
Конспект лекций москва 2004 удк 519. 713(075)+519. 76(075) ббк 22. 18я7
| Вид материала | Конспект |
- Учебное пособие тверь 2008 удк 519. 876 (075. 8 + 338 (075. 8) Ббк 3817я731-1 + 450., 2962.9kb.
- Тексты лекций Москва 2008 удк 339. 9(075. 8) Ббк 65. 5я73-2, 1528.45kb.
- Программно-технический комплекс Учебное пособие Новочеркасск юргту (нпи) 2010. Удк, 3911.73kb.
- Удк 152. 27 (075. 8) + 157 (075. 8) + 152. 3 (075, 60.12kb.
- Краткий конспект лекций Кемерово 2002 удк: 744 (075), 1231.26kb.
- Методические указания по курсу Новосибирск 2004 ббк ю 937. 4 Удк 152. 26 (075), 802.63kb.
- Москва 2011 ббк 63. 3 (2)я 7 к 90 удк 947 (075) История России, 110.08kb.
- Курс лекций Гродно 2005 удк 631. 1 (075., 1193.16kb.
- Удк 070(075. 8) Ббк 76. 01я73, 5789.66kb.
- Удк 339. 9(470)(075. 8) Ббк, 7329.81kb.
11.1. Типовая задача синтаксического анализа
Имеется активный нетерминал S, множество альтернатив для него Sk и текущее состояние анализируемой цепочки y.
Пусть выбрана альтернатива SX1X2…Xn, XiVNVT, при i[1,n].
Если X1 VT, то он должен совпадать с первым символом цепочки y. Если совпадает, то укорачиваем цепочку на этот символ и переходим к X2. Если не совпадает, то переходим к другой альтернативе.
Если же XiVN, тогда из Xi необходимо вывести какое-нибудь начало цепочки y. Если из Xi нельзя вывести никакое начало цепочки y, то возможны 2 варианта:
1. Перейти к Xi-1 и попытаться вывести из Xi-1 другое начало и т.д. ( получаем полный перебор вариантов вывода) – разбор с медленным возвратом.
2. Сразу отказаться от альтернативы SX1X2…Xn и выбрать другую (разбор с быстрым возвратом).
Очевидно, что наиболее удобными при анализе цепочек являются грамматики, допускающие детерминированный разбор, когда на каждом шаге мы можем однозначно выбрать альтернативу, и в случае невозможности подобрать нужную альтернативу цепочка не принадлежит языку (никакой вывод не может быть построен). Одним из таких типов грамматик являются LL(k)-грамматики.
11.2. LL(k)-грамматики
LL(k)-грамматиками называются грамматики, допускающие детерминированное построение левого разбора (left) при чтении анализируемой цепочки слева (left) направо, при подсматривании вперед не более чем на k символов.
Например, рассмотрим грамматику G18 с множеством правил:
S
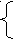 a SbB;
a SbB;B b B .
Эта грамматика является LL(1)-грамматикой, т.к. для выбора правильной альтернативы на каждом шаге нам достаточно анализировать один (текущий) символ цепочки.
Грамматика называется разделённой, если все правила грамматики имеют вид:Aa11a2 2…akk, причём aiaj при ij, aiVT, i(VTVN)* при i[1,k]. Очевидно, что в случае разделённой грамматики строится детерминированный нисходящий разбор.
Очевидно, что разделённые грамматики принадлежат к классу LL(1)-грамматик.
Грамматики могут оказаться LL(k)-грамматиками для различных k, например, грамматика может быть LL(3)-грамматикой, но не LL(2)-грамматикой. Бывают и грамматики, которые не являются LL(k)-грамматикой ни для какого k.
Н
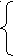 апример, рассмотрим грамматику G19 с множеством правил:
апример, рассмотрим грамматику G19 с множеством правил:S 0 A0B
A 0 A ac L(G)= {0n+1 c an, 0n+1 d bn, n 0}
B 0 B bd
В этой грамматике возможны выводы: S A n+10n+1 с an и SB n+1 0n+1 d bn ( n 0 ).
Чтобы определить по заданной терминальной цепочке, какое правило ( S A или S B ) было применено на первом шаге вывода, нужно прочитать n+1 символ, следовательно данная грамматика не является LL(k) ни при каком k.
