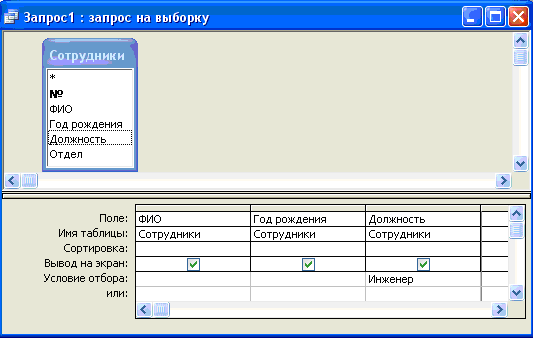
Рис.3.7. Формулировка запроса на языке QBE
Результат выборки будет иметь вид, приведенный на рис. 3.6. Обработка такого запроса может быть реализована в системе, например, так, что на основе представления запроса, заданного средствами QBE, автоматически генерируется его представление на языке SQL,и далее этот запрос обрабатывается обычными средствами исполнения SQL-запросов.
Языки разработки приложений. Для квалифицированных пользователей, например, для разработчиков сложных прикладных систем, как правило, языковые средства предоставляются в их явной синтаксической форме. В других случаях функции языков могут быть доступны неявным образом, когда они реализуются в форме так называемых языков четвертого поколения (4GL) - пользовательского интерфейса, включающего различного рода меню, диалоговые сценарии или заполняемые пользователем экранные формы, различные диаграммы и другие средства визуального представления данных. На основе данных, введенных пользователем, с помощью такого интерфейса формируются соответствующие синтаксические конструкции языка интерфейса, которые передаются на исполнение или включаются с генерируемый программный код приложения. Интерфейсы с неявным использованием языка широко используются в СУБД для персональных компьютеров.
Языки разработки приложений можно разделить на автономные, включающие и языки программирования баз данных.
- Автономные языки не только реализуют функции определения данных и манипулирования данными, но и обладают управляющими структурами и другими средствами, свойственными традиционным языкам программирования. Благодаря этому они могут использоваться как функционально полное инструментальное средство для создания приложений систем баз данных. В качестве примера можно привести язык dBase,построенный в стиле языков структурного программирования, FoxBase, FoxPro, Clipper.
- Включающие языки представляют собой расширения традиционного языка программирования операторами (командами, функциями, процедурами и т.п.), способными взаимодействовать с интерфейсами прикладного программирования СУБД, благодаря чему восполняется функциональная неполнота языков данной системы. Примером может служить универсальные языки программирования Кобол, Фортран, Паскаль, диалект языка Visual Basic для СУБД MS Access, называемый Access Basic.
- Языки программирования баз данных – это целостные языки программирования, соединяющие на единой концептуальной основе как возможности новейших языков программирования, так и функции, свойственные языковым средствам традиционных СУБД. Они представляют собой расширения известных языков программирования Паскаль, Ада, Модула либо являются оригинальными языками, например, Атлант, Тексис, Галилео и др. Широкое распространение получил язык Delphi, основанный на языке программирования Паскаль, обеспечивающий создание приложений вне среды СУБД, но имеющий средства доступа к базам данных.
С начала 1990-х годов наблюдается интенсивное внедрение в практическое программирование объектного языка C++, основанного на привычном большому кругу программистов языке С, и подобно Delphi обеспечивающий создание приложений вне среды СУБД, но имеющий средства доступа к базам данных. В середине 1990-х годов к нему добавился также язык Java.
Структура СУБД
Обработка данных и управление этой обработкой в вычислительно среде, а также взаимодействие с операционной системой и прикладными программами осуществляется комплексом программных средств, входящих в состав СУБД. В составе комплекса обычно выделяют следующие компоненты:
- ядро, обеспечивающее управление данными во внешней и оперативной памяти, а также протоколирование изменений;
- процессор языка базы данных, обеспечивающий обработку (трансляцию или компиляцию) и оптимизацию запросов на выборку и изменение данных;
- подсистему поддержки программных вызовов, которая обслуживает приложения, взаимодействующие с СУБД через средства пользовательского интерфейса;
- сервисные программы (системные и внешние утилиты), обеспечивающие настройку СУБД, восстановление после сбоев, экпорт-импорт, присоединение данных и ряд дополнительных возможностей обслуживания.
