
А. В. Брешенков Проектирование баз данных на основе информации табличного вида Допущено в качестве учебного пособия для студентов высших учебных заведений, обучающихся по направлению подготовки диплом
| Вид материала | Диплом |
Содержание4.6. Преобразование заполненных таблиц к четвертой нормальной форме. |
- Учебное пособие Допущено Министерством образования Российской Федерации в качестве, 2582.59kb.
- Д. В. Андреев Программирование микроконтроллеров mcs-51, 2064.3kb.
- И. В. Борискина, А. А. Плотников, А. В. Захаров проектирование современных оконных, 1699.55kb.
- «История нового времени», 4001.1kb.
- Учебное пособие. 3-е изд., испр и доп, 125.38kb.
- М. В. Ломоносова Хрестоматия по истории государства и права зарубежных стран, 11295.75kb.
- В. В. Крупица Личность Коллектив Стиль отношений (социально-психологический аспект), 4876.34kb.
- И. М. Синяева, В. М. Маслова, В. В. Синяев сфера, 5230.77kb.
- И. К. Корнеев информационная безопасность и защита информации учебное пособие, 7667.6kb.
- Курслекций допущено умо по образованию в области социальной работы в качестве учебного, 2178.14kb.
4.6. Преобразование заполненных таблиц к четвертой нормальной форме.
Для формулировки и пояснения цели рассмотрим пример приведенный в форме табл. 4.6.1.
Т а б л и ц а 4.6.1.
| № | Песня | Слова | Музыка | Исполнитель | Звание исполнителя |
| 1 | П1 | С1 | М1 | И1 | Н |
| 2 | П2 | С2 | М2 | И2 | З |
| 3 | П3 | С3 | М3 | И3 | А |
| 4 | П1 | С1 | М1 | И2 | З |
| 5 | П1 | С1 | М1 | И3 | А |
| 6 | П2 | С2 | М2 | И1 | Н |
| 7 | П2 | С2 | М2 | И3 | А |
| 8 | П3 | С3 | М3 | И2 | З |
| 9 | П3 | С3 | М3 | И1 | Н |
Для компактности примера при записи значений атрибутов использованы мнемонические обозначения.
Суть примера в том, что одну и ту же песню могут исполнять несколько исполнителей. В таблице представлены 3 песни и 3 исполнителя. Если случится так, что каждый исполнитель поет все 3 песни, то для хранения данных об этом, как видно из примера, требуется 9 записей. Но для хранения информации о песнях и об исполнителях достаточно по 3-и записи (всего 6). В реальных таблицах эти цифры могут быть на несколько порядков больше.
Связи такого рода внутри таблицы называются множественными, и от них следует избавляться с тем, чтобы неоправданно не расходовать память.
При проектировании реляционных таблиц в соответствии с требованиями их нормализации [2] множественные зависимости не допускаются. В случае же заполненных таблиц зависимости такого рода вполне могут быть и от них необходимо избавляться.
Предлагается следующий способ избавления от многозначных зависимостей.
В таблице ищутся кортежи атрибутов, конкатенации значений которых встречаются неоднократно. Если такие кортежи находится, то вероятно имеет место многозначная зависимость. Для избавления от этой зависимости формируются таблицы с найденными кортежами атрибутов. В них исключаются повторяющиеся записи. Затем для каждой пары полученных таблиц строится таблица, которая обеспечивает связи записей этой пары между собой – таблица связей. Таблица связей строится на основе анализа исходной таблицы.
Прежде, чем предложить формальный алгоритм, проиллюстрируем алгоритм на примере.
После сканирования таблицы и анализа всех возможных кортежей атрибутов выявляются две группы кортежей атрибутов, конкатенации значений которых повторяются. Эти таблицы (отношения) R1 и R2, представлены ниже. Отношение R1 приведено в табл. 4.6.2. Отношение R2 приведено в табл. 4.6.3.
