
Разработки уроков по информатике
| Вид материала | Урок |
СодержаниеЦели урока III. Теоретическая часть. III. Практическая часть. V. Вопросы учеников. I. Орг. момент. III. Теоретическая часть. Системы машинного перевода. V. Вопросы учеников. |
- Методические разработки уроков по теме «линейные алгоритмы вычисления выражений», 369.32kb.
- Общие принципы и подходы к обучению информатике, 160.44kb.
- Основы творческой разработки урока. Строение уроков основных типов, 302.33kb.
- Уроков к учебнику «Математика. 1 класс», 162.41kb.
- Задачи:. Формировать навыки разговорной речи >. Проконтролировать степень усвоения, 19.02kb.
- Применение метода проектов для разработки уроков и методических рекомендаций при изучении, 83.51kb.
- Учебно-методический комплекс курса по выбору "задачи егэ по информатике" (физико-математический, 704.64kb.
- С. М. Кирова Художественно-графическое отделение Основы композиции костюма Методические, 681.27kb.
- Александровна Тема «Организация движения Черепашки», 482.79kb.
- Типы и формы интегрированных уроков, 434.79kb.
Цели урока:
- помочь учащимся получить представление об OCR – программах распознавания текста, познакомиться с возможностями данных программы, научить распознавать отсканированный текст, передавать и редактировать его в Word.
- воспитание информационной культуры учащихся, внимательности, аккуратности, дисциплинированности, усидчивости.
- развитие познавательных интересов, навыков работы на компьютере, самоконтроля, умения конспектировать.
Оборудование:
доска, компьютер, компьютерная презентация.
План урока:
- Орг. момент. (1 мин)
- Актуализация знаний. (5 мин)
- Теоретическая часть. (10 мин)
- Практическая часть. (15 мин)
- Д/з (2 мин)
- Вопросы учеников. (5 мин)
- Итог урока. (2 мин)
Ход урока:
I. Орг. момент.
Приветствие, проверка присутствующих. Объяснение хода урока.
II. Актуализация знаний.
При создании электронных библиотек и архивов путем перевода книг и документов в цифровой компьютерный формат, при переходе предприятий от бумажного к электронному документообороту, при необходимости отредактировать полученный по факсу документ используются системы оптического распознавания символов.
На этом уроке мы научимся создавать преобразовывать отсканированное изображение в текст.
III. Теоретическая часть.
С помощью сканера достаточно просто получить изображение страницы текста в графическом файле. Однако работать с таким текстом невозможно: как любое сканированное изображение, страница с текстом представляет собой графический файл - обычную картинку. Текст можно будет читать и распечатывать, но нельзя будет его редактировать и форматировать. Для получения документа в формате текстового файла необходимо провести распознавание текста, то есть преобразовать элементы графического изображения в последовательности текстовых символов.
Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition - OCR).
Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами (именно так работали OCR первого поколения), но и самыми экзотическими, вплоть до рукописных. Уметь корректно работать с текстами, содержащими слова на нескольких языках, корректно распознавать таблицы. И самое главное — корректно распознавать не только четко набранные тексты, но и такие, качество которых, мягко говоря, далеко от идеала. Например, текст с пожелтевшей газетной вырезки или третьей машинописной копии. Само собой, распознать текст — это еще полдела. Не менее важно обеспечить возможность сохранения результата в файле популярного текстового (или табличного) формата — скажем, формата Microsoft Word.
Как видим, для того, чтобы получить электронную, готовую к редактированию копию любого печатного текста, программе OCR необходимо выполнить «цепочку» из множества отдельных операций.
Сначала необходимо распознать структуру размещения текста на странице: выделить колонки, таблицы, изображения и так далее. Далее выделенные текстовые фрагменты графического изображения страницы необходимо преобразовать в текст.
Если исходный документ имеет типографское качество (достаточно крупный шрифт, отсутствие плохо напечатанных символов или исправлений), то задача распознавания решается методом сравнения с растровым шаблоном. Сначала растровое изображение страницы разделяется на изображения отдельных символов. Затем каждый из них последовательно накладывается на шаблоны символов, имеющихся в памяти системы, и выбирается шаблон с наименьшим количеством отличных от входного изображения точек.
При распознавании документов с низким качеством печати (машинописный текст, факс и так далее) используется метод распознавания символов по наличию в них определенных структурных элементов (отрезков, колец, дуг и др.).
