
А. В. Брешенков Проектирование баз данных на основе информации табличного вида Допущено в качестве учебного пособия для студентов высших учебных заведений, обучающихся по направлению подготовки диплом
| Вид материала | Диплом |
- Учебное пособие Допущено Министерством образования Российской Федерации в качестве, 2582.59kb.
- Д. В. Андреев Программирование микроконтроллеров mcs-51, 2064.3kb.
- И. В. Борискина, А. А. Плотников, А. В. Захаров проектирование современных оконных, 1699.55kb.
- «История нового времени», 4001.1kb.
- Учебное пособие. 3-е изд., испр и доп, 125.38kb.
- М. В. Ломоносова Хрестоматия по истории государства и права зарубежных стран, 11295.75kb.
- В. В. Крупица Личность Коллектив Стиль отношений (социально-психологический аспект), 4876.34kb.
- И. М. Синяева, В. М. Маслова, В. В. Синяев сфера, 5230.77kb.
- И. К. Корнеев информационная безопасность и защита информации учебное пособие, 7667.6kb.
- Курслекций допущено умо по образованию в области социальной работы в качестве учебного, 2178.14kb.
4.4. Преобразование заполненных таблиц ко второй нормальной форме
Отношение считается приведенным ко 2-й нормальной форме, если никакие неключевые атрибуты не являются функционально зависимыми лишь от части ключа. Таким образом, 2-я нормальная форма может быть нарушена только в том случае, если ключ составной [2].
В табл. 4.4.1 приведен пример отношения, которое не удовлетворяет 2-й нормальной форме.
Т а б л и ц а 4.4.1
| Табельный № | Код работы | Начало работы | Исполнитель |
| 1121 | 27 | 1.1.6 | Федоров |
| 2231 | 15 | 15.1.6 | Петров |
| 3781 | 27 | 15.1.6 | Котов |
| 2231 | 14 | 17.2.6 | Петров |
| 1121 | 11 | 20.1.6 | Федоров |
| 3781 | 12 | 20.5.6 | Котов |
| 2231 | 33 | 1.1.7 | Петров |
Здесь в качестве составного ключа используются атрибуты “Табельный №” и “Код работы”. Нетрудно заметить, что неключевой атрибут 'Исполнитель' зависит лишь от части ключа – от атрибута 'Табельный №', это приводит к тому, что значение атрибута “Исполнитель”, как видно из табл. 4.4.1, дублируется. Это приводит к повышению вероятности ошибок ввода данных – если много раз вводится фамилия исполнителя, то легко ошибиться в написании или сопоставить ее не тому табельному номеру.
Кроме того, если потребуется изменить имя исполнителя, то придется его менять во всех записях или использовать специальный параметрический запрос на обновление.
И, наконец, если исполнителю еще не выдано задание, то при таком представлении данных информация о сотруднике будет отсутствовать.
Чтобы привести данное отношение ко 2-й нормальной форме, его необходимо представить в виде двух таблиц. При этом 1-я таблица должна включать в себя все атрибуты, кроме последнего, а 2-я таблица должна включать в себя последний атрибут и атрибут “Табельный №”.
Таким образом, 1-я таблица примет вид таблицы 4.4.2.
Т а б л и ц а 4.4.2
| Табельный № | Код работы | Начало работы |
| 1121 | 27 | 1.1.6 |
| 2231 | 15 | 15.1.6 |
| 3781 | 27 | 15.1.6 |
| 2231 | 14 | 17.2.6 |
| 1121 | 11 | 20.1.6 |
| 3781 | 12 | 20.5.6 |
| 2231 | 33 | 1.1.7 |
Вторая таблица примет вид (табл.4.4.3).
Т а б л и ц а 4.4.3
| Табельный № | Исполнитель |
| 1121 | Федоров |
| 2231 | Петров |
| 3781 | Котов |
| 2231 | Петров |
| 1121 | Федоров |
| 3781 | Котов |
| 2231 | Петров |
После исключения повторов табл. 4.4.3 примет вид таблицы 4.4.4.
