
Н. В. Берёза алгоритм принятия решения выбора рыночной стратегии для субъектов рынка Информационных услуг
| Вид материала | Документы |
- План введение 2 раздел 1 анализ рынка услуг по доставке грузов 4 Характеристика транспортных, 1451.06kb.
- Тема задачи и функции управления инновациями, 402.97kb.
- Рабочей программы дисциплины Рынок информационных продуктов и услуг (наименование), 28.71kb.
- Электронное научное издание «Труды мгта: электронный журнал», 106.8kb.
- Задачи для самостоятельной работы Алгоритм принятия решения о выборе критерия для сопоставлений, 1082.7kb.
- Рабочая программа дисциплины «Алгоритм принятия уголовно-процессуальных решений» Направление, 292.56kb.
- Алгоритм оценки нематериального фактора при расчете roi на примере ip-телефонии, 48.92kb.
- Задачи: познакомить школьников с этапами принятия решения в вопросе выбора профессии;, 361.96kb.
- Комплекс маркетинга (маркетинг мix). Общая характеристика. Сущность продуктовой стратегии, 25.14kb.
- Сигментация рынка и позиционирование товара. Выбор рыночной стратегии сбыта, 380.26kb.
Этап 5. Составление альтернативных многопродуктовых программ. На основании полученных данных субъектом составляется один или несколько вариантов продуктовой программы. При этом основными критериями могут служить: прибыльность деятельности (желаемый уровень рентабельности, уровень затрат не выше допустимого, период окупаемости), хорошие маркетинговые показатели (востребованность услуги и наличие перспектив, возможность оказания смежных услуг, лидирующее положение на рынке) или иные в зависимости от целей субъекта.
В данной работе будем рассматривать в качестве критерия некоторый желаемый уровень рентабельности, в этом случае нужно определиться с составом и структурой услуг и рассчитать возможные затраты и прибыль по каждому из планируемых видов услуг. В 3 предлагается методика оценки портфеля НИОКР на основе рентабельности портфеля:
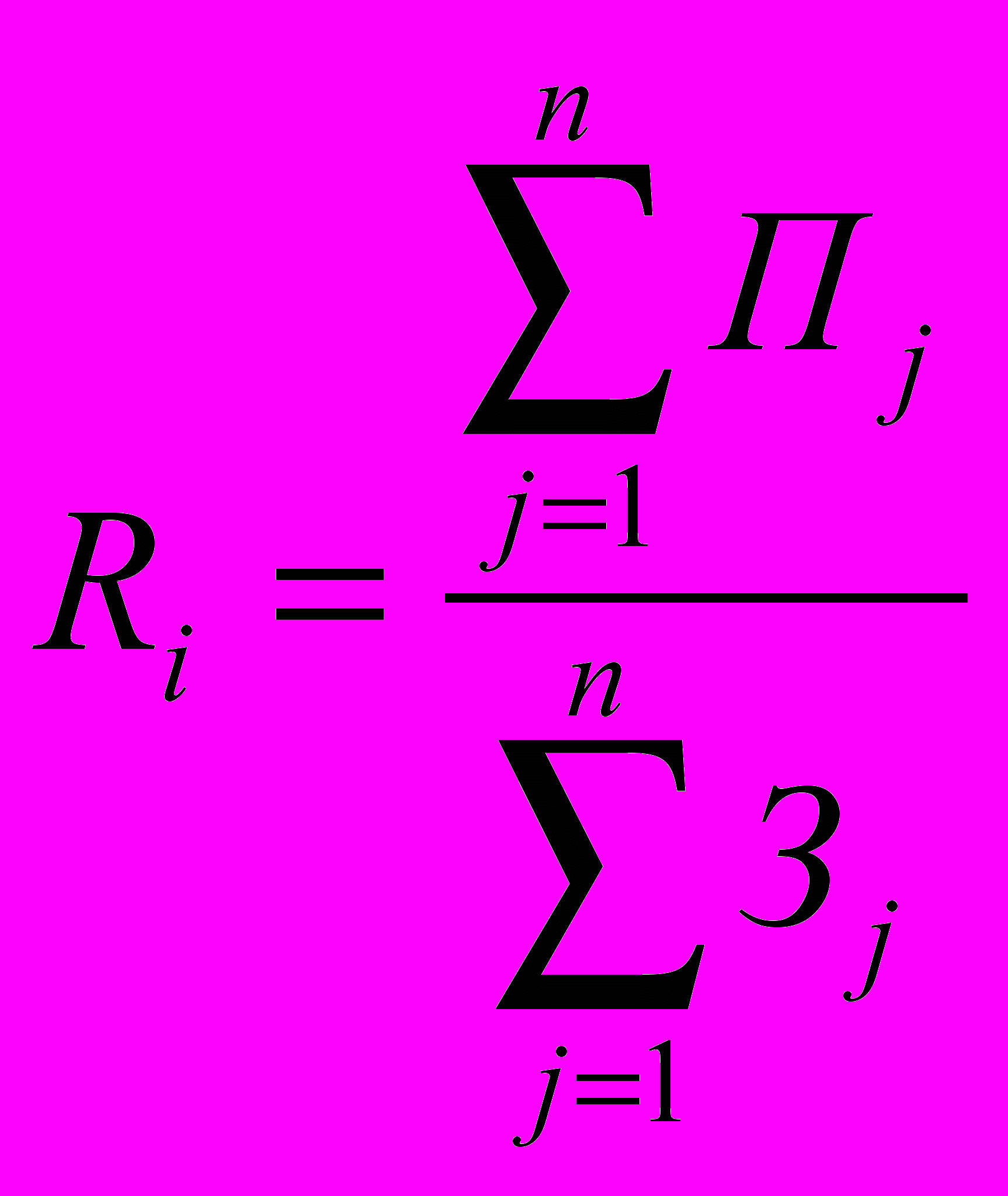 ,
