
Методы оптимизации энергопотребления в микроэлектронных системах
| Вид материала | Автореферат |
СодержаниеКраткое содержание работы |
- Решение задач глобальной оптимизации большой размерности на многопроцессорных комплексах, 143.77kb.
- Календарный план учебных занятий по дисциплине Компьютерный дизайн оптических наноструктур,, 39.38kb.
- Конспект лекций по Методам оптимизации для студентов, обучающихся по специальности, 41.05kb.
- Концепция системного подхода при проектировании сапр. Последовательный метод компоновки, 29.25kb.
- Учебной дисциплины «Методы оптимизации» для направления 010400. 62 «Прикладная математика, 40.12kb.
- Рабочая учебная программа по дисциплине «Методы оптимизации» Направление №230100 «Информатика, 129.28kb.
- Методы оптимизации запросов в реляционных системах, 453.81kb.
- Рабочая программа учебной дисциплины (модуля) методы оптимизации, 164.09kb.
- Алтайский Государственный Технический Университет им. И. И. Ползунова памятка, 129.3kb.
- Программа дисциплины " методы оптимизации " Направление, 59.57kb.
КРАТКОЕ СОДЕРЖАНИЕ РАБОТЫ
Во введении обоснована актуальность темы, сформулированы цель и задачи исследования, определены методы исследования, выделены научная новизна, основные защищаемые положения, приведены другие общие характеристики работы.
В первой главе приведена классификация источников рассеиваемой мощности и обзор методов снижения энергопотребления. Анализируются преимущества и недостатки существующих методов проектирования заказных СБИС с малым энергопотреблением.
В результате проведенного анализа существующих методов снижения энергопотребления были выбраны основные направления разработок и исследований, позволяющих повысить энергоэффективность на различных уровнях проектной иерархии микроэлектронных систем.
Асинхронная логика представляется одним из перспективных направлений развития цифровой микроэлектроники. В связи с этим основное внимание уделяется разработке эффективных методов, маршрутов и средств проектирования асинхронных цифровых систем.
Выбор асинхронных систем в качестве объекта исследования и разработки обусловлен несколькими факторами, влияющими на снижение энергопотребления:
I) Автоматическая остановка работы неиспользуемых компонентов.
Асинхронная система является полностью реактивной и представляет собой ансамбль коммуникационных процессов (модулей), которые находятся в неактивном состоянии до тех пор пока они не получат запрос информационное сообщение и данные для обработки. Существуют синхронные системы с возможность отключения тактового сигнала в отдельных блоках, однако они не достигают такого снижения энергопотребления как у асинхронных схем, поскольку определение моментов отключения блоков это сама по себе сложная задача, требующая дополнительных аппаратных ресурсов.
II) Автоматическое устранение паразитных переключений.
Потери энергии на нежелательные переключения в комбинационных синхронных схемах (например, арифметических блоках) могут достигать 30-40% от общей величины рассеиваемой мощности.
Сигналы, генерируемые в асинхронной схеме по определению являются корректными в любой момент времени и промежуточные неконтролируемые переключения недопустимы.
III) Отсутствие глобального тактирования.
В синхронных системах обеспечение глобального тактирования рассеивает до 50% общего уровня мощности. Напротив, в асинхронных системах глобальное тактирование заменено локальными сигналами взаимного подтверждения транзакций между соседними модулями. При этом, цена увеличения числа транзакций и аппаратных затрат не настолько высока, чтобы нивелировать эффект снижения потребляемой мощности. И этот эффект значителен.
IV) Изменение напряжения питания.
Асинхронные схемы (независимые от задержек) автоматически подстраивают скорость вычислений под сильно изменяющиеся операционные параметры, в частности, под напряжение питания.
Также, помимо описанных свойств, у асинхронных схем нет проблем с рассогласованием фронтов («гонок сигналов»). Асинхронные схемы позволяют разрабатывать системы нечувствительные к задержкам в цепях и нетребующие тщательной подгонки временных характеристик. Вкупе с этим легкость повторного использования делает применение асинхронные схем перспективным для различных технологий (с разными параметрами и проектными нормами).
Вторая глава посвящена разработке и исследованию методологии построения цифровых асинхронных компонентов систем-на-кристалле, включая схемотехнические основы создания асинхронных функциональных блоков, позволяющих снизить энергопотребление.
Проведен анализ работы асинхронных систем и особенностей протокольного взаимодействия. Разработано семейство методов схемотехнического построения асинхронных функциональных блоков для четырех различных способов реализации (динамической, статической основной, статической со «слабой» обратной связью и статической симметричной) для КМОП-технологии. В каждой схемотехнической реализации информационный сигнал является парафазным. Функциональные блоки, в отличие от метода минтермного синтеза, формируются не на основе пороговых элементов, а с помощью оптимизированных комбинаций транзисторных цепочек.
