
Конспект лекций для специальности «Прикладная информатика в экономике»
| Вид материала | Конспект |
- Учебно-методический комплекс для студентов заочного обучения специальности Прикладная, 81.9kb.
- Конспект лекций для специальности «Прикладная информатика в экономике», 535.22kb.
- Конспект лекций для студентов специальности Прикладная информатика (в экономике), 3204.37kb.
- Учебно-методический комплекс для студентов заочного обучения специальности Прикладная, 172.73kb.
- Рабочая учебная программа по Правоведению Для специальности- «Прикладная информатика, 388.83kb.
- Учебно-методический комплекс для студентов заочного обучения специальности Прикладная, 88.44kb.
- Программа по курсу "Математика. Алгебра и геометрия" для специальности 080801 (351400), 143.45kb.
- Учебно-методический комплекс Для специальности 080801 Прикладная информатика (в экономике), 296.07kb.
- Учебно-методический комплекс Для специальности 080801 Прикладная информатика (в экономике), 610.8kb.
- Рабочая программа по дисциплине «Исследование операций в экономике» для специальности, 137.37kb.
3.4. Физическое проектирование структур данных
В данном разделе рассмотрим способы организации хранения на машинных носителях информационных массивов, отражающих одну из рассмотренных логических моделей данных. Каждый раз при решении вопроса о выборе способа структуризации файла, основным критерием является последующая минимизация времени доступа к данным по запросам пользователя, который включает, в общем случае, наименование и значение ключевого поля. Для этого часто вводятся дополнительные массивы данных, что ведет к перерасходу объемов внешней памяти, но позволяет оптимизировать доступ к данным.
3.4.1. Методы физического проектирования для реляционных моделей
Поскольку для реляционных структур существуют вторичные и первичные ключи, которые используются при поиске данных, различают методы физического проектирования для доступа по первичному и вторичному ключу. При рассмотрении каждой физической модели одновременно будет обсуждаться вопрос доступа к данным, что является основным критерием при решении вопроса о структурах хранения.
Для доступа по первичному ключу различают модели: последовательная организация, индексно-последовательная организация, индексно-произвольная организация, рандомизация. Для доступа по вторичному ключу выделяют модели: цепь подобных записей и инвертированные файлы.
3.4.1.1. Последовательная организация
Записи файла соответствуют логической модели данных. Число реляционных структур (таблиц) соответствует числу файлов. Доступ к записям осуществляется тремя способами: последовательным сканированием, блочным, двоичным.
При последовательном сканировании записи файла могут быть неупорядочены по первичному ключу. Для обозначения значения ключевого поля в запросе введем нотацию Кдоступ. Последовательно, начиная с первой записи, сравнивается ключ каждой записи файла К с ключом доступа Кдоступ. При равенстве обоих ключей требуемая запись найдена: содержащаяся в ней информация полностью или частично выводится пользователю. Если же равенство не выполняется, последующие шаги алгоритма различаются для упорядоченного и неупорядоченного файла:
- для неупорядоченного файла сравнение повторяется до достижения его конца. В этом случае, если совпадения ключей так и не было, делается вывод об отсутствии нужной записи;
- для упорядоченного файла проверяется условие, например, превышения значения ключа доступа Кдоступ значения ключа К: если файл упорядочен по возрастанию, поиск продолжается; если по убыванию – поиск прекращается ввиду отсутствия нужной записи.
При блочном способе записи файла должны быть упорядочены по первичному ключу. Для удобства дальнейшего изложения предположим (здесь и далее по реляционным моделям), что упорядочение выполнено по возрастанию значения ключа.
Файл разделяется на виртуальные блоки размером N записей, где N – число записей в файле. С ключом доступа Кдоступ сравниваются ключевые поля последних записей в блоках - Кjблока, начиная с первого блока (j – номер блока). С помощью такого сравнения вначале определяется блок, в котором возможно нахождение нужной записи (для этого требуется выполнение условия Кдоступ < Кjблока)8, а затем уже, как правило, методом последовательного сканирования - сама запись в блоке.
При двоичном способе записи файла также должны быть упорядочены по первичному ключу. Файл последовательно делится на две части, уменьшая пространство поиска каждый раз вдвое. Ключ доступа Кдоступ сравнивается с ключевым полем «средней» записи - Кср. Здесь возможны варианты:
Кдоступ = Кср; «средняя» запись является искомой, алгоритм заканчивает работу;
Кдоступ > Кср; поиск продолжается в той половине файла, где первичные ключи имеют бóльшие значения;
Кдоступ < Кср; поиск продолжается в той половине файла, где первичные ключи имеют мéньшие значения.
