
1. Алфавит, слова, операции над словами
| Вид материала | Документы |
Содержание11. Синтаксический анализ для КС-языков S abcca S abcca |
- Исполнительный кодекс Республики Молдова, 2184.07kb.
- Статьи 4 изложить в следующей редакции: "Статья Ответственность физических, юридических,, 41.3kb.
- Республика Молдова, 777.62kb.
- Федеральный закон, 404.04kb.
- Подготовка к операции по прорыву блокады проводилась в глубокой тайне, 18.04kb.
- Игра «Алфавит» Чтобы узнать тему нашего занятия вы должны расшифровать слова. (зашифрованные, 50.79kb.
- «День культуры и славянской письменности», 78.75kb.
- Выполнили: Фурманова Диана 3класс, 121.65kb.
- Работа со словами с непроверяемыми написаниями, 134.51kb.
- Календарно-тематический план учебная дисциплина: «Математика», 34.71kb.
11. Синтаксический анализ для КС-языков
Может рассматриваться синтаксический анализ в широком или же узком смысле. Синтаксический анализ в узком смысле – по цепочке определить её структуру (или же построить синтаксическое дерево). Т.Е. задача сводится к построению вывода данной цепочки в данной грамматике.
Синтаксический анализ в широком смысле – определение, может ли данная цепочка быть построена с использованием данной грамматики. Это в общем случае гораздо более сложная задача.
Существующие алгоритмы синтаксического анализа классифицируются по:
- Cпособу построения вывода : нисходящие, восходящие, смешанные
- Способу выбора альтернативы: детерминированные и недетерминированные. В первом случае на каждом шаге выбирается правильная альтернатива, во втором – альтернатива выбирается наугад.
- Способу возврата (для недетерминированного выбора альтернативы): разбор с быстрым или медленным возвратом.
- По степени доступности цепочки: или цепочка доступна вся сразу, или же читается слева направо посимвольно (при этом доступно для анализа определенное число символов).
Обычно рассматривается нисходящий или восходящий разбор при чтении цепочки слева направо.
Типовая задача синтаксического анализа:
Имеется активный нетерминал S и множество альтернатив:
Sk и текущее состояние анализируемой цепочки Y. Пусть выбрана альтернатива SX1X2…Xn, XiVNVT, при i[1,n]. Если X1 VT, то он должен совпадать с первым символом цепочки Y. Если совпадает, то укорачиваем цепочку на этот символ и переходим к X2. Если не совпадает, то переходим к другой альтернативе.
Если же XiVN, тогда из Xi необходимо вывести какое-нибудь начало цепочки Y. Если из Xi нельзя вывести никакое начало цепочки Y, то возможны 2 варианта:
1). Сразу перейти к Xi-1 и попытаться вывести из Xi-1 другое начало и т.д. ( получаем полный перебор вариантов вывода) – разбор с медленным возвратом.
2). Сразу отказаться от альтернативы SX1X2…Xn (разбор с быстрым возвратом).
Очевидно, что наиболее удобными при анализе цепочек являются грамматики, допускающие детерминированный разбор, когда на каждом шаге мы можем однозначно выбрать альтернативу, и в случае невозможности подобрать нужную альтернативу цепочка не принадлежит языку (никакой вывод не может быть построен). Одним из таких типов грамматик являются LL(k)-грамматики.
11.1 LL(k)-грамматики
LL(k)-грамматиками называются грамматики, допускающие детерминированное построение левого разбора (left) при чтении анализируемой цепочки слева (left) направо, подсматривая вперед не более чем на k символов.
Например, рассмотрим грамматику с множеством правил:
S
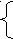 a SbB
a SbBB b B
Эта грамматика является LL(1)-грамматик, т.к. для выбора правильной альтернативы на каждом шаге нам достаточно анализировать один (текущий) символ цепочки.
Грамматика называется разделённой, если все правила грамматики имеют вид
Aa11a2 2…akk, причём aiaj при ij, aiVT, i(VTVN)* при i[1,k]. Очевидно, что в случае разделённой грамматики строится детерминированный нисходящий разбор.
Очевидно, что разделённые грамматики принадлежат к классу LL(1) грамматик. Грамматики могут оказаться LL(k) грамматиками для различных k, например, грамматика может быть LL(3) грамматикой, но не LL(2) грамматикой. Бывают и грамматики, которые не являются LL(k) грамматикой ни для какого k.
Например, рассмотрим грамматику с множеством правил:
S
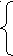 0 S0B
0 S0BA 0 A ac L(G)= {0n+1 c an, 0n+1 d bn, n 0}
B 0 B bd
Sl A n+10n+1 с an
Sl B n+1 0n+1 d bn ( n 0 ).