Дадим формальное определение LL(k) грамматики. Для этого введем определение
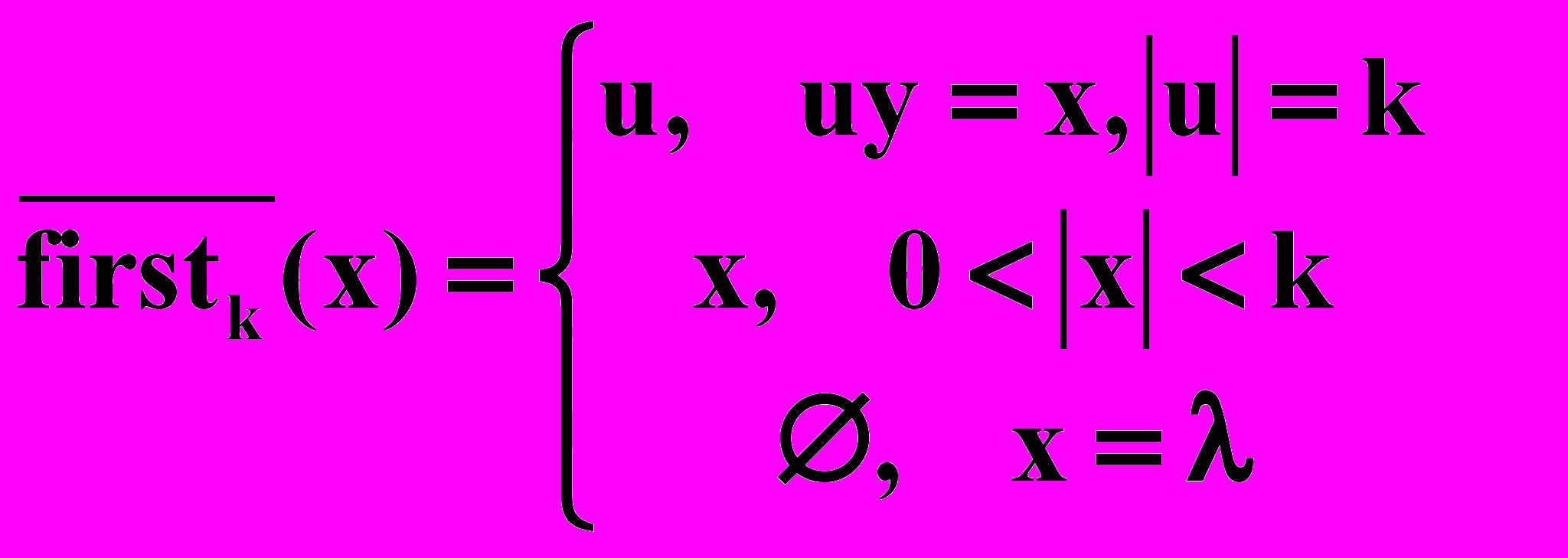
т.е. определяются первые k символов терминальной цепочки. Так как для пустой цепочки это пустое множество, то определим для данной грамматики пополненную грамматику, в которой не будут встречаться пустые цепочки:
Для грамматики G=< VN, VT, S, R> соответствующая пополненная грамматика G’=< VN{S’}, VT{$}, S’, R’>, где множество правил R’=R{S’ S $ }, здесь каждая цепочка имеет справа граничный маркер ($).