Любой символ можно описать через набор значений параметров, определяющих взаимное расположение его элементов. Например, буква «Н» и буква «И» состоят из трех отрезков, два из которых расположены параллельно друг другу, а третий соединяет эти отрезки. Различие между данными буквами — в величине углов, которые образует третий отрезок с двумя другими.
При распознавании структурным методом в искаженном символьном изображении выделяются характерные детали и сравниваются со структурными шаблонами символов. В результате выбирается тот символ, для которого совокупность всех структурных элементов и их расположение больше всего соответствует распознаваемому символу.
Наиболее распространенные системы оптического распознавания символов, например, ABBYY FineReader и CuneiForm от Cognitive, используют как растровый, так и структурный методы распознавания. Кроме того, эти системы являются «самообучающимися» (для каждого конкретного документа они создают соответствующий набор шаблонов символов) и поэтому скорость и качество распознавания многостраничного документа постепенно возрастают.
При заполнении налоговых деклараций, при проведении переписей населения и так далее используются различного вида бланки с полями. Рукопечатные тексты (данные вводятся в поля печатными буквами от руки) распознаются с помощью систем оптического распознавания форм и вносятся в компьютерные базы данных.
Сложность состоит в том, что необходимо распознавать написанные от руки символы, довольно сильно различающиеся у разных людей. Кроме того, система должна определить, к какому полю относится распознаваемый текст.
Системы распознавания рукописного текста. С появлением первого карманного компьютера Newton фирмы Apple в 1990 году начали создаваться системы распознавания рукописного текста. Такие системы преобразуют текст, написанный на экране карманного компьютера специальной ручкой, в текстовый компьютерный документ.
Программы для распознавания текста вы можете приобрети отдельно или получить бесплатно вместе с купленным вами сканером.
Возможно, самая известная программа для распознавания текстов – это FineReader от компании ABBYY. Именно эту программу чаще всего вспоминают, когда речь заходит о системах распознавания.
FineReader - омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами, без предварительного обучения. Особенностью программы FineReader является высокая точность распознавания и малая чувствительность к дефектам печати, что достигается благодаря применению технологии "целостного целенаправленного адаптивного распознавания".
FineReader имеет массы дополнительных функций, которые простому пользователю, возможно, и без надобности, но зато производят впечатление на определенные группы покупателей. Так, одним из козырей FineReader является поддержка неимоверного количества языков распознавания — 176, в числе которых вы найдете экзотические и древние языки, и даже популярные языки программирования.
Но далеко не все возможности включены в самую простую модификацию программы, которую вы можете получить бесплатно вместе со сканером. Пакетное сканирование, грамотная обработка таблиц и изображений — для всего этого стоит приобрести профессиональную версию программы.
Все версии FineReader, от самой простой до самой мощной, объединяет удобный интерфейс. Для запуска процесса распознавания вам достаточно просто положить документ в сканер и нажать единственную кнопку (мастер Scan & Read) на панели инструментов программы. Все дальнейшие операции — сканирование, разбивку изображения на «блоки» и, наконец, собственно распознавание программа выполнит автоматически. Пользователю останется только установить нужные параметры сканирования.
FineReader работает со сканерами через TWAIN-интерфейс. Это единый международный стандарт, введенный в 1992 году для унификации взаимодействия устройств для ввода изображений в компьютер (например, сканера) с внешними приложениями.
Качество распознавания во многом зависит от того, насколько хорошее изображение получено при сканировании. Качество изображения регулируется установкой основных параметров сканирования: типа изображения, разрешения и яркости.
Сканирование в сером является оптимальным режимом для системы распознавания. В случае сканирования в сером режиме осуществляется автоматический подбор яркости. Если Вы хотите, чтобы содержащиеся в документе цветные элементы (картинки, цвет букв и фона) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной тип изображения. В других случаях используйте серый тип изображения.
Оптимальным разрешением для обычных текстов является - 300 dpi и 400-600 dpi для текстов, набранных мелким шрифтом (9 и менее пунктов).
После завершения распознавания страницы FineReader предложит пользователю выбор: сканировать и распознавать дальше (для многостраничного документа) или сохранить полученный текст в одном из множества популярных форматов — от документов Microsoft Office до HTML или PDF. Можно, впрочем, сразу же перебросить документ в Word или Excel, и уже там исправить все огрехи распознавания (без ни обойтись просто невозможно). При этом FineReader полностью сохраняет все особенности форматирования документа и его графическое оформление.
Вопросы:
- Зачем нужны программы распознавания текста?
- Как происходит распознавание текста?
- Какие программы распознания текста вы знаете? Какими пользовались?
