
А. В. Брешенков Проектирование баз данных на основе информации табличного вида Допущено в качестве учебного пособия для студентов высших учебных заведений, обучающихся по направлению подготовки диплом
| Вид материала | Диплом |
СодержаниеУпражнения и вопросы для самоконтроля 3. Преобразование нереляционных таблиц в реляционные таблицы REM Заполнение таблицы обязательных замен |
- Учебное пособие Допущено Министерством образования Российской Федерации в качестве, 2582.59kb.
- Д. В. Андреев Программирование микроконтроллеров mcs-51, 2064.3kb.
- И. В. Борискина, А. А. Плотников, А. В. Захаров проектирование современных оконных, 1699.55kb.
- «История нового времени», 4001.1kb.
- Учебное пособие. 3-е изд., испр и доп, 125.38kb.
- М. В. Ломоносова Хрестоматия по истории государства и права зарубежных стран, 11295.75kb.
- В. В. Крупица Личность Коллектив Стиль отношений (социально-психологический аспект), 4876.34kb.
- И. М. Синяева, В. М. Маслова, В. В. Синяев сфера, 5230.77kb.
- И. К. Корнеев информационная безопасность и защита информации учебное пособие, 7667.6kb.
- Курслекций допущено умо по образованию в области социальной работы в качестве учебного, 2178.14kb.
Упражнения и вопросы для самоконтроля
- Сформулируйте основные характеристики модели реляционной БД.
- Сформулируйте основные характеристики модели информации табличного вида.
- В чем сходство между моделью реляционной БД и моделью информации табличного вида?
- В чем различие между моделью реляционной БД и моделью информации табличного вида?
- Сформулируйте задачи преобразования заполненных нереляционных таблиц в реляционные таблицы.
- Постройте схему иерархии методов проектирования реляционных баз данных на основе использования информации табличного вида
3. ПРЕОБРАЗОВАНИЕ НЕРЕЛЯЦИОННЫХ ТАБЛИЦ В РЕЛЯЦИОННЫЕ ТАБЛИЦЫ
3.1. Приведение значений атрибутов заполненных таблиц к одному типу
Ключевым требованием к реляционным таблицам являются одинаковые типы значений всех атрибутов.
К числу основных типов полей в реляционных таблицах относятся: числовой, текстовый, дата, время, логический, гиперссылки, OLE, MEMO. При вводе нового значения в каком-либо поле таблицы БД тип значения проверяется автоматически. Если тип вводимого значения не соответствует объявленному типу, то это значение не заносится в поле таблицы.
При заполнении нереляционных таблиц такой проверки не выполняется. В связи с этим в нереляционных таблицах в одном и том же столбце могут храниться данные различных типов. Это недопустимо в БД. Поэтому при преобразовании нереляционных таблиц в реляционный вид необходимо обеспечить единый тип значений для всех атрибутов.
В качестве примера таблицы с различными типами значений атрибутов в одноименных столбцах рассмотрим таблицу, представленную на рис. 3.1.

Рис. 3.1. Таблица с различными типами значений атрибутов в одноименных столбцах
В этой таблице в столбце ”B”, как мы видим, должны располагаться значения логического типа, в столбце “C” - значения числового типа, а в столбце “D” – значения типа ”Дата”.
Однако после импорта этой электронной таблицы с использованием стандартных средств Microsoft Access сформируется таблица БД, представленная на рис 3.2.

Рис 3.2. Результат импорта электронной таблицы с использованием стандартных средств Microsoft Access.
В этой таблице тип всех столбцов текстовый, так как имеет место смешение типов. Более того, даты превратились в числа. При этом в процессе выполнения процедуры импорта не было никакой возможности указать нужный тип.
При преобразовании таблиц (текстовых, электронных) стандартными средствами других СУБД тип столбцов иногда назначается исходя из анализа нескольких первых записей таблицы. Но это, в принципе, мало что меняет.
Конечно, для таблицы с незначительным числом записей и атрибутов несложно исправить значения и свойства атрибутов. Однако для больших объемов данных это неприемлемо. В связи с этим предлагается автоматизированный метод назначения типов атрибутов заполненных таблиц.