Чтобы определить по заданной терминальной цепочке, какое правило ( S A или S B ) было применено на первом шаге вывода, нужно прочитать n+1 символ, следовательно данная грамматика не является LL(k) ни при каком k
Дадим формальное определение LL(k) грамматики. Для этого введем определение
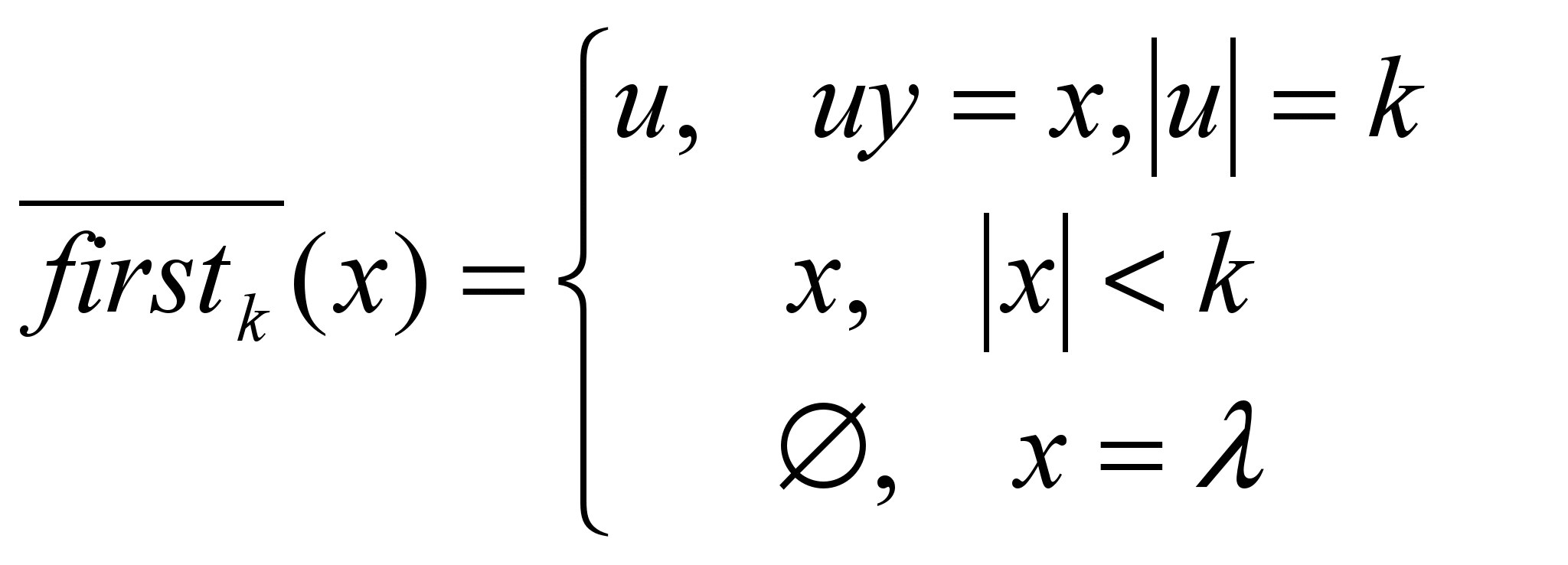
- определяются первые k символов терминальной цепочки. Т.к. для пустой цепочки это пустое множество, то определим для данной грамматики пополненную грамматику, к которой не будут встречаться пустые цепочки:
Для грамматики G=< VT,VN, S, R> соответствующая пополненная грамматика G’=< VT{$},VN{S’}, S’, R’>, где множество правил R’=R{S’ S $ }, где каждая цепочка имеет справа граничный маркер($).
Расширим определение множества first так, чтобы охватить произвольные цепочки (VTVN)*:
Для (VTVN)* Firstk()= { x/ * Z, ZVT*, x=
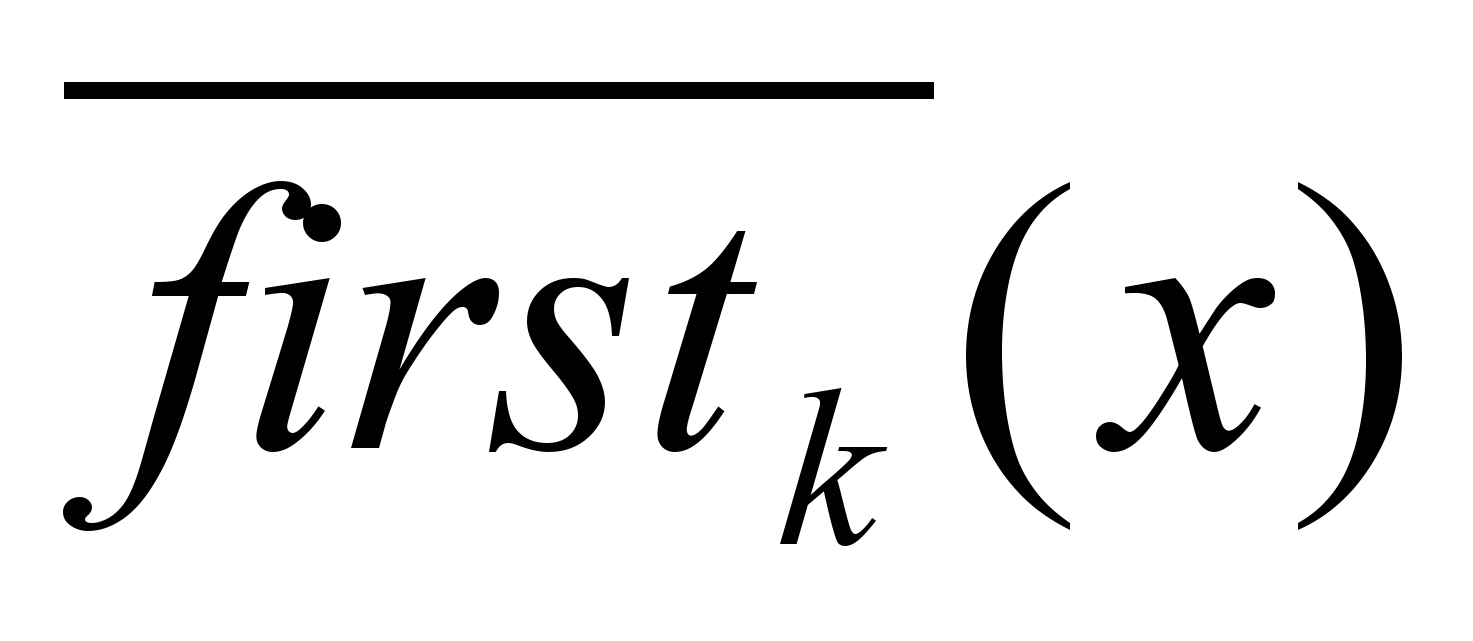 }.
