
Распределенные информационные системы
| Вид материала | Документы |
СодержаниеГлава 2. организация вычислительных процессов в распределённой системе управления. Обеспечение управления ядром надёжности хранения информации на магнитных дисках. |
- Направление 230400 «Информационные системы и технологии», 20.25kb.
- Программа дисциплины «информационные сети» Индекс дисциплины по учебному плану: опд., 123.28kb.
- Многоуровневая учебная программа дисциплины электротехника и электроника для подготовки, 409.29kb.
- Программа дисциплины «вычислительная математика» Индекс дисциплины по учебному плану:, 550.42kb.
- Реферат по курсу «Микропроцессорные системы» на тему «Распределенные вычислительные, 377.31kb.
- Программа государственного экзамена по специальности: 230201. 65 «Информационные системы, 450.31kb.
- В. П. Информационные системы в технике и технологиях. Ч. Диплом, 1332.77kb.
- Информационные технологии управления лекция 6 Информационные системы планирования (бюджетирования), 41.66kb.
- Конспект лекций по дисциплине «Информационные системы в экономике», 1286.5kb.
- Рабочая программа по дисциплине "алгоритмизация и программирование" для специальности, 136.78kb.
3.1. Концептуальная модель вычислительной системы с распределённым управлением.
Алгоритмы, предложенные в параграфах 2.1 – 2.4, являются оригинальными и ранее в распределённых вычислительных системах любого целевого назначения не использовались. Встаёт естественный вопрос о местоположении предложенных алгоритмов на уровнях иерархии архитектур связи в распределённых системах, известных в настоящее время. Поскольку в РМУВС используются локальные сети, возьмём за основу архитектуру локальных вычислительных сетей стандарта IEEE 802.
Рассмотрим модель IEEE 802 (рис 3.1). Эта модель определяет три уровня: физический уровень, уровень управления доступом к каналу (УДК) и уровень управления логической связью (УЛС). Особенность иерархического построения архитектуры заключается в том, что каждый N й уровень использует сервис N 1 –го уровня, расположенного непосредственно под ним; сервис ещё более низких уровней для уровня N непосредственно недоступен[1,5].
Попытаемся разместить наши алгоритмы на высоких уровнях, т.е. выше уровня УЛС, с учётом того, что задачи каждого уровня в архитектуре строго определены. Сразу видно, что алгоритмы параграфов 2.1 – 2.3 невозможно разместить на этих уровнях, так как механизмы гарантированной доставки широковещательных сообщений (МГД) для систем с ДПУ использует непосредственно уровень управления доступом при решении задачи; механизмы для ВОК систем помимо этого используют ещё и непосредственный доступ к каналу связи при выполнении групповых операций. Таким образом, на высоких уровнях остаётся только механизм взаимного распределённого программирования, который можно реализовать с использованием транспортного сервиса, предоставленного распределённой системой управления. Проанализируем остальные модели IEEE 802 в плане размещения на них механизмов параграфов 2.1 – 2.3. Начнём с самого нижнего уровня модели, физического.
В задачу этого уровня входит кодирование и передача информации от источника к приёмнику после получения разрешения на передачу, а также предоставление сервиса уровню УДК при разрешении им конфликтов. Физический уровень лишён всякого нижерасположенного сервиса. Размещение механизмов параграфов 2.1 – 2.3 (назовём их базовыми механизмами) на этом уровне приведёт к тому, что им придётся решать самостоятельно как все задачи физического уровня, так и задачу управления доступом к каналу. Так как базовые механизмы на это не рассчитаны, то их нельзя разместить на этом уровне. Перейдём к уровню управления доступом к каналу.
Основная задача этого уровня заключается в разрешении конфликтов при множественном доступе абонентов к общему каналу связи[25]. При разрешении конфликтов уровень УДК использует сервис физического уровня. Размещение базовых механизмов на этом уровне привело бы к тому, что им самостоятельно пришлось бы решать задачу управления доступом, на решение которой они не рассчитаны. Поэтому базовые механизмы нельзя размещать и на этом уровне. Рассмотрим уровень управления логической связью.
Уровень УЛС использует для своих целей при разрешении конфликтов сервис уровня УДК, а после разрешения конфликта – сервис физического уровня. Отметим, что в архитектуре IEEE 802 это единственный уровень, которому разрешается непосредственное использование сервиса «через уровень», расположенный под ним. Таким образом, на уровне УЛС имеется как сервис управления доступом, так и сервис физического уровня, что достаточно для реализации базовых механизмов при размещении их на этом уровне. Однако в архитектуре IEEE 802 задачи этого уровня чётко определены: это задача безошибочной доставки пакетов и задача управления потоком[19]. Поскольку помещение базовых механизмов на этот уровень значительно расширяет его функции, то существует 3 варианта реализации процедур уровня УЛС.
- Расширение функций существующих протоколов с целью реализации в них базовых механизмов.
- Возложение на базовые механизации задач уровня УЛС.
- Вертикальное разделение уровня УЛС с целью проведения границы между функциями уровня, определёнными архитектурой IEEE 802, и задачами базовых механизмов распределённого управления.
Первый вариант можно сразу не рассматривать, поскольку такое решение повлекло бы за собой пересмотр международных стандартов, существующих для этого уровня. Второй вариант невозможен, так как базовые механизмы не решают задач уровня УЛС. Остаётся третий, компромиссный вариант.
Предлагается модель, названная моделью распределённого управления в вычислительных системах (РУВС), в которой по сравнению с моделью IEEE 802 дополнительно вводится уровень распределённого управления, расположенный непосредственно над уровнем управления доступом к каналу и существующий параллельно и независимо от уровня УЛС (рис 3.2). Все базовые механизмы распределённого управления будут располагаться на этом уровне. С точки зрения реализации процедур это означает, что на уровне УЛС модели IEEE 802 существуют два параллельных независимых процесса: один из них обеспечивает реализацию протокола уровня УЛС, другой занимается решением базовых задач распределённого управления. Проблема синхронизации этих процессов решается локально и не вызывает трудностей.
3.2. Основные задачи управляющего ядра распределённой системы реального времени.
Мы вводим термин «управляющее ядро» для исследуемых систем по следующим соображениям. Во-первых, результаты главы 2 свидетельствуют о том, что ряд задач распределённого управления, традиционно решаемых программным обеспечением РВС, можно решать на нижних уровнях РМУВС с большей эффективностью. Во-вторых, механизмы, предложенные в главе 2, не решают полностью всех задач распределённого управления, и оставшиеся задачи необходимо решать программным путём. Таким образом, под управляющим ядром РМУВС мы понимаем программы распределённой операционной системы, использующие сервис рассмотренных механизмов. В дальнейшем в работе термин «распределённая операционная система» (РОС) следует понимать именно в этом смысле. Следует также отметить, что речь идёт о РОС реального времени.
Определим основные требования к распределённой операционной системе реального времени, Предназначенной для управления работой РМУВС[9]. С точки зрения операционной системы, работа в реальном времени означает в первую очередь наличие средств поддержки мультизадачного режима работы, в наличие приоритетной дисциплины управления. В распределённой вычислительной системе это означает, что все сообщения, передаваемые через сеть связи, также должны передаваться согласно их приоритетам. Возникает задача разработки протокола передачи сообщений с динамическими приоритетами и гарантированным временем доставки. В настоящее время подобные протоколы в созданных системах управления отсутствуют. Высокие требования к надёжности РМУВС заставляют отказываться от централизованных методов управления и применять децентрализацию с целью обеспечения требуемой надёжности и живучести системы в целом. Специфика сетевой организации РМУВС предполагает наличие в системе общих ресурсов, доступ к которым (при использовании механизмов распределённого управления) возможен от любой задачи. В каждый момент часть ресурсов используется, часть простаивает. Таким образом, создаётся избыточность ресурсов; избыточность может быть создана и искусственно для наиболее важных ресурсов. РОС должна использовать эту избыточность для повышения надёжности РМУВС при помощи реконфигурации системы при отказах отдельных ресурсов. Реконфигурация означает, что при отказе вышедший из строя ресурс подменяется не заранее определённым, а тем, кто в данный момент способен выполнить его работу. Основным моментом здесь является вопрос реконфигурации межпроцессорных связей, существующих в системе управления, поскольку реконфигурация связей должна быть прозрачной для процессов пользователей и выполняться на системном уровне. Существующая в системе неоднородность должна покрываться протоколами межпроцессорной связи. Далее, в РМУВС может находиться несколько групп вычислительных процессов, решающих различные задачи управления объектом. Влияние этих групп друг на друга должно быть в пределе ликвидировано; для каждой из этих групп остальные группы должны быть прозрачны. При этом возникает задача защиты групп от вмешательства посторонних процессов; в РМУВС подобные ситуации будут, по всей вероятности, возникать в основном из-за ошибок программного обеспечения или неквалифицированных действий операторов. Следует также решить вопрос синхронизации, возникающий при совместном использовании вычислительными процессами ресурсов системы, которые также могут быть распределены. С учётом перечисленных требований, перейдём к вопросам организации управляющего ядра РМУВС.
3.3. распределённая общая память как базовое средство построения управляющего ядра системы.
Как было отмечено в главе 1, при решении задач распределённого управления в децентрализованных распределённых вычислительных системах неизбежно возникают трудности, как раз и связанные с отсутствием центра, имеющего всю информацию о состоянии распределённой системы. Наличие в РМУВС такого центра позволило бы с помощью простых алгоритмов решить такие задачи, как синхронизация распределённых процессов при помощи глобальных флагов событий, адресация распределённых процессов при условии их динамического перемещения по системе, задача разделения распределённых ресурсов в условии параллельно существующих запросов на их использование, словом, практически весь перечень задач управляющего ядра РМУВС, перечисленных в разделе 2,3 настоящей работы. Однако, как уже неоднократно упоминалось, введение центра нежелательно для РМУВС из-за снижения надёжности работы системы. В этом случае, весь выигрыш надёжности, полученный за счёт распределённого управления, превратился бы в ничто из-за надёжности центра.
