
Лекция Темы обсуждений предыдущей лекции
| Вид материала | Лекция |
- Лекция поведение потребителя, 61.41kb.
- Лекция 11. Основные вопросы, выносимые на обсуждение на предыдущей лекции, 91.29kb.
- Лекция 4 основы теории спроса и предложения, 43.74kb.
- Лекция Расчет основных термодинамических величин ΔU,, 283.92kb.
- Темы, которые мы обсуждали на предыдущей лекции: Прообраз=(Тадж Махал)=Неизвестный, 97.53kb.
- Урок истории в 6 классе, 18.18kb.
- В. В. Управление персоналом. М.: Академия, 2003. 528 с. Лекция, 1904.58kb.
- Изучение теоретической механики, 209.36kb.
- Темы обсуждений Врамках мероприятия затронуты следующие темы: -типичные административные, 14.73kb.
- Лекции и семинары проблемная лекция, 45.27kb.
Лекция 7.
Темы обсуждений предыдущей лекции:
1. Ввели понятие остатка:
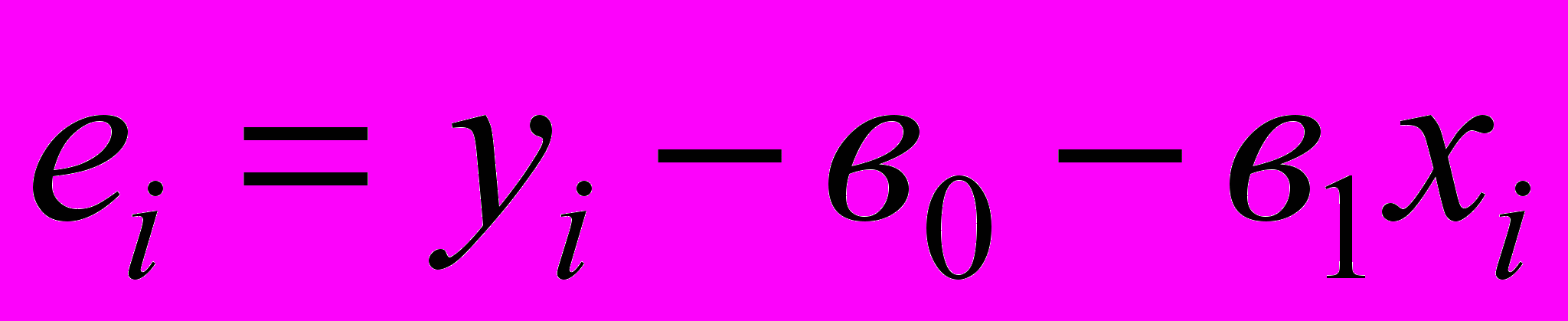
2.Доказали теорему:
TSS= RSS+ ESS.
3.Дали определение коэффициента детерминации:
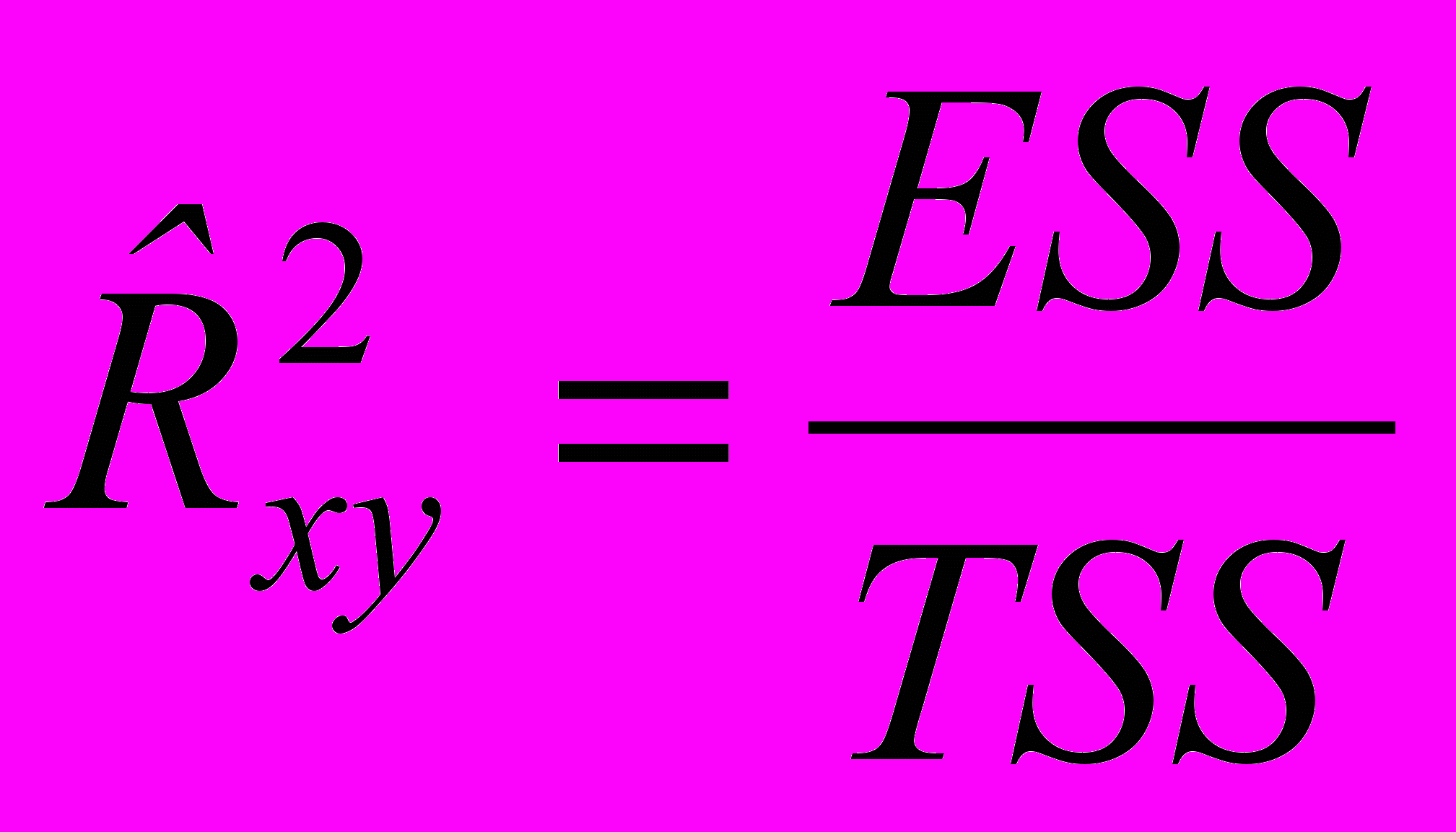
4. Отметили, что имеет место равенство:
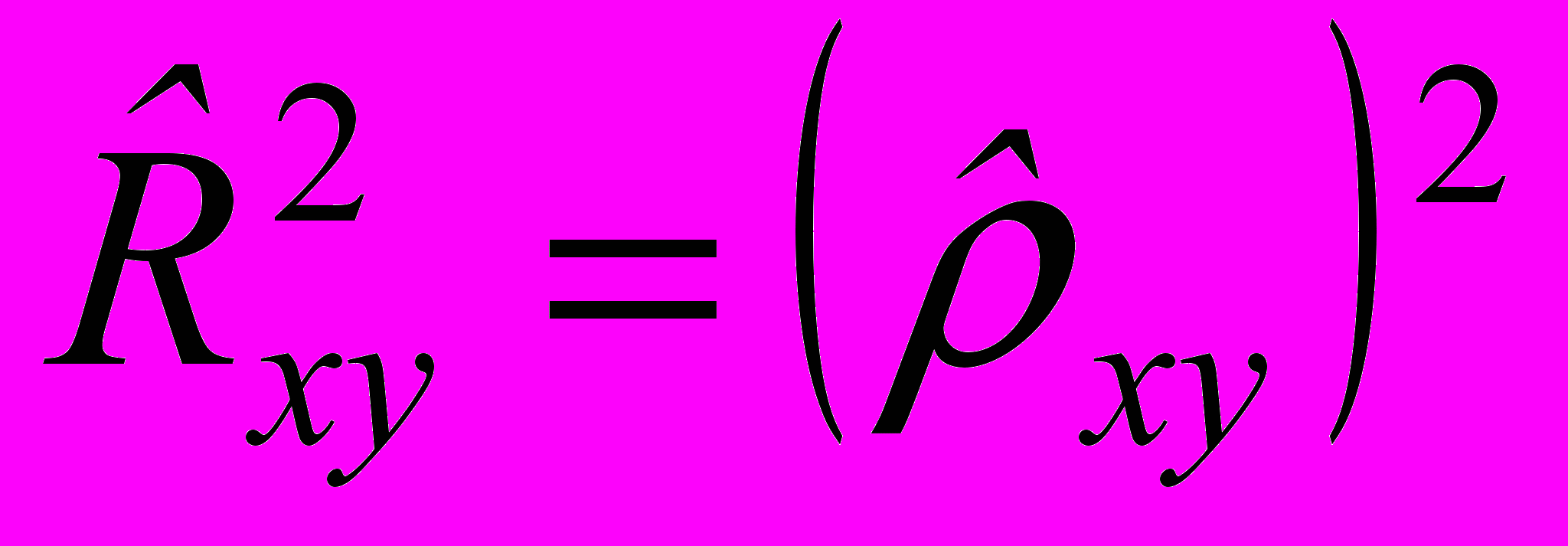
2.5. Анализ адекватности регрессионной модели эмпирическим данным
На этой лекции во-первых, рассмотрим каким образом, применяя статистическую проверку гипотез, можно проверить предположение о зависимости фактора x и результирующего признака y. Во-вторых, проведем проверку гипотезы о том, что функция, связывающая x и y, линейная.
Предположим, что переменная х в модели линейной регрессии носит случайный характер, причем ее закон распределения так же, как и у случайной составляющей модели, нормальный. В рамках этих предположений проверку гипотезы о независимости х и у сведем к проверке гипотезы о неокоррелируемости двух случайных величин. Как известно, для нормально распределенных случайных величин из некоррелируемости следует их независимость. Это позволит нам использовать коэффициент корреляции для оценки тесноты связи между двумя случайными величинами. Однако, как уже отмечалось выше и как указывается в [1]: «пока не предложено характеристики линейной связи, которая бы обладала очевидным преимуществом по сравнению с коэффициентом корреляции, его интерпретация оказывается часто весьма ненадежной».
Вычислим все выборочные числовые характеристики x и y и, самое главное, вычислим
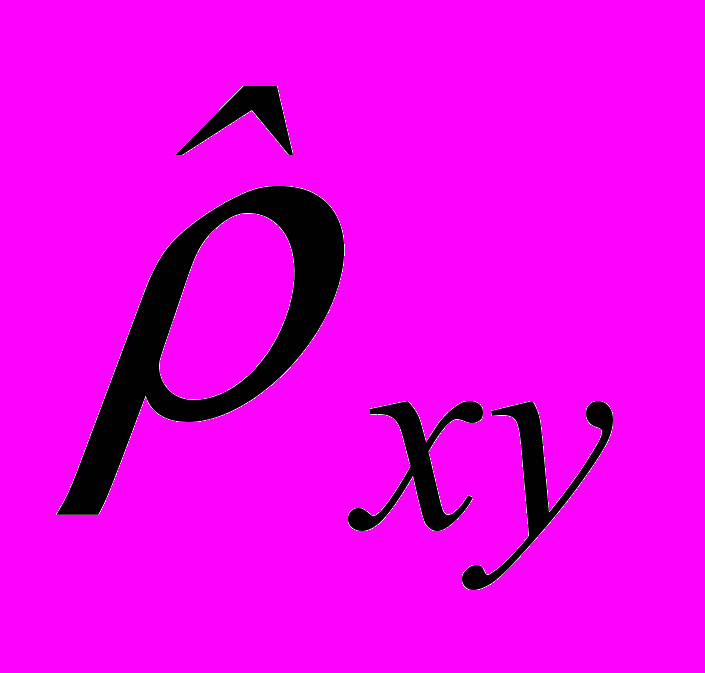 .
