
Конспект лекций для специальности «Прикладная информатика в экономике»
| Вид материала | Конспект |
- Учебно-методический комплекс для студентов заочного обучения специальности Прикладная, 81.9kb.
- Конспект лекций для специальности «Прикладная информатика в экономике», 535.22kb.
- Конспект лекций для студентов специальности Прикладная информатика (в экономике), 3204.37kb.
- Учебно-методический комплекс для студентов заочного обучения специальности Прикладная, 172.73kb.
- Рабочая учебная программа по Правоведению Для специальности- «Прикладная информатика, 388.83kb.
- Учебно-методический комплекс для студентов заочного обучения специальности Прикладная, 88.44kb.
- Программа по курсу "Математика. Алгебра и геометрия" для специальности 080801 (351400), 143.45kb.
- Учебно-методический комплекс Для специальности 080801 Прикладная информатика (в экономике), 296.07kb.
- Учебно-методический комплекс Для специальности 080801 Прикладная информатика (в экономике), 610.8kb.
- Рабочая программа по дисциплине «Исследование операций в экономике» для специальности, 137.37kb.
4.3. Кластеризация текстов
Для организации хранения кластерных файлов требуется их разбиение на кластеры.
Методы кластеризации основаны на построении полной матрицы подобия текстов заданного пространства, в которой для каждой пары текстов Di, Dj приводится коэффициент подобия S(Di,Dj). Затем вводится некоторое пороговое значение коэффициента подобия Ŝ: если S(Di,Dj)> Ŝ, тексты Di, Dj включаются в кластер, иначе – не включаются.