,где Ri − средняя рентабельность i-го портфеля, Пj – прибыль по j-му виду услуг, Зj – затраты по j-му виду услуг. Подобную методику можно использовать и в данном случае. На основании полученной рентабельности портфелей и желаемого уровня рентабельности принимаем или отклоняем бизнес-портфель.
Если уровень Ri больше или равен желаемому, то принимаем портфель, в противном случае отклоняем или корректируем состав и структуру услуг до достижения желаемого результата.
Этап 6. Анализ устойчивости (чувствительности) подразумевает создание сигнальных механизмов с целью повышения гибкости и адаптивности системы и определения границ саморегулируемости системы. В том случае, если система соответствует выбранным критериям устойчивости, то алгоритм завершен, в противном случае производится корректировка программы (возврат на этап 4) до получения удовлетворительного результата.
Этап 7. Конец.
Выводы
В работе представлена модель системы поддержки принятия решения на основе нечётких множеств, нечёткого вывода и экспертных систем. Применение данной системы позволит повысить качество и обоснованность принимаемых решений субъектов малого бизнеса при выборе состава услуг с учетов трех основных параметров – финансового состояния, индекса информатизации и этапа жизненного цикла услуги. Это сделает возможным в будущем создание программного продукта для принятия решений и выбора стратегии управления бизнесом для субъектов информационного рынка на базе описанной модели.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
- Measuring the Information Society – The ICT Development Index, 2010 ITU International Telecommunication Union, Place des Nations CH-1211 Geneva, Switzerland
- Measuring the Information Society – The ICT Development Index, 2009 ITU International Telecommunication Union, Place des Nations CH-1211 Geneva, Switzerland
- С.Д. Ильенкова, Л. М. Гохберг, С. Ю. Ягудин и др. / Под ред. проф. С. Д. Ильенковой. Инновационный менеджмент: Учебник для вузов. 2-е изд., перераб. и доп. – М.: ЮНИТИ-ДАНА, 2003. – 343 с.
