
Інформаційні ресурси для прийняття управлінських рішень безугла Ю.Є
| Вид материала | Документы |
- Назва модуля: Інформаційні системи в менеджменті Код модуля, 40.82kb.
- Тема Прийняття управлінських рішень, 421.91kb.
- Сучасні технології прийняття управлінських рішень, 100.09kb.
- Тематичний план дисципліни Плани лекцій та семінарських (практичних) занять. Завдання, 564.17kb.
- Ві адаптації теоретичних підходів, науково-методичних І практичних рекомендацій щодо, 199.41kb.
- Тема: Методи прийняття раціональних рішень у менеджменті, 61.09kb.
- Методологія прийняття управлінських рішень в управлінні підприємством, 119.65kb.
- «Укрвуглегеологія», 802.03kb.
- Програма вступних випробувань на навчання за освітньо-кваліфікаційним рівнем «Магістр», 345.36kb.
- Тема загальні засади ділового прогнозування, 195.94kb.
Палагута К.О., к.е.н., доцент
Донецький національний університет економіки і торгівлі
імені Михайла Туган-Барановского
ВИКОРИСТАННЯ XML – ТЕХНОЛОГІЙ В ЕКОНОМІЦІ
Мова XML (розширювана мова розмітки) та XML – технології стрімко розвиваються, стають фактично стандартом подання інформації у глобалізованому інформаційному просторі. На теперішній час мова XML є стандартом, з використанням якого фінансова звітність суб’єктів господарювання готується і передається до Державної податкової адміністрації у електронному вигляді через Internet. За допомогою програми «Податкова звітність» можна підготувати документи фінансової звітності у форматі XML і передати їх по каналах електронної пошти. У більшості програм автоматизації бухгалтерського обліку реалізовано функцію формування файлів фінансової звітності у форматі XML для передачі у податкову адміністрацію.
Розробка мови XBRL (Extensible Business Report Language – розширювана мова фінансових звітів) почалась у 1998 році з ініціативи і під керуванням AICPA (American Institute of Certified Public Accountants – Американського інституту сертифікованих бухгалтерів). XBRL є перекладенням існуючих стандартів фінансової і бухгалтерської діяльності на XML, що забезпечує їй значні переваги перед іншими способами подання і передачі ділової інформації.
Мова XBRL дозволяє багаторазово використовувати фінансову інформацію в різних ситуаціях – для публікації звітів, вибірки даних для різних додатків, заповнення різних форм звітності тощо. Завдяки своїм властивостям XBRL дозволяє здійснювати автоматичний обмін фінансовою інформацією між різним програмним забезпеченням, яке взаємодіє за допомогою різних інформаційних мереж, включаючи Інтернет. Вона усуває необхідність повторного введення фінансової інформації, тим самим знижуючи ризик помилкового введення даних та усуваючи необхідність ручного введення для отримання звітів у різних форматах (документи, підготовлені текстовими редакторами, HTML – документи для публікації звітів у Інтернет, документи у спеціалізованих форматах звітності). У результаті знижуються витрати на підготовку і передачу фінансових документів, спрощується доступ до інформації інвесторам і аналітикам. Використання XBRL як єдиного формату публікації фінансової інформації в мережі Інтернет дозволяє швидко знаходити необхідні фрагменти даних, у тому числі за допомогою інтелектуальних агентів.
У 1999 р. Центр ООН по підтримці процедур і практики управління, комерції та транспорту (UN/CEFACT) і Організація розвитку структурованих інформаційних стандартів (OASIS) почали виконання проекту по стандартизації глобального обміну бізнес - інформацією. У результаті виконання даного проекту розроблено ebXML (Electronic Business XML - XML для електронного бізнесу). Об’єднання Global Commerce Initiative (Глобальна комерційна ініціатива), в яку входить близько 30 транснаціональних корпорацій використовує ebXML як складову частину структури електронного бізнесу. У мові ebXML реалізовано концепцію EDI (Electronic Data Interchange – електронний обмін документами), сутність якої полягає у створенні систем, які відповідають вимогам: дотримання єдиного синтаксису повідомлень; можливість вибору елементів даних; єдиний формат генерації повідомлень і файлів, який забезпечує їх обмін.