}.Например, рассмотрим грамматику с множеством правил
S
abAabBA ab A c L(G)= {(ab)nc, (abc)n, n 1}
B cab Bc
Правила соответствующей пополненной грамматики:
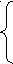 S’ S $
S’ S $S ® abA½abB
A ® ab A ½c
B ® cab B½c
Для данной грамматики
First1(S)={a}, First1(A)={a, c}, First1(B)={c}; First2(S)={ab}, First2(A)={ab, c$}, First2(B)={c$, ca}, First3(S)={abc}, First3(A)={abc, c$}, First3(B)={c$, cab}.
Тогда мы можем формально определить LL(k) грамматику как грамматику, для которой для любых двух левых выводов
S* A * x
S* A * y
AVN, , x, y VT*, (VN VT)*, из условияFirstk(x)=Firstk(y) следует .
Несложно показать, что наше формальное определение соответствует не формальному.
Теорема: LL(k) грамматика является однозначной.
Неоднозначность грамматики противоречит LL(k) свойству. Неоднозначна – значит, существуют два вывода для некоторой цепочки, значит, не сможем определить по k символам, каое из правил следует применить.
Теорема: КС-грамматика G=< VT,VN, S, R> является LL(k) грамматикой для любых двух правил А1 и А2 Firstk(1 ) Firstk(2 )= для любой цепочки , такой что S*A.
Использование LL(k) свойства при построении анализатора.
Пусть текущее состояние левого вывода цепочки z=y имеет вид А, где выведенное терминальное начало цепочки, А – текущий нетерминал( самый левый нетерминал), y не просмотренная часть цепочки.
Рассмотрим Firstk(y). Пусть для нетерминала А существуют альтернативы:
А12n R. Надо найти i для применения на данном шаге. Для этого надо вычислить
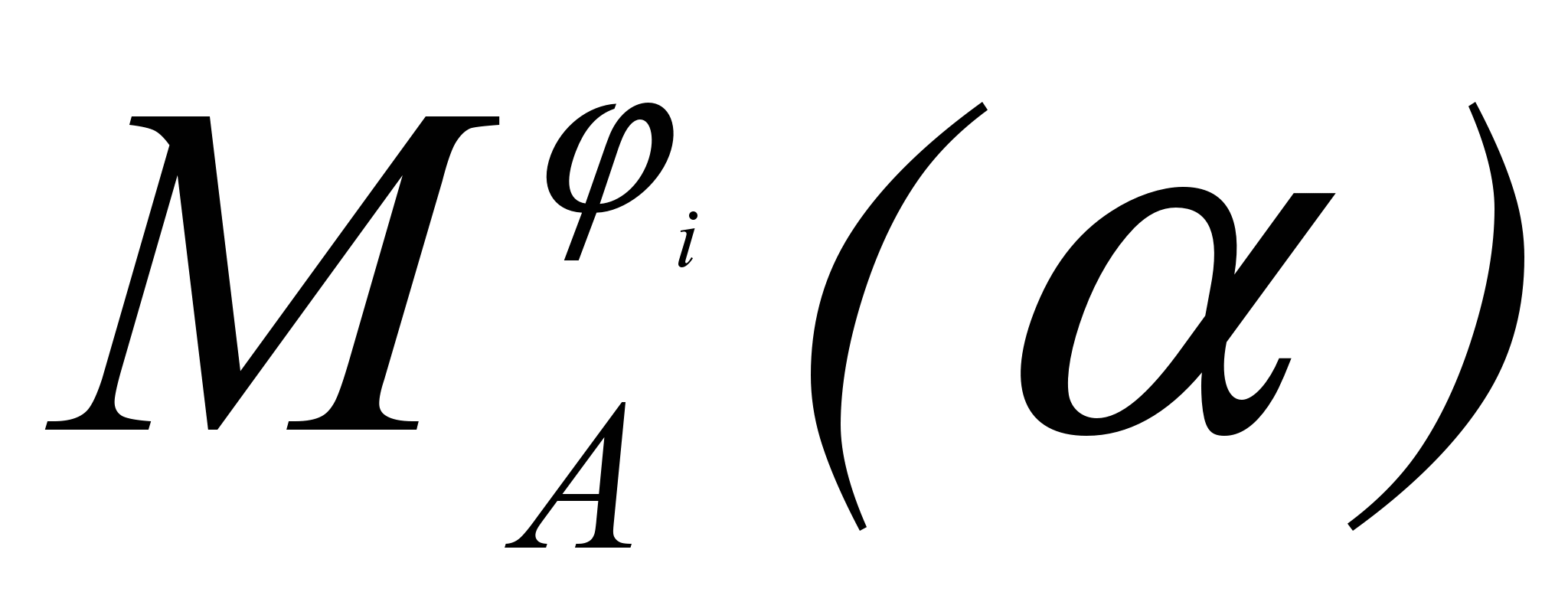 =Firstk(i). Это множество может быть заранее вычислено для всех А, , i. При этом из LL(k) свойства следует, что
=Firstk(i). Это множество может быть заранее вычислено для всех А, , i. При этом из LL(k) свойства следует, что 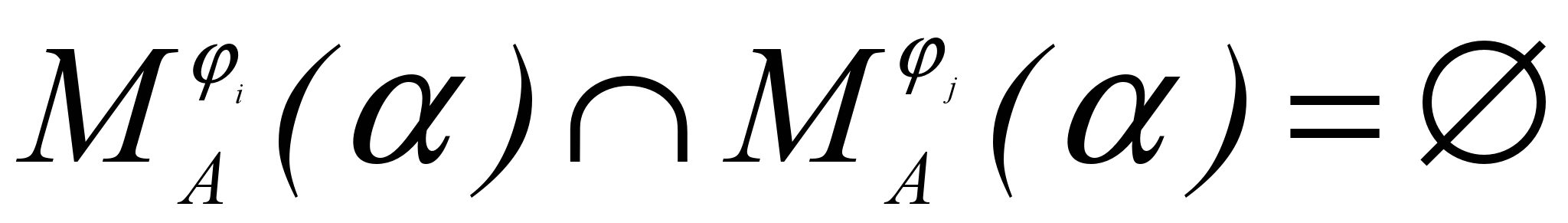 при ij.
