
Темы, которые мы обсуждали на предыдущей лекции: Прообраз=(Тадж Махал)=Неизвестный параметр
| Вид материала | Лекции |
Содержание2.1 Модель линейной регрессии 4. Случайные величины В силу второго предположения Требование постоянства дисперсии случайных величин Так как случайные величины |
- Индия: тадж махал, слоны и тигры, 205.65kb.
- Москва, ул. Полковая, д. 1, стр., 83.26kb.
- Муниципальное общеобразовательное учреждение, 380.61kb.
- Тел. 048-784-12-14(15,16), 62.43kb.
- Лекция Темы обсуждений предыдущей лекции, 112.29kb.
- Архитектуру называют "застывшей музыкой". Наверное, мы не ошибемся, если дополним,, 6476.86kb.
- Программа тура: Вылет из Москвы в 18: 50 из аэропорта Шереметьево-F, регулярный рейс, 117.92kb.
- Программа тура Вылет регулярным рейсом su-535 Москва Дели авиакомпании «Аэрофлот», 192.44kb.
- Урок истории в 6 классе, 18.18kb.
- Основы спектрального анализа звуков, 76.67kb.
ЛЕКЦИЯ 4.
Темы, которые мы обсуждали на предыдущей лекции:
1.Прообраз=(Тадж Махал)=Неизвестный параметр;
2.Образ=(Фотография)=Оценка параметра;
3.Интервальное оценивание (желание «подстраховать» полученную точечную оценку);
4. Проверка статистических гипотез (предположение вида:завтра будет хорошая погода не рассматриваем);
5. Первая попытка ответа на вопросы:
а) Зависит ли у от х?
б) Какого вида функция связывает эти переменные?
2 Парная линейная регрессия
^ 2.1 Модель линейной регрессии
Предположим, что у нас есть все основания считать, что два экономических показателя взаимосвязаны. Например, уровень инфляции и уровень безработицы в какой-либо стране или спрос на товар и цена товара, темп роста валового внутреннего продукта (ВВП) и доходность ценной бумаги.
В нашем распоряжении имеется набор данных, полученных в результате статистических наблюдений за интересующими нас показателями. Такие данные приводятся в различных периодических изданиях, журналах, газетах и бюллетенях и относятся ко всем сферам экономики.
Используя указанные эмпирические данные, мы хотим подобрать (если это возможно!) функцию, которая связывает эти экономические показатели. Безусловно, эта задача повлечет за собой целый ряд других задач (насколько хорошо мы подобрали функцию, значима или нет зависимость между показателями и т.д.), но пока рассмотрим подход к её решению.
Договоримся в дальнейшем зависимую (эндогенную) переменную обозначать через у, и называть результирующим признаком, а независимую (экзогенную) переменную через x и называть фактором. Тогда упорядоченный набор значений переменных (x; y) это двумерная выборка вида (1.1.7). Очень часто в литературе переменную х называют объясняющей переменной.
Пример 2.1.1. В качестве примера такой выборки рассмотрим следующую выборку значений темпа роста ВВП (переменная x) и доходности акций компании Widget (переменная y) [16]:
(5,7; 14,3), (6,4; 19,2), (7,9;23,4), (7;15,6), (5,1;9,2), (2,9; 13).
Эти же данные можно было бы записать в виде следующей таблицы:
-
Год
Темп роста ВВП(%)
Доходность акций компании Widget(%)
1
5,7
14,3
2
6,4
19,2
3
7,9
23,4
4
7
15,6
5
5,1
9,2
6
2,9
13
Или изобразить в виде точек на плоскости в ДСК
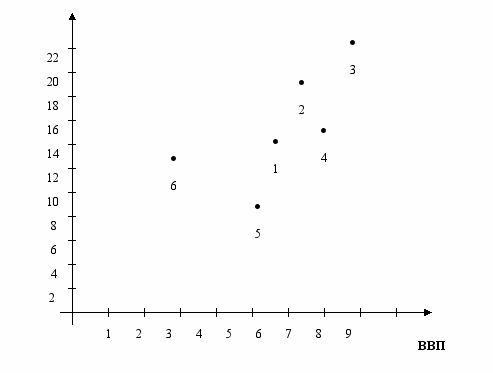
Характер расположения точек на рисунке, называемом корреляционным полем, подсказывает, что зависимость между переменными x и y близка к линейной, то есть
.