Суть метода состоит в том, что для каждого столбца импортируемой таблицы выполняется автоматический анализ всех его значений. По результатам анализа назначается тип столбца, который имеют большинство значений этого столбца. Разработчику БД предлагается принять назначенный тип. Если этот тип его не устраивает, предлагается очередной по приоритету тип. И так до тех пор, пока тип столбца не будет принят разработчиком БД. Затем осуществляется попытка автоматического преобразования всех значений текущего столбца к назначенному типу. В результате преобразований формируются таблица преобразованных значений и таблица значений, которые не удалось преобразовать. Разработчик анализирует таблицу непреобразованных значений и на основе использования автоматизированных средств осуществляет преобразование данных к назначенному им типу.
В соответствии с известными СУБД выделим базовые типы, к которым алгоритм должен сводить атрибуты заполненных таблиц. Это следующие типы: числовой, строковый, дата, логический.
Суть алгоритма состоит в следующем. Для каждого столбца выполняется проверка всех его значений на принадлежность к каждому из названных типов. Назначается тот тип, который имеют большинство значений столбца. После назначения типа столбцу проверяются все его значения, которые не соответствуют назначенному типу. Если значение столбца в соответствии со своим контекстом может быть отнесено к назначенному типу, то это значение преобразуется к формату принятого для данного типа, запоминается позиция преобразованного значения и его прежнее значение. Прежнее значение и его номер записываются в соответствующую таблицу. Если значение столбца в соответствии со своим контекстом не может быть отнесено к назначенному типу, его номер заносится в таблицу непреобразованных значений атрибута.
Рассмотрим в качестве примера значения столбца.
А = (1, 0, да, нет, FALSE, TRUE, истина, ложно, ‘’ , NULL, верно, неверно, 0, 0, 1, FALSE, верно, неверно).
Если формально рассматривать значения этого столбца, то его тип будет назначен как текстовый, т.к. большинство его значений - текст. Однако просто визуального анализа достаточно для того, чтобы определить тип столбца как логический.
Но для нескольких тысяч и даже сотен значений визуальный анализ данных чрезвычайно затруднителен.
При автоматизированном анализе в процессе проверки типа столбца существенно поможет таблица часто встречающихся значений для данного типа. Например, для типа “логический” рассмотренный столбец после преобразования вида его значений примет вид:
А = (да, нет, да, нет, нет, да, да, нет, '' , NULL, верно, неверно, нет, нет, да, нет, верно, неверно).
Таблица замененных значений примет вид.
A’’ = (1, 0, , , FALSE, TRUE, истина, ложь, , , 0, 0, 1, FALSE, , 0, 0, 1, FALSE, ,)
Таблица не замененных значений примет вид.
A’’ = (, , , , , , , , '' , NULL, верно, неверно, , , верно, неверно).
Здесь символом ”,” обозначены позиции, отмечающие значения, не входящие в соответствующие таблицы.
Объединив эти три столбца в одну таблицу, получим табл. 3.1. Здесь в столбце с заголовком ”№” расположены номера записей. В столбце ”А” приведены исходные значения анализируемого столбца. В столбце ”F’ ” - метки значений, которые преобразованы к выбранному типу. В столбце ”А' ” приведены значения анализируемого столбца, полученные после преобразования исходного столбца. В столбце ”F’’ ” - метки значений, которые не удалось преобразовать к выбранному типу. В столбце ”А'’ ” приведены значения, которые не удалось преобразовать к выбранному типу.
Т а б л и ц а 3.1
| № | А | F' | A’ | F’’ | A’’ |
| 1 | 1 | | да | | |
| 2 | 0 | | нет | | |
| 3 | FALSE | | нет | | |
| 4 | TRUE | | да | | |
| 5 | ИСТИНА | | да | | |
| 6 | ЛОЖЬ | | нет | | |
| 7 | '' | | '' | | '' |
| 8 | NULL | | NULL | | NULL |
| 9 | ВЕРНО | | ВЕРНО | | ВЕРНО |
| 10 | НЕВЕРНО | | НЕВЕРНО | | НЕВЕРНО |
| 11 | 0 | | нет | | |
| 12 | 0 | | нет | | |
| 13 | 1 | | да | | |
| 14 | FALSE | | нет | | |
| 15 | ВЕРНО | | ВЕРНО | | ВЕРНО |
| 16 | НЕВЕРНО | | НЕВЕРНО | | НЕВЕРНО |
Разработчику необходимо согласиться c изменениями или их отменить. Кроме того, он должен иметь возможность выбрать из предлагаемого списка значений для замены нужные значения там, где замен не произошло.