EDI системи – це міжвідомчі системи обміну електронними документами, які використовують стандартизовані правила складання електронних документів.
На відміну від орієнтації на бізнес-документи ebXML орієнтується на бізнес-процеси. Процес містить детальний опис обміну даними і послідовності повідомлень. Багатократно використовувані компоненти, які називаються компонентами ядра, можуть бути використані у повідомленнях для подання різної інформації.
Компоненти ядра створюють бізнес-механізм, який дозволяє використовувати специфічні для галузі словарі, причому самі по собі компоненти є семантично нейтральними. Зв’язки з компонентами ядра, що визначають специфічну для галузі семантику, записуються у розподілені сховища даних разом з іншими моделями, даними і об’єктами, які дозволяють організаціям обмінюватися даними. Дані доступні через API-інтерфейс. ebXML дозволяє також використовувати контакти електронним чином з використанням механізму виробничого партнерського узгодження.
Commerce XML (cXML – комерційний XML) створений на базі XML і призначений для опису даних каталогів і виконання електронних транзакцій. Розроблений групою 40 компаній, що займаються електронним бізнесом, під головуванням компанії Ariba Inc cXML є інструментом для виконання ефективних транзакцій через Internet. cXML включає в себе набір DTD для опису даних каталогів, замовлень на постачання. Мова також визначає засоби, за допомогою яких cXML – документи можуть бути отримані та передані через Internet.
Компанія Visa International розробила Visa XML Invoice Specification (специфікація для опису рахунків на XML), щоби дозволити своїм клієнтам обмінюватися інформацією про покупки, здійсненні за допомогою кредитних карток через Internet у захищеній і стандартизованій формі. Ця специфікація дозволяє власникам кредитних карток отримувати детальну інформацію про покупки по кредитним карткам. На теперішній час специфікація забезпечує основу для опису покупок по кредитним карткам на рівні компаній, а також для надання послуг у сфері туризму і відпочинку.
BIPS (Bank Internet Payment System) – банківська платіжна система через Internet) призначена для виконання захищених транзакцій через Internet. Клієнт-серверні додатки можуть використовувати BIPS для передачі платіжних доручень через Internet. Вільно розповсюджувана XML - специфікація дозволяє користувачам BIPS (банкам, установам і організаціям) реалізовувати сервіси електронного бізнесу для своїх клієнтів. Рішення створити специфікацію BIPS на основі XML дозволило легко перетворити BIPS – документи на інші стандартні XML – формати, що використовуються в електронній комерції. BIPS – транзакції можуть бути ініційовані як платниками, так і одержувачами платежу.
Роттер М. В., к.т.н., доцент
Донецький національний університет економіки і торгівлі
імені Михайла Туган-Барановського
СБІР ІНФОРМАЦІЇ ДЛЯ КОНКУРЕНТНОЇ РОЗВІДКИ
Наростання агресивності конкурентного середовища як на внутрішньому, так і на зовнішньому ринках, у тому числі на ринках глобальної конкуренції, сьогодні не оспорюється. Більше того, ця тенденція тільки посилюватиметься у зв'язку з глобалізацією економічної діяльності. Так, за словами російського теоретика, ректора Вищої школи бізнесу МГУ О. Виханського: "сейчас в управлении бизнесом главное не аналитика, а шпионаж".
Тому для виявлення намірів конкурентів підприємство може впровадити у свою структуру підрозділ конкурентної розвідки (КР). Так, наприклад, витрати на розвідку складають близько 1,5 % обороту великих організацій. У деяких японських фірмах розвідкою постійно займаються до 250 осіб. З за розкрадань виробничих секретів американські фірми терплять збитки 20 млрд. доларів в рік.
Таким чином, зрозуміло, що дуже актуальною стає збір інформації, без якої не може працювати конкурентна розвідка.