Большинство СУБД работают в среде операционной системы и тесно с ней связаны. Многопользовательские приложения, обработка распределенных запросов, защита данных требуют эффективно использовать ресурсы, управление которыми обычно является функцией ОС. Использование многопроцессорных систем и мультипоточных технологий обработки данных позволяет эффективно обслуживать параллельно выполняемые запросы, но требует координации использования ресурсов между ОС и СУБД. Соответственно, управление доступом и обеспечение защиты также обычно интегрируются с соответствующими средствами операционной системы.
Проектирование базы данных
Проектирование базы данных – одна из наиболее ответственных и трудных задач, связанных с созданием системы базы данных. В результате ее решения должны быть определены и содержание базы данных, и эффективный, с точки зрения всего сообщества будущих пользователей, способ ее организации в среде СУБД, выбранной для реализации системы.
В крупных системах проектирование базы данных требует особой тщательности, поскольку цена допущенных на этой стадии просчетов и ошибок особенно велика. Хотя некоторые из них могут быть скорректированы в процессе эксплуатации системы благодаря средствам реструктуризации и реорганизации базы данных, такие операции могут оказаться весьма дорогостоящими и потребовать переработки приложений. Проектирование баз данных не может быть полностью автоматизированным. Значительное место в нем отводится интуиции и опыту специалиста-проектировщика.
За прошедшие десятилетия усилиями многих специалистов были созданы разнообразные СASE-технологии (Computer-Aided Software/System Engineering), позволяющие систематизированным образом поддерживать и автоматизировать разработки сложных систем программного обеспечения, информационных систем и систем баз данных. Сформировался рынок коммерческих инструментальных программных средств CASE, на котором представлен широкий спектр таких инструментов. Они предназначены для создания и поддержки разрабатываемой системы на протяжении всего ее жизненного цикла, т.е. периода от принятия решения о создании системы до снятия ее с эксплуатации, либо только для поддержки отдельных его этапов. Некоторые из этих программных продуктов ориентированы на довольно широкий набор СУБД, другие предназначены для конкретных СУБД. Инструментарий CASE базируется на различных разновидностях структурных или объектно-ориентированных методов.
Важное достоинство использования СASE-технологий в том, что в процессе разработки системы осуществляется автоматическое документирование проекта. В репозитории используемого инструмента CASE сохраняются версии проекта системы и метаданные, описывающие свойства различных компонентов системы. Это позволяет использовать автоматизированные средства для реинжиниринга системы - ее модернизации в процессе эксплуатации с учетом изменившихся требований.
Процесс проектирования базы данных должен включать следующие этапы:
- концептуальное проектирование базы данных;
- выбор СУБД и других инструментальных программных средств ее реализации;
- логическое проектирование базы данных;
- физическое проектирование базы данных.
Концептуальное проектирование базы данных
Концептуальное проектирование базы данных выполняется в три этапа:
- определение предметной области системы;
- формирование взгляда на предметную область с позиций будущих пользователей;
- разработка модели предметной области.
Первой задачей этапа концептуального проектирования является определение предметной области системы, основанное на изучении информационных потребностей будущих пользователей. На практике встречаются в основном два подхода к выбору состава и структуры предметной области. Наиболее распространен подход, который можно назвать функциональным. Он реализует принцип «от задач» и применяется в случае, когда заранее известны функции некоторой группы лиц и/или комплекса задач, для обслуживания информационных потребностей которых создается рассматриваемая база данных. При другом, предметном, подходе информационные потребности будущих пользователей базы данных жестко не фиксируются. Они могут быть многоаспектными и весьма динамичными. В предметную область включают при этом такие сущности и взаимосвязи сущностей, которые наиболее значимы и наиболее характерны для нее. Такая база данных называется предметной. Она может быть использована при решении разнообразных, наиболее существенных задач, связанных с данной предметной областью.