Продолжение поиска заключается вновь в делении выбранной половины файла пополам и т.д. Алгоритм заканчивает работу при нахождении нужной записи или при условии, когда очередная «половина» файла содержит только одну запись, ключевое поле которой не совпадает с Кдоступ. Делается вывод об отсутствии нужной записи в файле.
3.4.1.2. Индексно-последовательная организация
Записи файла должны быть упорядочены по первичному ключу. Аналогично блочному методу доступа, файл делится на виртуальные блоки размером N. Затем ключевые поля последних записей блоков вместе с порядковыми номерами этих записей в файле включаются в дополнительные файлы, которые называются индексами. Видно, что данный способ использует дополнительные построения, - назовем тогда исходный файл основным.
Пусть основной файл соответствует реляционной модели для сущности кафедра из рассмотренного ранее примера и имеет вид:
кафедра
| название | шифр в вузе |
| АПП | 238 |
| СУиВТ | 239 |
| ТАМ | 145 |
| Экономики | 056 |
Для этого файла N = 4. Это значит, что индекс будет иметь вид:
| название | № п/п |
| СУиВТ | 2 |
| Экономики | 4 |
Доступ к записям вновь осуществляется по ключу Кдоступ, который указывается пользователем в запросе. Однако алгоритм поиска начнет его не с основного файла, а с индекса, интерпретируя его как обычный файл с последовательной организацией записей, и применит к нему один из описанных ранее методов доступа, например, последовательное сканирование. Тогда ключевое поле К каждой записи индекса будет сравниваться с ключом Кдоступ. Возможны варианты:
- Кдоступ = К – запись найдена, известен ее номер в основном файле, по этому номеру она считывается из него и предоставляется пользователю, алгоритм заканчивает работу;
- Кдоступ > К – считывается следующая запись индекса. Если индекс закончен, алгоритм заканчивает работу – запись не найдена. Иначе вновь ключевое поле К очередной записи индекса сравнивается с ключом Кдоступ; возможные варианты исхода сравнения описаны выше, начиная с п.1);
- Кдоступ < К – обнаружен блок основного файла, который может содержать искомую запись. Выполняется переход к найденному блоку по полю индекса № п/п – к последней его записи. Все записи блока основного файла последовательно сканируются в поисках искомой записи в соответствии с рассмотренным ранее методом последовательного сканирования.
3.4.1.3. Индексно-произвольная организация
Этот способ организации данных используется, когда надо обеспечить доступ по нескольким первичным ключам. Поскольку, в общем случае, невозможно упорядочить линейный список сразу по нескольким ключам, требуется применять особые методы оптимизации поиска.
В таком случае список упорядочивается по тому ключу, по которому предполагаются наиболее частые запросы. По этому ключу организуется индекс как в случае индексно-последовательной организации (см. предыдущий раздел). Остальные значения первичных ключей формируют дополнительный файл – также индекс. Они включаются в индекс в полном составе из исходного файла и упорядочиваются. Кроме того, в индекс записываются ссылки на эти элементы в основном файле в виде порядковых номеров записей.
Пусть основной файл вновь соответствует реляционной модели для сущности кафедра из рассмотренного ранее примера и имеет вид:
кафедра
| название | шифр в вузе |
| АПП | 238 |
| СУиВТ | 239 |
| ТАМ | 145 |
| Экономики | 056 |
В данной модели, как отмечалось ранее, два первичных ключа – название и шифр в вузе. Пусть предполагается искать данные по обоим ключам, причем, в основном поиск будет вестись по ключу название. Тогда по этому ключу упорядочиваются записи в файле (что и сделано в таблице). Видно, что второй ключ имеет неупорядоченные значения.
Формируются два индекса: первый – для ключа название – аналогичен предыдущему примеру:
| название | № п/п |
| СУиВТ | 2 |
| Экономики | 4 |
Второй индекс имеет вид:
| шифр в вузе | № п/п |
| 056 | 4 |
| 145 | 3 |
| 238 | 1 |
| 239 | 2 |
Видно из второй таблицы, что значения ключа шифр в вузе упорядочены по возрастанию. Это позволяет данный индекс рассматривать как упорядоченный последовательный файл и применять к нему рассмотренные методы доступа в разделе «Последовательная организация».