- Какое разрешение является оптимальным для сканирования текста, изображений?
III. Практическая часть.
Теперь потренируемся работать с программой ABBYY FineReader. Будем использовать упрощенную версию программы, поставляемую со сканером.
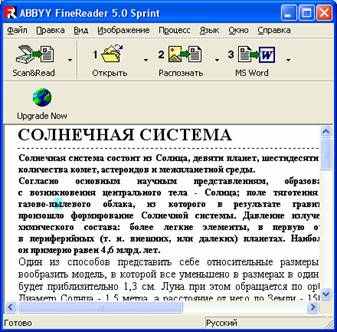
Запустите FineReader и откройте файл C:/Наш урок/Урок24 практика.jpg. Для этого щелкните на кнопке Открыть и выберите файл с изображением.
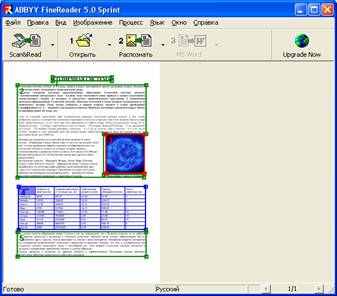
Распознайте это отсканированное изображение. Для этого нажмите кнопку Распознать. Прежде чем приступить к распознаванию, программа должна знать, какие участки изображения надо распознавать. Для этого проводится анализ макета страницы, во время которого выделяются блоки с текстом, картинки и таблицы. В большинстве случаев FineReader сам успешно справляется с анализом сложных страниц.
Если программа произвела анализ страницы неправильно, можно исправить вручную. Для этого щелкните Процесс→Анализ макета страницы.
Блоки - это заключенные в рамку участки изображения. Блоки выделяют для того, чтобы указать системе, какие участки, отсканированной страницы, надо распознавать и в каком порядке. Также по ним воспроизводится исходное оформление страницы. Блоки разных типов имеют различные цвета рамок.
Текст - блок используется для обозначения текста. Он должен содержать только одноколоночный текст. Если внутри текста содержатся картинки, выделите их в отдельные блоки.
Таблица - этот блок используется для обозначения таблиц или текста, имеющего табличную структуру. При распознавании программа разбивает данный блок на строки и столбцы и формирует табличную структуру. В выходном тексте данный блок передается таблицей.
Картинка - этот блок используется для обозначения картинок. Он может содержать картинку или любую другую часть текста, которую Вы хотите передать в распознанный текст в качестве картинки.
Результаты распознавания можно сохранить в файл, передать во внешнее приложение, не сохраняя на диск или скопировать в буфер обмена.
Распознанный текст можно отправить в Microsoft Word. Для этого щелкните кнопку Передать в MS Word. Запуститься программа Microsoft Word и откроется распознанный текст, который вы можете редактировать и форматировать, сохранить в файл.
Учащиеся выполняют задание.
IV. Д/з
Знать, что такое программы распознавания текста, уметь работать с этими программами. Дополнительное задание: установить дома программу OCR и подготовить реферат по какому-либо предмету. Текст распознать в OCR, редактирование и форматирование провести в Word.
V. Вопросы учеников.
Ответы на вопросы учащихся.
VI. Итог урока.
Подведение итога урока. Выставление оценок.
На уроке мы познакомились с программами OCR, научились распознавать отсканированное изображение с помощью программы ABBYY FineReader 5.0.
Урок №25.
Тема: «Компьютерные переводчики».
Цели урока:
- помочь учащимся получить представление об компьютерных словарях и системах машинного перевода текста, познакомиться с возможностями данных программы, научить использовать эти программы.
- воспитание информационной культуры учащихся, внимательности, аккуратности, дисциплинированности, усидчивости.
- развитие познавательных интересов, навыков работы на компьютере, самоконтроля, умения конспектировать.
Оборудование:
доска, компьютер, компьютерная презентация.
План урока:
- Орг. момент. (1 мин)
- Актуализация знаний. (5 мин)
- Теоретическая часть. (10 мин)
- Практическая часть. (15 мин)
- Д/з (2 мин)
- Вопросы учеников. (5 мин)
- Итог урока. (2 мин)
Ход урока:
I. Орг. момент.
Приветствие, проверка присутствующих. Объяснение хода урока.
II. Актуализация знаний.
Знание хотя бы одного иностранного языка необходимо сегодня всем, как воздух. В особенности пользователям: ведь избежать столкновения с английским языком при работе на компьютере, увы, невозможно. Ладно, если бы дело касалось только файлов с документацией к программам (которые у нас традиционно никто не читает) или названий программных меню (ориентироваться в которых можно научиться и без знания языка, методом научного тыка и зубрежки).
