
Принципы имитационного моделирования
| Вид материала | Лекция |
- Сравнение качества генерирования случайных чисел в системах имитационного моделирования, 22.53kb.
- Удк 004. 94 Взаимодействие агентов в распределенной дискретно-событийной системе имитационного, 84.04kb.
- Программа дисциплины Имитационное моделирование экономических процессов Семестры, 11.15kb.
- Становление и развитие имитационного моделирования в украине, 227.76kb.
- Исследования, научную и практическую значимость проводимых исследований; выбирать оптимальные, 147.35kb.
- Н. В. Карасева московский инженерно-физический институт (государственный университет), 30.54kb.
- Преимущества использования среды моделирования, 41.26kb.
- Технический отчет по курсу: «Математическое моделирование инженерно геодезических задач, 300.65kb.
- Компьютерное моделирование массового обслуживания клиентов на фармацевтическом рынке, 202.1kb.
- Сопоставление результатов расчетов насосной станции как системы массового обслуживания, 76.25kb.
Имитационное моделирование в экологии 1
Лекция 1.
Принципы имитационного моделирования
Все модели неправильны, но многие из них полезны.
Дж. Бокс
Можно построить имитацию любого явления, располагая всего одним числом.
А. В. Коросов
Ключевые слова
модель, этапы моделирования, классификации моделей, мысленные, аналитические, автоматные, статистические, имитационные модели, статические, динамические модели, переменные, зависимые, независимые переменные, реальные, модельные переменные, параметры, шаг модели, имитационная система
Модель – заместитель (образ) реального объекта (явления), обладающий упрощенной структурой и служащий для изучения основных свойств оригинала; модель строится исследователем, исходя из определенных целей. Неполнота моделей целесообразна.
Любая модель имеет параметры и переменные. Известная регрессионная линейная модель y = ax + b имеет переменные (x, y) и параметры (a, b).
Переменные – это реальные характеристики природных объектов, измеренные в природе. Независимые переменные – это обычно свойства среды (температура, влажность, освещенность, высота над уровнем моря и пр.), влияющие на биологические объекты. Зависимые переменные – это характеристики собственно объектов биологического исследования – особей растений, животных, их популяций, сообществ. Деление на независимые и зависимые переменные условно и определяется только структурой модели. Например, теплопотеря гомойотермных животных зависит от длины и густоты меха (независимая переменная), однако интенсивность теплопотерь определяет скорость роста подшерстка и, таким образом, определяет густоту меха – зависимая и независимая переменные меняются местами в зависимости от задач (и продолжительности) исследования.
Параметры – это числа, коэффициент, выражающие пропорции между переменными. Суть моделирования зачастую состоит только в том, чтобы оценить параметры функционирования природных объектов. Значения параметров (наряду со структурой модели) характеризуют механизмы протекания процессов в природе. Параметры выражают устойчивые соотношения, т. е. закономерности отношений между природными объектами. Зная величину параметров, можно понять ход биологических процессов – не только описать, но и предсказать природную динамику.
Структура модели – это математические средства, используемые при записи соотношений между переменными и параметрами. Для большинства эколого-биологических моделей достаточно 8 действий – 4 арифметических, возведение в степень, логарифмирование, округление, ликвидация знака. С этой точки зрения предел сложности имитационных моделей – это алгебраические модели. Из числа наиболее часто используемых моделей следует назвать линейные y = ax + b и степенные y = bxa. Структура имитационных моделей, кроме того, задается последовательными временными шагами.
^
Общие этапы моделирования (Фактически этапов больше)
- Выдвижение цели моделирования (исследования), подбор информации, данных.
- Построение математического выражения (алгебраических формул).
- Построение имитационной системы, настройка модели.
- Статистическое оценивание результатов (параметров).
- Эксперименты с моделью, выяснение существа изучаемого явления.
^
Классификация моделей
Вариантов классификаций очень много, ограничимся основанием: доступность для биологов.
1. Мысленные (и вербальные, словесные) модели позволяют создавать внутренний образ оригинала, с них начинается любое количественное моделирование, они служат для выдвижения четко сформулированных целей исследования и моделирования.
2. ^ Аналитические модели – системы дифференциальных уравнений. Обычно биологам недоступны? Характерная особенность состоит в том, что время входит в модель в качестве отдельной переменной. В том числе и в силу этого многокомпонентные дифуры не имеют аналитического решения и его приходится отыскивать с помощью численных методов приближения – оптимизации. Благодаря этой потребности численные методы оценки модельных параметров оказались хорошо развитыми, а в среду Excel включен макрос оптимизации, необходимый нам для построения имитационных моделей. ПО существу наши имитационные модели есть сильно упрощенные дифференциальные уравнения, решаемые с помощью численного приближения.