4.4. Поиск релевантных текстов
Как отмечалось, наиболее употребляемыми на практике являются два способа – инвертированные и кластерные файлы. Рассмотрим, как решается задача поиска релевантных текстов в этих случаях.
4.4.1. Поиск в инвертированных файлах
Пусть есть пространство текстов размером n, каждый из которых характеризуется вектором Vi = {(tk; wki)}. Пусть запрос содержит множество ключевых слов (терминов): q = ({tkq}). Определим формально текст, релевантный запросу q, как такой текст ТБД, для которого коэффициент подобия с запросом отличен от нуля.
Для расчета коэффициента подобия запроса и текстов ТБД применяются вектора текстов и запроса. Определим вектор запроса Vq:
Vq = {(tkq; wkq)},
где tkq – термин запроса;
wkq - вес этого термина.
Тексты Di характеризуются векторами Vi:
Vi = {(tk; wki)},
где tk – термин вектора текста – индексационный термин;
wki - вес этого термина:
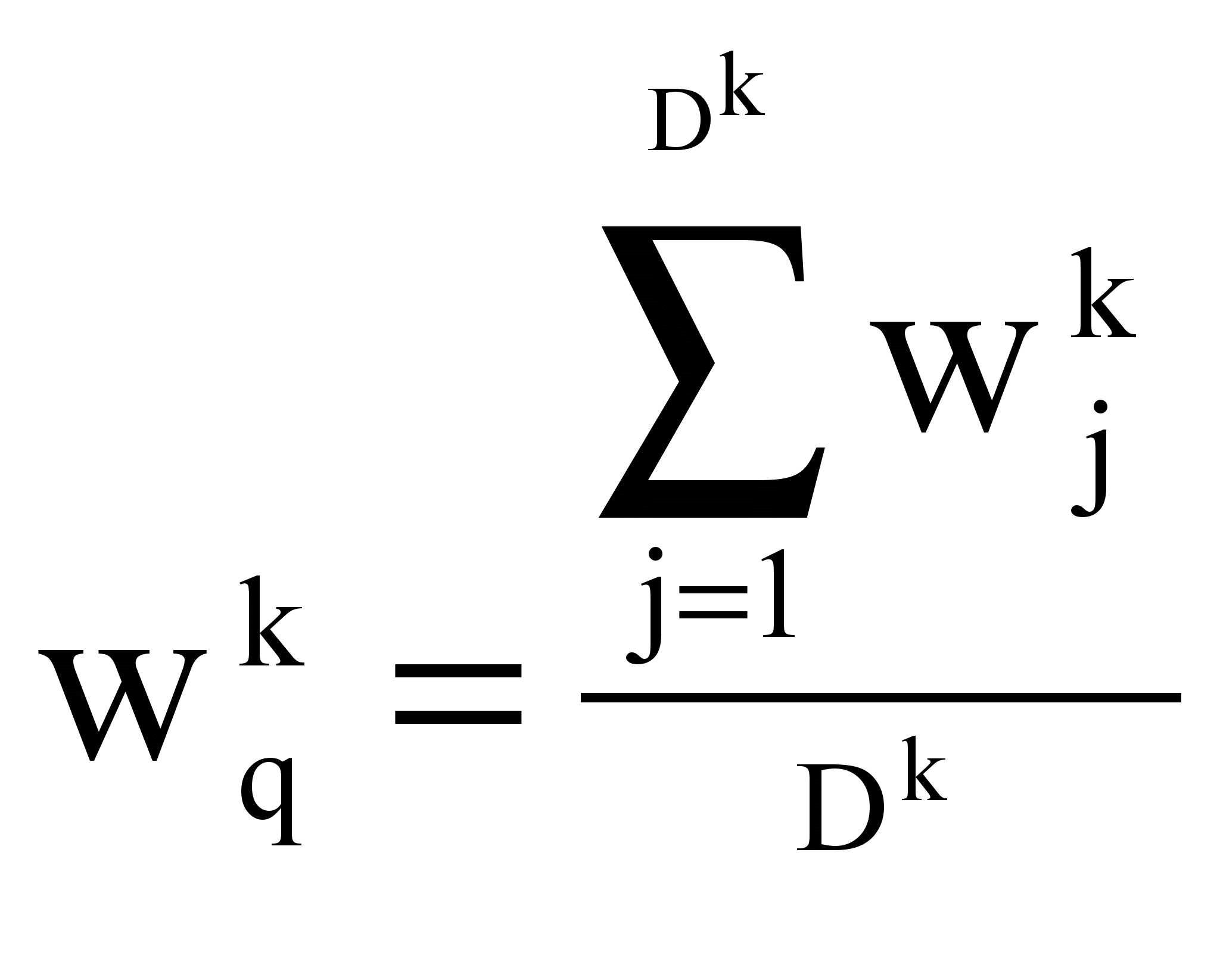
Тогда при поиске релевантного текста (текстов) по запросу q рассчитываются коэффициенты подобия запроса и каждого из текстов ТБД:
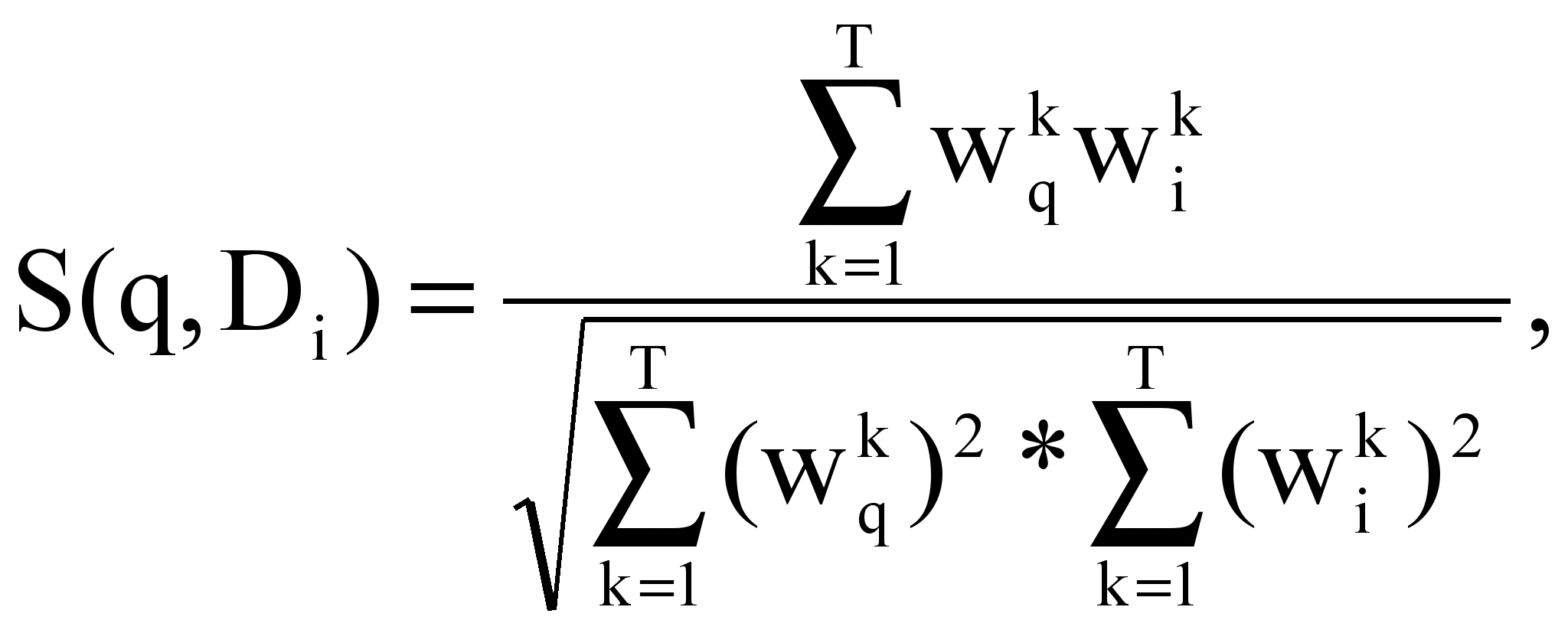
После определения релевантных текстов возможны два подхода:
- тексты упорядочиваются по убыванию релевантности, т.е. коэффициента подобия запросу, и предоставляются пользователю в таком упорядоченном виде;
- вводится пороговый коэффициент подобия Ŝ: пользователю выдаются только те тексты ТБД, для которых подобие с запросом превышает пороговое значение.
