
1. Алфавит, слова, операции над словами
| Вид материала | Документы |
Содержание9. Преобразования грамматик. |
- Исполнительный кодекс Республики Молдова, 2184.07kb.
- Статьи 4 изложить в следующей редакции: "Статья Ответственность физических, юридических,, 41.3kb.
- Республика Молдова, 777.62kb.
- Федеральный закон, 404.04kb.
- Подготовка к операции по прорыву блокады проводилась в глубокой тайне, 18.04kb.
- Игра «Алфавит» Чтобы узнать тему нашего занятия вы должны расшифровать слова. (зашифрованные, 50.79kb.
- «День культуры и славянской письменности», 78.75kb.
- Выполнили: Фурманова Диана 3класс, 121.65kb.
- Работа со словами с непроверяемыми написаниями, 134.51kb.
- Календарно-тематический план учебная дисциплина: «Математика», 34.71kb.
9. Преобразования грамматик.
В данном разделе приводятся такие преобразования грамматик, которые не выводят нас из класса эквивалентности, т.е. грамматика G1 таким образом преобразуется в грамматику G2, чтобы L(G1)=L(G2).
9.1 Устранение непроизводящих правил.
Непроизводящими правилами грамматики начинаются правила, применение которых никогда не приводит к построению терминальных цепочек.
Например, рассмотри правила для нетерминала А
АА А В А
В этом случае, появившись в цепочке, нетерминал А никогда не будет заменен терминальной цепочкой (имеется в виду, что других правил для А нет). Естественно, в реальности ситуации бывают не столь простые. Алгоритм устранения непроизводящих нетерминалов:
- Построение множества производящих нетерминалов NR:
- Строится множество NR1 = {A/ Aj,jVT}
- Последовательно строятся множества NRi+1={ A/ Aj,j(NRiVT)*} до тех пор, пока получим NRi+1= NRi или же NRi= VN. Тогда NR = NRi.
- Строится множество NR1 = {A/ Aj,jVT}
- Исключаем из грамматики все правила, в правых частях которых нетерминалы из VN\ NR.
- Исключаем из грамматики правые части правил, в которых присутствуют нетерминалы из VN\ NR.
Например, рассмотрим грамматику G с множеством правил
S
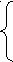 ABBC
ABBCA AAAB
B bBa
СсСd AC
Построим множество NR. NR1={B,C}, NR2={S, B, C}, NR3= NR2= NR.
Преобразованная грамматика примет вид:
S BC
B
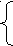 bBa
bBaСсСd
9.2. Устранение недостижимых нетерминалов.
Недостижимыми нетерминалами называются нетерминалы, которые никогда не могут быть построены при построении вывода, начиная с начального символа грамматики. Следует отметить, что такие нетерминалы в грамматиках встречаются в основном тогда, когда исключены некоторые непроизводящие символы, т.е. недостижимым нетерминал становится чаще всего после исключения некоторых непроизводящих симовлов. Например, если в грамматике для нетерминала А правила АА А В А, и нетерминал В не встречается в других правых частях правил грамматики, то в этом случае, после устранения нетерминала А нетерминал В становится недостижимым, и, следовательно, его можно исключить из грамматики без изменения порождаемого ей языка. Построение множества недостижимых нетерминалов похоже на построение множества непроизводящих нетерминалов: мы строим множество всех достижимых нетерминалов, а затем исключаем все остальные нетерминалы грамматики. Алгоритм построения грамматики, в которой используются только достижимые нетерминалы (множество достижимых нетерминалов –D) , выглядит следующим образом:
Пусть дана грамматика G=< VT,VN, S, R>, строится эквивалентная грамматика без непроизводящих символов G’ =< VT,VN’, S, R’>.
- Начальное значение D0=S.
- Итерационное построение множества D: Di+1= Di{A/BARB Di}
- Построение продолжается, до тех пор, пока Di+1= Di или Di+1= VN, в обоих случаях VN’= Di+1,
R’={ Ri / Ri=(A), A VN’,( VN’ VT)*}
Построенная грамматика не содержит недостижимых нетерминалов.