На Рис. 1. показаны типы реализации С-элементов, для которых разработаны методы схемотехнического построения.
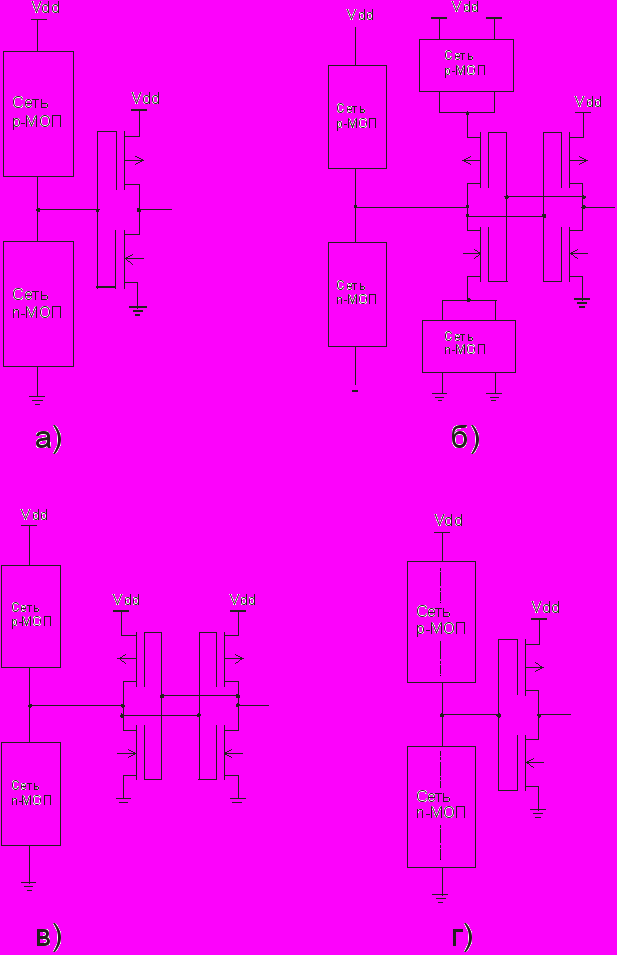
Рис. 1. Способы схемной реализации С-элементов: а) динамическая; б) статические основные; в) статические со «слабой» обратной связью; г) статические симметричные
Предлагается отдельно синтезировать схемы двух компонент формирования сигналов информационного выхода Q1 и Q0 (Рис. 2) на основе таблицы истинности, описывающей функцию блока. Асинхронные блоки, построенные по предложенному методу, могут иметь множество информационных входов и только один информационный выход.
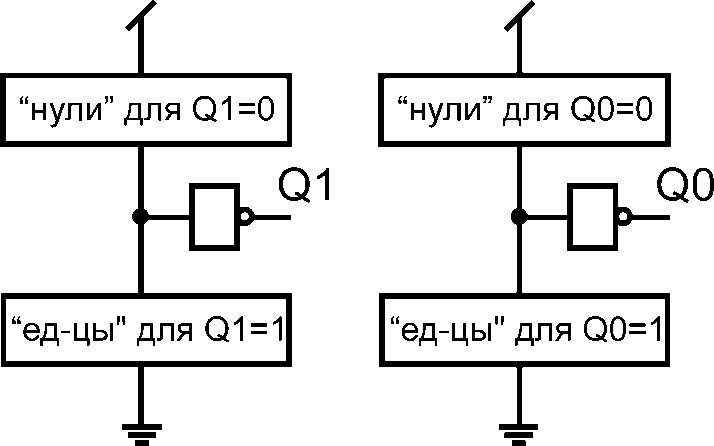 |
| Рис. 2. Структурная схема двухпроводных динамических асинхронных элементов |
Основные этапы методов построения схем функциональных блоков:
– на основе исходной таблицы истинности, описывающей тристабильные состояния информационных сигналов блока составляется расширенная таблица истинности с бистабильными состояниями пары выводов информационных сигналов;
– формируются цепочки последовательно соединенных p-канальных транзисторов, устанавливающих сигналы Q1 и Q0 в состояние 0. На данном этапе строятся части схемы с именами «нули» для Q1 = 0 и Q0 = 0. В последовательные цепочки включаются транзисторы, входы которых по расширенной таблице истинности находятся в состоянии 0 при нахождении Q1 и Q0 в состоянии 0. Далее последовательные цепочки транзисторов соответствующих компонент объединяются параллельно;
– составляются цепочки последовательно соединенных n-канальных транзисторов, устанавливающих сигналы Q1 и Q0 в состояние 1. На данном этапе строятся части схемы с именами «нули» для Q1 = 1 и Q0 = 1. В последовательные цепочки включаются транзисторы, входы которых по расширенной таблице истинности находятся в состоянии 1 при нахождении Q1 и Q0 в состоянии 1. Далее последовательные цепочки транзисторов соответствующих компонент объединяются параллельно;
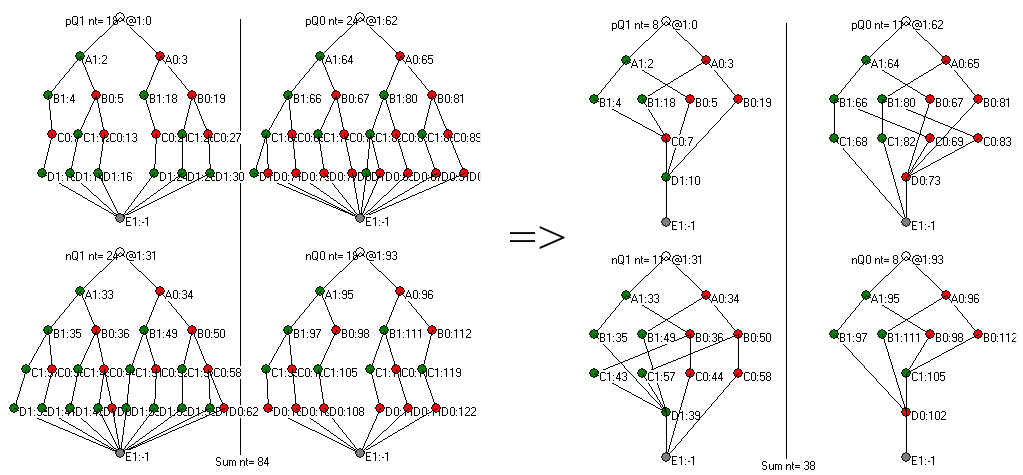
Рис. 3 Пример оптимизации транзисторных цепочек
– производится оптимизация полученных транзисторных цепочек, которые представляются соответствующим орграфом. Ребра орграфа направляются в одну выбранную сторону. Из графа, путем анализа путей из направленных ребер, удаляются петли и объединяются дублирующие друг друга узлы (см. Рис. 3).