.^ Выдвинем основную гипотезу H0 о том, что переменные x и y некоррелированные:
H0:
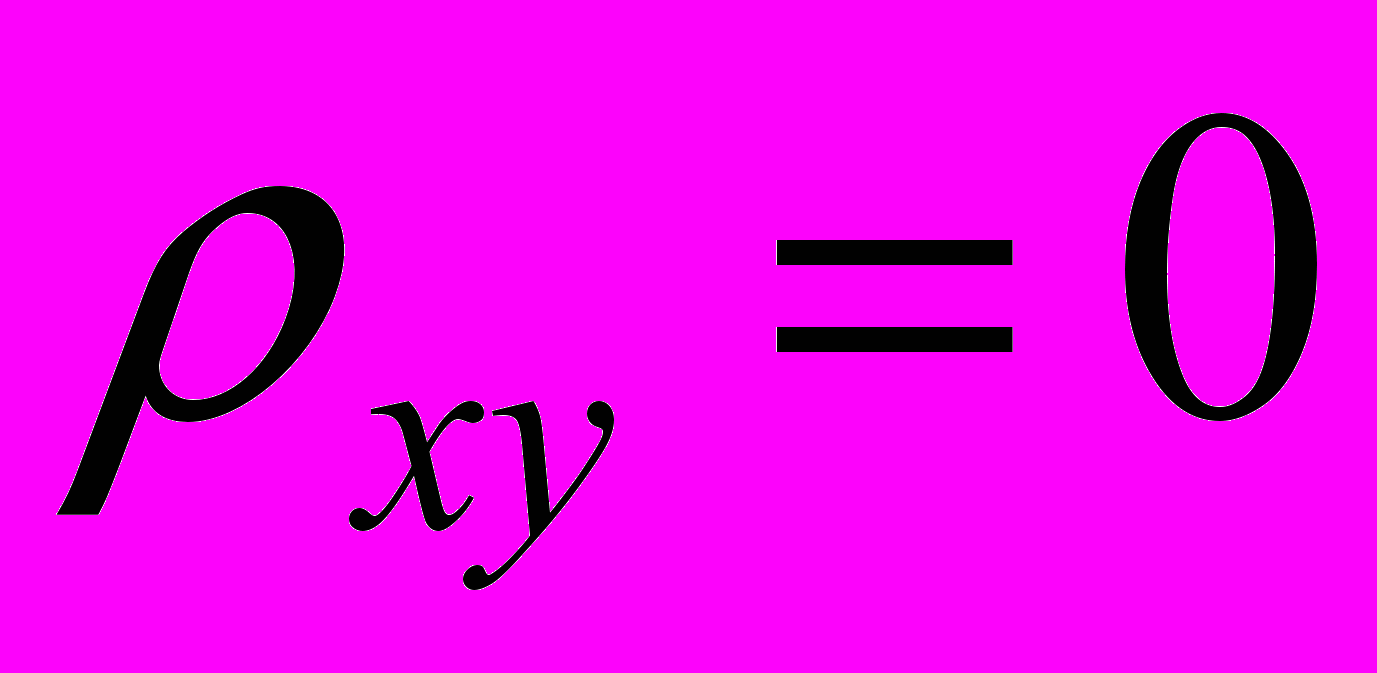
и альтернативную гипотезу Hа:
Hа:
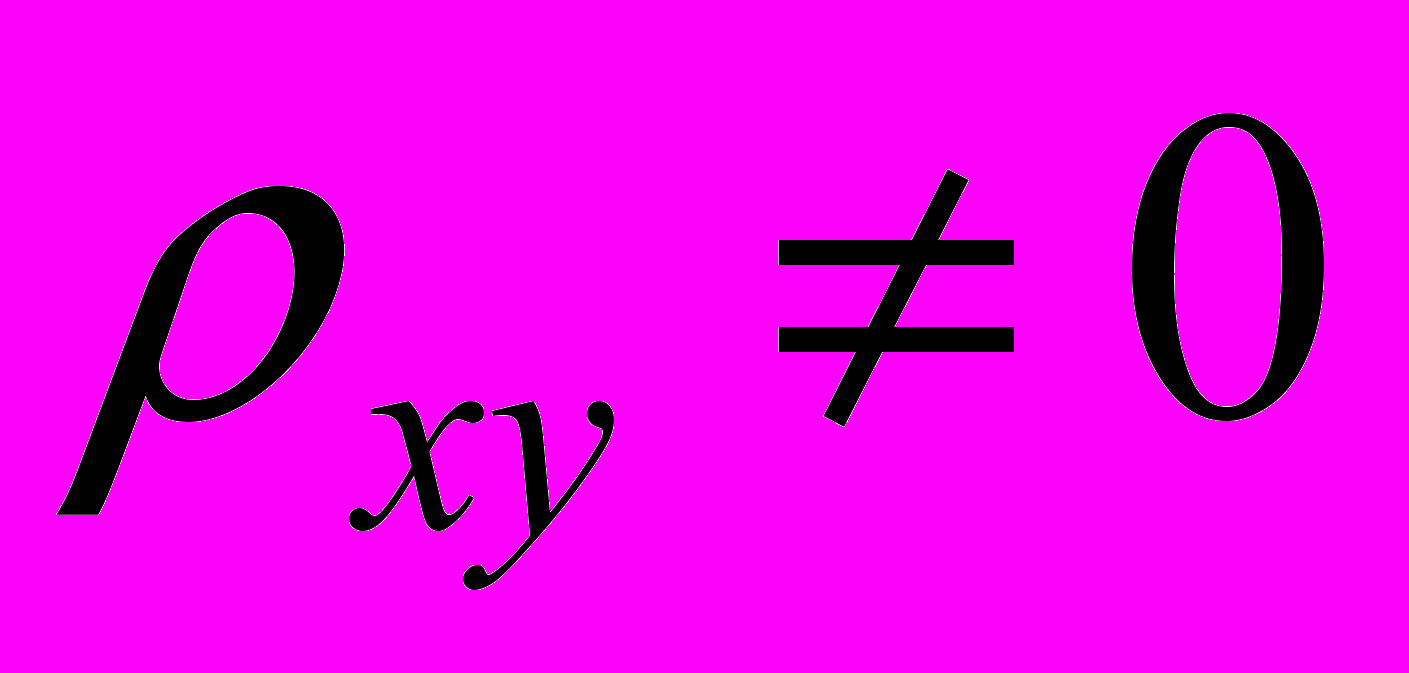 .
.Проверку гипотезы будем проводить, действуя согласно алгоритму, приведенному в параграфе 1.3. Для проверки гипотезы H0 введем выборочную статистику:
Z*=
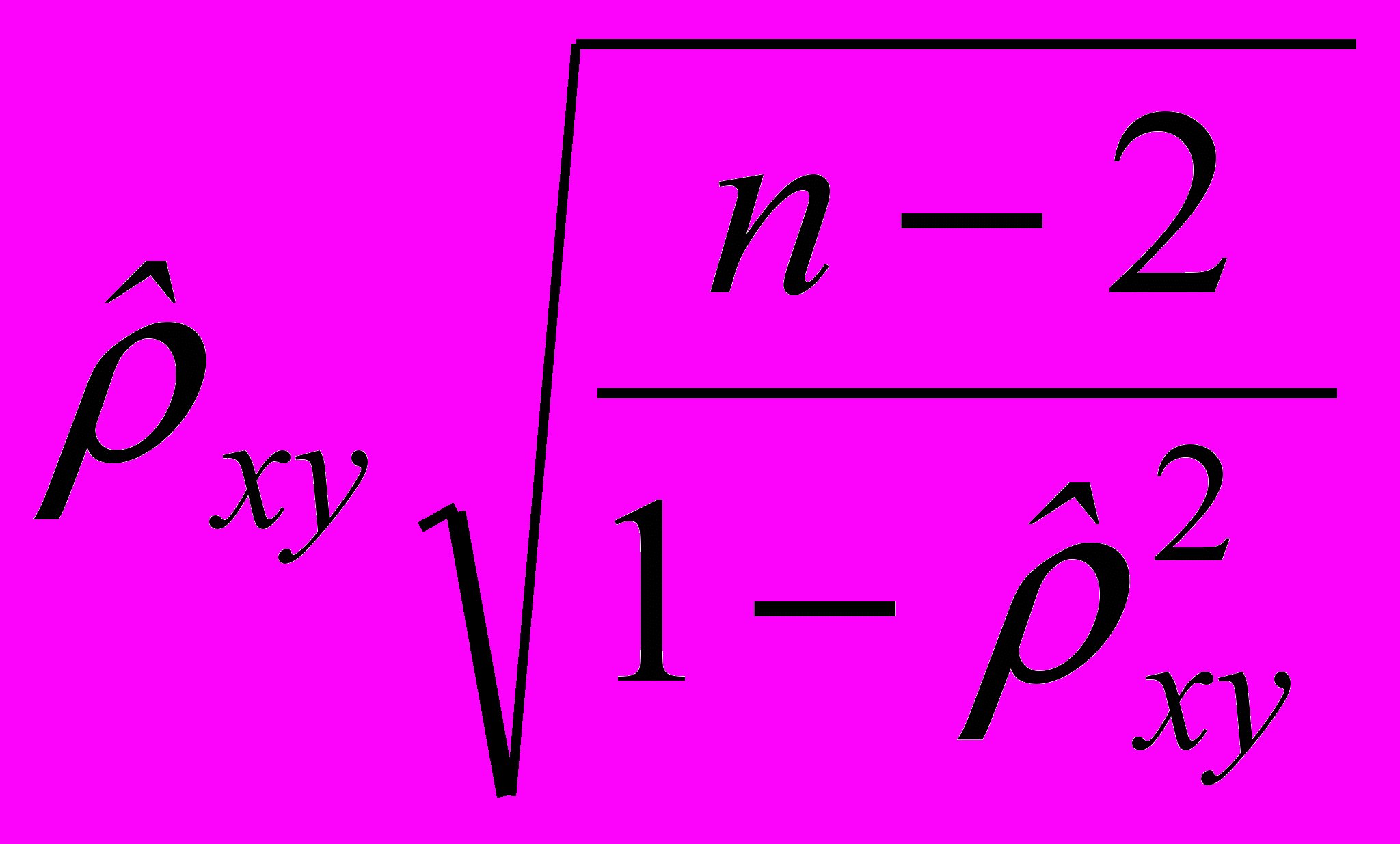 . (2.5.1)
. (2.5.1)Доказано, что если основная гипотеза верна, то эта статистика распределена по закону Стьюдента (t-распределение) с (n-2) степенями свободы. Её часто называют t-статистикой. Используя таблицы распределения Стьюдента, по заданному уровню значимости и
(n-2) степеням свободы, находим границу двусторонней критической области К2, К1= - К2.
Проверяем, если выполняется одно из неравенств Z*£ К1 или
Z* ³ К2, основную гипотезу отвергаем, принимаем альтернативную. В этом случае говорим, что у нас есть основание считать, что предположение о независимости случайных величин необоснованно.
В том случае, когда выборочная статистика удовлетворяет неравенству
К1 < Z* <К2 принимаем основную гипотезу и делаем вывод, что у нас нет оснований считать, что у зависит от х, либо зависимость носит нелинейный характер. Следовательно, когда принимаем основную гипотезу, нам следует или вообще отказаться от построения регрессионной модели между рассматриваемыми переменными, либо рассмотреть нелинейную модель.
^ Замечание 1. Если альтернативная гипотеза будет формулироваться следующим образом:
Hа:
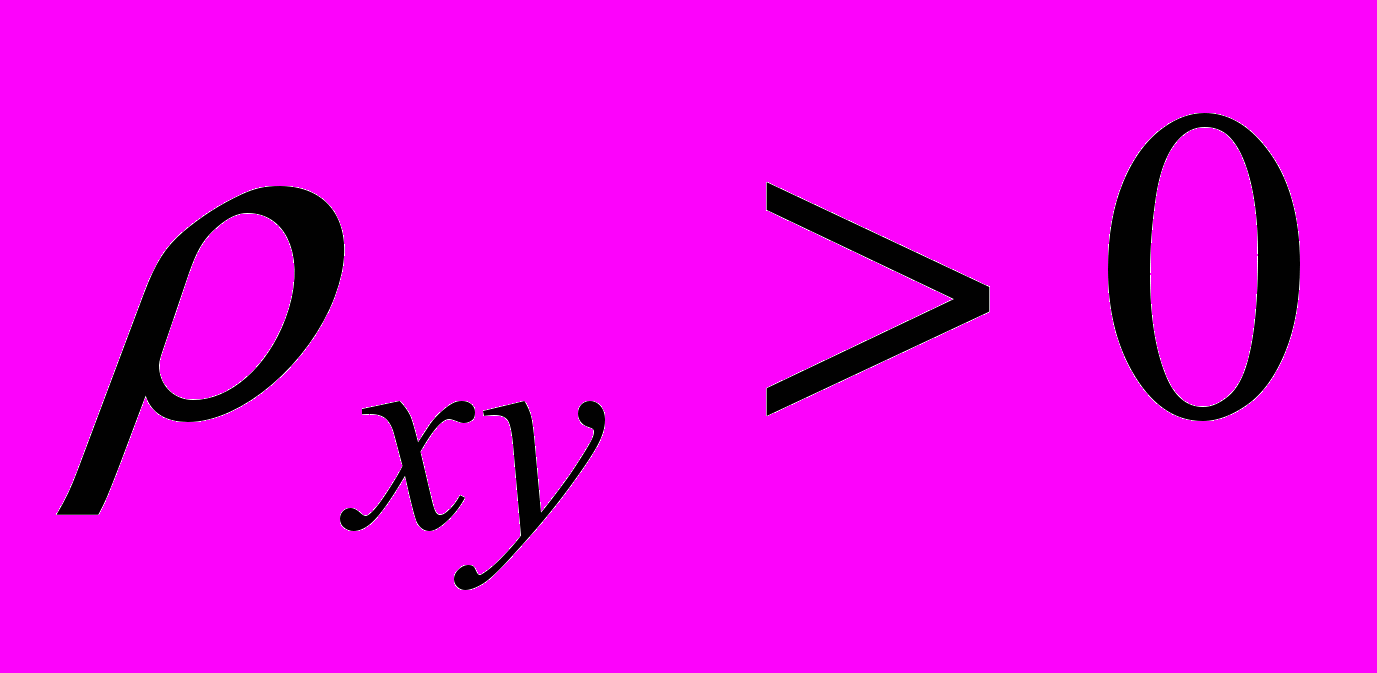 .