Расширим определение множества
 так, чтобы охватить произвольные цепочки (VTVN)*:
так, чтобы охватить произвольные цепочки (VTVN)*:Для (VTVN)* Firstk()= { x/ * Z, ZVT*, x=
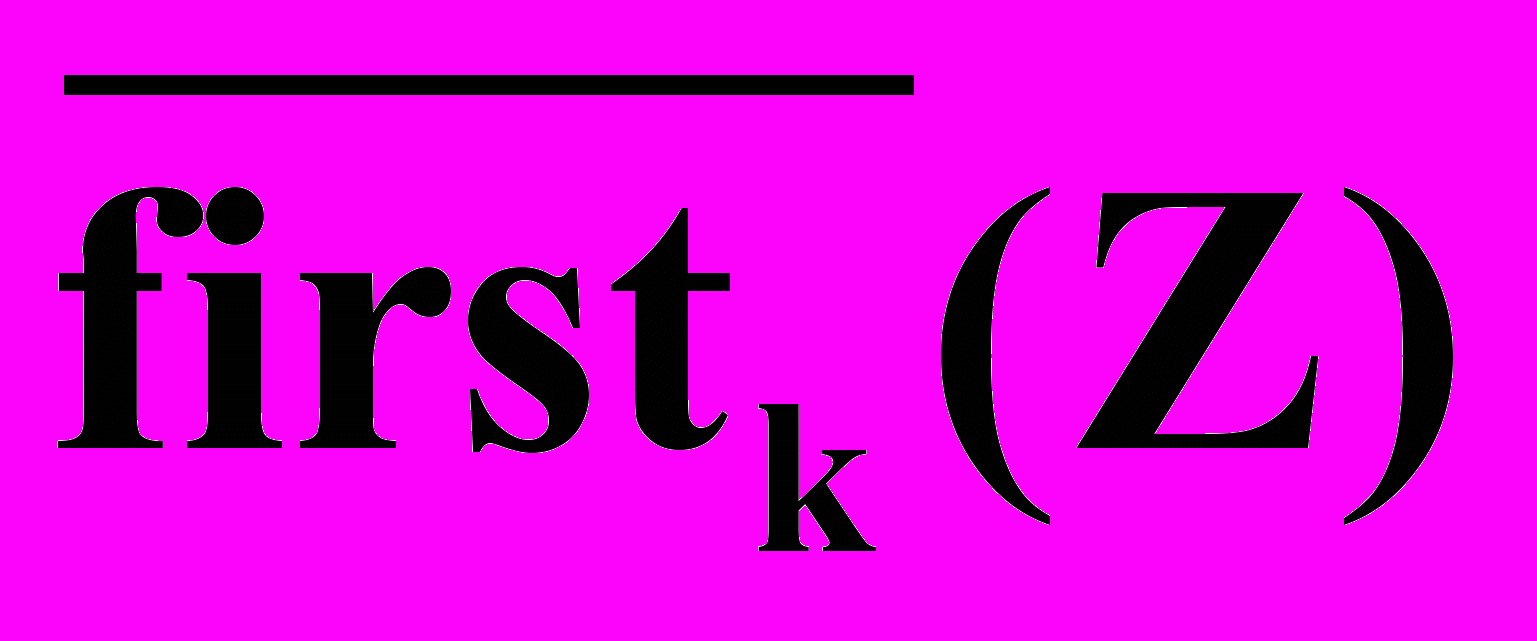 }.
}.Н
апример, рассмотрим грамматику G20 с множеством правилS abAabB;
A ab A c; L(G)= {(ab)nc, (abc)n, n 1}
B cab Bc .
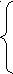 Правила соответствующей пополненной грамматики:
Правила соответствующей пополненной грамматики:S’ S $;
S ® abA½abB;
A ® ab A ½c;
B ® cab B½c.
Для данной грамматики
First1(S’)=First1(S)={a}, First1(A)={a, c}, First1(B)={c}; First2(S)={ab}, First2(A)={ab, c}, First2(B)={c, ca}, First2(S’)= =First2(S)={ab}; First3(S)= First3(S’)={abc, aba}, First3(A)={abc, aba, c}, First3(A$)={abc, aba, c$},First3(B)={c, cab}, First3(B$)={c$, cab}.
Тогда мы можем формально определить LL(k)-грамматику как грамматику, для которой для любых двух левых выводов
S* A * x
S* A * y
AVN, , x, y VT*, (VN VT)*, из условия Firstk(x)=Firstk(y) следует .
Несложно показать, что данное формальное определение соответствует неформальному.
Теорема 20. LL(k)-грамматика является однозначной.
Неоднозначность грамматики противоречит LL(k) свойству. Неоднозначна – значит, существуют два вывода для некоторой цепочки, поэтому не сможем определить по k символам, какое из правил следует применить.
