
Исследование эффективности реализации численных методов на кластерах персональных ЭВМ
| Вид материала | Исследование |
Содержание3.7. Параллельный алгоритм 3.8. Проверка эффективности работы программы Список литературы |
- Рабочей программы дисциплины «Численные методы и программирование» по направлению подготовки, 29.72kb.
- Решение физических задач на эвм" Лекции 20 ч. Практические занятия 96 ч. Учебная, 40.03kb.
- «Исследование и сопоставительный анализ численных методов решения задач не линейного, 321.81kb.
- Автономность эксплуатации без специальных требований к условиям окружающей среды, 258.87kb.
- Тема: «Интеграл» (заключительный урок), 49.41kb.
- Рабочая программа по разделу «Численные методы в строительстве», 71.92kb.
- На первой лекции мы рассмотрим общий смысл понятий бд и субд, 65.83kb.
- Лекция №7. Атрибутивная информация Лекция №7. Атрибутивные данные в гис, 283.92kb.
- Пояснительная записка к курсовой работе по предмету «Языки и технологии программирования», 353.31kb.
- Д. А. Силаев 1/2 года Физическое явление и математическая модель. Математическое исследование, 20.76kb.
3.7. Параллельный алгоритм
Наибольший интерес представляет модуль, в котором реализуется параллельное решение транспортной задачи.
Параллельный алгоритм (блок-схема)
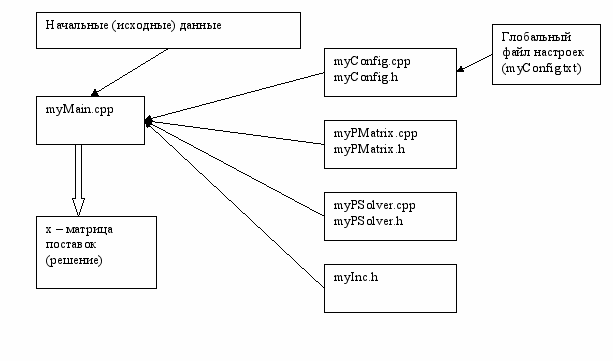
рис. 17
Данный модуль реализует параллельную версию алгоритма решения транспортной задачи.
В состав модуля входят следующие классы:
- myConfig (осуществляет чтение конфигурационных данных)
- myPMatrix (класс матрица)
- myPSolver (решатель)
В последовательной версии реализации алгоритма поля и методы были инкапсулированы в одном классе. В параллельной версии необходимо разделить данные и методы работы с ними.
Следовательно, необходимо создать специальный пользовательский тип, который удовлетворял требования MPI, которые предъявляются к объектам, участвующих в операциях обмена.
typedef struct
{
INT x;
INT y;
REAL value;
CHAR ox;
CHAR oy;
CHAR isBlocked;
} MyMElem;
В итоге в процедурах обмена параметром будет являться переменная типа MyMElem* - которая по сути представляет собой вектор (либо матрицу с числом строк = 1).
Класс myPMatrix во многом повторяет функционал класса myMatrix (он используется в последовательном алгоритме). И как параметр в методы принимает тип MyMElem*.
Так как в программе мы заранее не знаем, какой размер будет у массива, то память под матрицы выделяется динамически.
Посредством класса myPMatrix мы можем осуществлять следующие базовые действия с вектором:
Динамическое выделение памяти:
- MyMElem* allocatemyMatrix();
- MyMElem* allocatemyMatrix(int im, int in);
Инициализация элементов нулевыми значениями:
- void initmyMatrix(MyMElem* pVector);
- void initmyMatrix(int im, int in, MyMElem* pVector);
Заполнение матрицы:
- void fillmyMatrix(MyMElem* pVector);
- void fillmyMatrix(int im, int in, MyMElem* pVector);
Как особенность можно выделить то, что класс myPMatrix работает с вектором как с обыкновенной матрицей. То есть проход по всем элементам осуществляется через вложенный цикл с пересчетом индекса.
Например:
for (i = 0; i
for (j = 0; j
index = i*n +j;
}
printf("\n");
}
Для того, чтобы динамический массив типа MyMElem* мог участвовать в каких-либо операциях обмена, необходимо создать и зарегистрировать для MPI специальный тип.