. или
Hа:
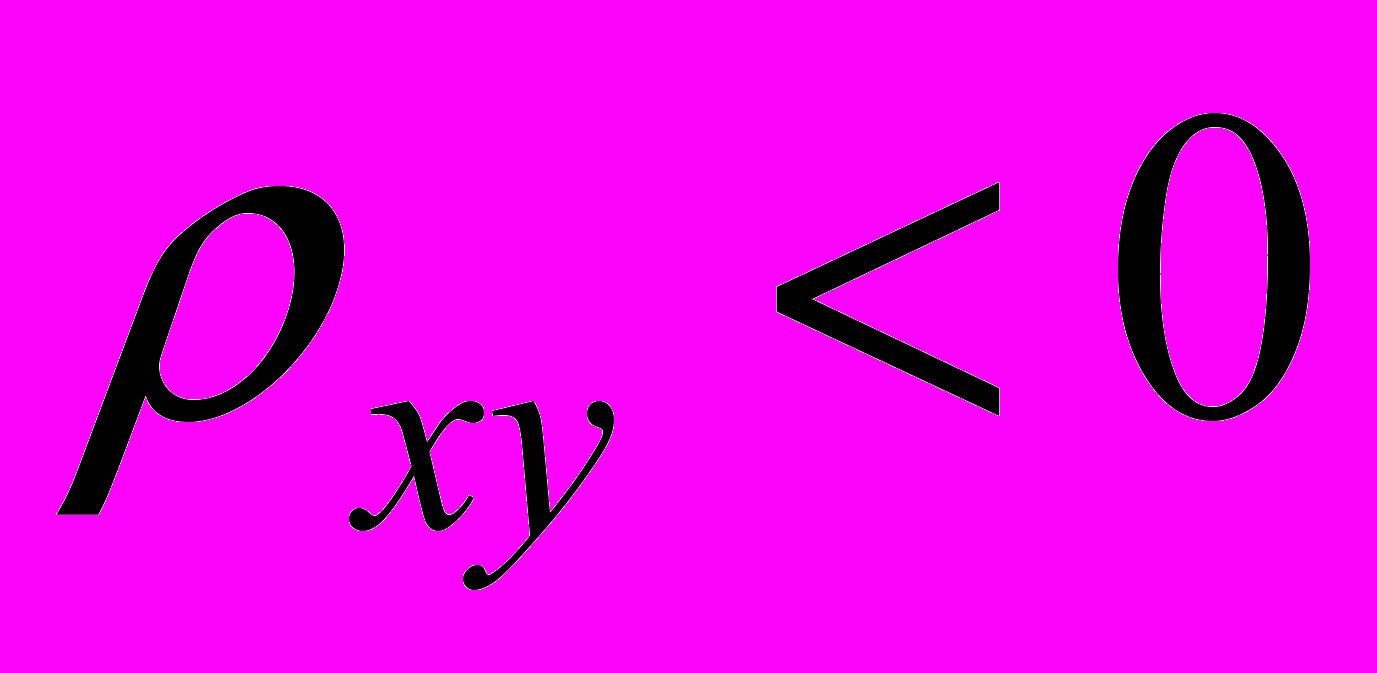 ,
,то в первом случае критическая область будет правосторонней и гипотезу Hа будем принимать тогда, когда будет иметь место неравенство Z* ³ К2. Если выборочная статистика будет удовлетворять неравенству Z*< К2 , будем принимать основную гипотезу. Во втором случае критическая область будет левосторонней, поэтому альтернативная гипотеза будет приниматься тогда, когда выполняется неравенство Z*£ К1. Основная гипотеза будет приниматься когда Z*> К1.▲
Замечание 2. Качественное проведение статистических расчетов, требует, чтобы объем выборки, по которой они проводятся, был достаточно велик. Если объем информации недостаточен (выборка небольшого объема), то даже, тогда когда теоретический коэффициент
(нормально распределенные случайные величины независимы), выборочный коэффициент корреляции может оказаться большой величиной и, на основании этого, мы можем сделать ошибочные выводы. Поэтому следует проверять значимость выборочного коэффициента корреляции, то есть проверять какую величину следует считать достаточной для того, чтобы сделать обоснованный вывод о стохастической связи между х и у.^ Основная и альтернативная гипотезы формулируются следующим образом:
H0:
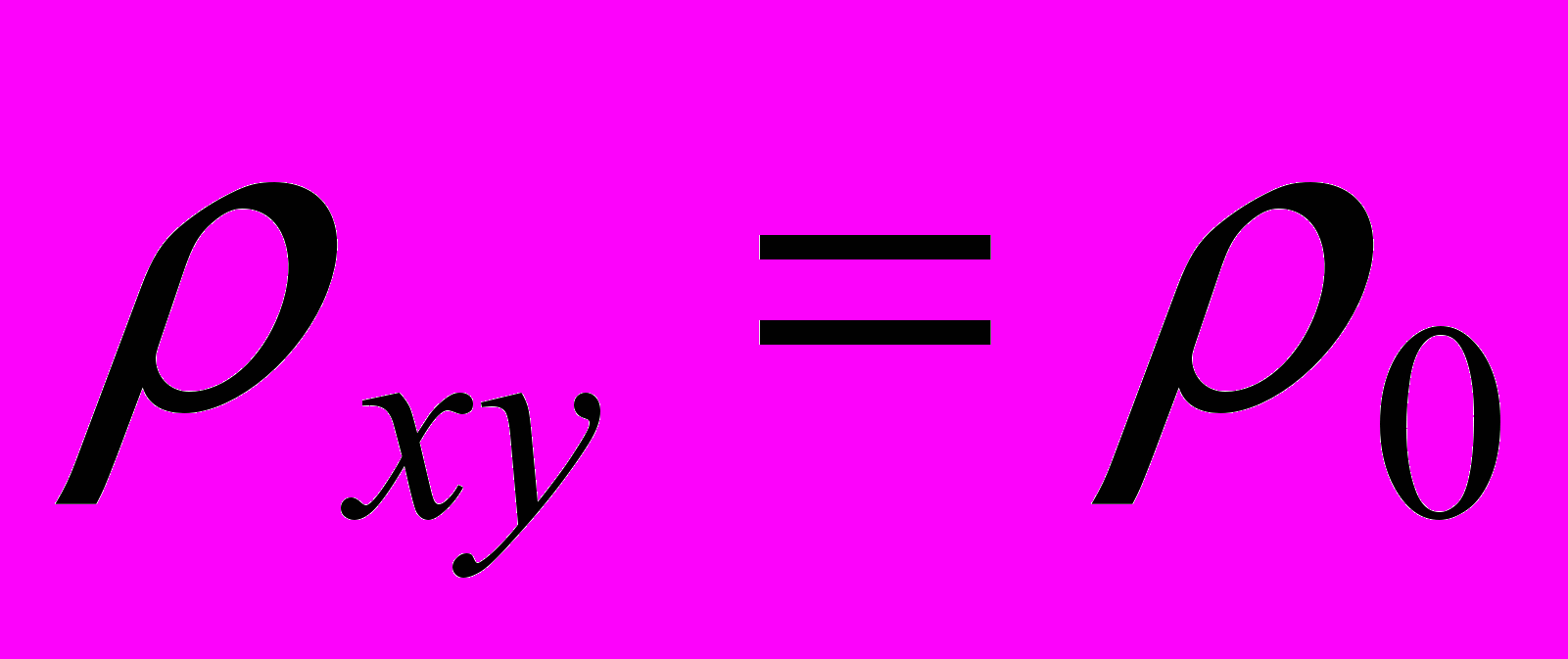 ,
, Hа:
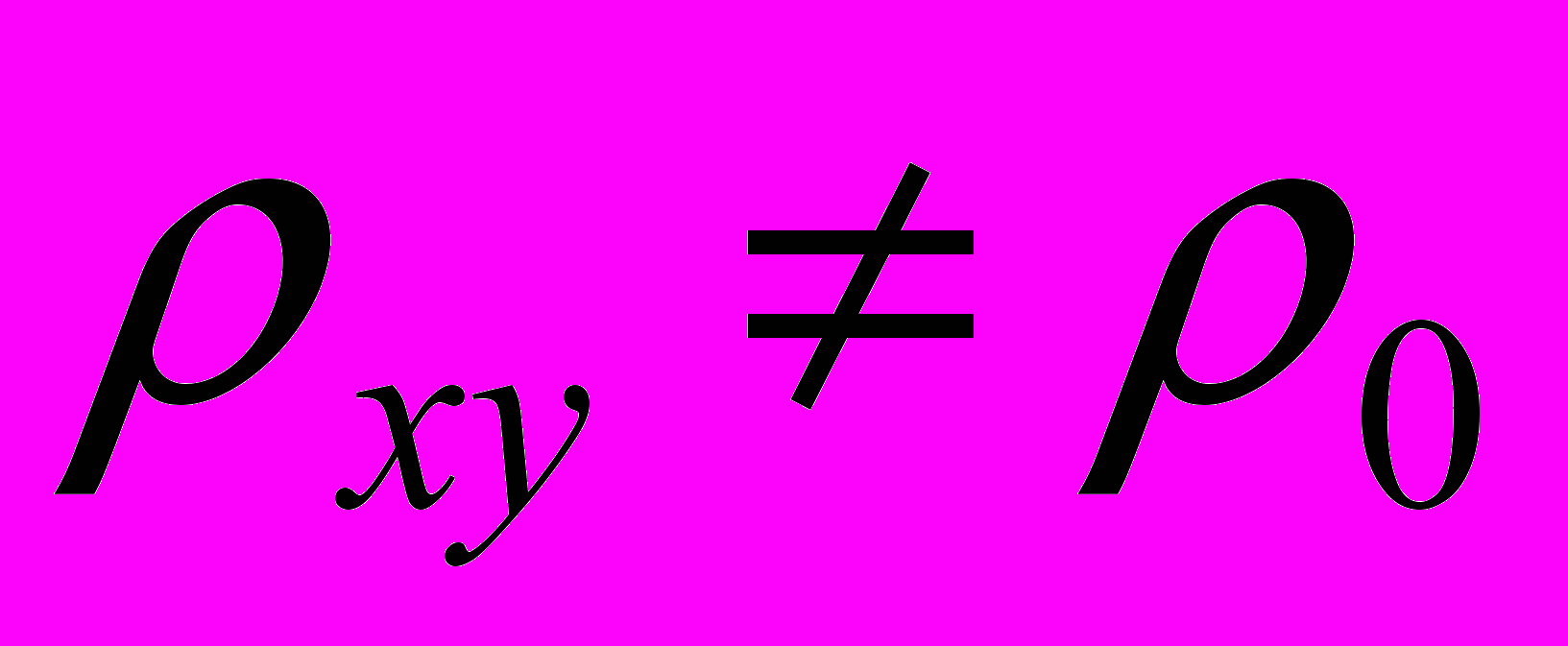 .