Т а б л и ц а 4.6.2 Т а б л и ц а 4.6.3
| Песня | Слова | Музыка | | Исполнитель | Звание исполнителя |
| П1 | С1 | М1 | И1 | Н | |
| П2 | С2 | М2 | И2 | З | |
| П3 | С3 | М3 | И3 | А | |
| П1 | С1 | М1 | И2 | З | |
| П1 | С1 | М1 | И3 | А | |
| П2 | С2 | М2 | И1 | Н | |
| П2 | С2 | М2 | И3 | А | |
| П3 | С3 | М3 | И2 | З | |
| П3 | С3 | М3 | И1 | Н |
В отношениях R1 и R2 исключаем дублирование записей. В результате получаем новые отношения R1' и R2’ (табл. 4.6.4 и табл. 4.6.5).
Т а б л и ц а 4.6.4 Т а б л и ц а 4.6.5
| Песня | Слова | Музыка | | Исполнитель | Звание исполнителя |
| П1 | С1 | М1 | И1 | Н | |
| П2 | С2 | М2 | И2 | З | |
| П3 | С3 | М3 | И3 | А |
Приписываем к отношениям R1’ и R2’ ключевые столбцы типа COUNTER. В результате таблицы примут вид табл. 4.6.6 и табл.4.6.7.
Т а б л и ц а 4.6.6 Т а б л и ц а 4.6.7
| Песня | Слова | Музыка | N1 | | N2 | Исполнитель | Звание исполнителя |
| П1 | С1 | М1 | 1 | 1 | И1 | Н | |
| П2 | С2 | М2 | 2 | 2 | И2 | З | |
| П3 | С3 | М3 | 3 | 3 | И3 | А |
Теперь перебираем все записи отношения R1. Для каждой записи ищем ее позицию в R1’, запоминаем ее в K1. В R2 выбираем соответствующую запись, ищем ее позицию в R2’, запоминаем ее в K2. Формируем новую запись отношения R3 = (K1, K2). Записываем K1, K2 в соответствующие поля отношения R3.
Например, 1-я запись в R1 находится в 1-й позиции R1’. K1 =1. Соответствующая запись в R2 находится в 1-й позиции R2’. K2 =1.
В результате перебора всех записей R1 и выполнения описанных действий будет сформировано отношение R3 вида (табл. 4.6.8).
Т а б л и ц а 4.6.8
-
К1
К2
1
1
2
2
3
3
1
2
1
3
2
1
3
2
3
1
Полученное отношение обеспечивает связь “ : ” между отношениями R1’ и R2’.
При необходимости можно сформировать запрос на основе таблиц R1’, R2’ и R3’, который позволит сформировать исходное отношение.
Даже в этом небольшом примере очевидна экономия памяти. В R задействовано 54 поля, в R1’, R2’ и R3 – 39 полей. На основе изложенного предлагается следующий формализованный алгоритм приведения заполненных таблиц к 4-й нормальной форме.
П1: Выявление групп кортежей атрибутов, конкатенации значений которых повторяются
FOR r = 1 то k–1, k NK
A = Ar
F = 0
FOR q = r + 1 то k-1, k NK
A = concat (A, Aq)
C = SELECT A FROM R GROUP BY A;
IF C = 1 THEN
A = A - Aq
ELSE
F = 1
END IF
NEXT q
IF F = 1 THEN PRINT(A)
NEXT r
Здесь IA – множество позиций атрибутов, конкатенации значений которых повторяются.
afr – значение атрибута Ar в f –ой строке.
k – степень R.
NK – номер ключевого атрибута;
Выражение SELECT A FROM R GROUP BY A; - SQL–подобная команда, позволяющая подсчитать количество повторяющихся значений с набором атрибутов А. Результат его выполнения – множество чисел. Каждое число соответствует количеству повторений какого–либо набора значений атрибутов.
С – множество этих чисел.
Выражение С = 1 означает, что повторений значений атрибутов нет. (С – единичное множество).
Выражение A = A - Aq означает исключение из конкатенации атрибутов атрибута Aq.
П2: Формирование таблиц без внутренних зависимостей.
R1 = Проекция A из R.
A1 = AR – A
R2 = Проекция A’ из R.