MPI_Datatype elemtype;
MPI_Datatype oldtypes[3] = {MPI_INT, MPI_LONG_DOUBLE, MPI_CHAR};
INT blockcounts[3] = {2, 1, 3};
// MPI_Aint type used to be consistent with syntax of
// MPI_Type_extent routine
MPI_Aint offsets[3];//, extent;(ïî èäåå íå íóæíà)
MPI_Aint baseaddrr, addrr1, addrr2;
//! testing
MPI_Address(&(va_buffer[0]), &baseaddrr);
MPI_Address(&(va_buffer[0].value), &addrr1);
MPI_Address(&(va_buffer[0].ox), &addrr2);
//! end of testing
offsets[0] = 0;
offsets[1] = addrr1 - baseaddrr;
offsets[2] = addrr2 - baseaddrr;
// Now define structured type and commit it
MPI_Type_struct( 3, blockcounts, offsets, oldtypes, &elemtype);
MPI_Type_commit(&elemtype);
С помощью функции MPI_Type_struct(int count, int *array_of_blocklengths, MPI_Aint *array_of_displacements, MPI_Datatype *array_of_types, MPI_Datatype *newtype) мы создаем структурный тип данных newtype из count блоков по array_of_blocklengths элементов типа array_of_types. Причем i-й блок начинается через array_of_displacements[i] байт с начала буфера посылки. Этот момент является очень важным, так как память для переменной может выделять не целым куском. И между элементами могут возникать пробелы.
Затем с помощью MPI_Type_commit(MPI_Datatype *datatype) регистрирую производный тип данных. После регистрации этот тип данных можно использовать в операциях обмена наравне с предопределенными типами данных (предопределенные типы данных регистрировать не нужно).
В конце необходимо освободить память:
MPI_Type_free(&elemtype);
С помощью этой функции происходит аннулирование производного типа данных. Параметр функции принимает значение MPI_DATATYPE_NULL. Причем гарантируется, что любой начатый обмен, использующий данные аннулируемого типа, будет нормально завершен. При этом производные от elemtype типы данных остаются и могут быть использованы далее. А предопределенные типы данных не могут быть аннулированы.
Далее для наиболее эффективной рассылки необходимо выбрать способ обмена данными между элементами кластера в ходе вычислений.
Наиболее распространенной схемой является та, в которой рассылающий процесс сам участвует в вычислениях.
Однако если нужно переслать массив значительной размерности, то имеет смысл использовать настраиваемую схему рассылки. Через конфигурационный файл myConfig.txt можно настроить количество элементов вектора передаваемых за один раз от корневого процесса какому-либо из рабочих.
Для наглядности приведем логическую блок-схему такого метода рассылки данных.
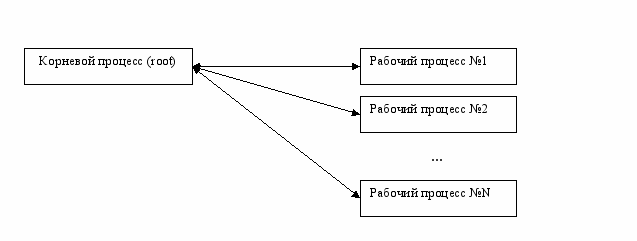
рис. 18
На первом этапе работы корневой процесс рассылает всем рабочим процессам по одному пакету. Если пакетов не хватает, то посылается сигнал, говорящий о том, что пакеты закончились. Затем корневой процесс переходит в режим ожидания ответа, о том, что посланный пакет успешно получен адресатом (рабочим процессом). Как только приходит уведомление о приеме пакета принявшему процессу отправляется дополнительный пакет, и корневой процесс снова переходит в режим ожидания ответа. Это продолжается до тех пор пока не будут разосланы все пакеты и не получены ответы об их успешной доставке адресатам (рабочим процессам).
Следует отметить процесс, который будет находиться на самом быстром участке кластера, получит свою порцию данных самым первым.
К достоинствам данного алгоритма стоит отнести тот момент что как только рабочий процесс получает свою порцию данных, то он отсылает сообщение корневому процессу о своей переполненности.