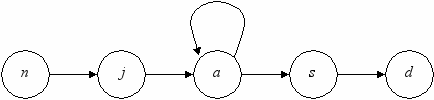
3. ^ Автоматные модели служат для отображения серии дискретных состояний объекта исследования, в которые он может переходить вследствие воздействия внешних или внутренних факторов, включая время. Например, дискретно можно представить онтогенетические стадии зрелости – новорожденный, молодой, взрослый, старый, мертвый. Для автоматных моделей пользуются графическим приложением теории графов и называют дискретные состояния узлами. Переход между состояниями отображается линией – дугой. Временные промежутки жизни модели задаются дискретно, как временные шаги равной протяженности. За один временной шаг особь либо может сменить состояние (идти по дуге), либо остаться в нем (петля – обычно дольше всего особи остаются во взрослом состоянии). Количественно такая модель задается таблицей переходов, каждая строка которой содержит ссылки на ячейки, куда следует переходить на следующем временном шаге.
4. Статистические модели – уравнения регрессии, выражающие обобщенные статистические соотношения изучаемых переменных y = f(x). Это глубоко эмпирические конструкции, основанные на статистической теории, служащие для доказательства реальности существования зависимостей между переменными. В основе регрессионных моделей лежит метод наименьших квадратов, применение которого ограничено рядом требований (относительно большой объем данных, нормальность распределения переменных и пр.). Это сужает область применения регрессионных моделей. В частности, с их помощью сложно исследовать редкие события и динамику систем.
5. ^ Имитационные модели призваны создавать детальный портретный количественный образ объекта исследования. Обычно под имитационным моделированием подразумевается следующая процедура. Сначала в природе замеряются различные переменные, между ними отыскиваются коэффициенты пропорциональности (в первую очередь с помощью статистических методов). Затем в среде компьютера строиться модель динамики изучаемой системы, использующая оцененные ранее коэффициенты (параметры). Однако возможен и иной подход, дополненный процедурой численной настройки модели. Суть подхода состоит в том, чтобы с помощью процедуры оптимизации подобрать такие параметры, чтобы расчетные модельные переменные максимально приблизились бы к наблюдаемым природным реальным переменным. Главное правило имитационного моделирования: выразить через неизвестные параметры известные переменные. Важной чертой имитационных моделей является вывод из структуры модели переменной время. Оно задается дискретно как шаги с помощью внешних процедур. На листе Excel одному временному шагу соответствует одна строка, содержащая стереотипные модельные формулы. Продолжительность временного шага определяется целями моделирования и может быть равна как миллисекундам, так и столетиям (в экологии популяций обычно - году). Одна строка описывает события, осуществляющиеся синхронно. Результаты этих вычислений необходимым образом передаются на следующие временные шаги.
^
Формализация: блок-схема
Для однозначного структурного выражения модели в виде уравнений (формул листа Excel) требуется сначала разобраться с логической структурой модели, жестко формализовать первичные словесные или мысленные представления об объекте исследования. Средством такой формализации служат схемы – блок-схемы или идеограммы. Идеограммы обычно выражают планируемые математические операции в предельно конкретном виде множества математических действий (см. идеограммы Иванищева). Блок-схемы служат для обозначения однотипных, но крупных действий и часто выражают группы из нескольких действий (см. блок-схемы Форрестера).
И то и другое (субъективно) кажется не очень удобным (либо очень частным, либо слишком общим). На наш взгляд, удобнее использовать одну базовую конструкцию блок-схемы (и одну частную). Стрелками выражаются переменные, изменяемые потоки, имеющие единицы измерения; за ними стоят реальные вещественно-энергетические объекты (имеющие массу, длину, температуру и пр.). Входные потоки являются условно-независимыми (обозначаются обычно x), выходные результирующие потоки являются зависимыми переменными (обозначаются y). Блоками (прямоугольниками) обозначаются процессы преобразования одних потоков – в другие. Эти процессы могут быть выражены простыми или сложными уравнениями, обычно – линейными или степенными y = f(x). В качестве дополнительных элементов блок-схемы используются блоки суммирования или разности между переменными. Вынесение этих операций за рамки основного элемента позволяет разбивать сложные уравнения на серию составных.
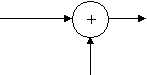
Дополнительным элементом, полезным для построения блок-схем имитационных моделей выступает операция суммирования y = y1 + y2, которая может быть представлена кружком со стрелками.
Обычно в любых учебниках и монографиях биологов, не связанных с моделированием, блок-схемы, изображающие биологические явления, построены с нарушением предложенных приемов (стрелка – только поток, блок – только процесс). Однотипные элементы таких схем имеют разную природу. Это не позволяет непосредственно выполнять построение уравнений по таким схемам, и вначале из приходится исправлять.
Задание: найти 3 блок-схемы в учебниках биологии и экологии, исправить в соответствии с требованиями для моделей.