Возможность выполнения этих действий разработчиком следует обеспечить в алгоритме и в его реализации. Очевидно, что трудоемкость манипуляций разработчика можно существенно уменьшить, если до разметки записей он укажет обязательные замены. Тогда результирующая таблица существенно сократится. Конечно, такую возможность необходимо предусмотреть в алгоритме и в его реализации. Например, в качестве обязательных замен разработчик может пометить замены, приведенные в табл. 3.2.
Т а б л и ц а 3.2
| 0 | нет | |
| 1 | да | |
| FALSE | нет | |
| TRUE | да | |
| ИСТИНА | да | |
| ЛОЖЬ | нет | |
Тогда табл. 3.1 примет вид табл. 3.3.
Т а б л и ц а 3.3
| № | А | F’ | A’ | F’’ | A’’ |
| 5 | ИСТИНА | | да | | |
| 6 | ЛОЖЬ | | нет | | |
| 7 | '' | | '' | | '' |
| 8 | NULL | | NULL | | NULL |
| 9 | ВЕРНО | | ВЕРНО | | ВЕРНО |
| 10 | НЕВЕРНО | | НЕВЕРНО | | НЕВЕРНО |
| 15 | ВЕРНО | | ВЕРНО | | ВЕРНО |
| 16 | НЕВЕРНО | | НЕВЕРНО | | НЕВЕРНО |
Для упрощения действий разработчика необходимо в алгоритме и его реализации обеспечить возможность принятия всех аналогичных замен при подтверждении одной, а также возможность замещения всех аналогичных вхождений при указании разработчиком шаблона для замещения.
Например, если разработчик в строке с номером 9 выберет замену ”ВЕРНО” на “да”, то в строке с номером 15 это должно быть выполнено автоматически.
Изложенное выше в основном нужно для разработки и пояснения алгоритма, который разрабатывается на основе принципа “от частного к общему”. Реализация средств разработчика БД, конечно, должна быть более эргономична.
По аналогии с приведенным примером приводятся к одному типу значения столбца в случае, если превалирующий тип отличен от “логического'” типа.
Следует отметить, что рассмотрен простейший случай – предполагаемый тип очевиден и для значений, которые остались не замененными легко подобрать замену.
Как показывает анализ реальных таблиц, для поиска превалирующего типа приходится выполнить проверку на соответствие нескольким типам. Кроме того, в реальных таблицах зачастую не удается подобрать значение для замещения из превалирующего типа, т.к. исходные значения ни на что не похожи. Чаще всего это ошибки заполнения таблиц. В этом случае они выявляются и исключаются. В крайнем случае, неопознанные значения заменяются пустыми значениями.
Опираясь на рассмотренный пример, изложим предлагаемый автоматизированный метод приведения значений атрибутов к одному типу в виде человеко – машинного алгоритма.
Он выглядит следующим образом.
FOR r =1 то k – 1
CN = 0
CB = 0
CS = 0
CD = 0
FOR f = 1 то m
SELECT CASE T (afr)
CASE ”NUM”
CN = CN + 1
CASE “LOG”
CB = CB + 1
CASE “STR”
CS = CS + 1
CASE “DAT”
CD = CD + 1
END SELECT
NEXT f
TYPE = FMAX (CN, CB, CS, CD)
PRINT (r, TYPE)
REM Вывод таблицы обязательных замен
REM Заполнение таблицы обязательных замен
PRINT (Ar, Ar', Ar’’)
REM Подтверждение (отмена) замен.
REM Присвоение значений.
NEXT r
Здесь k - степень отношения (перебираются все столбцы, кроме ключевого столбца).
m – мощность отношения.
CN, CB, CS; CD – счетчики совпадений значений столбца с соответствующим типом.
Функция FMAX позволяет определить наиболее часто встречающийся тип в столбце.
Оператор PRINT (r, TYPE) позволяет вывести номер анализируемого столбца и предлагаемый тип.
Оператор PRINT (Ar, Ar', Ar’’) позволяет вывести исходный столбец, измененный столбец и столбец значений, для которых соответствующей замены не нашлось.