В принципе, идея распределённой общей памяти, являющейся надёжным распределённым информационным центром, не нова и неоднократно упоминалась в главе 1 в работах, посвящённых организации баз данных со многими копиями. Однако, если базы данных представляют собой хранилища информации, с которыми имеет дело человек, и время ответа в таких системах определяется только психологическими факторами (т.е. достаточно велико), то в случае распределённой общей памяти мы имеем дело с вычислительными машинами и вычислительными процессами с быстрой реакцией. Поэтому прямое перенесение методов решения задачи обновления многих копий, разработанных для распределённых баз данных, в распределённую общую память (которая сама по себе тоже является распределённой базой системных данных), в РМУВС невозможно и в настоящее время такая память не используется. Однако, механизмы гарантированной доставки широковещательных сообщений и механизмы синхронизации, предложенные в главе 2 для исследуемых систем, позволяют решить эффективно задачу обновления многих копий распределённой общей памяти в РМУВС. Рассмотрим, каким образом организована распределённая общая память.
Каждый абонент системы имеет область памяти, предназначенную для хранения и модификации глобальной системной управляющей информации – общесистемных флагов событий, описателей глобальных задач, таблиц состояния распределённых ресурсов и т.д. (рис. 3.3). Эта область одинакова по размеру и идентична по содержимому у всех абонентов; она инициализируется при начальном запуске системы. Будем называть эту систему копией распределённой общей памяти (КРОП); совокупность всех КРОП и образует распределённую общую память (РОП).
Доступ к РОП контролируется набором идентичных программ, также распределённым по всем абонентам, имеющим КРОП. Этот набор программ называется распределённым монитором РОП (РМ-РОП). Находящаяся у отдельного абонента программа из набора РМ-РОП называется локальным монитором РОП (ЛМ-РОП). Каждый ЛМ-РОП контролирует доступ к охраняемой им КРОП, используя для синхронизации с остальными ЛМ-РОП механизм гарантированной доставки широковещательных сообщений (МГД) в системах с ДПУ и ВОК и механизм синхронизации с монополизацией по записи (СМЗ) в ВОК-системах.
Определим основные задачи, решаемые распределённым монитором РОП.
- Управление доступом к РОП при выполнении операции чтения. Решение этой задачи не вызывает трудностей – каждый ЛМ-РОП выполняет операцию чтения локально, считывая информацию из своей собственной КРОП. Все ЛМ-РОП могут читать информацию из РОП параллельно, каждый из своей КРОП, поскольку информация во всех КРОП идентична. Отметим, что операция чтения возможна только тогда, когда РОП не заблокирована каким-нибудь процессом распределённой ОС для выполнения очередной записи или обновления.
- Управление доступом к РОП при выполнении операции записи. Операция записи в РОП имеет ту особенности, что информация, изменённая в результате выполнения этой операции в любой КРОП, должна быть немедленно изменена во всех остальных КРОП; при этом любой доступ к РОП на время операции записи должен быть запрещён, либо ЛМ-РОП должны уметь различать, какая информация в РОП изменяется операцией записи, а какая считывается операцией чтения. В этом случае при обращении разных процессов РОС к разным участкам РОП операции чтения и записи могут выполняться одновременно.
- Управление доступом к РОП при выполнении операции обновления. Операция аналогична записи в РОП, за исключением того, что любой доступ к обновляемой области в РОП должен быть запрещён на время выполнения следующей последовательности действий: чтения информации из РОП, модификации считанной информации и записи результата в РОП. Любой доступ к обновляемой области в РОП во время выполнения этой неделимой последовательности может привести к рассинхронизации вычислительных процессов, использующих общие данные из обновляемой области.
Выполнение операций записи и обновления РОП производится в два этапа. На первом этапе происходит борьба за право получения доступа к РОП, на втором этапе – изменение содержимого РОП широковещательным сообщением с использованием соответствующего механизма гарантированной доставки.
В ВОК-системах алгоритм работы ЛМ-РОП при выполнении операций над распределённой общей памятью очень прост, так как всю работу по синхронизации разделения РОП берёт на себя либо механизм с абсолютной монополизацией, либо механизм с монополизацией по записи. Для РОП вполне достаточно использования более простого механизма с абсолютной монополизацией по той причине, что операция чтения может выполняться абонентами без всякой предварительной синхронизации. Это допустимо потому, что если будет считана какая-либо информация, которая уже заблокирована для обновления, но новое значение ещё не записано, то это будет только означать, что считана самая последняя версия этой информации непосредственно перед моментом записи новой версии. В этом случае рассинхронизация не происходит.
Таким образом, в ВОК-системах задача ЛМ-РОП сводится только к тому, что при получении запроса на обновление он инициирует запрос ALC (см. параграф 2.3.2) и после получения разрешения на занятие РОП для обновления производит необходимые действия, записывая обновлённые доставки с помощью механизма гарантированной доставки широковещательных сообщений для ВОК-систем. Все операции чтения из РОП выполняются параллельно всеми абонентами РМУВС, время выполнения операции обновления с учётом (2.2.4) определяется как
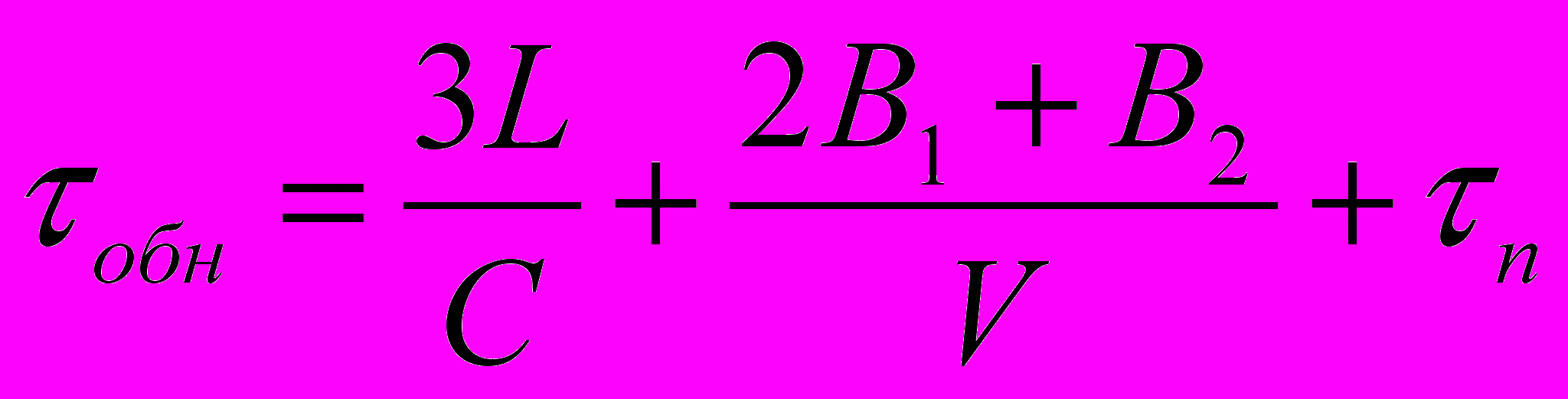 (3.3.1)
(3.3.1)где, как и в (2.2.4), L – общая длина шины ВОК; С – скорость распространения сигнала в линии, м/с; V – скорость передачи информации в линии, бит/с; В1 – длина запроса ALC, бит; В2 – длина области общей памяти плюс длина управляющих полей (см. параграф 2.2) широковещательного сообщения в ВОК-системе, бит;
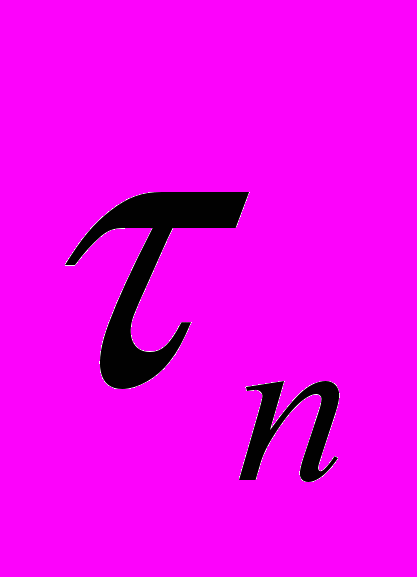 - длительность операции обновления (время процессора), с. При этом накладные расходу на синхронизацию и передачу содержимого РОП по сети при длине линии связи РМУВС, равной 1 км, размере области РОП 1 Кбайт и скорости передачи 10 Мбит/с составят около 1 мс, что вполне приемлемо.
- длительность операции обновления (время процессора), с. При этом накладные расходу на синхронизацию и передачу содержимого РОП по сети при длине линии связи РМУВС, равной 1 км, размере области РОП 1 Кбайт и скорости передачи 10 Мбит/с составят около 1 мс, что вполне приемлемо.Следует однако отметить, что, несмотря на эффективность ВОК-механизмов, их отличает довольно сложная реализация. Кроме того, в настоящее время аппаратура, реализующая механизмы для ВОК-систем, серийно не производится, и даже научные исследования в этой области далеко не завершены. Поэтому в настоящее время предложенные в главе 2 механизмы для ВОК-систем имют скорей научное, чем практическое значение. Однако в скором времени начинается выпуск сетевой аппаратуры для сетей с ДПУ, реализующей алгоритм децентрализованного пространственно-временного управления (ДПВУ)[25]. Поэтому перейдём к вопросам, связанным с организацией РОП для таких систем.
Рассмотрим, как организуется борьба за право получения доступа к РОП в системе с ДПУ. Особенность организации борьбы в таких системах заключается в том, что для них отсутствуют механизмы синхронизации, аналогичные механизму СМЗ для ВОК-систем. Поэтому всю работу по организации очередей в РОП, проверки её состояния, занятия и освобождения берёт на себя распределённый монитор РОП.
Вся область РОП делится на зоны. Разряд знака в зоне (т.е. разряд знака младшего байта зоны) является признаком занятости (если установлен, то зона заблокирована для операции обновления). При выполнении операции чтения ЛМ-РОП без всякой предварительной синхронизации считывает обычной командой чтения содержимое необходимого байта любой зоны из своей собственной КРОП.
При операции записи в РОП ЛМ-РОП инициирует борьбу за право получения доступа к каналу, выдавая соответствующую команду своему сетевому контроллеру. После занятия канала сетевым контроллером ЛМ-РОП записывает нужную информацию в РОП, которая потом передаётся согласно протоколу гарантированной доставки широковещательных сообщений для систем с ДПУ (см. параграф 2.1).