Формирование взгляда на предметную область с позиций уже сформировавшегося или потенциального сообщества будущих пользователей базы данных является второй задачей стадии концептуального проектирования базы данных. Такое представление предметной области - ее концептуальная модель - обычно выражается в терминах не отдельных сущностей предметной области и связей между ними, а их типов, связанных с ними ограничений целостности, а также тех процессов в предметной области, которые приводят к переходу ее из одного состояния в другое.
Концептуальная модель предметной области представляет собой описание структуры и динамики предметной области, характера информационных потребностей пользователей системы в терминах, понятных пользователю и независимых от программной реализации системы, в частности, от выразительных средств языков какой-либо конкретной СУБД. Такое описание может быть представлено с помощью любого способа, допускающего однозначную интерпретацию. Существующие в настоящее время программные продукты CASE обычно предоставляют разработчику визуальные средства представления и синтеза концептуальной модели на стадии разработки, основанные чаще всего на модели сущностей-связей или на унифицированном языке моделирования UML. В простейших случаях проектировщик базы данных ограничивается содержательным описанием модели предметной области на естественном языке. Он может использовать также разнообразные выразительные средства для изображения структуры предметной области, такие, как диаграммы типов (диаграммы Бахмана, диаграммы сущностей-связей и др.), - графы, вершины которых соответствуют типам сущностей, а ребра - типам связей между ними.
На рис. 3.8. приведена модель предметной области «Торговая фирма» с использованием метода ER- диаграмм (сущностей-связей). Элементы «прямоугольник» представляют сущности предметной области, «овал» - атрибуты сущностей, «ромб» - связи между сущностями.
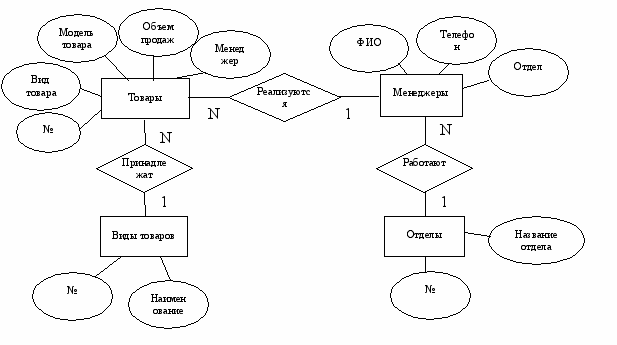
Рис. 3.8. Представление модели предметной области «Торговая фирма»
Выбор СУБД и других инструментальных программных средств
Выбор инструментальной системы управления базами данных является следующим важным этапом проектирования базы данных. Необходимость этого этапа обусловлена тем, что в настоящее время нет возможности создавать абсолютно мобильные системы базы данных и их приложения. Проблемы выбора СУБД, а также оценки характеристик их функционирования злободневны на всех стадиях развития технологий, когда речь идет о разработках крупных систем и систем с критическими требованиями к производительности, ресурсам памяти, надежности. В наиболее критичных случаях проводится сравнительный анализ характеристик различных СУБД с помощью методов имитационного моделирования. Однако оценки, получаемые с помощью дорогостоящих имитационных моделей, оказываются все-таки весьма грубыми. Оценка производительности СУБД для некоторых типовых приложений может осуществляться с помощью эталонных тестов, разработанных консорциумом ТРС (Transaction Processing Performance Council).
В последнее время в разработках крупных отечественных информационных систем для выбора одного из альтернативных вариантов инструментальных средств часто используют приближенные количественные оценки их производительности в данном конкретном приложении путем создания прототипа приложения. На прототипе проводятся необходимые измерения для разных СУБД, и на этой основе принимается решение о выборе СУБД для реализации проекта. Однако в большинстве случаев проектировщики руководствуются собственными интуитивными экспертными оценками требований к выбираемой системе по нескольким важнейшим количественным и качественным характеристикам. К числу таких характеристик относятся.