3.4.1.4. Рандомизация
Этот метод доступа имеет несколько названий: перемешивание, рандомизация, хэширование. Общая схема представлена на рисунке.
Область размещения записей файла
К1

Бакет 1
Бакет 2
.......
Бакет Nmax
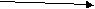

К2
К3


Область размещения записей файла делится на участки – бакеты. При добавлении записей файла в соответствии со значениями первичных ключей Кi алгоритм рандомизации определяет не адрес отдельной записи (как это было в предыдущих случаях), а номер (адрес) бакета. Сама запись размещается в бакете в первом свободном месте – после уже имеющихся в нем записей. Таким образом, записи внутри бакета не упорядочены.
При поиске записи алгоритм рандомизации по первичному ключу определяет вначале номер бакета, в котором должна находиться запись. Затем уже в найденном бакете способом последовательного сканирования делается попытка найти нужную запись.
Алгоритм рандомизации состоит из следующих шагов:
- этот шаг выполняется только для нечисловых значений ключа и состоит в их преобразовании в числовые значения. Для этого каждому символу алфавита, который используется для записи значения ключа, приписывается десятичная цифра от 0 до 9 и ключ переписывается. Например, пусть значения ключа формируются из букв русского алфавита. Припишем им десятичные цифры:
а
(1)
б в г д е ё ж з и й к л м н о п р с т у ф х ц ч ш щ ь ъ ы э ю я
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2
Тогда, например, ключ Сидоров запишется как 8945752 (различие прописных и строчных букв игнорируется). Очевидно, такая замена может привести к тому, что разные нечисловые значения будут иметь одинаковые числовые замены. Это одна из причин потери информации при выполнении алгоритмов рандомизации;
- порядок числового значения ключа приводится к порядку максимального номера бакета. Например, если максимальный номер бакета - четырехзначное число, то числовой ключ 8945752, полученный в предыдущем шаге, должен быть преобразован в четырехзначное число. Для такого преобразования существуют разные способы. Некоторые из них показаны ниже (в предположении, что максимальный номер бакета – четырехзначное число):
- метод квадратов: значение ключа возводится в квадрат. В полученном числе выбирается средняя часть, состоящая из требуемого количества цифр. Например, для числа 8945752 такое преобразование будет иметь вид:
8
 945752 80026478845504 4788;
945752 80026478845504 4788;средняя часть числа,
состоящая из 4 цифр
- сдвиг разрядов: разряды ключа делятся на старшие и младшие и сдвигаются друг к другу так, чтобы число перекрывающихся разрядов соответствовало требуемому числу цифр. Совмещенные цифры складываются. Например, для числа 8945752 такое преобразование будет иметь вид:
8
 945752 894 (13)(16)92 4792;
945752 894 (13)(16)92 4792;
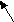
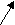
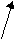 5752
5752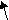
старшие младшие совмещенные результат окончательный
разряды разряды разряды сложения результат совмещенных разрядов
- метод складывания: ключ делится на 3 части, средняя из которых по количеству цифр равна требуемому порядку. Первая и третья части налагаются на среднюю часть и совмещенные цифры складываются. Например, для числа 8945752 такое преобразование будет иметь вид:
8
 945752 9457 (17)47(12) 8473.
945752 9457 (17)47(12) 8473.
 8 25
8 25с
 редняя результат окончательный
редняя результат окончательныйчасть наложенные сложения результат
части числа
Очевидно, рассмотренные методы могут дать одинаковые результаты для разных числовых значений ключа. Это вторая причина потери информации при рандомизации. Выбор того или иного метода из трех рассмотренных выполняется экспериментально: лучшим считается тот метод, при использовании которого бакеты заполняются записями относительно равномерно;
- полученное на предыдущем шаге число умножается на константу С, которая рассчитывается как отношение максимального номера бакета Nmax к максимальному n-разрядному числу, где n – порядок максимального номера бакета. Это позволяет сформировать реальные номера бакетов. Например, пусть максимальный номер бакета – 7000 (это Nmax). Очевидно, n = 4. Тогда упомянутая константа С имеет значение:
С = 7000/9999 = 0,7.
Рассчитаем реальный номер бакета для результата предыдущего шага, полученного методом складывания: 8473 * 0,7 = 5931.