При операции обновления ЛМ-РОП сначала выполняет операцию записи в РОП, устанавливая при этом значения битов знака в требуемых зонах в единицу. Для простоты реализации за одну операцию можно выполнить обновление только одной зоны РОП. Операцию обновления РОП можно начинать только при одновременном выполнении двух условий: канал должен быть занят сетевым контроллером абонента, и значение обновляемой зоны должно быть положительным. Предварительное занятие канала перед выполнением операции обеспечивает неделимость операции блокировки обновляемой зоны, а её положительное значение гарантирует то, что никакая больше операция обновления этой же зоны в системе не инициирована.
ЛМ-РОП абонента, выполняющего операцию обновления, проверяет значение обновляемой зоны, проверяя знак разряда младшего байта. Если оно положительно, то ЛМ-РОП инициирует борьбу за канал. После занятия канала ЛМ-РОП снова проверяет значение этого байта. Если оно положительно, то ЛМ-РОП устанавливает значение разряда знака байта в единицу и затем передаёт содержимое своей КРОП при помощи протокола гарантированной доставки широковещательных сообщений. После выполнения этой процедуры обновляемая зона будет заблокирована во всех КРОП, имеющихся в системе. ЛМ-РОП в случае безуспешной попытки выполнения операции блокировки зоны повторяет её М раз, где М – параметр системы. После этого (если алгоритм ДПУ представляет только два уровня приоритета) ЛМ-РОП выжидает некоторый случайный интервал времени. После чего повторяет всю процедуру блокировки обновляемой зоны. Если же ДПУ предоставляет несколько уровней приоритетов, то попытка блокировки зоны выполняется сначала на самом нижнем уровне, и затем с каждой новой попыткой приоритет сетевого контроллера повышается с интервалом Т. Это даёт возможность смоделировать дисциплину FIFO при конфликте абонентов за право выполнения операции обновления одной и той же зоны РОП.
После выполнения операции блокировки ЛМ-РОП считывает значение требуемого байта зоны, обновляет его в соответствии с поступившим от процесса запросом и затем выполняет операцию записи, одновременно обнуляя разряд знака младшего байта зоны, освобождая её для операций со стороны других абонентов.
Рассмотрим, как решается вопрос защиты РОП от разрушения в результате передачи заведомо неправильной информации при помощи широковещательных сообщений. Рассмотрим случаи, когда передаваемая широковещательная информация является заведомо ложной.
- У источника, производящего запись в РОП, произошёл сбой памяти до начала передачи. В этом случае возникает прерывание от схем контроля, и операция должна быть немедленно отменена до восстановления содержимого КРОП этого абонента каким-либо другим абонентом, выполняющим операцию записи в РОП.
- Процесс, обращаясь к ЛМ-РОП с запросом на выполнение операций записи или обновления, записывает заведомо ложную информацию в КРОП. Для ликвидации такой возможности область КРОП абонентов должна быть защищена от записи, и тогда ЛМ-РОП сам должен решать, к каким областям РОП можно предоставить доступ пользовательским процессам, а к каким нет. Доступ ко всей жизненно важной системной информации с правом её изменения могут иметь только программы операционной системы. Считается, что эти программы безусловно работают правильно, и разрушение системной информации в этом случае невозможно. Разрушение же пользовательской области РОП приведёт лишь к краху задач, вызвавших это разрушение, но система не пострадает.
- У источника, производящего запись в РОП, произошёл сбой или отказ памяти во время передачи, т.е. когда отменить запрос на передачу широковещательного сообщения уже нельзя. Рассмотрим, как решается вопрос защиты РОП в этом случае.
Предположим, что абоненты умеют различать, является ли принятая информация истинной или ложной. Наиболее просто способ – дублирование информации при передаче, т.е. двукратная посылка источником своей КРОП в течение одного сеанса. При этом приёмники записывают информацию в свои КРОП во время первой посылки и сравнивают записанную информацию с принимаемой во время второй. Если во время передачи у источника имел место сбой памяти, исказивший его КРОП, это будет немедленно обнаружено всеми приёмниками по несовпадению информации первой и второй посылок.
Далее, каждый абонент имеет у себя не одну область КРОП, а две. Назовём из КРОП-А и КРОП-В. Одна из этих областей в каждый момент времени является текущей, другая – резервной. Все ЛМ-РОП абонентов выполняют операции, связанные с РОП, только в текущей области КРОП. Все широковещательные сообщения, передаваемы при операции записи в РОП, принимаются только в резервную область КРОП. Если сообщение принято правильно и содержащаяся в нём информация истинна, то статус областей меняется: резервная область, содержащая теперь обновлённое содержимое РОП, становится текущей, а текущая область становится резервной и в неё можно принимать следующее широковещательное сообщение. Если же сообщение принято неправильно или содержит ложную информацию, то статус областей остаётся прежним. Поскольку все операции, связанные с РОП, выполняются в одной области (текущей), а приём нового содержимого РОП происходит в другую область (резервную), принимаемая ложная информация не будет разрушать РОП. Перейдём к рассмотрению вопросов, связанных с использованием РОП для организации вычислительных процессов в распределённых вычислительных системах.
- Адресация и защита вычислительных процессов в распределённых системах управления.
Одной из основных проблем управления распределёнными системами является проблема определения точного адреса процесса, участвующего в выполнении некоторой распределённой обработки данных, при условии, что этот процесс может изменять своё физическое местоположение. Эта проблема возникает в следующем случае. Предположим, что в системе решается некоторая распределённая задача Т, состоящая из набора вычислительных процессов
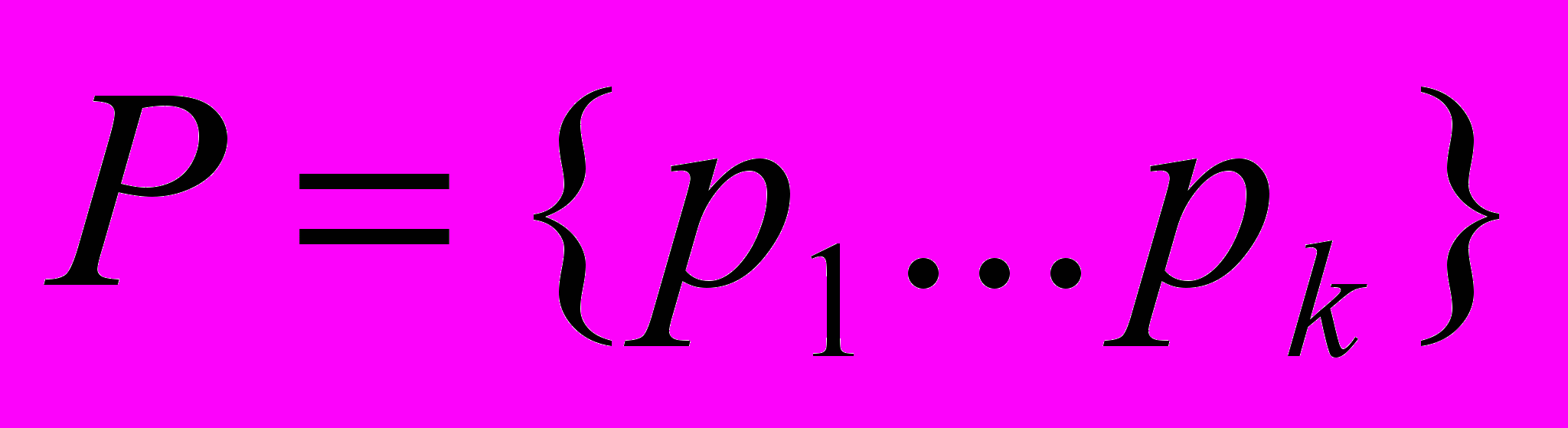 и структуры связей между процессами
и структуры связей между процессами 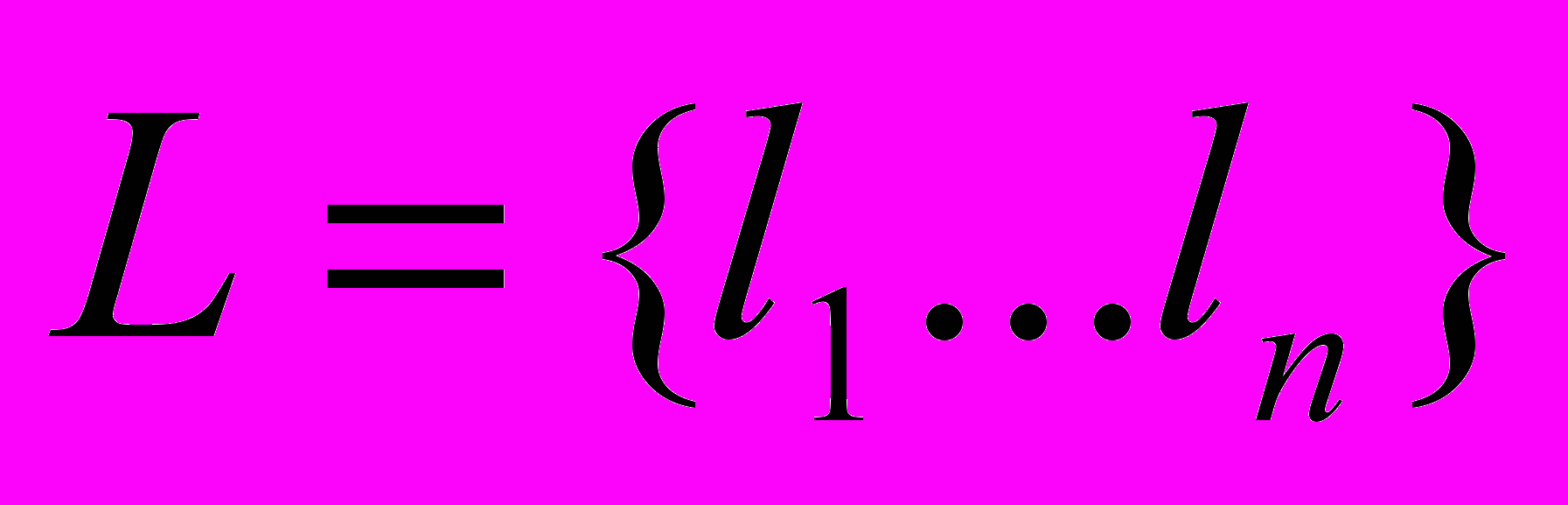 . Таким образом, задача может быть представлена в виде графа
. Таким образом, задача может быть представлена в виде графа 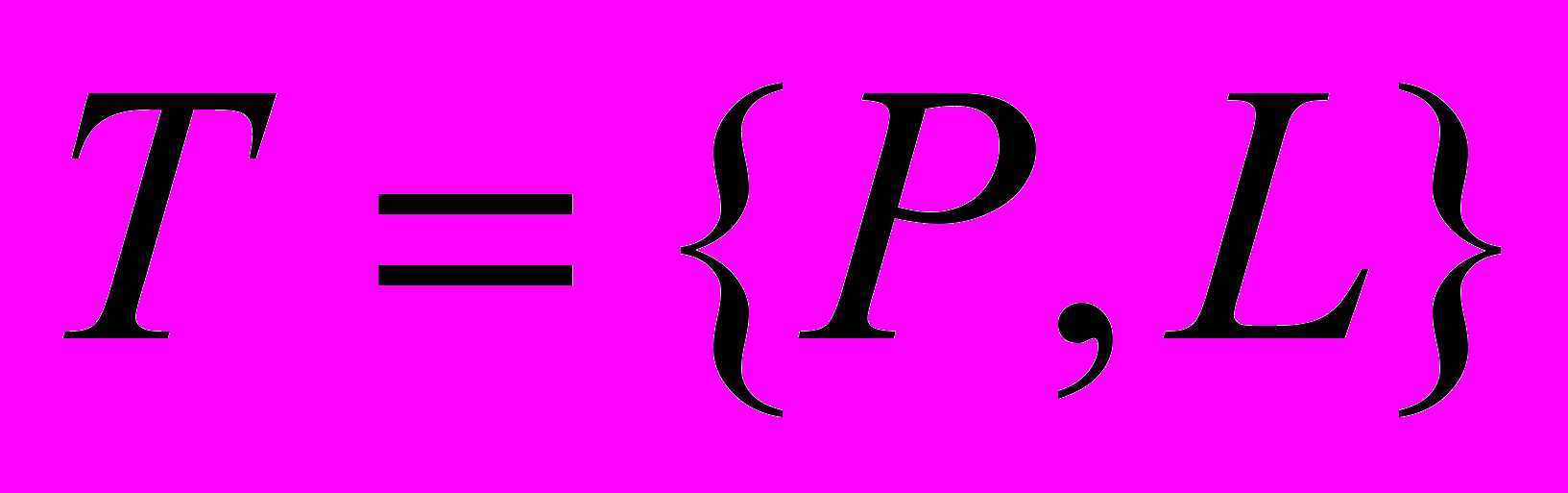 . В условиях неопределённости, существующих в распределённой системе, структура связей между процессами распределённой задачи может быть определена двумя путями. Первый путь – жёсткое закрепление за каждым процессом конкретного абонента РМУВС. При этом структура связей определяется уже на этапе программирования, и программы распределённой задачи должны содержать физические адреса тех абонентов, с которыми им предстоит взаимодействовать. Разновидностью такого подхода является случай, когда структура связей определяется не на этапе программирования, а на этапе запуска распределённой задачи. В этом случае оператор, запуская некоторый процесс распределённой задачи, определяет с пульта абонента, с какими другими абонентами будет взаимодействовать этот процесс. Достоинство такого подхода состоит прежде всего в простоте его реализации, и он широко используется в подавляющем большинстве систем [4,48,60,82 и др.]. Однако, такое решение задачи адресации не позволяет динамически перемещать взаимодействующие процессы по системе с целью, например, оптимизации загрузки РВС или с целью повышения надёжности её работы. Например, при отказе абонента, выполняющего некоторый процесс распределённой задачи, возникает вопрос – куда переместить этот процесс (задача выделения ресурса системы) и как сообщить остальным процессам о происшедшем перемещении (задача информационного распределённого сервиса). Проще всего это сделать вручную [60], но тогда получение результата решения распределённой задачи может затянуться на недопустимо большое время, и для систем управления быстрыми внешними для неё процессами такой подход может оказаться неприемлемым.
