
А. В. Брешенков Проектирование баз данных на основе информации табличного вида Допущено в качестве учебного пособия для студентов высших учебных заведений, обучающихся по направлению подготовки диплом
| Вид материала | Диплом |
- Учебное пособие Допущено Министерством образования Российской Федерации в качестве, 2582.59kb.
- Д. В. Андреев Программирование микроконтроллеров mcs-51, 2064.3kb.
- И. В. Борискина, А. А. Плотников, А. В. Захаров проектирование современных оконных, 1699.55kb.
- «История нового времени», 4001.1kb.
- Учебное пособие. 3-е изд., испр и доп, 125.38kb.
- М. В. Ломоносова Хрестоматия по истории государства и права зарубежных стран, 11295.75kb.
- В. В. Крупица Личность Коллектив Стиль отношений (социально-психологический аспект), 4876.34kb.
- И. М. Синяева, В. М. Маслова, В. В. Синяев сфера, 5230.77kb.
- И. К. Корнеев информационная безопасность и защита информации учебное пособие, 7667.6kb.
- Курслекций допущено умо по образованию в области социальной работы в качестве учебного, 2178.14kb.
4.3. Преобразование заполненных таблиц к первой нормальной форме
4.3.1. Избавление от сложных атрибутов
В работах [7,8] обоснована актуальность проблемы преобразования заполненных нереляционных таблиц в реляционные таблицы, сформулированы задачи преобразования, намечены пути решения отдельных задач. Здесь рассматривается одна из этих задач - избавление от сложных атрибутов в заполненных нереляционных таблицах. Простые атрибуты - это первое условие нормализации реляционных таблиц. При проектировании таблиц баз данных это условие закладывается изначально. В нереляционных таблицах или в данных табличного вида оно, как правило, не обеспечивается.
Для того, чтобы исключить подзаголовки 1-го и 2-го уровней и не потерять смысл атрибутов можно выполнить конкатенации заголовков и подзаголовков всех уровней и значениям подзаголовков нижнего уровня приписать значения конкатенации. После этого необходимо удалить строки с заголовками 1-го и, если есть таковые, строки с заголовками 2-го уровня. Этот процесс можно формализовать и соответственно реализовать его в виде машинных процедур. Однако полностью исключить участие человека из процесса преобразования данных табличного вида к реляционному виду удается не всегда, поэтому речь идет о человеко-машинных процедурах.
Для формализации процесса избавления от сложных атрибутов определим необходимые понятия.
Ячейка – это фрагмент таблицы, который имеет четыре ограничителя: верхний, нижний, левый и правый. В зависимости от формата представления данных табличного вида в качестве ограничителей могут выступать пробелы, символы табуляции, точки, вертикальные линии, горизонтальные линии или другие специальные символы. В электронных таблицах ячейка имеет адрес. В связи с этим одной из причин участия человека в процессе преобразования является необходимость указания символов ограничителей ячеек. Ячейка характеризуется номером строки таблицы данных и номером в строке. Таким образом, Яij - это область таблицы, выделенная ограничителями, находящаяся в i-ой строке таблицы и занимающая j-ю позицию. ЛГ(Яij) – левый ограничитель Яij; ПГ(Яij) – правый ограничитель Яij; УГ – указатель на правую или левую границу ячейки. С(Яij) – содержимое ячейки; СТi – i-ая строка.
Алгоритм избавления от сложных атрибутов выглядит следующим образом:
П1: {Подсчет числа ячеек в 1-ой, 2-ой, и 3-ей строках таблицы.}
{Подсчет выполняется для того, чтобы узнать есть ли в таблице подзаголовки, а также узнать, сколько уровней подзаголовков.}
М1 := 1;
УГ := ЛГ(Я11);
WHILE ПГ(Я1М1) not EMPTY M1 := M1 + 1;
М2 := 1;
УГ := ЛГ(Я21);
WHILE ПГ(Я2М2) not EMPTY M2 := M2 + 1;
М3 := 1;
УГ := ЛГ(Я31);
WHILE ПГ(Я3М3) not EMPTY M3 := M3 + 1;
IF М2 = М1 THEN GOTO П4; {нет подзаголовков}
IF (М2 > М1) and (M2 = M3) THEN GOTO П2;
IF М3 > М2 THEN GOTO П3;
{один уровень подзаголовков}
П2: k := 1;
j := 1;
УГ:= ЛГ(Я21);
WHILE j <> M2
WHILE ПГ(Я1K) <> ПГ (Я2J)
C(Я2J)= Concat(C(Я1K),' ',C(Я2J));
j := j + 1;
END WHILE;
k := k + 1;
j := j + 1;
END WHILE;
DELETE CT1;
GOTO П4;
{два уровня подзаголовков}
П3: к := 1;
n := 1;
j := 1;
WHILE j <> M3
WHILE ПГ(Я2n) <> ПГ (Я3j)
C(Я3j) = Concat(C(Я1k),' ',C(Я2n),' ',C(Я3j));
j := j + 1;
END WHILE;
IF ПГ(Я1k) = ПГ(Я3j) THEN k :=k + 1;
n := n + 1;
j := j + 1;
END WHILE;
DELETE CT1;
DELETE CT2;
П4: END.