Т а б л и ц а 4.4.4
| Табельный № | Исполнитель |
| 1121 | Федоров |
| 2231 | Петров |
| 3781 | Котов |
Теперь табл. 4.4.2 и табл. 4.4.4 связаны между собой посредством атрибута “Табельный №”.
Когда мощность отношения, как в примере, невелика, нетрудно выполнить рассмотренные мероприятия вручную. В противном случае это далеко не всегда возможно.
В связи с этим предлагается алгоритм автоматизированного приведения заполненных таблиц ко 2-й нормальной форме. Кратко сформулировать его можно следующим образом.
Для каждого атрибута, входящего в первичный ключ, выполняется поиск неключевых атрибутов, находящихся в полной функциональной зависимости. Для этого необходимо выявить ситуации, когда при равных значениях атрибутов, входящих в первичный ключ, равны значения неключевых атрибутов, находящихся в одноименных строках. Если такие атрибуты, входящие в первичный ключ найдутся, то исходная таблица разбивается на две таблицы. Для этого осуществляется операция проекции для исходной таблицы по всем столбцам, кроме функционально зависимогостолбца.
Далее осуществляется операция проекции для исходной таблицы по столбцу с функционально зависимым атрибутом и столбцу, который является частью первичного ключа и для которого выявлена функциональная зависимость.
Таблица, в которую не включен функционально зависимый атрибут, повторно проверяется на соответствие 2-й нормальной форме, и все перечисленные манипуляции повторяются.
Для описания алгоритма используется общий вид отношения, представленный в табл. 4.4.5.
Т а б л и ц а 4.4.5
| A1 | A2 | … | Ai | … | Aj | … | Ak |
| a11 | a12 | … | a1i | … | a1j | … | a1k |
| a21 | a22 | … | a2i | … | a2j | … | a2k |
| … | … | … | … | … | … | … | … |
| an1 | an2 | … | ani | … | ani | … | ank |
| … | … | … | … | … | … | … | … |
| am1 | am2 | … | ami | … | amj | … | amk |
В формализованном виде алгоритм выглядит следующим образом.
Выявление функциональной зависимости.
FOR s = 3 то k
C=0
FOR r = 1 то m
AR1 = ar1
ARS = ars
FOR r1 = 1 то m
IF NOT((ar1 1 = AR1) and (ar1 s = ARS)) THEN GOTO M
NEXT r1
C = C +1
IF C = r THEN
sz = s
PRINT (”ЗАВИСИМЫЙ АТРИБУТ”, sz)
STOP
END IF
NEXT r
M: NEXT s
PRINT (”ЗАВИСИМОГО АТРИБУТА НЕТ”)
Поясним алгоритм.
Во внешнем цикле перебираются все столбцы (атрибуты) кроме столбцов входящих в первичный ключ. Предполагается, что в ключ входят два первых атрибута. Переменная ”С” используется для подсчета ”успешных” проходов - проходов, которые не были завершены по команде "GOTO M”.
В цикле по ”r” выбираются очередное значение первого атрибута, входящего в первичный ключ ”AR1 = ar,1” и соответствующее ему значение неключевого атрибута из той же строки ”ARS = ars” и s-го столбца.
Для выбранной пары в цикле по ”r1” перебираются все записи отношения. В данном цикле выполняется проверка равенства значения выбранного неключевого атрибута и текущего неключевого атрибута при равенстве выбранного атрибута, входящего в первичный ключ и текущего атрибута, входящего в первичный ключ. Если данное условие не выполняется, то осуществляется ”аварийный” выход из цикла и в качестве проверяемого атрибута выбирается следующий s-й столбец отношения.
Если в цикле по ”r” не было ”аварийных” выходов (C = r), то зависимый атрибут найден, номер столбца запоминается в переменную sz для использования ее на следующих шагах алгоритма нормализации.
