
Распределенные информационные системы
| Вид материала | Документы |
- Направление 230400 «Информационные системы и технологии», 20.25kb.
- Программа дисциплины «информационные сети» Индекс дисциплины по учебному плану: опд., 123.28kb.
- Многоуровневая учебная программа дисциплины электротехника и электроника для подготовки, 409.29kb.
- Программа дисциплины «вычислительная математика» Индекс дисциплины по учебному плану:, 550.42kb.
- Реферат по курсу «Микропроцессорные системы» на тему «Распределенные вычислительные, 377.31kb.
- Программа государственного экзамена по специальности: 230201. 65 «Информационные системы, 450.31kb.
- В. П. Информационные системы в технике и технологиях. Ч. Диплом, 1332.77kb.
- Информационные технологии управления лекция 6 Информационные системы планирования (бюджетирования), 41.66kb.
- Конспект лекций по дисциплине «Информационные системы в экономике», 1286.5kb.
- Рабочая программа по дисциплине "алгоритмизация и программирование" для специальности, 136.78kb.
РАСПРЕДЕЛЕННЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Ю.А. Илларионов
ГЛАВА 1. АНАЛИЗ СОСТОЯНИЯ РАЗВИТИЯ ОСНОВНЫХ КОНЦЕПЦИЙ И АЛГОРИТМОВ УПРАВЛЕНИЯ ДЛЯ РАСПРЕДЕЛЁННЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ НА БАЗЕ ЛОКАЛЬНЫХ СЕТЕЙ.
1.1. Определение области исследования.
Распределённой вычислительной системой (РВС) будем называть систему, состоящую из двух компонентов: множества электронно вычислительных машин (ЭВМ) и сети связи (или сети передачи данных), объединяющей все ЭВМ, входящие в РВС. Всю полезную обработку информации производят вычислительные процессы, выполняющиеся на хост ЭВМ. Всю обработку информации, связанную с необходимостью её передачи через сеть связи, выполняют процессы, расположенные на коммуникационных ЭВМ[1,5,32].Коммуникационные ЭВМ необходимы в сетях связи, имеющих сложную многосвязную топологию, при условии, что прямые физические соединения (каналы) между взаимодействующими посредством передачи информации хост ЭВМ отсутствуют.
Таким образом, учитывая, что для эффективной обработки информации в РВС необходимо не только эффективно её обрабатывать на хост ЭВМ, но и эффективно (т.е. с наименьшими задержками) передавать её через сеть связи, работы в области РВС разделились на две группы:
1. Работы в области организации взаимодействия вычислительных процессов в РВС. В этих работах предполагается, что сеть связи уже существует и удовлетворяет определённым требованиям, выдвигаемым к ней. Таким образом, остаётся только решить задачу организации взаимодействия вычислительных процессов, учитывая, что:
- в РВС существует множество вычислительных процессов;
- в РВС существует множество вычислительных ресурсов;
- процессы и ресурсы могут располагаться на разных хост ЭВМ;
- процессы могут выполняться параллельно;
- в системе существует конкуренция распределённых параллельных процессов за ресурсы ЭВМ;
- в РВС существует неоднородность хост ЭВМ и их оперативных систем;
- существует тенденция к децентрализации управления взаимодействием вычислительных процессов в РВС с целью повышения надёжности последних.
2. Работы в области организации процессов передачи информации через сети связи. Для этих работ характерно представление о сети как о множестве портов ввода вывода, между которыми существуют логические соединения. Кто поставляет информацию в эти порты и кто её оттуда забирает, не является в данном случае объектом исследования. Задача состоит только в том, как наиболее эффективно осуществить передачу информации по сети связи от одного порта к другому, при условии, что:
- соединения между портами не являются фиксированными, и структура логических связей в сети может динамически изменяться;
- сеть может иметь многосвязную топологию, в которой отсутствуют непосредственные физические соединения между портами;
- информация в процессе передачи может искажаться;
- потоки информации, включая их объём и направление, заранее не определены;
- для организации передачи информации через сеть связи требуется организовать разделение коммуникационных ресурсов между потоками информации в условиях недостатка этих ресурсов;
- управление разделением коммуникационных ресурсов имеет тенденцию к децентрализации.
Настоящая диссертация относится к работам первой группы и посвящена только вопросам организации взаимодействия вычислительных процессов в РВС. Определим область исследования более точно. Учитывая, что с точки зрения возможностей технических средств РВС в основном различаются по применяемым в них сетям связи, распределённые системы можно разбить на две большие группы: РВС, построенные на базе сетей с маршрутизацией и РВС, построенные на базе сетей с селекцией информации, или сетей с общим каналом связи[33 35]. Настоящая работа посвящена вопросам организации разделения вычислительных ресурсов в РВС, предназначенных для управления производственными процессами в реальном времени и построенных на базе локальных сетей связи с децентрализованным приоритетным управлением доступом к общему каналу. Вопросы децентрализованного приоритетного управления доступом (ДПУ) рассмотрены в работах[25 27]. В этих же работах впервые была высказана мысль о том, что наличие средств ДПУ и средств обработки информации непосредственно в общем канале в процессе передачи может по новому организовать управление взаимодействием распределённых вычислительных процессов в РВС. Другими словами, локальные сети с ДПУ можно рассматривать не только как систему связи, но и как дополнительное средство управления распределёнными системами. Однако, этот вопрос не был до конца исследован.
Итак, основной целью настоящей работы является исследование вопросов разделения ресурсов РВС между вычислительными процессами в условиях существующей распределённости как ресурсов, так и процессов, при наличии множества параллельно возникающих в неопределённые моменты заявок на использование ресурсов; на основании проведённых исследований в работе должны быть разработаны новые высокоскоростные алгоритмы разделения ресурсов для РВС, построенных на базе локальных сетей с ДПУ и средствами вычислений в общем канале (ВОК)[25,26].Как уже было отмечено, исследования будут вестись в области РВС для промышленного применения, т.е. для систем реального времени. С точки зрения вычислительных мощностей этой системы, построенные в основном на базе микропроцессорной техники, поэтому в дальнейшем будем называть такие РВС распределёнными микропроцессорными управляюще вычислительными системами (РМУВС). Учитывая существующие особенности сетей связи для исследуемых систем, проанализируем эти особенности в сравнении с другими известными сетями.
1.2. Особенности локальных сетей с децентрализованным приоритетным управлением доступом к каналу.
Первые публикации, посвящённые принципам передачи информации через общий канал связи в режиме его разделения многими абонентами (с точки зрения сети, абонент – это хост ЭВМ, имеющая доступ к каналу через сетевой контроллер; в более широком смысле абонентом может быть и отдельный процесс, выполняемый на хост ЭВМ), появились в начале 70 х годов[21,61]. К этому моменту был накоплен достаточно большой опыт по созданию РВС на базе глобальных сетей, и это отразилось на решениях, которые в дальнейшем были использованы в РВС на базе локальных сетей (или локальных РВС ЛРВС). В некоторых работах до сих пор не делается различия между организацией управления в глобальных РВС и ЛРВС, а считается, что эти два класса различаются только по протяжённости их линий связи[4,6,7,23]. Появление стандартов IEEE 802[54] и ECMA[68 74] внесло некоторую ясность в этот вопрос, однако только в отношении организации связи с ЛРВС. Поэтому в большинстве работ, посвящённых организации взаимодействия вычислительных процессов в ЛРВС, не учитывается специфика таких систем, которая будет отражена ниже. Однако, ряд авторов считает, что ЛРВС в их современном понимании являются системами, по своим архитектурным особенностям приближающимся скорее к многопроцессорным системам, чем к «вычислительным сетям» в их традиционном понимании[20,25]. В особенности это относится к исследуемым в настоящей работе системам – ряд отличительных признаков позволяет рассматривать их как совершенно новый класс РВС, построенных на базе локальных сетей связи с уникальными возможностями, недоступными в других распределённых системах.
Отметим основные архитектурные особенности локальных сетей связи с ДПУ и ВОК, которые будут иметь значение в дальнейшем исследовании.
- Наличие общего высокоскоростного канала связи. Наличие общего канала делает локальную связь вырожденной, т.к. в такой сети нет необходимости производить основную сетевую процедуру – маршрутизацию пакетов при передаче информации[5,19]. Кроме того, как будет показано в дальнейшем, наличие общего канала в соединении с ДПУ и ВОК позволяют использовать канал не только как средство передачи информации, но и как эффективное средство управления распределённой системой. Высокая скорость передачи информации по каналу позволяет строить сетевые протоколы, используя заголовки довольно большой длины для упрощения протоколов[20]. Другими словами, при такой скорости нет необходимости в минимизации длины передаваемых пакетов. Большие пакеты позволяют перейти к методу коммутации сообщений, более простому с точки зрения организации системного программного обеспечения на транспортном уровне. Кроме того, возможность передачи заголовков большой длины позволяет, как будет показано в дальнейшем, использовать в ЛРВС принципиально новые способы обмена информацией, отличающиеся более высокой эффективностью и простой реализацией по сравнению с существующими.
- Управление доступом к каналу. Механизм управления доступом к каналу во многом определяет характеристики локальных сетей связи. Однако, до последнего времени исследовалось в основном влияние способов управления доступом на пропускную способность канала[25]. Вместе с тем, как отмечалось в работах[25,26] механизм управления доступом оказывает гораздо большее влияние на ЛРВС. В частности, применение ДПУ позволяет решить на низких уровнях ряд задач, которые традиционно решались на верхних уровнях при помощи обмена сообщениями. Вместе с тем, исследования в этой области только начинаются.
- Вычисления в общем канале. Алгоритмы вычислений в общем канале (ВОК) предложены в работах[25,26]. Суть их состоит в том, что информация, проходящая по каналу связи, может быть обработана абонентами распределённой системы без задержки на её обработку. Применение ВОК позволяет осуществлять в ЛРВС групповую обработку информации всеми абонентами в процессе её передачи и даёт возможность получения группового ответа от всех абонентов за одну пересылку информации по каналу, что недоступно в других распределённых системах.
Перечисление особенности сетей связи с ДПУ и ВОК даёт основания считать, что ЛРВС, построенные на базе таких сетей, нельзя рассматривать как «те же большие вычислительные сети, только маленькие», хотя вообще такая позиция в настоящее время широко распространена[3,6,7,23].
Перейдём к рассмотрению основных задач и концепций управления в распределённых системах.
1.3. Основные задачи и концепции управления в распределённых вычислительных системах.
Основной задачей управления в любой вычислительной системе является задача разделения ресурсов в условиях недостатка последних[24,30]. В РВС задача разделения имеет свои особенности, связанные с распределением ресурсов и процессов по различным абонентам системы. Перечислим эти особенности.
- Поскольку в РВС входит множество ЭВМ, то каждая из них может иметь свои ресурсы, доступные для процессов, выполняющихся как локально (т.е. на этой же ЭВМ), так и удалённо (т.е. на другой ЭВМ). Если ресурс является локальным (т.е. полностью принадлежит отдельной ЭВМ), то ответственность за корректную синхронизацию процессов при доступе к такому ресурсу полностью возлагается на эту ЭВМ. В этом случае проблемы синхронизации не возникает, если ресурс является монопольно используемым[24]. Если же ресурс является коммунальным[24], то в РВС возникает проблема разделения такого ресурса из за того, что если в сосредоточенных централизованных системах большинство накладных расходов на организацию разделения (т.е. выделение памяти для буферов и т.д.) берут на себя сами процессы по принципу «кому нужно, тот и платит», то в РВС эти расходы возлагаются на обслуживающую ЭВМ и получается, что «кто обслуживает, тот ещё и платит».