Итак, в группе процессов определяется корневой процесс (root), который занят тем, что считывает исходные данные, рассылает их другим процессам и аккумулирует результат. Все остальные процессы автоматически становятся рабочими, т.е. участвуют только в приеме данных, вычислениях и отсылке вычислений.
Для реализации параллельных вычислений необходимо выделить независимые части алгоритма. Для распараллеливания подходят:
- методы поиска опорных планов,
- проверка типа транспортной задачи,
- решение уравнения (рис. 15).
В качестве примера рассмотрим параллельную реализацию метода минимального элемента.
Логически программный код состоит из двух частей:
- Код, выполняемый на корневом процессе
- Код, выполняемый на подчиненном процессе (рабочем)
В программе это реализуется функцией:
myPSolver::findBasisMin( myPMatrix a, myPMatrix b, myPMatrix c, myPMatrix x, MyMElem* va, MyMElem* vb, MyMElem* vc, MyMElem* vx, ofstream& out)
Исходный код этой функции приводится в приложении.
3.8. Проверка эффективности работы программы
Для анализа эффективности программа запускалась на кластере БЕЛТА. Этот кластер был построен на основе сети FAST ETHERNET. Сеть находиться под управлением сервера, то есть все компьютеры находятся в одном домене (одно из условий корректной установки пакета MPI).
Кластер состоял из четырех машин (Pentium-4 1800 МГц, 512 МБ ОЗУ, 40ГБ).
Этапы развертывания MPICH:
- Установка пакета MPICH (mpich.nt.1.2.5.exe) на все машины. Желательно устанавливать в одну и ту же директорию;
- Установка значении переменных окружения (path = %SystemRoot%\system32;%SystemRoot%;c:\Program Files\MPICH\mpd\bin\; c:\Program Files\MPICH\SDK\Lib\). То есть необходимо для каждой машины прописать местоположение файла mpirun.exe;
- Создание на всех компьютерах share-папки. Ее абсолютный путь должен быть одинаковым для всех хостов;
- Затем необходимо зарегистрировать MPICH. Для этого необходимо запустить mpiregister.exe;
- Для того чтобы без проблем выполнялась команда mpirun c ключом (–np) необходимо запустить mpiconfig.exe;
- Затем exe-файлы программы необходимо скопировать во все share-папки.
Результаты тестирования:
| | Поиск опорного плана методом минимального элемента | |||
| | Ускорение | | | |
| | Число процессов | | ||
| Размерность задачи (m*n) | 1 | 2 | 3 | 4 |
| 100 | 1 | 0,841 | 0,825 | 0,773 |
| 500 | 1 | 1,632 | 1,857 | 2,015 |
| 1000 | 1 | 1,651 | 2,211 | 2,31 |
| 10000 | 1 | 1,756 | 2,401 | 2,682 |
| 100000 | 1 | 1,89 | 2,91 | 3,4 |
| | | | | |
| | | | | |
| | Поиск опорного плана методом северо-западного угла | |||
| | Ускорение | | | |
| | Число процессов | | ||
| Размерность задачи (m*n) | 1 | 2 | 3 | 4 |
| 100 | 1 | 0,851 | 0,836 | 0,778 |
| 500 | 1 | 1,653 | 1,863 | 2,185 |
| 1000 | 1 | 1,698 | 2,345 | 2,485 |
| 10000 | 1 | 1,802 | 2,5 | 2,751 |
| 100000 | 1 | 1,925 | 2,947 | 3,68 |
| | | | | |
| | | | | |
| | Поиск оптимального плана методом потенциалов | |||
| | Ускорение | | | |
| | Число процессов | | ||
