
А. В. Брешенков Проектирование баз данных на основе информации табличного вида Допущено в качестве учебного пособия для студентов высших учебных заведений, обучающихся по направлению подготовки диплом
| Вид материала | Диплом |
Содержание5.2. Алгоритмы назначения ключевых полей в заполненных реляционных таблицах |
- Учебное пособие Допущено Министерством образования Российской Федерации в качестве, 2582.59kb.
- Д. В. Андреев Программирование микроконтроллеров mcs-51, 2064.3kb.
- И. В. Борискина, А. А. Плотников, А. В. Захаров проектирование современных оконных, 1699.55kb.
- «История нового времени», 4001.1kb.
- Учебное пособие. 3-е изд., испр и доп, 125.38kb.
- М. В. Ломоносова Хрестоматия по истории государства и права зарубежных стран, 11295.75kb.
- В. В. Крупица Личность Коллектив Стиль отношений (социально-психологический аспект), 4876.34kb.
- И. М. Синяева, В. М. Маслова, В. В. Синяев сфера, 5230.77kb.
- И. К. Корнеев информационная безопасность и защита информации учебное пособие, 7667.6kb.
- Курслекций допущено умо по образованию в области социальной работы в качестве учебного, 2178.14kb.
5.2. Алгоритмы назначения ключевых полей в заполненных реляционных таблицах
При разработке алгоритмов логично выделить 3 ситуации: таблица состоит из одного поля; таблица состоит из нескольких полей, число которых не равно максимально возможному количеству полей для конкретной СУБД; таблица состоит из полей, число которых равно максимально возможному количеству полей для конкретной СУБД.
Если таблица состоит из одного поля, то его естественно назначить в качестве первичного ключа. Однако это решение, может быть, придется пересмотреть в процессе формирования связей между таблицами. В частности, если эта таблица с одним атрибутом справочного характера и ее поля используются для выбора значения поля для другой таблицы, то этот атрибут нельзя задействовать в качестве первичного ключа. Множество атрибутов таблицы в случае одного поля вырождается в один атрибут: А = {А1}. Множество значений по этому атрибуту: К1 = {К11, К12,…, К1n} должно удовлетворять требованию уникальности, т.е. К1i К1j; i = 1, n; j = 1, n; i j . Для обеспечения этого необходимо на основе отношения R1 степени 1 построить другое отношение R2 степени 1, мощность которого будет меньшей или равной мощности отношения R1. В терминах SQL необходимо выполнить следующий запрос на создание таблицы: SELECT DISTINCT R1.A1 INTO R2 FROM R1;
Назначение поля ключом возможно только в том случае, если тип атрибута А1 не является MEMO, OLE, LOB (в различных СУБД различные типы). В противном случае необходимо сформировать новое отношение R3 на основе отношения R1 с множеством атрибутов А = {А1, А2}. При этом нужно сформировать n значений по атрибуту К2 = {К21, К22,…, К2 n}, причем необходимо обеспечить условие К2i К2j; i = 1, n; j = 1, n; i j.
В физической реализации это сводится к назначению нового поля в таблицу, все значения которого уникальны. Проще всего в данном случае назначить новому полю тип – “счетчик”. Тогда автоматически сформируются уникальные значения этого поля для всех записей таблицы. Следует иметь в виду, что не во всех СУБД реализована возможность определения новых полей в заполненных таблицах, а тем более назначения их ключевыми. Поэтому эти манипуляции надо выполнять в СУБД, в которых они допустимы (например, в Microsoft Access), а затем экспортировать преобразованные таблицы в целевую СУБД.