Плохо, если вы не знаете иностранного языка... Однако горю вашему — отчасти — можно помочь, установив на компьютер одну из специализированных программ-переводчиков.
На этом уроке мы научимся работать с одной из таких программ - переводчиков.
III. Теоретическая часть.
Компьютерные словари.
Словари необходимы для перевода текстов с одного языка на другой. Первые словари были созданы около 5 тысяч лет назад в Шумере и представляли собой глиняные таблички, разделенные на две части. В одной части записывалось слово на шумерском языке, а в другой — аналогичное по значению слово на другом языке, иногда с краткими пояснениями.
Современные словари построены по такому же принципу. В настоящее время существуют тысячи словарей для перевода между сотнями языков (англо-русский, немецко-французский и так далее), причем каждый из них может содержать десятки тысяч слов. В бумажном варианте словарь представляет собой толстую книгу объемом в сотни страниц, где поиск нужного слова является достаточно трудоемким процессом.
Компьютерные словари могут содержать переводы на разные языки сотен тысяч слов и словочетаний, а также предоставляют пользователю дополнительные возможности.
Во-первых, компьютерные словари могут являться многоязычными, так как дают пользователю возможность выбрать языки и направление перевода (например, англо-русский, испано-русский и так далее).
Во-вторых, компьютерные словари могут кроме основного словаря общеупотребительных слов содержать десятки специализированных словарей по областям знаний (техника, медицина, информатика и др.).
В-третьих, компьютерные словари обеспечивают быстрый поиск словарных статей: «быстрый набор», когда в процессе набора слова возникает список похожих слов; доступ к часто используемым словам по закладкам; возможность ввода словосочетаний и др.
В-четвертых, компьютерные словари могут являться мультимедийными, то есть предоставлять пользователю возможность прослушивания слов в исполнении дикторов, носителей языка.
Системы машинного перевода.
Происходящая в настоящее время глобализация нашего мира приводит к необходимости обмена документами между людьми и организациями, находящимися в разных странах мира и говорящими на различных языках.
В этих условиях использование традиционной технологии перевода «вручную» тормозит развитие межнациональных контактов. Перевод многостраничной документации вручную требует длительного времени и высокой оплаты труда переводчиков. Перевод полученного по электронной почте письма или просматриваемой в браузере Web-страницы необходимо осуществить немедленно, и нет возможности и времени пригласить переводчика.
Системы машинного перевода позволяют решить эти проблемы. Они, с одной стороны, способны переводить многостраничные документы с высокой скоростью (одна страница в секунду) и, с другой стороны, переводить Web-страницы «на лету», в режиме реального времени. Лучшими среди российских систем машинного перевода считаются PROMT и «Сократ».
Системы машинного перевода осуществляют перевод текстов, основываясь на формальном «знании» языка (синтаксиса языка — правил построения предложений, правил словообразования) и использовании словарей. Программа-переводчик сначала анализирует текст на одном языке, а затем конструирует этот текст на другом языке.
Современные системы машинного перевода позволяют достаточно качественно переводить техническую документацию, деловую переписку и другие специализированные тексты. Однако они неприменимы для перевода художественных произведений, так как не способны адекватно переводить метафоры, аллегории и другие элементы художественного творчества человека.
Вопросы:
- Зачем нужны программы - переводчики?
- По какому принципу построены компьютерные словари?
- Какие тексты нецелесообразно переводить с помощью компьютерных переводчиков?
III. Практическая часть.
Теперь потренируемся работать с программой автоматизированного перевода текста - Сократ Персональный. Это программа из серии разработанных в России и выпущенных российской компанией АРСЕНАЛЪ программных продуктов. В серию программ Русский офис входит многим известный текстовый редактор Лексикон и другие программы.
Компания Арсеналъ разрешает работу незарегистрированной копии Сократ Персональный 4.0 в пробном режиме в течение 21 дня. Зарегистрировать программу можно на сайте компании.
Сократ - система перевода с английского на русский и наоборот Автоматически учитывает тематику текста Перевести документ можно с сохранением всех особенностей форматирования. Сократ можно использовать совместно с системой распознавания текстов FineReader для быстрого ввода документов со сканера и их перевода.