- В РВС ресурс может быть организован таким образом, что для решения о его предоставлении некоторому процессу необходимо коллективное согласие всех ЭВМ, которым принадлежат отдельные части такого ресурса, называемого распределённым. Эта задача возникла первоначально в распределённых базах данных, в которых для обеспечения высокой надёжности хранения информации применялось её многократное копирование и распределение копий по системе. Возникающая при этом задача синхронизации при обновлении многих копий распределённой информации является базовой задачей распределённого управления в РВС, и от эффективности её решения зависит в конечном итоге эффективность управления в целом.
Традиционно в любых вычислительных системах управление разделением ресурсов возлагается на системное программное обеспечение – операционные системы (ОС). Для РВС это также справедливо – подобное программное обеспечение называется распределёнными операционными системами (РОС). Несмотря на большое разнообразие существующих в настоящее время РОС и различие в применяемых в них алгоритмов управления, их можно классифицировать на основании нескольких базовых моделей, приводимых ниже.
Модель МРММ (много ресурсов – много мониторов). Основной идеей, положенной в основу этой модели, является принцип автономности[60], согласно которому любая ЭВМ, входящая в РОС, является «хозяином» своих собственных локальных ресурсов и только она имеет право решать задачу их разделения. При таком подходе на каждой ЭВМ имеется процесс, являющийся монитором ресурсов этой ЭВМ. Все остальные процессы связаны с мониторами посредством механизма обмена сообщениями через транспортную сеть согласно семиуровневой архитектуре |SO/OSI[48,83].Модель МРММ является моделью вычислительной сети в её традиционном понимании; системы, построенные в соответствии с этой моделью, предназначены в основном для реализации «электронной почты» и организации доступа к ресурсам удалённых ЭВМ. Задача управления разделением распределённых ресурсов в таких системах не решается.
Модель МРОМ (много ресурсов – один монитор). Полностью централизованная модель. В систему вводится центральный процесс, являющийся монитором всей системы и в частности, монитором распределённых ресурсов. Все остальные процессы имеют доступ к мониторам только посредством обращения к центральному монитору. Управление разделением распределённых ресурсов в этом случае не составляет трудности, но введение центрального процесса резко снижает надёжность работы РВС. Поэтому централизованные способы управления применяются, как правило, только в самых простых распределённых системах, не предназначенных для ответственных применений[6,7,23].
Модель ОРММ (один ресурс – много мониторов). Модель основана на предположении, что в системе имеется ресурс, надёжность которого намного больше, чем надёжность любого монитора. В действительности, как уже было сказано, такие ресурсы образуются за счёт копирования наиболее важных системных ресурсов и распределения копий по различным абонентам РВС; причём каждая копия имеет свой монитор. Считывать информацию можно параллельно с любой работоспособной копии ресурса, обновлять информацию необходимо на всех копиях. В этих условиях при обновлении информации все мониторы копий должны взаимодействовать с целью с целью принятия коллективного решения о предоставлении ресурса для операции обновления или записи. Такие РВС называются системами с распределённым (децентрализованным коллективным) управлением; их развитию и посвящена настоящая работа. Ключевым вопросом для таких систем является проблема синхронизации мониторов при выработке или коллективного решения. В зависимости от методов, используемых в настоящее время для синхронизации мониторов, РВС этого класса можно разбить на две группы.
В РВС первой группы мониторы взаимодействуют, обмениваясь сообщениями через транспортную сеть. Основное достоинство подобных систем состоит в том, что алгоритмы синхронизации мониторов в этом случае не зависят от структуры сети (топологии, методов доступа и т.д.) и могут быть использованы в любых РВС. Однако, как будет показано в дальнейшем, алгоритмы этого класса требуют пересылки значительного количества сообщений через транспортную сеть, что приводит к большим временным расходам на синхронизацию. При оценке эффективности алгоритмов следует учитывать то, что накладные расходы на пересылку одного сообщения через транспортную сеть составляют около 20 мс для широкого круга распределённых систем[76]. Тем не менее, такой подход к синхронизации широко используется из за отсутствия в настоящее время подходящих альтернативных способов для сетей ЭВМ.
В РВС второй группы для синхронизации мониторов применяются специально выделенные линии связи, по которым возможна передача только синхронизирующей управляющей информации (импульсов, потенциалов на линиях и т.д.). Такой принцип используется в мультимикропроцессорных системах с сетевой организацией, имеющих небольшую протяжённость линий связи. Однако для РВС на базе локальных сетей большой протяжённости (до 2 км) такой подход неприемлем из за значительного увеличения кабельной продукции, поскольку число линий синхронизации может зависеть как от числа распределённых продуктов, так и от числа абонентов системы[36].
Перейдём к рассмотрению известных алгоритмов разделения ресурсов в РВС с распределённым управлением.
1.4. Алгоритмы разделения ресурсов для систем с распределённым управлением.
Все алгоритмы разделения ресурсов для систем с распределённым управлением можно разбить на три группы: алгоритмы с использованием голосования, алгоритмы с использованием предварительной блокировки и алгоритмы с циркулирующей привилегией.
Алгоритмы с использованием голосования основаны на процессе обмена сообщениями между процессами контроллерами с целью прихода к соглашению относительно последовательности транзакций в распределённой системе. Под транзакцией понимается последовательность операций чтения информации из некоторой базы данных, обновления (изменения) считанной информации и записи обновлённой информации в базу данных[39]. Если голосования и выполнение транзакций производителя одними и теми же контроллерами, то голосование называется синхронным[46,62]; если разными, то голосование называется асинхронным.
В алгоритме синхронного голосования [53] контроллер, контроллер, принявший запрос на транзакцию, присоединяет тег – временной штамп из сообщения, содержащего суть запроса и идентификатор пославшего запрос абонента. Далее, если не было инициировано голосование предыдущей транзакции, этот контроллер посылает широковещательное сообщение со своим голосом всем остальным контроллерам (рис. 1.1.). Если предположить, что можно отличить более высокий приоритет некоторой транзакции Та от приоритета транзакции Тс, то система из трёх контроллеров будет работать следующим образом.
1. Контроллер В: если голос для транзакции Тс принят раньше, чем некоторый голос для Та, то контроллер В широковещательно посылает свой голос, отдавая его Тс (рис. 1.1а.). При получении запроса на транзакцию Та В уничтожает Тс и широковещательно отдаёт свой голос транзакции Та (рис. 1.1б.). Если голос за транзакцию Та принят раньше, В сразу отдаёт свой голос за Та, отбрасывая голоса за Тс, пришедшие позднее.
Рис 1.1.
2.Контроллер С: отдаёт свой голос за Та при приёме голоса за Та.
3.Контроллер А: отбрасывает все голоса за Тс.
После приёма голосов от всех контроллеров за одну и ту же транзакцию (в рассмотренном случае Та) каждый из контроллеров начинает выполнение этой транзакции.
В другом алгоритме синхронного голосования явно выделяется инициирующий контроллер[45]. Если транзакция поступила к контроллеру на выполнение (т.е. от пользователя), то этот контроллер инициирует голосование, посылая запрос на начало голосования остальным контроллерам. Если все остальные контроллеры ответят на этот запрос передачей сообщения АСК+, то транзакция принимается и инициирующий контроллер широковещательно посылает UPD сообщение для локальных инициаций транзакции всеми остальными контроллерами. Контроллеры, закончившие локальное выполнение транзакции (или вообще не начинавшие её выполнение) сигнализируют ответом END инициатору. После приёма END – сообщений от всех контроллеров, инициатор переходит в начальное состояние. Контроллеры, завершившие очередную транзакцию, также переходят в начальное состояние и готовы для новых транзакций.
Каждый из контроллеров, приняв запрос на новую транзакцию, может начать её выполнение только в том случае, если она совместима с текущей транзакцией, выполняемой контроллером. Только в этом случае сообщение АСК+ может быть послано инициатору, и начаться выполнение новой транзакции после приёма UPD. Транзакции считаются совместимыми, если они запрашивают различные наборы чтения и записи для своего выполнения.
Приоритеты транзакций различаются согласно алгоритму, приведённому в работе[52].На рис. 1.2. показано, как различается конфликт в том случае, когда две совместимые транзакции инициируют запрос на голосование. Контроллеры А и С голосуют за Та и Тс конкурентно. Контроллер В голосует за обе транзакции, т.к. он находится в начальном состоянии. А и С голосуют друг за друга после проверки, что транзакции Та и Тс совместимы (б). Инициируется локальное выполнение транзакций (в) и после завершения локального выполнения сигнализируется окончание (г).
Алгоритмы асинхронного голосования были использованы в распределённой базе данных SDD 1[40,41,66,67]. В этой системе транзакции группируются в набор классов транзакций в соответствии сих наборами чтения и записи. Классы транзакций предварительно определяются администратором базы данных. С целью уменьшения затрат на синхронизацию разработаны четыре различных протокола синхронизации. Протокол Р1 предоставляет управление на нижнем уровне, обладая минимальной стоимостью и высокой эффективностью, в то время, как протокол Р4 обеспечивает верхний уровень управления, обладая большими накладными расходами. Протоколы выбираются в соответствии с классами транзакций. Упорядочивание запросов чтения/записи от различных параллельных транзакций осуществляется путём присваивания временных штампов транзакциям и записи этих временных штампов во все запрошенные элементы базы данных, к которым конкретная транзакция имеет доступ[81].Изменение копии элемента базы данных предоставляется транзакции только в том случае, если временной штамп запроса транзакции на изменение более новый по сравнению с временным штампом копии.
Это гарантирует, что все копии приходят в одинаковое состояние одновременно с прекращением процедур их обновления.
