
«Учебник по курсу «Информатика»
| Вид материала | Учебник |
- Темы рефератов по курсу «Информатика», 10.55kb.
- Тематическое планирование курса «Информатика и икт» в 10 классе на 2011-2012 уч год., 579.08kb.
- Практикум по курсу "Информатика", 153.44kb.
- Метод Кругов Эйлера Аннотация. Логические задачи, представленные в данной рабочей тетради,, 456.39kb.
- Б. А. Ильиш строй современного английского языка Учебник, 4106.86kb.
- Программа по курсу "Математика. Алгебра и геометрия" для специальности 080801 (351400), 143.45kb.
- «Информатика», 1976.18kb.
- Конспекты лекций по курсу «Информатика» Для студентов Аграрного факультета рудн, 699.31kb.
- П. А. Орлов История русской литературы XVIII века Учебник, 4388.68kb.
- Решение экономических задач компьютерными средствами > Информатика в экономике: Учебное, 721.96kb.
Проектирование реляционных баз данных
При проектировании базы данных решаются две основные проблемы:
- Каким образом отобразить объекты предметной области в абстрактные объекты модели данных, чтобы это отображение не противоречило семантике предметной области, и было, по возможности, лучшим (эффективным, удобным и т. д.)? Часто эту проблему называют проблемой логического проектирования баз данных.
- Как обеспечить эффективность выполнения запросов к базе данных? Эту проблему обычно называют проблемой физического проектирования баз данных.
В случае реляционных баз данных нет общих рецептов по части физического проектирования. Здесь слишком много зависит от используемой СУБД. Поэтому ограничимся только существенными вопросами логического проектирования реляционных баз данных. Более того, не будем касаться определения ограничений целостности общего вида, а ограничимся ограничениями первичного и внешнего ключей. Будем считать, что проблема проектирования реляционной базы данных состоит в обоснованном принятии решений о том, из каких отношений должна состоять базы данных, и какие атрибуты должны быть у этих отношений.
Классический подход к проектированию реляционных баз данных заключается в том, что сначала предметная область представляется в виде одного или нескольких отношений, а далее осуществляется процесс нормализации схем отношений, причем каждая следующая нормальная форма обладает свойствами лучшими, чем предыдущая. Каждой нормальной форме соответствует некоторый определенный набор ограничений, и отношение находится в некоторой нормальной форме, если удовлетворяет свойственному ей набору ограничений. Примером набора ограничений является ограничение первой нормальной формы – значения всех атрибутов отношения атомарны. Поскольку требование первой нормальной формы является базовым требованием классической реляционной модели данных, будем считать, что исходный набор отношений уже соответствует этому требованию.
В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм:
- первая нормальная форма (1NF);
- вторая нормальная форма (2NF);
- третья нормальная форма (3NF);
- нормальная форма Бойса-Кодда (BCNF);
- четвертая нормальная форма (4NF);
- пятая нормальная форма, или нормальная форма проекции-соединения (5NF или PJ/NF).
Основные свойства нормальных форм такие:
- каждая следующая нормальная форма в некотором смысле лучше предыдущей;
- при переходе к следующей нормальной форме свойства предыдущих нормальных свойств сохраняются.
Процесс проектирования реляционной базы данных на основе метода нормализации преследует две основные цели:
- избежать избыточности хранения данных;
- устранить аномалии обновления отношений.
Эти цели являются актуальными для информационных систем оперативной обработки транзакций (On-Line Transaction Processing – OLTP), которым свойственны частые обновления базы данных, и потому аномалии обновления могут сильно вредить эффективности приложения. В информационных системах оперативной аналитической обработки (On-Line Analytical Processing – OLAP), в частности, в системах поддержки принятия решений, базы данных в основном используются для выборки данных. Поэтому аномалиями обновления можно пренебречь. Из этого не следует, что принципы нормализации непригодны при проектировании баз данных OLAP-приложений. Даже если схема такой базы данных должна быть денормализована по соображениям эффективности, то чтобы получить правильную денормализованную схему, нужно сначала понять, как выглядит нормализованная схема.