.Вспомогательную случайную величину вычислим по формуле:
Z* =
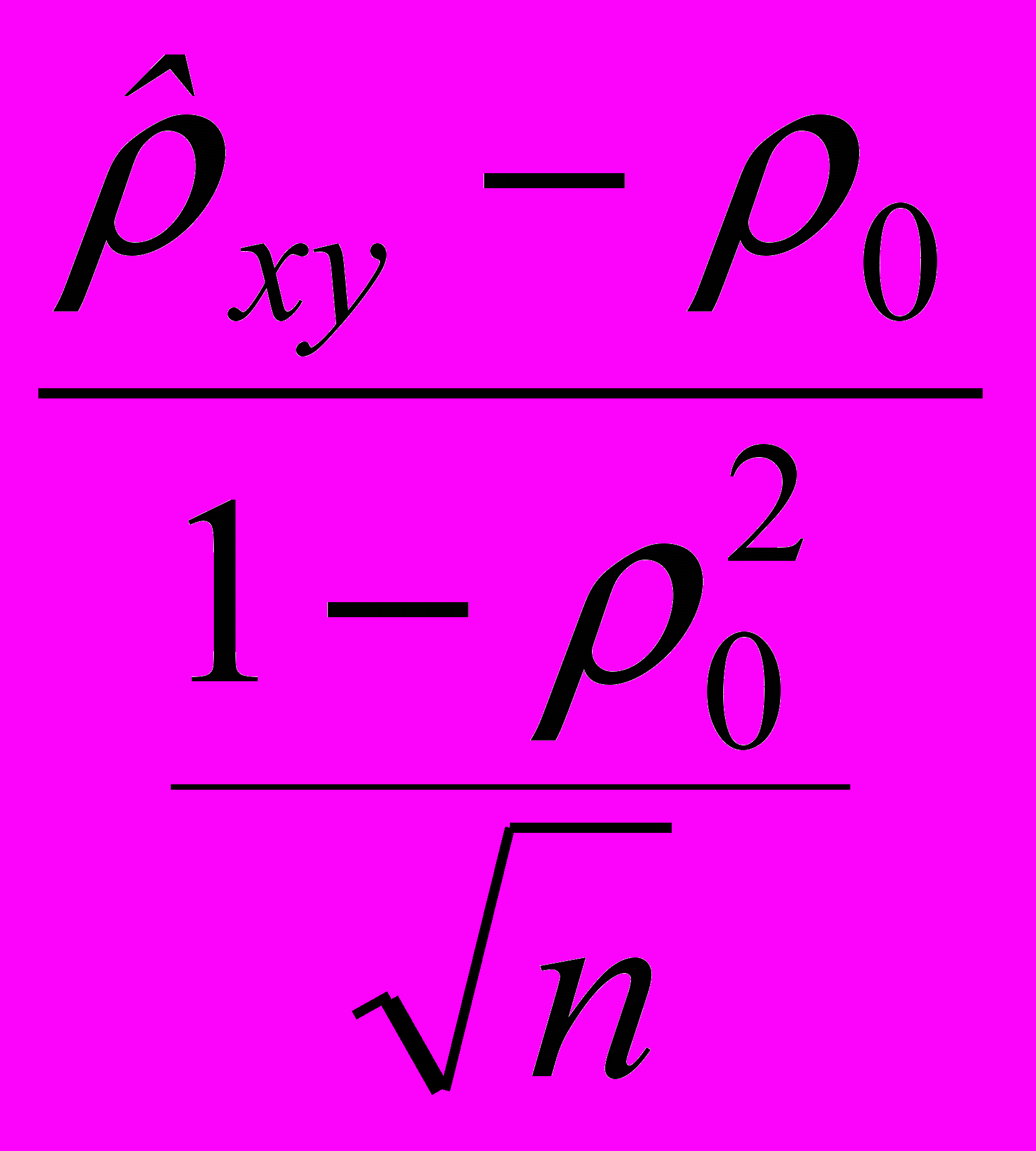 . (2.5.2)
. (2.5.2)Если основная гипотеза верна, то распределение случайной величины Z* асимптотически нормальное с параметрами
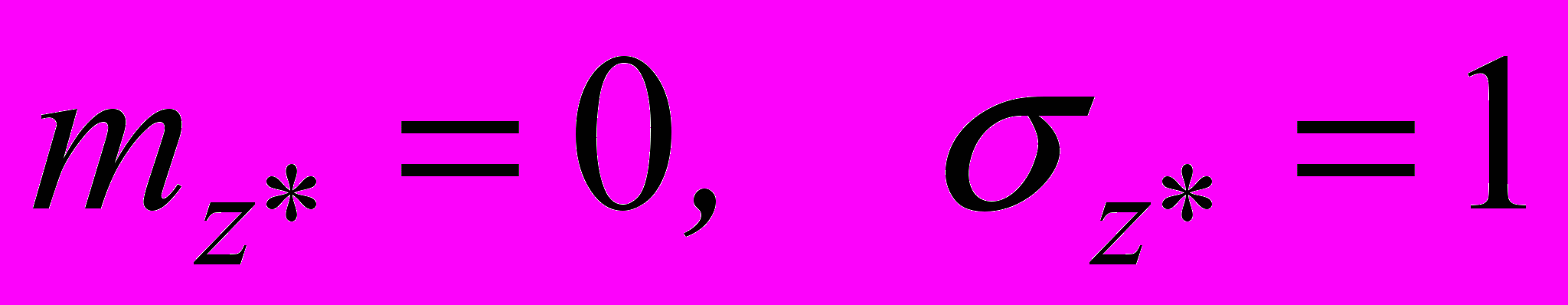 . Поэтому границу двусторонней критической области найдем по таблицам Лапласа по заданному уровню значимости (1-
. Поэтому границу двусторонней критической области найдем по таблицам Лапласа по заданному уровню значимости (1- ) из условия: К2 =
) из условия: К2 =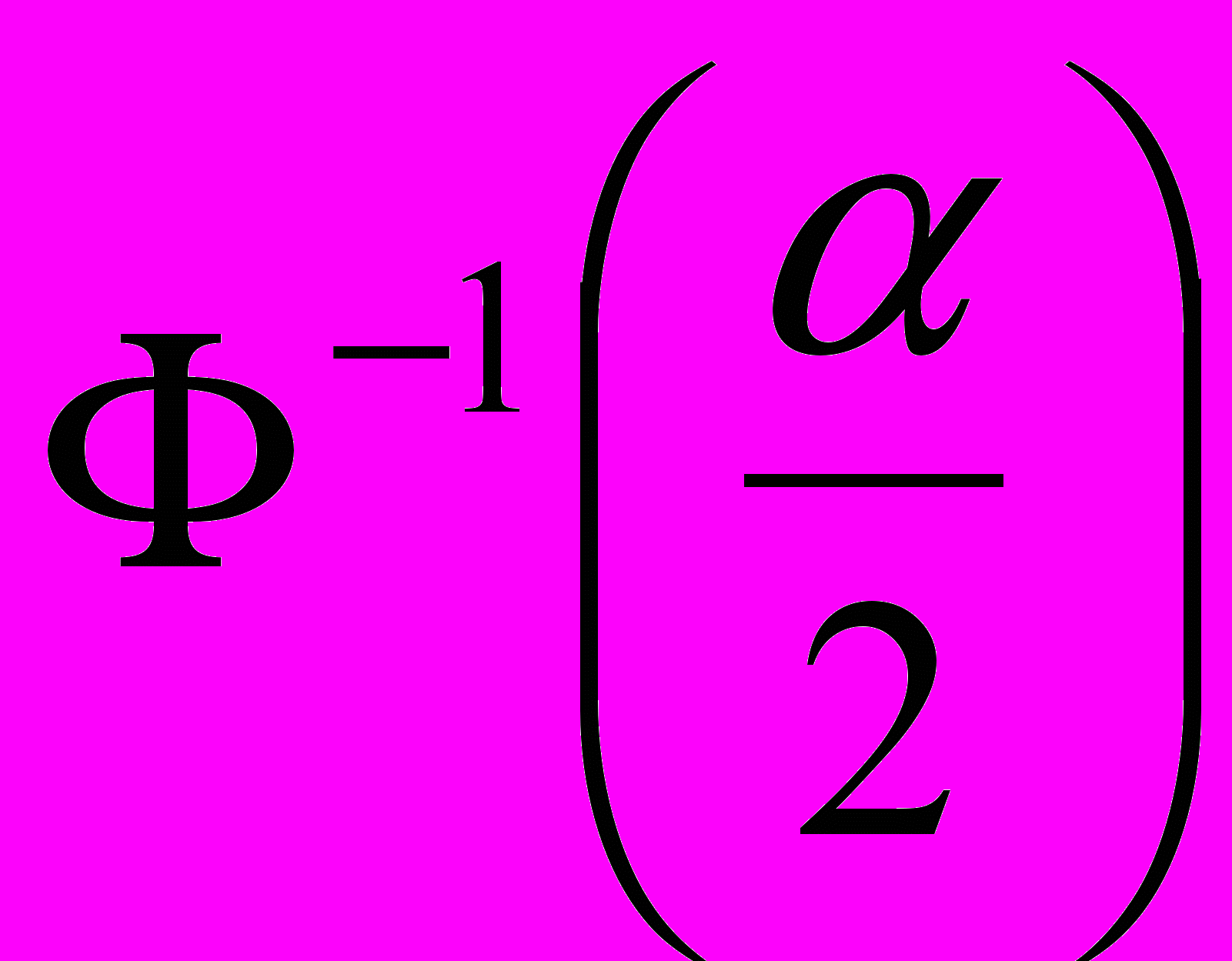 , К1= - К2. Принимаем основную гипотезу, когда имеет место неравенство:
, К1= - К2. Принимаем основную гипотезу, когда имеет место неравенство: 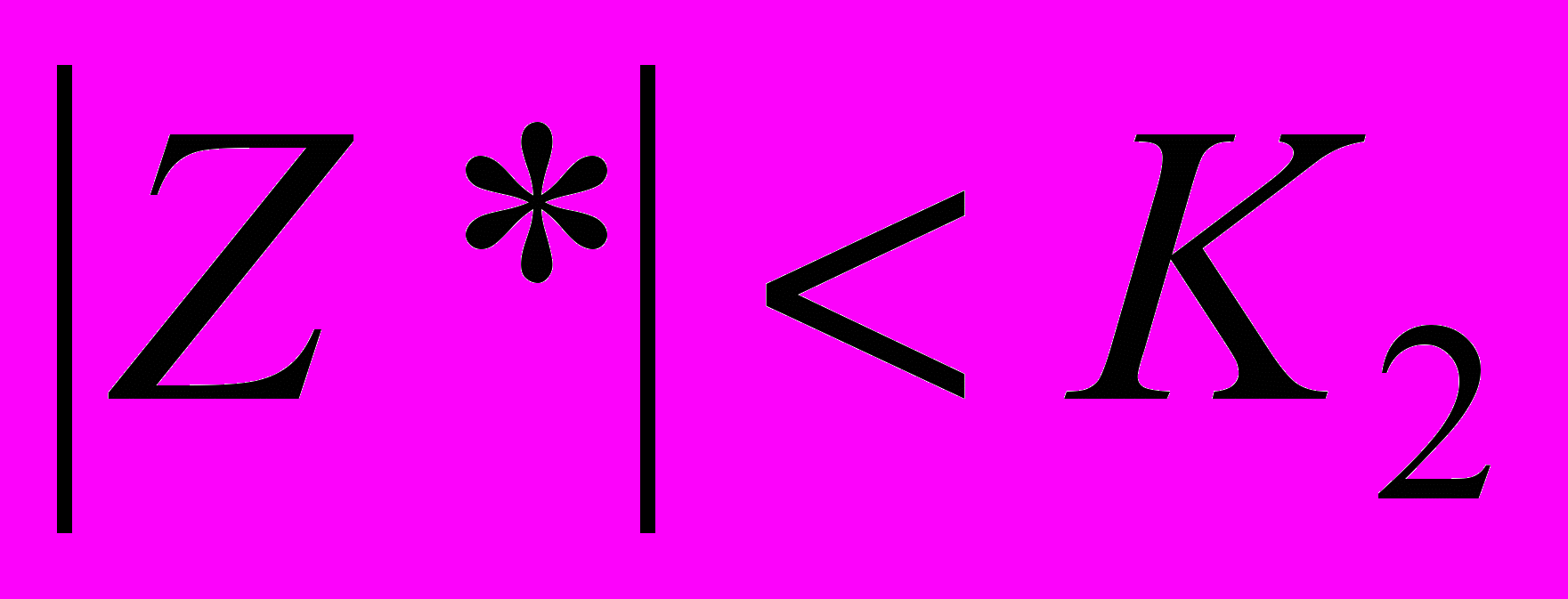 , отвергаем основную гипотезу в пользу альтернативной гипотезы, когда выполняется одно из неравенств Z*£ К1 или Z* ³ К2.
, отвергаем основную гипотезу в пользу альтернативной гипотезы, когда выполняется одно из неравенств Z*£ К1 или Z* ³ К2. Если альтернативная гипотеза будет иметь вид Hа:
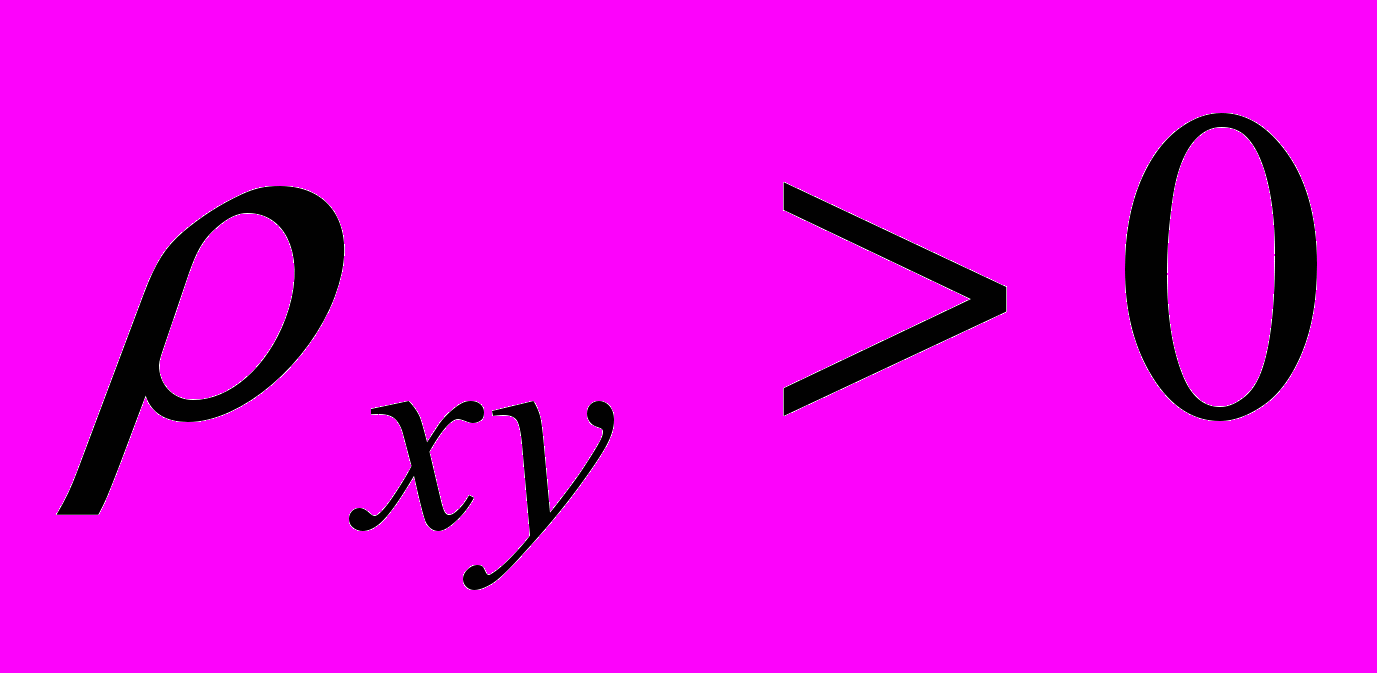 или Hа: , то критическая область будет правосторонней и левосторонней соответственно.