Если таблица включает в себя несколько полей, число которых не равно максимально возможному числу для инструментальной СУБД, то необходимо найти такое сочетание атрибутов, чтобы для всех записей таблицы их значения были бы уникальны. Пусть отношение R1, на котором построена таблица базируется на p – атрибутах А = {А1, А2, …, Аp}. Атрибут Ai имеет в таблице множество значений Кi = {Кi1, Кi2, …, Кin}. Атрибут Aj имеет в таблице множество значений Кj = {Кj1, Кj2, …, Кjm}. Так как таблица имеет фиксированное количество записей, то n и m имеют конкретные значения и в рассматриваемом случае n = m и равно числу записей таблицы. Необходимо найти кортеж атрибутов КА = {КА1, КА2, …, КАr}, КА А такой, что все кортежи их значений были уникальны. В таком случае мы имеем r-множество значений по числу атрибутов в кортеже КА, мощность каждого множества n – по числу строк
КК1 = {КК11, КК12, …, КК1n},
…
ККi = {ККi1, ККi2, …, ККin},
…
ККr = {ККr1, ККr2, …, ККrn}.
Тогда должно быть выполнено условие (1):
{КК11, …, ККi1, …, ККr1} …
{КК12, …, КKi2, …, ККr2} …
{КК1n, …, КKin, …, ККrn}.
Таким образом, необходимо выбрать кортеж атрибутов КА такой, чтобы выполнялось условие (1), которое обеспечивает уникальность сложного ключа. С другой стороны, важно обеспечить другое требование к первичному ключу – минимальность. Для реализации этого требования нужно стремиться к минимизации числа полей, входящих в первичный ключ, т.е. к минимизации размера кортежа КА. Кроме того, необходимо учитывать длину полей и в качестве претендентов на поля, включаемые в первичный ключ, выбирать поля с минимальной длиной. Кроме того, нельзя рассматривать в качестве претендентов поля, включаемые в первичный ключ поля с определенными типами – MEMO, OLE ,LOB.
Основываясь на вышесказанном, можно неформально, а затем и формально описать целевую функцию назначения первичного ключа. Суть ее состоит в том, что необходимо, отталкиваясь от требования минимальности, исключая недопустимые поля, найти совокупность атрибутов таблицы, суммарные значения которых бы не совпадали. Формальное описание целевой функции несколько громоздко и здесь не приводится. Методика назначения ключевого поля носит итерационный характер – ищется самый оптимальный путь, затем ведется поиск компромисса до тех пор, пока это возможно. Суть оптимального пути – поиск допустимого атрибута с минимальной длиной, значения которого уникальны. Суть компромисса сводится к тому, что ищется набор допустимых атрибутов с минимальной общей длиной, суммарные значения которых уникальны. При этом процесс поиска такого набора может прекратиться не только по достижению уникальности их значений, но и в том случае, когда из-за критического значения суммарной длины атрибутов станет целесообразно введение дополнительного поля и назначение его ключом.
Под критическим значением суммарной длины атрибутов понимается такое значение, которое требует расхода памяти на формирование ключа, превышающего расход памяти на введение дополнительного поля.
Поиск оптимального варианта состоит в следующем.
Перебираются все атрибуты Ai; i=1,r; A Ai; ТАi N, где ТА – тип атрибута, N = {MEMO, OLE, LOB}.
Для каждого атрибута проверяется условие (1). В рассматриваемом случае каждое множество вырождается в один элемент, и условие выглядит следующим образом:
{KKi1} {KKi2} … {KKin}.
Если условие выполняется, то запоминается имя атрибута и его длина. По завершению перебора проверяется, есть ли атрибуты, удовлетворяющие условию (1). Если таковые есть, то выбирается атрибут с минимальной длиной, и он назначается в качестве ключевого атрибута. Для организации такого поиска можно использовать относительно несложную хранимую процедуру. Если условию (1) не удовлетворяет ни один атрибут, осуществляется переход к поиску решения, при котором в качестве ключа назначается несколько атрибутов.
Формализованная методика выбора ключевого поля в этом случае выглядит следующим образом.
П1. Для множества LA = {LA1, … LAi, …,LAr} ищется min(LA), где LAi - длина атрибута Ai (физически это выражается количеством байтов, отводимым для значений Ai).