В основе метода нормализации лежит декомпозиция отношения, находящегося в предыдущей нормальной форме, в два или более отношения, удовлетворяющих требованиям следующей нормальной формы. Считаются правильными такие декомпозиции отношения, которые обратимы, т. е. имеется возможность собрать исходное отношение из декомпозированных отношений без потери информации.
Наиболее важные на практике нормальные формы отношений основываются на фундаментальном в теории реляционных баз данных понятии функциональной зависимости.
Пусть R – это отношение, а Х и Y - произвольные подмножества множества атрибутов отношения R. Тогда Y функционально зависит от Х, что в символическом виде записывается как X -> Y в том и только в том случае, если каждому значению X соответствует в точности одно значение Y.
Представляют интерес такие функциональные зависимости, которые выполняются для всех возможных значений соответствующего отношения. Такие зависимости могут рассматриваться как инварианты, или ограничения целостности отношения.
Функциональная зависимость X -> Y называется полной, если атрибут Y не зависит функционально от любого точного подмножества X.
Функциональная зависимость X ->Y называется транзитивной, если существует такой атрибут Z, что имеются функциональные зависимости X -> Z и Z -> Y и отсутствует функциональная зависимость Z -> X.
Неключевым атрибутом называется любой атрибут отношения, не входящий в состав потенциального ключа (в частности, первичного).
Отношение R находится во второй нормальной форме (2NF) в том и только в том случае, когда находится в 1NF, и каждый неключевой атрибут полностью зависит от первичного ключа.
Отношение R находится в третьей нормальной форме (3NF) в том и только в том случае, если находится в 2NF и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
На практике третья нормальная форма схем отношений достаточна в большинстве случаев, и приведением к третьей нормальной форме процесс проектирования реляционной базы данных обычно заканчивается. Однако иногда полезно продолжить процесс нормализации.
Семантическое моделирование данных
Реляционная модель данных достаточна для моделирования предметных областей. Однако, проявляется ограниченность реляционной модели данных в следующих аспектах:
- Модель не предоставляет достаточных средств для представления смысла данных.
- Для многих приложений трудно моделировать предметную область на основе плоских таблиц.
- Хотя весь процесс проектирования происходит на основе учета зависимостей, реляционная модель не предоставляет каких-либо средств для представления этих зависимостей.
- Несмотря на то, что процесс проектирования начинается с выделения некоторых существенных для приложения объектов предметной области («сущностей») и выявления связей между этими сущностями, реляционная модель данных не предлагает какого-либо аппарата для разделения сущностей и связей.
Указанные ограничения вызвали к жизни направление семантических (концептуальных, инфологических) моделей данных. Любая развитая семантическая модель данных, как и реляционная модель, включает структурную, манипуляционную и целостную части. Главным назначением семантических моделей является обеспечение возможности выражения семантики данных. На практике семантическое моделирование используется на первой стадии проектирования базы данных. При этом в терминах семантической модели производится концептуальная схема базы данных, которая затем
- Либо вручную преобразуется к реляционной (или какой-либо другой) схеме.
- Либо реализуется автоматизированная компиляция концептуальной схемы в реляционную.
- Либо происходит работа с базой данных в семантической модели, т.е. под управлением СУБД, основанных на семантических моделях данных. (Третья возможность еще не вышла за пределы исследовательских и экспериментальных проектов.)
Наиболее известным представителем класса семантических моделей предметной области является модель «сущность-связь» или ER-модель, предложенная Питером Ченом в 1976 году ER-модель обычно представляется в графической форме, либо с использованием оригинальной нотации П. Чена, называемой ER-диаграмма, либо с использованием других графических нотаций. На практике понятия ER-модель и ER-диаграмма часто не различают, хотя для визуализации ER-моделей предложены и другие графические нотации. Основными понятиями ER-модели являются сущность, связь и атрибут (свойство).
