
Т. А. Ткачева (отв редактор), Е. В. Кузнецова (зам отв редактора)
| Вид материала | Документы |
- Выпуск 48 Э. Ф. Шарафутдинова чеченский конфликт: этноконфессиональный аспект отв редактор, 3024.85kb.
- А. А. Чувакин (редактор), И. В. Огарь (зам. Редактора), Т. В. Чернышова (отв за выпуск),, 2910.4kb.
- Факультет философии и политологии, 13663.08kb.
- Книга памяти. Йошкар-Ола: Map кн изд-во, 1995. 528 с, К53 ил.,, 1691.88kb.
- Центр системных региональных исследований и прогнозирования иппк ргу и испи ран, 3282.27kb.
- М. В. Максимов (отв редактор, г. Иваново), А. П. Козырев (зам отв редактора, г. Москва),, 4733.99kb.
- Программа студенческой научно-практической конференции улан-Удэ 2008, 1483.93kb.
- Редколлегия: Э. П. Кругляков отв редактор, 161.35kb.
- Российская Библиотека Холокоста мы не можем молчать школьники и студенты о Холокосте, 4700.54kb.
- О. Г. Носкова Раздел работа психолога в системе образования и в социальном обслуживании, 10227.59kb.
1.Introduction
Le corpus de traductions présenté ici a été constitué pour extraire et étudier les constructions du type Verbe + Nom de sentiment (N_sent) en français et en russe. Nous nous proposons de dégager une méthodologie générale pour l'étude syntaxique contrastive des N_sent à partir des corpus parallèle alignés (CP).
Nous avançons l’hypothèse que le russe utilise plutôt des verbes (ici des verbes de sentiment) en tant qu’équivalents des constructions verbo-nominales (CVN) françaises [1], tandis que le français a une préférence pour les CVN_sent. Cette hypothèse sera vérifiée grâce au calcul des équivalents des CVN contenant sept N_sent (восхищение – admiration, тревога – angoisse, любовь – amour, гнев – colère, радость - joie, страх – peur) et aussi grâce à l’analyse linguistique de séquences extraites selon le patron syntaxique V+N_sent.
Notre objectif est donc d’étudier le statut du corpus parallèle et son apport à l’analyse contrastive ; ainsi que d’analyser les similitudes et les divergences entre les équivalents fonctionnels français et russes, extraits de ces corpus.
-
Principes méthodologiques et théoriques
Le corpus parallèle est un ensemble de textes originaux d’une langue pris avec leurs traductions dans une autre langue. «A body of texts in one language along with their translations into another is known as a ‘parallel corpus» [6: 62].
Notre corpus littéraire est constitué de 27 romans français traduits en russe et de 15 romans russes traduits en français (84 textes au total). Tous les textes sont écrits par des auteurs du XIXe et du XXe s. Ces textes ne sont pas soumis aux droits d’auteur et sont d’accès libre pour la constitution des corpus. La taille du corpus atteint 10 millions de mots et fournit 1500 occurrences pertinentes qui nous ont servi de base pour l’analyse des CVN et leurs équivalents. Pour constituer le corpus parallèle et aligner les textes, nous avons utilisé le logiciel Alinea [7, 12].
Nous définissons les équivalents fonctionnels de traduction (EF) comme les correspondances sémantiques et grammaticales des unités lexicales (un mot, un groupe de mots ou une phrase) entre la langue source et la langue cible. On trouve chez A. Ludskanov une définition des EF plus exacte : « Les équivalents fonctionnels sont des unités constructives de la traduction, des unités de langue qui remplissent dans le système du contexte les mêmes fonctions que l’unité correspondante de l’original et qui, dans leur ensemble, confèrent à la traduction la même fonctionnalité esthétique et émotionnelle, sur le plan des idées et du contenu que celle de l’original, c.à.d. assurent le transfert de l’information invariante » (Notre traduction du bulgare) [8 : 113]. Dans ce travail, nous étudions les EF des CVN_sent en français et en russe.
Sous le terme de noms de sentiment sont englobés, dans cet article, les noms psychologiques d’affect [11, 5]; les émotions de courte durée (sentiment-émotions : раскаяние - раскаяться) et de longues durée (sentiments stables : испытывать yгрызения совести), [2] ; les noms endogènes (crainte, amour) et exogènes (peur, agacement) spécifiés pour distinguer les sentiments éprouvés par l’expérienceur sans cause extérieure et les sentiments conditionnés par la cause extérieure [3].