- Берёза Н.В. Процесс принятия решения о выборе рыночной стратегии и состава оказываемых услуг для субъектов информационного рынка // Вестник Адыгейского государственного университета. – 2011. − № 2г.
- Грушенко В.И. Стратегия управления бизнесом. От теории к практической разработке и реализации: монография / В.И. Грушенко. – М.: ЮНИТИ-ДАНА: Закон и право, 2010. – 295 с.
- Сильнова С.В., Полюдова Г.Р., Пузырникова Е.А. Поддержка принятия решений при управлении предприятием на основе нечетких моделей // Вестник компьютерных и информационных технологий. – 2009. − № 11. – С. 33-41.
- Ефремов В.С. Классические модели стратегического анализа и планирования: модель HOFER/SCHENDEL Электронный ресурс. − Режим доступа http://www.intalev.ru/index.php?id=3973 (дата обращения − 26.04.2011г.)
- Халов Е.А. Систематический обзор чётких одномерных функций принадлежности интеллектуальных систем // Информационные технологии и вычислительные системы. – 2009. − № 3. − С. 60-74.
- Недосекин А.О., Максимов О.Б. Новый комплексный показатель оценки финансового состояния предприятия Электронный ресурс // Консультационная группа «Воронов и Максимов». − Режим доступа http://www.vmgroup.ru/publications/public4.htm(дата обращения - 26.04.2011г.)
Берёза Наталья Викторовна
Южно-Российский государственный университет экономики и сервиса.
346500, г. Шахты, Ростовской области, ул. Шевченко,147
Е-mail: nvbereza@bk.ru.
Тел.: 89281794421.
Bereza Natalya Viktorovna
The South Russia State University of Economics and Service.
147, Shevchenko street, Shakhty, Rostov region, The Russian Federation, 346500.
Е-mail: nvbereza@bk.ru.
Phone: +79281794421.
УДК 681.3.016
О.С. Коваленко
Обзор состояний, проблем и перспектив хранения и Анализа данных в «облаке»
В статье осуществлен обзор состояний, проблем и перспектив облачного хранения данных. Рассмотрены возможности и методы применения интеллектуального анализа данных в облачных хранилищах данных. Описываются преимущества и недостатки облачного хранения данных, а также преимущества и недостатки аналитики как сервиса.
База данных; хранилище данных; облачное хранилище данных; интеллектуальный анализ данных.
O.S. Kovalenko
review of states, problems and aspects about data warehouse and data mining in cloud
The article reviewed states, problems and aspects about cloud filing. It was considered the scope and methods of application for Data Mining in cloudy Data Warehouses. Advantages and disadvantages of cloudy Data Warehouses and BIaas were analyzed.
Key words: database; data warehouse; cloud data warehouse; Data Mining; BI.
Введение
В конце 2008 года четыре крупнейшие интернет-корпорации – Microsoft, Google, IBM и Apple – практически синхронно объявили о намерениях запустить в 2009 году сервисы, предназначенные для хранения больших объемов пользовательских данных. Предполагалось, что это будут не просто хранилища, но одновременно будет обеспечена их интеграция и с другими сервисами [1,2].
Облачное хранилище данных – модель онлайн-хранилища, в котором данные хранятся на многочисленных, распределённых в сети серверах, предоставляемых в пользование клиентам, в основном третьей стороной. В противовес модели хранения данных на собственных, выделенных серверах, приобретаемых или арендуемых специально для подобных целей, количество или какая-либо внутренняя структура серверов клиенту, в общем случае, не видна. Данные хранятся, а равно и обрабатываются, в облаке, которое представляет собой, с точки зрения клиента, один большой, виртуальный сервер. Физически такие сервера могут располагаться весьма удалённо друг от друга географически, вплоть до расположения на разных континентах [3].
Облачное хранение данных
Облачное хранение данных сегодня предлагает целый ряд компаний, среди которых Box.net, Live Mesh, JungleDisk, DropBox, SkyDrive [4]. Некоторые из них предлагают не просто хранить данные, но также синхронизировать папки и файлы между несколькими устройствами. В [4] проводится аналогия между данными, хранящиеся в «облаках» и деньгами, хранящимися на банковских счетах.