- тип модели данных, поддерживаемый СУБД, ее адекватность потребностям моделирования рассматриваемой предметной области. В настоящее время выбор фактически осуществляется между реляционными, объектно-реляционными и объектными СУБД;
- масштабы разрабатываемой системы - количество потенциальных пользователей, ожидаемый объем данных в базе, интенсивность потока запросов;
- аппаратно-программная платформа, на которой будет функционировать разрабатываемая система;
- характеристики производительности системы;
- наличие в данной СУБД средств разработки приложений;
- запас функциональных возможностей для дальнейшего развития системы, разрабатываемой средствами данной СУБД;
- степень оснащенности системы инструментарием для персонала администрирования данными;
- удобство и надежность СУБД в эксплуатации.
Поставляемые в настоящее время реляционные SQL-cepверы баз данных ведущих поставщиков программного обеспечения систем баз данных довольно близки по своим функциональным возможностям. В этих условиях на выбор разработчика влияет ценовая политика поставщика, приверженность разработчика к какой-либо линии программных продуктов и другие факторы отнюдь не технологического характера.
Логическое проектирование базы данных
Задача этапа логического проектирования базы данных состоит в отображении концептуальной модели предметной области в модель данных, поддерживаемую СУБД, выбранной для реализации системы. В результате выполнения этого этапа создаются схемы базы данных. Инструменты CASE, поддерживающие проектирование баз данных, обеспечивают автоматическую генерацию схем базы данных.
Логическое проектирование выполняется в три этапа:
- формирование информационных структур данных с учетом выбранной модели данных;
- нормализация информационных структур;
- представление логической модели;
- модификация концептуальной модели по результатам логического проектирования.
При проектировании реляционных баз данных формирование информационных структур сводится к отображению сущностей предметной области в двумерные таблицы, при этом:
- атрибуты отображаются в поля таблицы;
- определяются типы данных полей (текстовый, числовой, календарный и пр.);
- выделяются первичные и вторичные (внешние) ключи;
- определяются связи между таблицами. Чтобы связать две реляционные таблицы, необходимо ввести в структуру первой таблицы внешний ключ – первичный ключ второй таблицы.
На рис. 3.9. представлены информационные структуры базы данных «Торговая фирма».


Т


 овары N N 1 Менеджеры N
овары N N 1 Менеджеры N | № | Вид товара | Модель товара | Объем продаж | Менеджер | | Менеджер | Телефон | Отдел |
| | | | | | | | | |
| | | | | | | | | |
| | | | | | | | | |
| | | | | | | | | |
| | | | | | | | | |
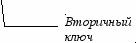
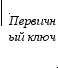
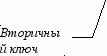
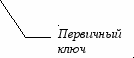
Виды товара 1 Отделы 1
| Вид товара | Наименование | | | № | Название |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
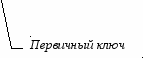
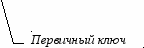
Рис. 3.9. Информационные структуры базы данных «Торговая фирма»
Нормализация – это разбиение таблицы на две или более с целью ликвидации дублирования данных и потенциальной их противоречивости. Окончательная цель нормализации сводится к получению такого проекта базы данных, в котором «каждый факт появляется лишь в одном месте». Например, для таблицы «Товары» характерны:
- избыточность данных. Значения данных повторяются, например, фамилия, имя, отчество менеджеров.
- потенциальная противоречивость. Если при вводе данных о менеджерах будет допущена ошибка, ее придется исправлять, просматривая все вхождения этих данных.
Товары
| № | Вид товара | Модель товара | Объем продаж | Менеджер |
| 1 | 1 | Canon LBP 2900 | 124 509 | Иванов Иван Михайлович |
| 2 | 1 | HP LJ 1100 | 235 677 | Синицын Петр Сергеевич |
| 3 | 1 | HP DJ 400 | 34 556 | Иванов Иван Михайлович |
| 4 | 2 | Epson Perfection 2480 | 56 745 | Петров Юрий Никитич |
| 5 | 2 | Epson Perfection 1200 | 138 534 | Петров Юрий Никитич |
| 6 | 1 | HP LJ 1200 | 567 843 | Синицын Петр Сергеевич |
| 7 | 1 | Canon LBP 3200 | 234 543 | Иванов Иван Михайлович |
Рис. 3.10. Таблица «Товары» базы данных «Торговая фирма»
Решение этих проблем возможно, применяя аппарат нормализации таблиц.