Класс транзакций
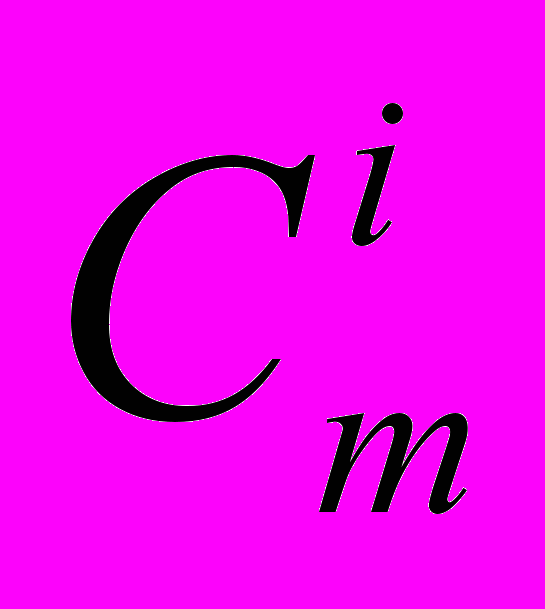 в SDD 1 определён как набор транзакций, связанных с отдельной хост ЭВМ, на которой расположена новая база данных. Все транзакции, принадлежащие характеризуются взаимоисключающими наборами чтения
в SDD 1 определён как набор транзакций, связанных с отдельной хост ЭВМ, на которой расположена новая база данных. Все транзакции, принадлежащие характеризуются взаимоисключающими наборами чтения 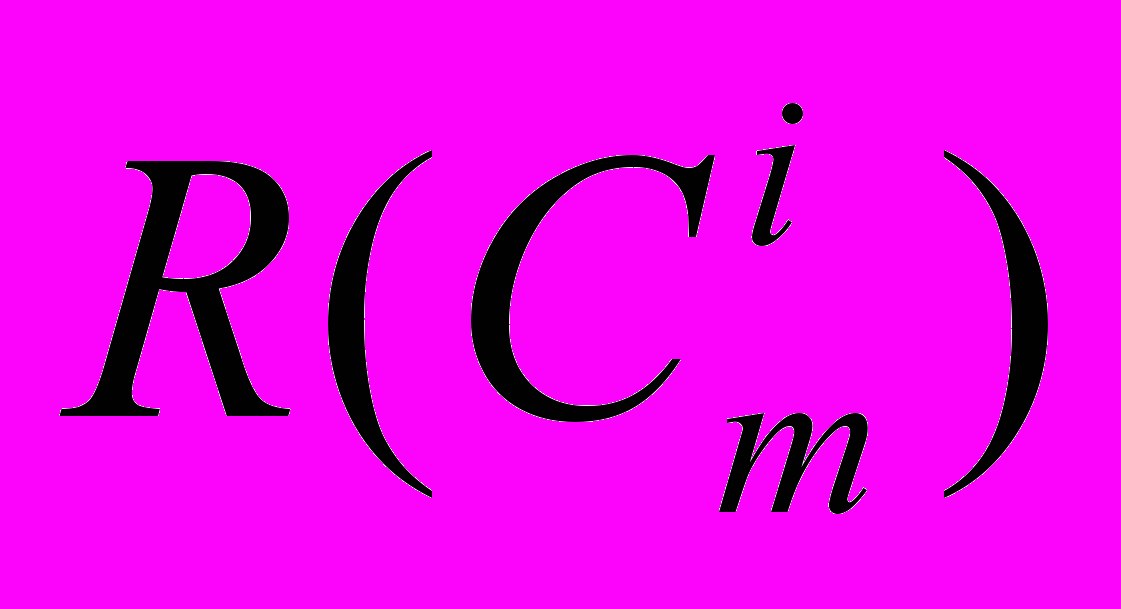 и взаимоисключающими наборами записи
и взаимоисключающими наборами записи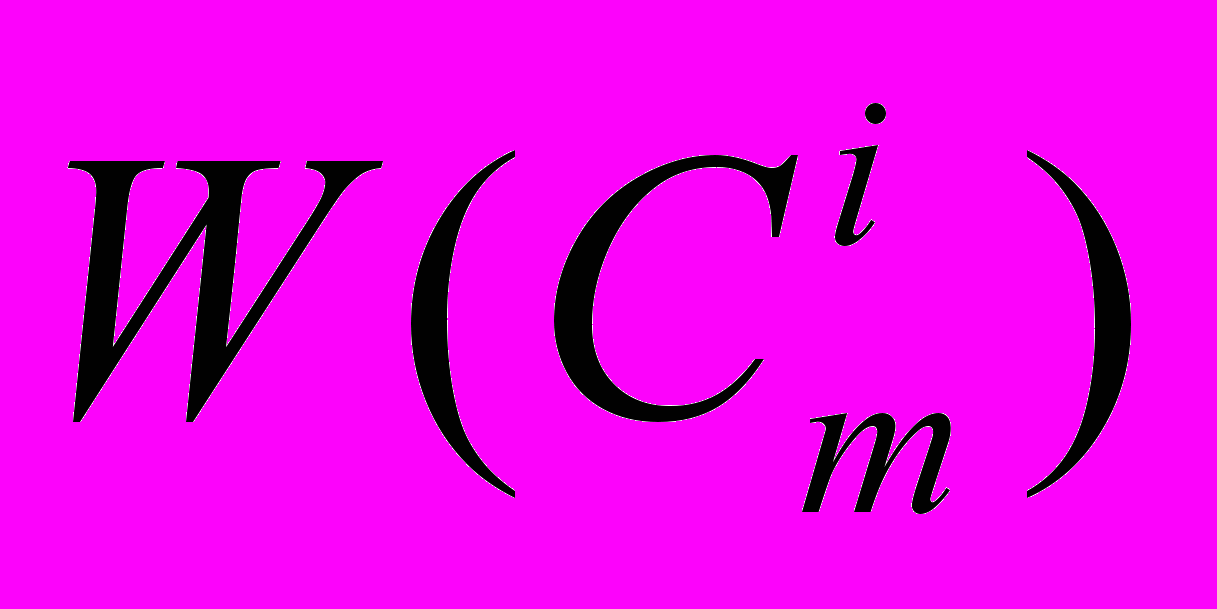 .Транзакции обрабатываются в двух стадиях следующим образом. В течение первой стадии каждая транзакция обрабатывается локально на той хост ЭВМ, где она была инициирована; при этом используется копия базы данных, принадлежащая этой ЭВМ. Все необходимые операции чтения/записи выполняются локально; генерируется и сохраняется список изменений базы данных. Локальное выполнение транзакции определяется как примитивная акция
.Транзакции обрабатываются в двух стадиях следующим образом. В течение первой стадии каждая транзакция обрабатывается локально на той хост ЭВМ, где она была инициирована; при этом используется копия базы данных, принадлежащая этой ЭВМ. Все необходимые операции чтения/записи выполняются локально; генерируется и сохраняется список изменений базы данных. Локальное выполнение транзакции определяется как примитивная акция 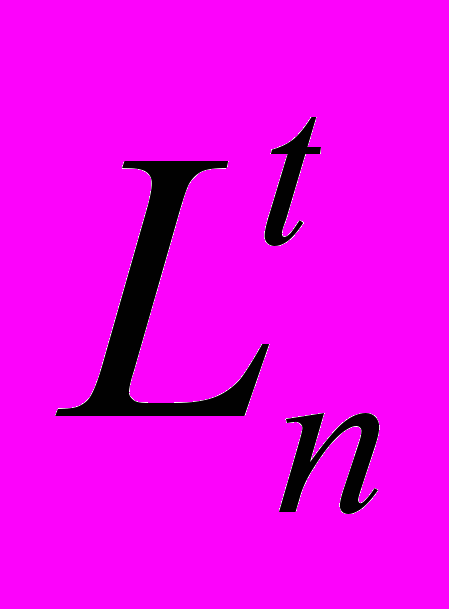 . Как только первая стадия транзакции завершена, контроллер широковещательно посылает список изменения базы данных всем остальным контроллерам, которые обновляют свои копии согласно присланному списку. Эти действия определяются как другая примитивная акция
. Как только первая стадия транзакции завершена, контроллер широковещательно посылает список изменения базы данных всем остальным контроллерам, которые обновляют свои копии согласно присланному списку. Эти действия определяются как другая примитивная акция 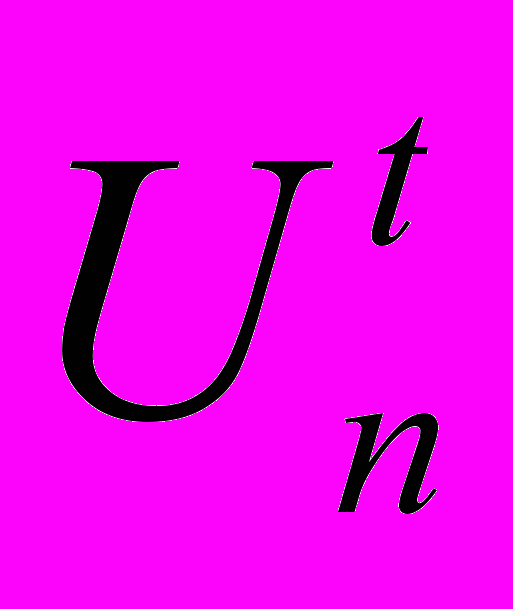 . Примитивы и неделимы, в то время как комбинация L и U транзакции t не нуждаются в неделимости. В SDD 1 возможна такая последовательность примитивов L и U при условии, что история выполнения трёх транзакций t1,t2 и t3 сохраняется
. Примитивы и неделимы, в то время как комбинация L и U транзакции t не нуждаются в неделимости. В SDD 1 возможна такая последовательность примитивов L и U при условии, что история выполнения трёх транзакций t1,t2 и t3 сохраняется 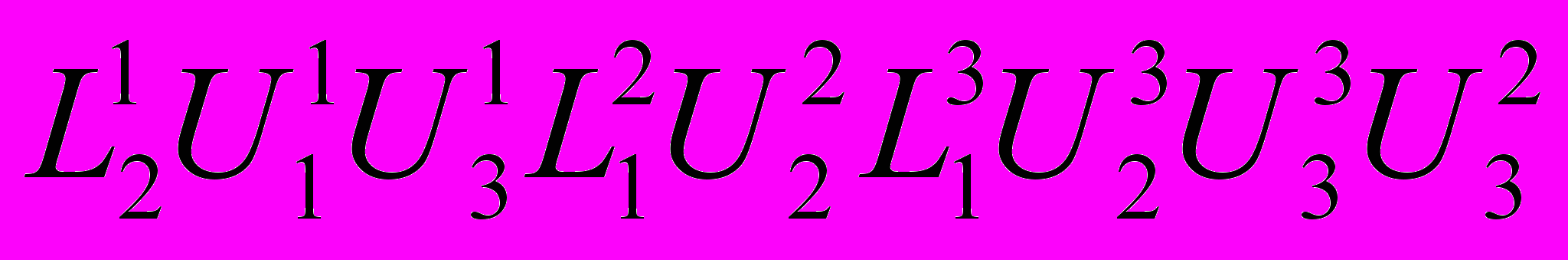 .Для определения возможного взаимовлияния транзакций из разных классов, вызванного перекрытием наборов записи и чтения, предлагается конструкция, названная L U графом. Этот граф соединяет пары узлов, отмеченных как L и U для каждого класса .Дуги между
.Для определения возможного взаимовлияния транзакций из разных классов, вызванного перекрытием наборов записи и чтения, предлагается конструкция, названная L U графом. Этот граф соединяет пары узлов, отмеченных как L и U для каждого класса .Дуги между 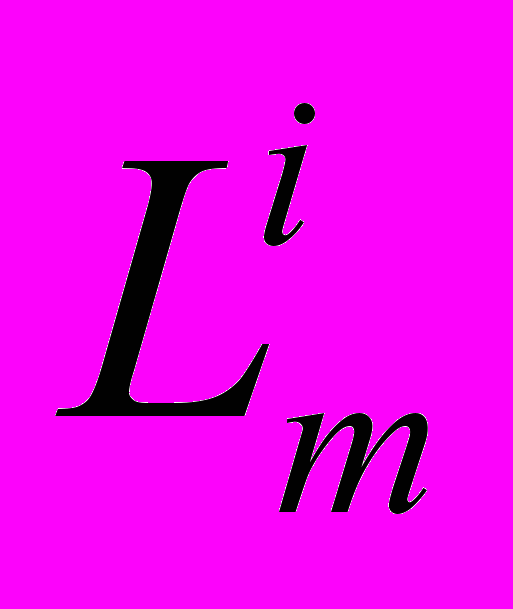 и остальными узлами находятся в соответствии со следующими типами взаимовлияния транзакций:
и остальными узлами находятся в соответствии со следующими типами взаимовлияния транзакций:1.Дуга к узлу U, принадлежащему к тому же классу.
