Принятие управленческих решений невозможно без анализа данных. В сфере государственного и муниципального управления принятие решений сопряжено с обработкой больших объемов статистических данных – показателей, сопровождающих жизнедеятельность территории. Информация может быть организована в виде электронных таблиц, баз данных или информационных хранилищ. Для того, чтобы существующие информация способствовали принятию управленческих решений, она должна быть обработана с применением всего арсенала современных программных средств анализа.
Интеллектуальный анализ данных (добыча данных - Data Mining) - процесс аналитического исследования больших массивов информации (обычно экономического характера) с целью выявления определенных закономерностей и систематических взаимосвязей между переменными, которые затем можно применить к новым совокупностям данных.
Очень часто добыча данных трактуется как "смесь статистики, методов искусственного интеллекта и анализа баз данных". Поэтому в данном разделе предполагается, что читатель знаком с логикой статистических выводов в объеме таких дисциплин как статистика, эконометрика.
В общем случае процесс интеллектуальный анализ данных (ИАД) состоит из трех стадий:
выявление закономерностей (свободный поиск);
использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование);
анализ исключений, предназначенный для выявления и толкования аномалий в найденных закономерностях.
3.8.1. Методы интеллектуального анализа данных
Все методы интеллектуального анализа данных подразделяются на два больших класса по принципу работы с исходными обучающими данными (рис. 3.27.):
группа методов, опирающихся на известные закономерности, так называемые методы рассуждений на основе анализа прецедентов. Данные здесь могут храниться в явном детализированном виде и непосредственно использоваться для прогностического моделирования и (или) анализа исключений. Главная проблема этой группы методов — затрудненность использования при больших объемах данных, хотя именно при анализе больших хранилищ данных методы ИАД приносят наибольшую пользу.
группа методов, основанных на выявлении закономерностей в процессе свободного поиска. Здесь информация вначале извлекается из первичных данных и преобразуется в некоторые формальные конструкции (их вид зависит от конкретного метода), т.е. осуществляется выявление закономерностей в данных в процессе свободного поиска, что отсутствует в первой группе методов. Для прогностического моделирования и анализа исключений используются результаты этой стадии, которые гораздо более компактны, чем сами массивы исходных данных. При этом полученные конструкции могут быть либо «прозрачными» (интерпретируемыми), либо «черными ящиками» (нетрактуемыми).
Рис. 3.27. Классификация технологических методов
интеллектуального анализа данных
При добыче данных аналитика не очень интересует конкретный вид зависимостей между переменными задачи. Выяснение природы участвующих здесь функций или конкретной формы интерактивных многомерных зависимостей между переменными не является главной целью этой процедуры. Основное внимание уделяется поиску решений, на основе которых можно было бы строить достоверные прогнозы. Таким образом, в области добычи данных принят такой подход к анализу данных и извлечению знаний, который иногда характеризуют словами "черный ящик".
В области добычи данных наиболее часто используются:
классические приемы разведочного анализа данных;
нейронные сети, которые позволяют строить достоверные прогнозы, не уточняя конкретный вид тех зависимостей, на которых такой прогноз основан.
3.8.2. Разведочный анализ данных
Классический разведочный анализ данных:
применяется для нахождения связей между переменными в ситуациях, когда отсутствуют (или недостаточны) априорные представления о природе связей (традиционная проверка гипотез предназначена для подтверждения достаточных априорных предположений о связях между переменными, например, "Имеется положительная корреляция между возрастом человека и его/ее нежеланием рисковать");
учитывает и сравнивает большое число переменных, а для поиска закономерностей используются самые разные методы.
нацелен, таким образом, на выяснение природы явления (системы добычи данных в большей степени ориентированы на практическое приложение полученных результатов);
Методы разведочного анализа данных включают:
основные статистические методы,
методы многомерного анализа, предназначенные для отыскания закономерностей в многомерных данных, более сложные и специально разработанные;
графические методы.
К ссылка скрыта относится процедура анализа распределений переменных, просмотр корреляционных матриц с целью поиска коэффициентов, превосходящих по величине определенные пороговые значения (см. предыдущий пример), или анализ многовходовых таблиц частот (например, "послойный" последовательный просмотр комбинаций уровней управляющих переменных).
Дискриминантный анализ используется для принятия решения о том, какие переменные различают (дискриминируют) две или более возникающие совокупности (группы). Например, некий исследователь в области образования может захотеть исследовать, какие переменные относят выпускника средней школы к одной из трех категорий: (1) поступающий в колледж, (2) поступающий в профессиональную школу или (3) отказывающийся от дальнейшего образования или профессиональной подготовки. Для этой цели исследователь может собрать данные о различных переменных, связанных с учащимися школы. После выпуска большинство учащихся естественно должно попасть в одну из названных категорий. Затем можно использовать дискриминантный анализ для определения того, какие переменные дают наилучшее предсказание выбора учащимися дальнейшего пути.