Теорема 21. КС-грамматика G=< VN, VT, S, R> является LL(k)-грамматикой для любых двух правил А1 и А2 и для любой цепочки , такой что S*A из условия 12 следует, что Firstk(1 ) Firstk(2 )=.
Использование LL(k) свойства при построении анализатора.
- Пусть текущее состояние левого вывода цепочки z=y имеет вид А, где – выведенное терминальное начало цепочки, А – текущий нетерминал( самый левый нетерминал), y – не просмотренная часть цепочки.
- Рассмотрим Firstk(y). Пусть для нетерминала А существуют альтернативы: А12n R. Надо найти i для применения на данном шаге.
- Вычисляем
 = Firstk(i). Это множество может быть заранее вычислено для всех А, , i. При этом из LL(k) свойства следует, что
= Firstk(i). Это множество может быть заранее вычислено для всех А, , i. При этом из LL(k) свойства следует, что 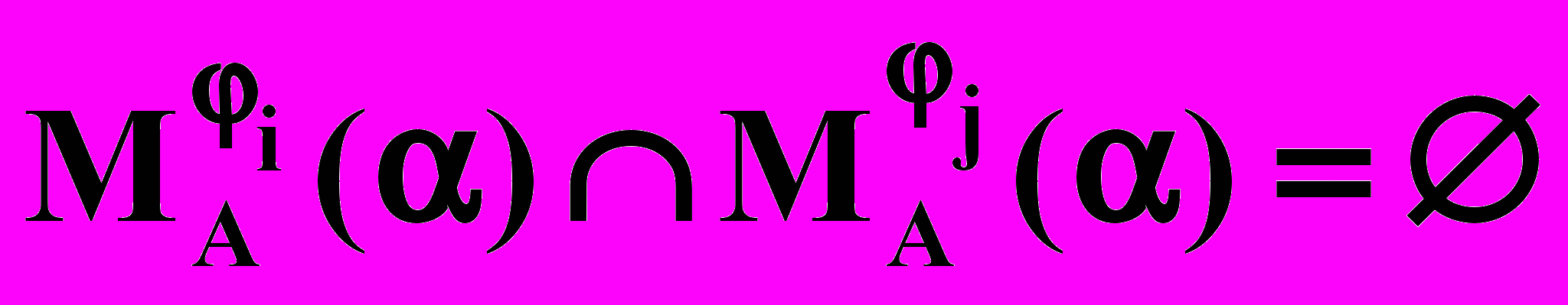 при ij.
при ij.
- Выбираем i, такое, что Firstk(y)= Firstk(i). Если такого i нет, то zL(G).
- Переходим к анализу полученной цепочки ’y’ (xy’y’), где ’ – терминальное начало цепочки 1. Шаги повторяются, пока не разберём всю цепочку, или не установим, что zL(G).
Пример:
Рассмотрим анализ цепочки acbbd в грамматике G21
S
 ac SbB;
ac SbB;B b Bd.
Эта грамматика является LL(1) грамматикой. На первом шаге определяем, какое правило применялось вначале: First1(acS)={a}, First1(bB)={b}, поэтому на первом шаге применяется правило S ac S, выведенная цепочка принимает вид: acS, First1(bbd)={b}, поэтому применяется правило S bB, и выведенная цепочка принимает вид acbB. Определяем First1(bB)={b}, First1(d)={d}, поэтому применяемое правило B b B, выведенная цепочка принимает вид acbbB, применяем правило B d, получаем исходную цепочку acbbd, значит, анализируемая цепочка принадлежит языку, порождаемому грамматикой.