Следует обратить внимание на то, что, несмотря на сходство работы алгоритма с двумерным массивом, при его реализации в виде программ вероятно данные не будут изначально представлены двумерным массивом. Таблица может быть представлена текстовым файлом, электронной таблицей или файлом БД. В связи с этим в алгоритме намеренно используются обозначения типа ars, а не a(r,s).
В соответствии с предложенным алгоритмом на функциональную зависимость проверяется первый атрибут, входящий в первичный ключ. Для проверки на функциональную зависимость второго атрибута, входящего в первичный ключ необходимо выполнить такой же алгоритм. Только вместо ar1 нужно использовать ar2, а вместо ar11 - ar12. Это можно реализовать, расширив предыдущий алгоритм, но от этого он станет менее понятен.
При маловероятном стечении обстоятельств программные средства, реализованные в соответствии с приведенным алгоритмом могут ошибочно указать на функционально зависимый атрибут. Разработчик БД легко может выявить эту ошибку, визуально проанализировав две записи отношения, в которых предполагаются функционально зависимые атрибуты. Поэтому предлагаемый способ приведения отношения ко 2-й нормальной форме человеко-машинный, (автоматизированный).
Если зависимый атрибут выявлен, то выполняются его следующие шаги.
Формирование отношения из зависимых атрибутов.
FOR i = 1 TO m
bi1 = ai1
bi2 = ai sz
NEXT i
REM Исключение дублирования
FOR i = 1 TO m
s = Concat(bi1, bi2)
FOR J =i+1 TO m
s1 = Concat(bi1, bi2)
IF s1 = s THEN DLETE(Sj)
NEXT J
NEXT i
Поясним алгоритм.
В рамках 1-го цикла строится отношение “B” из 2-х атрибутов. При этом для каждой строки нового отношения в качестве ключевого (1-го) значения атрибута используется значение исходного отношения, которое соответствует части ключа, а в качестве значения второго атрибута используется соответствующее функционально зависимое значение исходного отношения.
В рамках второго цикла исключается дублирование записей в полученном отношении. Для этого во внешнем цикле посредством оператора Concat(bi1, bi2) формируется строка из значений текущей записи отношения, а во внутреннем цикле эта строка сравнивается с оставшимися строками отношения. Если обнаруживается дублирование строк, то текущая строка внутреннего цикла посредством оператора DLETE(Sj) удаляется.
Следует обратить внимание на то, что в соответствии с предложенным алгоритмом предполагается, что функционально зависимым является первый атрибут, входящий в первичный ключ. Если функционально зависимым является второй атрибут, входящий в первичный ключ, то вместо переменной ai1 нужно использовать переменную ai2.
Упрощение исходного отношения.
FOR i = 1 TO m
C = 0
FOR J = 2 TO k
IF j <> sz THEN
C = C + 1
di,c = aij
END IF
NEXT J
NEXT i
Поясним алгоритм.
В рамках внешнего цикла перебираются все записи исходного отношения и формируются записи нового отношения “D”.
Во внутреннем цикле заполняются все столбцы нового отношения значениями столбцов исходного отношения. Причем 1-й столбец не включается, так как он в качестве ключевого атрибута задействован в отношении ”B”. Не включаются также в отношение ”D” значения функционально зависимого столбца с номером ”sz” так как он задействован в отношении ”B”.
Приведение отношений ко 2-й нормальной форме реализовано в отдельных инструментальных системах, ориентированных на создание БД, в частности в Microsoft Access. Для этого, вероятно, использован алгоритм подобный алгоритму описанному выше. Рассмотрим преобразование отношения, представленного в табл. 4.4.1 ко 2-й нормальной форме.
Соответствующая таблица представлена на рис 4.4.1.