или Hа: , то критическая область будет правосторонней и левосторонней соответственно.Указанную проверку гипотез рекомендуют проводить при помощи данного критерия, когда
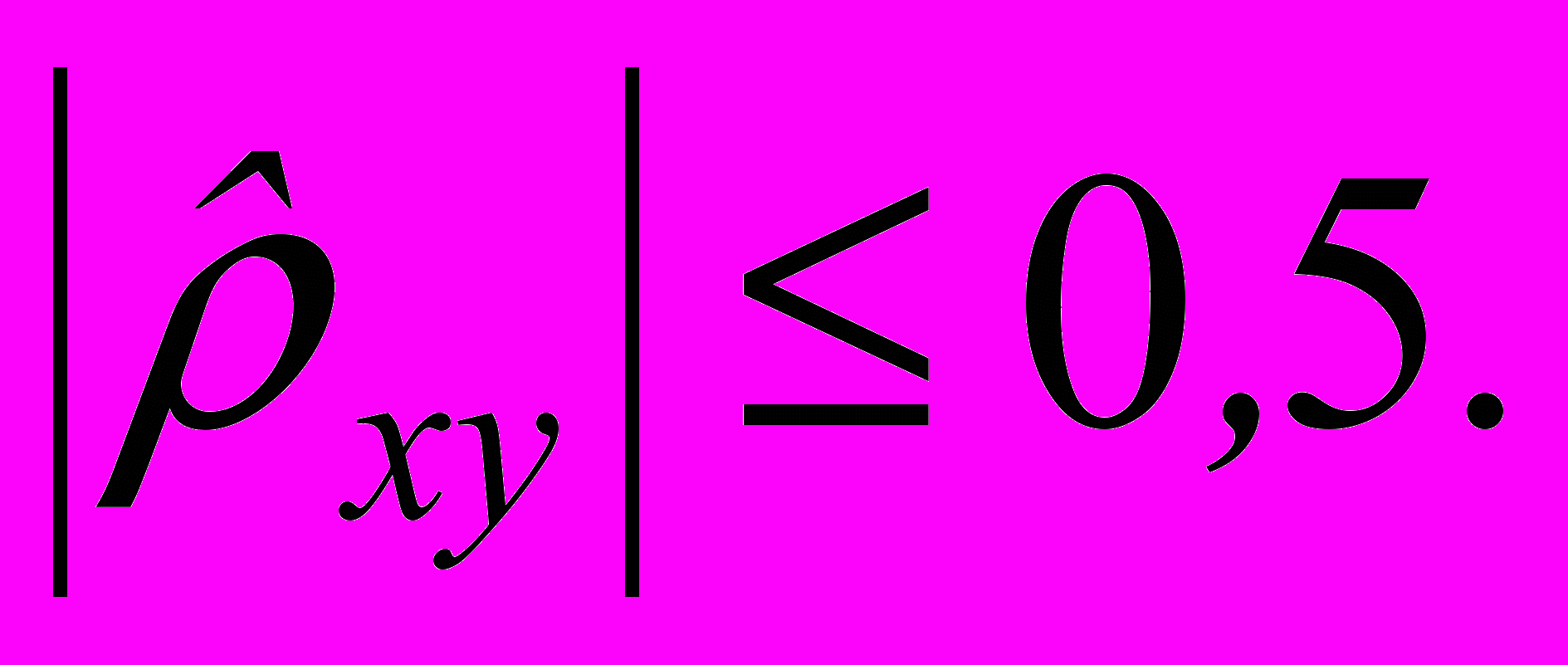 Чтобы проверять основную гипотезу без этого ограничения, можно использовать статистику вида (2.5.3):
Чтобы проверять основную гипотезу без этого ограничения, можно использовать статистику вида (2.5.3):Z*=
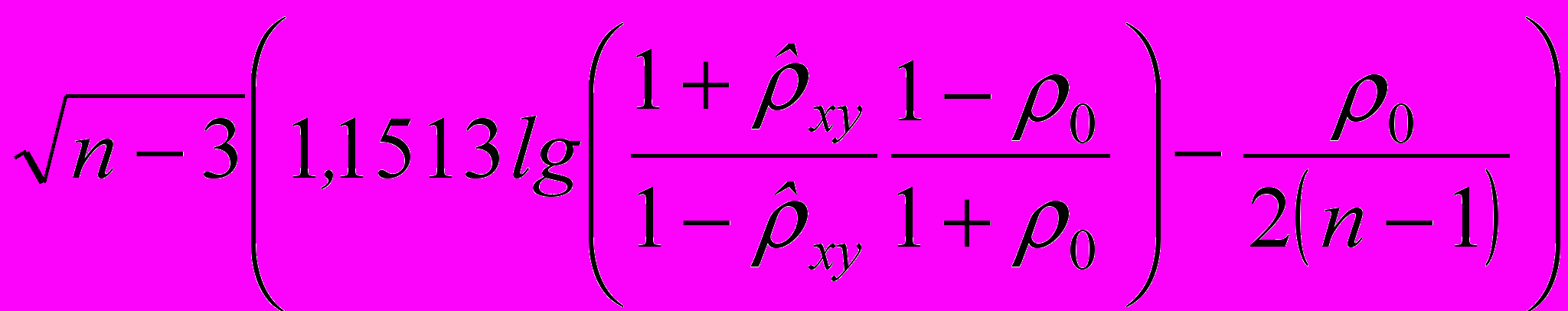 . (2.5.3)
. (2.5.3)Случайная величина (2.5.3) будет также иметь асимптотически нормальное распределение с нулевым математическим ожиданием и единичной дисперсией. Схема принятия или отклонения основной гипотезы полностью повторяет выше изложенную. ▲
^ Для дальнейших рассуждений нам понадобятся следующие понятия: оценка неизвестной дисперсии s2, оценка дисперсии для в1 и для в0
Несмещенная оценка дисперсии s2 будет вычисляться по формуле:
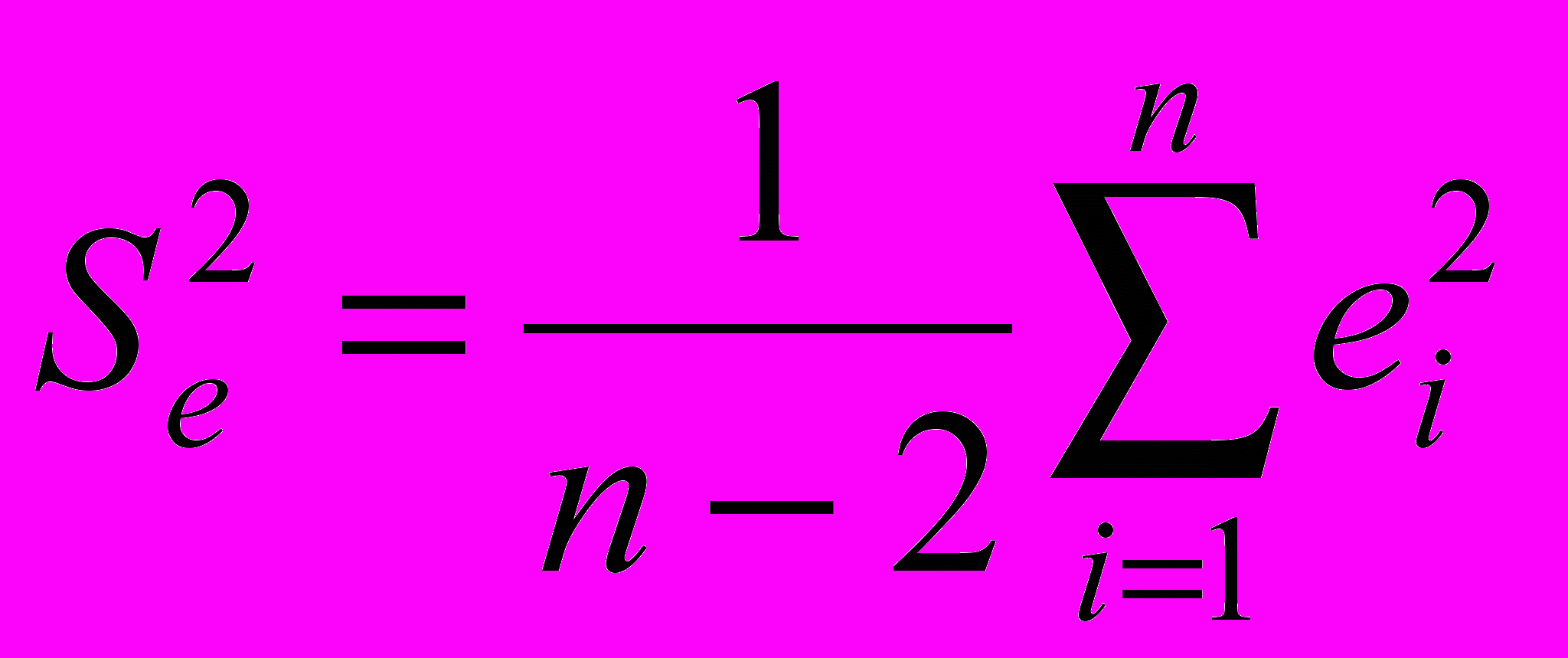 . (2.5.4)
. (2.5.4)Величину
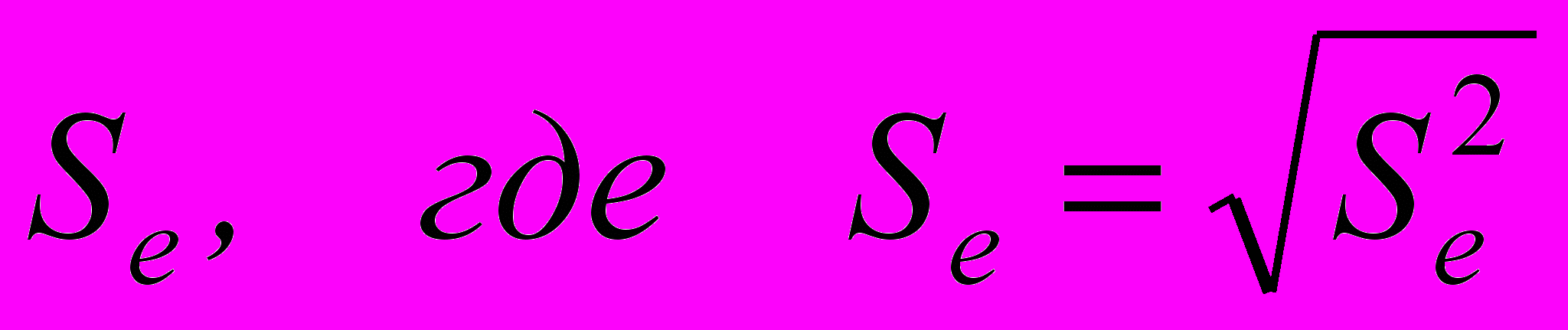
называют стандартной ошибкой.