П2. Предположим min(LA) = LАk. Тогда выполняется анализ всех возможных пар атрибутов Ak и Ai, i k, i = 1, r, где r – число атрибутов таблицы и проверяется условие (1), которое в этом случае будет выглядеть следующим образом:
{KKk1, KKi1} {KKk2, KKi2} … {KKkn, KKin}, где n – число строк таблицы. Если данное условие выполняется, то запоминается атрибут Ai и его длина.
П3. После завершения перебора ищется min(LAN), где LAN – длины найденных атрибутов. Предположим min(LAN) = LAq, тогда в качестве первичного ключа назначается сложный ключ AkAq.
П4. Если условие (1) не выполняется ни для одной пары атрибутов Ak и Ai, то ищется min(LA-1), где LA-1 = {LA1, …, LAi, …LAr-1}, LA LA-1k. Предположим min(LA-1) = LAk1, тогда выполняется анализ всех возможных пар атрибутов Ak1 и Ai i k, i k1, i = 1, r-1 и проверяется условие (1) по аналогии с П2. Далее выполняются действия аналогичные действиям П3. Если условие (1) не выполняется ни для одной пары атрибутов Ak1 и Ai, то ищется min(LA-2), где LA-2 = {LA1, …LAi, … LAp-2}, LAk LA-2 , LAk1 LA-2
Итерации такого рода осуществляются до тех пор, пока не выполнится условие (1) или не исчерпаются все атрибуты таблицы.
Если условие (1) так и не выполнилось, то это означает, что первичный ключ на основе 2-х атрибутов назначить невозможно. В случае наличия в таблице всего 2-х атрибутов необходимо ввести дополнительное поле и назначить его ключевым полем.
Если в таблице более 2-х атрибутов и ключ из 2-х атрибутов сформировать не удалось, необходимо найти компромисс между введением дополнительного неинформативного атрибута и неоправданным использованием памяти для сложного ключа из 3-х полей. Для этого надо “измерить” суммарные длины всех возможных сочетаний троек атрибутов (в случае 3-х атрибутов будет одно сочетание). Если минимальная суммарная длина сочетания превышает 4 байта, то компромисс разрешается в пользу введения дополнительного поля и назначения его ключевым полем. В противном случае имеет смысл попытаться найти три атрибута для формирования сложного ключа.
Суммарная длина сравнивается с 4-мя байтами в связи с тем, что поле типа “счетчик”, которое имеет смысл использовать в качестве дополнительного, имеет длину 4 байта.
В формализованном виде методика поиска первичного ключа в этом случае выглядит следующим образом.
П1. Ищется min(LA3); LA3 = {LA31, LA32, …LA3i, …LA3j, …LA3n};
LA3i = lenqth(Aqj) + lenqth (Apj) + lenqth (Atj),
qi = 1, n; pi = 1, n; ti = 1, n; qi pi ti ,
LA3j = lenqth(Aqj) + lenqth (Apj) + lenqth (Atj) ;
qj = 1, n; pj = 1, n; tj = 1, n; qj pj tj;
(qi qj ) (pi pj) (ti tj).
Если min(LA3) 4 байт, то поиск атрибутов, из которых можно сформировать первичный ключ, прекращается, вводится дополнительный атрибут и назначается ключевым атрибутом. В противном случае выполняется переход к П2.
П2. Предположим, что min(LA3) = LA3k, тогда анализируется AK = {Aqk, Apk, Atk}; AAК.
Имеется три множества значений атрибутов:
KKqk = {KKqk1, …, KKqki, …, KKqkn},
KKpk = {KKpk1, …, KKpki, …, KKpkn},
KKtk = {KKtk1, …, KKtki, …, KKtkn}, где n – число записей таблицы.