| Размерность задачи (m*n) | 1 | 2 | 3 | 4 |
| 100 | 1 | 0,741 | 0,814 | 0,744 |
| 500 | 1 | 1,558 | 1,734 | 1,985 |
| 1000 | 1 | 1,642 | 2,148 | 2,291 |
| 10000 | 1 | 1,686 | 2,341 | 2,583 |
| 100000 | 1 | 1,88 | 2,908 | 3,501 |
рис. 19
| Подписи графика | Размерность задачи |
| Ряд 1 | 100 |
| Ряд 2 | 500 |
| Ряд 3 | 1000 |
| Ряд 4 | 10000 |
| Ряд 5 | 10000 |
График для метода минимального элемента
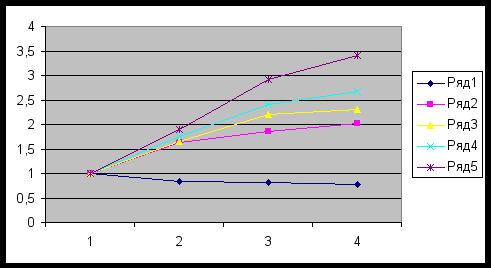
График для метода северо-западного угла
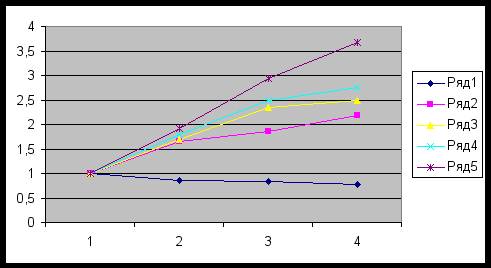
График для метода потенциалов
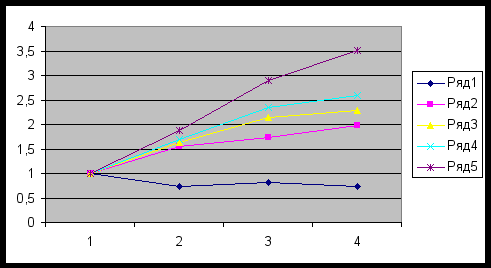
Согласно полученным результатам ускорение при небольших размерностях задачи значительно меньше 1. Это значит алгоритм неэффективно работает при небольших размерностях задачи. Однако для больших размерностей мы получаем значительный выигрыш. Таким образом при увеличении размерности матриц соотношение операций пересылок и полезных операций уменьшается.
Заключение
В ходе работы были рассмотрены технологии параллельного программирования (классификация архитектур параллельных ЭВМ, кластеры, интерфейс параллельного программирования MPI), способы анализа эффективности реализации численных методов посредством формульного анализа, проанализирована эффективность параллельных алгоритмов. Был изучен математический аппарат задач линейного программирования. Было создана и оттестирована программа, реализующая последовательную и параллельную версии решения транспортной задачи. В результате тестирования был сделан вывод, что данный алгоритм подходит для решения транспортных задач. Также были выявлены факторы, влияющие на масштабируемость параллельных вычислений.
Список литературы
- Программирование для многопроцессорных систем в стандарте MPI: Пособие / Г.И. Шпаковский, Н.В. Серикова. – Мн.: БГУ, 2002
- Руководство по работе на вычислительном кластере: Пособие / Г.И. Шпаковский, А.Е. Верхотуров, Н.В. Серикова. – Мн.: БГУ, 2004
- Вл.В.Воеводин, А.П.Капитонова. "Методы описания и классификации вычислительных систем". Издательство МГУ,1994.
- Параллельное программирование с использованием технологии MPI: Пособие / Анотонов А.С. – М.: Изд-во МГУ, 2004, 71 с.
- Метод формульного анализа масштабируемости (ФАМ): Пособие по курсу “Архитектура высокопроизводительных ЭВМ” / Шпаковский Г.И. – Мн.: БГУ, 2005
- Мулярчик С.Г. Численные методы: Конспект лекций. Мн., БГУ, 2001
- Программирование многопроцессорных вычислительных систем: Пособие / Букатов А.А., Дацюк В.Н., Жегуло А.И. – Ростов-на-Дону: ООО «ЦВВР», 2003, 208 с.
- Hwang K., Briggs F.A. Computer Architecture and Parallel Processing. 1984. P.32-40.
- Flynn M. Very high-speed computing system // Proc. IEEE. 1966. N 54. P.1901-1909.
- Skillicorn D. A Taxonomy for Computer Architectures // Computer. 1988. V.21. N 11. P.46-57.
- Dasgupta S. A Hierarchical Taxonomic System for Computer // 1990. V.23. N 3. P.64-74.
- Интернет адрес: ссылка скрыта
- Интернет адрес: ссылка скрыта