Сервисы хранения данных демонстрируют многообразие преобразований архитектур управления данными, а на горизонте видно еще больше новых архитектур. Специалисты предвидят, что многие будущие приложения, ориентированные на обработку данных, будут опираться на облачные сервисы данных [5].
Общей проблемой провайдеров облачных сервисов является потребность в компромиссе между функциональными возможностями и эксплуатационными расходами. В сегодняшних начальных сервисах данных обеспечиваются API, намного более ограниченные, чем в традиционных системах баз данных, с минималистским языком запросов и ограниченными гарантиями согласованности. Это затрудняет программирование приложений, но позволяет провайдерам облачных сервисов создавать более предсказуемые службы, в которых обеспечиваются соглашения об уровне обслуживания, трудно достижимые для полнофункциональных сервисов данных на основе языка SQL. Потребуется дополнительная работа и накопление опыта в нескольких направлениях для исследования непрерывного спектра подходов между ранними облачными сервисами данных и более развитыми с функциональной точки зрения, но, возможно, менее предсказуемыми альтернативами [5].
В облачных средах особенно важным качеством является управляемость. По сравнению с традиционными системами, достижение высокого уровня управляемости в облачных средах осложняется тремя факторами: ограниченным человеческим вмешательством, значительным разбросом диапазона рабочих нагрузок и разнообразием совместно используемых инфраструктур. В подавляющем большинстве случаев будут отсутствовать администраторы баз данных или систем, которые могли бы помочь разработчикам при создании приложений, основанных на облачных сервисах; администрирование платформ должно будет в основном производиться в автоматическом режиме. Системы всегда трудно настраивать при наличии смешанных рабочих нагрузок, которые в данном контексте, по-видимому, будут неизбежно возникать. Со временем может значительно изменяться рабочая нагрузка даже у одного и того же потребителя: эластичное обеспечение облачных услуг делает эти сервисы экономически целесообразными для пользователей, которым в короткие промежутки работы может потребоваться значительно больше ресурсов, чем обычно. При этом возможности настройки сервисов зависят от способа «виртуализации» совместно используемой инфраструктуры. Например, в Amazon EC2 для обеспечения программного интерфейса используются виртуальные машины аппаратного уровня. На другом конце спектра в salesforce.com реализуется хостинг с несколькими арендаторами одного ресурса («multi-tenant» hosting), когда с использованием одной СУБД поддерживается много независимых схем баз данных. Возможны и многие другие решения по виртуализации. В каждом из этих решений обеспечивается свой подход к контролю поддерживаемых рабочих нагрузок и используемых платформ. При наличии этих вариантов потребуется пересмотреть традиционные роли и распределение ответственности для многоуровневого управления ресурсами [5].
Потребность в управляемости делает более срочной разработку технологий самоуправления баз данных, которые исследовались в последнее десятилетие. Для обеспечения жизнеспособности этих систем потребуются адаптивные онлайновые методы, хотя наличие новых архитектур и API (включая гибкость, позволяющую отойти от традиционной семантики SQL и транзакций, когда это разумно) могут приводить к использованию подходов, подрывающих адаптивность [5].
Отдельной проблемой является абсолютный масштаб «облачных вычислений». Сегодняшние SQL-ориентированные системы баз данных не могут масштабироваться на тысячи узлов при размещении в облачном контексте. В области хранения данных непонятно, следует ли обходить эти ограничения с применением новых методов реализации транзакционности, или с использованием новой семантики хранения данных, или того и другого. В существующих облачных сервисах начинают применяться некоторые простые прагматические подходы, но для синтеза идей, описанных в литературе, в современных условиях облачных вычислений требуется дополнительная работа. При обработке и оптимизации запросов будет нереально производить исчерпывающий поиск в пространстве планов с учетом тысяч обрабатывающих узлов, потребуются ограничения, налагаемые на пространство планов или на поиск. Дополнительные исследования требуются для обеспечения понимания реальной масштабируемости «облачных вычислений» (как ограничений по производительности, так и требований приложений). Такое понимание должно помочь разработчикам осуществлять навигацию в возникающем пространстве проектных решений [5].
