
Московский государственный инженерно-физический институт (технический университет) Факультет Автоматики и электроники И. И. Шагурин, М. О. Мокрецов основы микропроцессорной техники (учебное пособие)
| Вид материала | Учебное пособие |
СодержаниеМикропроцессоры общего назначения |
- Реализация креативной технологии обучения с опорой на невербальное логически структурированное, 19.01kb.
- Новосибирский Государственный Технический Университет. Факультет автоматики и вычислительной, 2544.79kb.
- «Информация», 313.2kb.
- «генотип», 408.58kb.
- Диалектика, 172.21kb.
- Новосибирский Государственный Технический Университет. Факультет автоматики и вычислительной, 1650.9kb.
- Пространство и время, 76.07kb.
- Искусственный интеллект, 12.42kb.
- Московский Государственный Институт Электроники и Математики (Технический Университет), 10.69kb.
- Московский Государственный Институт Электроники и Математики (Технический Университет), 763.07kb.
Рис.1.12. Реализация конвейерного исполнения команд при идеальной (а)
и реальной (б) загрузке 6-ступенчатого конвейера.
Однако такая эффективная работа конвейера обеспечивается только при его равномерной загрузке однотипными командами. Реально отдельные ступени конвейера могут оказаться незагруженными, находясь в состоянии ожидания или простоя. Ожиданием называется состояние исполнительной ступени, когда она не может выполнить требуемую микрооперацию, так как еще не получен необходимый операнд, являющийся результатом выполнения предыдущей команды. Простоем называется состояние ступени, когда она вынуждена пропустить очередной такт, так как поступившая команда не требует выполнения соответствующего этапа. Например, при выполнении безадресных команд не требуется производить формирование адреса и прием операнда (простой на ступенях ФА и ПО конвейера).
На рис.1.12,б показан пример работы 6-ступечатого конвейера при выполнении фрагмента реальной программы, когда отдельные ступени оказываются в состоянии ожидания (ОЖ) или простоя (ПР). Команда INC R2, которая увеличивает на 1 содержимое регистра R2, не требует выборки операндов из памяти и размещения в ней результата. Поэтому при ее выполнении реализуется состояние простоя (ПР) на ступенях конвейера, выполняющих микрооперации ФА, ПО, РР. Команда MOV (R2), R3 производит пересылку содержимого ячейки памяти, адресуемой содержимым регистра R2, в регистр R3. При ее выполнении реализуются состояния ожидания (ОЖ), пока в регистре R2 не будет получен результат предыдущей операции. Такты ожидания (ОЖ) вводятся также при выполнении команды сложения ADD R3, (R4) до получения необходимого значения операнда в регистре R3. В результате введения состояний ожиданий и простоя реальная производительность процессора при выполнении данного фрагмента программы составит 5/3 команд/такт, то-есть будет в 1,7 раз меньше, чем в идеальном случае (рис.1.12,а).
В современных высокопроизводительных микропроцессорах процедура выполнения команд может разбиваться на еще более мелкие этапы, чтобы успеть выполнить соответствующие микрооперации на каждой ступени за один такт, длительность которого при тактовой частоте более 1 ГГц составляет менее наносекунды. Поэтому в таких процессорах число ступеней конвейера достигает 10 и более. Например, в микропроцессорах Pentium 4 используется 20-ступенчатый конвейер.
Эффективность использования конвейера определяется типом поступающих команд. При поступлении однородных команд обеспечивает сокращение числа состояний простоя и ожидания в процессе их выполнения, в результате чего повышается производительность процессора. При использовании в программе разноформатных команд, содержащих различное количество байтов, число состояний простоя и ожидания, которые приходится вводить в процессе выполнения команд, значительно увеличивается. Поэтому принятый во многих RISC-процессорах стандартный 4-байтный формат команд обеспечивает существенное сокращение числа ожиданий и простоев конвейера, что позволяет значительно повысить производительность.
Другой причиной снижения эффективности конвейера являются команды условного ветвления. Если выполняется условие ветвления, то приходится производить перезагрузку конвейера командами из другой ветви программы, что требует выполнения дополнительных рабочих тактов и вызывает значительное снижение производительности. Поэтому одним из основных условий эффективной работы конвейера является сокращение числа его перезагрузок при выполнении условных переходов. Эта цель достигается с помощью реализации различных механизмов предсказания направления ветвления, которые обеспечиваются с помощью специальных устройств - блоков предсказания ветвления, вводимых в структуру процессора.