3. L’apport du corpus parallèle pour l’analyse contrastive
Pour la linguistique contrastive la constitution des CP (ou de traduction) a ses avantages indéniables. Les CP permettent d’étudier les différences entre les textes sources et leurs traductions et aussi de découvrir les faits de langue qui n’auraient pas été révélées dans les corpus monolingues comparables [10: 972]. Toutefois, on reproche souvent aux corpus de traduction, qui offrent un accès direct aux équivalences, de contenir des traces de la langue source et, du fait de ces artefacts traductionnels, de ne pas être totalement fiables [4: 155 – 156]. Nous essayerons de vérifier ces affirmations sur nos CP à travers l’étude des CVN_sent.
Dans un premier temps, pour vérifier notre hypothèse, nous calculerons le taux de fréquence des CVN_sent françaises par rapport aux verbes distributionnels, aux CVN et aux autres constructions en russe et inversement.
Si l'on compare les données des deux graphiques (Figures 1 et 2), nous pouvons observer les tendances dans les fréquences des CVN dans le corpus français – russe et le corpus russe - français.
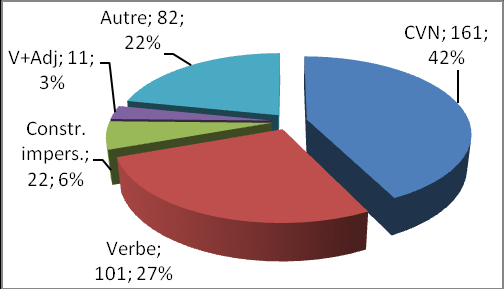
Figure 1 : La répartition des EF des CVN françaises en russe (CP français – russe).
Les chiffres avec le pourcentage signifient le nombre d’occurrences pertinentes à partir desquelles le calcul a été effectué.
Le pourcentage le plus important, à savoir 42% revient aux CVN russes du type дрожать от гнева и страха, питать любовь, замереть от восхищенияь, купаться в радости и счастье. Ainsi, malgré la proportion importante des verbes en russe, à savoir 27% (бояться, любить, злиться, радоваться, восхищаться), ils sont moins nombreux que les CVN, ce qui ne confirme pas notre hypothèse sur la prédominance des verbes de sentiment comme EF des CVN françaises. Le taux des constructions impersonnelles (Cimp) est peu significatif (6%) et renvoie plutôt au champ du N_sent strax (мне страшно, жутко, боязно). La construction Verbe + Adjectif apparaît aussi parmi les EF, quoiqu’elle soit très peu fréquente (3% : быть влюблённым, разгневанным, счастливым). Toutes les constructions libres sont rassemblées dans la catégorie « Autre ».
Les équivalents français des CVN russes sont sensiblement différents, comme le montrent les résultats extraits du corpus parallèle russe - français, représentés sur la figure 2.
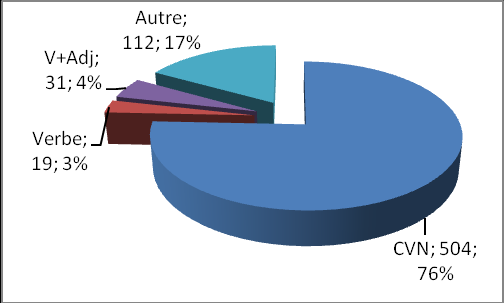
Figure 2 : Les EF des CVN russes en français (CP russe – français)
Le graphique ci-dessus met en évidence que les CVN françaises sont l’EF le plus fréquent des CVN_sent russes. Leur taux s’élève à 76% dans le CP russe – français (éprouver de la joie, être en colère, avoir de l’admiration, avoir peur). Les équivalents verbaux sont très peu fréquents (3%), ainsi que les constructions V+Adj (4%). Nous remarquons que les constructions impersonnelles ne font pas partie des EF français. Ce fait s’explique par la spécificité de la langue russe qui a tendance à utiliser fréquemment des constructions impersonnelles, notamment dans l’expression des sentiments.
Pour rappeler, notre hypothèse avançait l’idée que le russe utilise plutôt les verbes comme équivalents de traduction des CVN françaises. Pourtant, les équivalents verbaux en russe, aussi nombreux, concernent surtout les CVN sources avec les N_sent amour (EF : любить), colère (EF : злиться), peur (EF : бояться). Contrairement à notre hypothèse, nos résultats montrent que le russe utilise plus de CVN. Ces différences peuvent être expliquées par les propriétés particulières de certains N_sent russes (p.ex. l’absence de verbe approprié (le cas de счастье), le choix lexical du traducteur, l’influence de la langue source, la petite taille de nos CP). En revanche, en ce qui concerne les équivalents des CVN russes en français, l’hypothèse se confirme. En effet, les CVN russes sont traduites le plus souvent par les CVN françaises et ceci pour tous les N_sent de notre sélection.