Полужирным шрифтом выделены действия разработчика, которые он должен выполнить в ответ на результаты работы автоматических средств.
Следует отметить, что в процессе реализации алгоритма необходимо предусмотреть разработку таблицы предлагаемых замен для всех основных типов. Их формирование неочевидно. Например, для числовых значений допустимо множество представлений. То же самое можно сказать о типе ”Дата, время”. В связи с многообразием представления значений одного типа программные средства замены нетривиальны.
Рассмотрим, как эта проблема решается в СУБД Microsoft Access.
В примере задана простейшая структура двух таблиц - для Таблицы1 и Таблицы2. В каждой таблице по одному полю, в Таблицы1 тип поля ”Логический”, в Таблицы2 тип поля ”Текстовый”. В обеих таблицах имена полей одинаковые - ”Логический”. Таблица1 не заполнена. Таблица2 заполнена данными, представленными на рис. 3.3.
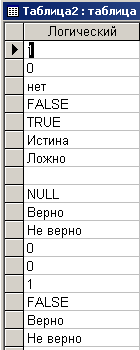
Рис. 3.3. Таблица2
Выполним попытку добавить данные из Таблицы2 в Таблицу1. Для этого сформирован следующий запрос на добавление.
INSERT INTO Таблица1 ( Логический )
SELECT Таблица2.Логический
FROM Таблица2;
Здесь конструкция ”INSERT INTO Таблица1 (Логический)” указывает на то, что выполняется добавление в поле “Логический” таблицы “Таблица1”. Конструкция “SELECT Таблица2.Логический FROM Таблица2;” указывает на то, что данные для добавления выбираются из поля “Логический” таблицы ”Таблица2”.
В результате выполнения этого запроса будет выведено сообщение, приведенное на рис. 3.4.
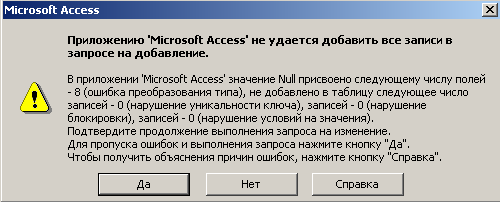
Рис. 3.4. Сообщение, сформированное после выполнения запроса на добавление
Текст сообщения говорит сам за себя. В результате выполнения запроса на добавление для 8-и из 17-и возникла ошибка преобразования типа.
После выполнения запроса Таблица1 примет следующий вид рис. 3.5.

Рис. 3.5. Таблица1 после добавления значений поля ”Логический”
Сравнивая рис. 3.3 и рис. 3.5 легко сделать вывод о том, что пользователь, вероятно, ожидал других результатов добавления.
Конечно, трудно ожидать от разработчиков Microsoft Access, что они смогут предусмотреть все формы записей, соответствующих какому-либо типу, которые придут в голову пользователю.
Значительно лучше обстоит дело в СУБД Microsoft Access с распознаванием текстовых значений, в которых подразумевается дата.
Рассмотрим еще один пример.
В примере задана простейшая структура двух таблиц - для Таблицы3 и Таблицы4. В каждой из них по одному полю. В Таблице4 тип поля - ”Дата”, в Таблицы3 тип поля - ”Текстовый”. В обеих таблицах имена полей одинаковые - ”Дата”. Таблица4 не заполнена. Таблица3 заполнена данными, представленными на рис. 3.6.

Рис. 3.6. Таблица3 с данными
Сформируем запрос на добавление.
INSERT INTO Таблица4 ( Дата )
SELECT Таблица3.Дата
FROM Таблица3;
В результате выполнения этого запроса Таблица4 примет вид, представленный на рис. 3.7.
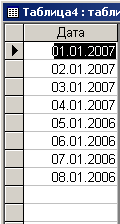
Рис. 3.7. Результат выполнения запроса на добавление
Сравнивая рис. 3.6 и рис. 3.7 нетрудно сделать вывод о том, что, несмотря на различные формы представления даты, большая часть значений успешно преобразовалась. Там, где год не указан, назначается текущий год и это логично. Не преобразовались только последние два значения, которые явно на даты не похожи. Но, к сожалению, в реальных таблицах такого рода ”даты” имеют место.