Сущность - это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна. В диаграммах ER-модели сущность представляется в виде прямоугольника, содержащего имя сущности. При этом имя сущности - это имя типа, а не некоторого конкретного экземпляра этого типа. Для большей выразительности и лучшего понимания имя сущности может сопровождаться примерами конкретных объектов этого типа. Каждый экземпляр сущности должен быть отличим от любого другого экземпляра той же сущности (это требование в некотором роде аналогично требованию отсутствия кортежей-дубликатов в реляционных таблицах). Сущности подразделяются на сильные и слабые. Сильные сущности существуют сами по себе, а существование слабых сущностей зависит от существования сильных.
Связь - это ассоциация, устанавливаемая между сущностями. Эта ассоциация может существовать между разными сущностями или между сущностью и ей же самой (рекурсивная связь). Сущности, включенные в связь, называются ее участниками, а количество участников связи называется ее степенью. Участие сущности в связи может быть как полным, так и частичным. Связи в ER-модели могут иметь тип «один к одному», «один ко многим», «многие ко многим». Именно тип связи «многие ко многим» является единственным типом, представляющим истинную связь, поскольку это единственным тип связи, который требует для своего представления отдельного отношения. Связи типа «один к одному» и «один ко многим» всегда могут быть представлены с помощью механизма внешнего ключа, помещаемого в одно из отношений.
Свойством сущности (и связи) является любая деталь, которая служит для уточнения, идентификации, классификации, числовой характеристики или выражения состояния сущности (или связи). Значения свойств каждого типа извлекаются из соответствующего множества значений, которое в реляционной терминологии называется доменом. Свойства могут быть простыми или составными, ключевыми, однозначными или многозначными, опущенными (т. е. «неизвестными» или «непредставленными»), базовыми или производными.
Более сложными элементами ER-модели являются подтипы и супертипы сущностей. Как в языках программирования с развитыми типовыми системами (например, в языках объектно-ориентированного программирования), вводится возможность наследования типа сущности, исходя из одного или нескольких супертипов.
На ER-диаграммах множества сущностей изображаются в виде прямоугольников, множества отношений изображаются в виде ромбов. Слабый тип сущности изображают в виде прямоугольника с двойным контуром. Слабый тип связи изображают в виде ромба с двойным контуром. Если сущность участвует в отношении, они связаны линией. Тип связи с частичным участием изображают двойной линией. Вид типа связи обозначается над линиями в виде соответствующих надписей возле типов сущностей. Например, если это вид бинарной связи «один ко многим», то делают надписи 1, n (или m), соответственно, возле соответствующих типов сущностей. Атрибуты изображаются в виде овалов и связываются линией с одним отношением или с одной сущностью. Именование сущности обычно выражается уникальным существительным, именование связи обычно выражается глаголом, именование атрибута обычно выражается существительным. Неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности, являются ключом сущности.
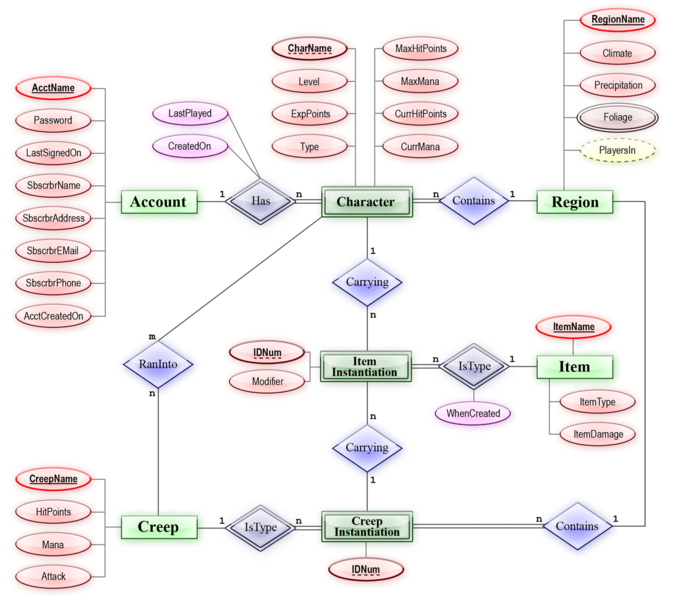
Существует множество инструментов для работы с ER-моделями, вот некоторые из них: Microsoft Visio, ERwin, Oracle Designer, PowerDesigner, Rational Rose. В справочниках приводятся сведения о 25 таких инструментах.