. В условиях неопределённости, существующих в распределённой системе, структура связей между процессами распределённой задачи может быть определена двумя путями. Первый путь – жёсткое закрепление за каждым процессом конкретного абонента РМУВС. При этом структура связей определяется уже на этапе программирования, и программы распределённой задачи должны содержать физические адреса тех абонентов, с которыми им предстоит взаимодействовать. Разновидностью такого подхода является случай, когда структура связей определяется не на этапе программирования, а на этапе запуска распределённой задачи. В этом случае оператор, запуская некоторый процесс распределённой задачи, определяет с пульта абонента, с какими другими абонентами будет взаимодействовать этот процесс. Достоинство такого подхода состоит прежде всего в простоте его реализации, и он широко используется в подавляющем большинстве систем [4,48,60,82 и др.]. Однако, такое решение задачи адресации не позволяет динамически перемещать взаимодействующие процессы по системе с целью, например, оптимизации загрузки РВС или с целью повышения надёжности её работы. Например, при отказе абонента, выполняющего некоторый процесс распределённой задачи, возникает вопрос – куда переместить этот процесс (задача выделения ресурса системы) и как сообщить остальным процессам о происшедшем перемещении (задача информационного распределённого сервиса). Проще всего это сделать вручную [60], но тогда получение результата решения распределённой задачи может затянуться на недопустимо большое время, и для систем управления быстрыми внешними для неё процессами такой подход может оказаться неприемлемым.Другой путь состоит в создании помимо основной структуры связей альтернативной структуры. При этом процессы, входящие в альтернативную структуру, находятся в режиме горячего резерва [36] и при обнаружении отказа абонента, входящего в основную структуру, происходит автоматическое переключение требуемых процессов распределённой задачи на альтернативный процесс, полный адрес которого также жёстко зафиксирован. Помимо того, что такой подход не решет задачи оптимизации загрузки системы, он требует для обеспечения надёжности удвоения ресурсов, необходимых для решения распределённой задачи (при полном дублировании) и, как минимум, утроения при мажорировании.
Альтернативой двум рассмотренным способам является подход, когда РВС рассматривается не просто как набор ЭВМ и сеть передачи данных, а как система с интеграцией ресурсов. При этом естественно существующая в каждой большой системе избыточность ресурсов используется для обеспечения требуемой надёжности: [31] простаивающие ресурсы используются для подмены вышедших из строя или разгрузки перегруженных ресурсов динамически. Структура связей в этом случае заранее не определена и в задачу распределённой операционной системы входит поиск требуемого ресурса, закрепление его за процессом распределённой задачи и автоматическое определение структуры связей; при изменении загрузки или выходе из строя абонентов структура связей автоматически реконфигурируется. В данном разделе не рассматриваются вопросы, связанные с обнаружением ситуаций, при которых требуется реконфигурация системы; также не рассматриваются алгоритмы реконфигурации. Предполагается, что все необходимые перемещения процессов распределённой задачи уже закончены и требуется сообщить остальным процессам задачи новые адреса перемещённых процессов. Таким образом, рассматривается только задача адресации, а также задача защиты процессов от несанкционированного вмешательства со стороны процессов, образующих другие распределённые задачи.
Рассмотрим организацию адресации в системе, имеющей распределённую общую память. Основными адресуемыми объектами являются задачи и порты. Задача есть вычислительный процесс, обладающий именем, состоянием, который выполняется локально одним процессом распределённой системы. Распределённая задача образуется из множества задач локальных после того, как установлена необходимая реконфигурация связей. Порт есть локальная задача, основное значение которой состоит в передаче информации другим задачам. С точки зрения организации адресации распределённая операционная система не видит различия между портом и локальной задачей, поэтому в дальнейшем будет рассматриваться только вопрос адресации задач.
С точки зрения организации адресации функциональная структура РМУВС приведена на рис.3.4. Как видно, она состоит из групп, каждая из которых состоит, в свою очередь, из абонентов. Конфигурация групп и их количество определяется при генерации системы. Каждый из абонентов РВС может откликаться на следующие виды адресов: широковещательный, групповой и индивидуальный. Все эти адреса в дальнейшем будут называться физическими адресами абонентов. На широковещательный адрес откликаются все абоненты РВС, на групповой – все абоненты адресованной группы и на индивидуальный – только адресованный абонент. Все абоненты системы имеют доступ к общесистемной распределённой памяти (ОРП), все абоненты одной и той же группы имеют доступ к общегрупповой распределённой памяти (ОГРП). ОРП и ОГРП организованы по принципу, рассмотренному в параграфе 3.3.
Под адресацией будем понимать определение точного местонахождения в системе адресуемой задачи с целью передачи её некоторой информации или изменения её состояния. Будем называть операцию передачи информации от задачи А к задаче В информационным запросом (ИЗ), операцию изменения состояния задачи В задачей А – управляющим запросом (УЗ). Все запросы передаются по сети в виде сообщений, при этом запросы типа ИЗ поступают к явно адресованному порту, запросы типа УЗ неявно адресуются приёмному порту локальной операционной системы адресуемого абонента.
Адресация задач осуществляется по имени задач. Имя задачи состоит из двух полей: поля физического адреса абонента (ФАА) и поля локального имени задачи (ЛИЗ). Поле ЛИЗ определяет то имя, под которым адресуемая задача известна своей операционной системе. ЛИЗ используется локальными операционными системами, имеющимися у каждого абонента, для организации мультизадачного режима работы этого абонента. Таким образом, ЛИЗ является идентификатором локальной задачи (ЛЗ). Все ЛИЗ локальных задач, выполняемых в мультизадачном режиме, должны быть различными. ЛИЗ задач, выполняемых параллельно различными абонентами системы, могут быть одинаковы. Уникальность имени задачи обеспечивается в этом случае различными ФАА.
Адресация в системе может быть четырёх типов:
- локальная адресация;
- удалённая явная адресация;
- удалённая неявная адресация;
- глобальная адресация.
Локальная адресация имеет место в том случае, когда адресуемая задача вычисляется тем же абонентом, что и запрашиваемая в мультизадачном режиме.
Удалённая явная адресация применяется тогда, когда запрашивающей задаче известен полный адрес (ФАА и ЛИЗ) адресованной задачи. Этот адрес либо жёстко программируется, либо вводится с терминала оператором при запуске задачи.