Таким образом, неизвестные параметры функции линейной регрессии мы оценили при помощи МНК, а неизвестную дисперсию ошибок модели мы оценили по формуле (2.5.4). Как уже отмечалось, найденные оценки параметров в1 и в0 являются случайными величинами. Свойства этих оценок мы обсудим в следующем параграфе, здесь приведем только выражение для оценки дисперсии в1
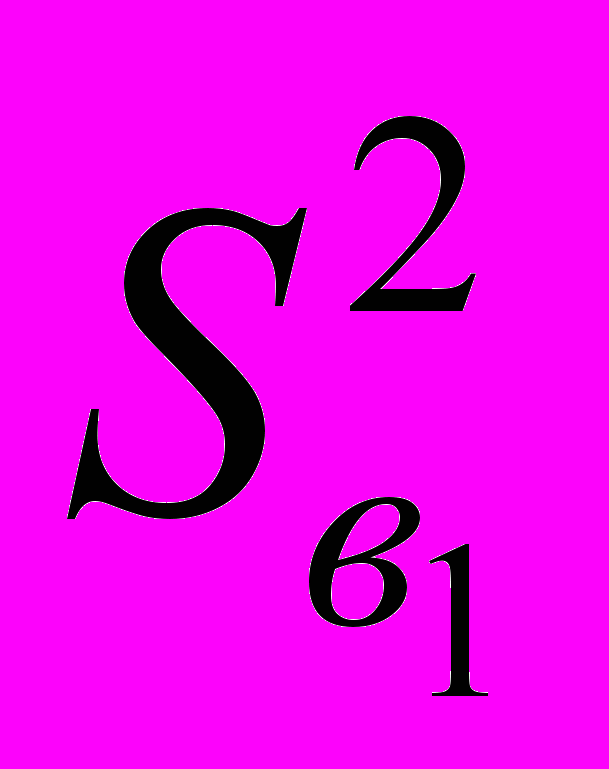 :
: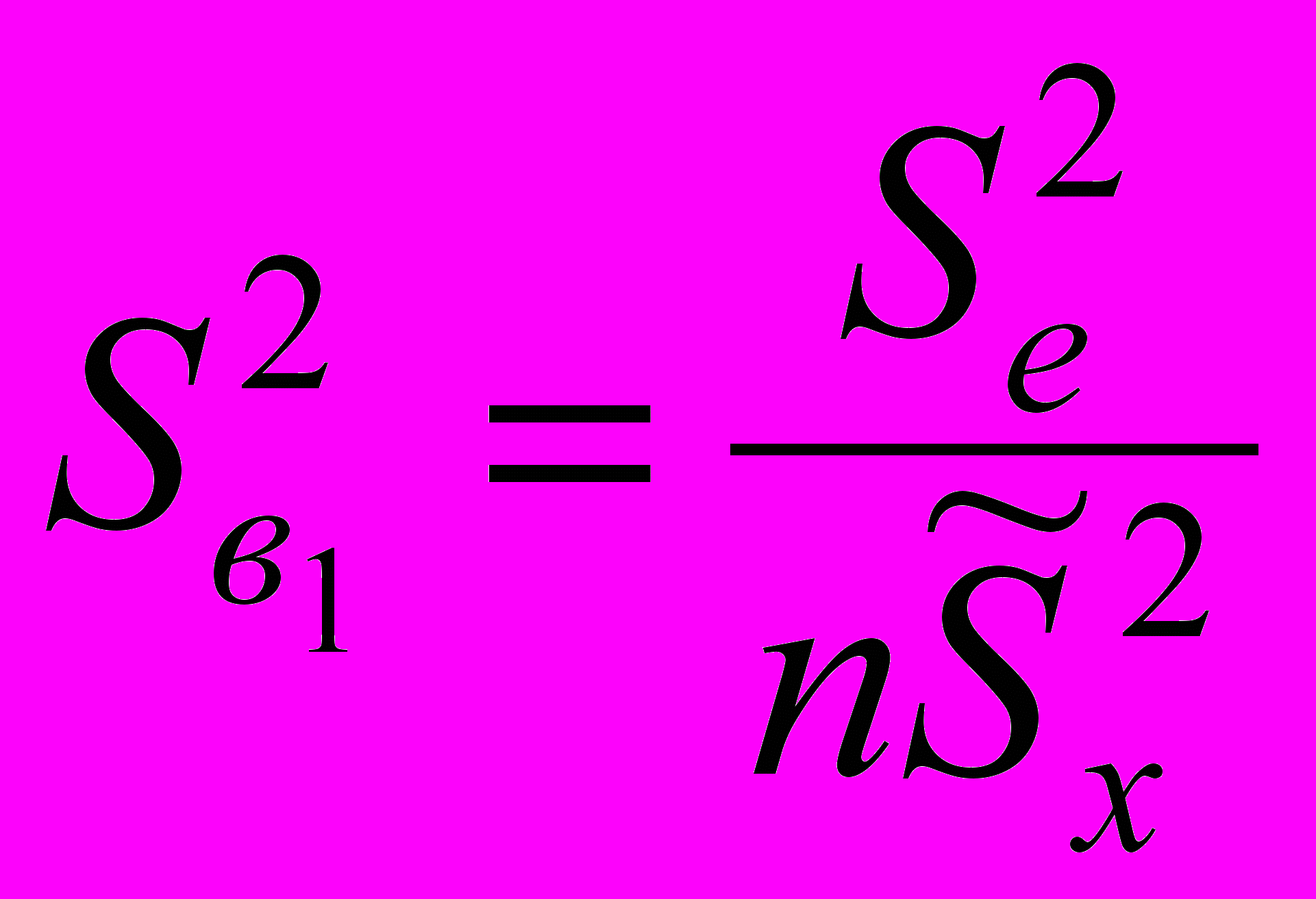 . (2.5.5)
. (2.5.5)Стандартная ошибка оценки в1 будет равна:
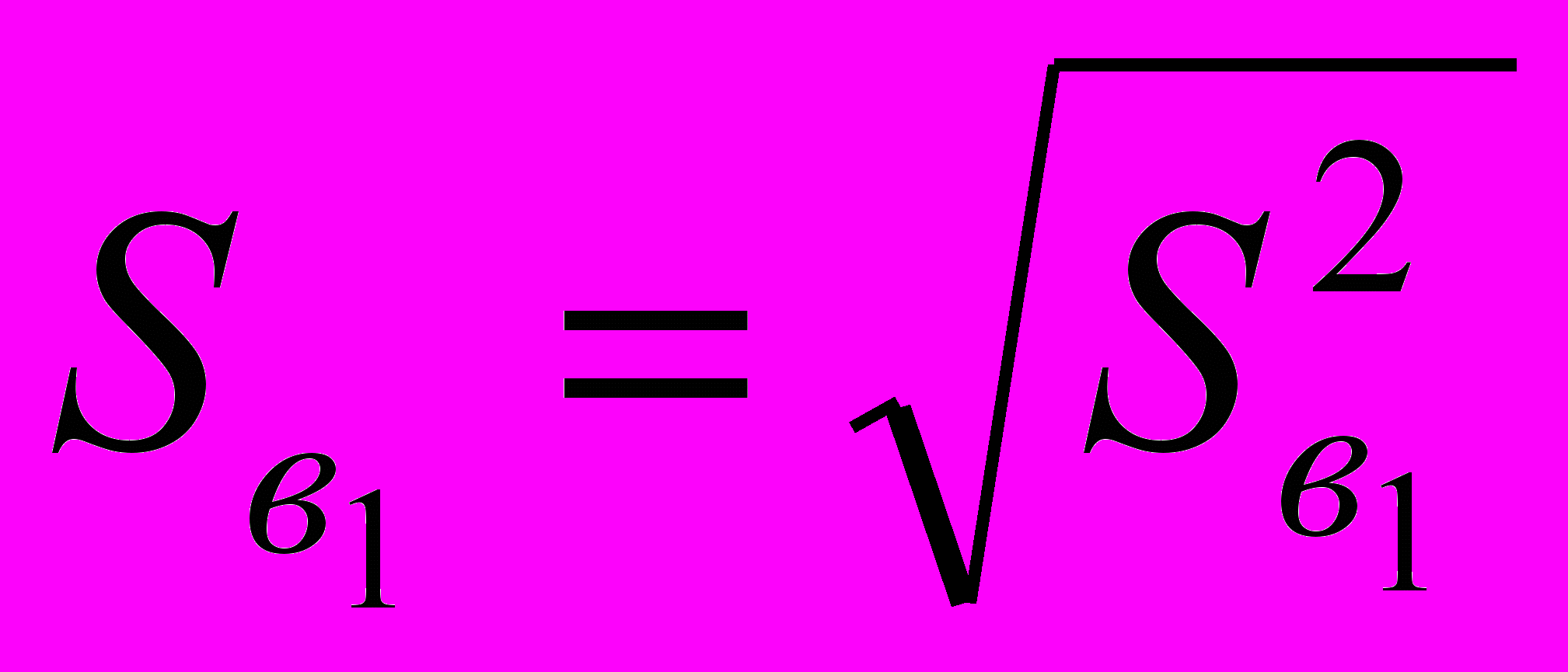 .
.Теперь перейдем к рассмотрению статистической проверке гипотезы о линейности функции регрессии. Согласно выбранной модели зависимость переменных х и у имеет вид:
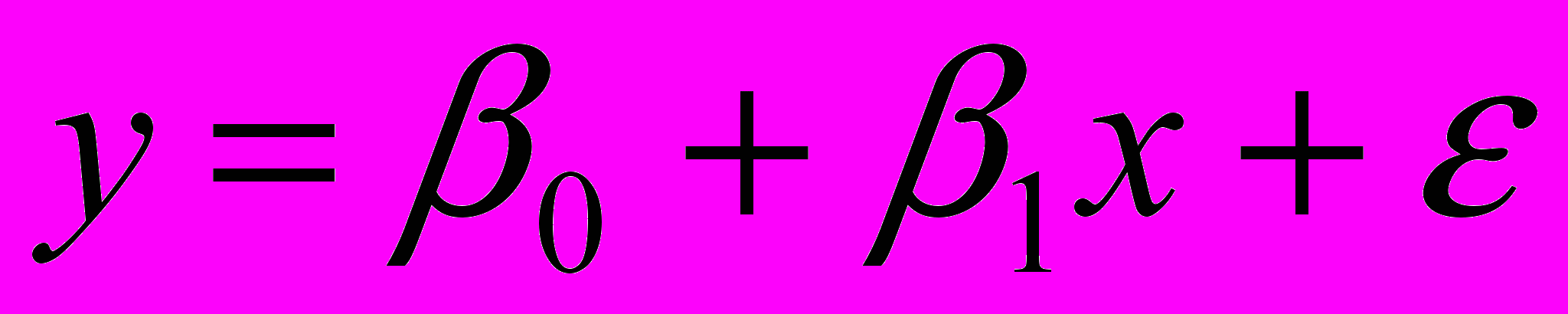 .
.Если коэффициент b1 перед переменной x будет равен нулю, то переменные x и y будут независимы или зависимость y от x будет нелинейной. Поэтому сформулируем основную гипотезу следующим образом:
H0:
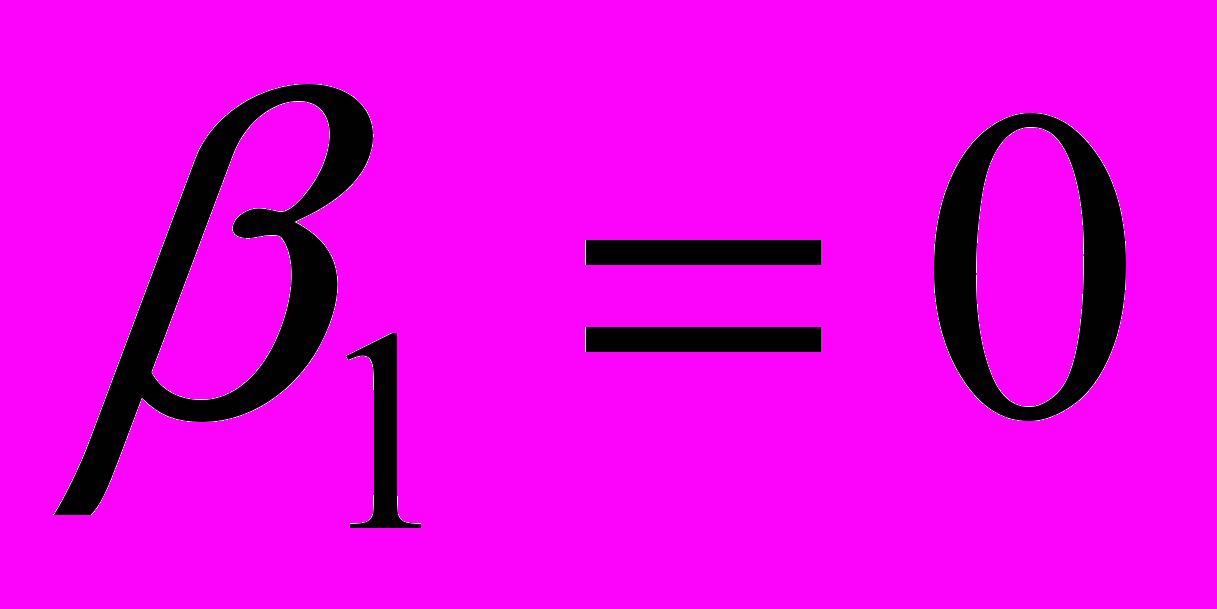
и альтернативную гипотезу Hа:
Hа:
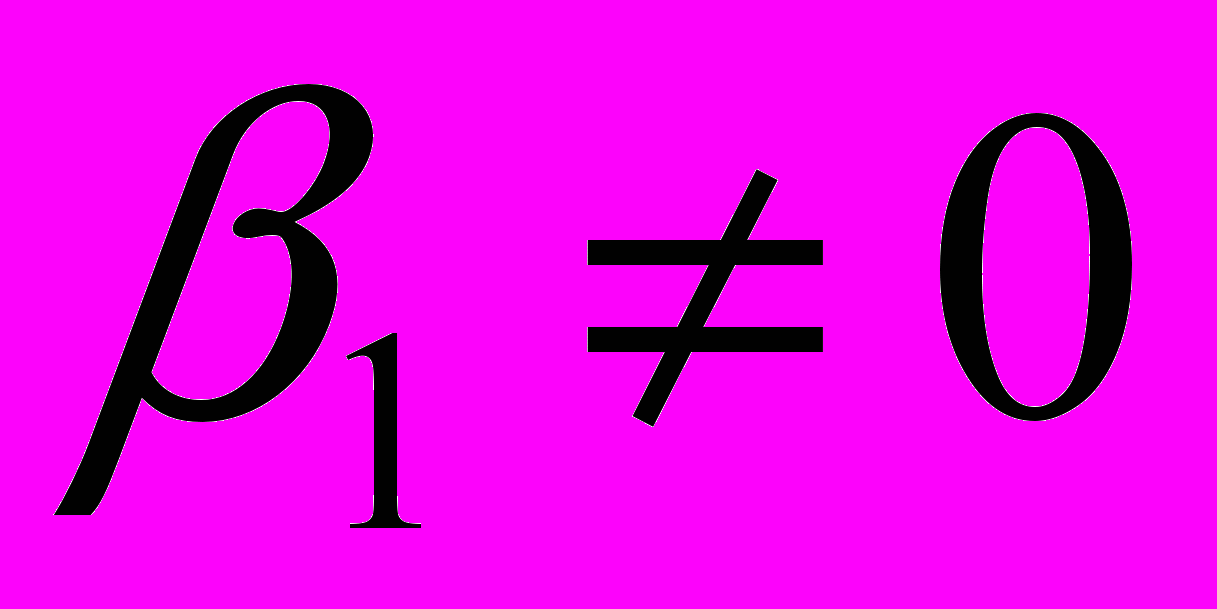 .