Получение реляционной схемы из ER-схемы осуществляется с помощью следующей пошаговой процедуры.
Шаг 1. Каждая простая сущность превращается в таблицу. Простая сущность - сущность, не являющаяся подтипом и не имеющая подтипов. Имя сущности становится именем таблицы.
Шаг 2. Каждый свойство (атрибут) становится возможным столбцом с тем же именем; может выбираться более точный формат. Столбцы, соответствующие необязательным атрибутам, могут содержать неопределенные значения; столбцы, соответствующие обязательным атрибутам, - не могут.
Шаг 3. Компоненты уникального идентификатора сущности превращаются в первичный ключ таблицы. Если имеется несколько возможных уникальных идентификаторов, выбирается наиболее используемый. Если в состав уникального идентификатора входят связи, к числу столбцов первичного ключа добавляется копия уникального идентификатора сущности, находящейся на дальнем конце связи (этот процесс может продолжаться рекурсивно). Для именования этих столбцов используются имена концов связей и/или имена сущностей.
Шаг 4. Связи «многие к одному» (и «один к одному») становятся внешними ключами. Т.е. делается копия уникального идентификатора с конца связи «один», и соответствующие столбцы составляют внешний ключ. Необязательные связи соответствуют столбцам, допускающим неопределенные значения; обязательные связи - столбцам, не допускающим неопределенные значения.
Шаг 5. Индексы создаются для первичного ключа (уникальный индекс), внешних ключей и тех атрибутов, на которых предполагается в основном базировать запросы.
Шаг 6. Если в концептуальной схеме присутствовали подтипы, то возможны два способа:
- все подтипы в одной таблице,
- для каждого подтипа - отдельная таблица.
Язык реляционных баз данных SQL
Из рассмотрения реляционной модели известно, что двумя фундаментальными языками запросов к реляционным базам данных являются языки реляционной алгебры и реляционного исчисления. При всей своей строгости и теоретической обоснованности, эти языки не стали стандартными языками реляционных СУБД. Юридическим и фактическим стандартом стал язык SQL (Structured Query Language – «язык структурированных запросов»).
SQL представляет собой некоторую комбинацию реляционного исчисления кортежей и реляционной алгебры, и был разработан в середине 70-х годов в компании IBM в рамках проекта экспериментальной реляционной СУБД System R. Деятельность по стандартизации SQL началась практически одновременно с появлением его первых коммерческих реализаций. В 1986 г. был принят стандарт ANSI, а в 1987 г. Этот стандарт был одобрен международной организацией по стандартизации (ISO). Время от времени выпускается пересмотренная версия этого стандарта; наиболее свежее обновление было выпущено в 2008 г. Формальное название стандарта SQL – ISO/IEC 9075 «Database Language SQL».
Несмотря на наличие международного стандарта, многие производители СУБД вносят изменения в язык SQL, тем самым отступая от стандарта. В результате у разных производителей СУБД в ходу разные диалекты SQL, в общем случае между собой несовместимые. В настоящее время проблема совместимости решается так: описание языка имеет модульную структуру, основная часть стандарта вынесена в раздел «SQL/Foundation», все остальные выведены в отдельные модули, остался только один уровень совместимости – «Core», что означает поддержку этой основной части. Поддержка остальных возможностей оставлена на усмотрение производителей СУБД.