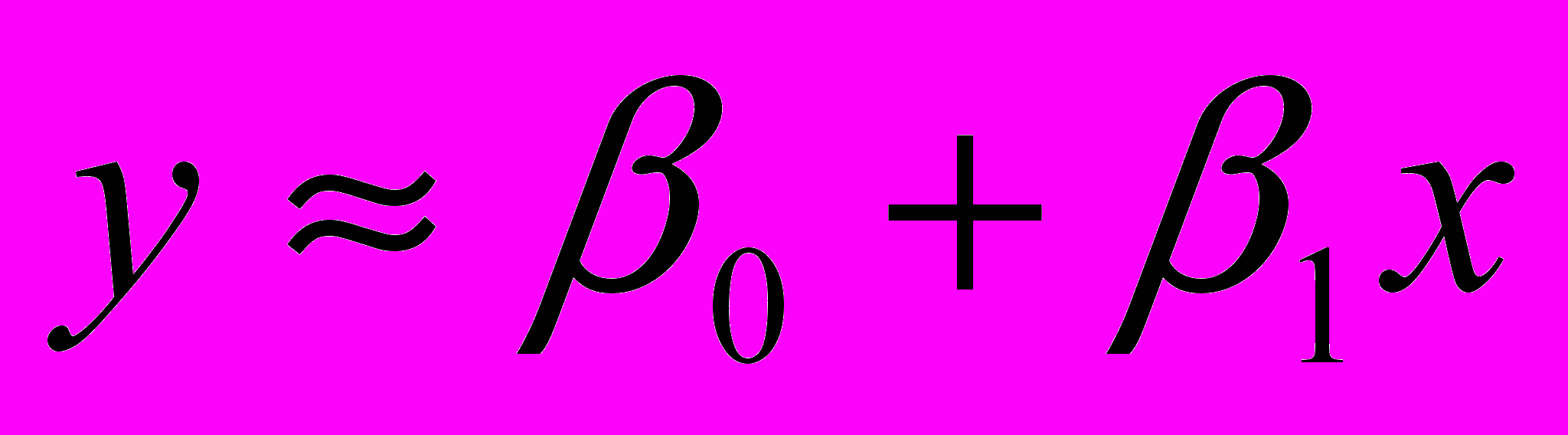
Или
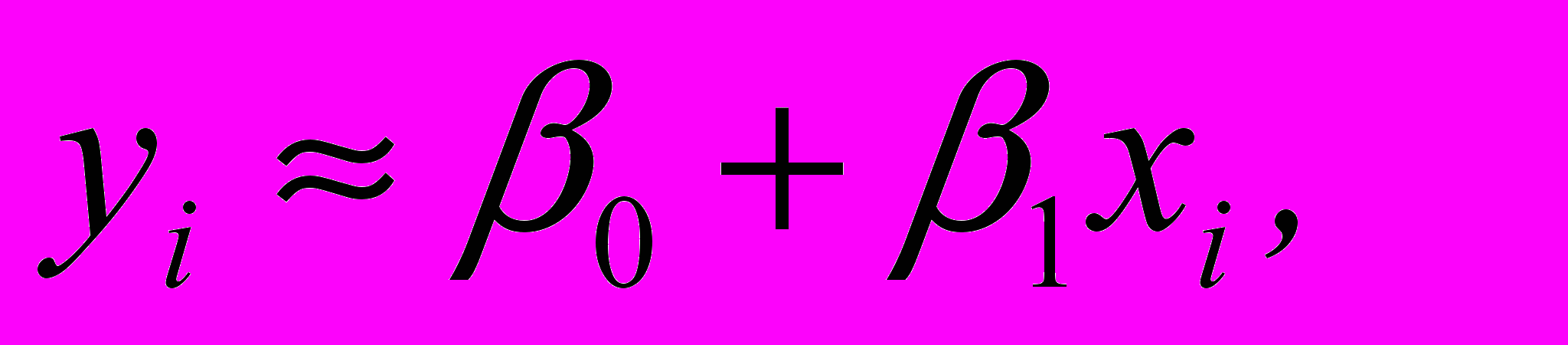 (2.1.1)
(2.1.1)Однако если зависимость между переменными была бы линейной, то все точки лежали бы на одной прямой, значит нужно внести коррективу. Включим в модель, которую мы пытаемся подобрать, ещё одну переменную, которую назовем ошибкой наблюдения (или неучтенными в модели факторами) и обозначим через .