Теоретически функциональный блок, сформированный подобным образом, может содержать любое количество входов. Но в схемах с большим числом транзисторов (больше 8), соединенных последовательно, сопротивление цепочек может оказаться значительным и существенно снижать энергоэффективность. Поэтому, при построении относительно больших схем, устанавливаются ограничения на допустимые величины паразитных параметров (емкости, сопротивления).
Произведена оценка логической сложности схем, создаваемых по предложенному методу, а также сравнительный анализ с результатами применения NCL-методов. Для получения адекватных оценок сравниваемые схемы рассматривались без учета оптимизации. Логическая сложность схем прошедших оптимизацию будет зависеть от выполняемых ими аналитических функций.
Для оценки быстродействия предложенных схем и схем на основе NCL-элементов было проведено схемотехническое SPICE-моделирование. При моделировании рассматривались типичные случаи для анализа разницы быстродействия логических схем.
Сделан вывод о том, что предлагаемые методы построения асинхронных блоков позволяют, по сравнению с традиционными методами проектирования на основе NCL-логики, сократить число используемых транзисторов (в среднем до 60%) и снизить энергопотребление. Анализ эффективности процедур оптимизации транзисторных цепочек показал, что при возрастании числа входов суммарное число транзисторов в блоке сокращается более чем вдвое (для 5 входов и более). Дана рекомендация о том, что построение асинхронных логических блоков с количеством входов больше 5-6 делать нецелесообразно из-за резко возрастающей их логической сложности и заметному влиянию паразитных параметров.
С учетом схемотехнических особенностей проектируемых асинхронных блоков, разработаны аналитические модели оценки энергопотребления и задержки сигналов для всех рассматриваемых типов реализации. Параметрами моделей являются ширины транзисторов анализируемого, управляющего и нагрузочного элементов, а также технологические и топологические параметры МОП-транзисторов. Оговорены границы применимости данных моделей.
Предложенные модели позволяют на основе введенного интегрального критерия относительно быстро и с приемлемой точностью оценить энергоэффективность проектируемых асинхронных КМОП-элементов без применения ресурсозатратного моделирования.
На Рис. 4 показана зависимость задержки динамического асинхронного элемента от ширины n-канальных транзисторов и их соотношения к ширине p-канальных (для длины канала 0,18 мкм).