В современных микропроцессорах используются разнообразные способы предсказания ветвлений. Наиболее простой способ состоит в том, что процессор фиксирует результат выполнения предыдущих команд ветвления по данному адресу, и считает, что следующая команда с обращением по этому адресу даст аналогичный результат. Данный способ предсказания предполагает более высокую вероятность повторного обращения к определенной команде, задаваемой данным условием ветвления. Для реализации этого способа предсказания ветвления используется специальная память BTB (Branch Target Buffer), где хранятся адреса ранее выполненных условных переходов. При поступлении аналогичной команды ветвления предсказывается переход к ветви, которая была выбрана в предыдущем случае, и производится загрузка в конвейер команд из соответствующей ветви. При правильном предсказании не требуется перезагрузка конвейера, и эффективность его использования не снижается. Эффективность такого способа предсказания зависит от емкости BTB и оказывается достаточно высокой: вероятность правильного предсказания составляет 80% и более. Повышение точности предсказания достигается при использовании более сложных способов, когда хранится и анализируется предистория переходов – результаты нескольких предыдущих команд ветвления по данному адресу. В этом случае возможно определение чаще всего реализуемого направления ветвления, а также выявление чередующихся переходов. Реализация таких алгоритмов требует использования более сложных блоков предсказания, но при этом вероятность правильного предсказания повышается до 90-95 %.
Возможность повышения производительности процессора достигается также при введении в структуру процессора нескольких параллельно включенных операционных устройств, обеспечивающих одновременное выполнение нескольких операций. Такая структура процессора называется суперскалярной. В этих процессорах реализуется параллельная работа нескольких исполнительных конвейеров, в каждый из которых поступает для выполнения одна из выбранных и декодированных команд. В идеальном случае число одновременно выполняемых команд равно числу операционных устройств, включенных в исполнительные конвейеры. Однако при выполнении реальных программ трудно обеспечить полную загрузку всех исполнительных конвейеров, поэтому на практике эффективность использования суперскалярной структуры оказывается несколько ниже. Современные суперскалярные процессоры содержат до 4 до 10 различных операционных устройств, параллельная работа которых обеспечивает выполнение за один такт в среднем от 2 до 6 команд.
Эффективная одновременная работа нескольких исполнительных конвейеров обеспечивается путем предварительной выборки-декодирования ряда команд и выделения из них группы команд, которые могут выполняться одновременно. В современных суперскалярных процессорах производится выборка нескольких десятков команд, которые декодируются, анализируются и группируются для параллельной загрузки в исполнительные конвейеры. Обычно в процессорах имеется несколько устройств для выполнения целочисленных операций, одно или несколько устройств для обработки чисел с плавающей точкой, отдельные устройства для обработки специальных форматов видео- и аудиоданных. Параллельно работают также устройства формирования адресов и выборки операндов для загружаемых команд. При этом обычно реализуется спекулятивная (предварительная) выборка операндов, чтобы для поступающих на исполнение команд уже были готовы операнды, которые записываются в специальные регистры. Чтобы обеспечить возможно полную загрузку исполнительных конвейеров, в процессе анализа и группировки декодированных команд возможно изменение порядка их следования. В результате команды выполняются не в порядке их выборки из памяти, а по мере готовности необходимых операндов и исполнительных устройств. Таким образом позже поступившие команды могут быть выполнены до ранее выбранных. Чтобы запись в память результатов происходила в соответствии с исходной последовательностью поступления команд программы, на выходе данных включается специальная буферная память, восстанавливающая порядок выдачи результатов согласно выполняемой программе.
Одновременное параллельное выполнение команд может оказаться невозможным, если они обращаются к одному регистру. При ограниченной емкости РЗУ процессора такие случаи могут возникать достаточно часто, что снижает эффективность работы исполнительных конвейеров. Поэтому в ряде процессоров вводятся специальные регистровые блоки, дублирующие РЗУ. При поступлении команд, которые обращаются к одинаковым регистрам РЗУ, производится их переадресация к дублирующим регистровым блокам – «переименование» регистров. В результате обеспечивается возможность одновременного выполнения таких команд, что позволяет реализовать более эффективную параллельную работу исполнительных конвейеров.
В качестве примера на рис. 1.13 показана типичная суперскалярная структура процессора с Гарвардской архитектурой, которая реализована в высокопроизводительных 32-разрядных микропроцессорах семейства PowerPC, выпускаемых компаниями Motorola и IBM. Гарвардская архитектура обеспечивается разделением потоков команд и данных во внутренней структуре процессора путем использования отдельных блоков кэш-памяти IC (кэш команд) и DC (кэш данных). Каждая кэш-память имеет отдельный блок управления MMU (Memory Managment Unit).
В процессоре реализуется 6-ступенчатый конвейер выполнения команд. Устройство управления содержит три первых ступени конвейера, реализующих выборку, декодирование и распределение команд по параллельно работающим исполнительным устройствам.
Шина результатов