При совместном использовании физических ресурсов в облачной инфраструктуре требуется обеспечение безопасности и конфиденциальности данных, которые не могут гарантироваться за счет наличия физического разграничения машин или сетей. Следовательно, облачные сервисы обеспечивают плодородную почву для усилий по объединению и ускорению исследований, выполняемых сообществом баз данных в этих областях. Залогом успеха здесь будет ориентация на конкретные сценарии использования облачных сервисов, основанные на практических экономических стимулах для сервис-провайдеров и потребителей [5].
Кроме того, прогнозируется появление каркасных приложений, способных свободно перемещаться между разнородными «облачными» средами, как следствие уменьшение роли ОС, поскольку значительную часть функций (например, по защите информации, по управлению ею) пользователь будет получать из «облаков» [6].
Анализ данных в облачных хранилищах
Методы бизнес-анализа и технологии их поддержки пребывают в сложном «диалектическом» взаимодействии – новые методы анализа данных стимулируют появление новых технологий и наоборот. Современный виток развития BI связан с появлением технологий «BI по запросу», или BIaaS. Этот качественный переход, прежде всего, связан с облачными технологиями [7].
Процессы управления бизнесом сложнее, чем любой технической системой, но и их условно можно представить в виде пяти основных этапов, цепочку которых можно рассматривать в контексте окружения для BI [7]:
- обнаружение и детализация проблемы;
- постановка задачи и идентификация данных, необходимых для ее решения;
- анализ данных, в том числе пробный анализ (Exploratory Data Analysis, EDA), анализ, позволяющий построить гипотезы (Structured Data Analysis, SDA) и определить потоки данных, а также другие виды анализа;
- Business Intelligence – толкование данных, подготовка отчетов, построение моделей и выработка рекомендаций, прогнозов и предсказаний;
- принятие решений.
Таким образом, в цепочке обратной связи BI занимает место между различными методами анализа данных и принятием решений, из чего следует, что суть BI в преобразовании данных в информацию, которую уже можно использовать для принятия решений. Основная же задача BI состоит в агрегации, интеграции и интерпретации данных из разнородных источников, с тем, чтобы превратить их в удобную для принятия решений информацию. В этом контексте между данными и информацией отношения чрезвычайно просты: на входе BI – данные, на выходе – информация, в других случаях отношения могут быть иными, но при обсуждении роли BI в цепочке обратной связи, входящей в систему управления предприятием, этого достаточно. Таким образом, это важнейший компонент системы управления бизнесом [7].
BI и облака
Современные технологии хранилищ оказываются идеологически близкими к облакам (Табл. 1.), например, благодаря применению масштабируемых архитектур типа Shared Nothing. Облака и современные хранилища строятся как распределенные системы с независимыми узлами при обеспечении доступа к ним по модели повременной оплаты (pay-as-you-go). Сервисная модель обеспечила предприятиям среднего и малого бизнеса доступ к системам BI, ранее применяемым только крупными компаниями. BI по запросу дает таким предприятиям относительную простоту использования, существенное сокращение затрат и сокращение сроков внедрения с полутора-двух лет до нескольких недель [7].
Таблица 1
Компоненты облаков и хранилища
| PaaS | Системы визуализации и анализа данных |
| SaaS | Хранилища данных, базы данных, системы интеграции данных |
| IaaS | Системы хранения данных и серверные пулы |
Традиционно системы BI имели дело со структурированными данными из относительно ограниченного пула корпоративных данных, что существенно сужает область действия поиска информации для принятия решений. Очевидно, что решения, принимаемые в современном бизнесе, должны базироваться на более широком информационном поле, учитывающем не только многочисленные неструктурированные данные (текстовые документы, письма, мультимедиа и т.п.), но и хранилища и источники данных вне компаний. Однако для расширения сферы влияния BI на все доступное информационное поле одной какой-либо системы, даже корпоративного уровня, недостаточно. Возможно, технологии BIaaS позволят не только крупным, но и средним компаниям охватить и обработать все необходимые для бизнеса источники данных [7].