Уравнение (2.1.1) перепишем в виде
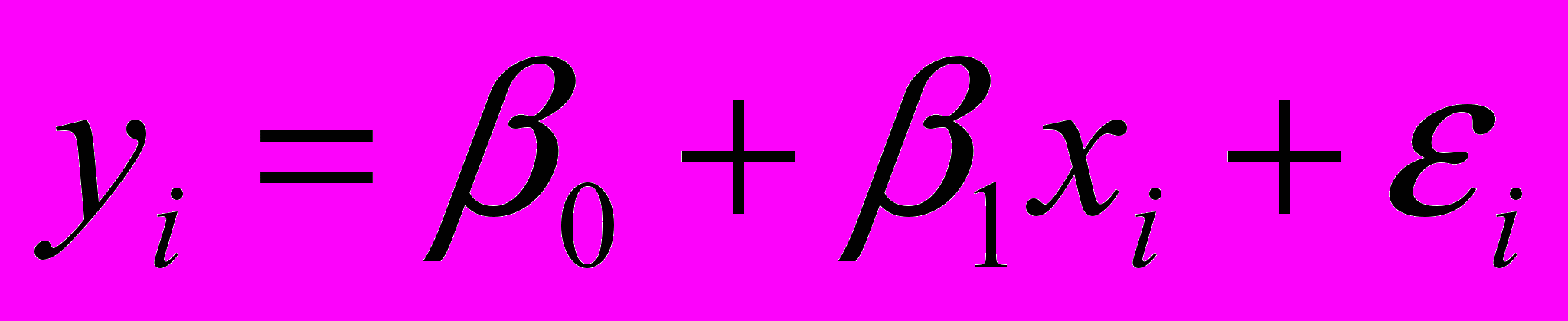 (2.1.2)
(2.1.2)Относительно переменных i сделаем следующие допущения. Будем считать, что:
- Ошибки наблюдения i являются случайными величинами, распределенными по нормальному закону.
- Математическое ожидание всех случайных величин i равно нулю:
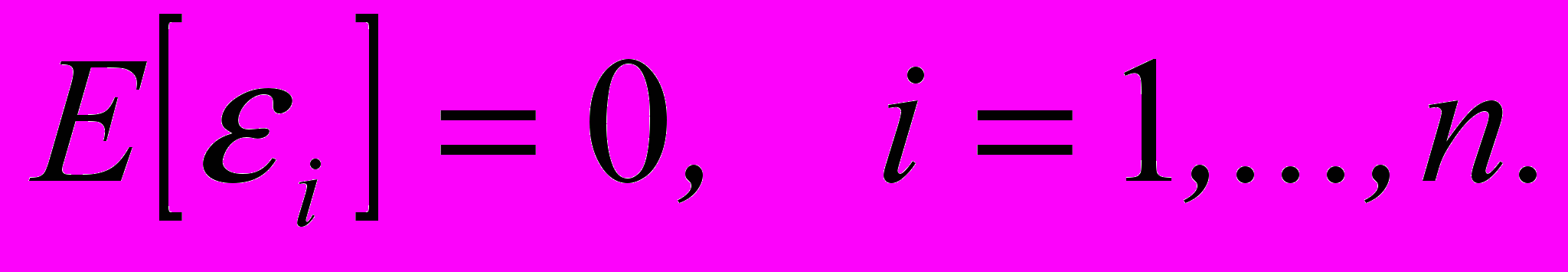
- Все ошибки наблюдения i имеют одинаковую (но неизвестную!) дисперсию:

^ 4. Случайные величины i и j, ij, предполагаются независимыми друг от друга.
Замечание 1. Известно, что выражение для момента корреляции двух случайных величин можно записать в виде:
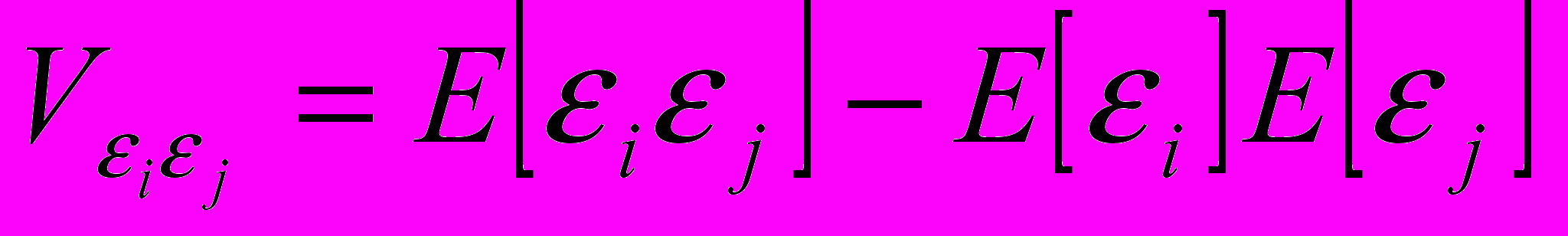 .