.Рассмотрим вспомогательную случайную величину вида:
Z*=
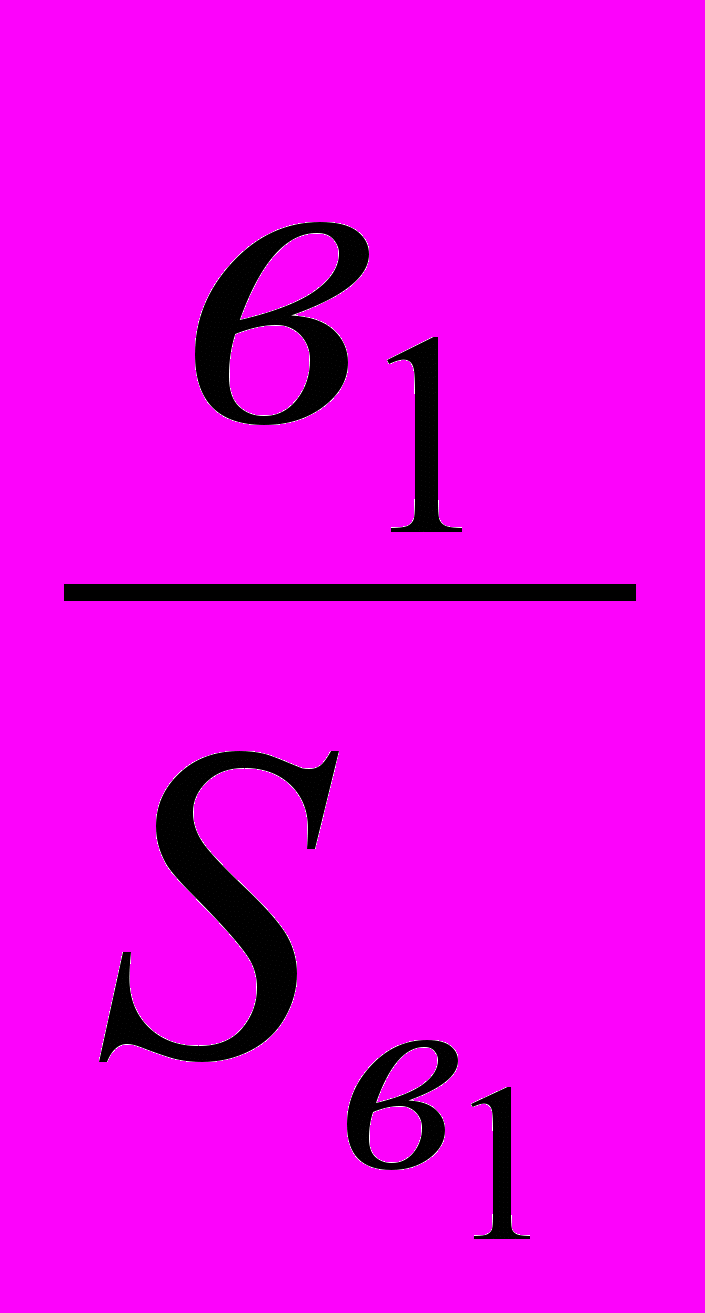 . (2.5.6)
. (2.5.6)Если основная гипотеза верна, то случайная величина (2.5.6) будет распределена по закону Стьюдента с (n-2) степенями свободы. По таблицам распределения Стьюдента, по заданному уровню значимости и (n-2) степеням свободы, находим границу двусторонней критической области К2, К1= - К2. Если выполняется одно из неравенств Z*£ К1 или Z* ³ К2, основную гипотезу отвергаем, принимаем альтернативную. В этом случае говорим, что у нас есть основание считать, что предположение о том, что регрессионная модель является линейной, не обосновано. Когда выборочная статистика удовлетворяет неравенству
К1 < Z* <К2,
принимаем основную гипотезу и делаем вывод, что у нас нет оснований считать, что у зависит от х линейно, либо делаем вывод, что зависимость может носить нелинейный характер.
^ При альтернативных гипотезах вида: вид Hа:
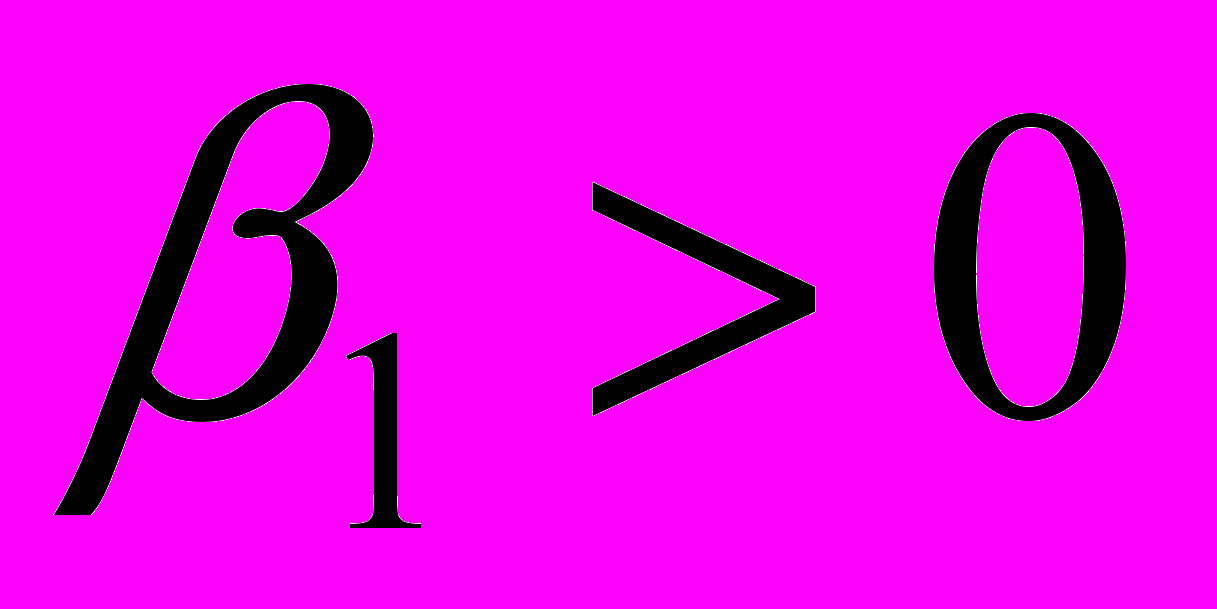 или Hа:
или Hа: 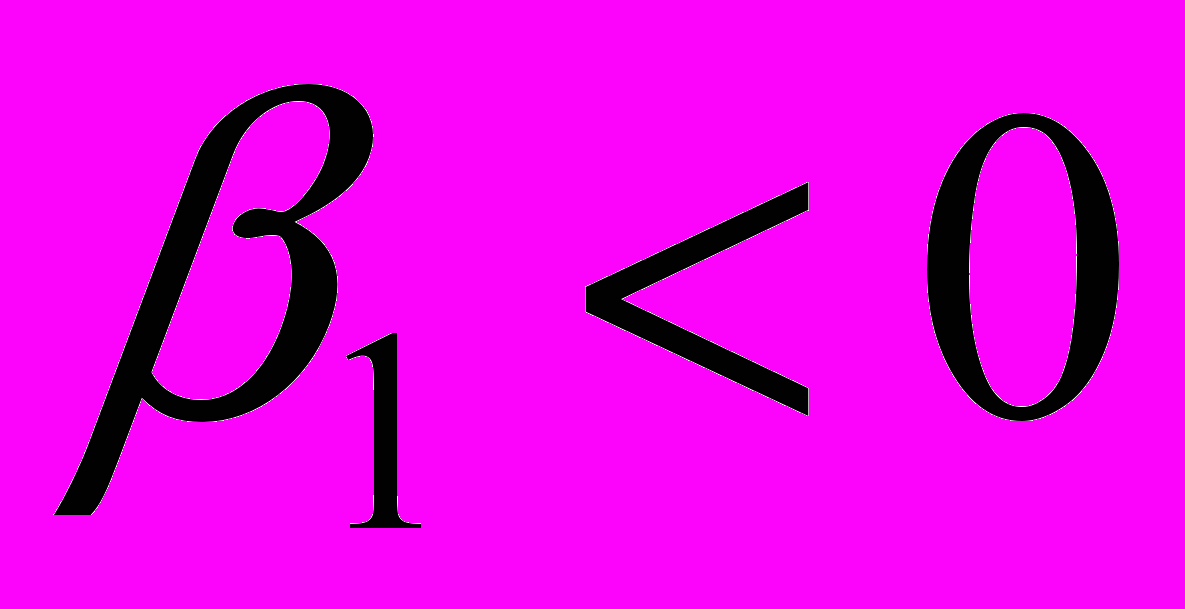 , критическая область будет правосторонней и левосторонней соответственно.