3.4.1.5. Цепь подобных записей
К исходному файлу не предъявляется никаких требований. К нему достраиваются дополнительные файлы – индексы - в количестве, соответствующем числу вторичных ключей. Записи таких файлов имеют два поля: первое – значение вторичного ключа из основного файла, второе – ссылка на первую запись в основном файле с таким же значением вторичного ключа (в качестве ссылки используется порядковый номер записи в файле). Сами записи файла также модифицируются: они дополняются полями в количестве, соответствующем числу вторичных ключей. Каждое поле служит для организации цепочек записей с одним значением вторичного ключа.
Пусть основной файл имеет вид:
сотрудник
| ФИО | ученая степень | научное звание | контактные данные | название (кафедры) | название (должности) |
| Иванов И.И. | к.т.н. | доцент | 234567 | СУиВТ | доцент |
| Петров П.П. | к.т.н. | нет | 456789 | ТАМ | доцент |
| Сидоров С.С. | нет | нет | 123456 | СУиВТ | ассистент |
| Яковлев Я.Я. | д.т.н. | профессор | 345678 | ТАМ | профессор |
Вторичными ключами являются ученая степень, научное звание, название (кафедры), название (должности). Построим индексы для этих ключей:
| ученая степень | № п/п | | научное звание | № п/п | | название (кафедры) | № п/п | | название (должности) | № п/п |
| д.т.н. | 4 | | доцент | 1 | | СУиВТ | 1 | | ассистент | 3 |
| к.т.н. | 1 | | нет | 2 | | ТАМ | 2 | | доцент | 1 |
| нет | 3 | | профессор | 4 | | | | | профессор | 4 |
Как видно из таблиц, каждый индекс содержит поле со всеми значениями соответствующего вторичного ключа из основного файла и поле (озаглавлено № п/п), в котором указывается номер записи основного файла, где впервые встречается соответствующее значение вторичного ключа. Значения вторичных ключей в индексах упорядочены по возрастанию, так что с индексами можно работать как с упорядоченными файлами (в роли первичных ключей таких файлов выступают вторичные ключи основных файлов).
Модифицируем также и основной файл. Для удобства поместим дополнительные поля (они выделены заливкой) справа от соответствующего вторичного ключа. Получим таблицу:
сотрудник
| ФИО | ученая степень | № п/п | научное звание | № п/п | контактные данные | название (кафедры) | № п/п | название (должности) | № п/п |
| Иванов И.И. | к.т.н. | 2 | доцент | - | 234567 | СУиВТ | 3 | доцент | 2 |
| Петров П.П. | к.т.н. | - | нет | 3 | 456789 | ТАМ | 4 | доцент | - |
| Сидоров С.С. | нет | - | нет | - | 123456 | СУиВТ | - | ассистент | - |
| Яковлев Я.Я. | д.т.н. | - | профессор | - | 345678 | ТАМ | - | профессор | - |
Рассмотрим, как выполняется задача поиска нужной записи.
Пусть надо найти фамилии и инициалы всех сотрудников, работающих в должности ассистента. Очевидно, Кдоступ = <название (должности) = ассистент>. Поиск осуществляется последовательным выполнением шагов:
- по индексу для ключа название (должности) определяется запись со значением первого поля, равным ассистент (поскольку индекс – это упорядоченный файл, к нему применяются рассмотренные ранее методы, например, метод последовательного сканирования, анализ работы которых в данном случае не приводится). Это первая запись индекса;
- по полю № п/п выясняется номер записи основного файла с искомым ключом доступа – это запись с номером 3;
- в основном файле выбирается третья запись. Выводится фамилия и инициалы сотрудника – это Сидоров С.С.;
- в соответствии со значением поля № п/п для поля название (должности) в основном файле определяется номер следующей записи основного файла с аналогичным значением вторичного ключа – поскольку данное поле не содержит ссылки, это означает, что цепочка записей закончилась, следовательно, список сотрудников сформирован; алгоритм заканчивает работу.
Если доступ планируется одновременно по нескольким вторичным ключам, можно оптимизировать эту процедуру. Оптимизация состоит в том, что каждый индекс дополняется полем, в котором указывается число записей в цепочке, и тогда вначале обращение осуществляется к тому индексу, в котором длина цепочки минимальна.