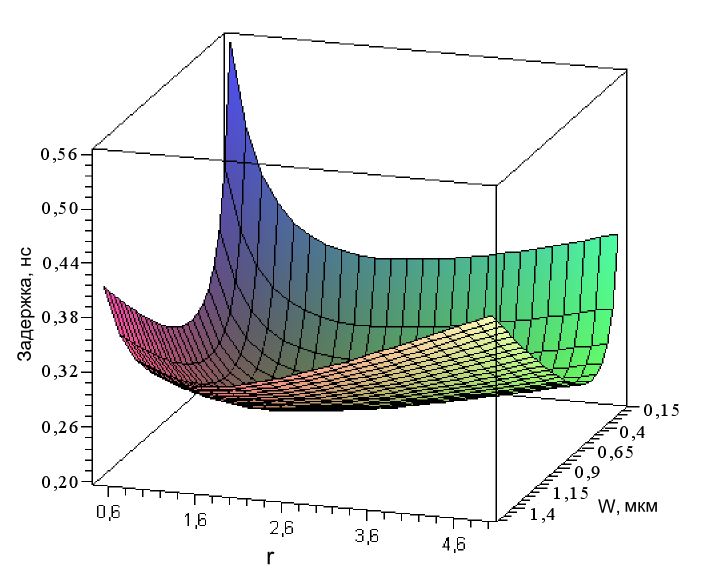
Рис. 4 Зависимость задержки динамического элемента от ширины n-канальных транзисторов и их соотношения к ширине p-канальных (r)
На основе введенных выражений для подсчета потребляемой энергии и задержек сигналов получен интегральный критерий энергоэффективности для динамического элемента:
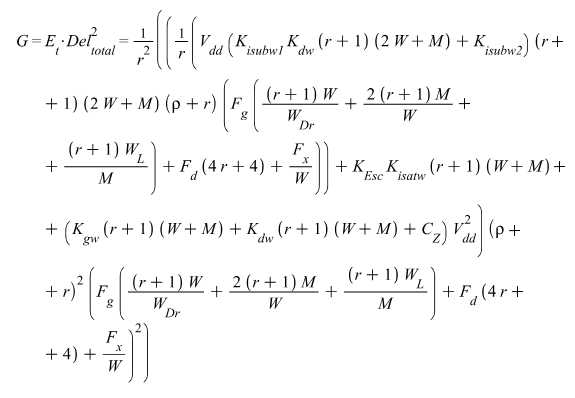
где Et – общая потребляемая энергия; Deltotal – общая задержка; r – отношение ширин каналов транзисторов; Vdd – напряжение питания; Kisubw1, Kdw, Kisubw2, KEsc, Kisatw, Kgw, Fg, Fd, Fx – введенные коэффициенты; W ширина канала n-МОП транзистора; M ширина канала n-МОП транзистора в буферной части; WDr,WL ширины каналов n-МОП транзисторов в управляющем и нагрузочном элементах; CZ удельная емкость диффузионных областей; соотношение, определяемое следующим образом:
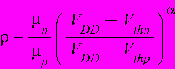 ,
,где α - коэффициент, равный 2 для длинных каналов и приблизительно 1,25 – для короткоканальных транзисторов; Vthn, Vthp – пороговые напряжения n- и p-канальных транзисторов соответственно; µn, µp – подвижности носителей заряда n- и p-типа соответственно.
На Рис. 5 приведены зависимости задержки D, потребляемой энергии E и значения интегрального критерия G от ширины канала n-МОП транзисторов в динамическом элементе.
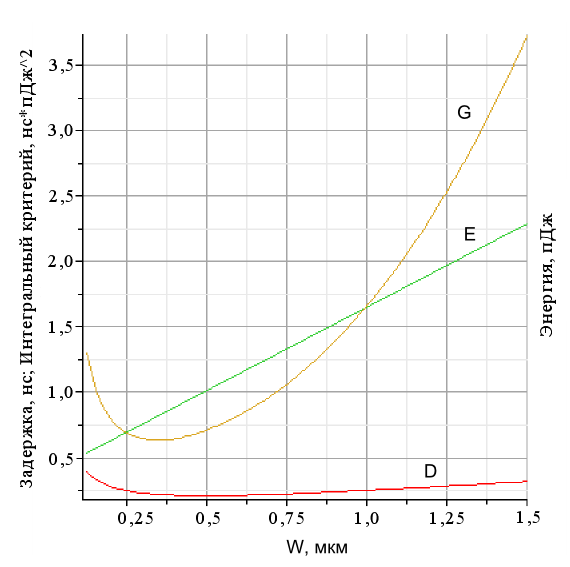 |
| Рис. 5 Параметры динамического элемента |
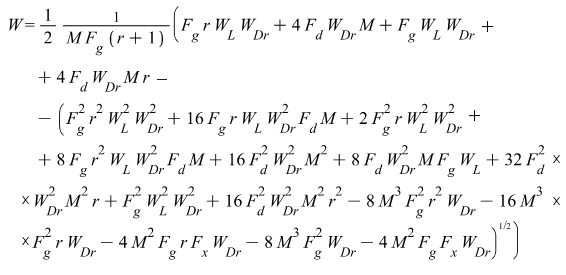 .