при ij.Выбираем i, такое, что Firstk(y)= Firstk(i). Если такого i нет, то zL(G).
Затем переходим к анализу полученной цепочки xy’y’, где ’ – терминальное начало цепочки 1.
Шаги повторяются, пока не разберём всю цепочку, или не установим, что zL(G).
Пример:
Рассмотрим анализ цепочки acbbd в грамматике
S
ac SbBB b Bd
Эта грамматика является LL(1) На первом шаге определяем, какое правило применялось вначале: First1(acS)={a}, First1(bB)={b}, поэтому на первом шаге применяется правило S ac S, анализируемая цепочка принимает вид:bbd, First1(bbd)={b}, поэтому применяется правило S bB, и анализируемая цепочка принимает вид bd. Определяем First1(bB)={b}, First1(d)={d}, поэтому применяемое правило B b B, анализируемая цепочка принимает вид d, применяем правило B d, остается пустая цепочка как в выводе, так и анализируемая цепочка, поэтому анализируемая цепочка принадлежит языку, порождаемому грамматикой.
Проблемы, возникающие при построении анализатора для LL(k) грамматик:
1. При k1
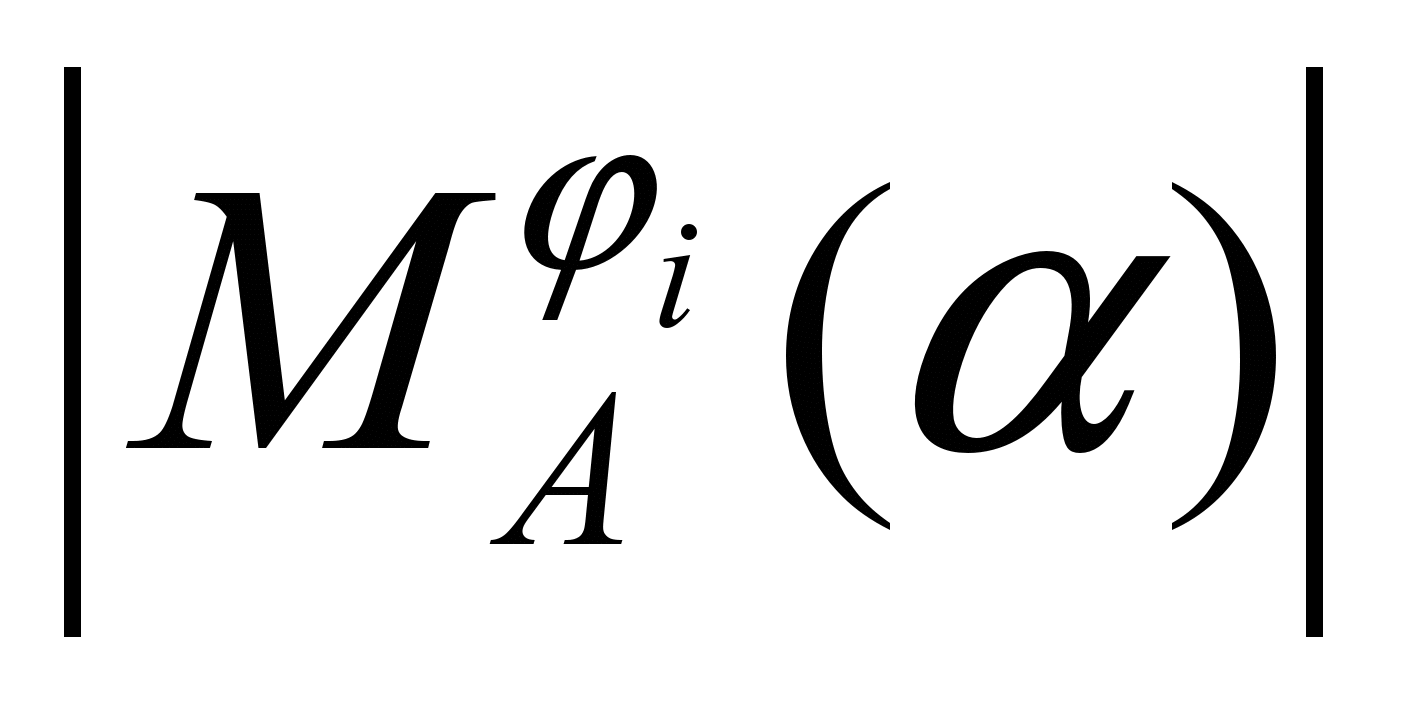 может стать неприемлемо большой , т.к. пропорциональна k.
может стать неприемлемо большой , т.к. пропорциональна k.2.