Нетрудно заметить, что многие команды алгоритма несколько напоминают команды языка программирования Pascal. Так сделано в связи с тем, что при исключении подзаголовков очень вероятна работа с текстовыми файлами, сам алгоритм неочевиден и оправданна его изначальная ориентация на предполагаемый язык реализации.
В алгоритме задействован оператор DELETE, применение которого реализует удаление строк. В П2 удаляется 1-ая строка CT1 со сложными атрибутами. В П3 удаляется 1-ая и 2-ая строки (CT1 , CT2) со сложными атрибутами. Следует обратить внимание, что алгоритм предназначен для реализации в человеко-машинных процедурах. Это связано с тем, что сформированные в соответствии с алгоритмом атрибуты могут быть длинными и не удовлетворять требованиям инструментальной СУБД. Они могут оказаться семантически избыточными и нуждаться в корректировке. Кроме того, в атрибутах могут быть символы, недопустимые с точки зрения инструментальной СУБД. В качестве таких символов могут выступать “!”, “.”, “@” и другие. В связи с этим при реализации алгоритма необходимо предусмотреть автоматизированное исключение из атрибутов символов, указанных пользователем.
Нетрудно доказать, что алгоритм корректный, т.е. алгоритм сходится. П1 алгоритма конечен, т.к. число ячеек любой строки таблицы данных ограничено. П2 и П3 также конечны, так как циклы, которые в них задействованы, ограничены фиксированными значениями параметров.
Кроме того, алгоритм обладает малой вычислительной сложностью, которую можно оценить следующим образом. Для П1 максимальное число итераций оценивается как N*3, где N – число простых атрибутов или количество ячеек в строках с данными или степень таблицы данных. Для П2 и П3 максимальное число операций N. Так как П2 и П3 алгоритма альтернативны, то общая вычислительная сложность алгоритма N*4, т.е. линейна. Причем значение коэффициента невелико.
Нетрудно показать, что таблица, полученная в результате работы алгоритма, удовлетворяет 1-ой нормальной форме. Действительно, в соответствии с требованиями алгоритма (П1), преобразование сложных атрибутов в простые начинает выполняться, когда количество атрибутов (заголовков) будет равным числу элементов в строке с данными - N. Если бы в результате выполнения алгоритма атрибуты остались сложными, то количество заголовков должно было получиться меньшим количества элементов в строке с данными, а это противоречит предыдущему высказыванию. Таким образом, число атрибутов после выполнения алгоритма соответствует количеству ячеек в строках с данными и эти атрибуты неделимы. Кроме того, в соответствии с пунктами алгоритма (П2, П3) вся необходимая информация о семантике столбцов собирается и сохраняется в простых атрибутах. В связи с этим после удаления строк со сложными атрибутами смысловое назначение столбцов таблицы не утрачивается.
Следует отметить, что проблемы с заголовками в данных табличного вида полностью не исчерпываются посредством применения предложенного алгоритма. В соответствии с моделью данных табличного вида заголовки могут позиционироваться внутри таблиц. Для исключения таких заголовков чаще всего недостаточно простого удаления соответствующих записей. Как правило, для выбора способа избавления от заголовков, расположенных внутри таблицы, необходим анализ нескольких факторов. Одним из результатов анализа могут быть выводы о необходимости реструктуризации таблицы.
Иногда для решения проблемы избавления от сложных атрибутов оправданно использование существующих средств. Рассмотрим пример таких средств. В качестве исходной таблицы рассмотрим фрагмент реальной таблицы, сформированной в Microsoft Excel, представленный на рис. 4.3.1.
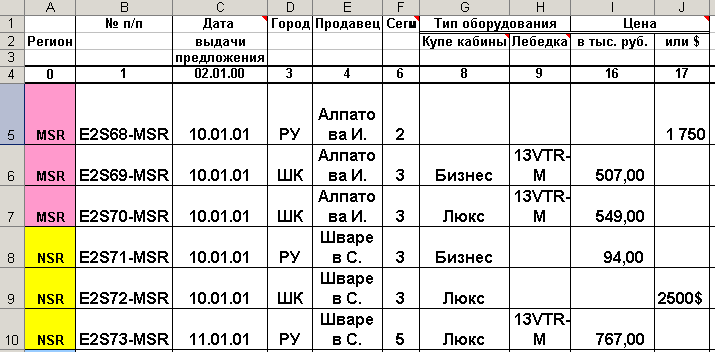
Рис. 4.3.1. Исходная таблица со сложными атрибутами
Как видно из рис. 4.3.1, в таблице имеются два сложных атрибута - “Тип оборудования” и ”Цена”. Выполним импорт этой таблицы в СУБД Access. Для этого используется меню Файл/Внешние данные/Импорт. В процессе выполнения шагов мастера импорта указывается лист рабочей книги Microsoft Excel, назначается строка заголовка, имя создаваемой таблицы. Окно мастера на его очередном шаге имеет вид рис 4.3.2.