Кластерный анализ включает в себя набор различных алгоритмов классификации. Общий вопрос, задаваемый исследователями во многих областях, состоит в том, как организовать наблюдаемые данные в наглядные структуры. Например, биологи ставят цель разбить животных на различные виды, чтобы содержательно описать различия между ними. В соответствии с современной системой, принятой в биологии, человек принадлежит к приматам, млекопитающим, амниотам, позвоночным и животным. В этой классификации, чем выше уровень агрегации, тем меньше сходства между членами в соответствующем классе. Человек имеет больше сходства с другими приматами (т.е. с обезьянами), чем с "отдаленными" членами семейства млекопитающих (например, собаками) и т.д. Общие методы кластерного анализа: объединение (древовидная кластеризация), двувходовое объединение и метод K средних.
Факторный анализ ставит целью сокращение числа переменных (редукция данных) и определение структуры взаимосвязей между переменными, т.е. классификацию переменных. Поэтому факторный анализ используется или как метод сокращения данных или как метод классификации.
Дисперсионный анализ ставит целью исследование значимости различия между средними. Более естественным был бы термин «анализ суммы квадратов» или «анализ вариации», но в силу традиции употребляется термин дисперсионный анализ.
Множественная регрессия ставит целью анализ связи между несколькими независимыми переменными и зависимой переменной (отклик). Позволяет исследователю задать вопрос (и, вероятно, получить ответ) о том, "что является лучшим предиктором для ...". Например, исследователь в области образования мог бы пожелать узнать, какие факторы являются лучшими условиями успешной учебы в средней школе, а психолога мог быть заинтересовать вопрос, какие индивидуальные качества позволяют лучше предсказать степень социальной адаптации индивида. Социологи, вероятно, хотели бы найти те социальные индикаторы, которые лучше других предсказывают результат адаптации новой иммигрантской группы и степень ее слияния с обществом. Термин "множественная" указывает на наличие нескольких предикторов или регрессоров, которые используются в модели.
Графические методы (визуализация данных). Широкий набор мощных методов разведочного анализа данных представлен также средствами графической визуализации данных. С их помощью можно находить зависимости, тренды и смещения, "скрытые" в неструктурированных наборах данных.
Самым распространенным и исторически первым из методов, которые можно отнести к графическому разведочному анализу данных является закрашивание. Закрашивание - интерактивный метод, позволяющий пользователю выбирать на экране компьютера отдельные точки-наблюдения или группы таких точек, находить их характеристики (в том числе общие) и изучать влияние отдельных наблюдений на соотношения между различными переменными.
К другим аналитическим графическим методам относятся подгонка и построение функций, сглаживание данных, наложение и объединение нескольких изображений, категоризация данных, расщепление или слияние подгрупп данных на графике, агрегирование данных, идентификация и маркировка подгрупп данных, удовлетворяющих определенным условиям, построение пиктографиков, штриховка, построение доверительных интервалов и областей, создание мозаичных структур, спектральных плоскостей, послойное сжатие, а также использование карт линий уровня, методов редукции выборки, интерактивного вращения и динамического расслоения трехмерных изображений, выделение определенных наборов и блоков данных.
Классические методы анализа доступны в программных пакетах Statistica, SyStat, программах электронных таблиц, например, доступном и широко используемом табличном процессоре MS Excel.
3.8.3. Нейронные сети
Статистические методы хорошо работают при большом объеме априорных данных, на практике количество данных может быть ограниченно. Поэтому часто для целей анализа и прогнозирования применяют нейронные сети, которые можно обучить на имеющемся наборе данных. Например, есть информация о деятельности нескольких десятков банков (их открытая финансовая отчетность) за некоторый период времени. По окончании этого периода известно, какие из этих банков обанкротились, у каких отозвали лицензию, а какие продолжают стабильно работать (на момент окончания периода). Необходимо решить вопрос о том, в каком из банков стоит размещать средства, т.е. решить задачу анализа рисков вложений в различные коммерческие структуры. В этом случае в качестве исходной информации используются данные финансовых отчетов различных банков, а в качестве целевого поля – итог их деятельности.
Нейронные сети – это класс аналитических методов, построенных на (гипотетических) принципах обучения мыслящих существ и функционирования мозга и позволяющих прогнозировать значения некоторых переменных в новых наблюдениях по данным других наблюдений (для этих же или других переменных) после прохождения этапа так называемого обучения на имеющихся данных.