Проблемы, возникающие при построении анализатора для LL(k)-грамматик:
1. При k1
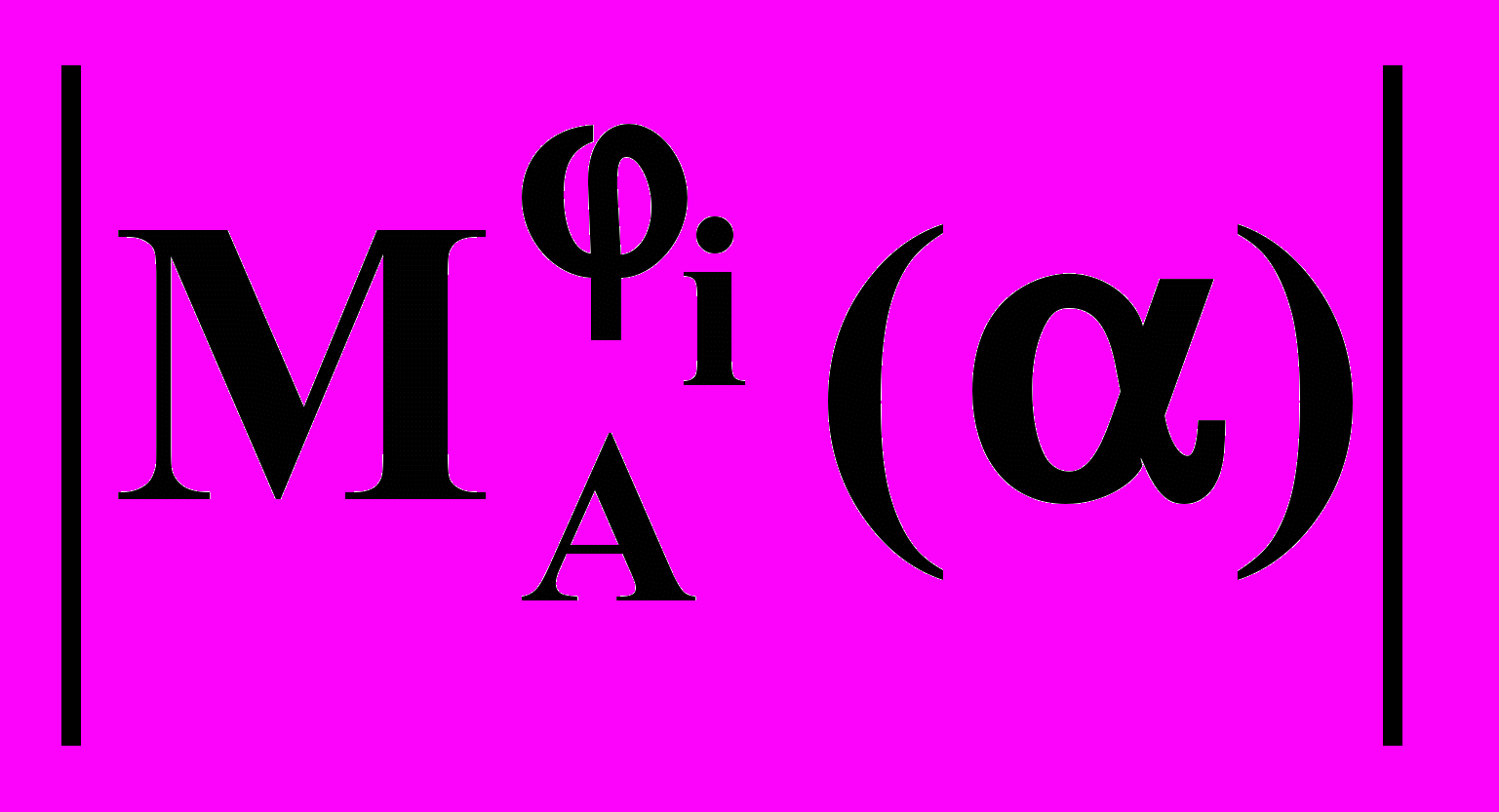 может стать неприемлемо большой, т.к. пропорциональна k.
может стать неприемлемо большой, т.к. пропорциональна k.2.
является функцией от трёх переменных: А, i, , т.е. велик сам объём предварительных вычислений.Однако можно упростить задачу, усилив условия, накладываемые на грамматику.
Обозначим
 и потребуем, чтобы
и потребуем, чтобы  при ij.
при ij.Грамматика G называется строго LL(k)-грамматикой, если для любых двух левых выводов
S*1 A 1 1 1 *1x
S*2A 2 2 2 *2 y
AVN, 1, 2, x, y VT*, 1 2 (VN VT)*, из условия Firstk(x)=Firstk(y) следует .
Несложно показать, что G является строго LL(k)-грамматикой для любого AVN из того, что AR, AR, , следует MAMA=.