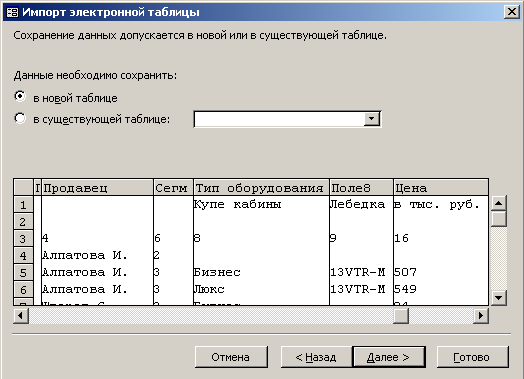
Рис. 4.3.2. Окно мастера импорта таблиц
При выполнении следующих шагов мастера можно назначить индексные поля, в отдельных случаях можно назначить типы полей, назначить ключевое поле. В результате выполнения всех шагов мастера исходная таблица в формате Microsoft Access примет вид рис 4.3.3.
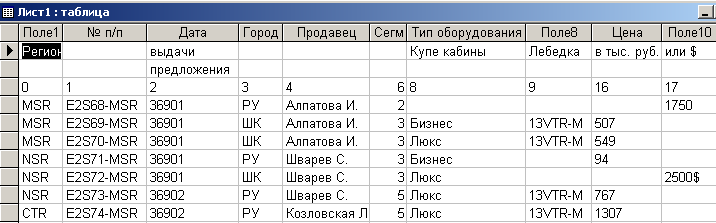
Рис. 4.3.3. Исходная таблица в формате Microsoft Access
Даже из поверхностного анализа заголовков таблицы и содержимого полей видно, что в таком виде таблица неприемлема для использования. В связи с этим для избавления от сложных атрибутов необходимо, в соответствии с алгоритмом, сформировать простые заголовки и избавиться от подзаголовков, которые попали в значения атрибутов. В значения атрибутов, как видно из рис. 4.3.3 попали части и некоторых простых заголовков.
Редактирование заголовков реализуется, когда таблица открыта в режиме Конструктора; редактирование полей таблицы реализуется, когда таблица открыта в режиме Просмотра.
После выполнения необходимых действий в режиме Конструктора и в режиме Просмотра таблица примет вид рис. 4.3.4.
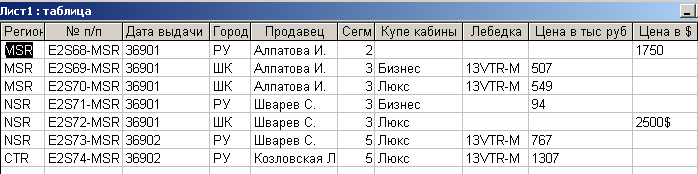
Рис. 4.3.4. Преобразованная таблица в формате Microsoft Access
Для рассмотренного фрагмента таблицы описанные выше манипуляции не составили большого труда. Однако даже эта таблица в полном объеме включает в себя более сорока полей, причем многие из них входят в состав сложных атрибутов. Нередко встречаются таблицы с несколькими сотнями столбцов, в этом случае рассмотренные мероприятия могут оказаться нетривиальными.
4.3.2. Исключение подзаголовков расположенных внутри таблицы
Информация табличного вида нередко представлена таким образом, что заголовки (атрибуты) таблицы чередуются со значениями атрибутов. Другими словами то, что должно использоваться в качестве заголовков таблицы используется в качестве их значений. Это недопустимо в таблицах, используемых в реляционных БД. От такого положения вещей следует избавляться. Рассмотрим пример, приведенный в табл. 4.3.1.
Т а б л и ц а 4.3.1
| Оборудование | Цена | Количество |
| Москва, Подмосковье | ||
| Эскалаторы | 50000 | 9 |
| Траволаторы | 70000 | 11 |
| Лифты | 40000 | 7 |
| Моторы | 7000 | 77 |
| Сибирь, Урал | ||
| Эскалаторы | 40000 | 5 |
| Траволаторы | 60000 | 9 |
| Лифты | 30000 | 5 |
| … | ||
| … | … | … |
Таблицу такого рода невозможно обрабатывать с помощью языка запросов.
В связи с этим эту таблицу оправданно представить в виде 2-х связанных реляционных таблиц: ”Продажи” и “Регионы”.