Каждая таблица должна удовлетворять условию, в соответствии с которым все данные должны иметь атомарное (далее неделимое) значение. Говорят, что такая таблица находится в первой нормальной форме – 1НФ. Например, в таблице «Товары» данные в поле «Менеджер» не атомарны и могут быть разделены на три данных «Фамилия», «Имя», «Отчество». Аналогично, могут быть разделены данные в поле «Модель товара» на данные «Фирма» и «Модель».
Таблица находится в первой нормальной форме (1НФ) тогда и только тогда, когда в любом допустимом значении этой таблицы каждая ее строка содержит только одно значение каждого атрибута.
После приведения в первую нормальную форму таблица «Товары» будет иметь вид:
Товары
| № | Вид товара | Фирма | Модель товара | Объем продаж | Фамилия | Имя | Отчество |
| 1 | 1 | Canon | LBP 2900 | 124 509 | Иванов | Иван | Михайлович |
| 2 | 1 | HP | LJ 1100 | 235 677 | Синицын | Петр | Сергеевич |
| 3 | 1 | HP | DJ 400 | 34 556 | Иванов | Иван | Михайлович |
| 4 | 2 | Epson | Perfection 2480 | 56 745 | Петров | Юрий | Никитич |
| 5 | 2 | Epson | Perfection 1200 | 138 534 | Петров | Юрий | Никитич |
| 6 | 1 | HP | LJ 1200 | 567 843 | Синицын | Петр | Сергеевич |
| 7 | 1 | Canon | LBP 3200 | 234 543 | Иванов | Иван | Михайлович |
Рис. 3.11. Таблица «Товары» в первой нормальной форму
Таблица находится во второй нормальной форме (2НФ), если она удовлетворяет определению 1НФ и все ее поля, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом.
Полная функциональная зависимость, по сути, является связью типа «Многое к одному». Все неключевые поля зависят только от ключевого поля и не находятся в зависимости ни от какой его части, если таблица имеет составной ключ. В рассматриваемой таблице «Товары» ключевое поле (поле»№») не является составным. Можно считать, что таблица находится во второй нормальной форме.
Таблица находится в третьей нормальной форме (3НФ), если она удовлетворяет определению 2НФ и ни один из ее неключевых атрибутов не связан функциональной зависимостью с любым другим неключевым атрибутом.
В таких случаях говорят об отсутствии транзитивной зависимости. Для устранения транзитивной зависимости производится расщепление информационной структуры на две и более, если потребуется. Говорят - декомпозиция исходного отношения (таблица «Товары»).
Товары Товары Менеджеры
| №  | | № |  | Ф   амилия амилия |
| В  ид товара ид товара | | В ид товара | | И мя |
| Ф ирма | | Ф ирма | | О тчество |
| М одель товара | = | М одель товара | + | |
| О бъем продаж | | О бъем продаж | | |
| Ф амилия |   | Ф амилия | | |
| И мя |  | | | |
| О тчество | | | | |
| | | | | |
Товары Товары Фирмы
| № |  | № |  | М   одель одель товара |
| В ид товара | | В ид товара | | Ф  ирма ирма |
| Ф ирма |  | М одель товара | | |
| М одель товара | = | О бъем продаж | + | |
| О бъем продаж | | Ф амилия | | |
| Ф амилия | | | | |
| | | | | |
Рис.3.12. Пример расщепления информационной структуры таблицы «Товары»
Полной декомпозицией таблицы называют такую совокупность произвольного числа проекций, соединение которых полностью совпадает с одержимым исходной таблицы. Нормализация таблиц решает проблемы избыточности и потенциальной противоречивости данных.
После процедуры нормализации формируется логическая (даталогическая) модель с учетом появившихся новых информационных структур, например, таблицы «Менеджеры». Определяются ключевые поля для них, устанавливаются связи и задаются типы данных полей. На завершающем этапе логического проектирования выполняется модификация концептуальной модели предметной области с учетом появившихся новых сущностей и изменения состава атрибутов исходных сущностей.