Версия Сократ Интернет переводит страницы WWW непосредственно в браузере. Странствуя по Сети, вы при желании видите как исходный текст Web-страниц на английском, немецком и французском языках, так и перевод на русский язык с сохранением оформления
Персональная версия системы Сократ "понимает" только английский, она переводит фрагменты текста из буфера обмена Windows, а также может служить в качестве англо-русского и русско-английского словаря. Очень удобна и для перевода сообщений встроенных справочных систем (HELP) англоязычных программ
Сократ-Словарь — оперативный помощник переводчика, оснащенный двухсторонними русско-английским и немецко-английским словарями Может быть дополнительно оснащен многочисленными словарями для перевода с одного европейского языка на другой
Профессиональная система перевода Сократ — наиболее мощный продукт, позволяющий использовать дополнительные тематические словари и создавать свои собственные, расширяя словарный запас.
Кроме базовой англо-русской версии, поставляется также версия с поддержкой немецкого и французского языков.
Запустите программу: Пуск→Все программы→Переводчики→Русский офис→Сократ Персональный.
Включите режим Словарь. При открытом окне программы для этого достаточно кликнуть по закладке Словарь. Рабочая область поделена на три части: окно словарной базы, поле ввода, окно перевода.
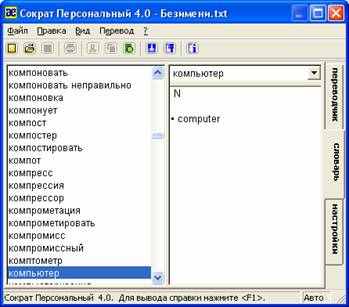
Получить перевод слова из словаря можно следующими способами:
- ввести слово в поле ввода. Перемещение по словарной базе осуществляется по мере ввода букв, до тех пор пока не будет получено максимально возможное совпадение.
- вставить слово в поле ввода из Буфера обмена. В этом случае будет осуществлен быстрый переход к тому слову, которое имеет максимально возможное совпадение с выбранным.
- выбрать ранее переведенное слово из окна истории поля ввода. В этом случае будет осуществлен быстрый переход к тому слову, которое имеет максимально возможное совпадение с введенным.
- выделить слово в другом приложении и удерживая клавишу Shift и щелкнуть по выделению правой кнопкой мыши. Во всплывающем окне будет выведен перевод выделенного слова.
- использовать сочетание Горячих клавиш, предварительно поместив необходимое слово в Буфер обмена.
Теперь включите режим Переводчика. При открытом окне программы для этого достаточно кликнуть по закладке Переводчик. Окно Переводчика поделено на 2 части: окно исходного текста (вверху) и окно перевода (внизу).
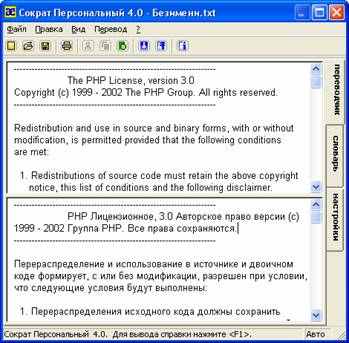
Наберите (или скопируйте) текст в верхнем окне закладки Переводчик. Для того, чтобы перевести введенный текст, нажмите кнопку Перевести на панели инструментов или в меню Перевод выберите команду Перевести. После этого в нижнем окне закладки появится перевод. Результаты перевода могут быть сохранены в файл или помещены в Буфер обмена.
Программа может также переводить текст из файла. Для этого в окне программы выберите пункт Открыть из меню Файл. Появится диалог открытия файлов. Откройте необходимый Вам файл. Программа самостоятельно выполнит перевод, поместив исходный текст в верхнее окно закладки Переводчик, а его перевод – в нижнее.
Кроме рассмотренных возможностей программа предоставляет перевод текста из буфера обмена, перевод текста в справке, быстрый перевод текста в других приложения… Как пользоваться этими возможностями вы можете узнать из справочной системы.
Для выхода из программы дайте команду Файл→Выход. При закрытии программы кнопкой закрыть программа остается работать и ее иконка помещается на Панель Задач Windows
 .
.Теперь откройте файл C:\Наш урок\Урок 25 Практика.doc и выполните перевод слов и текста.
Учащиеся выполняют задание.
IV. Д/з
Знать, что такое программы автоматического перевода текста, уметь работать с этими программами. Дополнительное задание: соединиться с Интернетом и используя какой-либо on-line переводчик перевести текст.
V. Вопросы учеников.
Ответы на вопросы учащихся.
VI. Итог урока.
Подведение итога урока. Выставление оценок.
На уроке мы познакомились с программами компьютерного перевода текстов, научились переводить слова и текст с помощью программы Сократ Персональный.
Урок №26.