.Подобные выражения получены для всех 4-х реализаций асинхронных элементов.
Проведенный с помощью разработанных моделей анализ параметров различных КМОП-реализаций асинхронных блоков показал, что динамическая реализация обладает наилучшей энергоэффективностью, однако область ее применения ограничена заданными режимами работы схем. На Рис. 6 показаны зависимости интегральных критериев от ширины транзисторов для различных реализаций асинхронных элементов.
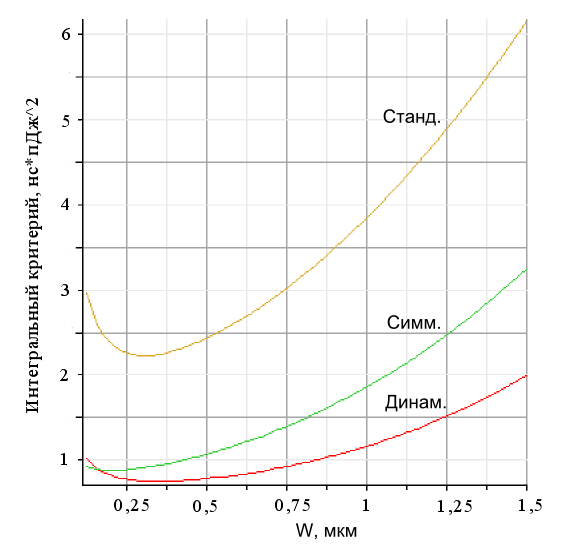
Рис. 6 Интегральные критерии трех реализаций
На основе анализа результатов, полученных с помощью разработанных моделей и контрольного SPICE-моделирования (на моделях 5-го уровня) показано, что расхождение между ними составляет не более 8%. Качественная оценка полученных зависимостей производилась на основе типичных параметров технологий КМОП 0,18 мкм и 0,8 мкм. Также, предлагаемые модели пригодны для использования при КМОП-технологиях с меньшими топологическими размерами вплоть до проявления квантовых эффектов.
В третьей главе предлагаются методы снижения энергопотребления в цифровых устройствах на архитектурном уровне.
Разработан метод снижения энергопотребления в цифровых системах-на-кристалле за счет минимизации объемов необходимой оперативной статической памяти.
На первом этапе метода производится анализ реализуемого алгоритма и выявляются циклы и контейнеры для промежуточного хранения данных.
На втором этапе определяются возможности замены контейнеров промежуточного хранения данных на схемы, вычисляющие и выдающие результат к необходимому моменту времени. В большинстве случаев это целесообразно делать, т.к. энергозатраты на обращение к большому массиву памяти оказываются выше, чем на расчет нужных (производных промежуточных) данных.
На заключительном этапе метода производится формирование тел циклов в аппаратном виде, а управление их итерациями – в программном.
В качестве иллюстрации и с целью анализа эффективности разработанного метода показана минимизация энергопотребления асинхронной системы, реализующей алгоритм турбодекодирования. Энергопотребление процесса турбодекодирования является одним из важнейших факторов при разработке носимых портативных коммуникационных устройств, работающих, например, по одному из популярных стандартов передачи данных, таких как: W-CDMA (3GPP), CDMA2000 (3GPP2), UMTS/сети 3G, B3G/4G, DVB-RCS, IEEE 802.16/WiMAX, IEEE 802.11n.
Предлагается асинхронная архитектура последовательного турбодекодера (по алгоритму максимума апостериорной вероятности - MAP), которая позволяет значительно снизить уровень мощности, потребляемой при итеративном декодировании информационных сигналов (Рис. 7). Снижение энергопотребления происходит за счет сокращения количества блоков необходимой оперативной статической памяти и применения асинхронной схемотехники, которая «упраздняет» глобальные тактирующие сигналы.
В ранних исследованиях показано, что в параллельной реализации SISO-декодера более 70% от общего объема потребляемой мощности расходуется памятью метрик состояний, 20% - памятью априорной информации, а остальное (около 10%) - блоками расчета метрик. Суммарная площадь блоков памяти, согласно тем же исследованиям, составляет в SISO-декодере около 80%. Это подтверждает утверждение, что при разработке малопотребляющих архитектур декодеров в первую очередь целесообразно сокращать объемы блоков памяти и число обращений к ним.