Исключение дублирования
R1’ = SELECT A FROM R1 GROUP BY A
R2’ = SELECT A FROM R2 GROUP BY A’
Здесь проекция A из R означает операцию реляционной алгебры – проекцию, которая выполняется над отношением R. Атрибуты проекции составляют множество A. Ограничений при выборе нет. Другими словами формируется таблица со столбцами из множества А.
AR – множество атрибутов R;
Строго говоря, при выполнении команды ”Проекция” дублирование записей исключается. Однако для большей прозрачности алгоритма и удобства его реализации приведены две последние команды.
Назначение R1’ и R2’ ключевых атрибутов
A = A + N1
A’ = A’ + N2,
где N1 – ключевой атрибут типа COUNTER для отношения R2', N2 – ключевой атрибут типа COUNTER для отношения R2’.
П3: Формирование таблицы для организации связей между R1’ и R2’.
FOR f = 1 то m
C1 = 0
FOR f1 =1 то m1
C1 = C1 + 1
IF Sf(R1) = Sf1(R1’) THEN GOTO M1
NEXT f1
M1: C2 = 0
FOR f2 = 1 то m2
C2 = C2 + 1
IF Sf (R2) = Sf2 (R2’) THEN GOTO M2
NEXT f2
M2: r3f,1 = C1
r3f,2 = C2
NEXT f
Здесь m - мощность R1, R2;
m1 – мощность R1’;
m2 – мощность R2’;
Sf (R2) – список значений f-й строки отношения R1.
Sf1(R1’) - список значений строки f1 отношения R1’ (из списка исключено значение ключевого атрибута).
Аналогично Sf (R2) и Sf2 (R2’).
r3f,1 – значение 1-го атрибута f-й строки отношения R3.
r3f,2 – значение 2-го атрибута f-й строки отношения R3.
Важно отметить, что предложенный алгоритм позволяет исключить одну множественную зависимость в отношении R. Не исключено, что в отношениях R1' и R2' могут также быть множественные зависимости, хотя это случается редко. Прерогатива разработчика – проверить R1' и R2' на наличие множественных зависимостей.
В случае необходимости с помощью соответствующего запроса из полученных 3-х отношений легко получить нужную информацию. Например, посредством запроса SELECT…формируется отношение R.
Выполним попытку нормализовать таблицу 4.6.1 стандартными средствами СУБД Microsoft Access. В формате Microsoft Access она представлена на рис. 4.6.1.
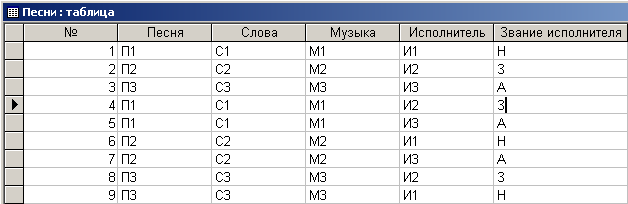
Рис. 4.6.1. Исходная таблица в формате Microsoft Access
После запуска мастера (меню Сервис/Анализ/таблица) и выбора данной таблицы Microsoft Access сформирует следующее сообщение (рис. 4.6.2).

Рис. 4.6.2. Сообщение Acces
Т.е. использование мастера не позволяет выполнить действия по приведению таблицы к 4-й нормальной форме. Мастер рекомендует использование средств самостоятельного разделения. Далеко не всегда в реальных таблицах с большим числом столбцов и записей разработчик может выделить поля, которые можно сгруппировать. Однако можно попытаться нормализовать таблицу посредством предлагаемых средств. Включение соответствующего мастера приведет к формированию окна мастера, приведенного на рис. 4.6.3.

Рис. 4.6.3. Окно мастера анализа таблиц
Если разработчик сможет догадаться, что поля “Исполнитель” и “Звание исполнителя” должны принадлежать отдельной таблице, то он может перетащить эти поля в новую таблицу. Результат преобразования представлен на рис 4.6.4.