При всех своих изменениях, SQL остаётся единственным механизмом связи между прикладным программным обеспечением и базой данных. В тоже время, современные СУБД предоставляют пользователю развитые средства визуального построения запросов. Хотя SQL и задумывался как средство работы конечного пользователя, в конце концов, он стал настолько сложным, что превратился в инструмент профессионального программиста.
Все операторы, составляющие основу SQL с момента его появления, можно разделить на следующие группы:
- операторы определения данных (Data Definition Language – DDL)
- CREATE создает объект базы данных
- ALTER изменяет объект
- DROP удаляет объект
- CREATE создает объект базы данных
- операторы манипуляции данными (Data Manipulation Language – DML)
- SELECT считывает данные, удовлетворяющие заданным условиям
- INSERT добавляет новые данные
- UPDATE изменяет существующие данные
- DELETE удаляет данные
- SELECT считывает данные, удовлетворяющие заданным условиям
- операторы определения доступа к данным (Data Control Language – DCL)
- GRANT предоставляет пользователю (группе) разрешения на определенные операции с объектом
- REVOKE отзывает ранее выданные разрешения
- DENY задает запрет, имеющий приоритет над разрешением
- GRANT предоставляет пользователю (группе) разрешения на определенные операции с объектом
- операторы управления транзакциями (Transaction Control Language – TCL)
- COMMIT применяет транзакцию.
- ROLLBACK откатывает все изменения, сделанные в контексте текущей транзакции.
- SAVEPOINT делит транзакцию на более мелкие участки.
- COMMIT применяет транзакцию.
Не вдаваясь в детали синтаксиса, в качестве примера приведем сценарий создания базы данных «Поставщики и детали», схема которой была рассмотрена ранее.
USE master
IF DB_ID (N'Поставщики и детали') IS NOT NULL
DROP DATABASE [Поставщики и детали]
GO
CREATE DATABASE [Поставщики и детали]
GO
USE [Поставщики и детали]
CREATE TABLE S
(
Sno INT IDENTITY(1,1) NOT NULL,
Sname VARCHAR(20) NOT NULL,
Status INT,
City VARCHAR(15)
)
CREATE TABLE P
(
Pno INT IDENTITY(1,1) NOT NULL,
Pname VARCHAR(20) NOT NULL,
Color CHAR(10),
Weight REAL,
City VARCHAR(15)
)
CREATE TABLE SP
(
Sno INT NOT NULL,
Pno INT NOT NULL,
Qty INT
)
ALTER TABLE S
ADD
CONSTRAINT PK_S PRIMARY KEY (Sno),
CONSTRAINT UK_S UNIQUE (Sname)
ALTER TABLE P
ADD
CONSTRAINT PK_P PRIMARY KEY (Pno)
ALTER TABLE SP
ADD
CONSTRAINT PK_SP PRIMARY KEY (Sno, Pno),
CONSTRAINT FK_SP_S FOREIGN KEY (Sno) REFERENCES S (Sno),
CONSTRAINT FK_SP_P FOREIGN KEY (Pno) REFERENCES P (Pno)
К приведенному сценарию можно дать следующие комментарии.
- Сценарий написан на диалекте SQL компании Microsoft (для Microsoft SQL Server), известном под названием Transact-SQL (T-SQL).
- Сценарии состоит из трех пакетов. Конец пакета отмечается командой GO.
- Специальная команда USE меняет контекст на указанную базу данных.
- Если идентификационный номер базы данных «Поставщики и детали» не NULL, то такая база данных уже существует и ее надо предварительно уничтожить. Для этой цели в начале сценария используется оператор IF.
- Свойство IDENTITY используется для получения автоматически увеличивающегося идентификационного номера поставщика и детали.
- Операторы CREATE TABLE и ALTER TABLE, включат в себя такие ограничения целостности, как ограничение целостности NULL, ограничение первичного ключа (PRIMARY КЕУ), ограничение уникальности (UNIQUE), ограничение внешнего ключа (FOREIGN КЕУ).