2.Дуга к узлу
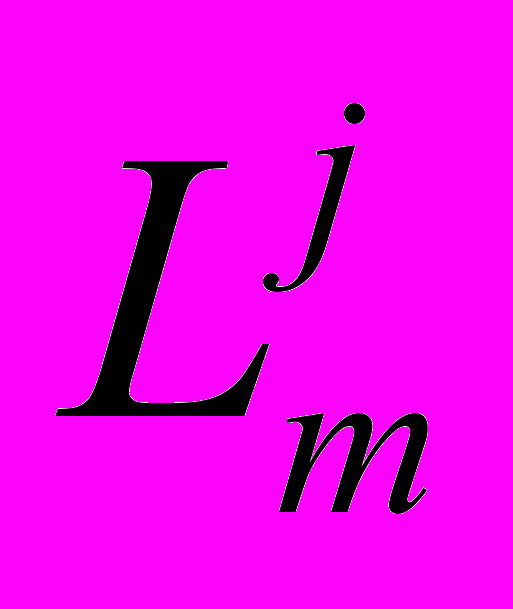 другого класса на той же хост ЭВМ m возникает при выполнении условий
другого класса на той же хост ЭВМ m возникает при выполнении условий 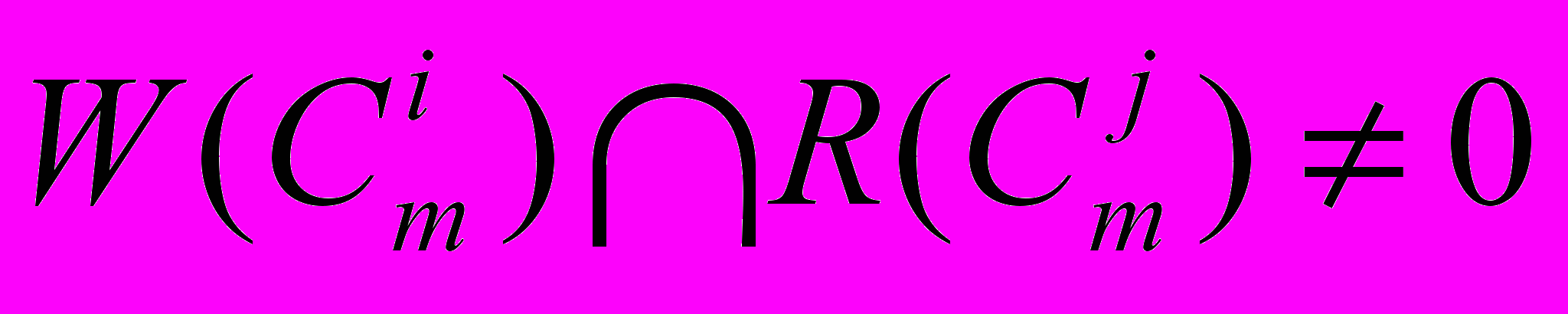 ,
, 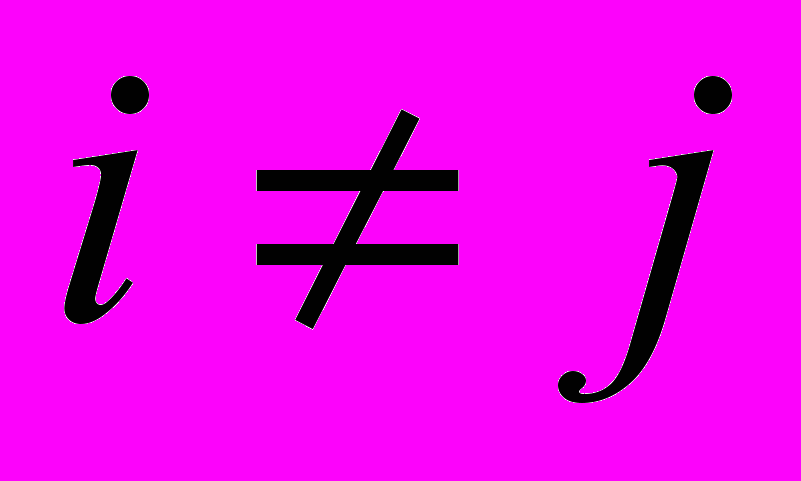 или
или 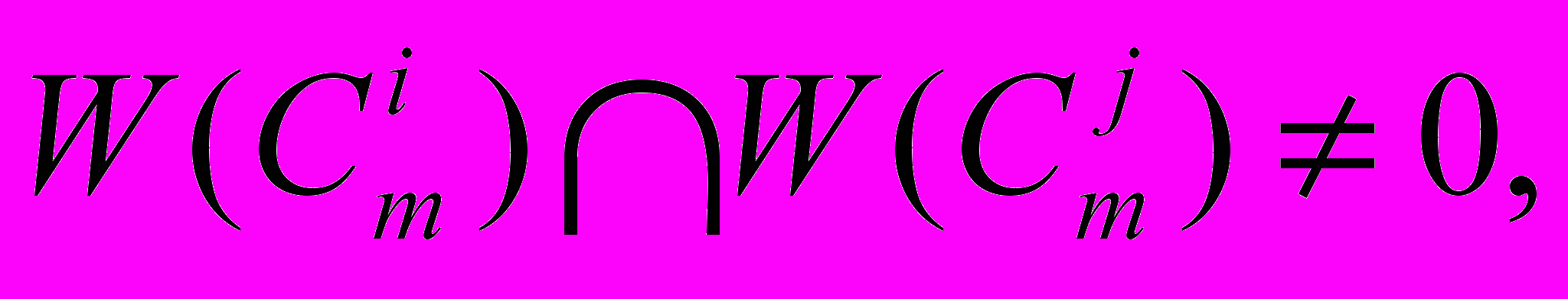 (горизонтальная дуга).
(горизонтальная дуга).3.Дуга к узлу
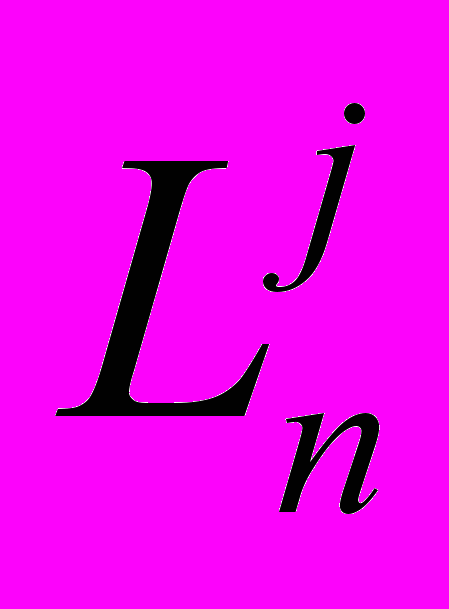 того же класса, расположенному на другой хост ЭВМ возникает, если
того же класса, расположенному на другой хост ЭВМ возникает, если 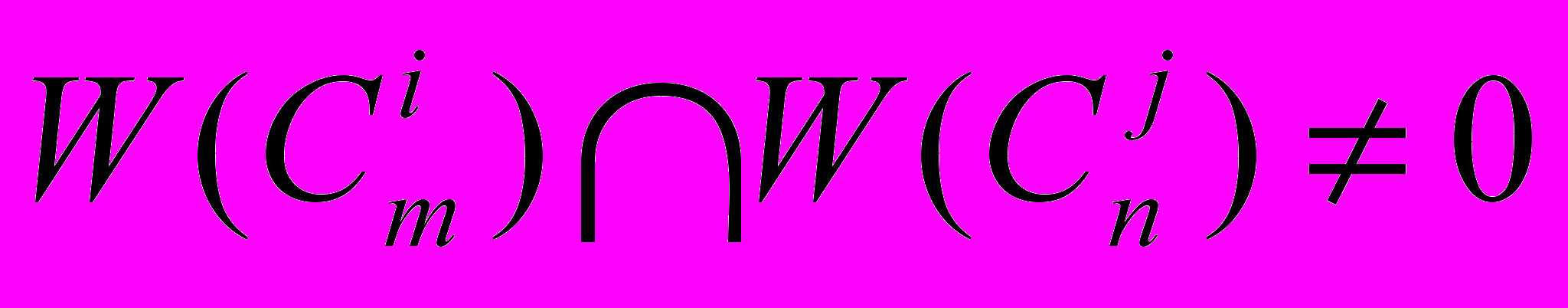 ,
,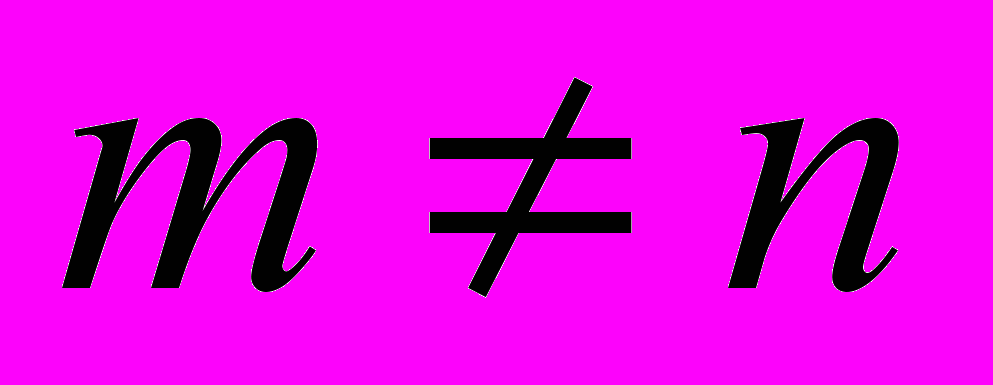 (горизонтальная дуга).
(горизонтальная дуга).4. Дуга к узлу U другого класса, расположенному на другой хост ЭВМ возникает, если
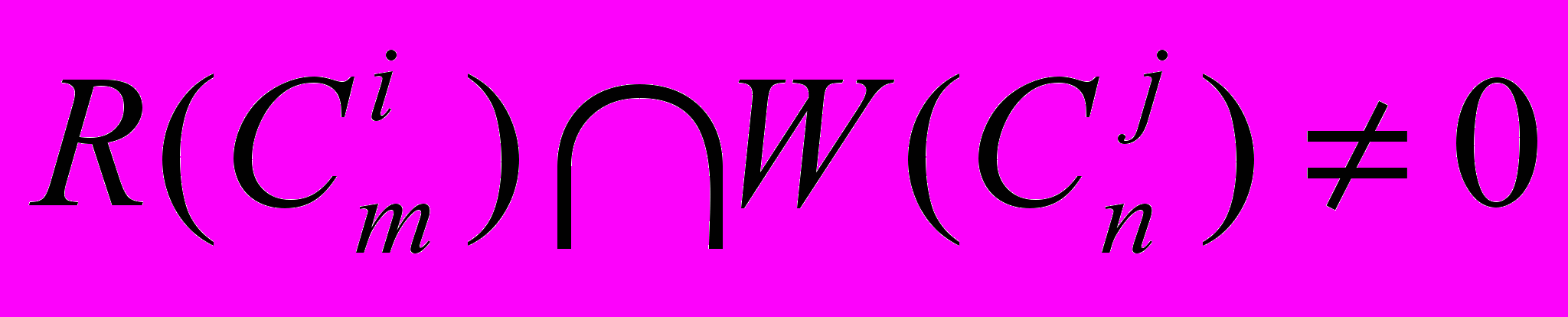 , .