Удалённая неявная адресация имеет место в случае управляющих запросов. При этом запрашивающая задача указывает полный адрес удалённой задачи (так же, как и в случае удалённой явной адресации), однако сообщение, содержащее запрошенную операцию изменения состояния удалённой задачи, переадресуется локальной операционной системой источника запроса входному порту локальной операционной системы приёмника. Фактически, такой тип адресации является удалённым выполнением команд – обращений к супервизору. Все обращения при этом форматируются в соответствии с техникой механизма взаимного распределённого программирования для обеспечения согласования форматов при наличии в системе неоднородных абонентов. Для запрашивающей задачи это означает, что во-первых, синтаксически удалённый запрос не отличается от местного, и, во-вторых, ей нет необходимости знать имя приёмного порта удалённой операционной системы.
Глобальная адресация (или адресация глобальных задач) применяется для того, чтобы избавить запрашивающую задачу от необходимости указания полного адреса удалённой задачи. Глобальные задачи могут быть двух типов: системные глобальные задачи (СГЗ) и групповые глобальные задачи (ГГЗ). Системная глобальная задача – это задача, информация о которой (включая её точное местоположение в системе) хранится в общесистемной распределённой памяти. При перемещении такой задачи по системе эта информация будет изменяться тем процессом распределённой операционной системы, который отвечает за реконфигурацию РВС. Поскольку доступ к ОРП имеют локальные операционные системы всех абонентов, перемещение задачи будет всем известно немедленно после записи её нового адреса в ОРП. Групповая глобальная задача аналогична системной, однако информация о ней доступна только абонентам, входящим в одну и ту же группу. Для того, чтобы задача стала глобальной, её нужно объявить таковой, выдав соответствующее обращение к операционной системе. Максимальное количество глобальных задач в системе и в группах определяется только объёмом ОРП и ОГРП и устанавливается при генерации системы.
Все локальные операционные системы абонентов при получении любого запроса от локальных задач действуют по следующему алгоритму определения типа адресации.
Алгоритм 3.3.1
- Проверить, указан ли в запросе полный адрес (имя) адресуемой задачи. Если да, то переход к п. 2, иначе к п. 5.
- Проверить тип запроса. Если запрос управляющий (удалённый вызов супервизора), то переход к п. 3, иначе к п. 4.
- Переадресовать запрос входному порту локальной операционной системы адресованной задачи и выполнить. Конец алгоритма.
- Выполнить информационный запрос, передав сообщение адресованному порту. Конец алгоритма.
- Искать задачу с указанным ЛИЗ в локальной системной памяти абонента. Если задача найдена, то переход к п. 6, иначе переход к п.7.
- Задача является локальной, выполнить запрос обычным образом без выхода в сеть. Конец алгоритма.
- Искать задачу с указанным ЛИЗ в распределённой памяти (сначала в ОГРП, а если не найдена – в ОРП). Если задача найдена, то переход к п. 8, иначе к п.9.
- Считать информацию о глобальной задаче из распределённой общей памяти, узнать её точный адрес, поместить его в сообщение и передать его. Конец алгоритма.
- Задача с указанным ЛИЗ отсутствует. Сообщить запрашивающей задаче об ошибке. Конец алгоритма.
Из алгоритма видно, что точное значение полного адреса удалённой задачи требуется задаче-источнику запроса только в случаях явной или неявной удалённой адресации. При локальной адресации или адресации глобальных задач от задачи-источника требуется только знание ЛИЗ адресата. Это даёт возможность создавать распределённые задачи, отдельные процессы которых взаимодействуют с помощью указания только логических имён, независимо от конкретного физического их расположения в каждый момент времени. Поэтому все производимые реконфигурации при отказах или изменении нагрузки не отражаются на процессах пользователей, образующих распределённую задачу. Опишем алгоритм работы локальных операционных систем при приёме сообщения.
Алгоритм 3.3.2
- Проверить. Имеется ли указанная в сообщении задача или порт. Если да, то переход к п.2, иначе к п.3.
- Проверить, имеет ли право доступа задача-источник запроса к адресованной задаче. Если имеет, то послать положительную квитанцию источнику, иначе отрицательную. Конец алгоритма.
- Послать отрицательную квитанцию с кодом «Задача отсутствует». Конец алгоритма.
Особым случаем адресации является адресация флагов событий. Флаги событий используются в РОС для синхронизации взаимодействия процессов распределённой задачи и являются неявно адресуемыми объектами, идентифицируемыми по номеру флага. Распределённая операционная система должна различать четыре группы флагов событий: общесистемные флаги, групповые флаги, флаги абонента и индивидуальные флаги локальной задачи. Общесистемные флаги располагаются в ОРП и могут быть использованы для организации распределённого взаимодействия процессов на уровне всей системы. Групповые флаги располагаются в ОГРП и могут использоваться для такой же цели на уровне группы абонентов. Флаги абонентов располагаются в его же собственной системной локальной памяти и являются общими для всех процессов, выполняемых этим абонентом в мультизадачном режиме. Индивидуальные флаги располагаются в памяти отдельной локальной задачи и служат для её синхронизации с драйвером, таймером и т.д. Использование ВРП-механизма и наличие распределённой общей памяти позволяет сделать адресацию флагов всех четырёх групп прозрачной для задач пользователей; наличие сети они не замечают. Количество флагов в каждой группе должно быть определено при генерации операционной системы.
В распределённых операционных системах, построенных на основе модели РУВС, правом передачи широковещательных сообщений владеют только программы РОС, образующие распределённый монитор РОП; непосредственно для задач пользователей такая возможность не предоставляется. При необходимости многопунктовой адресации задачам пользователей предоставляется две возможности:
- Работа через РОП (ОРП или ОГРП). Все сообщения направляются в пользовательскую часть РОП, откуда затем могут быть считаны любой другой локальной задачей. Такой режим аналогичен работе задач через COMMON в обычных вычислительных системах. Размер пользовательской части РОП устанавливается при генерации системы; размер передаваемой через РОП информации по возможности должен быть минимизирован.
- Последовательная передача сообщения адресатам. При таком режиме длина сообщения ограничена только максимально возможной длиной сообщения в системе, установленной при генерации. При таком режиме сеть не является прозрачной.
Рассмотрим, как решается задача защиты процессов, образующих распределённую задачу, от постороннего вмешательства. Поскольку при рассматриваемом подходе РВС является системой с интеграцией ресурсов, процессы, входящие в разные распределённые задачи, могут влиять друг на друга, разрушая установленную логику взаимодействия процессов внутри некоторых распределённых задач. В основном это будет происходить из-за ошибок программного обеспечения. РОС обеспечивает защиту следующим образом.
Процессы, образующие некоторую распределённую задачу, объединяются в коалицию. Коалиция – это группа процессов распределённой задачи, доступ которым ограничен. Ограничения доступа следующие:
- Любая задача, входящая в коалицию К, имеет неограниченный доступ к любой другой задаче, входящей в эту же коалицию.
- Существует класс задач, называемых привилегированными, которые имеют неограниченный доступ к любой задаче в системе.
- Если задача не входит в коалицию К и не является привилегированной, она имеет доступ к задачам из коалиции К только при указании правильного пароля коалиции.
Пароль коалиции – это целое случайное число, получаемое при создании коалиции и известное всем задачам, входящим в коалицию. Пароли коалиций хранятся в РОП и доступны только оператору системы; любая задача, не являющаяся привилегированной, при необходимости доступа к задачам из некоторой коалиции должна запросить у оператора пароль этой коалиции.
Коалиция создаётся следующим образом. Любая задача в системе издаёт запрос на создание коалиции, указывая в нём полные имена всех задач, которые должны быть включены в коалицию и определяя имя коалиции. Если коалиция с указанным именем уже создана, то запрашивающая задача извещается об этом и запрос отвергается. В противном случае задачи, указанные в запросе на создание коалиции, включаются в неё при выполнении следующих условий:
- Указанная задача должна быть в системе.
- Указанная задача не входит в другие коалиции.
- Указанная задача на момент поступления запроса на создание коалиции разрешила включать себя в коалицию с указанным в запросе именем.
Запрашивающая задача автоматически включается в создаваемую ей коалицию. Если запрос отвергнут из-за того, что коалиция с указанным именем уже существует, запрашивающая задача может обратиться к оператору, чтобы получить пароль этой коалиции, и затем войти в эту коалицию (если оператор сообщил пароль, разрешая тем самым вхождение), издав соответствующий запрос.
При получении запроса на создание коалиции от задачи пользователя локальная операционная система этого абонента выполняет следующие действия:
- Выясняет, нет ли уже коалиции с указанным именем; если есть, то возвращает управление запрашивающей задаче с соответствующим признаком завершения запроса.
- Генерирует пароль коалиции – случайное число, отличное от нуля, и заносит имя коалиции и пароль в ОРП.
- Опрашивает указанные в запросе задачи, предлагая им вступить в коалицию и сообщая пароль. Если опрашиваемая задача удовлетворяет вышеописанным условиям вступления в коалицию, то локальная ОС абонента, где расположена эта задача, отвечает согласием; при этом пароль и имя коалиции заносятся в блок управления задачей. Нулевое значение пароля в блоке управления задачей означает, что задача не входит ни в какие коалиции.
В коалицию может входить произвольное количество задач – от одной до максимально возможного количества, определяемого при генерации системы. Если коалиция состоит из одной задачи, то это означает, что задача защищает от несанкционированного доступа только саму себя.
Задачи могут выходить из коалиции, например, для того, чтобы вступить в другие коалиции. Задача выходит из коалиции явно, если она издаёт соответствующий запрос – «Выйти из коалиции». Задача выходит из коалиции неявно, если она нормально или аварийно завершает своё выполнение.
Коалиция ликвидируется либо тогда, когда она пуста (т.е. все задачи вышли из коалиции), либо по команде оператора.
С точки зрения привилегий все задачи в системе делятся на две группы: привилегированные и непривилегированные, как и в обычных операционных системах с многопользовательской защитой. Задачи могут входить в систему либо по команде оператора, либо по запросу от выполняющейся задачи. Если задача входит в систему по запросу оператора, то оператор сам устанавливает статус задачи – привилегированная или непривилегированная. Если задача инициируется другой задачей, то действует следующее правило: задачи, инициированные привилегированной задачей, могут быть как привилегированные, так и непривилегированные (в зависимости от запроса). Задачи, инициированные непривилегированной задачей, автоматически получают статус непривилегированности. Сразу после запуска системы в ней присутствует только одна привилегированная задача – программа связи с оператором, и оператор должен издать запрос на запуск некоторой задачи, которая осуществит «раскрутку системы», т.е. запустит все необходимые для работы задачи с указанием их статуса. Если в системе необходимо иметь привилегированные задачи, отличные от программы связи с оператором, то задача раскрутки должна запускаться как привилегированная.
