
Зосимова Ирина Викторовна построение системы понятий для оценки деятельности операторов связи магистерская диссертация
| Вид материала | Диссертация |
| 1.2 Вывод по прецедентам 1.3 Извлечение данных. Методология CRISP-DM |
- Магистерская программа «Государственные и муниципальные финансы» Кафедра государственного, 867.91kb.
- Программа дисциплины Современные технологии pr для направления 030201. 65 Политология,, 95.26kb.
- Федеральная служба по надзору в сфере образования и науки сборник «Построение Общероссийской, 1565.91kb.
- Приглашаем принять участие в отраслевой электротехнической конференции системы гарантированного, 33.18kb.
- Задание модели системы в пространстве состояний, построение оптимального наблюдателя, 14.7kb.
- Магистерская программа Прикладная экономика Кафедра магистерская диссертация роль лизинга, 822.73kb.
- «Методы геолого-экономической оценки месторождений нефти и газа», 93.21kb.
- Слезко Ирина Викторовна. Математический анализ учебно-методический комплекс, 1104.84kb.
- Название: Магистерская диссертация. Методика написания, правила оформления и процедура, 1519.29kb.
- Мониторинга оценки качества образования в гимназии, 163.07kb.
1.2 Вывод по прецедентам
Создание удачной (то есть, с одной стороны, адекватно описывающей практические проблемы, с другой стороны, допускающей надлежащий обсчет) математической модели для плохо формализованной прикладной сферы практически невозможно. В качестве замены адекватной математической модели чаще всего приходится использовать массивы прецедентов, то есть пары вида “входная информация – выходная информация”. [1]
Моделирование подхода к решению проблем, основанного на опыте прошлых ситуаций, привело к появлению технологии логического вывода, основанного на прецедентах (по-английски – Case-Based Reasoning, или CBR), и в дальнейшем – к созданию программных продуктов, реализующих эту технологию. [2]
Кроме того, происходило накопление примеров удачно решенных практических задач и соответствующих алгоритмов. Появились группы ученых, накопившие опыт решения прикладных задач и использовавшие для разных задач близкие по структуре алгоритмы. Произошел переход от принципа “прикладная задача – алгоритм”, к принципу “семейство алгоритмов – прикладная задача”.
Вывод на основе прецедентов – это метод принятия решений, в котором используются знания о предыдущих ситуациях или случаях (прецедентах). При рассмотрении новой проблемы (текущего случая) отыскивается похожий прецедент в качестве аналога. Вместо того, чтобы искать решение каждый раз сначала, можно пытаться использовать решение, принятое в сходной ситуации, возможно, адаптировав его к изменившейся ситуации текущего случая. После того, как текущий случай будет обработан, он вносится в базу прецедентов вместе со своим решением для его возможного последующего использования в будущем.
Прецедент включает в себя:
Описание проблемы,
Решение этой проблемы,
Результат (обоснованность) применения решения.
Например, если цель состоит в диагностике заболеваний и выборе лечения, то описательная информация должна содержать симптомы больного, результаты лабораторных исследований, хронология состояния больного, сведения о возможной аллергической реакции на те или иные лекарственные средства и т. д.
В нашем случае, для каждого оператора связи строится профиль его поведения, на основании этого профиля делаются предположения о тех или иных случаях мошенничества. Затем эти предположения проверяются с привлечением фонового знания (иными словами, знания о предметной области, domain knowledge): справочной информации, условий межоператорских соглашений и т.д. Описание прецедента заносится в базу с указанием о том, подтвердилось ли предположение или нет. Когда другой оператор начинает действовать на этой территории, также строится профиль его поведения, затем этот профиль сравнивается с профилями, уже занесенными в базу - в случае совпадения автоматически генерируется предупреждение о возможной утечке дохода.
При анализе поведения абонентов довольно часто используется алгоритм построения профиля, с последующим делением абонентов на группы и поиска абонентов, чье поведение сильно отличается от поведения группы (см. п. 1.4). При таком анализе используются либо теоретико-вероятностные методы, либо более сложные методы извлечения данных (Data mining). При анализе поведения операторов мною также были использованы методы извлечения данных.
1.3 Извлечение данных. Методология CRISP-DM
Для кластеризации базы прецедентов и определения степени близости между прецедентами использовались методы извлечения данных.
Решение задач телекоммуникации - стандартная область приложения аналитических методов. Именно с зарождением телефонии в начале прошлого века связано развитие многих теоретико-вероятностных методов (теории массового обслуживания, надежности, случайных процессов специального вида) [7].
Феллер, например, в своей знаменитой книге “Введение в теорию вероятностей и ее приложения” [8] приводил много примеров, связанных с проводной связью: задача о телефонных линиях (сколько должно быть телефонных линий между станциями А и B, если они обслуживают N абонентов, и лишь один из сотни вызовов может быть неуспешен), задача о времени ожидания вызова, распределение телефонных соединений с неправильным номером.
Но методы математической статистики оказываются главным образом полезными для проверки заранее сформулированных гипотез, тогда как часто основной и самой трудоемкой задачей является именно определение гипотезы. Таким образом, от вероятностных методов анализа событий состоялся переход к более сложным методам, объединенным под общим названием Data Mining, что можно перевести как ”извлечение информации” или “добыча данных”. Нередко встречается термин "обнаружение знаний в базах данных" (Knowledge Discovery in Databases). Цель такого извлечения информации состоит в выявлении скрытых правил и закономерностей в наборах данных. Вот только некоторые методы, причисляемые к Data Mining: ассоциация (объединение), классификация, кластеризация, анализ временных рядов и прогнозирование, нейронные сети [9].