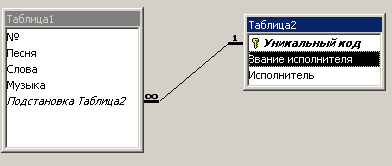
Рис. 4.6.4. Результат преобразования
К сожалению, если разработчик подозревает о наличии связи многие - ко многим, с использованием рассматриваемых средств он не сможет создать третью объединяющую таблицу. Поэтому будет сформировано две таблицы (рис. 4.6.5 и рис. 4.6.6).
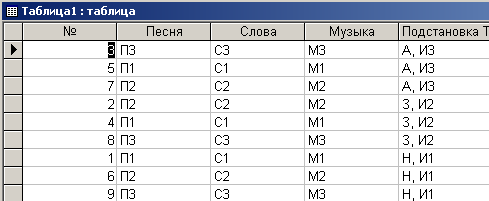
Рис. 4.6.5. Вид Таблицы1
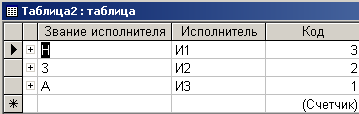
Рис. 4.6.6. Вид Таблицы2
Некоторое улучшение состояния дел произошло в таблице Таблица2, в ней значительно меньше записей, чем в исходной таблице. Однако от связи многие - ко многим избавиться не удалось.
Выполним манипуляции в рамках Microsoft Access, которые необходимы для приведения отношения, представленного на рис. 4.6.1 к 4-й нормальной форме.
Посредством следующего запроса сформируем новую таблицу на базе исходной таблицы:
SELECT Песни.Песня, Песни.Слова, Песни.Музыка INTO Песня
FROM Песни;
Здесь создается новая таблица “Песня’. Она формируется на основе полей “Песня”, “Слова” и “Музыка” из таблицы “Песни”. В результате выполнения запроса сформируется таблица, представленная на рис. 4.6.7.
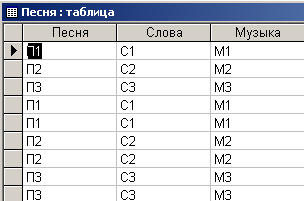
Рис. 4.6.7. Таблица песен, сформированная на базе исходного отношения
Для исключения дублирования записей в таблице, приведенной на рис. 4.6.1 и создания таблицы без дублирования используется следующий запрос:
SELECT DISTINCT Песня.Песня, Песня.Слова, Песня.Музыка INTO Песня1
FROM Песня;
В данном запросе на базе таблицы “Песня” формируется таблица “Песня1”. Конструкция DISTINCT позволяет передать записи в новую таблицу без дублирования. В результате выполнения данного запроса сформируется таблица, приведенная на рис. 4.6.8.
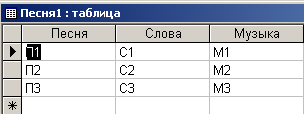
Рис. 4.6.8. Таблица без дублирования записей
Теперь для полученной таблицы сформируем ключевое поле типа “Счетчик”. Для этого откроем данную таблицу в режиме Конструктора и добавим к списку ее полей нужное поле. На рис. 4.6.9 приведена модифицированная таблица в режиме Конструктора.
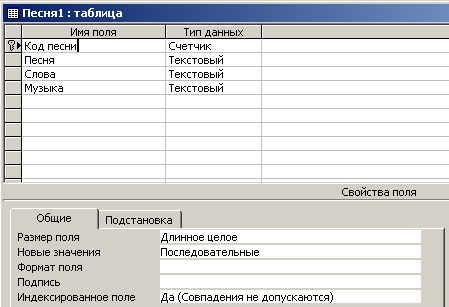
Рис. 4.6.9. Модифицированная таблица в режиме Конструктора
Вид модифицированной таблицы в режиме Просмотра показан на рис. 4.6.10. Следует обратить внимание на то, что в свойстве ”Индексированное поле” нового поля ”Код поля” выбрана опция “Да (Совпадения не допускаются)”. Это обеспечивает уникальность поля ”Код поля”.