Например, рассмотрим грамматику G с множеством правил
S
 A C B C
A C B CA AD DF
D aA D A
F b F
B bBa
СсСd
Тогда здесь A и D непроизводящие нетерминалы, после их устранения нетерминал F становится недостижимым, поэтому нетерминалы A, D и F могут быть исключены из грамматики с сохранением языка, порождаемого грамматикой.
9.3. Устранение - правил
Устранение - правил связано с исключением построения цепочек, которые после преобразований превращаются в пустую цепочку. Цель такого преобразования грамматики – если в грамматике строится пустая цепочка, то она строится в результате первого шага построения. Применение любого из оставшихся правил приводит к построению непустых цепочек, более того, цепочка, построенная из каждого из нетерминала, состоит не менее чем из одного терминального символа.
Пусть дана грамматика G=< VT,VN, S, R>, строится эквивалентная грамматика G’ =< VT,VN’, S, R’>.
- Построить множество N = { A / A + } - множество нетерминальных символов, из которых возможен вывод пустой цепочки. Множество N строится итерационно. На первом шаге строится N0.
N0 = { B / B R}
Пусть построено N1, N2, ..., Ni , ( i 0). Тогда Ni+1 = Ni { B / B R & ( Ni)* }.
Если на очередном шаге Ni+1 = Ni, то искомое множество N найдено ( N = Ni ).
- Построить R’ — множество правил эквивалентной грамматики так, что:
- Если A0 B1 1 B2 ... Bk k R , k 0 и Bi N для 0 i k, но ни один символ в цепочках j, 1 j k не содержит символа из N, то включить в R’ все правила вида
A 0X11X2...Xkk
Xi либо Bi, либо (при этом правило A не включать; это могло бы произойти, если все i = ).
- если S N, включить в R’ также правило S’ S где S’ - новый начальный символ.
Таким образом, любая КС—грамматика может быть приведена к виду, когда R не содержит -правил, либо есть точно одно правило S’ и S’ не встречается в правых частях остальных правил из R. Такие грамматики будем называть неукорачивающими.
Например, пусть дана грамматика G с множеством правил
SA B BC
A aAb
B dBc
C CCAc
N0= {A, C}
N1= {A, C}= N. Поскольку L(G) (S N), правила грамматики примут вид
SA B B BC
A aAb ab
B dBc
C CCAca c
Б . Устранение правил А В (цепных правил)
Применение цепных правил приводит к увеличению длины ветвей синтаксического дерева, исключение цепных правил часто приводит к большей «прозрачности» грамматики и уменьшению длины выводов, которые можно построить. Алгоритм исключения цепных правил:
1. Для каждого A VN построить NA = { B / A B }, т.е. множество нетерминальных символов, выводимых из данного символа. Процедура построения следующая:
а) положить NA0 ={A}.
б) пусть построены NA0, NA1 ... NAi . Тогда
NAi+1 = { C / B C R & B NAi } NA0.
Если на очередном шаге NAi+1 = NAi, то положить NA = NAi.
2. Построить R’ (множество правил эквивалентной грамматики) так: если B R и не является цепным правилом, то включить в R’ правила A . для всех таких A, что
B NA.
Рассмотрим пример. Пусть множество правил грамматики имеет вид:
S
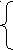 T+ST
T+STT MTM
M (S) i
Простроим для данной грамматики множества NA
NS ={S, T, M}
NT = {T, M}
NM = {M}
После преобразования грамматики она примет вид:
S
T+S MT(S) iT MT (S) i
M (S) i
В данном случае преобразование грамматики не привело к её упрощению, но построенные синтаксические деревья будут иметь меньшую глубину, и построение дерева будет происходить быстрее.
Грамматика называется неукорачивающей, если для любого правила грамматики выполняется. Такое определение применимо как к КС-грамматикам, так и к КЗ-грамматикам. А-грамматика так же может быть неукорачивающей. Для КС и А-грамматик необходимым и достаточным условием принадлежности к классу неукорачивающих грамматик является отсутствие в них -правил.
Грамматика называется приведенной, если она неукорачивающая и не содержит непроизводящих символов.
Поэтому, если L(G), то существует приведенная грамматика G1, такая, что L(G1)=L(G).
В случае же L(G), существует эквивалентная грамматика с единственным укорачивающим правилом.