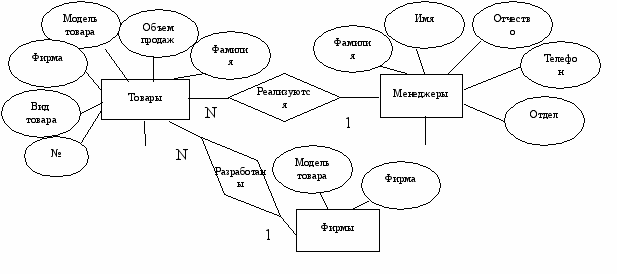
Рис. 3.13. Фрагмент модифицированной модели
предметной области «Торговая фирма»
Для реляционных баз данных создан математический аппарат логического проектирования баз данных, основанный на теории нормализации. Он позволяет синтезировать такие таблицы, которые обеспечивают устранение избыточности данных в базе данных, тем самым исключаются различные аномалии в организации базы данных и выполнении операций манипулирования данными.
Физическое проектирование базы данных
На данном этапе должны быть решены вопросы построения структуры хранимых данных, размещения хранимых данных в пространстве памяти, выбора эффективных методов доступа к ним. Принятые проектные решения оказывают определяющее влияние на производительность системы базы данных. Они документируются в форме схемы хранения на языке определения хранимых данных.
Для конечного пользователя этап физического проектирования фактически сводится к созданию базы данных на носителе в рамках выбранной СУБД и генерации программного кода приложений системы базы данных. Процесс проектирования базы данных имеет итерационный характер. В процессе функционирования системы базы данных становится возможным измерение ее реальных характеристик, определение узких мест. В соответствии с этими новыми знаниями, а также в связи с возникающими изменениями условий эксплуатации системы осуществляют модификацию первоначально созданного проекта.
Локальные и распределенные базы данных
По топологии хранения различаются локальные и сетевые базы данных.
Локальные базы данных размещены на локальном компьютере и обрабатываются одним пользователем. Сетевые базы данных работают в вычислительных сетях и подразделяются на сосредоточенные и распределенные базы данных.
Сосредоточенная база данных – база данных полностью поддерживается на одном компьютере и доступная по запросам пользователей, работающих непосредственно на данном компьютере, либо предоставляемая для сетевого доступа.
Сетевой доступ к такой базе данных часто применяется в локальных сетях, а также в Web-пространстве. Появление компьютерных сетей позволило создавать распределенные базы данных.
Распределенная база данных – база данных, составные части которой размещаются на различных узлах компьютерной сети.
Части базы данных на отдельных узлах могут при этом использоваться одновременно как автономные локальные базы данных. Благодаря функциональным возможностям программного обеспечения, применяемого для поддержки и использования распределенных баз данных, фактор распределенности данных может быть прозрачным для пользователей. В таких случаях пользователь распределенной базы данных не обязан знать, каким образом ее компоненты размещены в узлах сети, и представляет себе эту базу данных как единое целое. Работа с распределенной базой данных осуществляется с помощью системы управления распределенной базой данных (СУРБД). Распределенные базы данных часто создаются в территориальных информационных системах.
Методы распределения данных
В распределенных базах данных используются два метода распределения данных - фрагментация и тиражирование. Фрагментация данных заключается в разбиении базы данных на составные части, хранимые в различных узлах сети. Тиражирование данных (репликация) используется для сокращения сетевого трафика и повышения производительности системы при обработке пользовательских запросов за счет того, что данные в сети размещаются в местах их порождения и/или активного использования. При этом копии некоторых составных частей базы данных (репликаты) хранятся в различных узлах сети. Естественно, что при обновлении какой-либо копии возникает необходимость синхронизации состояния всех копий модифицированного фрагмента базы данных. Затраты ресурсов на эту процедуру являются платой за сокращение сетевого трафика.
Архитектура распределенной обработки данных
Почти все модели организации взаимодействия пользователя с базой данных предполагают распределение функций ранее приведенных групп обработки данных между, как минимум, двумя частями приложений:
- клиентской, которая отвечает за целевую обработку данных и организацию взаимодействия с пользователем;
- серверной, которая обеспечивает хранение данных, обрабатывает запросы и посылает результаты клиенту для специальной обработки.