В качестве примера можно привести полное и открытое облачное решение в области BI предложенное, альянсом из четырех компаний – RightScale, Jaspersoft, Talend и Vertica. Решение, построенное на принципе оплаты по мере использования, может быть доступно по цене практически любому предприятию или организации. Это предложение подойдет, в первую очередь, небольшим компаниям или подразделениям корпораций, в которых нет полноценных средств BI [7,8].
Пример реализации BI в облаках
На рис. 1. Показано распределение функций между участниками союза по созданию открытого облачного bi-решения: компания rightscale предоставляет облачную платформу, компании talend, vertica и jaspersoft осуществляют сбор данных, работу с ними в хранилище и собственно услуги бизнес-анализа [7].

Рис. 1. Распределение функций в стеке продуктов компаний RightScale, Jaspersoft, Talend и Vertica
Компания RightScale обеспечивает выполнение приложений на различных облачных платформах, что сегодня актуально в условиях отсутствия общепринятых стандартов на облачные инфраструктуры. Предложение от RightScale включает методы и лучший опыт внедрения приложений на разнотипных облачных платформах. Компания дает своим потребителям единый и унифицированный доступ к облакам разных типов. Она поддерживает более 1,1 млн серверов. Платформа RightScale Cloud Management Platform существует в нескольких изданиях, от свободно распространяемого для разработчиков Developer Edition до Professional Edition [7].
ПО, поставляемое компанией RightScale, использует старую идею макрокоманд, хорошо известную программистам на ассемблере. Но в данном случае макро – не оболочка для какой-то повторяющейся последовательности команд, а более сложная структура, получившая название Deployment («развертывание»), которая включает все необходимые атрибуты виртуальных серверов ЕС2 или других физических платформ. Макро – это исполняемое описание или мгновенный снимок платформы, позволяющее выполнить описание в том или ином операционном окружении. В альянсе четырех компаний RightScale выполняет связующую функцию, создав набор макро для интеграции продуктов компаний Vertica, Talend и Jaspersoft в единую систему [7].
Компания Talend предлагает решения интеграции данных класса ETL (Extract, Load, Transform/ извлечение, загрузка, преобразование). Она поставляет продукт в открытых кодах, ее основное решение – Talend Open Studio. В альянсе Talend обеспечивает подготовку и загрузку необходимых данных в хранилище, для этого Talend Cloud Execution Servers (сервер использования облака от компании Talend) размещается в облаке с использованием RightScale Cloud Management Platform (платформа управления облаком от компании RightScale). Последовательность действий для запуска платформы RightScale выглядит так [7]:
- подписка на сервисы облачного провайдера и получение аккаунта у RightScale;
- создание в облаке сервера Talend Cloud Execution Servers из репозитория шаблонов Talend Repository, загрузка на сервер пользователя и настройка инструмента Talend Open Studio;
- настройка процедур ETL в облаке и дальнейшая работа под управлением Talend Administrator.
В разработках компании Vertica участвует Майкл Стоунбрейкер, создавший СУБД Vertica, Ingres, Postgres, Streambase и Illustra. СУБД Vertica специально предназначена для аналитических приложений и, помимо организации данных по колонкам (о ней говорят чаще всего), отличается альтернативной техникой обновления out-of-place. Существуют разные технологии обновления данных, в реляционных СУБД чаще всего используется классическая, in-place, – данные изменяются именно в том месте, где они были изначально записаны. При использовании метода out-of-place внесенные изменения записываются отдельно и связываются указателями и первичными записями, что эффективно в аналитических приложениях при работе с большими объемами данных. Однородность типов данных при организации по колонкам позволяет более эффективно использовать технологии компрессии и тем самым уменьшить нагрузку на ввод/вывод. Еще одно преимущество Vertica – изначальная ориентация на кластеры и на платформы с массовым параллелизмом, поэтому она сама построена по архитектуре Share Nothing, предполагающей работу на распределенных системах с независимыми узлами. В такой системе не может быть «точки разногласия» – все узлы равны между собой. Все это делает Vertica желательным кандидатом на работу в облачной инфраструктуре. Последовательность действий для запуска Verica аналогична приведенной выше процедуре запуска платформы RightScale и отличается лишь последним шагом, предполагающим в данном случае подписку на сервисы Vertica [7].