Предлагается следующая последовательность действий. Формируется новый столбец с номерами регионов. Сканируется преобразованная таблица, очередному региону присваивается номер, и этот номер распространяется на товары, проданные в данном регионе. Затем из записей с регионами формируется новая таблица, соответствующие записи из исходной преобразованной таблицы удаляются. После этих преобразований будут сформированы 2-е таблицы, связанные между собой связью типа 1: . Проиллюстрируем вышесказанное на примере.
Результат формирование нового столбца с номерами регионов и заполнением столбца приведен в таблице 4.3.2.
Т а б л и ц а 4.3.2
| № | Оборудование | Цена | Количество |
| 1 | Москва, Подмосковье | ||
| 1 | Эскалаторы | 50000 | 9 |
| 1 | Траволаторы | 70000 | 11 |
| 1 | Лифты | 40000 | 7 |
| 1 | Моторы | 7000 | 77 |
| 2 | Сибирь, Урал | ||
| 2 | Эскалаторы | 40000 | 5 |
| 2 | Траволаторы | 60000 | 9 |
| 2 | Лифты | 30000 | 5 |
| m | … | ||
| m | … | … | … |
Результат Формирования новой таблицы регионов и исключения записей с регионами из исходной таблицы приведены соответственно в табл. 4.3.3 и табл. 4.3.4
Т а б л и ц а 4.3.3
| № | Регион |
| 1 | Москва, Подмосковье |
| 2 | Урал, Сибирь |
| … | |
| m | |
Т а б л и ц а 4.3.4
| № | Оборудование | Цена | Количество |
| 1 | Эскалаторы | 50000 | 9 |
| 1 | Траволаторы | 70000 | 11 |
| 1 | Лифты | 40000 | 7 |
| 1 | Моторы | 7000 | 77 |
| 2 | Эскалаторы | 40000 | 5 |
| 2 | Траволаторы | 60000 | 9 |
| 2 | Лифты | 30000 | 5 |
| … | … | ||
| m | … | … | … |
Для таблиц данного вида вполне можно строить реляционные запросы.
Для небольшого рассмотренного примера описанные манипуляции вполне можно выполнить вручную. Для реальных таблиц мощностью десятки тысяч записей это чрезвычайно затруднительно и чревато ошибками.
В связи с этим предлагается машинный алгоритм преобразования.
Предварительно представим таблицу (отношение) рассматриваемого типа в общем виде (табл. 4.3.5).
Т а б л и ц а 4.3.5
| A1 | ... | Ai | ... | Ak |
| a11 | ... | NULL | ... | NULL |
| a21 | ... | a2i | ... | a2k |
| … | … | … | … | … |
| aj1 | ... | NULL | ... | NULL |
| … | ... | … | ... | … |
| af1 | ... | NULL | ... | NULL |
| am1 | ... | ami | ... | amk |
Особенность таблицы такого рода состоит в том, что в некоторых ее строках значение имеет только один атрибут. Принимается, что такой атрибут является внутренним подзаголовком таблицы.
Неформальный алгоритм исключения подзаголовков состоит в следующих действиях.
П1: Выполняется сканирование всех записей отношения R. Каждая запись проверяется на наличие в ней только одного значения атрибута. Записи такого рода подсчитываются. Если таких записей несколько, то подзаголовки в отношении R присутствуют и выполняется переход к следующему пункту (П2). В противном случае алгоритм завершает работу.
П2: К отношению R приписывается дополнительный атрибут KR с типом ”числовой” (формируется R'),.
COUNTER := 0;
П3: Выполняется сканирование всех записей отношения R'. Если в записи имеется только одно заполненное значение атрибута, то счетчик подзаголовков COUNTER увеличивается на 1.
Значению атрибута KR присваивается значение COUNTER.
П4: Создается новое отношение R2, включающее в себя 2-а атрибута NR и атрибут с подзаголовком.
Выполняется сканирование всех записей отношений R'. Записи, которые имеют только одно (кроме ключевого) заполненное значение, атрибута перемещаются в отношение R2.
В результате выполнения алгоритма сформируются отношение R2 (с подзаголовками исходной таблицы) и отношение R1 без подзаголовков. Связи между таблицами обеспечиваются посредством ключевых атрибутов KR, которые присутствуют в обоих отношениях.
Формализованный алгоритм исключения внутренних подзаголовков выглядит следующим образом.
COUNTER = 0
FOR r = 1 то m
COUNTER1 = 0
FOR f = 1 то k
IF ark = NULL THEN COUNTER1 = COUNTER1 + 1
NEXT f
IF COUNTER1 = k-1 THEN COUNTER = COUNTER + 1
NEXT r
IF COUNTER 2 THEN EXIT
REM Формирование двух отношений
R’ = R (A1, …, Ai, …, Ak) + R (KR)
COUNTER = 0
FOR r = 1 то m
COUNTER1 = 0
FOR f = 1 то k
IF ark = NULL THEN COUNTER1 = COUNTER1 + 1
NEXT f
IF COUNTER1 = k - 1 THEN
COUNTER = COUNTER + 1
Z(R2 COUNTER,1) = COUNTER
Z(R2 COUNTER,2) = ark
DELETE * FROM R’ WHERE (A1 = ark)
ELSE
Z(R’r, 1) = COUNTER
END IF
NEXT r
Здесь m-мощность R.
k – степень R.