В общем случае предполагается, что эти части приложения функционируют на отдельных компьютерах, т.е. к серверу баз данных с помощью сети подключены компьютеры пользователей (клиенты).
Разделение процесса выполнения запроса на клиентскую и серверную компоненту позволяет:
- различным прикладным (клиентским) программам одновременно использовать общую базу данных;
- централизовать функции управления, такие как, защита информации, обеспечение целостности данных, управление совместно используемым ресурсов;
- обеспечивать параллельную обработку запроса в случае распределенных баз данных;
- высвобождать ресурсы рабочих станций и сети;
- повышать эффективность управления данными за счет использования ЭВМ, специально разработанных для работы СУБД (серверы баз данных и машины баз данных).
С точки зрения ролевой модели взаимодействия функциональных компонентов систем наибольшее распространение получили архитектуры файл-сервер и клиент-сервер.
Архитектура «файл-сервер»
А
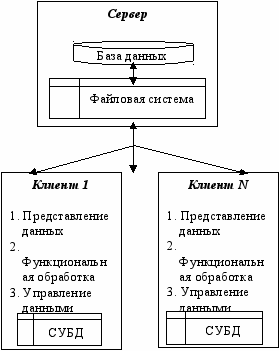 рхитектура «файл-сервер» характерна выделением компонента «файловый сервер» и использования его для хранения базы данных и предоставления данных клиентам. Средства организации и управления базой данных (в том числе и СУБД) целиком располагается на машине клиента, а база данных, представляющая собой обычно набор специализированных структурированных файлов, на машине-сервере. В этом случае серверная компонента представлена даже не средствами СУБД, а сетевыми составляющими операционной системы, обеспечивающими удаленный разделяемый доступ к файлам.
рхитектура «файл-сервер» характерна выделением компонента «файловый сервер» и использования его для хранения базы данных и предоставления данных клиентам. Средства организации и управления базой данных (в том числе и СУБД) целиком располагается на машине клиента, а база данных, представляющая собой обычно набор специализированных структурированных файлов, на машине-сервере. В этом случае серверная компонента представлена даже не средствами СУБД, а сетевыми составляющими операционной системы, обеспечивающими удаленный разделяемый доступ к файлам. Ф
Рис. 3.17. Архитектура "файл-сервер"
айловым сервером файлы базы данных в соответствии с пользовательскими запросами передаются клиентам, где производится обработка с использованием СУБД.
Достоинство – возможность обслуживания запросов нескольких клиентов.
Недостатки:
- высокая загрузка сети и машин-клиентов, так как обмен идет на уровне физических записей и даже файлов, из которых на машине клиента будут выбраны и представлены необходимые для приложения элементы данных;
- низкий уровень защиты данных, т.к. доступ к файлам базы данных управляется общими средствами ОС.
- низкий уровень управления целостностью и непротиворечивостью данных, так как бизнес-правила функциональной обработки, сосредоточенные на клиентской части, могут быть противоречивыми и несинхронизированными.
Архитектура «клиент - сервер»
С начала 1990-х годов стала активно применяться и развиваться архитектура «клиент - сервер». В архитектуре «клиент-сервер» средства управления базой данных и база данных размещаются на машине-сервере.
В
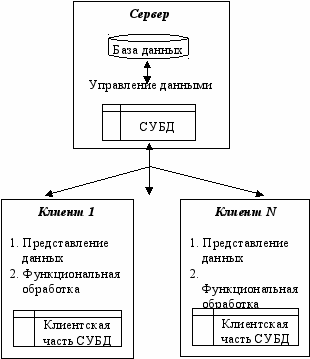 заимодействие между клиентом и сервером происходит на уровне команд языка манипулирования данными СУБД (обычно SQL), которые обрабатываются СУБД на машине-сервере. Сервер базы данных осуществляет поиск записей и анализирует их. Записи, удовлетворяющие условиям, могут накапливаться на сервере и после того, как запрос будет целиком обработан, пользователю на клиентскую машину передаются все логические записи (запрашиваемые элементы данных), удовлетворяющие поисковым условиям.