.Так как величины i и j по четвертому предположению независимы, то они и некоррелированные, то есть
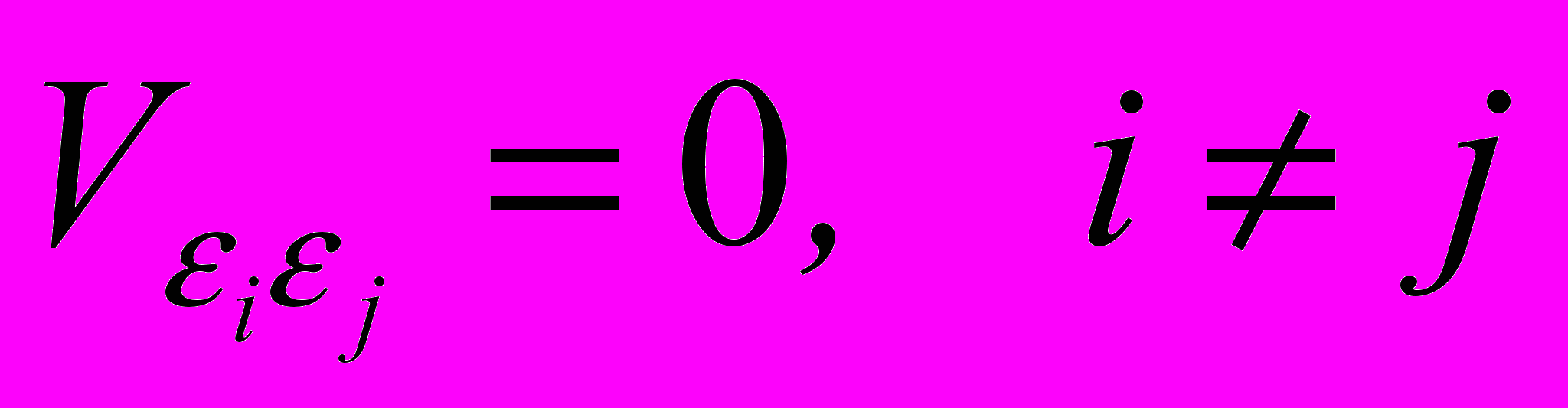 .
. ^ В силу второго предположения
Поэтому получаем, что
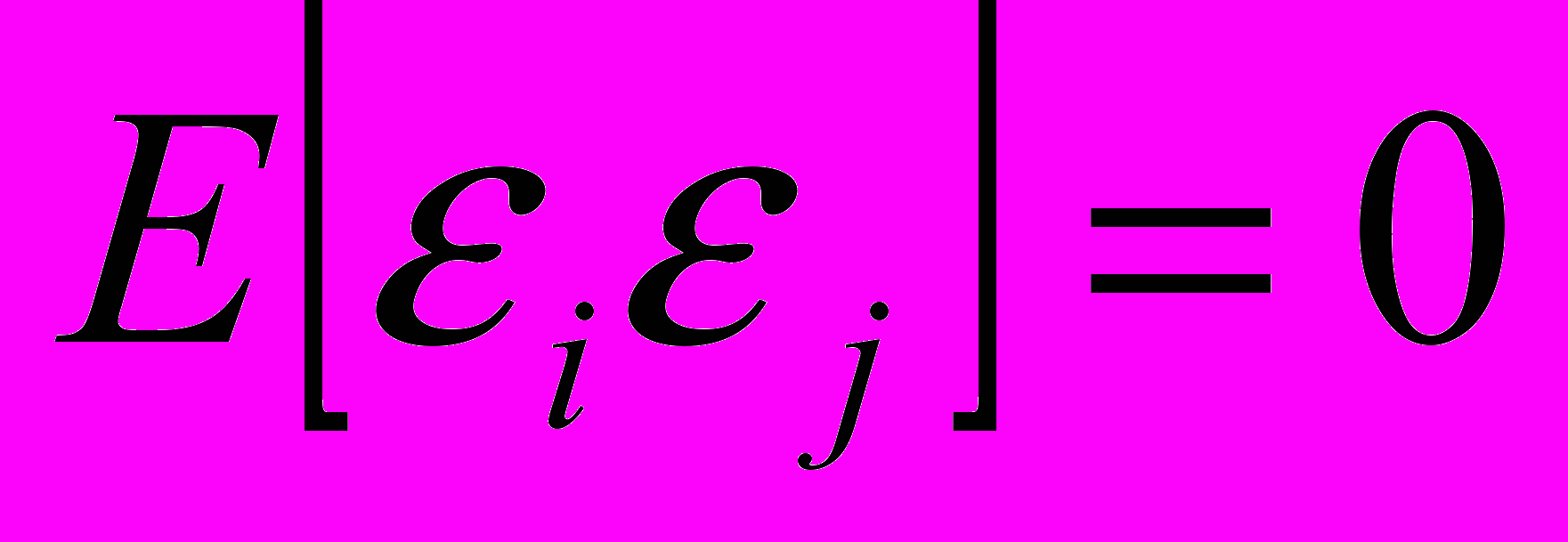 .
.Замечание 2. Относительно факторной переменной х будем рассматривать два предположения:
● переменная х носит детерминированный (неслучайный) характер;
● переменная х является случайной величиной.
Каждый раз будет оговорено, в рамках какого из двух предположений рассматривается изучаемая модель.