Необходимо проверить условие:
{KKqk1, KKpk1,KKtk1}, …,{KKqki, KKpki, KKtki},…,{KKqkn, KKpkn, KKtkn}. (2)
Если это условие выполняется, то тройка атрибутов АК принимается в качестве сложного ключа. Процесс завершается. В противном случае выполнятся переход к П3.
П3. Ищется min(LA3-1); LA3 LA3-1; LA3 LA3k.
Предположим, что min(LA3-1) = LA3k1. Если LA3k1 4 байт, то вводится дополнительный атрибут и назначается ключевым атрибутом. Процесс завершается. В противном случае анализируется тройка атрибутов АК1 по аналогии с П2. Если условие (2) выполняется, то тройка атрибутов АК1 принимается в качестве сложного ключа и процесс завершается. В противном случае ищется min(LA3-2); LA3 LA3-2; LA3 LA3k ; LA3 LA3k1 и выполняется анализ в соответствии с П3.
Как следует из последней рекомендации, процесс поиска описывается рекурсивно, что позволяет сделать вывод о возможности использования для реализации предложенной методики рекурсивных процедур.
Если в процессе поиска 3-х ключевых атрибутов с уникальными значениями таковых не найдется, то распространять поиск на 4-е и более атрибутов не имеет смысла. Исходя из опыта работы с СУБД, сделан вывод, что использование 4-х и более полей для формирования сложного ключа неоправданно. Это связано с тем, что в подавляющем большинстве случаев их суммарная длина велика и, кроме того, более 4-х полей, входящих в ключевое поле, плохо воспринимаются пользователями БД. Это экспериментально доказано при выполнении ряда реальных разработок. В этом случае вводится дополнительное поле и назначается ключевым полем.
В третьей ситуации, когда таблица состоит из полей, число которых равно максимально возможному количеству полей конкретной СУБД, поиск атрибутов для формирования первичного ключа осуществляется в соответствии с методикой, рассмотренной выше. Однако, когда возникает необходимость введения нового поля и назначения его в качестве ключевого, то это выполнить невозможно, так как будет превышено допустимое число атрибутов. Такое случается редко. Если же это произошло необходимо выявить атрибуты, у которых все значения пустые. Как показывает опыт, такие атрибуты находятся - столбцы сформированы на всякий случай. Затем нужно предложить потенциальному пользователю БД выбрать из числа найденных атрибутов ненужный, переопределить его тип и назначить ключевым. Если же пользователь БД настаивает на необходимости всех атрибутов, то нужно проанализировать таблицу на возможность нормализации (в некоторых СУБД, в частности в Microsoft Access, это можно автоматизировать). Если нормализация возможна, то таблица преобразуется в две и более таблиц, а их первичные и внешние ключи назначаются, исходя из условий нормализации. Процесс же назначения ключевых полей в данном случае в основном относится к аспектам формирования реляционных таблиц на основе информации, представленной в табличной форме и формированию связей между таблицами. Если рассматриваемая таблица не нормализуется, то ее можно разбить на две таблицы, затем в каждой таблице ввести дополнительные поля, назначить их ключевыми полями и реализовать связь один - к одному по этим полям.
Выполним назначения первичного ключа на основе средств СУБД Microsoft Access. В качестве исходных данных возьмем реальную таблицу, сформированную в формате Microsoft Excel и представленную на рис. 5.2.1.
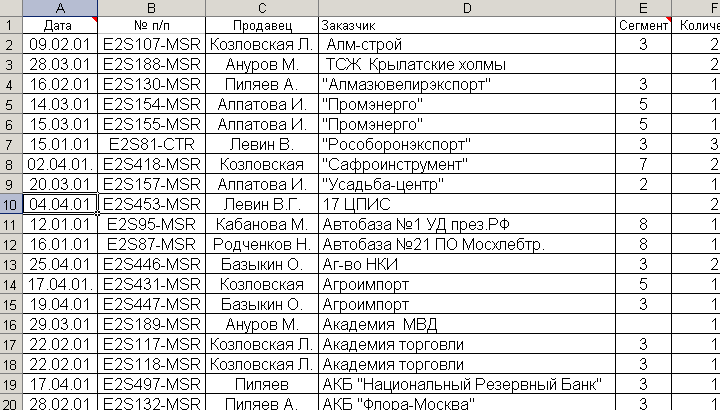
Рис. 5.2.1. Исходная таблица, сформированная в формате Microsoft Excel
После импорта этой таблицы Microsoft Access с выполнением всех необходимых манипуляций она примет вид рис 5.2.2.