Например, основной список представлен таблицей:
сотрудник
| ФИО | ученая степень | № п/п | научное звание | № п/п | контактные данные | название (кафедры) | № п/п | название (должности) | № п/п |
| Иванов И.И. | к.т.н. | 2 | доцент | - | 234567 | СУиВТ | 3 | доцент | 2 |
| Петров П.П. | к.т.н. | - | нет | 3 | 456789 | ТАМ | 4 | доцент | - |
| Сидоров С.С. | нет | - | нет | - | 123456 | СУиВТ | - | ассистент | - |
| Яковлев Я.Я. | д.т.н. | - | профессор | - | 345678 | ТАМ | - | профессор | - |
Индексы модифицированы и показаны в таблицах (дополнительные поля показаны заливкой):
| ученая степень | № п/п | длина цепочки | | научное звание | № п/п | длина цепочки | | название (кафедры) | № п/п | длина цепочки | | название (должности) | № п/п | длина цепочки |
| д.т.н. | 4 | 1 | | доцент | 1 | 1 | | СУиВТ | 1 | 2 | | ассистент | 3 | 1 |
| к.т.н. | 1 | 2 | | нет | 2 | 2 | | ТАМ | 2 | 2 | | доцент | 1 | 2 |
| нет | 3 | 1 | | профессор | 4 | 1 | | | | | | профессор | 4 | 1 |
Значения полей длина цепочки – это количество записей основного файла с соответствующим значением вторичного ключа.
Пусть надо определить, какие сотрудники работают в должности доцентов и не имеют ученой степени. Очевидно, Кдоступ = <название (должности) = доцент, ученая степень = нет). Задача решается следующим образом:
- в индексах для вторичных ключей название (должности) и ученая степень ищутся записи со значениями полей доцент и нет: это, соответственно, записи с номерами 2 и 3;
- анализируется, для какого индекса поле длина цепочки имеет минимальное значение: очевидно, длина цепочки для ключа со значением нет короче, чем для ключа со значением доцент, поэтому для поиска в основном файле определяется ключ ученая степень со значением нет;
- в соответствии со значением поля № п/п выбранного ключа осуществляется обращение к элементу с номером 3 основного файла;
- у выбранного элемента анализируется поле название (должности): его значение равно ассистент: данная запись не удовлетворяет условиям поиска, а потому никакого вывода данных пользователю не происходит;
- в соответствии со значением поля № п/п для поля ученая степень определяется номер следующей записи основного файла с аналогичным значением вторичного ключа. Поскольку это поле не содержит ссылки, это означает, что цепочка записей закончилась, следовательно, список сотрудников сформирован (он пуст); алгоритм заканчивает работу.
3.4.1.6. Инвертированные файлы
Основной файл не изменяется. Строятся индексы в нужном количестве. В индекс включаются все значения соответствующего вторичного ключа, а также все ссылки на записи основного файла с данным значением вторичного ключа.
Пусть основной файл показан в таблице:
сотрудник
| ФИО | ученая степень | научное звание | контактные данные | название (кафедры) | название (должности) |
| Иванов И.И. | к.т.н. | доцент | 234567 | СУиВТ | доцент |
| Петров П.П. | к.т.н. | нет | 456789 | ТАМ | доцент |
| Сидоров С.С. | нет | нет | 123456 | СУиВТ | ассистент |
| Яковлев Я.Я. | д.т.н. | профессор | 345678 | ТАМ | профессор |
Соответствующие индексы показаны в таблицах:
| ученая степень | № п/п | | научное звание | № п/п | | название (кафедры) | № п/п | | название (должности) | № п/п |
| д.т.н. | 4 | | доцент | 1 | | СУиВТ | 1, 3 | | ассистент | 3 |
| к.т.н. | 1, 2 | | нет | 2, 3 | | ТАМ | 2, 4 | | доцент | 1, 2 |
| нет | 3 | | профессор | 4 | | | | | профессор | 4 |
Расположение всех ссылок для некоторого вторичного ключа в одном поле позволяет исключить перебор записей в цепочке записей при их поиске.
Рассмотрим, как выполняется задача поиска нужной записи.
Пусть надо определить список всех сотрудников, работающих в должности доцента, Кдоступ = <название (должности) = доцент>. Поиск осуществляется последовательным выполнением шагов:
- по индексу для ключа (название должности) находится соответствующий элемент: это вторая запись в файле;
- выбираются ссылки для этой записи: это множество {1, 2};
- по основному файлу выбираются последовательно записи с номерами 1 и 2 и выводится содержимое поля ФИО для этих записей; получаем список - Иванов И.И. и Петров П.П. Работа алгоритма закончена.