При применении этих методов, прежде всего, встает вопрос выбора конкретной архитектуры сети (числа "слоев" и количества "нейронов" в каждом из них). Размер и структура сети должны соответствовать (например, в смысле формальной вычислительной сложности) существу исследуемого явления. Поскольку на начальном этапе анализа природа явления обычно не бывает хорошо известна, выбор архитектуры является непростой задачей и часто связан с длительным процессом проб и ошибок. В последнее время стали появляться нейронно-сетевые программы, в которых для решения этой трудоемкой задачи поиска "наилучшей" архитектуры сети применяются методы искусственного интеллекта.
Построенная сеть подвергается затем процессу так называемого "обучения". На этом этапе нейроны сети итеративно обрабатывают входные данных и корректируют свои веса таким образом, чтобы сеть наилучшим образом прогнозировала (в традиционных терминах следовало бы сказать "осуществляла подгонку") данные, на которых выполняется "обучение". После обучения на имеющихся данных сеть готова к работе и может использоваться для построения прогнозов. «Сеть», полученная в результате "обучения", выражает закономерности, присутствующие в данных. При таком подходе она оказывается функциональным эквивалентом некоторой модели зависимостей между переменными, подобной тем, которые строятся в традиционном моделировании.
Однако, в отличие от традиционных моделей, в случае "сетей" эти зависимости не могут быть записаны в явном виде, подобно тому, как это делается в статистике (например, "A положительно коррелировано с B для наблюдений, у которых величина C мала, а D - велика"). Иногда нейронные сети выдают прогноз очень высокого качества; однако, они представляют собой типичный пример нетеоретического подхода к исследованию (иногда это называют "черным ящиком"). При таком подходе сосредотачиваются исключительно на практическом результате - в данном случае - на точности прогнозов и их прикладной ценности, - а не на сути механизмов, лежащих в основе явления, или соответствии полученных результатов какой-либо имеющейся теории
Основателями теории нейронных сетей были Сантьяго Рамон-и-Кахаль, испанский гистолог, автор учения о нейроне как морфологической единице нервной системы (1894 г.), У. Маккалох, У. Питтс, Ф. Розенблатт, М.Минский, Дж. Хопфилд и др.
Фрэнк Розенблатт придумал нейронную сеть, названную перцептроном, и построил в 1957г. первый нейрокомпьютер Марк-1. Перцептрон был предназначен для классификации объектов. Розенблат придумал систему обучения подобных сетей. На этапе обучения «учитель» сообщает перцептрону к какому классу принадлежит предъявленный объект. Обученный перцептрон способен различать объекты, в том числе новые, не использовавшиеся при обучении.
В пятидесятые и шестидесятые годы группа исследователей, объединив эти биологические и физиологические подходы, создала первые искусственные нейронные сети. Выполненные первоначально как электронные сети, они были позднее перенесены в более гибкую среду компьютерного моделирования, сохранившуюся и в настоящее время. Нейронные сети были использованы для такого широкого класса задач, как предсказание погоды, анализ электрокардиограмм и искусственное зрение.
Следует отметить, что методы нейронных сетей могут применяться и в таких исследованиях, где целью является построение объясняющей модели явления, поскольку нейронные сети помогают изучать данные на предмет поиска значимых переменных или групп таких переменных, и полученные результаты могут облегчить процесс последующего построения модели. Более того, сейчас имеются нейросетевые программы, которые с помощью сложных алгоритмов могут находить наиболее важные входные переменные, что уже непосредственно помогает строить модель.
Одно из главных преимуществ нейронных сетей состоит в том, что они, по крайней мере, теоретически, могут аппроксимировать любую непрерывную функцию, т.е. описать любой процесс, и поэтому исследователю нет необходимости заранее принимать какие-либо гипотезы относительно модели, и даже - в ряде случаев - о том, какие переменные действительно важны. Однако существенным недостатком нейронных сетей является то обстоятельство, что окончательное решение зависит от начальных установок сети и, как уже говорилось выше, его практически невозможно "интерпретировать" в традиционных аналитических терминах, которые обычно применяются при построении теории явления.
Программное обеспечение для анализа данных с использованием нейросетевого подхода: Пакет Neural Connection, NeuroOffice, Neuro Builder, NeuroShell, NeuroWindows, SPSS.
3.8.4. Методы анализа данных в сфере бизнеса
В последнее время возрос интерес к разработке новых методов интеллектуального анализа данных, специально предназначенных для сферы бизнеса. Наиболее часто используются Деревья классификации.