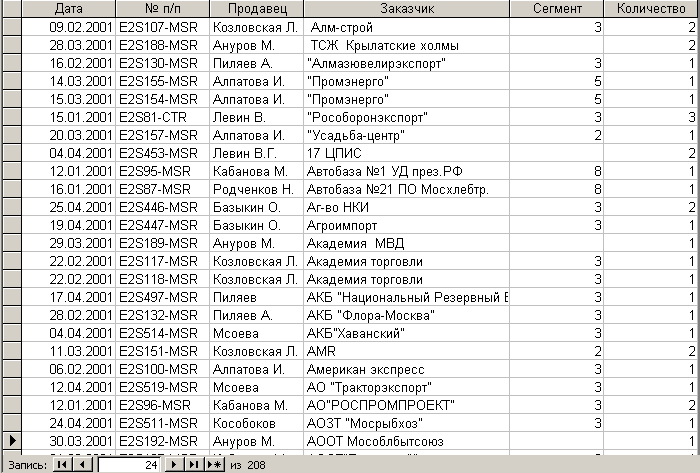
Рис. 5.2.2. Таблица, импортированная в Microsoft Accesss
Прежде, чем выполнять манипуляции по назначению первичного ключа, необходимо выяснить у разработчиков представленной таблицы Microsoft Excel, предполагалось ли в каком-либо поле таблицы использование уникальных значений. Если такое поле предполагалось, то необходимо построить запрос на выявление повторяющихся значений в указанном столбце. Затем, если обнаружится дублирование значений полей, необходимо вместе с разработчиком сделать нужные исправления.
Если к разработчику таблицы нет доступа, то выявление ключевого столбца придется осуществлять исходя из визуального анализа таблицы или в соответствии с предложенным алгоритмом.
Так как таблица включает в себя чуть больше двухсот записей, то можно попытаться визуально определить столбец с уникальными значениями. Явными претендентами на такие столбцы являются первый и второй столбцы, так как первые двадцать значений этих столбцов не дублируются. В остальных столбцах, даже в начальных двадцати записях, наблюдается дублирование значений. Для выявления дублирования значений полей можно построить соответствующий запрос, а если записей немного, проще всего отсортировать записи по нужному столбцу и оценить дублирование визуально. На рис. 5.2.3. приведена часть значений 1-го отсортированного столбца.
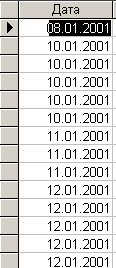
Рис. 5.2.3. Отсортированные значения 1-го столбца
Даже из анализа начальных значений столбца, становится очевидным дублирование его значений. Таким образом, в качестве ключевого столбца данный столбец использован быть не может.
Выполним сортировку значений второго столбца, Несколько отсортированных значений второго столбца представлено на рис. 5.2.4.

Рис. 5.2.4. Отсортированные значения 2-го столбца
Визуальный анализ первых значений данного столбца позволяет предположить, что он может претендовать на ключевой столбец. Действительно, начальные значения не совпадают. После просмотра всех значений данного столбца повторяющихся значения не обнаружено. Поэтому можно открыть таблицу в режиме Конструктора и назначить данное поле ключевым полем. Однако при попытке выхода из режима Конструктора система выдает сообщение, представленное на рис 5.2.5.