заимодействие между клиентом и сервером происходит на уровне команд языка манипулирования данными СУБД (обычно SQL), которые обрабатываются СУБД на машине-сервере. Сервер базы данных осуществляет поиск записей и анализирует их. Записи, удовлетворяющие условиям, могут накапливаться на сервере и после того, как запрос будет целиком обработан, пользователю на клиентскую машину передаются все логические записи (запрашиваемые элементы данных), удовлетворяющие поисковым условиям. С
Рис. 3.18. Архитектура "клиент-сервер"
УБД делится на две части: интерфейсную клиентскую, запускаемую на рабочей станции, и серверную. Клиентская часть служит для ввода и отображения данных, а серверная обеспечивает решение всех задач, связанных с интенсивными вычислениями, включая анализ данных, контроль их хранения, а также манипулирование данными. Сервер баз данных – программа, реализующая функции собственно СУБД: определение данных, запись-чтение данных, поддержка схем внешнего, концептуального и внутреннего уровней, диспетчеризация и оптимизация выполнения запросов, защита данных. Клиенты – различные программы, написанные как пользователем, так и поставщиками СУБД. Программа-клиент организована в виде приложения, работающего «поверх» СУБД, и обращающегося для выполнения операций над данными к компонентам СУБД через интерфейс внешнего уровня – утилиты и инструментальные средства, условно не отнесенные к СУБД, выполняющиеся самостоятельно как пользовательское приложение.
Сервер баз данных - 1) совокупность функциональных компонентов СУБД с архитектурой «клиент-сервер», относящийся к серверной части системы и обеспечивающий обработку запросов к базе данных, поступивших со стороны клиента; 2) компьютер в сети, на котором поддерживается система баз данных.
Основной функцией сервера является оптимальное управление ресурсом для множества клиентов, одновременно запрашивающих у него этот ресурс (им может быть, например, информация базы данных), используя механизм блокировок, возвращает записи базы данных по запросам клиентов, гарантирует параллельность, минимальный сетевой трафик и повышенную производительность системы. Сервер базы данных является интеллектуальным по сравнению с файловым сервером. Клиентская часть - это внешний интерфейс, т.е. часть системы, которую пользователь применяет для взаимодействия с данными. Она работает с небольшими специальными наборами данных, такими, как строки таблицы (а не с целыми файлами баз данных как это бывает в случаях систем с файловой архитектурой).
Достоинства:
- возможность обслуживания запросов нескольких клиентов;
- снижение нагрузки на сеть и машины сервера и клиента;
- защита данных осуществляется средствами СУБД, что позволяет блокировать не разрешенные пользователю действия;
- сервер реализует управление транзакциями и может блокировать попытки одновременного изменения одних и тех же записей.
Недостатки:
- бизнес-логика функциональной обработки и представление данных могут быть одинаковы для нескольких клиентских приложений и это увеличит совокупные потребности в ресурсах при исполнении вследствие повторения части кода программ и запросов;
- низкий уровень управления непротиворечивостью данных, так как бизнес-правила функциональной обработки, сосредоточенные на клиентской части, могут быть противоречивыми.
Для того чтобы устранить указанные недостатки, необходимо, чтобы противоречивость бизнес-логики и изменения баз данных контролировались бы на стороне клиента. С этой целью:
- общие или критически значимые функции оформляются в виде хранимых процедур, включаемых в состав базы данных;
- вводится механизм отслеживания событий базы данных – триггеров, также включаемых в состав базы данных.
При возникновении соответствующего события (обычно изменения данных), СУБД вызывает для выполнения хранимую процедуру, связанную с триггером, что позволяет эффективно контролировать изменение баз данных. Хранимые процедуры и триггеры могут быть использованы любыми клиентскими приложениями, работающими с базой данных. Это снижает дублирование программных кодов и исключает необходимость компиляции каждого запроса. Такую архитектуру организации взаимодействия иногда называют архитектурой «активный сервер базы данных» или архитектурой с «тонким клиентом», в отличие от предыдущей архитектуры, которую называют архитектурой «выделенный сервер баз данных» или архитектурой с «толстым» клиентом».