Data Mining наиболее эффективен в том случае, когда осуществляется спланированным и систематическим образом. Для правильного планирования процесса “извлечения данных” необходимо ответить на следующие вопросы:
- Какую проблему вы хотели бы решить?
- Какие источники данных доступны, и какие фрагменты этих данных относятся к рассматриваемой проблеме?
- Какие предварительные преобразования необходимо провести до начала процесса data mining?
- Какую технику data mining вы будете использовать?
- Как будут оцениваться результаты data mining?
- Как можно максимально использовать информацию, полученную при помощи data mining?
Для обеспечения качества процесса data mining можно воспользоваться подробной моделью данного процесса.
Модель стандартного межотраслевого процесса для Data Mining (Cross Industry Standard Process for Data Mining, CRISP-DM) носит общий характер и может применяться в различных сферах бизнеса для решения самых различных проблем. Общая модель состоит из шести этапов. Эти шесть этапов объединяются в циклическом процессе (см. рис.3).
- Понимание бизнеса. Возможно, это наиболее важный этап data mining. Этап понимания бизнеса включает в себя определение целей, оценку ситуации, определение целей data mining и создание плана проекта.
- Понимание данных. Данные представляют собой “сырой материал” для data mining. Данный этап посвящен рассмотрению существующих данных и их характеристик. Он включает в себя сбор исходных данных, описание данных, исследование данных и проверку их качества.
- Подготовка данных. После ознакомления с имеющимися данными, необходимо подготовить данные к процессу data mining. Подготовка включает в себя отбор, чистку, преобазование, объединение и форматирование данных.
- Моделирование. Это наиболее сложный этап data mining, на котором для получения информации из данных используются сложные аналитические методы. Данный этап включает в себя выбор техник моделирования, создание плана анализа, постороение и оценку моделей.
- Оценка. После построения моделей возникает необходимость оценить, насколько результаты data mining будут полезны в достижении целей. Данный этап включает в себя оценку результатов, обзор процесса data mining и определение последующего плана действий.
- Внедрение. После того, как было затрачено большое количество усилий, наступает время применения результатов. Данный этап посвящен вопросам интегрирования полученного знания в Бизнес-процессы для того, чтобы решить исходную бизнес-проблему. Он включает в себя планирование внедрения, мониторинг и поддержку, создание окончательного отчета и обзор всего проекта.
В описанной модели есть несколько ключевых моментов. Прежде всего, несмотря на существование общей тенденции выполнения этапов проектов в описанном выше порядке, возможны ситуации, когда этапы проектов соотносятся друг с другом не так, как это описывается в модели. К примеру, обычно этап подготовки данных предшествует этапу моделирования. Однако принятые решения и информация, полученная в процессе этапа моделирования, часто вынуждает нас повторно задуматься об этапе подготовке данных, что может, в свою очередь, привести к новым моделям и т.д. Обмен с помощью обратной связи идет между двумя этими этапами до тех пор, пока для обоих этапов не будет найдено удовлетворительное решение. Сходным образом, на основе результатов, полученных на этапе оценки, вы можете снова перейти к этапу понимания бизнеса и прийти к выводу, что вы пытались ответить на неправильно сформулированный вопрос. Вследствие этого, вы можете изменить свое понимание бизнеса и снова повторить все остальные этапы, лучше понимая, каких результатов вы хотите добиться.
Вторым ключевым моментом является итеративный характер data mining. Редко бывает так, что вам достаточно будет спланировать проект data mining, выполнить его, обобщить полученные результаты и завершить на этом работу. Использование data mining представляет собой непрекращающийся процесс. Знание, полученное в течение одного цикла data mining, обязательно приведет к постановке новых вопросов и задач. Эти новые вопросы и возможности приведут к необходимости снова повторить процесс data mining.
Методы добычи данных могут использоваться в системах вывода по прецедентам:
- для вычисления степени близости между прецедентами (одним из таких способов является разбиение прецедентов на классы эквивалентности, когда близкими текущему случаю считаются прецеденты того же класса),
- для получения дополнительных знаний из базы прецедентов, что позволяет, например, выявлять значимость признаков и заполнять отсутствующие признаки,
- при адаптации решения,
- и даже при добавлении прецедентов (добыча данных может помочь найти дополнительные знания в базе данных и представить это как сконструированный прецедент).
В нашем случае, методы добычи данных будут использоваться при вычислении степени близости между прецедентами и разбиении прецедентов на классы эквивалентности: операторы связи буду разделены на группы с применением кластерного анализа на основании их профилей.
Кроме того, процесс извлечения данных будет разбит на этапы и описан в соответствии с методологией CRISP-DM.
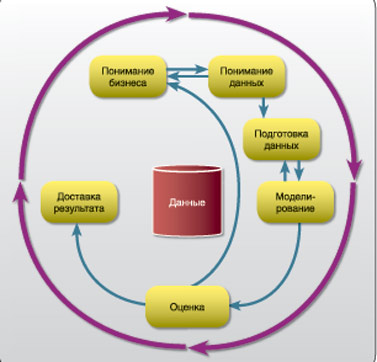
Рис.3 Методология CRISP-DM