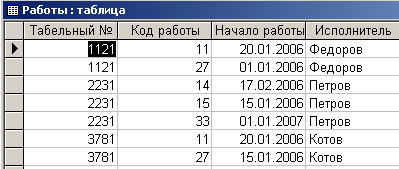
Рис. 4.4.1. Ненормализованная таблица
С помощью меню Microsoft Access Сервис/Анализ/Таблица необходимо запустить мастер для преобразования таблицы. Выполняя шаги мастера, разработчик в конечном итоге получит схему данных, представленную на рис. 4.4.2.

Рис. 4.4.2. Схема данных, полученная после нормализации
Как видно из комментариев, представленных в окне, пользователю предоставляется возможность изменения имен таблиц. Кроме того, пользователю предоставляется возможность самостоятельно сформировать подходящие по смыслу группы. Нередко такое предложение может скорее запутать, чем помочь.
Как видно из схемы данных, в “Таблица1” добавлено ключевое поле с именем ”Уникальный код”. Неочевидно, что это ключевое поле нужно. Правда, при желании впоследствии его можно удалить и сформировать новое ключевое поле.
Кроме того, в “Таблица1” появилось поле с именем “Подстановка Таблица2”. Из связи, сформированной на схеме данных, можно догадаться, что это бывшее поле “Табельный №”.
Рассмотрим содержимое сформированных таблиц. На рис 4.4.3 приведено содержимое “Таблица2”.
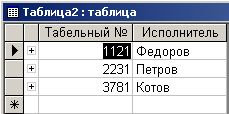
Рис. 4.4.3. Содержимое таблицы “Таблица2”
На этом рисунке то, что и ожидалось от результатов нормализации. Он практически совпадает с табл. 4.4.4.
На рис 4.4.4 приведено содержимое таблицы ”Таблица1”.
.
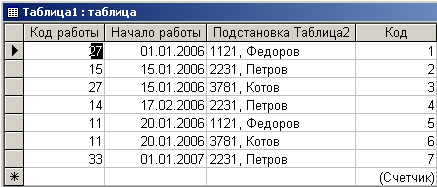
Рис. 4.4.4. Содержимое таблицы “Таблица1”
Некоторое недоумение вызывает поле ”Подстановка Таблица2”. Из его содержимого можно предположить, что это бывшее поле “Табельный №”. Действительно, если открыть данную таблицу в режиме Конструктора (рис. 4.4.5), можно увидеть, что поле с именем “Табельный №” в “Таблица1” присутствует. Все дело в том, что в качестве его подписи использовано другое имя - ”Подстановка Таблица2”
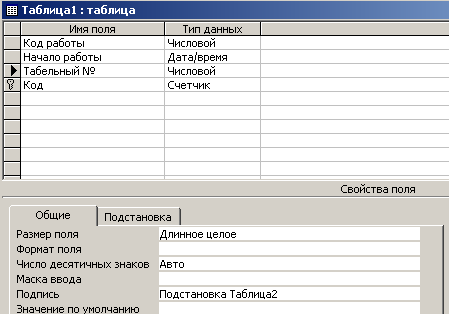
Рис. 4.4.5. ”Таблица1” в режиме Конструктора
Для того, чтобы выяснить откуда такое необычное содержимое поля “Табельный №” (новое имя ”Подстановка Таблица2”) необходимо открыть вкладку ”Подстановка”, рис. 4.4.6.