Конкурентна розвідка виконує дві функції.
- Пасивна - постійне спостереженні за діями суперників.
- Активна - полягає в цілеспрямованому зборі і обробці інформації для управління конкурентними ситуаціями, ухвалення швидких управлінських рішень, обумовлених найсвіжішими даними.
Збір відкритої (доступної) інформації полягає в забезпеченні високого рівня інформованості з питань, суть яких відома або може легко бути відома конкурентному оточенню. Кожен учасник ринку незалежно від інших прагне не відстати від потоків інформаційного руху, що динамічно розвиваються. Для цього постійно здійснюється збір первинних даних.
Первинні дані збираються у тому випадку, коли для ухвалення рішення недостатньо керуватися вторинними даними або коли інформація знаходиться у формі, непридатній для вирішення проблеми.
| Первинна інформація | |
| Достоїнства | Недоліки |
| Дозволяє отримати специфічну інформацію, наближену безпосередньо до проблеми | Відносно дорогий метод збору інформації |
| Оперативність і своєчасність отримання даних | Окрім грошових, вимагає ще й тимчасових витрат |
| Доповнює вторинні дані і разом з ними формує фундамент для ухвалення управлінських рішень | На її основі не можна приймати повноцінні управлінські рішення |
| Легкість використання | Ефективність проявляється при використанні спільно з вторинною інформацією |
| Можна оцінити достовірність даних | Для збору, обробки і аналізу первинної інформації потрібний кваліфікований персонал |
Вторинні дані не є результатами спеціально проведених досліджень і збираються в процесі кабінетних досліджень, тому безпосередньо не пов'язані з цілями маркетингових досліджень.
Можна стверджувати, що повноцінне управлінське рішення може бути прийняте тількі при сумісному використанні первинної та вторинної інформації.
| Вторинна інформація | |
| Достоїнства | Недоліки |
| Швидкість отримання в порівнянні із збором первинних даних та відносна дешевизна | Менша новизна даних |
| Легкість використання | Неможливість оцінити достовірність |
| Доступність | Відбиває лише загальну динаміку процесів, що цікавлять |
| Підвищує ефективність використання первинних даних | Є недостатньою для вирішення складних управлінських проблем |
Література:
- Прескотт Дж.Е., Миллер С.Х. Конкурентная разведка. Уроки из окопов [Текст] / Прескотт Дж.Е. - М.: «Альпина Паблишер», 2003 - 336 с. - ISBN 5-94599-066-3
- Starting a CI Program. Houston: APQC / [Электронный документ] / (www. APQC.org).
- Роттер М.В. Створення інформаційної системи підприємства з використанням методів конкурентної розвідки [Текст] / Роттер М.В. Торгівля і ринок України: Темат. зб. наук. праць.- Донецьк: ДонНУЕТ, 2009. - Вип. 28. – Т. 1. - С. 329-336.
- Роттер М.В. Побудова й ефективна експлуатація системи забезпечення інформаційної безпеки підприємства [Текст] / Роттер М.В. Торгівля і ринок України: Темат. зб. наук. праць.- Донецьк: ДонНУЕТ, 2011. - Вип. 31. – Т. 2. - С. 124-133.
Роттер М. В. к.т.н., доцент
Донецький національний університет економіки і торгівлі
імені Михайла Туган-Барановського
ЕФЕКТИВНІ МЕТОДИ ПОШУКУ ІНФОРМАЦІЇ У ІНТЕРНЕТ
Пошук інформації завжди був однієї з основний складових успіху будь-якої діяльності, у тому числі. Останнім часом особливо актуальним стає пошук потрібних даних в Інтернет. Професійний пошук інформації в Мережі представляє собою окремий напрямок діяльності, що вже давно перетворился в дуже прибутковий бізнес. Так, існують самостійні дослідницькі центри, що спеціалізуються на пошуку даних. Як приклад, можна привести компанію лінгвістичної інженерії MAAG, що орієнтована на інформаційно-аналітичне забезпечення таких ключових галузей французької економіки, як аерокосмічна промисловість, транспорт і енергетика.