Определение 2.1.1. Условия 1-4 называются условиями Гаусса – Маркова.
Замечание 3. Вернемся к условиям Гаусса – Маркова и прокомментируем их. Предположение о том, что
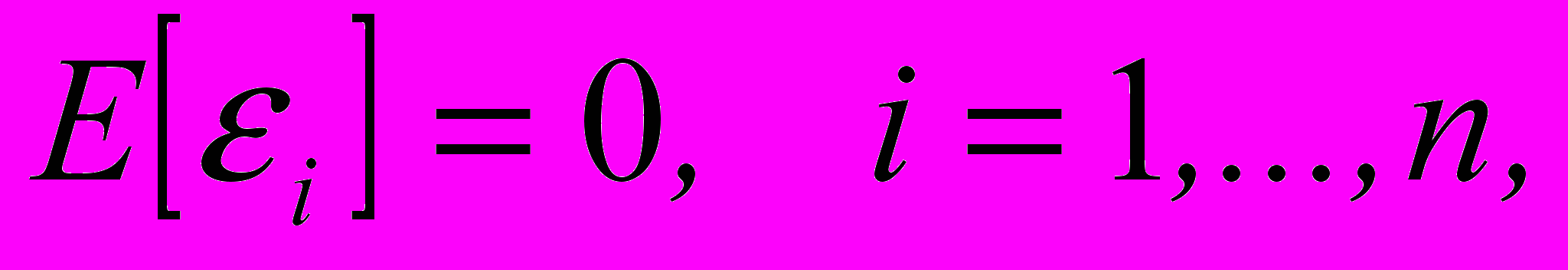
означает, что ошибки наблюдения поступают с разными знаками и компенсируют друг друга. То есть исключается ситуация, когда ошибки систематически появляются с одним и тем же знаком. Поэтому в случае, когда
, говорят, что систематическая ошибка равна нулю.^ Требование постоянства дисперсии случайных величин I говорит о том, что все наблюдения производятся с равной точностью. Поэтому в русскоязычной литературе говорят, что имеет место равноточная схема наблюдений. В англоязычной литературе предположение о том, что имеет место равенство,
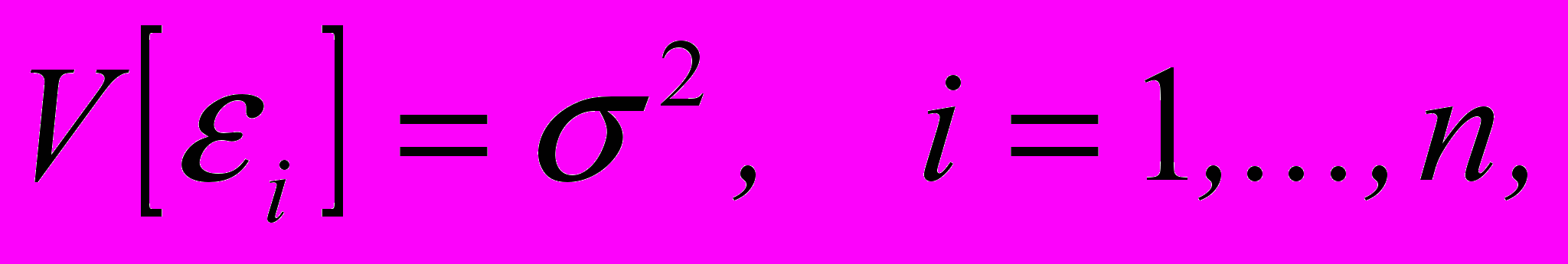 называют условием гомоскедастичности (homoscedasticity). Если
называют условием гомоскедастичности (homoscedasticity). Если 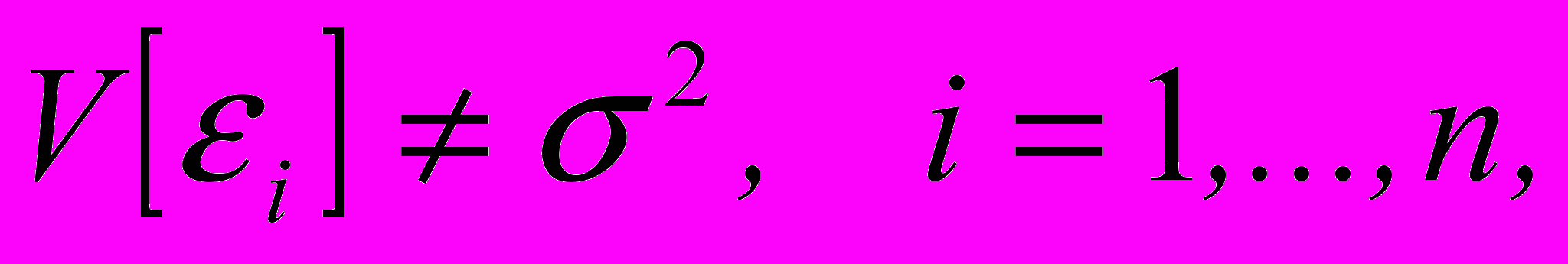
то говорят, что имеет место гетероскедастичность ошибок.