BPU
Кэш команд
IC (16 Кбайт)
IMMU

Команды
Адрес
BIU


IU
Блок GPR
32х32 бит
Буфер GPR
12x32 бит

LSU
Блок FPR
32х64 бит
Буфер FPR
8x64 бит


FPU

4. Выполнение команд




5. Буфер результатов
6. Обратная запись









Кэш данных
DC (16 Кайт)
DMMU




Данные
Адрес
A 31-0
D 63-0

Cxx
.
.
.

Контроллер шины

Устройство управления
1. Выборка
команды


2. Декодирование
3. Распределение
команд

Блок
завершения
Рис.1.13. Типичная суперскалярная структура процессора
с Гарвардской внутренней архитектурой
Команды условных ветвлений поступают на выполнение в блок предсказания ветвлений BPU (Branch Prediction Unit), который обеспечивает загрузку в конвейер следующих команд в соответствии с наиболее вероятным направлением хода программы.
Исполнительные устройства сгрупированы в два блока. Блок целочисленных операций содержит два исполнительных устройства - SIU1 и SIU2 (Single Instruction Unit) для простых операций, выполняемых за один такт, и одно устройство для выполнения сложных операций MIU (Multiple Instruction Unit), которые занимают несколько тактов. Эти устройства обслуживаются блоком из 32 регистров общего назначения GPR (General Purpose Registers). Блок FPU (Floating Point Unit) выполняет операции с плавающей точкой за несколько тактов. Он обслуживается отдельным блоком из 32 регистров FPR (Floating Point Registers), которые имеют по 64 разряда. Каждый из регистровых блоков имеет набор дублирующих регистров (буферы GPR и FPR), которые обеспечивают возможность «переименования» регистров в случае их одновременного использования несколькими командами, находящимися на стадии исполнения. Блок LSU (Load – Store Unit) производит операции загрузки регистров из памяти и записи содержимого регистров в память.
После выполнения операций полученные результаты поступают в блок завершения, где они накапливаются в специальной буферной памяти, а затем записываются в кэш данных или основную память в соответствии с исходной последовательностью команд программы (процедура обратной записи, восстанавливающая нормальную последовательность выдачи результатов). Контроллер шины BIU (Bus Interface Unit) обеспечивает обращение к системной шине, которая содержит 32-разрядную шину адреса A31-0, 64-разрядную шину данных D63-0 и линии для передачи различных управляющих сигналов Cxx.
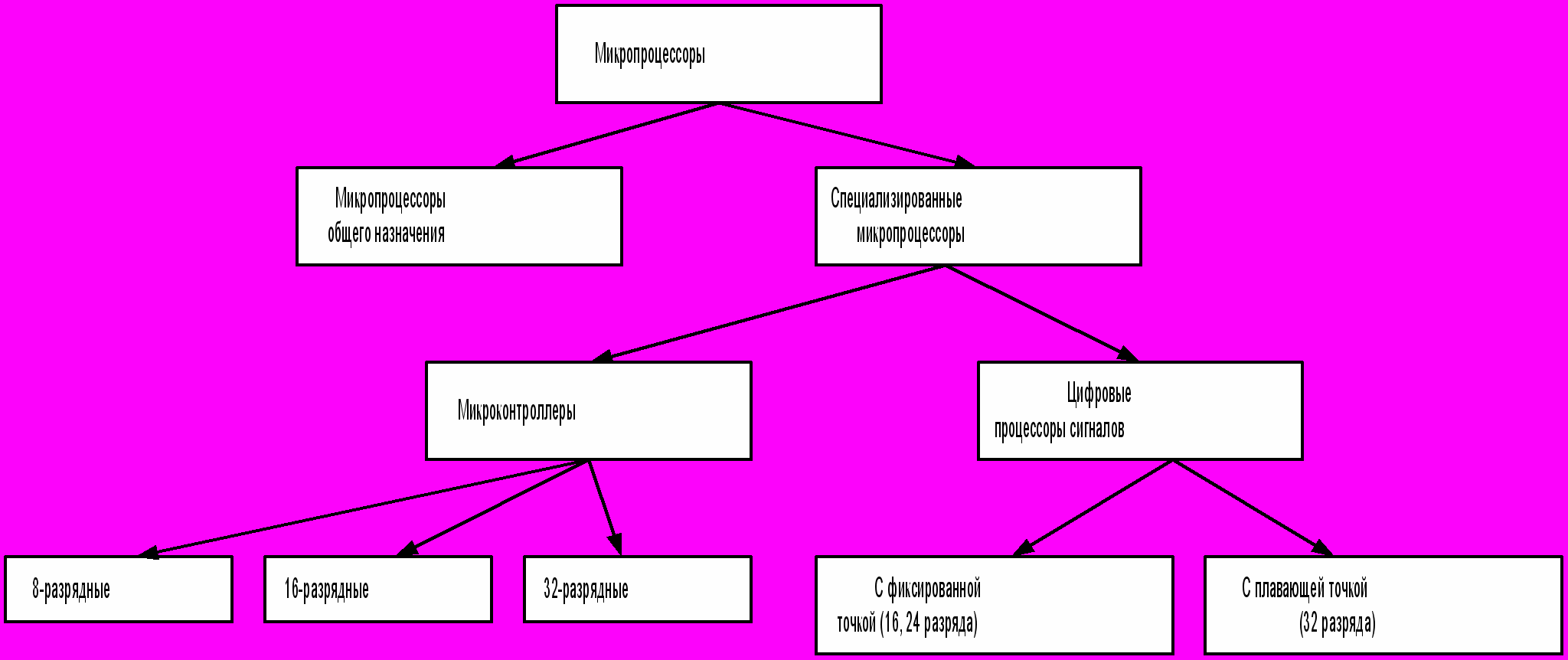
Рис. 1.14. Классификация современных микропроцессоров
по функциональному признаку.