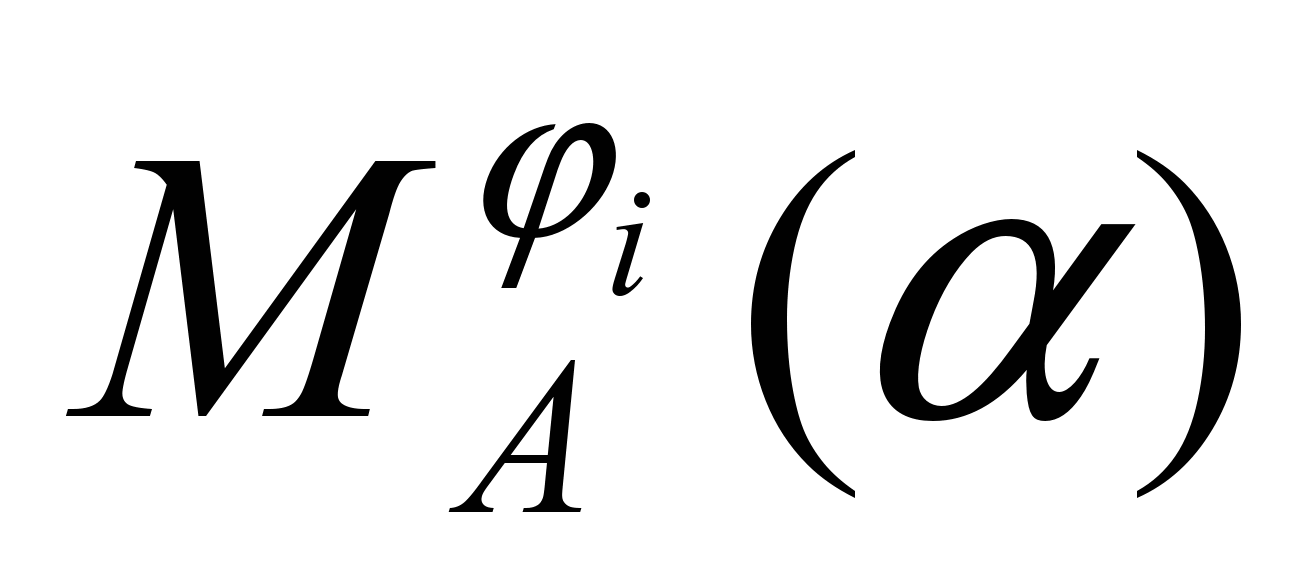 является функцией от трёх переменных: А, i, - т.е. велик сам объём предварительных вычислений.
является функцией от трёх переменных: А, i, - т.е. велик сам объём предварительных вычислений.Однако можно упростить задачу, усилив условия, накладываемые на грамматику:
Обозначим
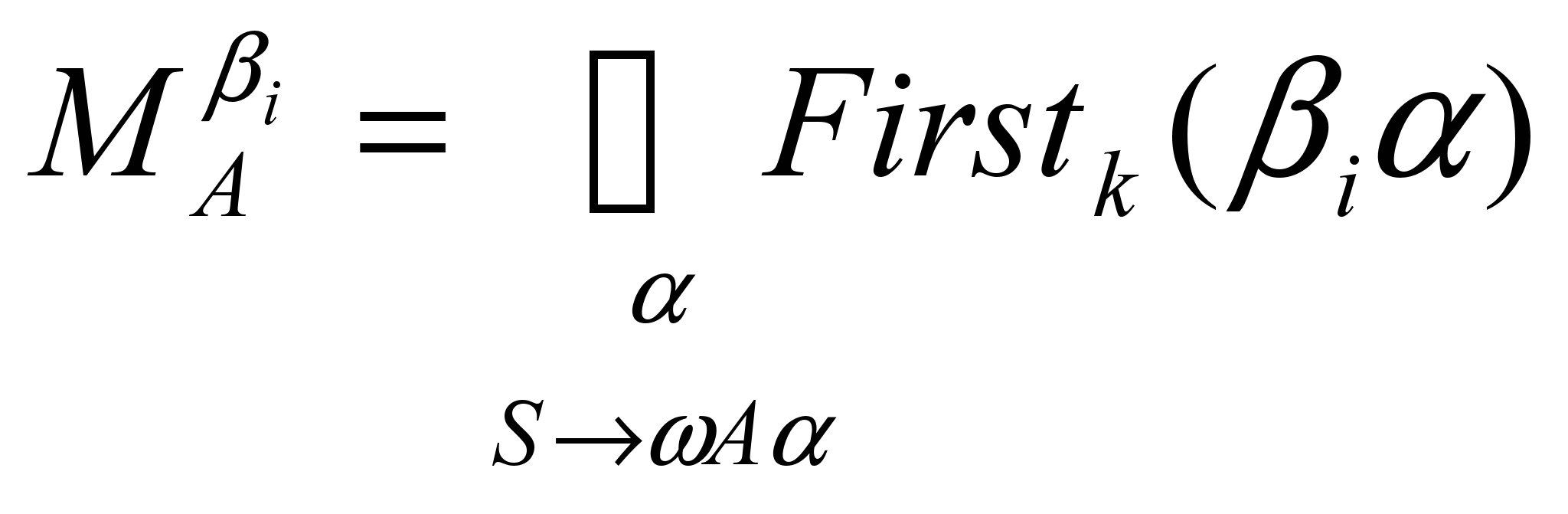 и потребуем, чтобы
и потребуем, чтобы 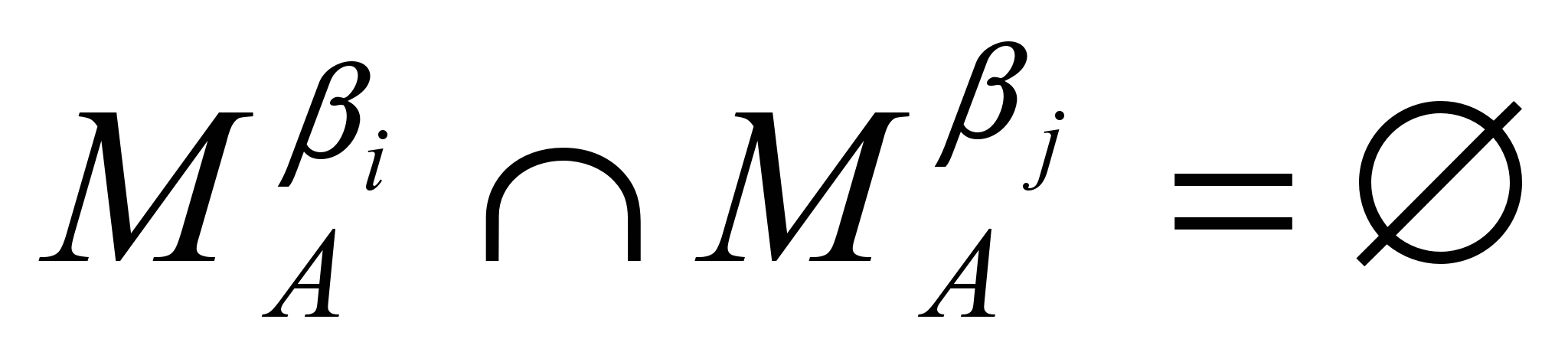 при ij.