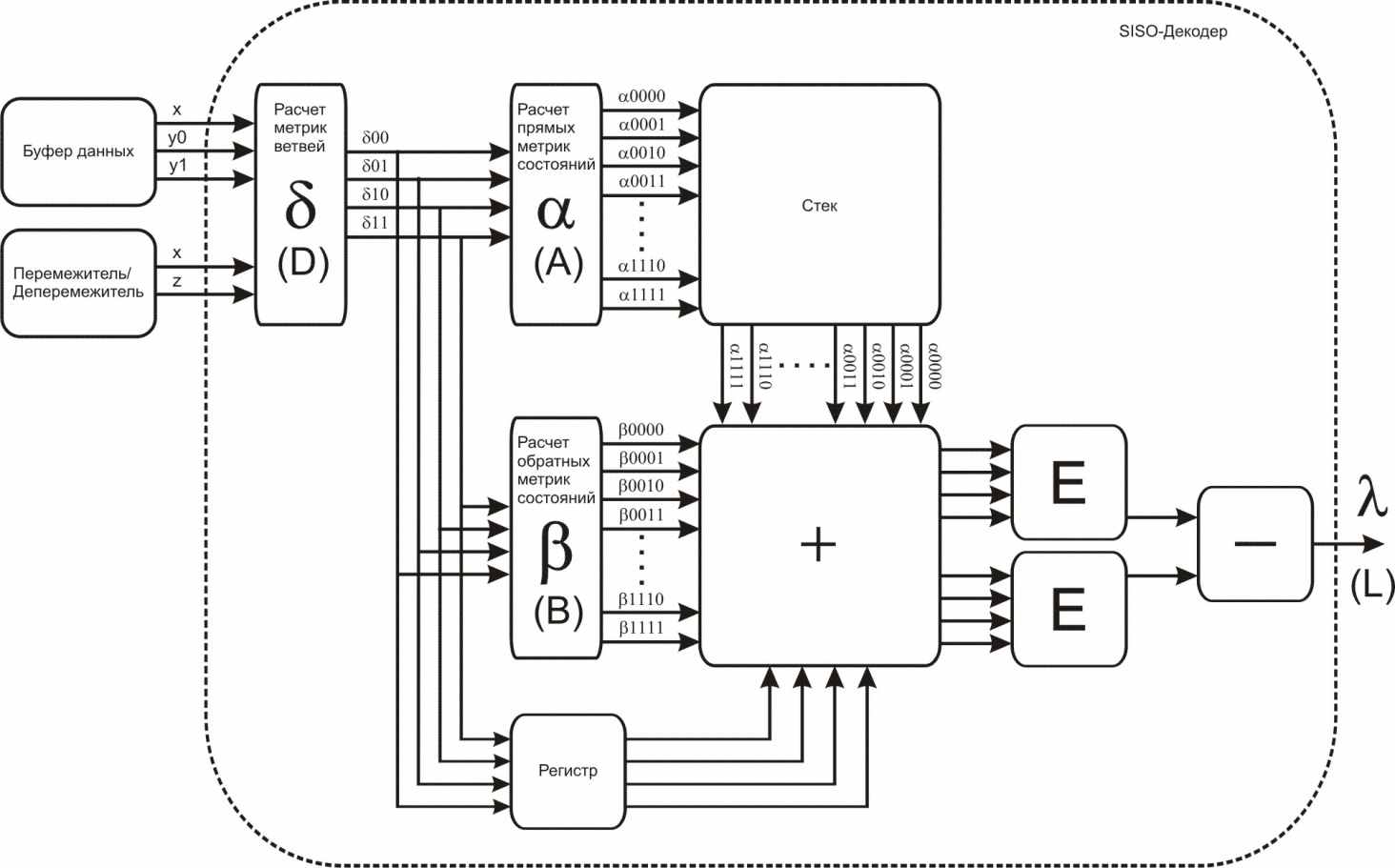
Рис. 7. Разработанная архитектура турбодекодера с малым
энергопотреблением
В декодере максимально объединены аналогичные аппаратные ресурсы, в частности: декодеры SISO (Soft In Soft Output), перемежитель и деперемежитель. Хотя, декодирование с помощью одного (совмещенного) SISO-декодера может быть выполнено различными путями, предлагается оптимизировать ресурсы памяти и количество обращений к ней, за счет некоторых компромиссов в производительности.
Энергопотребление параметризуемой и масштабируемой архитектуры декодера было проанализировано с помощью модели, учитывающей размер модулей расчета метрик, разрядность данных, количество символов в пакете, степень кодирования, кодовое ограничение, количество итераций.