Цілком зрозуміло, що переглянути величезну кількість джерел Інтернет неможливо (горезвісне "прокляття розмірності інформації") тому, виходить парадоксальна ситуація: для того, що знайти інформацію про те, як шукати в Інтернет, потрібно вміти шукати в Інтернет (у древній міфології подібна положення описувалося наступною метафорою: "змій Уроборос, що кусає сам себе за хвіст").
Для розуміння того, як здійснюється пошук, корисно відзначити, що правила побудови текстів єдині. Це означає, що поза залежністю від мови, автора, культурної традиції тощо, внутрішня структура тексту залишається незмінною й описується законами, що були сформульовані в 1949 р. гарвардським професором-лінгвістом і філологом Джорджем Кінгслі Зіпфом .
Закони ці емпіричні і були отримані не за допомогою математичних висновків, а на основі аналізу статистики частоти слів у текстах на багатьох мовах. Інакше кажучи, Зіпф встановив статистичні закономірності розподілу частоти слів. Суть законів Зіпфа полягає в тому, що в кожній мові є слова, які зустрічаються частіше, ніж інші, але не мають значення. Є слова, що зустрічаються рідше, але мають набагато більше значеннєве навантаження. Також Зіпф установив, що найбільше вживані слова мови, яка існує тривалий час, коротше інших. Часте вживання як би "істірає" їх.
Коли Зіпф сформулював закономірності розподілу частоти слів, законом вони не вважалися. Після появи комп'ютерів були проведені дослідження, що підтвердили ці закономірності, які стали називати законами Зіпфа.
Цікавляче нас практичне застосування цих законів полягає в тому, що вони використовуються при розробці алгоритму роботи пошукових систем і при оптимізації сайта.
На основі законів Зіпфа пошукові системи розділяють усі слова на групи.
Слова, що зустрічаються найбільш часто (междометия, прийменники, суфікси, тощо). Ці слова пошукові системи вважають інформаційним шумом і не враховують при ранжируванні сайтів.
Слова, що пошукові системи вважають важливими (ключові слова). Частина таких слів, що мають важливе значення для конкретного сайта, враховують при ранжируванні. Інші ключові слова вважають випадковими для даного сайту і їхня роль при його ранжируванні невелика.
Дуже коротко, сам Зіпф сформулював це так "Слова з великою кількістю букв зустрічаються в тексті рідше коротких слів". Ґрунтуючись на цьому постулаті, Зіпф вивів два універсальних закони.
Перший закон Зіпфа "ранг - частота"
Кількість разів, що слово зустрічається в тексті, називається частотою входження цього слова. Частоти розташовуються і нумеруються в міру їхнього убування. Порядковий номер частоти зветься рангом частоти. Так, слова, що найбільш часто зустрічаються, будуть мати перший ранг, слова, що слідують за ними - другий і т.д. При випадковому виборі імовірність зустріти дане слово буде дорівнювати відношенню частоти входження цього слова до загального числа слів у тексті.
Другий закон Зіпфа "кількість - частота"
При розгляді першого закону не враховувався той факт, що різні слова можуть входити у текст з однаковою частотою. Зіпф установив, що частота і кількість слів, що входять у текст з цією частотою, теж зв'язані між собою. Якщо побудувати графік, відклавши по осі ординат частоту входження слова, а по осі абсцис - кількість слів у даній частоті, то крива, що вийшла, буде зберігати свої параметри для усіх без винятку створених людиною текстів. Як і в попередньому випадку, це твердження вірне в межах однієї мови. Однак, і міжмовні розходження невеликі. На якій би мові ні був написан текст, форма кривої Зіпфа залишиться незмінною. Відмітимо, що закони Зіпфа універсальні і можуть застосовуватися не тільки до текстів.