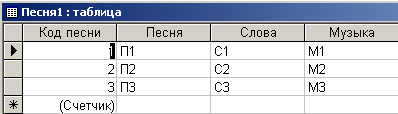
Рис. 4.6.10. Вид модифицированной таблицы в режиме Просмотра
Таким образом, посредством проведенных мероприятий на базе исходной таблицы сформирована новая таблицы, которая позиционируется с одной стороны ”многие” и включает в себя соответствующие поля. Кроме того, в новой таблице сформировано ключевое поле, посредством которого впоследствии будет организована связь с другой таблицей, которая позиционируется с другой стороны ”многие”.
Эта другая таблица включает в себя поля ”Исполнитель” и ”Звание исполнителя”. Выполнив манипуляции с исходной таблицей, подобные манипуляциям, проделанным выше, получим новую таблицу, которая представлена на рис. 4.6.11.
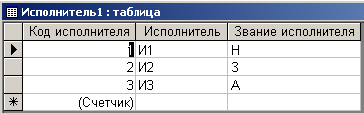
Рис. 4.6.11. Вид полученной таблицы исполнителей в режиме Просмотра
Следующим шагом приведения исходного отношения к 4-й нормальной форме является создание таблицы из ключевых полей построенных таблиц, которые приведены на рис. 4.6.10 и 4.6.1.
В режиме Конструктора данная таблица выглядит в соответствии с рис. 4.6.12.
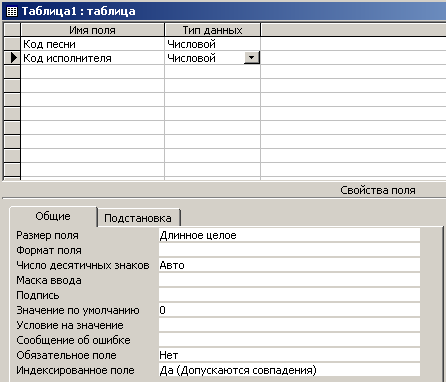
Рис. 4.6.12. Таблица для организации связей, представленная в режиме Конструктора
Следует обратить внимание на то, что типы полей выбраны ”Длинное целое”. Так сделано в связи с тем, что эти поля предполагается использовать для связывания с соответствующими полями таблиц, которые приведены на рис. 4.6.10 и 4.6.1. Типы полей для связывания должны совпадать. А в таблицах, которые приведены на рис. 4.6.10 и 4.6.1, соответствующие поля имеют тип ”Счетчик”. Для формирования значения поля типа ”Счетчик” используется тип данных ”Длинное целое”.
В свойствах полей “Индексированное поле” выбраны значения ”Да (Допускаются совпадения)”. Это сделано в связи с тем, что по данным полям могут сортироваться записи, кроме того, значения данных полей могут повторяться.
Следующим шагом приведения исходного отношения к 4-й нормальной форме является построение схемы данных из 3-х сформированных таблиц.
Очередным шагом приведения исходного отношения к 4-й нормальной форме является заполнение таблицы ”Связи”, которая связывает таблицы ”Песня1” и ”Исполнитель1”. Для этого можно вывести на экран содержимое 4-х таблиц: исходной, ”Песня1”, ”Исполнитель1” и таблицы ”Связи”. Затем в соответствии с ранее изложенным алгоритмом вручную заполнить таблицу ”Связи”.
На рис. 4.6.13 приведена соответствующая экранная форма.
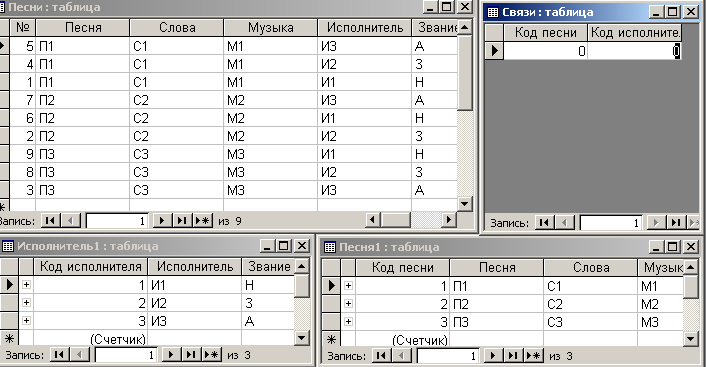
Рис. 4.6.13. Экранная форма с 4-я таблицами, открытыми в режиме Просмотра, редактирования и ввода данных
После заполнения таблицы ”Связи” в соответствии с предложенным алгоритмом она примет вид, приведенной на рис. 4.6.14.