4.5.2. Поиск при кластерной организации хранения
Пусть пространство текстов разбито на множество кластеров {Cl}, каждый из которых есть своё подпространство размером nl текстов исходного пространства размером n текстов. При этом каждый кластер характеризуется профилем Пl и вектором Vl вида:
Vl = {(tlk, flk)},
где {tlk} =
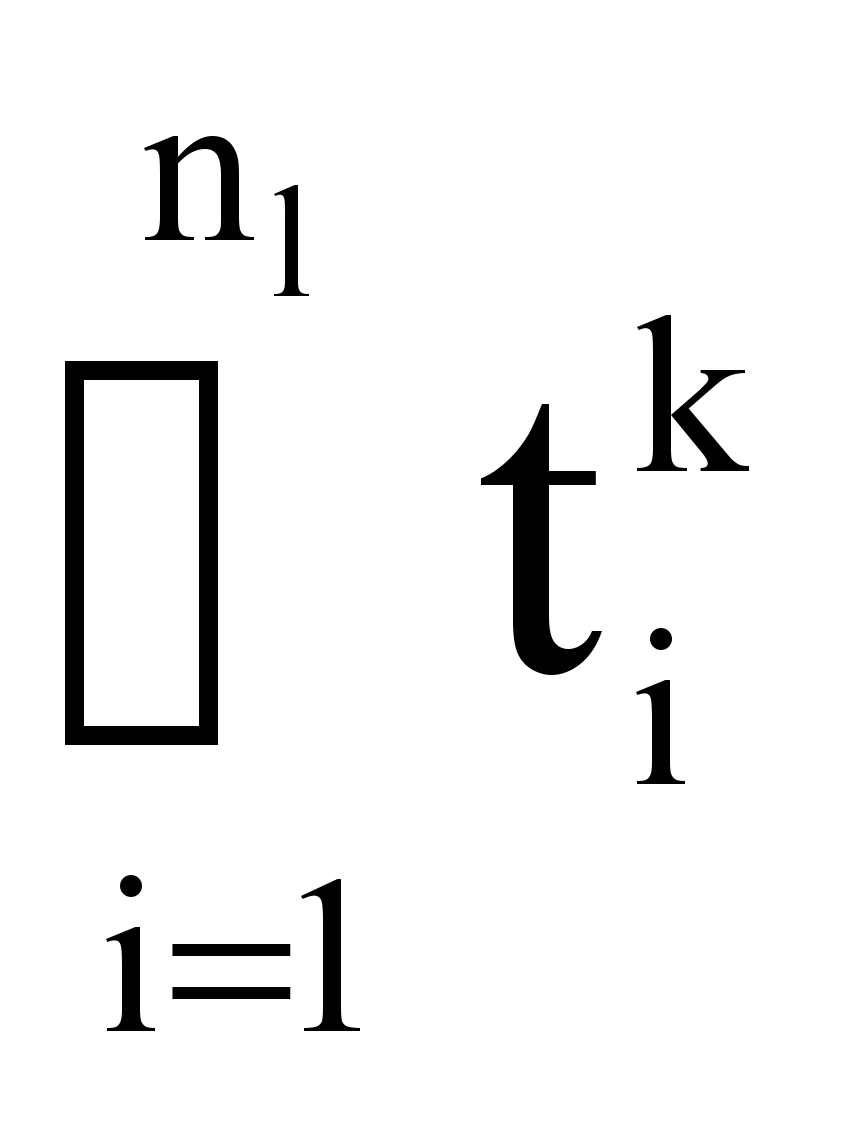 , т.е. множество {tlk} индексационных терминов есть объединение индексационных терминов текстов кластера Сl,