Эффективность предложенного метода повышения энергоэффективности за счет минимизации аппаратных ресурсов (объемов ОЗУ) доказана сравнительным анализом результатов проектирования с существующими архитектурами различных систем-на-кристалле. В частности, показано сравнение энергоэффективности декодера сверточных турбокодов по алгоритму MAP. Достигнуто сокращение в 2 раза по энергопотреблению и площади по сравнению с аналогами. Однако для достижения данных параметров по энергопотреблению, необходим компромисс по критерию производительности.
Первыми шагами на пути развития структурированных систем коммуникации и повторного использования IP-ядер явились разработки сетей-на-кристалле (Network on a Chip – NoC), являющихся частью систем-на-кристалле.
Для применения NoC в конкретном приложении необходимо определить связь каждой вершины графа задач (ГЗ) со своим компонентным ресурсом в архитектуре, а также сконфигурировать каждое IP-ядро под заданный набор задач, используя базовые средства управления компонентными ресурсами. В связи с этим, для определения связи вершин ГЗ с компонентными ресурсами, необходимо решить задачу покрытия многозадачного графа сети.
Разработан метод покрытия многозадачного графа сети и размещения разногабаритных СФ-блоков на поле кристалла. Вершины многозадачного графа сопоставляются узлам NoC при условии, что каждая из задач (однозадачный граф) должна выполняться за минимально возможное время, но не дольше заданного времени. Минимизируется суммарная длина связей между СФ-блоками.
Предложенный метод предназначен для построения пользовательских или стандартизованных сетей-на-кристалле, таких как AMBA, WISHBONE и д.р.
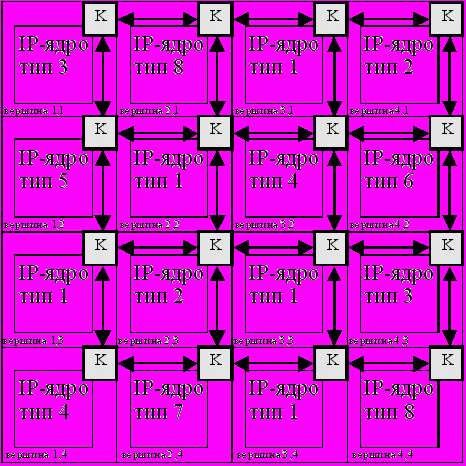
Исходная архитектура сети имеет матричный вид (Рис. 8). Каждый узел сети это IP-ядро из заданной библиотеки, состоящей из L ядер. На Рис. 8 обозначение К соответствует средствам управления компонентными ресурсами.
 |
| Рис. 8. Матричная архитектура сети |
– размерности матричной архитектуры (X, Y) при условии 1 ≤ L X×Y;
– многозадачный граф, заданный как набор из S параллельных однозадачных графов, с общим количеством m вершин и n ребер. Каждая вершина Vi выполняет функцию fi из заданного набора функций F = {fi : 0 i < m}. Каждое ребро Ei имеет разрядность данных wj (0 j < n), т.е. размер слов при передаче между двумя вершинами, соединенных этим ребром;
– временные ограничения на S параллельных однозадачных графов: D0,…,D(s-1).
Времена выполнения функций F каждым типом IP-ядра из библиотеки устанавливаются в определенные значения. Если IP-ядро j не может выполнить функцию fi, то время выполнения для него устанавливается равным бесконечности. Каждое IP-ядро k (0 k < L) имеет заданную размерность входных данных равную Ik и выходных – Ok.
В связи со специфичностью решаемой задачи целевая функция для алгоритма имеет некоторые особенности, поскольку трудно определить единственную целевую функцию, учитывающую временные требования для каждого однозадачного графа.
Целевая функция должна включать в себя оценки всех однозадачных графов и, поэтому, может быть представлена следующим образом: TF = max {T0/D0, …, Ts-1/Ds-1}, где Ti – время критического пути однозадачного графа i.
Время критического пути однозадачного графа определяется как сумма задержек на ребрах и вершинах, принадлежащих критическому пути. Задержки на вершинах равны времени выполнения функций F. Задержками на ребрах являются времена прохождения данных между вершинами.
При данном определении целевой функции TF она должна быть минимизирована и ее значение не должно превышать 1.
Алгоритм оптимизации основан на моделировании генетической эволюции, для которого определен способ кодирования хромосом и необходимые генетические операторы.
Кодирующая хромосома включает в себя информацию о точном соответствии вершин многозадачного графа и типов IP-ядер. Поскольку архитектура NoC матричного типа, то кодирующая хромосома H может представлять из себя строку, в которой каждый ген g является типом IP-ядра, а их порядковый номер – положением в матрице графа: H = {gi : 0 gi L; i = 1…X×Y}.