, .5. Дуги между узлом U и другими узлами возникают по следующему правилу: к
, если 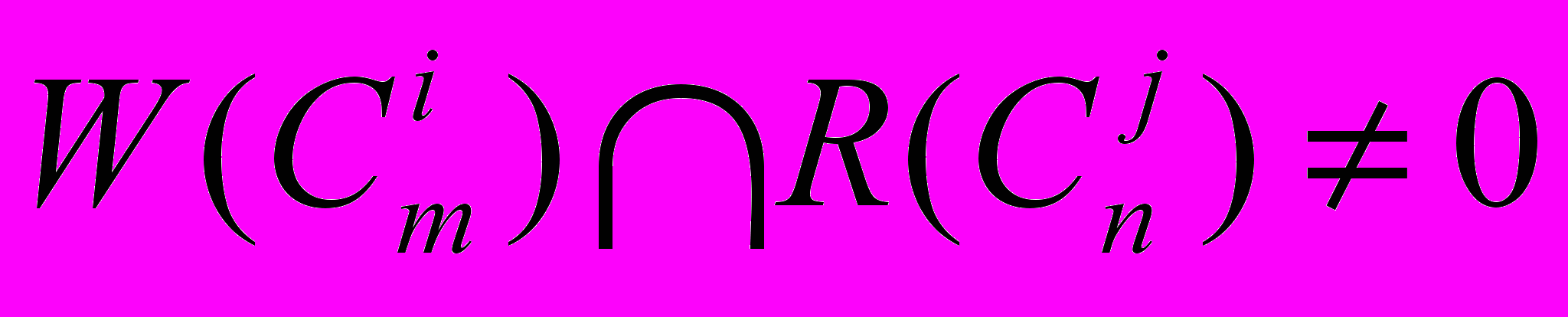 и (диагональная дуга). На рис. 1.3. показан L U граф для транзакций классов
и (диагональная дуга). На рис. 1.3. показан L U граф для транзакций классов 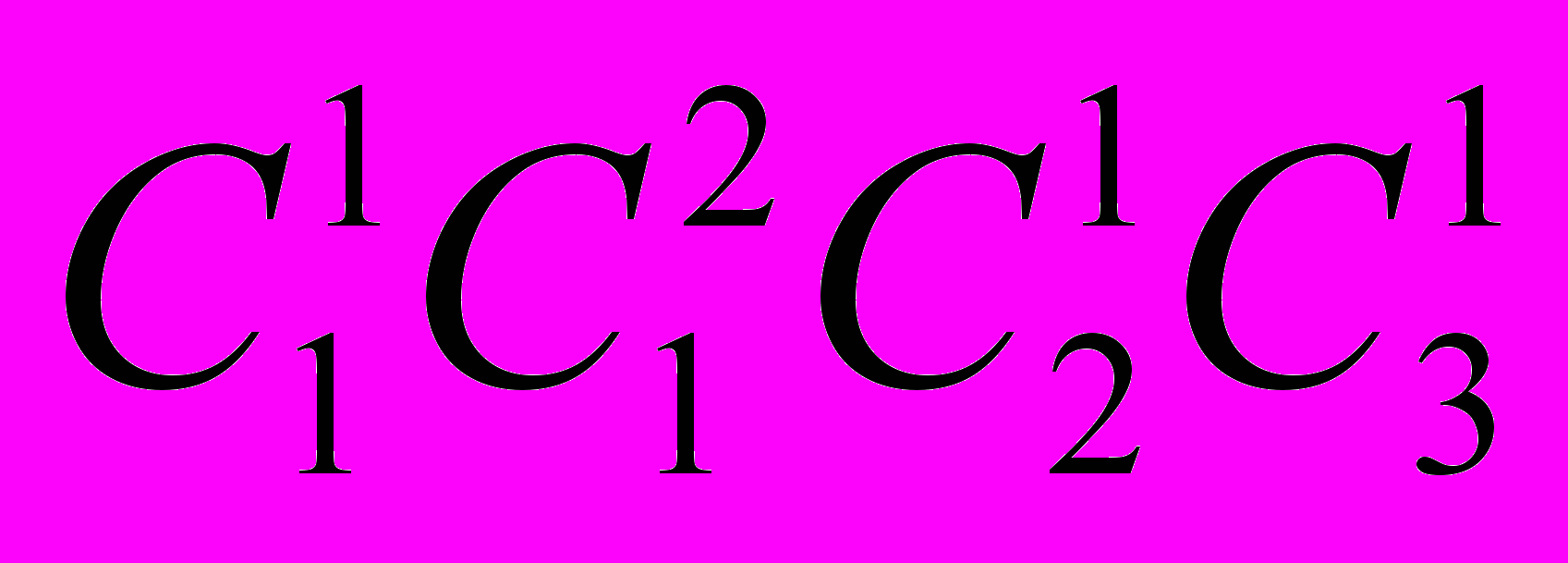 при условиях
при условиях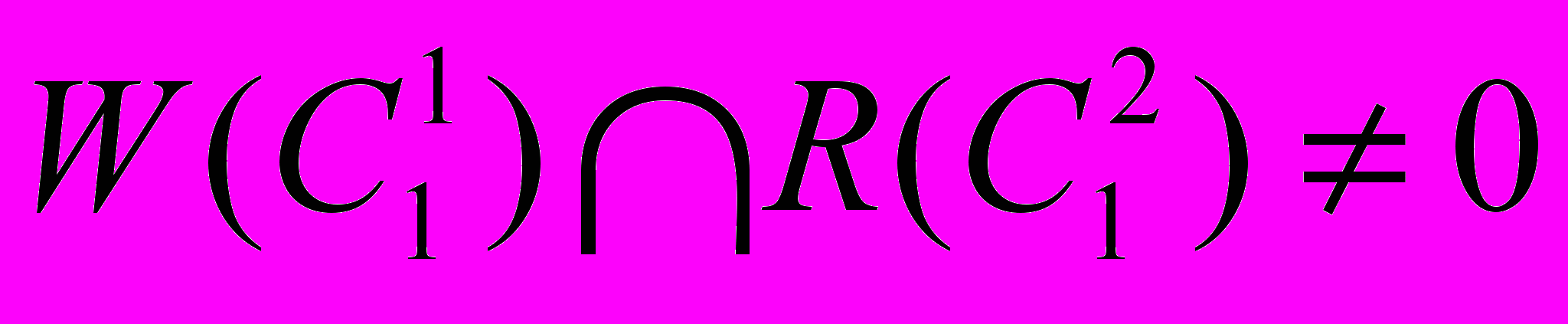 ,
, 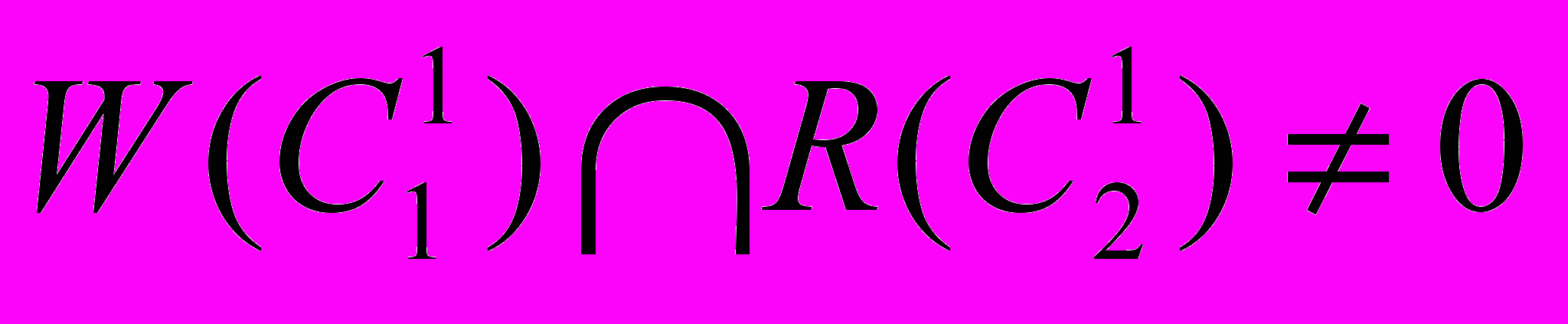
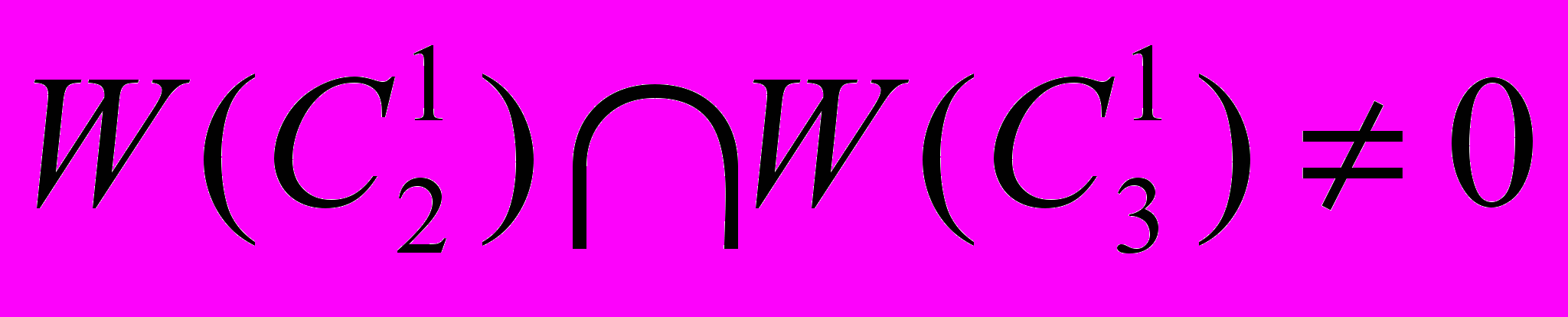 ,
, 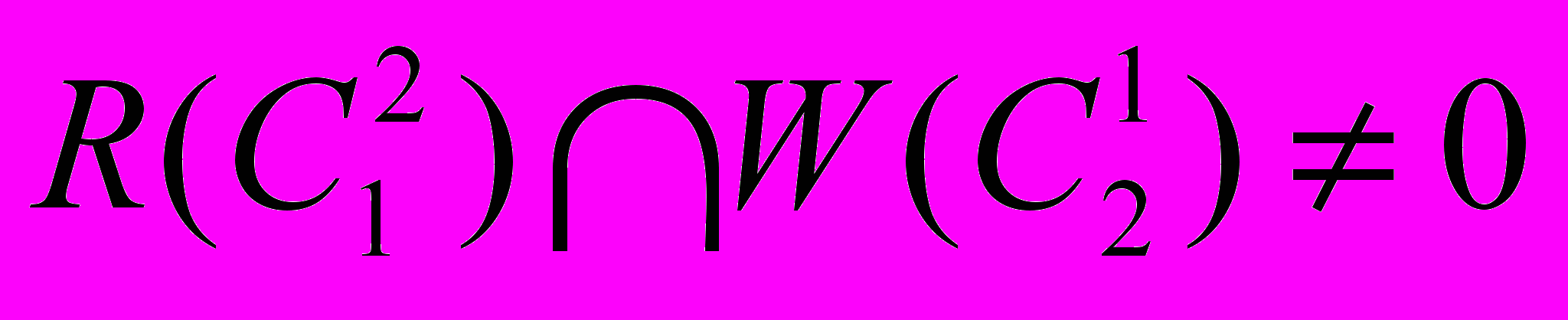
Как только граф L U для данной системы построен, определяется таблица для выбора одного из четырёх протоколов Р1 Р4 для каждого класса транзакций в соответствии с топологией L U по следующим правилам.
- Если некоторого класса не находится в цикле, или если находится в цикле и при этом типы взаимовлияния транзакций соответствуют (2,2),(3,3),(2,3),(2,5),(3,5), то выбирается протокол P1, который просто обеспечивает неделимость примитива
 посредством блокировок наборов записи и чтения транзакции
посредством блокировок наборов записи и чтения транзакции  .
.
- Если находится в цикле и тип взаимодействия соответствует комбинации (4,4), то для выполнения каждой транзакции выбирается протокол Р2.
- Если находится в цикле и тип взаимодействия транзакций соответствует комбинациям (2,4,),(3,4),(4,5), то выбирается протокол Р3.
Протоколы Р2 и Р3 идентичны, за исключением правил присваивания временного штампа голосовательным сообщениям, которые широковещательно адресуются всем контроллерам. Протокол Р2 выбирает наиболее новый временной штамп из
, в то время как Р3 выбирает временной штамп с текущим временем. На рис. 1.4. показана работа протоколов Р2 и Р3. Предположим, что две транзакции ta и tc конкурируют, причём транзакция tc имеет более новый временной штамп. Тогда контроллеры А,В и С взаимодействуют следующим образом при голосовании:- Если к А приходит голос за tc , он помещается в очередь.