, критическая область будет правосторонней и левосторонней соответственно.Как уже отмечалось, коэффициент детерминации может быть рассмотрен как один из показателей качества модели парной линейной регрессии. Поэтому для проверки адекватности модели парной линейной регрессии эмпирическим данным можно проверить гипотезу о равенстве нулю теоретического коэффициента детерминации:
H0:
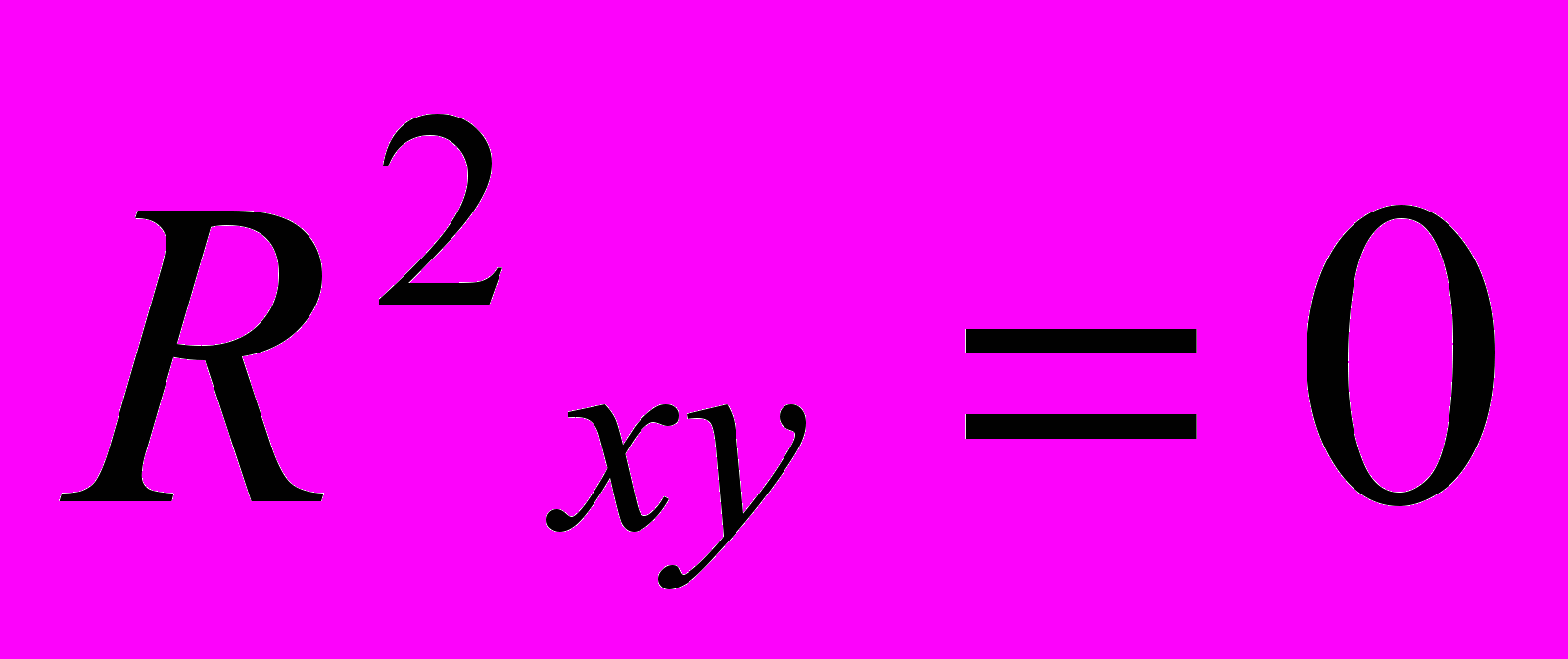 ,
,Hа:
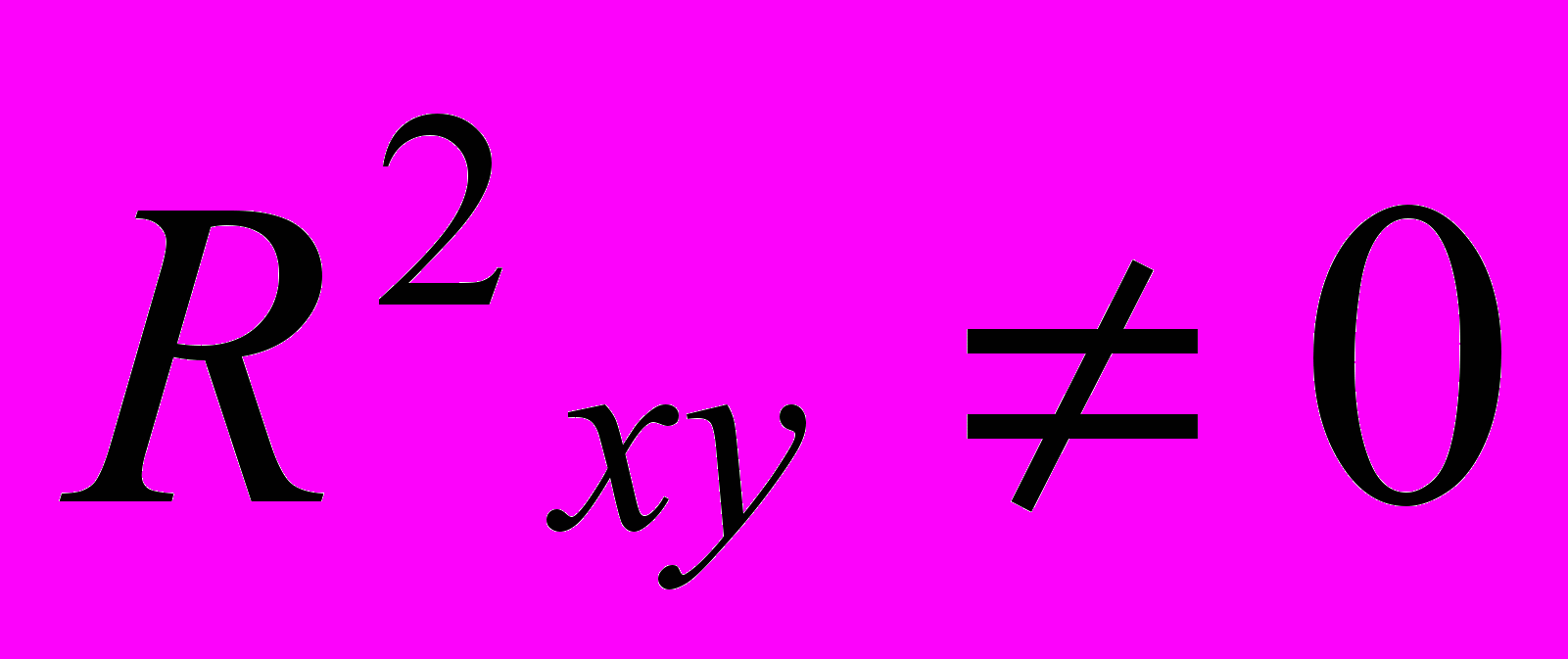 .
.Используя выборочный коэффициент детерминации
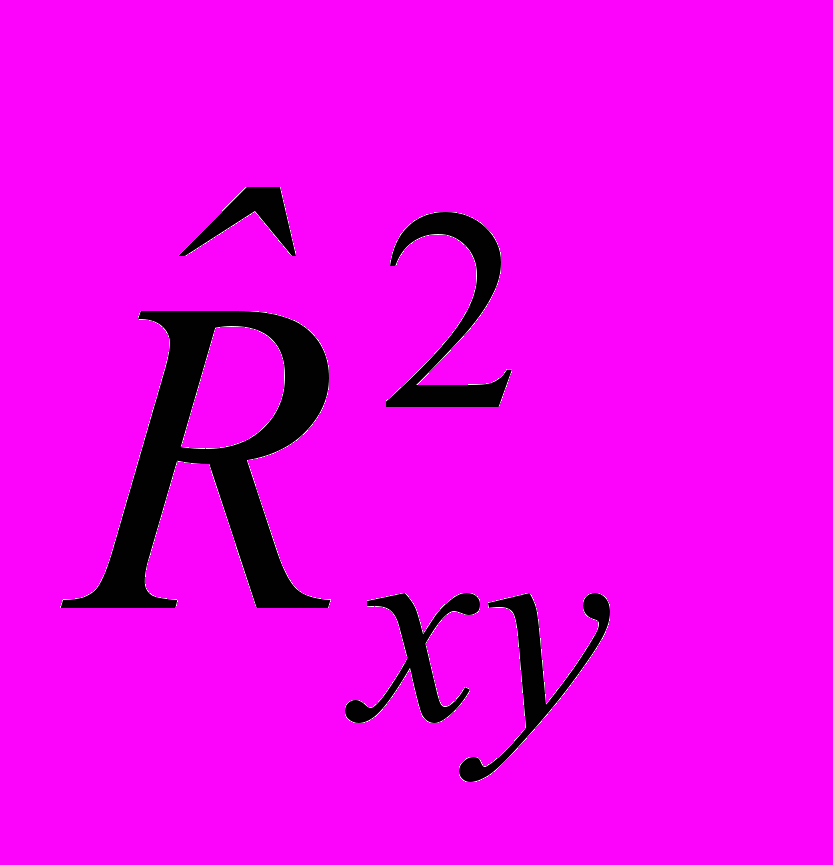 , вычисляем выборочную статистику Z* вида:
, вычисляем выборочную статистику Z* вида: Z* =
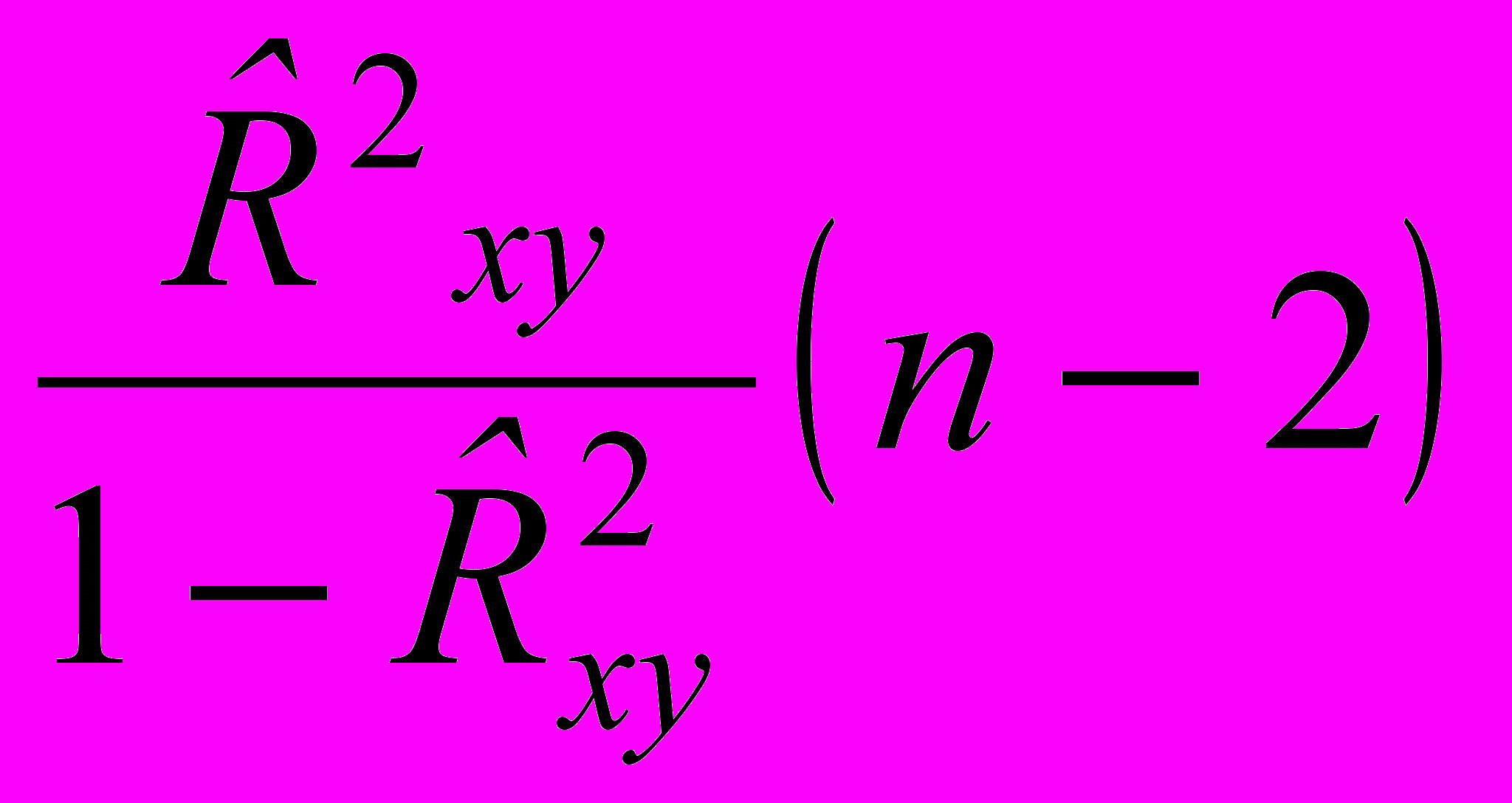 . (2.5.7)
. (2.5.7)Если основное предположение о равенстве нулю коэффициента детерминации верно и изменение у никак не связано с изменчивостью функции регрессии у от х, то случайная величина (2.5.7) будет распределена по закону Фишера с n1= 1, n2=(n-2) степенями свободы (ее называют F-статистикой).
Несмотря на вид сформулированной альтернативной гипотезы, критическая область будет правосторонней. Границу критической области ищут по уровню значимости (1-a) и n1= 1, n2= (n-2) степеням свободы.
Если 0£ Z*
Если Z* ³ K2, то основная гипотеза отвергается, и мы соглашаемся (наше «согласие» носит вероятностный характер!) с предположением о том, что модель парной линейной регрессии адекватна эмпирическим данным.
Замечание 3. При проведении проверки гипотез для нахождения границ критической области в EXCEL можно воспользоваться встроенными функциями категории «Статистические». В том случае, когда выборочная статистика распределена по закону Стьюдента и критическая область двусторонняя, чтобы найти значение К2, нужно обратиться к функции «СТЬЮДРАСПОБР». Эта функция возвращает искомое значение К2 по двум входным параметрам: указанной вероятности и известному числу степеней свободы. Например, пусть 1-α =0,05, объем выборки n=50, тогда число степеней свободы (n-2) =48. Значение К2, используемое при проверке гипотезы будет равно:
К2 = СТЬЮДРАСПОБР(0,05; 48)= 2,010635.
Поиск границы критической области при проверке гипотезы по критерию Фишера предполагает использование функции «FРАСПОБР». Для того, чтобы найти К2 – границу правосторонней критической области, при работе с этой функцией нужно ввести три параметра, например
К2 = FРАСПОБР(0,05; 1;48)= 4,042652.▲