при ij.Грамматика G называется строго LL(k) грамматикой, если для любых двух левых выводов
S*1 A 1 1 1 *1x
S*2A 2 2 2 *2 y
AVN, 1, 2, x, y VT*, 1 2 (VN VT)*, из условияFirstk(x)=Firstk(y) следует . Несложно показать, что G является строго LL(k) грамматикой для любого AVN из того, что AR, AR, , следует, что MAMA=.
Теорема: LL(1) грамматика всегда строго LL(1) грамматика.
Доказательство:
Предположим, что некоторая грамматика G - LL(1) грамматика, но не строго LL(1) грамматика. Тогда существуют два вывода
S*1 A 1 1 1 *1x11 *1x1y1
S*2A 2 2 2 *2 x12 *1 x2y2,
Такие, что First1 (x1y1)= First1(x2y2) & - Условие (*).
Но т.к. G - LL(1) грамматика, то
S*1 A 1 1 1 *1x11 *1x1y1
S*1 A 1 1 1 *1x21 *1x2y1
и из First1 (x1y1)= First1(x2y1) следует, что - Условие (**).
Покажем, что условия (*) и (**) несовместны.
Рассмотрим следующие случаи:
1. x1, x2 , тогда First1(x1y1)=First1(x1), First1(x2y2)=First1(x2), First1(x1 )=First1(x2)по условию (*) .
С другой стороны, по условию (**) First1(x1 )=First1(x2). Противоречие.
2. x1=, x2= приводит к неоднозначности грамматики.
3. Пусть x1=, x2. Тогда в условии (*)First1(x1y1)=First1(y1)= First1(x2y2)=First1(x2) &
По условию (**) First1(x1y1)=First1(y1)= First1(x2y1)=First1(x2) & =. Противоречие.
Случай 4, x1¹l, x2=l разбирается аналогично случаю 3.
Из теоремы следует критерий принадлежности грамматики классу LL(1):
G – LL(1) MAMA= при для всех AVN, где MAb=

При этом если
а) ,*, , то MA=First1()
b) *, MA=First1()
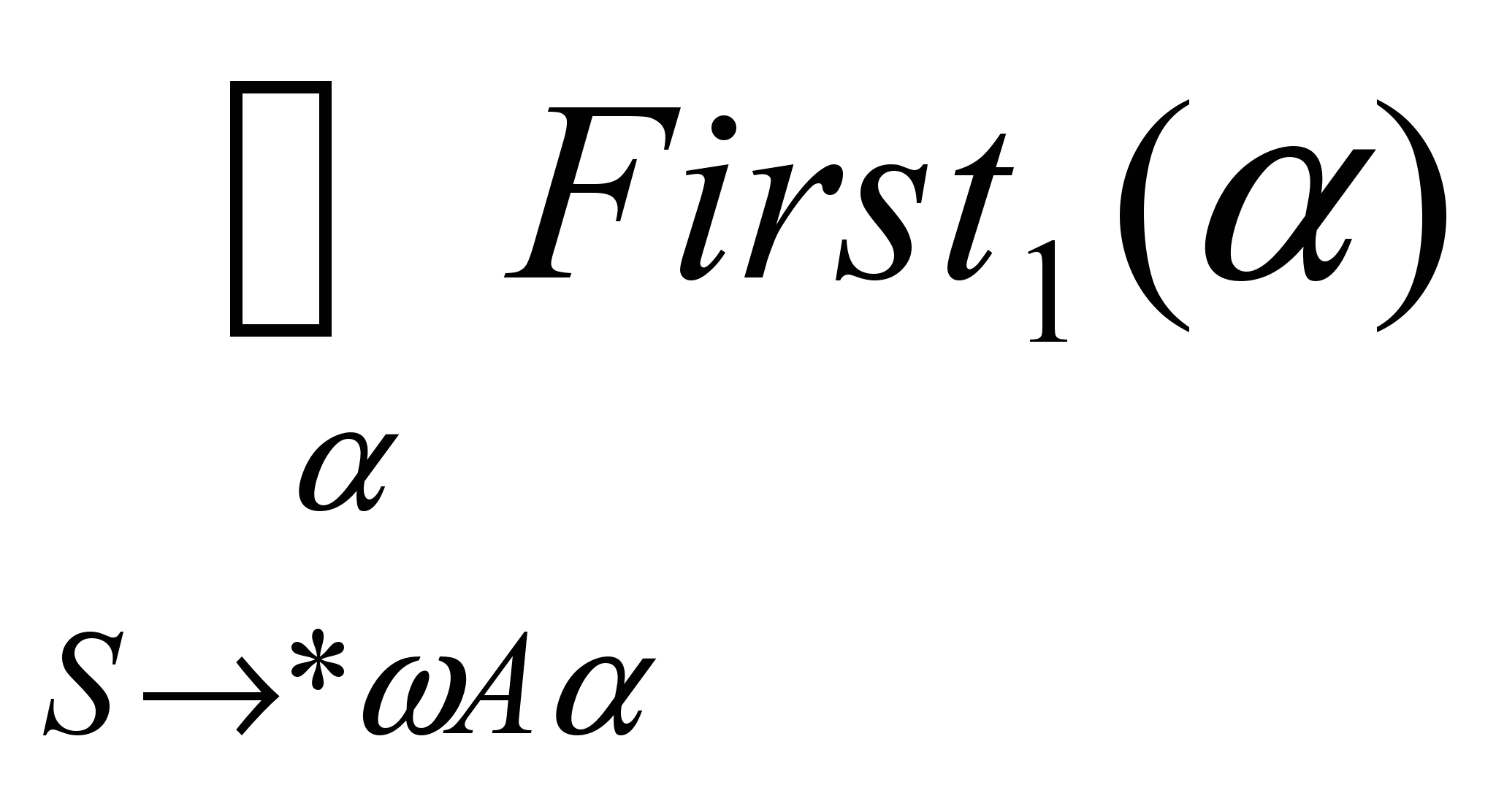
Т.К. рассматриваем пополненную грамматику, то (First1()=).
Определим множество Follow1(X)={a/ S+Xa&aVT}, X(VNVT).
Т.о. G - LL(1) грамматика AVN, , AR&AR& MAMA=.
Определения и алгоритмы нахождения множеств First и Follow
1. First1()
- First1()=
- aVT First1(a)=a
- First1(A)={ First1(xi)/Ax1x2…xnR&i=1i=m&x1…xm-1+}
- First1(x1x2…xn)={ First1(xi)/ First1(x1)& i=1i=m&x1…xm-1+}
Например, рассмотрим грамматику:
S
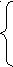 ABCCA
ABCCAAa
B b B
CcCd
В пополненной грамматике добавляется начальной правило S’ S$.
S
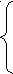 ’ S
’ S S ABCCA
Aa
B b B
CcCd
First1(A)={a};
First1(B)={b};
First1(C)={c,d};
First1(S)= First1(ABC) First1(AC)={a, b, c, d}
- Follow1(A)= ={First1()/ S * A }