- Если контроллер В свободен, то к приходу голоса он устанавливает свои локальные часы: TIME (B)=max (локальное время, время из штампа) и посылает сообщение о принятии голоса источнику запроса. При этом временной штамп сообщения содержит значение локальных часов контроллера В. Если В занят выполнением транзакции с меньшим временным штампом, чем принятый, то В во первых завершает текущую транзакцию, а затем посылает все и принимает новые запросы.
- Контроллер А ждёт до тех пор, пока не получит от всех контроллеров голоса за ta или сообщение с большим временным штампом, чем TS(A).
- Когда А получит все необходимые голоса за ta, примитив
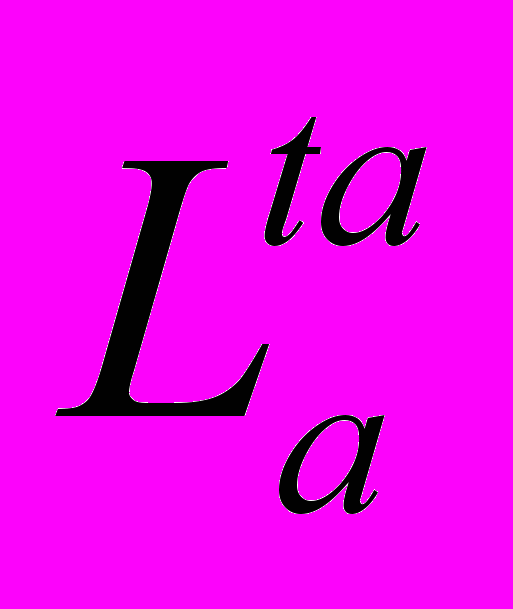 выполняется согласно протоколу Р1.
выполняется согласно протоколу Р1.
- Далее А возобновляет обработку текущих U сообщений и запросов на принятие транзакций.
Для выполнения транзакций, не отнесённых заранее к какому либо классу, применяется протокол Р4.Этот протокол аналогичен Р2 иР3 за исключением того, что временной штамп запроса на голосование относится к некоторому времени в будущем. Этот временной штамп должен быть достаточно большим для обеспечения того, сто не найдётся ни одного контроллера, выполняющего транзакцию с более поздним временным штампом. В противном случае голос отклоняется и затем посылается снова с большим временным штампом.
Разновидностью рассмотренного механизма является механизм голосования по большинству голосов[52,81], в которых для принятия решения не требуется сбора всех голосов за некоторую транзакцию, а достаточно сбора большинства голосов.
Алгоритмы с использованием предварительной блокировки основаны на занятии всех требуемых ресурсов перед выполнением транзакции. В этих алгоритмах используется идей синхронизации путём взаимного исключения[24].
В алгоритме[77] предложена следующая идея синхронизации:
- Процесс, инициирующий транзакцию, посылает сообщение с запросом на блокировку всем мониторам копий базы данных.
- Мониторы отвечают процессу сообщением «блокировка успешна» или «блокировка не выполнена».
- Если все мониторы ответили «блокировка успешна», то переход к п.6.
- Если хотя бы один монитор ответил «блокировка не выполнена», то процесс посылает сообщение с запросом о временном освобождении запрошенного ресурса всем мониторам. Приняв такое сообщение, все мониторы ставят ранее принятый запрос на блокировку в очередь отложенных запросов.
- После истечения некоторого времени инициирующий процесс посылает всем мониторам подтверждение запроса на блокировку. Переход к п. 2.
- Все мониторы начинают выполнение транзакции.
В работе[77] показано, что тупики в рассмотренном алгоритме не возникают. В другой работе этого же автора предложен двухфазный протокол блокировки[78], который определяет следующее правило: к тому времени, как некоторая транзакция освободит все заблокированные ей для чтения данные, она должна выполнить все блокировки, необходимые ей для записи.
Следующее решение состоит в построении отношений ведущий ведомый между мониторами копий[37]. Предположим, что приоритеты мониторов А, В, С находятся в следующем отношении
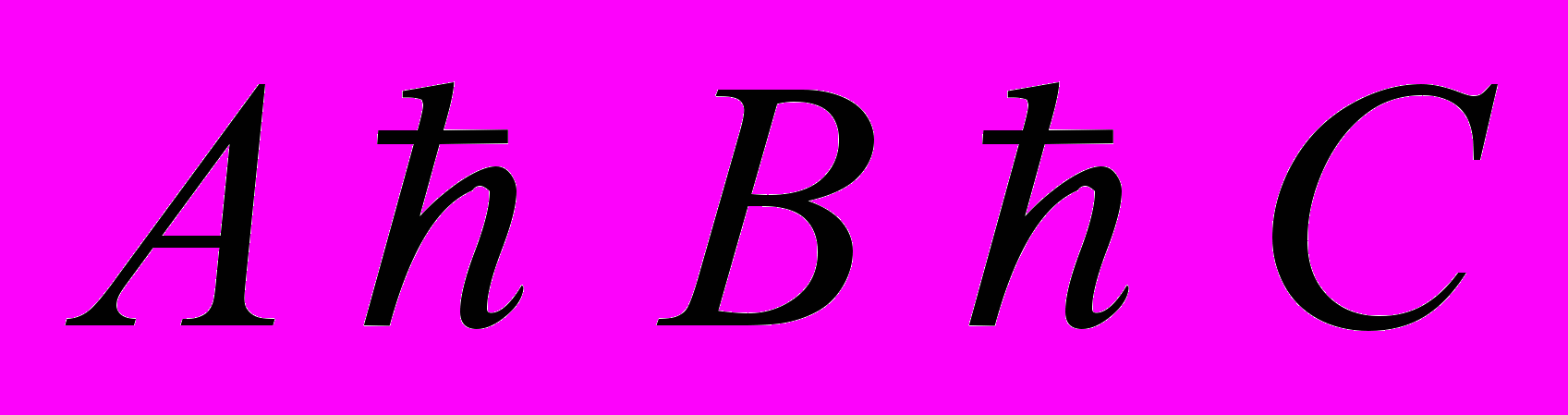 . В этом случае каждая транзакция посылается монитору А, который и занимается разрешением конфликтов между транзакциями. Отметим, что в этом алгоритме после выполнения процедуры построения отношений ведущий ведомый в децентрализованной системе управление копиями базы данных становится централизованным (в рассмотренном случае центром является монитор А). Вопросы построения отношений ведущий ведомый исследованы в работе[22].
. В этом случае каждая транзакция посылается монитору А, который и занимается разрешением конфликтов между транзакциями. Отметим, что в этом алгоритме после выполнения процедуры построения отношений ведущий ведомый в децентрализованной системе управление копиями базы данных становится централизованным (в рассмотренном случае центром является монитор А). Вопросы построения отношений ведущий ведомый исследованы в работе[22].Алгоритмы с использованием циркулирующей привилегии основаны га концепции виртуального кольца процессов[44]. В алгоритмах этой группы право на использование любого ресурса (локального или распределённого) передаётся по очереди между процессами, образующими логическое кольцо. Передача права в распределённой системе выполняется путём посылки сообщения соседнему по кольцу процессу[57,58].
Рассмотрим основные особенности приведённых выше трёх групп алгоритмов разделения ресурсов. Как видно, алгоритмы с использованием голосования являются достаточно гибкими, позволяя строить системы для достаточно широкого круга применений; эти алгоритмы полностью децентрализованы. Однако все они используют широковещательные сообщения. Алгоритмы с использованием предварительной блокировки также требуют обмена широковещательными сообщениями в децентрализованном случае; в противном случае, управление сводится к централизованным алгоритмам. Наконец, использование циркулирующей привилегии не позволяет учитывать динамические приоритеты конкурирующих процессов, что очень важно для систем управления. На основании сказанного можно сделать следующий важный вывод: в системах с распределённым управлением полной децентрализации алгоритмов в сочетании с требуемой гибкостью можно достичь только путём использования широковещательной адресации.
Рассмотрим основные проблемы, возникающие при организации доставки широковещательных сообщений в распределённых системах.
1.5. Алгоритмы доставки широковещательных сообщений.
Алгоритмы распределённого управления ресурсами, рассмотренные в параграфе 1.4, выдвигают определённые требования к организации доставки широковещательных сообщений. Формально эти требования изложены в работах[42,47,50,56,59,79,80]; их суть вкратце сводится к следующему.
- События, порождающие широковещательные сообщения, могут возникать в системе параллельно на многих абонентах.
- Единственным сигналом, информирующим произвольного абонента о наступлении некоторого события в распределённой системе, является приём этим абонентом сообщения с кодом данного события.
- Все сообщения – как индивидуальные, так и широковещательные, принимаются абонентами последовательно
- Порядок наступления событий в системе определяется не физическим временем их возникновения, а порядком приёма абонентами сообщений с кодами этих событий.
- Порядок приёма широковещательных сообщений у всех абонентов должен быть одинаков.
Для локальных сетей с общим каналом связи и аппаратурной поддержкой широковещательной адресации нарушение порядка приёма широковещательных сообщений в основном может происходить из за искажений информации в процессе передачи. При этом часть приёмников может принять сообщение правильно, остальные – неправильно. Поскольку пришедшая искажённая информация не считается принятой, приёмники, принявшие искажённое сообщение, будут ждать его повтора. Если в этот момент придёт широковещательное сообщение от другого источника, которое будет принято всеми абонентами правильно, порядок широковещательных сообщений будет разным у разных абонентов.
Основная идея алгоритмов доставки широковещательных сообщений состоит в присвоении каждому такому сообщению уникального идентификатора, отражающего порядок появления данного сообщения в системе. При этом на приёмном конце по идентификаторам нетрудно разобраться в том, в каком порядке сообщения были посланы. Таким образом, основным объектом исследований в существующих работах по доставке широковещательных сообщений является вопрос генерирования уникальных идентификаторов. Рассмотрим основные алгоритмы доставки таких сообщений.
Использование центральных физических часов. В этом алгоритме все сообщения получают уникальный временной штамп[56] от центральных физических часов. Алгоритм предельно прост, однако существует опасность, что в случае больших задержек при передаче процесс, восстанавливающий порядок посылки сообщений (выполняющийся у абонентов приёмников), будет работать с ошибками. Для ликвидации этой опасности предлагается априорное знание максимальных задержек при передаче, либо их оценка на конкретной работающей системе[43].
Разновидностью центральных физических часов является использование центрального процесса[51,75]. Хотя центральный процесс является более интеллектуальным средством по сравнению с физическими часами, и позволяет решать дополнительные задачи помимо простановки идентификаторов, он является менее надёжным в силу сложности оборудования (по сравнению с физическими часами).
Использование счётчиков событий. Счётчики событий описаны в работе[64]. Они представляют собой переменные, которые содержат число событий отдельного класса, обнаруженных в системе к настоящему моменту времени. Определим три примитива на счётчике событий:
- Продвинуть (Е) – увеличить значение счётчика Е на 1.
- Читать (Е) – вернуть текущую величину счётчика Е запрашиваемому процессу.
- Ждать (Е, К) – Блокировать запрашивающий процесс до тех пор, пока величина Е не достигнет К.
Для реализации алгоритма не требуется взаимного исключения на более низких уровнях. Например, в распределённой системе счётчик событий может быть построен из нескольких простых счётчиков – по одному на каждый конкурирующий процесс. При этом операция «читать» будет выполняться локально, операция «продвинуть» будет продвигать произвольный локальный счётчик.
Статические секвенсоры. Статический секвенсор есть неубывающая целочисленная переменная[64], на которой определён только один примитив.