Література:
- Книга алхимических эмблем "Философский камень". [Електронний ресурс] / ru.wikipedia.org/wiki/Уроборос
- МАРП: Поиск информации в Интернет [Електронний ресурс] / www.dist cons.ru/modules/searchinf/tm1/main1.phpl
- Поиск информации в Интернет [Електронний ресурс] / ura ura.pisem.net/
- Печищев И.М. Поиск информации в Интернет [Електронний ресурс] / Печищев И.М.; company.yandex.ru/academic/class/courses/pechishev.xml
- Веб-студия "Антула". Законы Зипфа. [Електронний ресурс] / www.antula.ru/law-zipf.php
- Роттер М.В. Економічна інформатика. Web-дизайн (розробка і створення сайтів) Навчальний посiбник. [Текст] / Роттер М.В.; Донецьк: ДонНУЕТ, 2008. – 180 с.
Шабельник Т.В., к.е.н., доцент
Донецький національний університет економіки і торгівлі
імені Михайла Туган-Барановського
ІНФОРМАЦІЙНЕ ЗАБЕЗПЕЧЕННЯ СИСТЕМИ УПРАВЛІННЯ ПОПИТОМ ТОРГОВЕЛЬНОГО ПІДПРИЄМСТВА
Моделювання системи управління попитом торговельного підприємства припускає наявність у процесах прийняття рішень системи інформаційного забезпечення 1. Усі елементи системи інформаційного забезпечення мусять бути взаємопов’язані між собою та відповідати загальним вимогам, це – вірогідність, точність, надійність, комплексність 1.
Для побудови системи, що відповідає зазначеним вимогам, необхідно визначити наступні дії:
- визначення множини завдань управління;
- визначення кола осіб, що приймають рішення, їхніх прав, обов'язків і відповідальностей;
- визначення множини інформаційної потреби кожної особи, що приймає рішення для реалізації конкретних завдань управління;
- розробки форм і термінів подання необхідної інформації.
З позиції моделювання системи управління попитом торговельного підприємства система інформаційного забезпечення успадковує сформовану практику створення традиційного інформаційного забезпечення прийняття управлінських рішень 2, але має особливості за рахунок специфіки завдань управління.
Відзначимо, що кінцевим завданням системи управління попитом торговельного підприємства є організація функціонування торговельного підприємства на всіх стадіях реалізації продукції таким чином, щоб була досягнута висока ефективність за рахунок максимальної кореляції функції попиту на продукцію із функцією пропозиції торговельного підприємства.
Побудова системи інформаційного забезпечення для рішення даного завдання в умовах розвитку ринку потребує дослідження стадії реалізації продукції.
На стадії реалізації продукції вплив попиту на пропозицію виражається через зміну ціни та кількості продукції, що реалізується.
Тобто, вартісну оцінку реалізації продукції
Для формування закону зміни потужності продажів продукції і-го виду торговельного підприємства
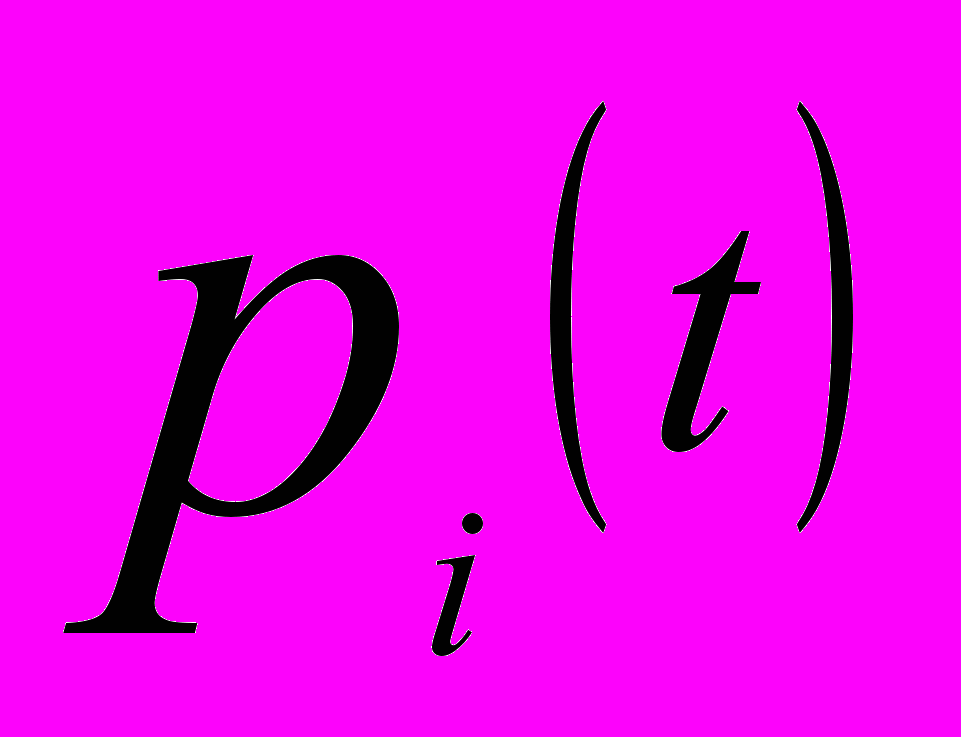 необхідно по кожному виду продукції, що поставляється на ринок, зробити дослідження попиту, із використанням широко відомих методів статистичних досліджень попиту та пропозиції.