Рассматриваем грамматику без непроизводящих правил, тогда если S * B A , то First1( ) Follow1(A).
- Неверно, что *, тогда First1()=First1().
- *, тогда First1()=First1()First1().
Поэтому Follow1(A)={ First1(Xm)/ B A X1 X2…XnR&m=1X1X2…Xm*} {Follow1(B)/B A R &*}
Т.е. просматриваются все правые части правил, в которые входит исследуемый нетерминал.
Рассмотрим грамматику
S
’ S $S ABCCA
Aa
B b B
CcCd
Здесь N={A,B}
Follow1(S)={$},
Follow1(A)= First1(B) First1(C) Follow1(S)={b, c, d, $},
Follow1(B)= First1(C)={c,d},
Follow1(C)= First1(A) ) Follow1(S)={a,$}.
Проанализируем LL(1) свойство грамматики:
MSABC= First1(A) First1(B) First1(C)={a, b, c, d},
MSCA= First1(C)={c,d}.
Т.к. MSABC MSCA , то грамматика не является LL(1) –грамматикой.
Восходящий анализ.
При восходящем анализе цепочка сворачивается путем применения правил в обратном порядке (дерево вывода строится снизу вверх).
Введенные строки анализируются слева направо, полученные подстроки сопоставляются в правыми частями грамматики, и при совпадении заменяются на соответствующий нетерминальный символ в левой части правила (свёртка). Цепочка, заменяемая на этот символ, называется основой.
Если свёртываемая основа выбирается случайно, то может потребоваться возврат, и число шагов построения вывода пропорционально длине цепочки.
Среди грамматик выделяется класс LR(k) грамматик - тот тип грамматик, для которых однозначно восстанавливается правый вывод (R) при чтении цепочки слева (L) направо, при подглядывании вперёд не более чем на k символов.
Алгоритм такого разбора в общем случае сложен, поэтому чаще всего рассматривается удобный подкласс ГПП (грамматики простого предшествования) – частный случай LR(k) грамматик, в которых для выделения основы используются отношения простого предшествования.
Пусть цепочка X получена G=< VT,VN, S, R> с помощью правого вывода:
S12….n=X (VT)*.
Тогда при восходящем анализе будем иметь
X=n ├ n-1 …├ 0 = S.
Выделим i-ый шаг вывода S*Ay (=i-1) y (=i)*x y, здесь Ay текущее состояние правого вывода, A – самый правый нетерминал в выводе. Свёртка состоит в переходе от y к aAy, (a j y├ aAy) т.е. мы должны выделить подцепочку j, которая сворачивается в нетерминал A применением правила A j в обратном порядке.