Теорема 22. LL(1)-грамматика всегда строго LL(1)-грамматика.
Доказательство.
Предположим, что некоторая грамматика G – LL(1) грамматика, но не строго LL(1)-грамматика. Тогда существуют два вывода:
S*1 A 1 1 1 * 1x11* 1x1y1
S*2A 2 2 2 * 2 x22* 2 x2y2,
(AVN, 1, 2, x1,y1, x2,y2 VT*, 1 2 (VN VT)*), такие, что First1 (x1y1) = First1(x2y2) & – Условие (*).
Но так как G – LL(1)-грамматика, то
S* 1 A 1 1 1* 1x11 * 1x1y1
S* 1 A 1 1 1* 1x21* 1x2y1
(AVN, 1, 2, x1,y1, x2 VT*, 1 2 (VN VT)*) и из First1 (x1y1) = First1(x2y1) следует – Условие (**).
Покажем, что условия (*) и (**) несовместны.
Рассмотрим следующие случаи:
1. x1, x2 , тогда First1(x1y1)=First1(x1), First1(x2y2)=First1(x2), First1(x1 )=First1(x2) и, по условию (*), .
С другой стороны, по условию (**), из First1(x1 )=First1(x2) следует . Противоречие.
2. x1=, x2= приводит к неоднозначности грамматики.
3. Пусть x1=, x2. Тогда в условии (*)First1(x1y1)=First1(y1)= =First1(x2y2)=First1(x2) & .
По условию (**) First1(x1y1)=First1(y1)= First1(x2y1)=First1(x2) & =. Противоречие.
4. Случай 4, x1¹l, x2=l разбирается аналогично случаю 3.
Из теоремы следует критерий принадлежности грамматики классу LL(1):
G – LL(1) грамматика AVN, , AR & AR & & MAMA=, где MAb=

При этом если
а) , *, , то MA=First1()
б) *, MA=First1()

Определим множество Follow1(X)={a/ S+Xa&aVT}, для X(VNVT).
Тогда условие б) можно переписать следующим образом:
б) *, MA=First1()Follow1(A).
Так как рассматриваем пополненную грамматику, то (First1()=).
Определения и алгоритмы нахождения множеств First и Follow
1. First1()
1.1. First1()=
1.2. aVT First1(a)=a
- First1(A)={ First1(xi) / Ax1x2…xnR & (i=1 i=m &
& x1…xm-1+)}
1.4. First1(x1x2…xn)={ First1(xi)/ i=1i=m&x1…xm-1+}
Например, рассмотрим грамматику G22 с правилами:
S
 ABCCA;
ABCCA;Aa;
B b B;
CcCd .
В пополненной грамматике добавляется начальное правило S’ S$:
S
’ S $;S ABCCA;
Aa;
B b B;
CcCd .
First1(A)={a};
First1(B)={b};
First1(C)={c,d};
First1(S)= First1(ABC) First1(CA)={a, b, c, d}.
- Follow1(A)=
 ={First1()/ S * A }. Рассматриваем грамматику без непроизводящих правил, тогда если S * B A , то First1( ) Follow1(A).
={First1()/ S * A }. Рассматриваем грамматику без непроизводящих правил, тогда если S * B A , то First1( ) Follow1(A).
- , *, , тогда First1()=First1().
- *, тогда First1()=First1()First1().
- , *, , тогда First1()=First1().
Поэтому Follow1(A)={ First1(Xm)/ B A X1 X2…XnR &
& (m=1X1X2…Xm-1*)} {Follow1(B)/B A R &*}
То есть просматриваются все правые части правил, в которые входит исследуемый нетерминал.
Рассмотрим пополненную грамматику G23, в этой грамматике N={A,B};
Follow1(S)={$},
Follow1(A)= First1(B) First1(C) Follow1(S)={b, c, d, $},
Follow1(B)= First1(C)={c,d},
Follow1(C)= First1(A) Follow1(S)={a,$}.
Проанализируем LL(1)-свойство грамматики:
MSABC= First1(A) First1(B) First1(C)={a, b, c, d},
MSCA= First1(C)={c,d}.
Так как MSABC MSCA , то грамматика не является LL(1) –грамматикой.