Хотя микропроцессор является универсальным средством для цифровой обработки информации, однако отдельные области применения требуют реализации определенных специфических вариантов их структуры и архитектуры. Поэтому по функциональному признаку выделяются два класса: микропроцессоры общего назначения и специализированные микропроцессоры (рис.1.14). Среди специализированных микропроцессоров наиболее широкое распространение получили микроконтроллеры, предназначенные для выполнения функций управления различными объектами, и цифровые процессоры сигналов (DSP – Digital Signal Processor), которые ориентированы на реализацию процедур, обеспечивающих необходимое преобразование аналоговых сигналов, представленных в цифровой форме.
Микропроцессоры общего назначения предназначены для решения широкого круга задач обработки разнообразной информации. Их основной областью использования являются персональные компьютеры, рабочие станции, серверы и другие цифровые системы массового применения. К этому классу относятся CISC-процессоры Pentium компании Intel, K7 компании Advanced MicroDevices (AMD), 680x0 компании Motorola, RISC-процессоры PowerPC, выпускаемые компаниями Motorola и IBM, SPARC компании Sun Microsystems и ряд других изделий различных производителей.
Расширение области применения таких микропроцессоров достигается, главным образом, путем роста производительности, благодаря чему увеличивается круг задач, который можно решать с их использованием. Поэтому повышение производительности является магистральным направлением развития этого класса микропроцессоров. Обычно это 32-разрядные микропроцессоры (некоторые микропроцессоры этого класса имеют 64-разрядную или 128-разрядную структуру), которые изготавливаются по самой современной промышленной технологии, обеспечивающей максимальную частоту функционирования.
Ряд наиболее популярных микропроцессоров этого класса (Pentium, AMD K7 и некоторые другие) следует отнести к CISC-процессорам, так как они выполняют большой набор разноформатных команд с использованием многочисленных способов адресации. Однако в их внутренней структуре содержится RISC-процессор, который выполняет поступившие команды после их преобразования в последовательность простых RISC-операций. Ряд других микропроцессоров этого класса непосредственно реализует RISC-архитектуру. Поэтому можно считать, что использование RISC-архитектуры характерно для большинства этих микропроцессоров. Однако в ряде последних разработок (Itanium, PA8500) некоторых ведущих производителей успешно применяются принципы VLIW-архитектуры, которая может составить конкуренцию RISC-архитектуре в соревновании за достижение наивысшей производительности.
Практически все современные микропроцессоры этого класса используют Гарвардскую внутреннюю архитектуру, где разделение потоков команд и данных реализуется с помощью отдельных блоков кэш-памяти (рис.1.13). В большинстве случаев они имеют суперскалярную структуру с несколькими исполнительными конвейерами (до 10 в современных моделях), которые содержат до 20 ступеней.