Отметить (С) – вернуть текущую величину С и увеличить С на единицу.
Секвенсоры требуют применения взаимного исключения для обеспечения неделимости примитива «отметить», поэтому механизм не допускает одновременного выполнения двух примитивов, поступивших от разных процессов. Временные характеристики механизма определяются реализацией взаимного исключения.
Рассмотренные способы идентификации широковещательных сообщений относятся к централизованной группе и обладают всеми достоинствами и недостатками централизованных способов управления. Рассмотрим алгоритмы децентрализованной группы.
Множественные физические часы. При таком подходе каждый абонент имеет собственные часы, откуда и берётся значение текущего времени для идентификации сообщений. Сложность состоит в том, что в РВС недостаточно запустить все часы в одно и то же время – необходимо, чтобы расхождение их показаний в процессе функционирования не превышало некоторую заранее заданную величину. В работе[55] предложено следующее решение проблемы. Система представляется как сильносвязанный граф процессов с диаметром d.Каждому из процессов с интервалом t посылается синхронизирующее сообщение, содержащее текущее значение времени Т. После приёма синхросообщения процесс продвигает свои локальные часы так, чтобы они показывали время позднее, чем Т. Предполагается, что известна нижняя граница u и верхняя граница u+z величины задержек при передаче сообщений в системе. Обозначая k – необходимая точность локальных часов, с расхождение показаний двух локальных часов, при условии
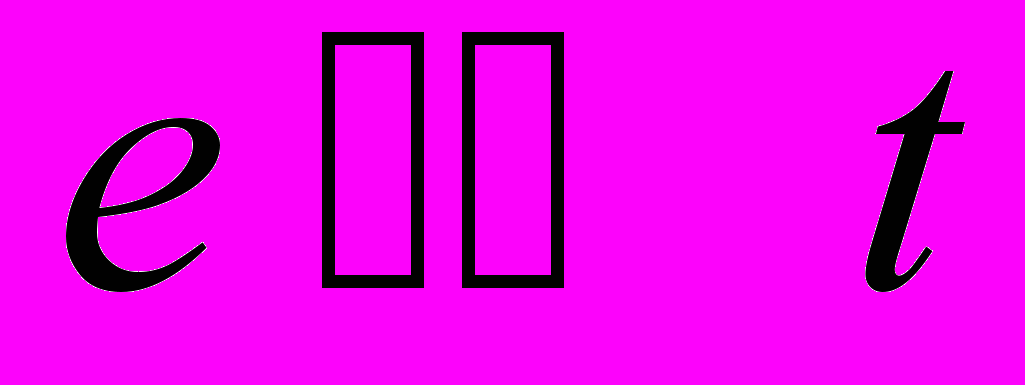 и
и 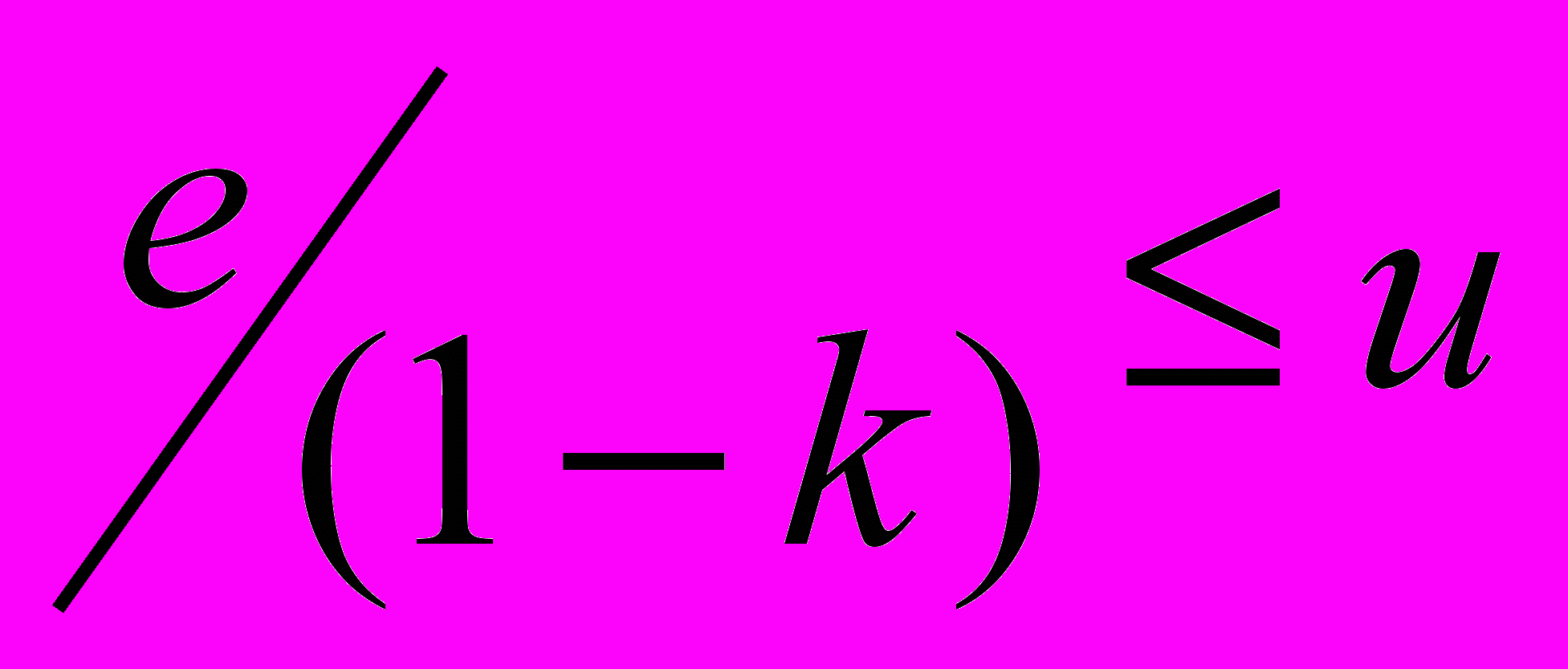 получим
получим 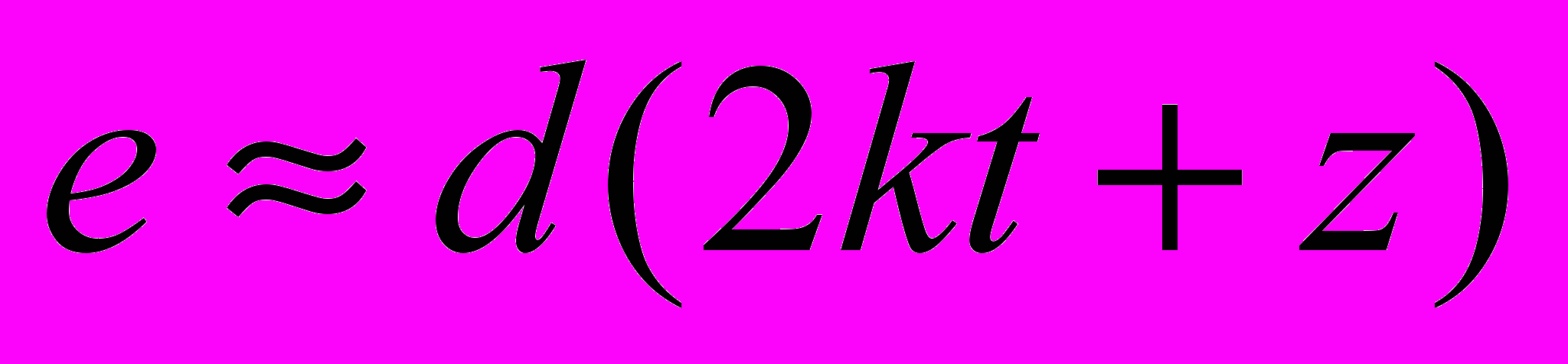 .
.Множественные логические часы. Механизм, предложенный в работе[56], может быть рассмотрен как некоторая функция F, которая присваивает значение произвольной, локально инициируемой акции. Множественные логические часы могут быть реализованы в виде множества счётчиков событий. Основная проблема в системе с логическими часами состоит в выборе некоторых условий, удовлетворение которых позволит восстановить исходный порядок событий в распределённой системе. Например, условия могут быть сформулированы таким образом: для некоторого события a в процессе I и b в процессе j, если
 , то
, то 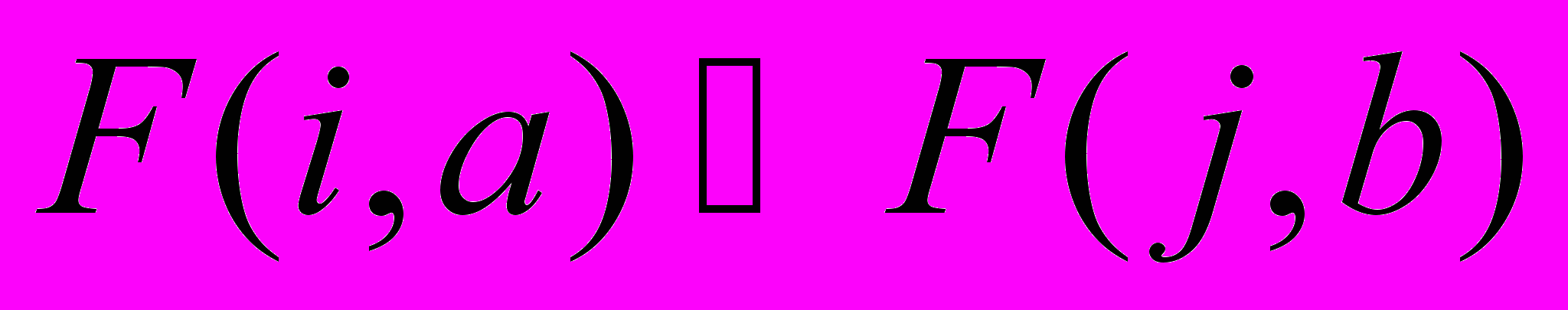 . Символ
. Символ означает, а предшествует в во времени. Для удовлетворения этих условий предлагаются следующие правила.
означает, а предшествует в во времени. Для удовлетворения этих условий предлагаются следующие правила.- Каждый конкурирующий процесс увеличивает
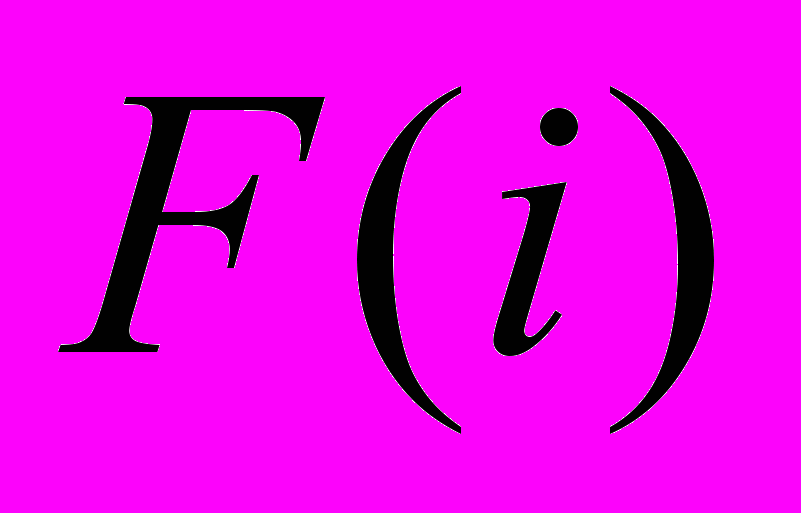 между некоторыми двумя успешно завершёнными акциями.
между некоторыми двумя успешно завершёнными акциями.