Пример разбора цепочки для грамматики с арифметикой.
Для ГПП техника выделения основы следующая:
Строится матрица отношений предшествования между символами VTVN. При этом между парой символов х и y может существовать не более одного отношения предшествования, обозначаемого символами <, ≗, >.
Грубо говоря, отношения предшествования отражают порядок появления символов в правом выводе.
Если a j y – текущее состояние цепочки, где j – основа, то
Между всеми смежными символами цепочки , выполняется отношение < или ≗ .
2. Между последним символом цепочки и первым символом цепочки (основы) выполняется отношение < .
3. Между смежными символами основы выполняются отношения ≗.
4. Между последним символом основы и первым символом цепочки у выполняется отношение >.
Если такое свойство отношений имеет место и для каждой пары символов определено не более одного отношения, то основу легко выделить, просматривая цепочку y слева направо до тех пор, пока впервые не встретится отношение >. Для нахождения левого конца основы надо возвращаться назад, пока впервые не встретится отношение < . Цепочка, заключенная между < и > и будет основой. Если в грамматике нет правил с одинаковыми правыми частями, то однозначно находится нетерминал А такой, что A , что позволяет свернуть основу, получая цепочку i-1 .
Этот процесс продолжается до тех пор, пока цепочка либо не свернется к начальному символу S, либо дальнейшие свертки окажутся невозможными.
Отношения простого предшествования с указанными свойствами могут быть определены на VNVT следующим образом [1]:
X < Y, если в R есть правило A X B , и при этом BY;
X ≗ Y, если в R есть правило A X Y .
Отношение > определяется на (VNVT) VT , так как непосредственно справа от основы может быть только терминальный символ.
X > a, если в R есть правило A X Y , и B + X, Y* a . Так как основа может совпадать с правым или левым концом цепочки, то удобно заключить анализируемую цепочку в концевые маркеры $ и $ , положив для X VNVT, X > $ для всех X, для которых S X и X< $ для всех X, для которых S X .
Грамматика G называется грамматикой простого предшествования, если она не содержит -правил, для любой пары символов из VNVT выполняется не более одного отношения простого предшествования и в ней нет правил с одинаковыми правыми частями.
Выполнение этих требований, очевидно, гарантирует возможность на любом шаге разбора однозначно выделить основу и произвести свертку.
Пример. Пусть множество правил грамматики: S a S S b, S c. Для заключения цепочки в маркеры вводим новый начальный символ S’и правило S’$S$. Отношения предшествования для этой грамматики приведены в табл.1.
| | S | a | b | c | $ |
| S | ≗ | < | ≗ | < | |
| a | ≗ | < | | < | |
| b | | > | > | > | > |
| c | | > | > | > | > |
| $ | | < | | < | |
Разбор цепочки $accb$.$<a<c>cb$├$<a≗S<co>b$├$<a≗S≗S≗bo>$├$S$
Вывод, соответствующий этому разбору:
S’ $ S $$ a S S b $$ a S c b $$ a c c b $
Способ построения свёртки для цепочки связан с использованием стека, куда посимвольно переносится информация из входного буфера, до тех пор, пока не встретится отношение >. Тогда к цепочке от отношения > до ближайшего слева отношения < должна применяться свёртка.
Алгоритм разбора для ГПП:
1. Анализируемая цепочка заключается в маркеры.
2. Берём очередной символ из входного буфера (слева направо). Если между верхним символом стека и первым символом входной цепочки отношение<o или ≗ , то заносим этот символ из входной цепочки в стек и возвращаемся к шагу 2, если же между верхним символом стека и первым символом входной цепочки отношение o>, то переходим к шагу 3. Если между символами нет никакого отношения предшествования, то цепочка не принадлежит языку, порождаемому грамматикой.
3. Обратное движение: из стека вынимаются символы до первого отношения <o между первым символом стека и символом цепочки во входном буфере. Если такой символ появился, то переходим к шагу 4, иначе цепочка не принадлежит языку, порождаемому грамматикой.
4. Применяем свёртку (заменяем выделенный фрагмент на левую часть правила грамматики, правая часть которого совпадает с основой) и возвращаемся к шагу 2. Если свёртка неприменима (нет такой правой части правила), то цепочка не принадлежит языку, порождаемому грамматикой.
Если в результате применения свёртки мы приходим к цепочке $ S $, то исходная цепочка принадлежит языку, порождаемому грамматикой, в противном случае цепочка не принадлежит языку, порождаемому грамматикой.
Обозначим
Head(A)={X/A+X} (First1(A)=Head(A) VT),
Tail(A)= {X/A+ X}, тогда
X
X > a A B C & X Tail(B) & aFirst1(C).
Пример разбора цепочки aaccbbcb с использованием построенной таблицы отношений предшествования приведен в табл.2.
Таблица 2
| | Отношение | Входная | |
| Стек | предшествования | строка | Операция |
| $ | < | aaccbcb$ | сдвиг |
| $a | < | accbcb$ | сдвиг |
| $aa | < | ccbcb$ | сдвиг |
| $aac | > | cbcb$ | «Свертка» |
| $aaS | < | cbcb$ | сдвиг |
| $aaSc | > | bcb$ | «Свертка» |
| $aaSS | ≗ | bcb$ | сдвиг |
| $aaSSb | > | cb$ | «Свертка» |
| $aS | < | cb$ | сдвиг |
| $aSc | > | b$ | «Свертка» |
| $aSS | ≗ | b$ | сдвиг |
| $aSSb | > | $ | «Свертка» |
| $S | | $ | «Конец» |