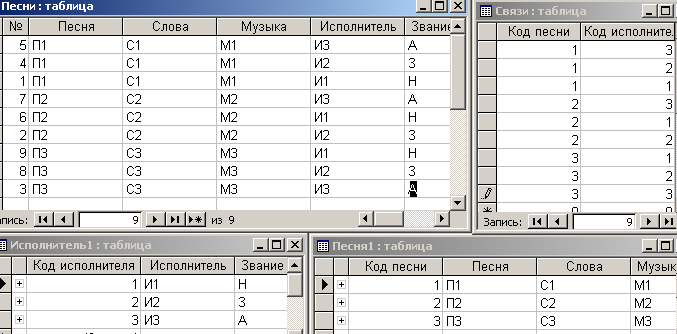
Рис. 4.6.14. Экранная форма с 4-я таблицами и заполненной таблицей ”Связи”
Собрать данные в одну таблицу из 3-х можно с помощью запроса, вид бланка которого приведен на рис. 4.6.15.
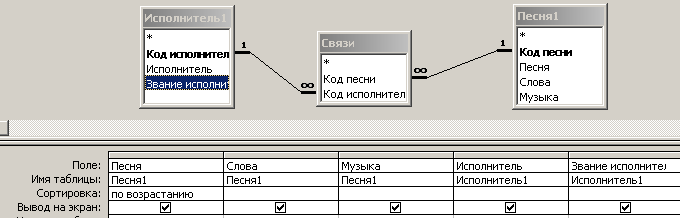
Рис. 4.6.15. Бланк запроса для сбора данных из трех таблиц
В формате SQL данный запрос выглядит следующим образом:
SELECT Песня1.Песня, Песня1.Слова, Песня1.Музыка, Исполнитель1.Исполнитель, Исполнитель1.[Звание исполнителя]
FROM Песня1 INNER JOIN (Исполнитель1 INNER JOIN Связи ON Исполнитель1.[Код исполнителя] = Связи.[Код исполнителя]) ON Песня1.[Код песни] = Связи.[Код песни]
ORDER BY Песня1.Песня;
Посредством данного запроса из двух таблиц выбирается пять полей. Первая конструкция INNER JOIN позволяет выбирать данные, в которых ключевые поля совпадают ( Исполнитель1.[Код исполнителя] = Связи.[Код исполнителя]). Вторая конструкция INNER JOIN позволяет выбирать данные, в которых другие ключевые поля совпадают (Песня1.[Код песни] = Связи.[Код песни]). Посредством конструкции “ORDER BY Песня1.Песня” выполняется сортировка выводимых данных по полю “Песня” таблицы ”Песня1”.
Результат выполнения данного запроса представлен на рис. 4.6.16.
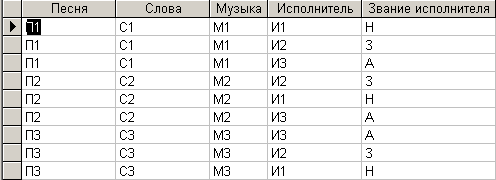
Рис. 4.6.16. Результат выполнения запроса, сформированного для сборки данных из трех таблиц
Как видно из рисунка результат выполнения запроса полностью совпадает с исходной таблицей.
При таких небольших таблицах, которые приведены, вполне допустимы рассмотренные манипуляции. Однако, если исходная таблица будет включать в себя реальное количество записей, подобная технология избавления от многозначных зависимостей мало приемлема. В связи с этим нужны дополнительные автоматизированные средства, реализованные в соответствии с рассмотренными выше алгоритмами.