^
Статические имитационные модели
Статические модели призваны отображать явление в целом, безотносительно от его динамики. Такие модели почти во всем подобны регрессионным, но имеют два ценных отличия. Во-первых, из можно построить по существенно ограниченным данным, используя пропуски в данных. Во-вторых, в случае со степенными моделями получаются долее правильные результаты, нежели в регрессионном анализе. Дело в том, что линейная схема метода наименьших квадратов (используемая для поиска коэффициентов регрессии) требует в случае криволинейной зависимости предварительного «испрямления» данных, которое выполняется логарифмированием. Для этих данных рассчитываются линейные коэффициенты регрессии, которые затем «восстанавливаются» обратным преобразование. Однако при логарифмировании происходит ничем биологически не оправданное взвешивание значений – большие снижают свою значимость, а небольшие величины приобретают дополнительную значимость. Это приводит к получению неправильных линий криволинейной регрессии. Процедура прямой подгонки (оптимизации) лишена этого недостатка.
Смысл построения модели состоит в определении коэффициентов пропорциональности (a, b) между переменными (x, y).
Процедура определения параметров состоит из двух этапов. Сначала строится модель yм = f(a, b, xр) – серия модельных уравнений, рассчитывающих значения зависимой (модельной) переменной (yм) на основе независимой реальной переменной (xр), с использованием параметров (a, b). Исходные значения параметров задаются исследователем: это могут быть биологически осмысленные примерные значения, случайные числа или значения 1. На втором этапе значения параметров (a, b) последовательно перебираю с помощью специальной процедуры с целью максимально приблизить значения модельных зависимых переменных yм к значениям реальных зависимых переменных yр: ф = (yм – yр)2 → 0.
Для реализации процедуры подгонки параметров строится имитационная система – некое множество информационных блоков, обслуживающих построение модели. В состав имитационной системы входят блоки: столбцы с исходными данными (A, B), столбец с модельными формулами (C), столбец с расчетами невязки ф (квадрата отличий модели от реальности) (D), блок параметров (2 ячейки). Стрелками показаны отношения между компонентами имитационной системы.
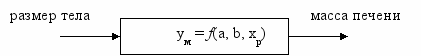
| A | B | C | D | E |
| независимая р  еальная еальнаяпеременная | зависимая реальная переменная | зависимая модельная переменная | невязка | параметры |
| xр | yр | yм | (yм – yр)2 | a |
| | | | | b |
Для примера рассмотрим исследование зависимости массы печени от размеров тела живородящей ящерицы. (предполагается, что модельное построение выполняется читателем на листе Excel) В первом приближении выберем значения параметров, равными 1. Тогда расчетная масса печени будет равна в каждом случае размеру тела:
Pmod = 1*Lt1.
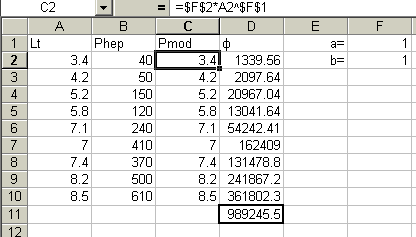
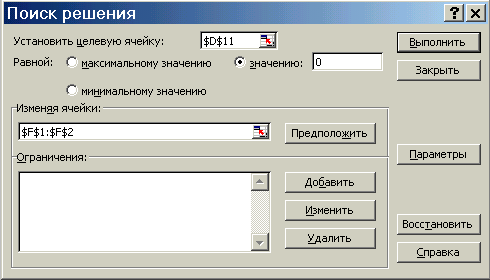
Для настройки модели (подгонка параметров) вызовем макрос (Сервис \ Поиск решения) и заполняя окно: ^ Установить целевую ячейку $D$11 (суммарная невязка), Равной значению 0 (минимум отличий модели от реальности), Изменяя ячейки $F$1:$F$2 (значения параметров), Выполнить. Появившееся окно означает только то, что функцию невязки не удалось свести к нулю. Однако это обычный результат – полная идентичность модели и реальности практически никогда не достигается; жмем ОК. Как видно значение невязки сократилось в 500 раз – с 989245 до 21666, что уже хорошо. Об адекватности полученных результатов следует судить с использованием статистических методов. Пока следует рассмотреть резултаты.
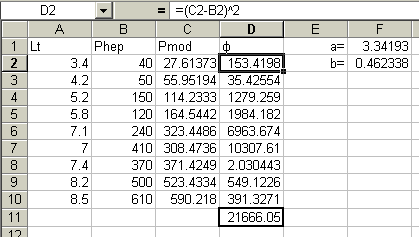
Полученный коэффициент пропорциональности массы печени и длины тела a = 3.3 соответствует соотношению линейных и объемных размеров геометрических тел. Иными словами, масса печени прямо пропорциональна объему тела ящерицы, а учитывая плотность, близкую к 1 – массе тела. Функция печения как барьерного органа объясняет этот результат: объем печени пропорционален объему протекающих в организме обменных процессов.