Выражение R’ = R + R (KR) означает добавление к R атрибута с именем KR.
Выражение Z(R2COUNTER,1) означает значение элемента R2 в строке COUNTER и 1-м столбце.
Выражение Z(R’r, 1) означает значение элемента R’ в строке r и 1-м столбце.
Важно отметить, что предложенный алгоритм не следует применять ко всем таблицам, которые нужно преобразовать, а только к тем таблицам, которые имеют вид подобный рассмотренному примеру.
Назначение таблицы на преобразование – прерогатива разработчика. Более того, после принятия решения о преобразовании могут потребоваться действия разработчика, связанные с приведением исходной таблицы к регулярному виду. Кроме того, от разработчика потребуются значительные усилия по формированию связей между полученными таблицами. Способы наведения связей зависят от инструментальной СУБД. В связи с этим предлагаемый метод нельзя назвать автоматическим, он – автоматизированный.
Формально условие отсутствия внутренних подзаголовков в таблице выглядит следующим образом.
sj (sj s) (ajt = NULL) (ajt sj),
j = 1, m; t = 1, k-1.
Здесь s – множество строк таблицы.
ajt – значение t-го атрибута в j-й строке.
m – мощность таблицы; k – степень таблицы.
Для формализованного описания алгоритма умышленно использованы обозначения команд, характерных для многих языков программирования. Это сделано для того, чтобы облегчить реализацию алгоритма на каком-либо языке программирования высокого уровня.
Иногда для избавления от заголовков внутри таблицы оправданно использование существующих средств. Рассмотрим пример таких средств. В качестве исходной таблицы рассмотрим фрагмент реальной таблицы сформированной в Microsoft Excel, представленный на рис. 4.3.5.
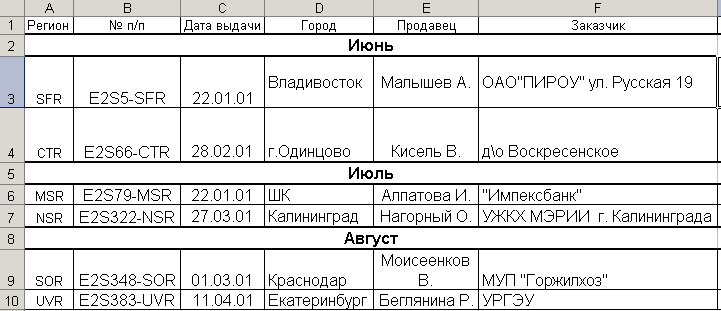
Рис. 4.3.5. Фрагмент таблице в формате Microsoft Excel с заголовками внутри таблицы
После импорта данной таблицы в формат БД Microsoft Access она примет вид, представленный на рис. 4.3.6.
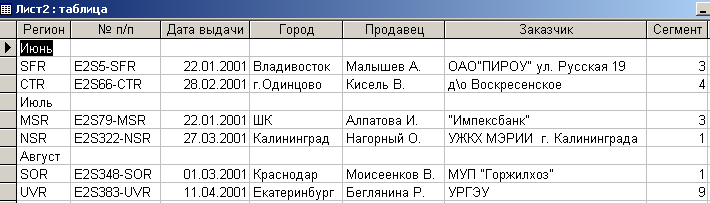
Рис. 4.3.6. Результат импорта таблицы в СУБД Microsoft Access
Нетрудно заметить, что заголовки, расположенные внутри таблицы, превратились в значения ячеек с заголовком ”Регион”.
Для приведения таблицы к приемлемому виду можно в режиме Конструктора определить новый столбец ”Месяц”, а потом в режиме Просмотра этот столбец вручную заполнить. Результат такого преобразования представлен на рис. 4.3.7.
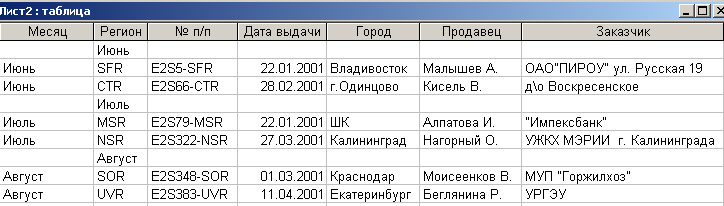
Рис. 4.3.7. Преобразованная таблица
Теперь остается только удалить записи с пустыми значениями первого атрибута и таблица примет приемлемый вид. Правда, полученную таблицу нужно нормализовать, но об этом речь пойдет позже.