Решение, представленное пакетом средств интеллектуального анализа данных JasperSoft Business Intelligence Suite (сервер Jasperserver и аналитика Jaspersoft Analytics), имеет две редакции: открытую и профессиональную. Первая базируется на Linux или Windows, серверах приложений Jboss или Tomcat, СУБД MySQL и каталоге Hibernate. Профессиональная версия поддерживает все коммерческие диалекты Unix, включая Mac OS X, а также несколько дистрибутивов Linux, коммерческие серверы приложений IBM WebSphere, BEA WebLogic и Oracle Application Server. На рис. 2. приведена архитектура пакета средств интеллектуального анализа данных Jaspersoft Business Intelligence Suite [7].

Рис. 2. Структура пакета средств интеллектуального анализа данных Juspersoft Business Intelligence Suite
В основе пакета средств интеллектуального анализа данных JasperSoft Business Intelligence Suite лежит модуль отчетности JasperReports, а отличительная особенность пакета заключается в том, что он может быть оформлен как автономный (stand alone), если задействовать его собственные средства для сбора данных JasperETL. Другой вариант – встраивание в системы типа ERP или CRM. Имеется версия для использования провайдерами SaaS, которая способна выполняться во множестве экземпляров (out-of-the-box multi-tenancy). Эта способность («коммунальность») распространяется на аутентификацию, на управление метаданными, администрирование данных в базах со строчной и колоночной организацией. Для запуска JasperSoft Business Intelligence Suite необходимо оформить подписку на сервисы любого облачного провайдера, получить аккаунт у RightScale на управление облачными структурами, выбрать шабон JasperServer в репозитории RightScale, а затем развернуть облачную версию JasperServer [7].
BI-системы применяются для анализа текущего состояния бизнеса, что в ряде случаев оказывается весьма важно для принятия правильных решений. Аналитические системы выполняют такие задачи, как: формирование регламентированной и корпоративной отчетности, выявление скрытых тенденций, прогнозирование и т.д. Сегодня растет понимание того, что системы бизнес-аналитики необходимо строить на хранилищах данных – OLTP-системы уже не справляются с возрастающими нагрузками. Возникает потребность работs BI-систем с актуальными данными, еще не поступившими в хранилище, не отказываясь от анализа исторических данных. Исходя из этих потребностей, сейчас все более актуальны хранилища «реального» времени, позволяющие данным появляться в хранилище с минимальной временной задержкой. Такие хранилища позволяют эффективно решать задачи оперативной отчетности и аналитики «реального» времени [7].
Еще одна тенденция – наличие в BI-системе «единого клиента». В организациях, как правило, функционируют несколько информационных систем и один и тот же клиент может присутствовать в нескольких системах. Если у компании нет системы управления мастер-данными (MDM), то после загрузки данных в хранилище произойдет дублирование и для устранения этой проблемы производители предлагают использовать специализированные MDM-системы. Но их функционал значительно больше, чем борьба с дублированием, поэтому стоимость таких систем достаточно высока. Кроме этого, некоторые из MDM-систем имеют сложности при работе с русским языком, поэтому часто задачу по созданию «единого клиента» необходимо решать в рамках внедрения BI-системы [7].