необхідно по кожному виду продукції, що поставляється на ринок, зробити дослідження попиту, із використанням широко відомих методів статистичних досліджень попиту та пропозиції. Для відображення даних процесів у складі інформаційного забезпечення прийняття рішень представимо структуру інформаційних даних на стадії реалізації продукції.
Таким, чином, стадія реалізації готової продукції торговельного підприємства мусить мати наступну структуру інформаційних даних:
- номенклатура продукції, що реалізується;
- статистичні дані про продукцію на ринку за визначений період часу із вказівкою обсягів продажів та цін;
- коло замовників (споживачів) продукції;
- договірні зобов’язання на поставку продукції споживачам;
- характеристика засобів регулювання термінів поставки продукції на ринок.
Згідно структури інформаційних даних управлінський персонал повинен мати наступну інформацію про предметну область:
- закон зміни попиту на продукцію i-го виду;
- наявність можливості регулювання строків поставки i-го виду продукції на ринок шляхом зміни термінів поставки або з використанням складування продукції.
Вихідними інформаційними даними для прийняття рішень управлінським персоналом з питань регулювання процесів реалізації продукції є значення закону зміни попиту на продукцію торговельного підприємства.
У цілому для виконання модельних розрахунків на торговельному підприємстві є необхідним створення комп’ютерної бази даних для підтримки прийняття управлінських рішень. Так, реалізація інформаційного забезпечення модельних розрахунків системи управління попитом торговельного підприємства є можливою при незначних витратах з використанням наявного традиційного інформаційного забезпечення. У цьому випадку, найбільше теоретично розроблений є підхід, заснований на використанні концепції управління проектами. Виходячи із цього, інформаційне забезпечення системи управління попитом торговельного підприємства може бути створено на основі розробки проекту інформаційного забезпечення моделювання закону попиту продукції на ринку збуту.
Застосування нових технологій у створенні системи інформаційного забезпечення прийняття рішень у системі управління попитом на продукцію торговельного підприємства дозволить знизити собівартість, підвищити рентабельність і якість системи управління торговельним підприємством.
Література:
- Иванов, Н. Н. Информационно-сервисные системы в управлении сложными экономическими объектами : монография / Н. Н. Иванов. – Донецк : Юго-Восток, 2005. – 252 с. - ISBN 966-374-018-3.
- Лепа, Р. Н. Ситуационный механизм подготовки и принятия управленческих решений на предприятии: методология, модели и методы / Р. Н. Лепа; НАН Украины; Институт экономики промышленности. — Донецк : ООО "Юго-Восток, Лтд", 2006. — 308c. – ISBN 966-02-4155-0.