Использование рассмотренных средств нетрудоемко и оправданно, когда таблица включает в себя несколько десятков записей. Реальные же таблицы нередко включают в себя десятки тысяч записей. В этом случае такого рода преобразование таблиц трудоемко и может привести к ошибкам.
Эта же самая таблица, импортированная в формат Microsoft SQl Server, выглядит следующим образом (рис 4.3.8).
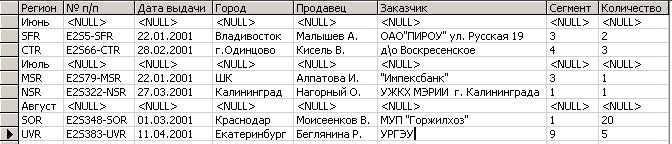
Рис. 4.3.8. Результат импорта таблицы в СУБД Microsoft SQl Server
Результат импорта таблицы в БД Microsoft SQl Server внешне несущественно отличается от результата импорта таблицы в БД Microsoft Access (рис. 4.3.6). Однако из рисунка видно, что незаполненные ячейки явно представлены значением ”NULL”. Такое представление незаполненных ячеек выгодно отличается от представления незаполненных ячеек в СУБД Microsoft Access. Дело в том, что в СУБД Microsoft Access незаполненные ячейки и пустые строки (””) отображаются одинаково – пустыми ячейками. Таким образом, в СУБД Microsoft Access визуально невозможно определить содержит ли ячейка данные или нет. Пустая строка является данными. Значение ”NULL” свидетельствует об отсутствии данных. В рассматриваемом случае это важно, так как именно отсутствие данных в определенных ячейках позволяет принять решение о необходимости нормализации таблицы на основе использования стандартных средств СУБД. Таким образом, в качестве инструментальных средств, используемых для приведения таблиц к 1-й нормальной форме, предпочтительно применение средств СУБД Microsoft SQl Server.
4.3.3. Нормализация заполненных таблиц с подзаголовками в первом столбце.
Нередко в таблицах первый столбец используется для хранения подзаголовков групп. Например, это справедливо для табл. 4.3.6.
Т а б л и ц а 4.3.6
| Секция | Спортсмен | Разряд | Год рождения |
| Плаванье | Федоров | 1 | 1985 |
| | Панин | 3 | 1988 |
| | Быстров | 2 | 1987 |
| | Мишин | 1 | 1984 |
| Гребля | Конев | 3 | 1989 |
| | Батурин | 2 | 1983 |
| | Иванов | мастер | 1983 |
| Бег | Синицын | 3 | 1986 |
| | Петров | 1 | 1986 |
Использование такого рода таблицы в составе БД приведет к тому, что будет невозможно построить запрос, чтобы получить информацию о том, в каких секциях занимаются спортсмены Панин, Быстров, Мишин, Батурин, Иванов, Петров.
В качестве самого простого решения этой проблемы может быть заполнение всех незаполненных полей в 1-м столбце. Однако это может привести к неоправданному расходованию памяти. Простое заполнение столбца оправданно лишь в том случае, если значения 1-го столбца включают в себя не более 5-ти символов, т.к. для нумерации записей подавляющего большинства таблиц достаточно 4-х байтов.
В противном случае необходимо:
- выделить 1-й столбец в отдельную таблицу;
- пронумеровать его записи;
- исключить в новой таблице повторяющиеся записи;
- пронумеровать записи исходной таблицы в соответствии с новой таблицей;
- удалить первый столбец исходной таблицы;
- сформировать связи между полученными таблицами.
Выполним описанные преобразования на примере.
В табл. 4.3.7 приведен результат добавления и заполнения ключевого столбца в исходной таблице.
Т а б л и ц а 4.3.7
| Секция | Спортсмен | Разряд | Год рождения | K2 |
| Плаванье | Федоров | 1 | 1985 | 1 |
| | Панин | 3 | 1988 | 1 |
| | Быстров | 2 | 1987 | 1 |
| | Мишин | 1 | 1984 | 1 |
| Гребля | Конев | 3 | 1989 | 2 |
| | Батурин | 2 | 1983 | 2 |
| | Иванов | мастер | 1983 | 2 |
| Бег | Синицын | 3 | 1986 | 3 |
| | Петров | 1 | 1986 | 3 |
В табл. 4.3.8 приведен результат формирования новой таблицы и исключения в ней повторяющихся строк 1-го столбца из исходной таблицы.
Т а б л и ц а 4.3.8
| К2 | Секция |
| 1 | Плаванье |
| 2 | Гребля |
| 3 | Бег |
В табл. 4.3.9 приведен результат удаления 1-го столбца из исходной таблицы.