Благодаря своей универсальности микропроцессоры общего назначения используются также в специализированых системах, где требуется высокая производительность. На их основе реализуются одноплатные компьютеры и промышленные компьютеры, которые применяются в системах управления различными объектами. Одноплатные (встраиваемые) компьютеры содержат на плате необходимые дополнительные микросхемы, обеспечивающие их специализированное применение, и предназначены для встраивания в аппаратуру различного назначения. Промышленные компьютеры размещаются в корпусах специальной конструкции, обеспечивающих их надежную работу в жестких производственных условиях. Обычно такие компьютеры работают без стандартных периферийных устройств (монитор, клавиатура, “мышь”) или используют специальные варианты этих устройств, модифицированные с учетом специфических условий применения.
Микроконтроллеры являются специализированными микропроцессорами, которые ориентированы на реализацию устройств управления, встраиваемых в разнообразную аппаратуру. Ввиду огромного количества объектов, управление которыми обеспечивается с помощью микроконтроллеров, годовой объем их выпуска превышает 2 миллиарда экземпляров, на порядок превосходя объем выпуска микропроцессоров общего применения. Весьма широкой является также номенклатура выпускаемых микроконтроллеров, которая содержит несколько тысяч типов.
Характерной особенностью структуры микроконтроллеров является размещение на одном кристалле с центральным процессором внутренней памяти и большого набора периферийных устройств. В состав периферийных устройств обычно входят несколько 8-разрядных параллельных портов ввода-вывода данных (от 1 до 8), один или два последовательных порта, таймерный блок, аналого-цифровой преобразователь. Кроме того различные типы микроконтроллеров содержат дополнительные специализированные устройства – блок формирования сигналов с широтно-импульсной модуляцией, контроллер жидко-кристаллического дисплея и ряд других. Благодаря использованию внутренней памяти и периферийных устройств реализуемые на базе микроконтроллеров системы управления содержат минимальное количество дополнительных компонентов.
В связи с широким диапазоном решаемых задач управления требования, предъявляемые к производительности процессора, объему внутренней памяти команд и данных, набору необходимых периферийных устройств, оказываются весьма разнообразными. Для удовлетворения запросов потребителей выпускается большая номенклатура микроконтроллеров, которые принято подразделять на 8-, 16- и 32-разрядные.