^
Динамические имитационные модели
Динамические модели позволяют изучать механизм явления, детальную картину протекания внутренних процессов на каждом временном шаге раздельно (i – 1, 2, … n – номера шагов модели). Модель состоит из двух главных частей – это осуществление изучаемого процесса на данном шаге жизни модели (dyi), и результат хода процесса на всех предыдущих шагах (yi). Например, рост особи по годам предстает как годовой прирост (частный результат), который добавляется в общим размерам особи (общее достижение за все годы роста):
dyi = f(a, b, yi)
yi+1 = yi + dyi.
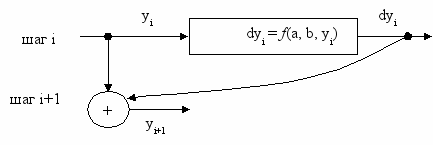
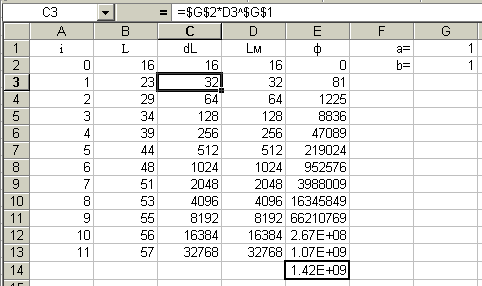
Модель строиться в двух столбцах листа Excel: в одном рассчитывается текущий прирост, во втором – этот прирост прибавляется к ранее достигнутым размерам. В целом имитационная система имеет пять столбцов, в которых включены следующие данные: счетчик шагов (A), реальная переменная, наблюдаемый размер тела (B), модельный прирост (C), модельный размер (D), невязка (E) и блок параметров (F).
| A | B | C | D | E | F |
| Счетчик | р  еальная еальнаяпеременная: размеры | модельная переменная: прирост | модельная переменная: размеры | невязка | параметры |
| i | yрi | dyi | yi | (yi– yр)2 | a |
| i+1 | | | yi+1 | | b |
| i+2 | | | | | |
Важно отметить, что исходные значения размеров тела yрi используются только для вычислении функции невязки, но не включены в формулу расчета прироста. Исключением является самое первое, стартовое значение yр1, которое берется в качестве первого модельного значения yм1 = yр1. (есть и другие варианты определения стартового значения).
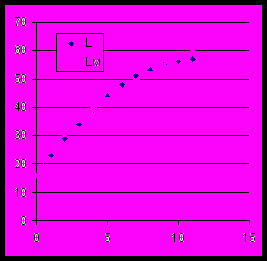
В качестве примера рассмотрим рост (L) обыкновенной гадюки по годам (i). Для определения величины годового прироста использовали степенную модель dL = b*L a.
П
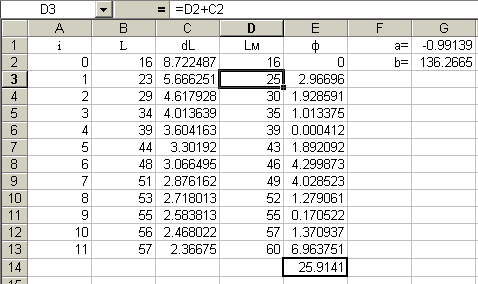
 осле настройки модель прироста оказалась следующей: dL = 136*L –0.99.
осле настройки модель прироста оказалась следующей: dL = 136*L –0.99. Отрицательный степенной коэффициент говорит о том, что чем боле значение L, тем меньше значение dL, т. е. чем крупнее гадюка, тем меньше ее прирост. Вместе с том, коэффициенты сложно интерпретировать, поскольку доля 0.99 каждый раз исчисляется из нового значения прироста.
Это заставляет перестроить модель и использовать более простую, линейную модель прироста:
dL = b + L*a.
После настройки она обрела вид:
dL = 9.6 + L*–0.14.
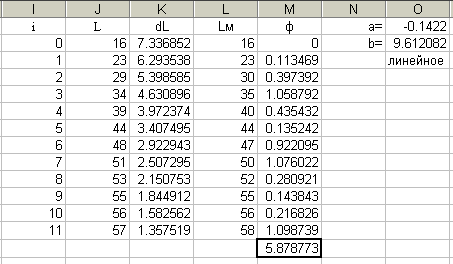
Полученные коэффициенты имеют гораздо более прозрачную интерпретацию. В нулевой год жизни прирост составил 9.6 см, а в дальнейшем каждый год уменьшался на величину, пропорциональную 14% от достигнутой длины тела. Эти значения имеют ясное биологическое содержание и их интересно оценивать и сравнивать для разных экологических групп (самки и самцы), разных местообитаний, ареалов, видов и пр.