Условие независимости случайных величин i и j, ij, которое автоматически влечет за собой их некоррелированность, означает, что ошибка i-ого наблюдения не влияет на результат j-го.
Замечание 4. Вернемся к уравнению (2.1.2). В этом уравнении коэффициенты 0 и 1 являются неизвестными параметрами, которые подлежат нахождению.
В силу того, что переменные i в уравнении (2.1.2) являются случайными величинами, то и уi , которые связаны с ними функционально, будут носить случайный характер. Вычислим математическое ожидание и дисперсию уi, предполагая, что переменная х носит детерминированный характер:

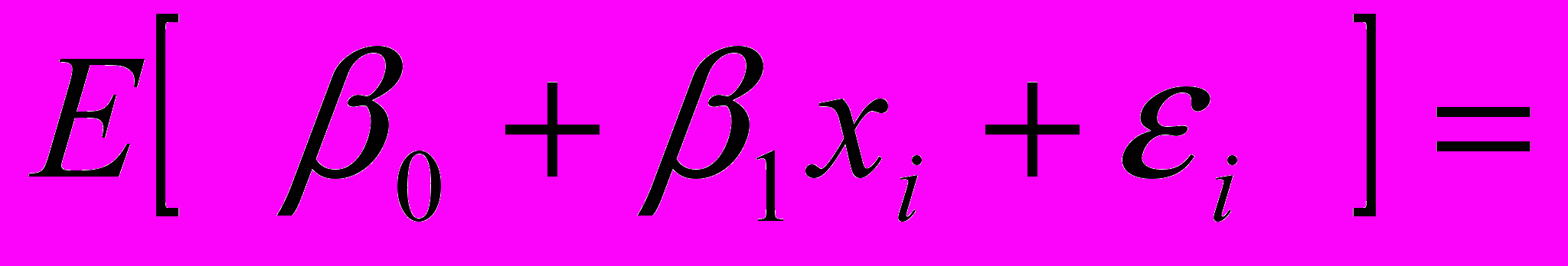
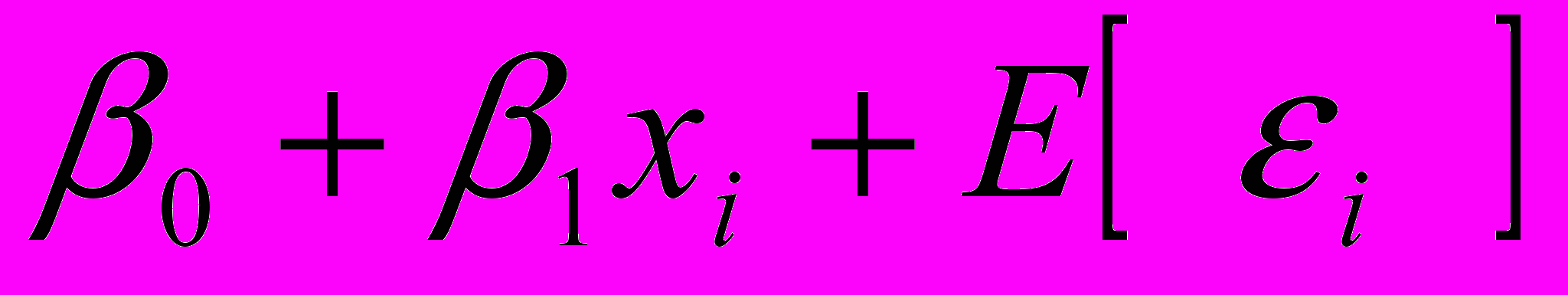
 ;
;

^ Так как случайные величины i распределены по нормальному закону, то по теореме о том, что линейное преобразование случайных величин, распределенных по нормальному закону, сохраняет закон распределения (изменяются только параметры распределения), можем сделать вывод: случайные величины уi распределены по нормальному закону распределения с математическим ожиданием
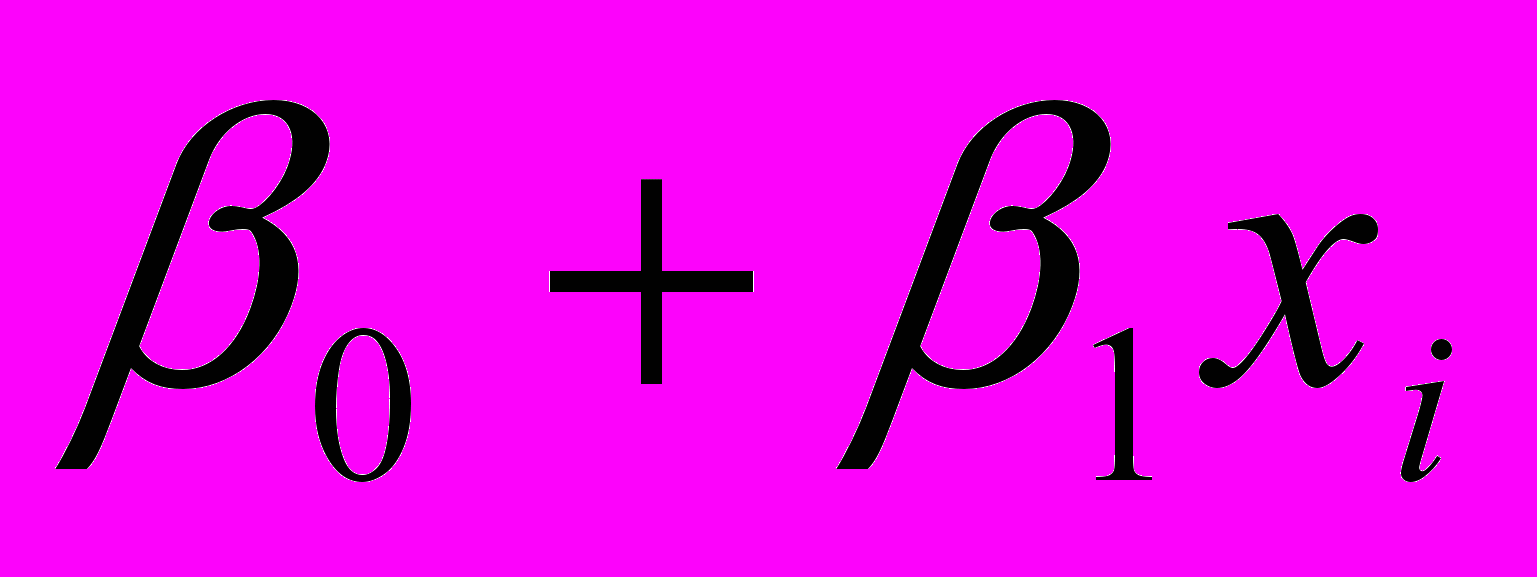 и одинаковыми дисперсиями 2.▲
и одинаковыми дисперсиями 2.▲Таким образом, математическое ожидание случайной величины уi будет зависеть от такого, какое значение примет переменная хi, (которая в общем случае также является случайной величиной), то есть будет являться условным математическим ожиданием.