Деревья классификации – это метод, позволяющий предсказывать принадлежность наблюдений или объектов к тому или иному классу категориальной зависимой переменной в зависимости от соответствующих значений одной или нескольких независимых переменных.

 Технологии интеллектуального анализа данных
Технологии интеллектуального анализа данных
 етоды многомерного анализа, предназначенные для отыскания закономерностей в многомерных данных, более сложные и специально разработанные;
етоды многомерного анализа, предназначенные для отыскания закономерностей в многомерных данных, более сложные и специально разработанные; рафические методы (визуализация данных). Широкий набор мощных методов разведочного анализа данных представлен также средствами графической визуализации данных. С их помощью можно находить зависимости, тренды и смещения, "скрытые" в неструктурированных наборах данных.
рафические методы (визуализация данных). Широкий набор мощных методов разведочного анализа данных представлен также средствами графической визуализации данных. С их помощью можно находить зависимости, тренды и смещения, "скрытые" в неструктурированных наборах данных. 
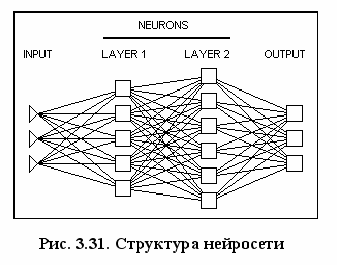 ри применении этих методов, прежде всего, встает вопрос выбора конкретной архитектуры сети (числа "слоев" и количества "нейронов" в каждом из них). Размер и структура сети должны соответствовать (например, в смысле формальной вычислительной сложности) существу исследуемого явления. Поскольку на начальном этапе анализа природа явления обычно не бывает хорошо известна, выбор архитектуры является непростой задачей и часто связан с длительным процессом проб и ошибок. В последнее время стали появляться нейронно-сетевые программы, в которых для решения этой трудоемкой задачи поиска "наилучшей" архитектуры сети применяются методы искусственного интеллекта.
ри применении этих методов, прежде всего, встает вопрос выбора конкретной архитектуры сети (числа "слоев" и количества "нейронов" в каждом из них). Размер и структура сети должны соответствовать (например, в смысле формальной вычислительной сложности) существу исследуемого явления. Поскольку на начальном этапе анализа природа явления обычно не бывает хорошо известна, выбор архитектуры является непростой задачей и часто связан с длительным процессом проб и ошибок. В последнее время стали появляться нейронно-сетевые программы, в которых для решения этой трудоемкой задачи поиска "наилучшей" архитектуры сети применяются методы искусственного интеллекта. остроенная сеть подвергается затем процессу так называемого "обучения". На этом этапе нейроны сети итеративно обрабатывают входные данных и корректируют свои веса таким образом, чтобы сеть наилучшим образом прогнозировала (в традиционных терминах следовало бы сказать "осуществляла подгонку") данные, на которых выполняется "обучение". После обучения на имеющихся данных сеть готова к работе и может использоваться для построения прогнозов. «Сеть», полученная в результате "обучения", выражает закономерности, присутствующие в данных. При таком подходе она оказывается функциональным эквивалентом некоторой модели зависимостей между переменными, подобной тем, которые строятся в традиционном моделировании.
остроенная сеть подвергается затем процессу так называемого "обучения". На этом этапе нейроны сети итеративно обрабатывают входные данных и корректируют свои веса таким образом, чтобы сеть наилучшим образом прогнозировала (в традиционных терминах следовало бы сказать "осуществляла подгонку") данные, на которых выполняется "обучение". После обучения на имеющихся данных сеть готова к работе и может использоваться для построения прогнозов. «Сеть», полученная в результате "обучения", выражает закономерности, присутствующие в данных. При таком подходе она оказывается функциональным эквивалентом некоторой модели зависимостей между переменными, подобной тем, которые строятся в традиционном моделировании. снователями теории нейронных сетей были Сантьяго Рамон-и-Кахаль, испанский гистолог, автор учения о нейроне как морфологической единице нервной системы (1894 г.), У. Маккалох, У. Питтс, Ф. Розенблатт, М.Минский, Дж. Хопфилд и др.
снователями теории нейронных сетей были Сантьяго Рамон-и-Кахаль, испанский гистолог, автор учения о нейроне как морфологической единице нервной системы (1894 г.), У. Маккалох, У. Питтс, Ф. Розенблатт, М.Минский, Дж. Хопфилд и др. последнее время возрос интерес к разработке новых методов интеллектуального анализа данных, специально предназначенных для сферы бизнеса. Наиболее часто используются Деревья классификации.
последнее время возрос интерес к разработке новых методов интеллектуального анализа данных, специально предназначенных для сферы бизнеса. Наиболее часто используются Деревья классификации.