- Программные средства обеспечения надёжности распределённой системы управления.
- Действия управляющего ядра при отказе питания.
- Действия управляющего ядра при отказе питания.
В существующих вычислительных сосредоточенных системах с централизованным управлением при отказах питания применяется запись содержимого памяти и регистров на массовые накопители на магнитных дисках с последующим рестартом после восстановления питания. Однако, применение подобного приёма в распределённых системах связано с рядом трудностей, перечисленных ниже. Первая трудность связана с тем, что не все абоненты распределённой системы могут иметь массовые накопители. Например, микро-ЭВМ, входящие в состав РВС, могут работать с удалёнными массовыми накопителями в обратном режиме разделения [26], и для них необязательно наличие собственных накопителей, а с точки зрения экономии даже не желательно, учитывая большую стоимость электромеханических устройств по сравнению со стоимостью самих микро-ЭВМ. Вторая трудность связана с первой и состоит в том, что во время сбоя питания накопитель, к которому через сеть логически подключена микро-ЭВМ, может быть занят выполнением некоторой ранее инициированной операции, а на поиск по сети альтернативного устройства для сохранения содержимого памяти и регистров может не хватить времени. Предлагается следующее решение задачи.
В РВС выделяется группа абонентов, используемых лишь для одной цели – в качестве «кэш» памяти при аварийном сохранении содержимого регистров и памяти абонента, у которого произошёл отказ питания. Все станции из этой группы имеют одинаковый групповой адрес, хранящийся в общесистемной распределённой памяти. Назовём этот адрес адресом группы сохранения (АГС). Каждый абонент, входящий в группу сохранения, может находиться в двух состояниях – свободен и занят. Абонент из группы сохранения (ГС) занят тогда, когда он хранит у себя в памяти содержимое регистров и памяти отказавшего по питанию другого абонента. Абонент из ГС остаётся занятым до тех пор, пока он не осуществит запись сохранённого им содержимого памяти и регистров на любой массовый накопитель из имеющихся в РВС. После выполнения операции записи сохранённого содержимого абонент из ГС становится свободен и способен принимать другие запросы на сохранение памяти и регистров. Исходное состояние всех абонентов из ГС – свободен.
Каждый из абонентов РВС при начальном запуске выполняет процедуру форматирования аварийного сообщения на случай отказа питания. При этом АГС помещается в самый младший байт памяти, в следующий байт помещается собственный адрес абонента. Таким образом, формируется кадр в соответствии с протоколом канального уровня, характерным для всех ЛВС [54] и в частности, для систем с ДПУ. Информационное поле кадра содержит всю область памяти абонента.
При сбое питания абонент поднимает приоритет своего сетевого контроллера на уровень аварийных сигналов и передаёт сообщение, содержащее его содержимое памяти (сохранив предварительно регистры) с помощью группового сообщения всем абонентам группы сохранения. Доставка группового сообщения выполняется в соответствии с протоколом гарантированной доставки широковещательных сообщений (см. пп. 2.1-2.2).
Все свободные абоненты из группы сохранения принимают данное сообщение и переходят в состояние занятости, одновременно начиная борьбу за право перейти в состояние «свободно». При этом каждый из них пытается передать групповое сообщение другим абонентам, содержащим признак «работу взял». Тот из них, кто первым передаст это сообщение, остаётся в состоянии занятости, остальные при получении такого сообщения снимают сои запросы на его передачу и переходят в состояние «свободно».
Абонент, взявший на себя работу, имеет теперь достаточно времени для поиска в системе массового накопителя для окончательного сохранения содержимого памяти и регистров отказавшего по питанию абонента, и операция не вызывает затруднений.
Определим требуемую скорость передачи с учётом объёма памяти абонентов – микро-ЭВМ. Обозначая М максимально возможный объём памяти у микро-ЭВМ, Т- время, в течение которого напряжение питания поддерживается за счёт источника питания, V – скорость передачи информации по каналу связи и N – максимально возможное количество одновременно отказавших по питанию абонентов в системе, получим
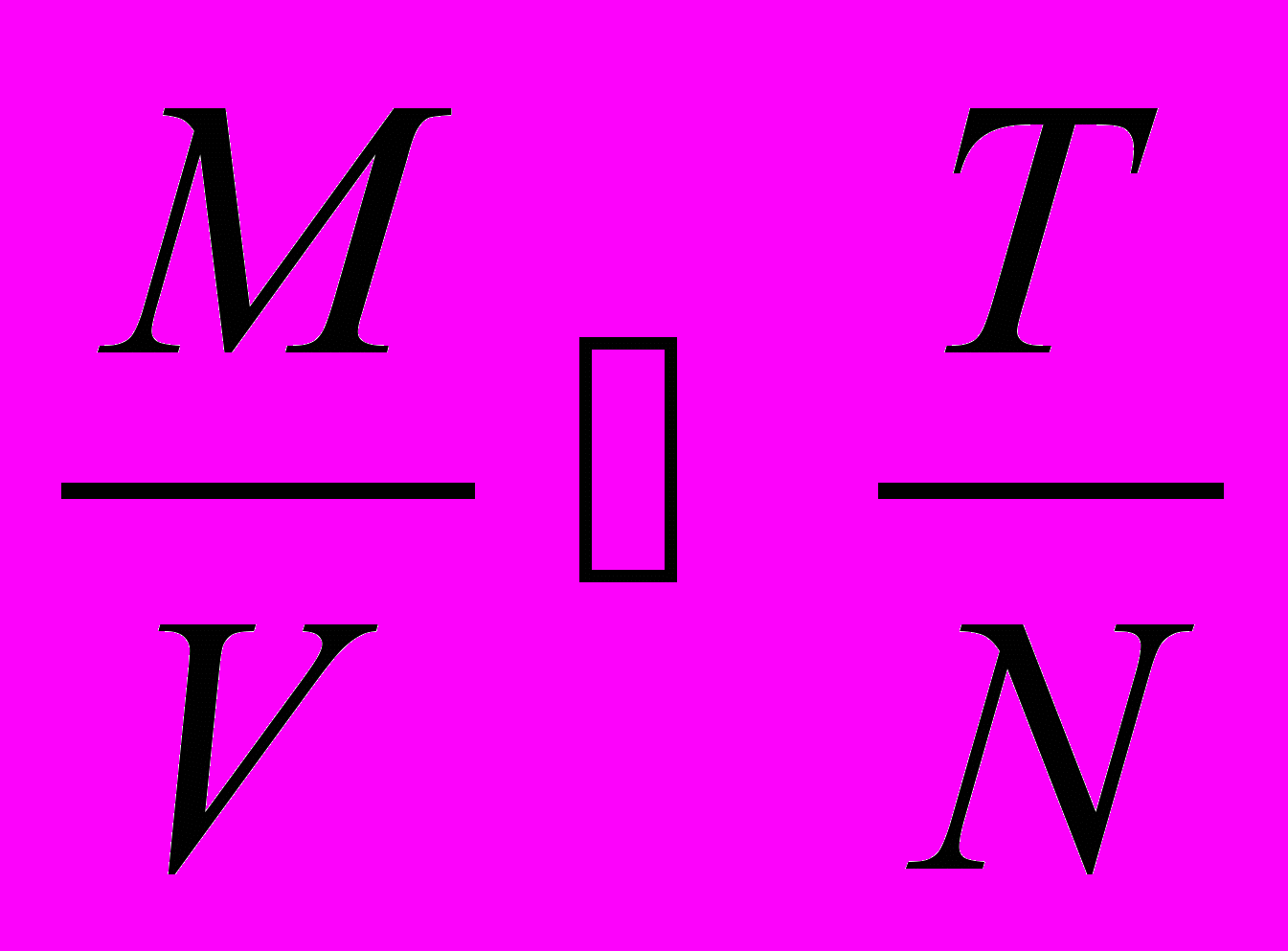 (3.5.1)
(3.5.1)откуда
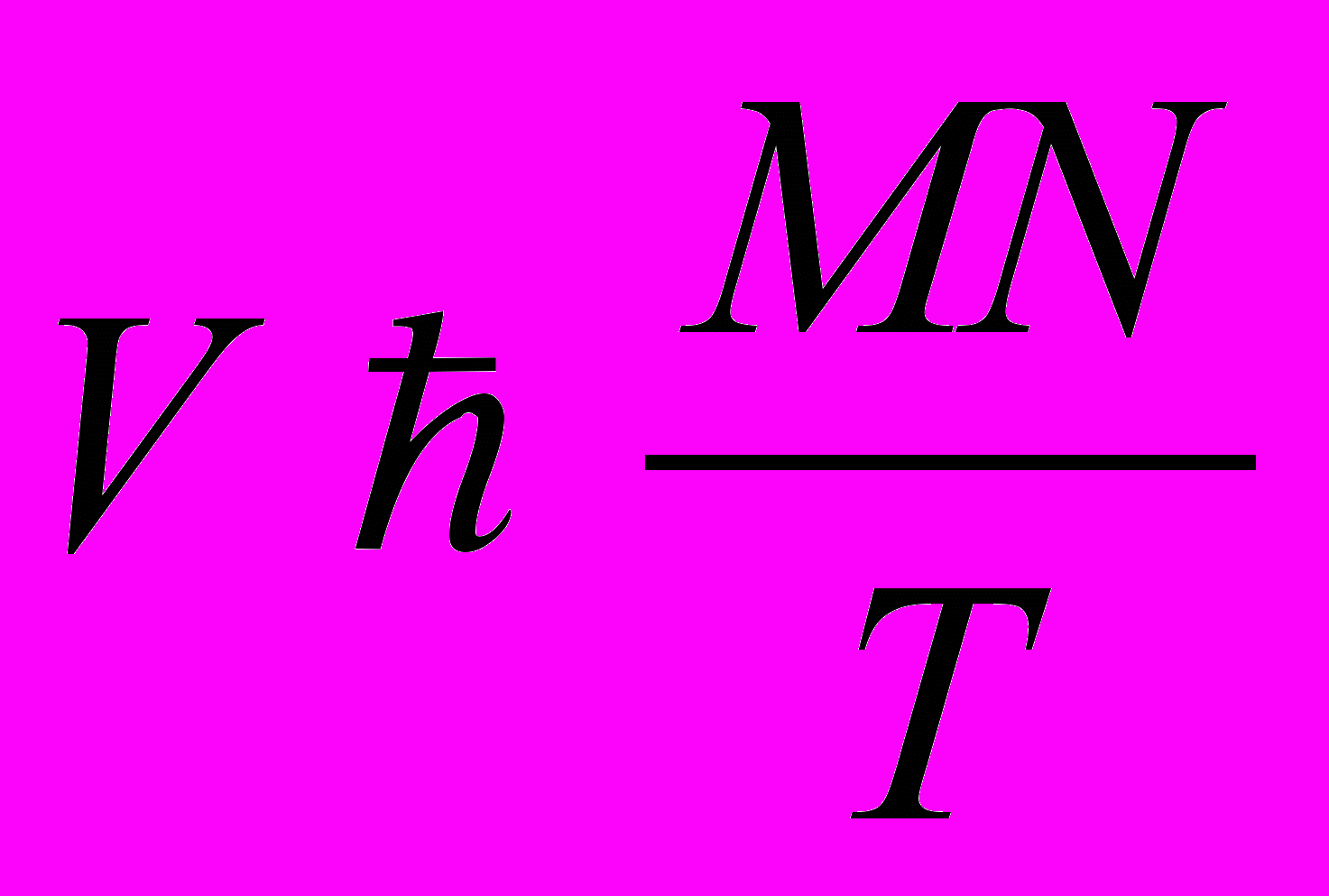 (3.5.2)
(3.5.2)Например, при М=64 Кбайт, Т=0,5 с и N=2 (величины М и Т приведены для микро-ЭВМ типа «Электроника-60»), получим требуемое значение скорости передачи V>2 Мбит/с, что легко достижимо в настоящее время в сетях с ДПУ.