Наиболее распространенные в настоящее время платформы для аналитических систем – BOBJ (SAP), OBIEE (Oracle) и CognosBI (IBM) – ориентированы на сотрудников всех уровней, от операционного персонала до руководителей любого ранга. Большой популярностью пользуются проактивные уведомления на электронную почту, например, в виде ссылки на информационную панель, отражающую ключевые показатели эффективности, причем, чем выше должность руководителя, тем более агрегированная информация ему необходима [7].
Крупные компании предпочитают предварительно настроенные индустриальные аналитические приложения от ведущих поставщиков. Плюсом таких решений является то, что эти аналитические приложения интегрированы с промышленными ERP- и CRM-системами и включают в себя лучшие практики. Средние компании, как правило, ограничиваются набором отчетных форм по специфичным предметным областям [7].
Не существует такого понятия, как готовое аналитическое решение: каждое внедрение требует серьезной доработки под заказчика. Вместе с тем, ведущие производители объявили о появлении версий своих аналитических систем, распространяемых по модели SaaS или On Demand. Корпорация IBM в лице своего подразделения Business Analytics and Optimization Services Group, насчитывающего более 4 тыс. консультантов, наибольшее внимание уделяет системам корпоративного управления (Сorporate Per formance Management, CPM). В фокусе группы – задачи стратегического BI (forward-looking BI). С этой целью IBM развивает прогнозное моделирование (predictive modeling) и совершенствует средства добычи данных. Показательно, что в прошлом году ею был куплен известный поставщик аналитического ПО – компания SPSS, последняя версия продукта, которой так и называется – PASW (Predictive Analytics SoftWare). Компания Oracle после покупки Siebel и Hyperion получила возможность для поставки функционально полного стека продуктов Business Intelligence Enterprise Edition, функционал которого еще расширится с появлением аппаратно-программной системы хранилищ данных Exadata V2. Microsoft предпринимает попытки создать недорогую платформу для BI на базе SQL Server, SharePoint и Office. Первый включает средства для создания отчетов, ETL, аналитики и добычи данных, SharePoint 2010 – приборные панели (dashboard), средства для демонстрации показателей (scorecard), причем, Excel в новой редакции получил еще более сильные аналитические инструменты, а Power Pivot позволяет теперь собирать сведения из разных источников. Кроме того ожидается появление SQL Server 2008 R2 Parallel Data Warehouse, продукта полученного в результате приобретения компании DATAllegro и предназначенного для параллельной обработки данных. Компания SAP реализует модель BIaaS в продукте BusinessObjects XI, вошедшем в портфель ее решений после приобретения французской компании BusinessObjects в 2007 году, но имеются и классические версии SAP BusinessObjects Edge BI и SAP NetWeaver BusinessWarehouse, распространяемые по традиционной модели. Среди новинок можно отметить введение в BusinessObjects семантического уровня следующего поколения, позволяющего скрыть сложность структуры используемых данных, представив их в удобном для бизнес-пользователей виде. Можно отметить также базу данных, работающую в оперативной памяти, – NetWeaver Business Warehouse Accelerator, что позволяет ускорить работу хранилищ данных [7].
Но стоит отметить, что для успешного масштабирования на "облаке" СУБД должна обладать следующими обязательными характеристиками [8]:
- работать по принципу shared nothing («ничего общего») – использование общих ресурсов ограничивает машстабирование;
- эффективно работать на commodity hardware («обычном «железе») – «облачные» вычислительные центры состоят из обычных по характеристикам (commodity) серверов, не имеющих сверхпроизводительных многоядерных процессоров, специальных дисковых контроллеров и сверхбыстрой памяти;
- автоматически балансировать и поддерживать кластер серверов – чем больше серверов, тем больше вероятность сбоя в работе любого из них; так, по опыту Google, из тысячи серверов ежеминутно один выходит из строя, и СУБД должна эффективно справляться с подобными ситуациями;
- быстро обрабатывать запросы – при работе с находящимися в "облаке" серверами ко времени обработки запроса добавляется время передачи сообщений по интернету, поэтому СУБД должна работать максимально быстро для достижения приемлемого для пользователя времени отклика (аналогичная проблема стоит перед Panorama Analytical Applications).