Т а б л и ц а 4.3.9
| Спортсмен | Разряд | Год рождения | K2 |
| Федоров | 1 | 1985 | 1 |
| Панин | 3 | 1988 | 1 |
| Быстров | 2 | 1987 | 1 |
| Мишин | 1 | 1984 | 1 |
| Конев | 3 | 1989 | 2 |
| Батурин | 2 | 1983 | 2 |
| Иванов | мастер | 1983 | 2 |
| Синицын | 3 | 1986 | 3 |
| Петров | 1 | 1986 | 3 |
Между данными таблицами имеется связь ”1: ”, которая осуществляется посредством ключевых полей K2.
Неформальный алгоритм исключения подзаголовков в 1-м столбце состоит в следующем:
П1: К исходному отношению R добавляется дополнительный атрибут со значением типа ”числовой”.
П2: COUNTER: = 0
Перебираются все записи отношения R. Если значение 1-го столбца текущей строки непустое, то COUNTER: = COUNTER + 1.
Значение счетчика записывается в поле ключевого столбца соответствующей строки.
П3: Перебираются все записи отношения R. Если значение 1-го столбца текущей строки не пустое, то создается новая запись отношения R2. В первое поле записи R2 заносится значение последнего атрибута текущей записи отношения R. Во второе поле отношения R2 заносится значение первого атрибута текущей записи отношения R.
В таблицах незначительного объема предложенные манипуляции нетрудно выполнить вручную. В таблицах мощностью несколько сотен записей и более оправданно использование автоматизированных средств.
Для изложения предлагаемого алгоритма в формализованной форме представим отношение рассматриваемого типа в общем виде (табл. 4.3.10).
Т а б л и ц а 4.3.10
| A1 | ... | Ai | ... | Ak |
| a11 | ... | NULL | ... | NULL |
| a21 | ... | a2i | ... | a2k |
| … | … | … | … | … |
| aj1 | ... | NULL | ... | NULL |
| … | ... | … | ... | … |
| af1 | ... | NULL | ... | NULL |
| am1 | ... | ami | ... | amk |
Нетрудно видеть, что общий вид таблицы рассматриваемого типа внешне не отличается от общего вида таблицы предыдущего типа. Однако, смысловое содержание таблиц различается. В предыдущем случае были ”неправильные” записи, а в рассматриваемом случае присутствует ”лишний” столбец.
Подобие общих видов таблиц отражается и на подобии алгоритмов.
Формализованный алгоритм исключения подзаголовков в 1-м столбце приведен ниже.
R’ = R + R(K2)
C = 0
FOR r = 1 то m
C1 = 0
FOR f = 1 то k
IF ark = NULL THEN C1 = C1 + 1
NEXT f
IF C1 = k - 1 THEN
C = C + 1
Z(R2i 1) = C
Z(R2i 2) = ark
ELSE
Z(ar k+1) = C
END IF
NEXT r
DEL A1 FROM R
Принятые обозначения аналогичны обозначениям предыдущего алгоритма.
Оператор DEL A1 FROM R означает удаление 1-го столбца из R.
Как и в предыдущем случае для использования алгоритма необходимо участие разработчика БД. В частности, участие разработчика необходимо для принятия решения о необходимости использования алгоритма.
В отдельных случаях для исключения заголовков в первом столбце оправданно использование стандартных существующих средств. В качестве примера рассмотрим фрагмент реальной таблицы, представленной в формате Microsoft Excel, который приведен на рис. 4.3.8.
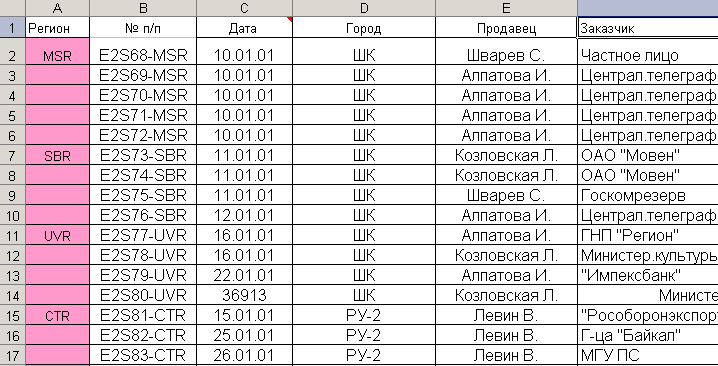
Рис. 4.3.8. Фрагмент таблицы в формате Microsoft Excel с заголовками в 1-м столбце
После импорта этой таблицы в Microsoft Access она примет следующий вид (рис. 4.3.9).