- Если акция а есть посылка сообщения т процессом I, то т содержит временной штамп
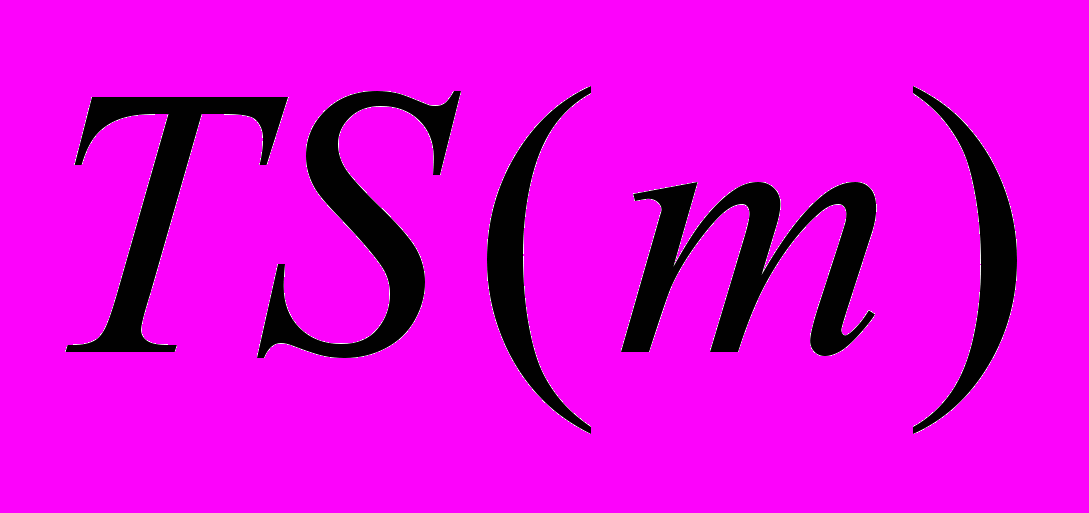 =
=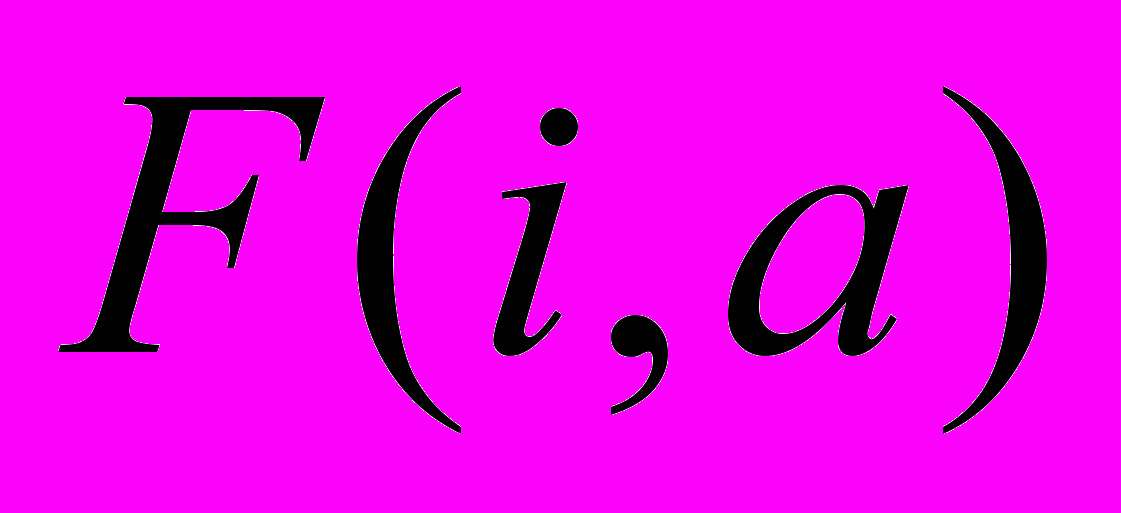 . После приёма сообщения т процесс j устанавливает F(j) и одновременно больше, чем значение временного штампа TS(m).
. После приёма сообщения т процесс j устанавливает F(j) и одновременно больше, чем значение временного штампа TS(m).
Использование правил 1 и 2 позволяет построить алгоритм синхронизации, обеспечивающий последовательную идентификацию сообщений в условиях возможного параллелизма в их поступлении.
Выводы и постановка основных задач.
На основании анализа литературы, проведённого в настоящей главе, можно сделать следующие выводы.
- В системах с распределённым управлением чрезвычайную важность имеет посылка широковещательных сообщений.
- Методы обеспечения правильной доставки широковещательных сообщений обладают большими накладными расходами, что происходит в силу следующих причин. Первое: поскольку в существующих сетях нет средств «групповых» ответов от всех абонентов (т.е. ответа всех абонентов в одном сообщении), приходится применять индивидуальный сбор квитанций от каждого абонента. Это справедливо и для локальных сетей с общим каналом связи, в которых имеется возможность широковещательной адресации. Таким образом, невозможно
выполнить передачу широковещательного сообщения за время, лучшее, чем
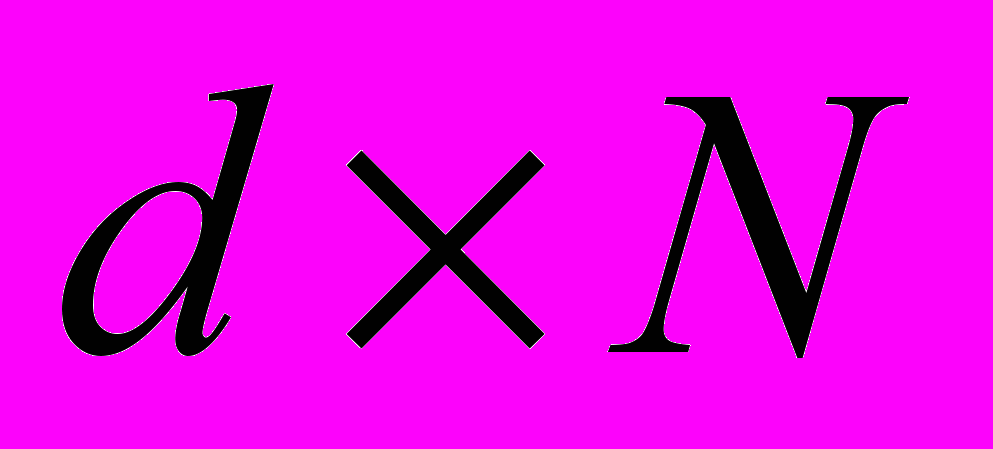 , где d – среднее время доставки произвольного сообщения в сети, N – число абонентов. Величина d зависит от способа обмена информацией и составляет около 20 мс при методе обмена сообщениями, и порядка сотен микросекунд при методах удалённого вызова[17,18,76]. Второе: применение методов уникальной идентификации широковещательных сообщений вносит дополнительные накладные расходы на идентификацию с одной стороны, и на последующее восстановление порядка посылки таких сообщений с другой стороны. Таким образом, полное время доставки широковещательного сообщения составляет
, где d – среднее время доставки произвольного сообщения в сети, N – число абонентов. Величина d зависит от способа обмена информацией и составляет около 20 мс при методе обмена сообщениями, и порядка сотен микросекунд при методах удалённого вызова[17,18,76]. Второе: применение методов уникальной идентификации широковещательных сообщений вносит дополнительные накладные расходы на идентификацию с одной стороны, и на последующее восстановление порядка посылки таких сообщений с другой стороны. Таким образом, полное время доставки широковещательного сообщения составляет 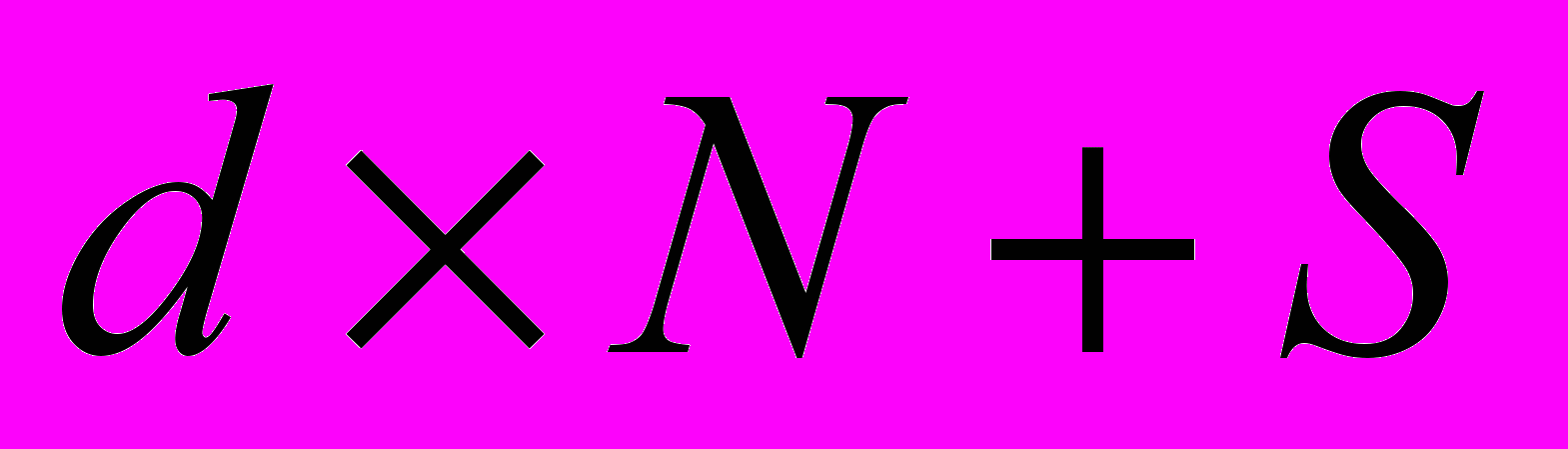 , где S – суммарное время идентификации и восстановления порядка посылки.
, где S – суммарное время идентификации и восстановления порядка посылки.4. Большое время доставки широковещательных сообщений и его зависимость от числа абонентов сети не позволяет использовать ресурсы с большой степенью распределённости. Например, привлекательная идея распределённой общей памяти, используемая в мультимикропроцессорных системах[36], нереализуема в распределённых системах на базе локальных сетей с использованием известных автору алгоритмов доставки широковещательных сообщений. Время доступа к такой памяти было бы неприемлемо велико. Поэтому идеи распределённого управления в настоящее время используются только в распределённых базах данных с многими копиями, где время реакции определяется только человеческим фактором и может быть достаточно велико (порядка единиц секунд). Использование идей распределённого управления в РМУВС исследовано недостаточно полно.
Таким образом, можно поставить следующие задачи, подлежащие исследованию в диссертации.
- Необходимо попытаться решить задачу правильной доставки широковещательных сообщений, используя при этом те особенности, которые отличают локальные сети с ДПУ и ВОК. Время доставки таких сообщений должно быть по возможности минимизировано.
- Необходимо провести исследования перспектив применения в РМУВС идей распределённой общей памяти. При этом необходимо учитывать возможности разработанных алгоритмов доставки широковещательных сообщений для сетей с ДПУ и ВОК.
- Необходимо показать, каким образом использование особенностей сетей с ДПУ и ВОК будет влиять на повышение эффективности алгоритмов управления ресурсами как с точки зрения логической организации взаимодействия процессов распределённой оперативной системы, так и с точки зрения улучшения временных характеристик алгоритмов.
- Необходимо провести экспериментальную проверку принятых решений для оценки их эффективности и логической правильности.
- Необходимо выработать рекомендации по построению РМУВС на базе сетей с ДПУ и ВОК, рассчитанных на ответственные применения в условиях жёстких временных ограничений.