Предлагается использовать метод подсчета целевой функции задачи покрытия сети с учетом геометрии топологических отображений IP-блоков. Данный метод состоит из следующих этапов:
I. На основе значений генов хромосомы H IP-ядра, соответствующих типов, располагаются на плоскости, таким образом, чтобы они были на достаточном друг от друга расстоянии не касаясь. Взаимное расположение IP-ядер на плоскости определяется порядковыми номерами их генов. Центры блоков совпадают с положение узлов графа.
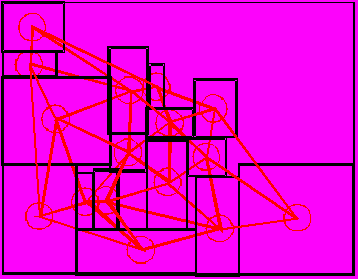 |
| Рис. 9. Эскиз NoC для вычисления целевой функции |
а) текущим назначается блок левой нижней вершины графа;
б) текущий блок помещается без зазоров в свободное левое нижнее пространство между двух смежных ему блоков (нижним и левым). Если текущим блоком является блок, назначенный в п. «а», то он помещается в левый нижний угол плана;
в) текущим назначается блок, узел которого является следующим в порядке обхода графа. Обход графа производится по принципу сканирования диагоналей. Если остались не размещенные блоки, то переход к п. «б», иначе к п. «г»;
г) стягивание областей средств управления компонентными ресурсами (см. Рис. 8 – области К), которые изначально произвольно располагались в блоках. Стягивание производится по направлению к центру плана кристалла.
д) перестроение архитектуры сети, на основе триангуляции, сформированной на центрах областей К (см. Рис. 9).
III. Подсчет целевой функции.
Оценка энергоэффективности межсоединений в проектируемой сети-на-кристалле производится на основе моделей межсоединений. На Рис. 10 показана модель межсоединений в системе-на-кристалле.
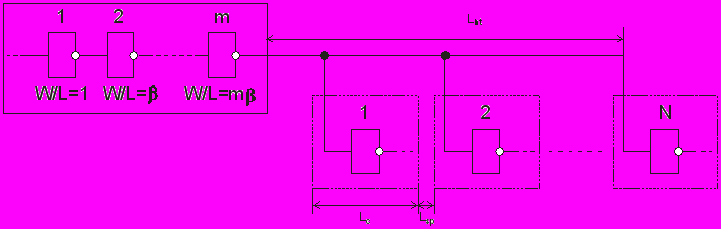 Рис. 10. Модель линии передачи в сети-на-кристалле
Рис. 10. Модель линии передачи в сети-на-кристаллеПередающий блок включает в себя набор буферов, которые нагружены линией передачи. Линия передачи подключена к нескольким принимающим блокам, каждый из которых имеет входной терминал с минимальным инвертором.
Интегральный критерий для оценки энергоэффективности:
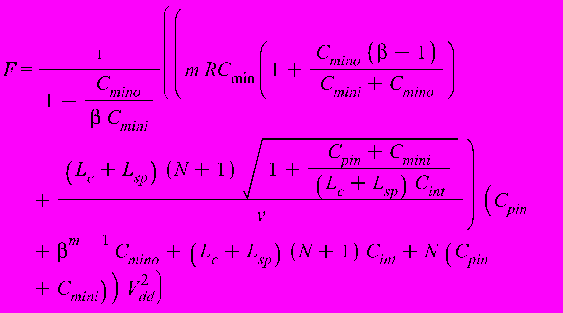
где Cmini – входная емкость минимального инвертора; Cmino – выходная емкость минимального инвертора; β – коэффициент прогрессии увеличения размеров выходных буферов в цепочке; m – число буферов в цепочке; RCmin - время распространения сигнала через минимальный инвертор; Lc – средняя длина стороны принимающего блока; Lsp – расстояние между принимающими блоками; N – число принимающих блоков; Cpin – емкость вывода; Cint – погонная емкость линии передачи; Vdd – напряжение питания.
Анализ разработанного метода сокращения транзакций показал, что улучшение энергоэффективности систем-на-кристалле достигается за счет оптимизации топологической архитектуры внутрикристальной сети.
Эффективность предложенного метода оптимизации транзакций доказана сравнительным анализом с существующими методами распределения задач в графе, которые не учитывают реальных размеров и ориентацию топологии блоков в сочетании с моделями энергоэффективности межсоединений. Среднее сокращение энергопотребления достигает 20%.
Достоверность разработанных аналитических моделей была проверена путем сопоставления с эталонным SPICE-моделированием на моделях 5-го уровня. Расхождение в оценке нетрассированных соединений с трассированными достигает 50 %.