- Обеспечение управления ядром надёжности хранения информации на магнитных дисках.
Как было отмечено в главе 1, единственным системным средством обеспечения надёжности хранения информации в распределённых базах данных является полное либо частичное многократное копирование хранимой информации. При таком подходе к обеспечению надёжности возникает задача обновления многих копий, относящихся к задачам синхронизации. В настоящем разделе предлагается алгоритм решения этой задачи, использующий распределённую общую память. Алгоритм носит название механизма приоритетного асинхронного голосования (ПАГ); он использует конструкцию, названную в настоящей работе стоппером. Стоппер был предложен в механизме синхронизации потоком событий [11]; окончательное название эта конструкция получила в настоящей диссертации.
Рассмотрим работу стоппера. Каждому процессу распределённой задачи ставится а соответствие группа флагов
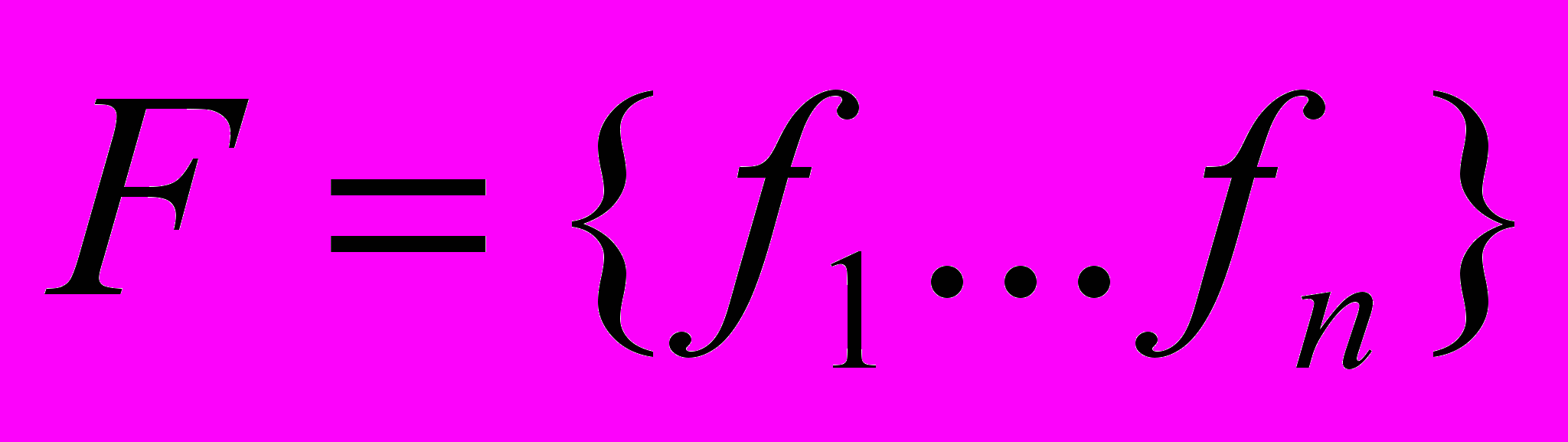 . Количество флагов в группе равно количеству процессов распределённой задачи, i-й флаг связан с i-ым процессом. Для i-го процесса i-ый флаг имеет значение «Событие послано», остальные флаги – «Событие от k-го процесса принято». Группа флагов F находится в распределённой общей памяти – общесистемной или групповой. При достижении точки синхронизации i-ый процесс посылает событие остальным процессам, устанавливая i-ый флаг в единицу. После этого процесс ждёт до тех пор, пока все флаги в группе F не будут установлены. Нетрудно видеть, что к определённому моменту времени останется лишь один процесс, не пославший события. При этом у остальных процессов не будет установлен флаг приёма события от этого процесса, и, следовательно, они будут находиться в состоянии ожидания. Посылка события последним процессом распределённой задачи и будет являться неделимой синхрооперацией, освобождающей все остальные процессы (рис. 3.5), причём неделимость этой операции обеспечивается наличием в сети общего канала и возможности групповой адресации. ПАГ-механизм использует расширенную конструкцию стоппера, в которой с каждым флагом из группы F связан приоритет этого флага. Приоритет флага определяется посылающим событие процессором динамически; значение приоритетов флагов также хранится в РОП и доступно для всех процессов распределённой задачи. Приоритеты флагов образуют в РОП вектор, i-й элемент которого соответствует i-му флагу из группы F.
. Количество флагов в группе равно количеству процессов распределённой задачи, i-й флаг связан с i-ым процессом. Для i-го процесса i-ый флаг имеет значение «Событие послано», остальные флаги – «Событие от k-го процесса принято». Группа флагов F находится в распределённой общей памяти – общесистемной или групповой. При достижении точки синхронизации i-ый процесс посылает событие остальным процессам, устанавливая i-ый флаг в единицу. После этого процесс ждёт до тех пор, пока все флаги в группе F не будут установлены. Нетрудно видеть, что к определённому моменту времени останется лишь один процесс, не пославший события. При этом у остальных процессов не будет установлен флаг приёма события от этого процесса, и, следовательно, они будут находиться в состоянии ожидания. Посылка события последним процессом распределённой задачи и будет являться неделимой синхрооперацией, освобождающей все остальные процессы (рис. 3.5), причём неделимость этой операции обеспечивается наличием в сети общего канала и возможности групповой адресации. ПАГ-механизм использует расширенную конструкцию стоппера, в которой с каждым флагом из группы F связан приоритет этого флага. Приоритет флага определяется посылающим событие процессором динамически; значение приоритетов флагов также хранится в РОП и доступно для всех процессов распределённой задачи. Приоритеты флагов образуют в РОП вектор, i-й элемент которого соответствует i-му флагу из группы F.Рассмотрим процедуры механизма приоритетного асинхронного голосования. Предположим, что некоторый файл А размножен и его копии хранятся на дисках Д1,Д2 и Д3, принадлежащих различным абонентам распределённой системы. Тогда на каждом из этих абонентов запускается процесс-контроллер, управляющей доступом транзакций и записям файла А на диске Дi, принадлежащем i-му абоненту (i=1,2,3). Каждый из контроллеров действует по следующему алгоритму (рис. 3.6).
Сразу после запуска контроллер выполняет операцию «Ждать F», где F – стоппер. После того, как все контроллеры выполнят эту операцию, их выполнение будет продолжено. При выполнении операции ожидания стоппера каждый контроллер помимо события посылает остальным контроллерам приоритет транзакции (если к моменту точки синхронизации транзакция поступила). Если же запрос на транзакцию контроллером не был получен, то он посылает пустое событие.
После выполнения синхронизации с помощью стоппера все контроллеры просматривают вектор приоритетов транзакций, связанный со стоппером, и выбирает транзакцию с максимальным приоритетом. Если имеются транзакции с равными приоритетами, то выбирается транзакция, имеющая минимальный индекс в векторе приоритетов. Такая процедура гарантирует, что все контроллеры выберут одну и ту же транзакцию. Если все контроллеры послали пустое событие, то каждый из них просто возвращается в точку синхронизации. Таким образом, все контроллеры постоянно находятся в цикле ожидания транзакций, синхронизируя свои действия при помощи стоппера.
Выбрав транзакцию, контроллеры запускают процессы её обработки и снова возвращаются в точку синхронизации. Транзакция будет запущена только в том случае, если она не конфликтует с уже запущенными ранее транзакциями. Если контроллеры обнаружат конфликт, то транзакция будет поставлена в очередь и будет ждать до тех пор, пока не завершится транзакция, с которой она конфликтует.