, т.е. множество {tlk} индексационных терминов есть объединение индексационных терминов текстов кластера Сl, 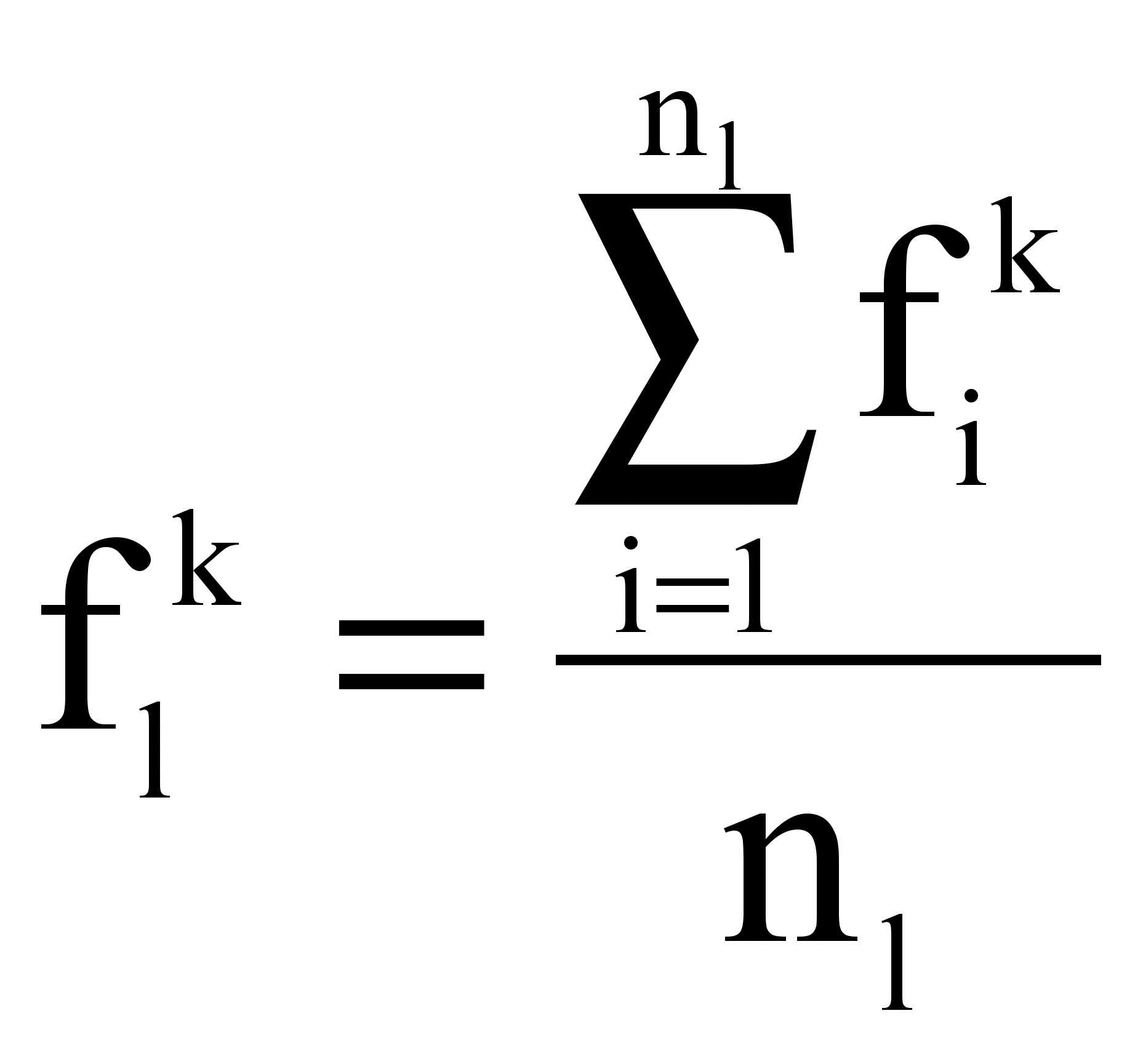 , т.е. частоты терминов есть усредненные частоты терминов по текстам кластера.
, т.е. частоты терминов есть усредненные частоты терминов по текстам кластера. Рассчитываются коэффициенты подобия S(q, Cl) запроса и кластера, представленного своим вектором:
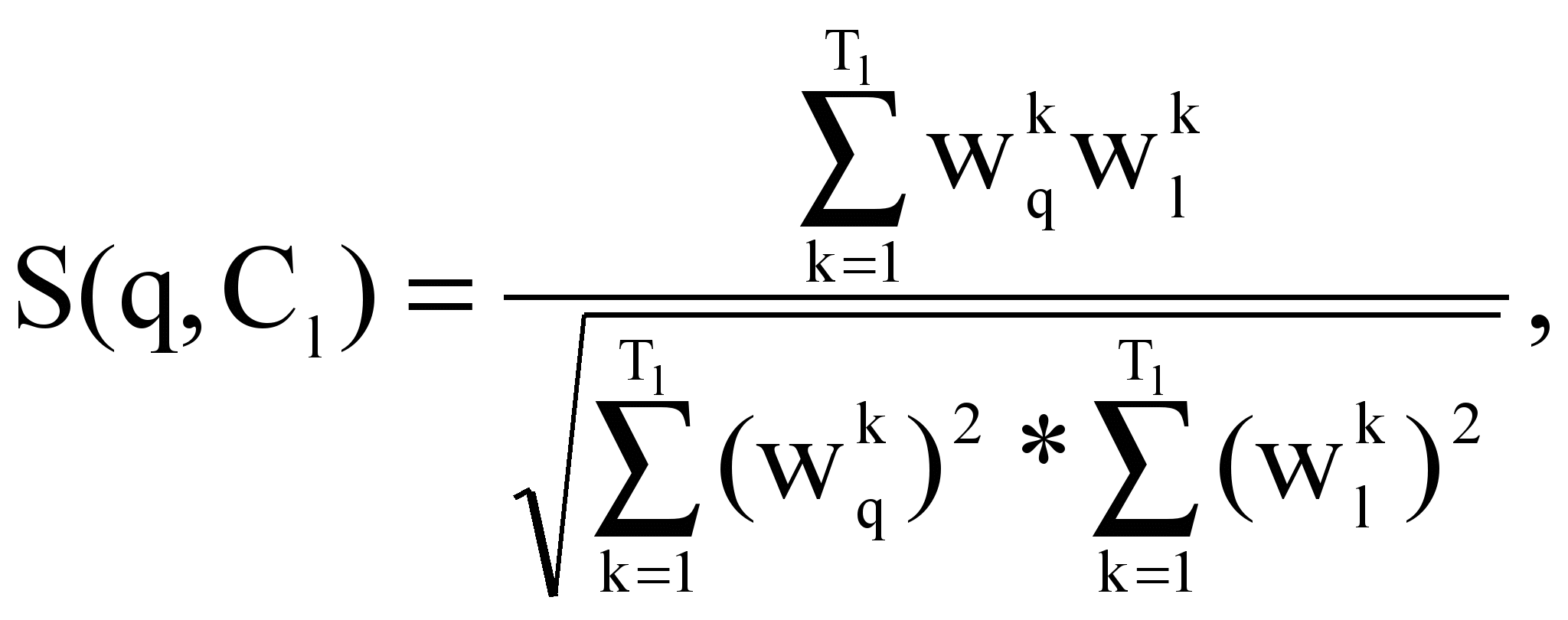
где wlk – вес термина tk в профиле кластера Cl;
Тl – число индексационных терминов в профиле кластера Сl.