Функция переменной х, задающая значение условного математического ожидания, называется функцией регрессии первого рода или модельной функцией регрессии. Так как в нашем распоряжении только информация эмпирического характера, то мы будем работать с функцией регрессии второго рода или, так называемой эмпирической функцией регрессии, служащей статистической оценкой модельной функцией регрессии.
Будем обозначать эмпирическую функцию регрессию
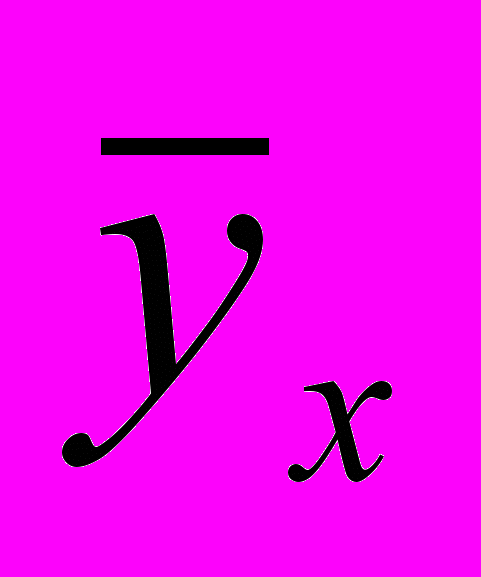 . Таким образом,
. Таким образом,  , (2.1.3)
, (2.1.3)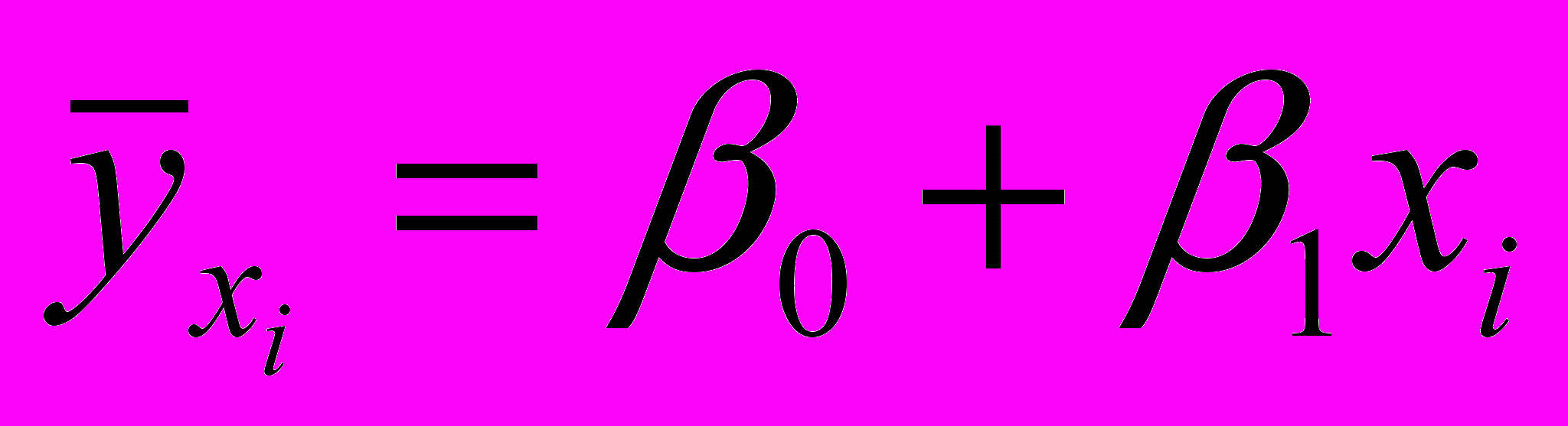
 (2.1.4)
(2.1.4)Эта функция показывает, как «в среднем» изменяются значения случайной величины у, в зависимости от того, какие значения примет х. График функции регрессии одной переменной называют линией регрессии.
Определение 2.1.2. Функция (2.1.3), задающая среднее значение переменной у, при условии, что независимая переменная х приняла фиксированное значение, называется функцией регрессии второго рода или эмпирической функцией регрессии.
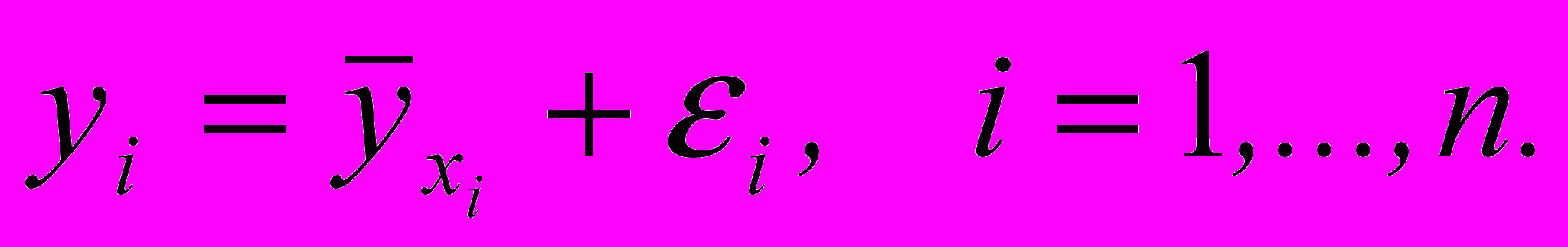 (2.1.6)
(2.1.6)Определение 2.1.3. Если выполняются условия Гаусса-Маркова и имеет место уравнение (2.1.5) (или (2.1.6)), то говорят, что задана классическая нормальная регрессионная модель.