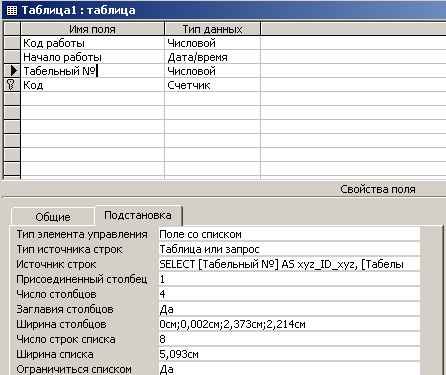
Рис. 4.4.6. Вкладка ”Подстановка” для Таблицы
Как видно из рисунка, в свойстве ”Число столбцов” задействовано 4-е столбца. В свойстве ”Источник строк” задействован SQL-запрос, который выглядит следующим образом:
SELECT [Табельный №] AS xyz_ID_xyz, [Табельный №] & ', ' & [Исполнитель] AS xyz_DispExpr_xyz, [Табельный №], [Исполнитель] FROM Таблица2 ORDER BY [Табельный №];
Анализируя эту конструкцию, можно сделать вывод, что для поля с именем ”Табельный №” в ”Таблица1” при его заполнении предлагается список из 2-х полей ([Табельный №], [Исполнитель]) таблицы ”Таблица2”. В качестве содержимого в поле вводятся поля [Табельный №], [Исполнитель], разделенные символом ', ' и находящиеся в таблице “Таблица2”, в которой данные отсортированы по полю [Табельный №] (ORDER BY [Табельный №]).
Проще говоря, при вводе данных в поле Таблицы1 используется поле со списком, который строится посредством команды SELECT
Выбор значений из предлагаемого списка проиллюстрирован на рис. 4.4.7. Справа от поля ”Подстановка Таблица2” имеется маркер списка. После щелчка по этому маркеру сформируется список для выбора нужного значения.
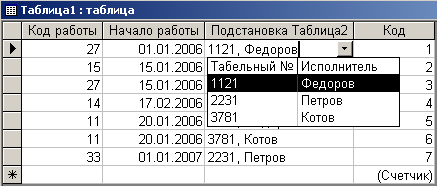
Рис. 4.4.7. Иллюстрация поля со списком
Резюмируя сказанное выше относительно инструментальных средств Microsoft Access, ориентированных на приведение отношений ко 2-й нормальной форме, можно сделать вывод о том, что эти средства чаще всего обеспечивают реализацию нужных функций. Однако результаты преобразований не всегда очевидны и легко понимаемы, а модифицировать результаты преобразования может только квалифицированный пользователь Microsoft Access.
В частности, можно убрать ”Подпись” (рис. 4.4.5), изменить вкладку ”Подстановка” в соответствии с рис. 4.4.8.
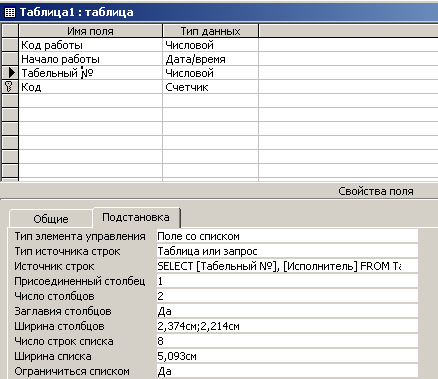
Рис. 4.4.8. Модифицированная вкладка ”Подстановка” для Таблицы1
Затем можно переписать оператор SELECT следующим образом:
SELECT [Табельный №], [Исполнитель] FROM Таблица2 ORDER BY [Табельный №];
После этого Таблица1 примет более очевидный и удобный для дальнейшей модификации вид (рис. 4.4.9).
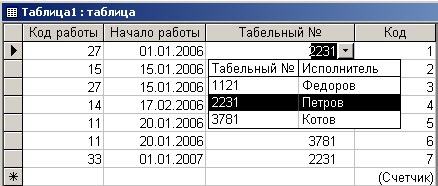
Рис. 4.4.9. Вид модифицированной таблицы “Таблица1”
В связи с вышесказанным можно сделать вывод о том, что квалифицированный пользователь может использовать средства Microsoft Access для приведения таблиц ко 2-й нормальной форме. Однако, в этом случае необходимо самостоятельно выявить ”подозрительные таблицы”, а затем выполнить необходимые модификации.
Предложенный алгоритм наиболее актуален в том случае, если данные не представлены или не могут быть непосредственно представлены в СУБД типа Microsoft Access.