После определения релевантного кластера (его подобие с запросом отлично от нуля) поиск релевантного текста (текстов) выполняется внутри кластера.
4.5. Методы расширенного поиска
Часто при поиске в ТБД необходимо увеличить число релевантных текстов (в поисковых системах Интернет это называется расширенным поиском). Пространство релевантности увеличивается за счет дополнительных совпадений терминов запроса и индексационных терминов.
Для увеличения числа совпадений используются методы:
- применение словаря синонимов (тезауруса), в котором термины сгруппированы в классы синонимии, или эквивалентности. Для построения тезауруса используют методы кластеризации элементов, в которых в качестве элементов выступают индексационные термины;
- исключение из рассмотрения префиксной и постфиксной частей терминов и выделение их основ путем проведения морфологического анализа;
- использование ассоциативного индексирования для приписывания терминам дополнительных терминов, которые ассоциируются с исходными;
- вероятностное индексирование.
4.5.1. Построение словаря синонимов
Смысл этого метода сводится к тому, что с каждым термином tk связывается множество его синонимов Synk. Образуется тезаурус. Тогда вектор запроса пополняется терминами из тезауруса, что расширяет число текстов, релевантных запросу.
Связь термина tk с множеством Synk может быть представлена дополнительной графой справочника, в которой множество синонимов задано либо явно, либо списком номеров синонимичных терминов из того же справочника, например:
| Термин tk | Синонимы Synk | Текст | |||
| Ф1 | Ф2 | Ф3 | Ф4 | ||
| К1 | К4 | wФ1К1 | wФ2К1 | wФ3К1 | wФ4К1 |
| К2 | - | wФ1К2 | wФ2К2 | wФ3К2 | wФ4К2 |
| К3 | - | wФ1К3 | wФ2К3 | wФ3К3 | wФ4К3 |
| К4 | К1 | wФ1К4 | wФ2К4 | wФ3К4 | wФ4К4 |
Тогда, например, если в запросе участвует термин К1, а его синонимом является термин К4, то запросу релевантны тексты, характеризующиеся как термином К1, т.е. Ф1, так и К4, т.е. Ф4.
При формировании тезауруса применяются рассмотренные выше для текстов методы кластеризации. Для этого каждый термин tk представляется вектором Vk вида:
Vk = {(Di, fik)} или Vk = {(Di, wik)}.
Тогда для терминов tk и tr коэффициент подобия S(tk,tr) рассчитывается по формуле:
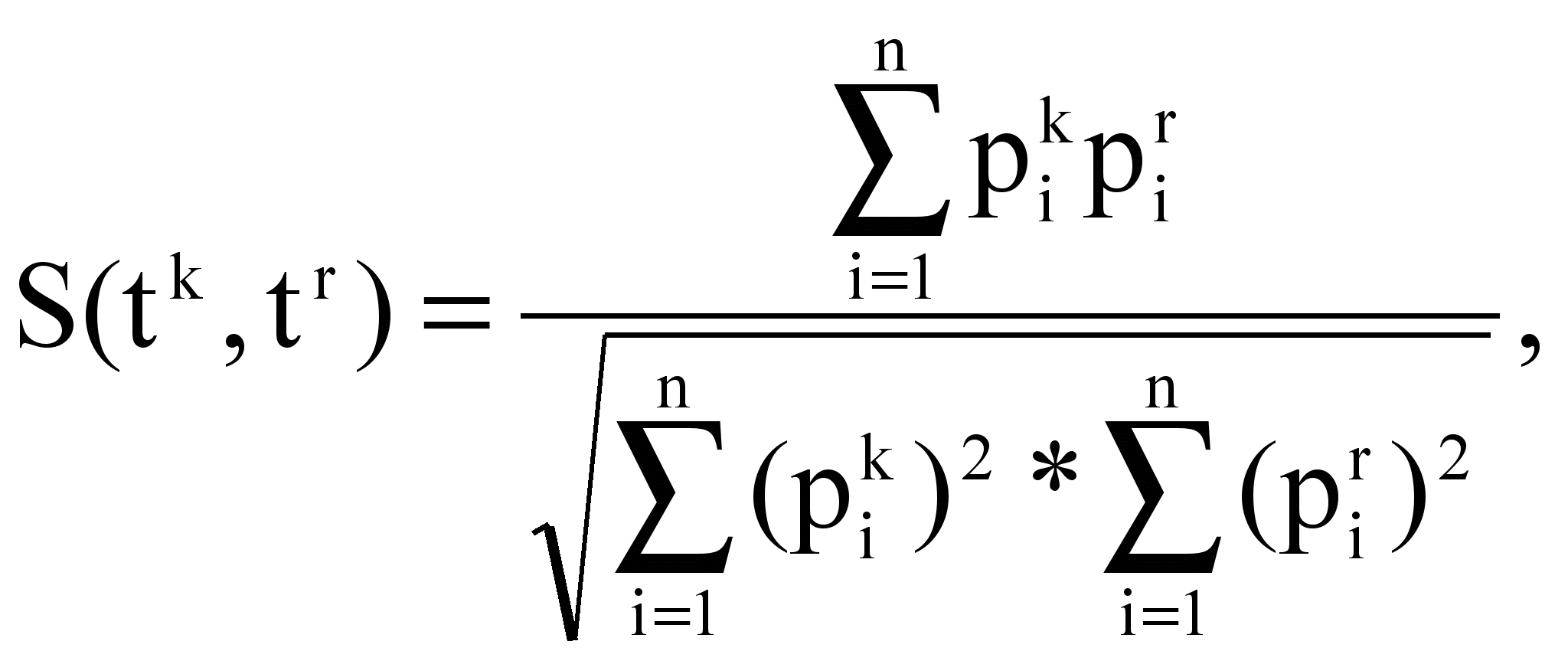
где pir – параметр (частота или вес), характеризующий термин tr в тексте Di,
n – число текстов в наборе.
4.5.2. Ассоциативное индексирование терминов
Для каждого термина tk находятся дополнительные термины, которые ассоциируются с исходным, - Assk. Тогда вектор запроса, аналогично предыдущему методу, пополняется дополнительными терминами. Это, очевидно, расширяет число релевантных запросу текстов. Связь термина tk с множеством Assk может быть также представлена дополнительной графой справочника.
Для выявления ассоциируемых терминов строится матрица ассоциируемости, задающая для каждой пары терминов (tk, tr) показатель ассоциируемости a(k, r):
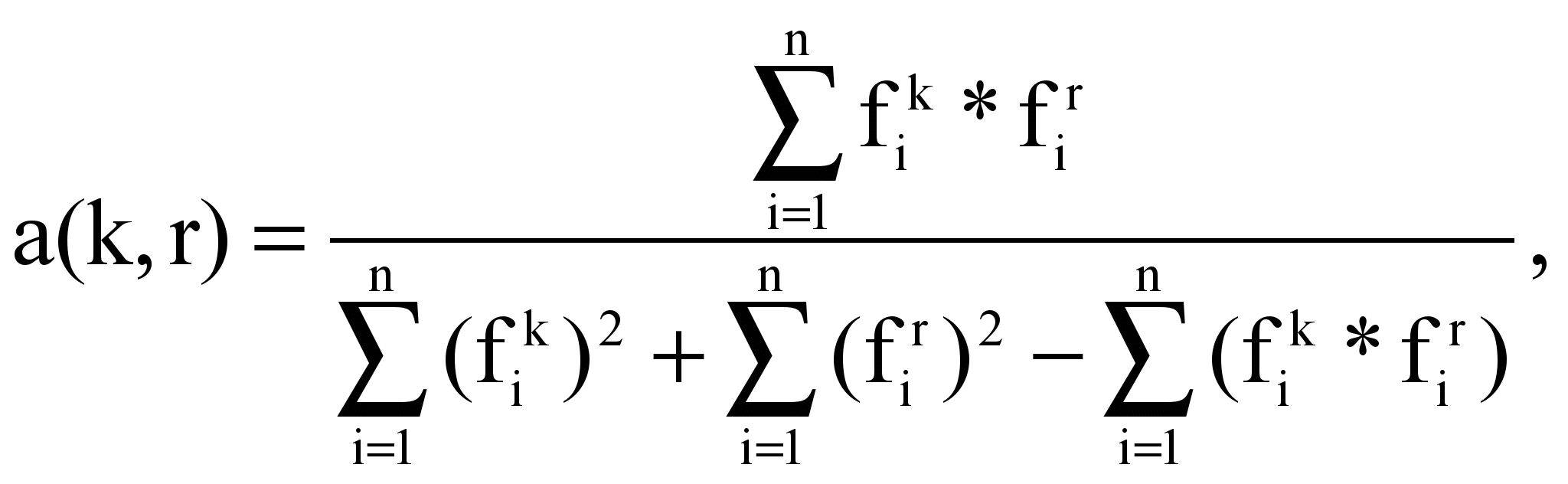
где fik, fir – частоты терминов tk, tr в тексте Di.