Подводя итог, отметим, что когда мы говорим о регрессионной модели, то мы имеем в виду уравнение (2.1.5), когда речь идет о функции регрессии, то рассматривается уравнение (2.1.3). Регрессионная модель включает в себя функцию регрессии и неучтенные в модели факторы, носящие по предположению случайных характер.
- Оценивание параметров функции регрессии
В эконометрике приходится сталкиваться с двумя ситуациями. Уже имеющаяся математическая модель, построенная, исходя из тех или иных экономических предпосылок, проверяется эконометрическими методами на ее соответствие новым экономическим условиям. Иными словами, известная экономическая модель проверяется на «правильность». Еще одна ситуация, с которой приходится встречаться, заключается в том, что необходимо построить саму модель, то есть, подобрать функцию, которая аппроксимирует зависимость между теми или иными показателями. Такая попытка построения модели была предпринята нами в примере 2.1.1. Однако, даже после того, как сам вид модели задан, остается важная задача отыскания неизвестных параметров модели, или, выражаясь более корректно, оценивания параметров регрессионной модели. Существуют различные подходы и методы к решению задачи оценивания параметров. В этом параграфе рассмотрим метод поиска оценок неизвестных коэффициентов, называемый методом наименьших квадратов (МНК или OLS- ordinary least squares).