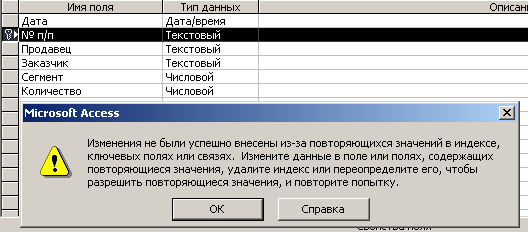
Рис. 5.2.5. Сообщение системы при попытке выхода из режима Конструктора
Данное сообщение свидетельствует о том, что все-таки визуально не удалось выявить повторяющиеся значения второго столбца.
В связи с этим следует выполнить запрос вида:
SELECT Заказы.[№ п/п], Заказы.Дата
FROM Заказы
WHERE Заказы.[№ п/п] In (SELECT [№ п/п] FROM [Заказы] GROUP BY [№ п/п] HAVING Count(*)>1 );
С помощью конструкций “SELECT Заказы.[№ п/п], Заказы.Дата FROM Заказы” выводятся поля “Заказы.[№ п/п]” и “Заказы.Дата” из таблицы “Заказы”, которые удовлетворяют условию, указанному в конструкции WHERE
В этом запросе вся сложность в конструкции WHERE. Здесь выбираются только те записи, для которых выполняется сложное условие, включающее в себя конструкцию “SELECT”. Конструкция “SELECT” выбирает поле [№ п/п] из таблицы “Заказы”, которая посредством конструкции ”GROUP BY [№ п/п]” сгруппирована по этому полю. Причем выбираются только те поля, у которых количество повторений больше единицы. Отбор осуществляется посредством условия ”HAVING Count(*)>1”.
Таким образом, выводятся только те значения поля “Заказы.[№ п/п]”, которые входят в результат выполнения внутренней команды “SELECT”. Оператор вхождения - ”In”.
Следует отметить, что в рамках системы Microsoft Access имеется специальный Мастер для проектирования запросов на просмотр повторяющихся записей. Однако запрос, построенный с помощью мастера, в виде соответствующей SQL-команды выглядит несколько сложнее.
Результат выполнения данного запроса приведен на рис. 5.2.6.
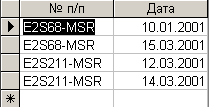
Рис. 5.2.6. Результат выполнения запроса на просмотр повторяющихся значений поля
К сожалению, данное поле тоже не подходит на роль ключевого поля. Поэтому, если действовать формально и в соответствии с предложенным выше алгоритмом, необходимо попытаться сформировать первичный ключ из двух полей. И действительно, если выполнить запрос на проверку повторения значений двух первых полей, то в результате получится пустой список записей, приведенный на рис. 5.2.7.
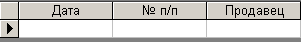
Рис. 5.2.7. Пустой список записей
Соответствующий запрос выглядит следующим образом:
SELECT Заказы.Дата, Заказы.[№ п/п], Заказы.Продавец
FROM Заказы
WHERE Заказы.Дата In (SELECT [Дата] FROM [Заказы] GROUP BY [Дата],[№ п/п] HAVING Count(*)>1 And [№ п/п] = [Заказы].[№ п/п]);
После открытия таблицы в режиме Конструктора и назначения двух первых полей в состав ключа, ошибки не произойдет.
Однако в данном случае, вероятнее всего мы имеем дело с ошибками ввода значений. Действительно, трудно предположить, что из двухсот значений только два из них совпадают. Поэтому в данном конкретном случае имеет смысл изменить повторяющиеся значения, пометив их характерным символом, например символом “#”. А затем предоставить Заказчику возможность ввести правильные значения. Само же поле после этого использовать в качестве ключевого. Изменение такого рода приведено на рис. 5.2.8.

Рис. 5.2.8. Измененное значение поля претендента на ключевое поле
Таким образом, для небольших таблиц вполне оправданно задействовать творческое начало разработчика БД и принять решение о назначении ключевых полей на основе использования стандартных средств СУБД и визуального анализа таблиц.