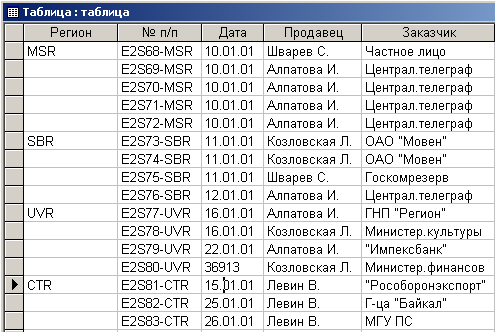
Рис. 4.3.9. Результат импорта в Microsoft Access
С помощью запроса можно сформировать новую таблицу, которая включает в себя только заголовки. Этот запрос имеет следующий вид.
SELECT Таблица.Регион INTO Таблица2
FROM Таблица
WHERE (Таблица.Регион) Is Not Null;
В этом запросе из таблицы с именем Таблица (FROM Таблица) в таблицу с именем Таблица2 (INTO Таблица2) записываются значения поля ”Регион” (Таблица.Регион). Причем выбираются только те поля, которые имеют непустые значения (WHERE (Таблица.Регион) Is Not Null)
Результат выполнения этого запроса представлен на рис. 4.3.10.
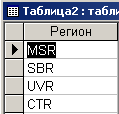
Рис. 4.3.10. Результат выполнения запроса
На следующем шаге преобразований необходимо открыть таблицу Таблица2 в режиме Конструктора, добавить новое поле типа ”Счетчик” и назначить его ключевым. После этого таблица примет вид рис. 4.3.11.
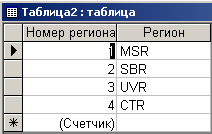
Рис. 4.3.11. Таблица2 с дополнительным полем
Следующим шагом преобразования является ввод в таблицу 4.3.9 номеров регионов. В результате получится таблица, представленная на рис. 4.3.12.
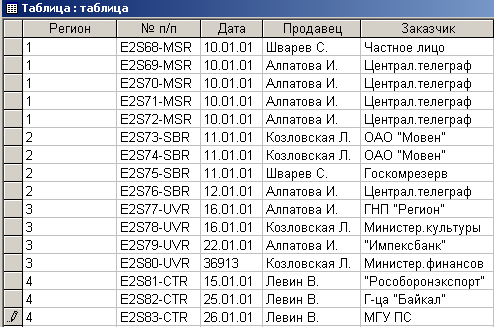
Рис. 4.3.12. Таблица с пронумерованными регионами
Для обеспечения связи между таблицами необходимо в режиме Конструктора в таблице “Таблица” изменить тип поля ”Регион” на числовой.
После названных преобразований можно построить схему данных, которая представлена на рис. 4.3.13.
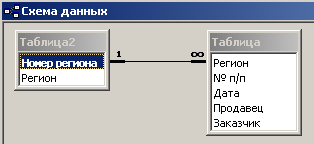
Рис. 4.3.13. Схема данных
После выполненных манипуляций обеспечена ссылочная целостность данных, т.е. в таблице Таблица нельзя ссылаться на несуществующий регион. Обеспечивается каскадное обновление, т.е. при изменении названия региона в таблице Таблица2 все соответствующие ссылки в таблице Таблица обновятся. Обеспечивается каскадное удаление, т.е. при удалении региона из таблицы Таблица2 удалятся все записи, связанные с этим регионом в таблице Таблица. Кроме того, сводится к минимуму вероятность ошибок при вводе нового региона. Действительно, вводить регион достаточно только в одну таблицу.
Для просмотра всей необходимой информации из двух таблиц можно построить следующий запрос.
SELECT Таблица2.Регион, Таблица.[№ п/п], Таблица.Дата, Таблица.Заказчик
FROM Таблица2 INNER JOIN Таблица ON Таблица2.[Номер региона] = Таблица.Регион;
Запрос позволяет выбрать указанные поля из обеих таблиц. Конструкция “Таблица2 INNER JOIN Таблица ON Таблица2.[Номер региона] = Таблица.Регион” свидетельствует о том, что используется внутреннее соединение двух таблиц (INNER JOIN), т.е. выбираются из таблиц только те поля, у которых ключевые поля совпадают (Таблица2.[Номер региона] = Таблица.Регион). В квадратных скобках указываются поля, в которых есть пробел.
Результат выполнения этого запроса представлен на рис. 4.3.14.
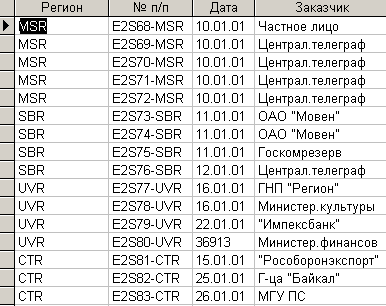
Рис. 4.3.14. Результат выполнения запроса
Как видно из выполненных мероприятий, даже для небольших по объему таблиц, они не являются тривиальными. Повышение размерности преобразуемых таблиц существенно увеличивает трудоемкость необходимых преобразований, а также увеличивает вероятность ошибок разработчика, допущенных в ходе выполнения преобразования.