Этот показатель принимает значения от 1 до 0: если он равен 1, то термины полностью ассоциируются, если равен 0, то никакой ассоциации между ними не существует. На практике для определения ассоциируемости вводится некоторое пороговое значение показателя â. Тогда термины ассоциируются, если для них показатель ассоциируемости превышает это пороговое значение.
4.5.3. Вероятностное индексирование терминов
Этот метод применяется при кластерной организации файлов, причем кластеры не должны пересекаться.
Суть метода состоит в том, что наличие в векторе запроса некоторых терминов используется как основа для утверждения, что данный запрос с вероятностью p относится к кластеру Сl с профилем Пl. Если вероятность превышает некоторое пороговое значение, термины из профиля (или их веса) приписываются к вектору запроса.
Вероятность p рассчитывается следующим образом:
p(t1, t3,..., tT’, Cl) = в*p(Cl)*p(Cl, t1)*p(Cl, t3)*...*p(Cl, tT’),
где р(Cl) - вероятность кластера Cl:
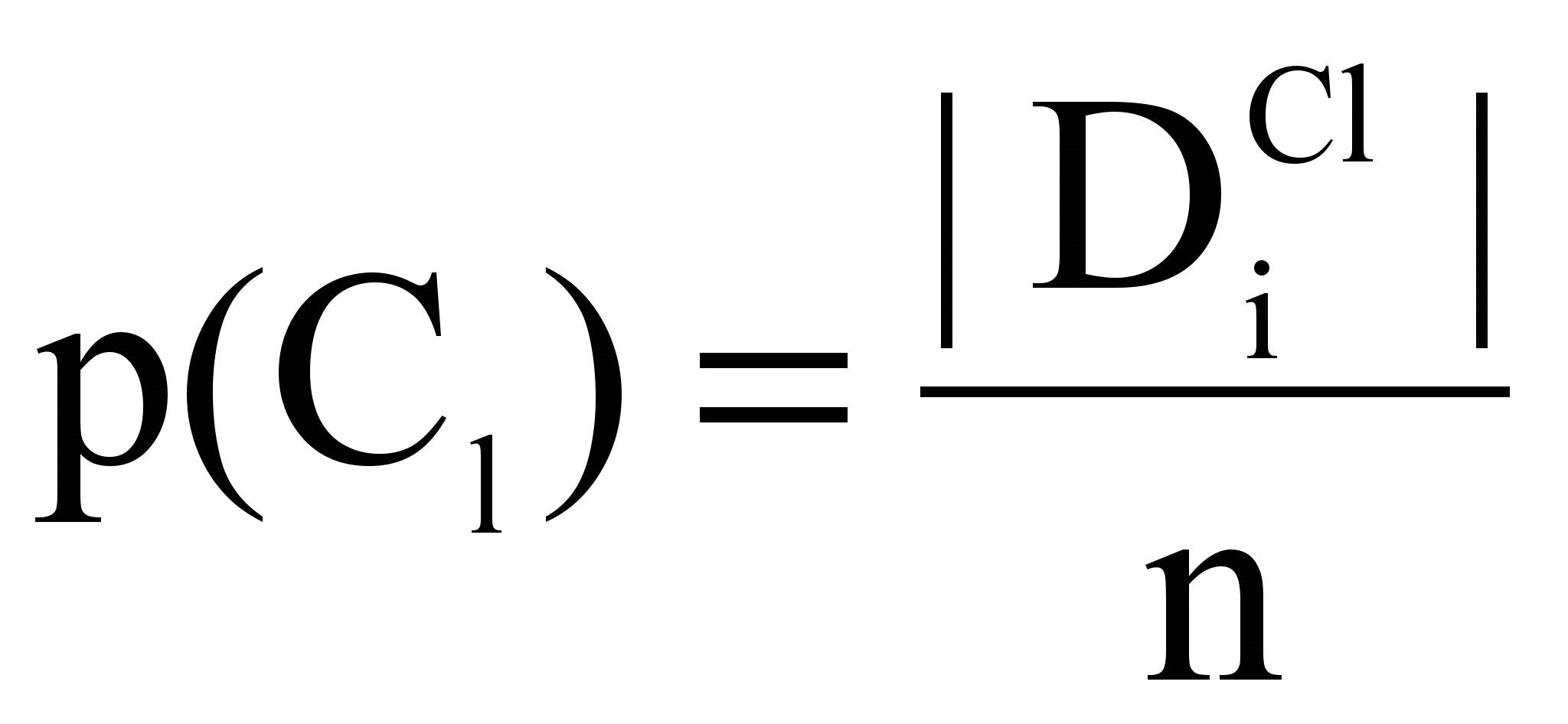 ,
, |DiCl| - число текстов в кластере Cl,
n - число текстов во всех кластерах,
р(Cl, tk) - вероятность того, что каждый текст из кластера Cl содержит термин tk:
p(Cl, tk) =
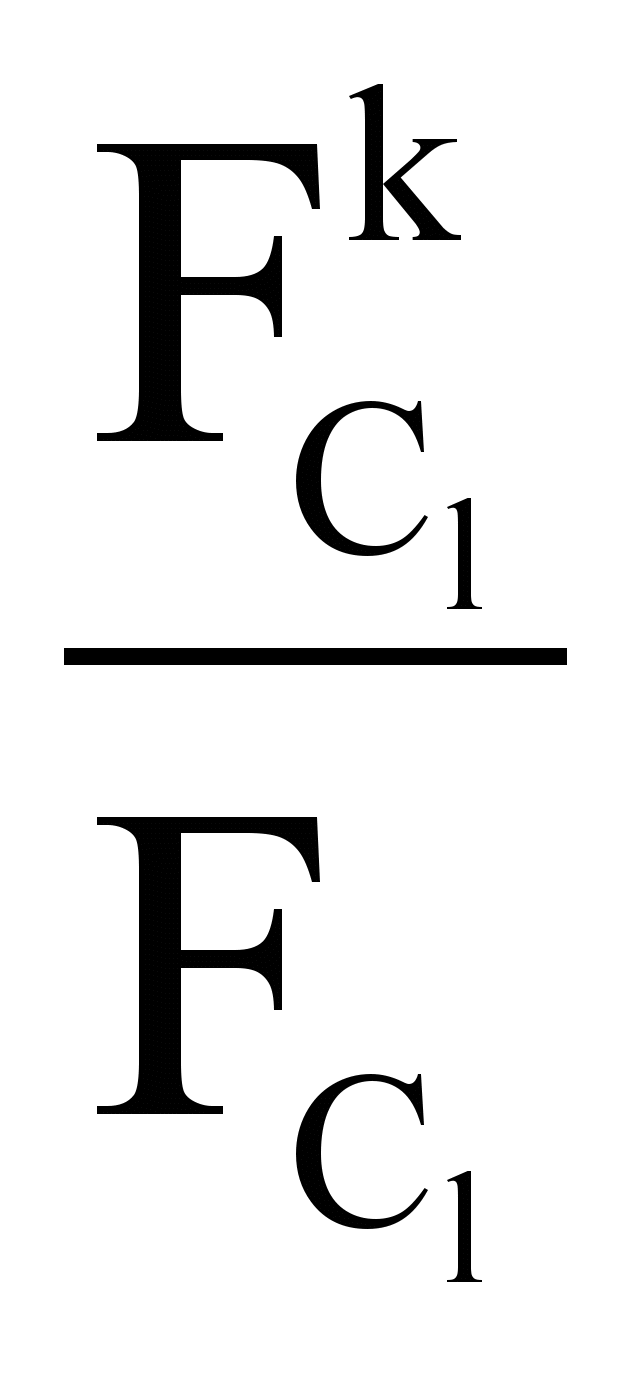
FClk – общее число терминов tk в текстах кластера Cl,
FCl – общее число терминов в текстах кластера Cl,
Т’ - число терминов с ненулевым весом в векторе запроса,
в – константа, значение которой выбирается таким образом, чтобы выполнялось условие:
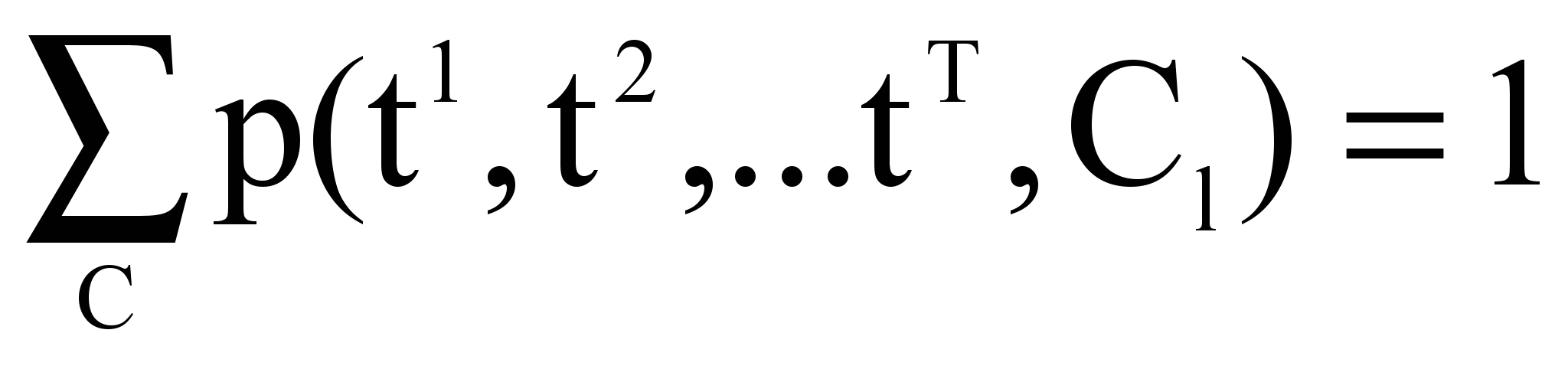 ,
,где С – общее число кластеров.