- Сценарий можно расширить, добавив значения по умолчанию (DEFUULT), ограничения общего вида (CHECK) и команды импорта файла данных в таблицы базы данных (BULK INSERT).
Среди других перечисленных операторов наибольшее значение для конечного пользователя имеет оператор SELECT, который извлекает строки из базы данных и позволяет делать выборку одной или нескольких строк или столбцов из одной или нескольких таблиц. Полный синтаксис инструкции SELECT сложен, однако основные предложения можно вкратце описать следующим образом:
[ WITH общее_табличное_выражение]
SELECT [ DISTINCT | ALL ] [ TOP выражение [ PERCENT ] ] { * | список_выбора } [ INTO новая_таблица ]
[ FROM список_табличных_источников ]
[ WHERE условие_поиска ]
[ GROUP BY group_by_выражение ]
[ HAVING условие_поиска ]
[ ORDER BY order_by_выражение [ ASC | DESC ] ]
Предложения, составляющие оператор SELECT, имеют следующий смысл:
- WITH задает временно именованный результирующий набор, который используется для организации рекурсивного запроса.
- SELECT определяет столбцы, возвращаемые запросом.
- DISTINCT указывает на то, что только уникальные строки могут появляться в результирующем наборе.
- ALL указывает на то, что в результирующем наборе могут появляться дублирующиеся строки. ALL применяется по умолчанию.
- TOP указывает на то, что только заданное число или процент строк будет возвращен из результирующего набора.
- * указывает на то, что все столбцы из всех таблицв предложении FROM должны быть возвращены.
- INTO создает новую таблицу и вставляет в нее строки результата выполнения запроса.
- FROM указывает таблицы или табличные выражения, которые используются в операторе SELECT.
- WHERE определяет условия поиска строк, возвращаемых запросом.
- GROUP BY задает группы, в которые должны быть помещены строки вывода.
- HAVING определяет условие поиска для группы.
- ORDER BY указывает порядок сортировки для столбцов, возвращаемых оператором SELECT.
Из перечисленных предложений оператора SELECT наиболее часто используются SELECT, FROM и WHERE. Если исключить все опции предложения SELECT, то получается такая простая конструкция:
SELECT { * | список_выбора }
FROM список_табличных_источников
WHERE условие_поиска
Не углубляясь в детали синтаксиса даже такой простой конструкции, рассмотрим несколько примеров, раскрывающих наиболее важные моменты. Примеры в точности соответствуют тем, которые рассматривались в разделе реляционной алгебры.
- Получить имена поставщиков, которые поставляют деталь под номером 2.
SELECT DISTINCT S.Sname
FROM S
WHERE EXISTS ( SELECT *
FROM SP
WHERE SP.Sno = S.Sno AND SP.Pno = 2)
- Получить имена поставщиков, которые поставляют, по крайней мере, одну красную деталь.
SELECT DISTINCT S.Sname
FROM S
WHERE S.Sno IN ( SELECT SP.Sno
FROM SP
WHERE SP.Pno IN ( SELECT P.Pno
FROM P
WHERE P.Color = 'Красный'))
- Получить имена поставщиков, которые поставляют все типы деталей.
SELECT DISTINCT S.Sname
FROM S
WHERE NOT EXISTS (SELECT *
FROM P
WHERE NOT EXISTS (SELECT *
FROM SP
WHERE SP.Sno = S.Sno AND SP.Pno = P.Pno))
- Получить номера поставщиков, поставляющих, по крайней мере, все те детали, которые поставляет поставщик под номером 2.
- Получить все пары номеров поставщиков, размещенных в одном городе
SELECT A.Sno AS SA, B.Sno AS SB
FROM S AS A, S AS B
WHERE A.City = B.City AND A.Sno < B.Sno
- Получить имена поставщиков, которые не поставляют деталь под номером 2.
SELECT DISTINCT S.Sname
FROM S
WHERE NOT EXISTS (SELECT *
FROM SP
WHERE SP.Sno = S.Sno AND SP.Pno = 2)