Определим время цикла синхронизации контроллеров в механизме приоритетного асинхронного голосования. Обозначая d среднее время передачи одного сообщения, N – число контроллеров, Ta – время анализа вектора приоритетов для самого медленного из контроллеров, Тз – время запуска транзакции для самого медленного из контроллеров, при использовании алгоритма доставки широковещательных сообщений (см. параграф 2.1) получим
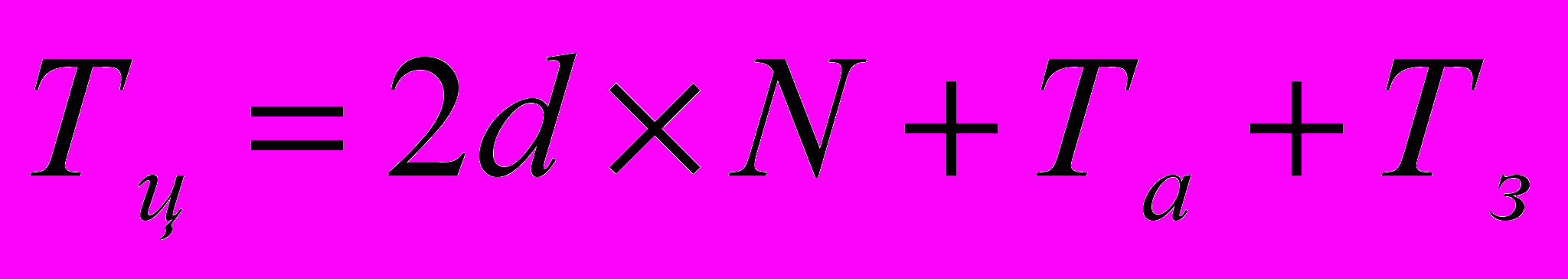 (3.4.3)
(3.4.3)Время цикла контроллера определяет пропускную способность ПАГ-механизма. Как видно, для синхронизации необходимо послать
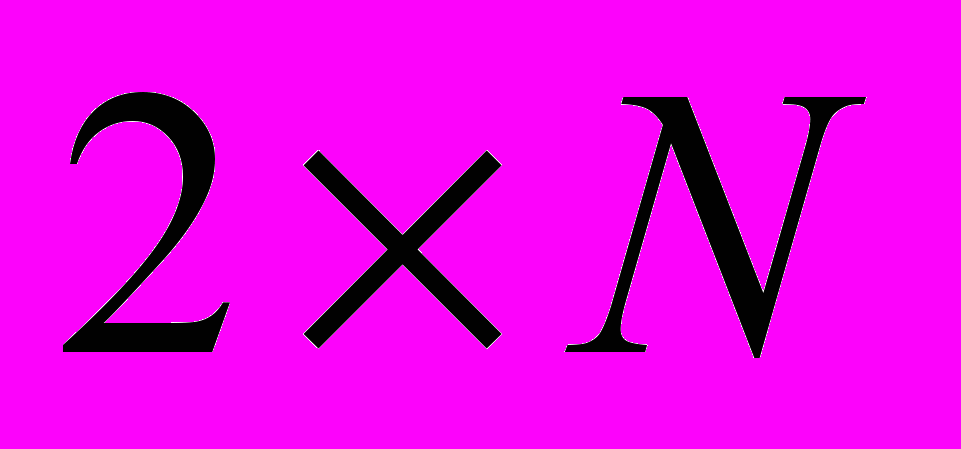 сообщений. Это существенно лучше механизма синхронного голосования [53], для которого при синхронизации требуется посылка
сообщений. Это существенно лучше механизма синхронного голосования [53], для которого при синхронизации требуется посылка 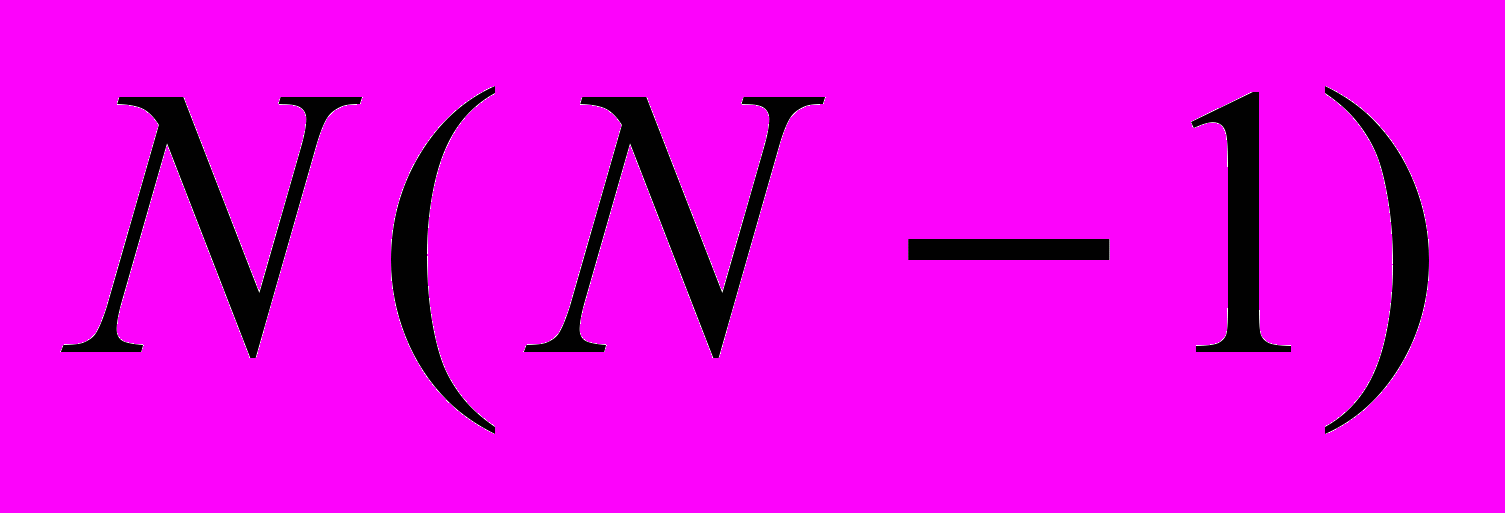 сообщений. Таким образом, ПАГ-механизм снижает расходы на синхронизацию по сравнению с механизмом [52] в
сообщений. Таким образом, ПАГ-механизм снижает расходы на синхронизацию по сравнению с механизмом [52] в 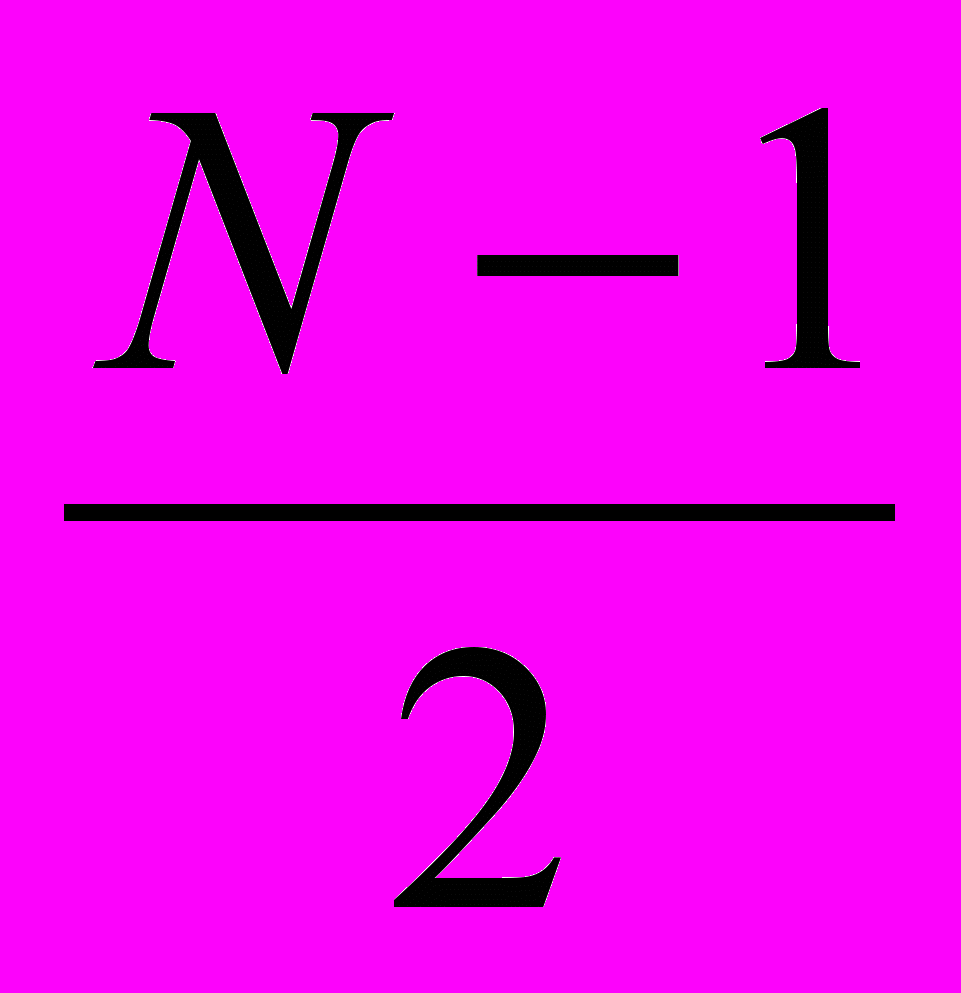 раз. Кроме того, механизм приоритетного асинхронного голосования позволяет учитывать приоритеты поступающих транзакций, что весьма важно для исследуемых систем.
раз. Кроме того, механизм приоритетного асинхронного голосования позволяет учитывать приоритеты поступающих транзакций, что весьма важно для исследуемых систем.Выводы
Использование механизмов гарантированной доставки широковещательных сообщений и механизмов синхронизации для ВОК-систем позволяет просто и эффективно решать ряд проблем, возникающих при разработке средств управления распределённой управляюще-вычислительной системой, т.е. программ распределённых операционных систем. В первую очередь предложенные во второй главе механизмы позволяют иметь в РМУВС с децентрализованным управлением распределённую общую память (РОП), наличие которой упрощает решение задач РМУВС. Получается, что в децентрализованной РМУВС можно применять централизованные алгоритмы, храня при этом необходимую для управления информацию в РОП. При этом организация РОП гарантирует, что надёжность всей системы не снижается, как в случае введения централизованного информационного центра. РОП допускает параллелизм при выполнении операций чтения и обеспечивает синхронизацию процессов при выполнении ими операций записи и обновления РОП. Предложенные способы использования РОП для глобальной адресации, синхронизации при доступе многих транзакций к копиям распределённой базы данных решают ряд задач распределённого управления РМУВС. Рассмотренная модель РМУВС отражает специфику использования канала связи как средства синхронизации параллельных процессов в РВС. Основной вывод, который можно сделать на основании материалов, содержащихся в главе 3, следующий: с помощью механизмов, рассмотренных в главе 2, решён комплекс основных задач, позволяющих строить управляющее ядро РМУВС на основе принципов распределённого управления; при этом за счёт использования нестандартных средств при решении этих задач получен значительный выигрыш за счёт резкого уменьшения накладных расходов на организацию распределённого управления в РМУВС. К недостаткам предлагаемых решений следует отнести прежде всего усложнение сетевой аппаратуры при аппаратной реализации базовых механизмов (механизмов, предложенных в главе 2). В особенности это относится к механизмам для ВОК-систем. Однако, представляется, что, несмотря на этот недостаток, предложенное направление исследований является весьма перспективным и работы в этом плане должны быть продолжены.