
Конспект лекций для специальности «Прикладная информатика в экономике»
| Вид материала | Конспект |
- Учебно-методический комплекс для студентов заочного обучения специальности Прикладная, 81.9kb.
- Конспект лекций для специальности «Прикладная информатика в экономике», 535.22kb.
- Конспект лекций для студентов специальности Прикладная информатика (в экономике), 3204.37kb.
- Учебно-методический комплекс для студентов заочного обучения специальности Прикладная, 172.73kb.
- Рабочая учебная программа по Правоведению Для специальности- «Прикладная информатика, 388.83kb.
- Учебно-методический комплекс для студентов заочного обучения специальности Прикладная, 88.44kb.
- Программа по курсу "Математика. Алгебра и геометрия" для специальности 080801 (351400), 143.45kb.
- Учебно-методический комплекс Для специальности 080801 Прикладная информатика (в экономике), 296.07kb.
- Учебно-методический комплекс Для специальности 080801 Прикладная информатика (в экономике), 610.8kb.
- Рабочая программа по дисциплине «Исследование операций в экономике» для специальности, 137.37kb.
Глава 4. Документальные информационные системы
Как отмечалось ранее, информационные массивы таких систем содержат неструктурированные данные произвольного формата. Наиболее представительное множество документальных систем основано на текстовых данных, поэтому дальнейшее изложение относится именно к ним.
Минимальным информационным элементом в документальных ИС является файл. В ответ на запрос пользователя ИС отклик системы содержит не данные, описывающие отдельные факты, как в случае фактографических ИС, а целые файлы (или ссылки на них), релевантные запросу, т.е. отвечающие его смыслу. Выделение смысла текста (или запроса) – самостоятельная очень сложная проблема, которая касается такой области современной информатики как искусственный интеллект, а потому здесь не рассматривается. На практике определение релевантности текста и запроса выполняется, в простейшем случае, на основе совпадения терминов запроса и текста, что, конечно, сильно обедняет результат поиска, поскольку один смысл можно выразить по-разному. При этом в качестве таких терминов могут использоваться как отдельные слова, так и словосочетания. Применяемые для поиска релевантных текстов термины называются также ключевыми словами (или ключами)9.
При организации хранения неструктурированных данных решаются две основные задачи:
- минимизация времени доступа к данным. Это приводит к дополнительным построениям при размещении данных, что требует затрат времени и памяти компьютера;
- уменьшение «шума» отклика ИС, т.е. нахождение данных, наиболее релевантных запросу.
4.1. Методы организации хранения неструктурированных данных
Различают следующие методы хранения неструктурированных данных, организованных в виде файлов:
- последовательные файлы,
- цепочечные файлы,
- инвертированные файлы,
- кластерные файлы.
Совокупность файлов, содержащих текстовые данные, составляет полнотекстовую базу данных – ТБД, т.е. информационные массивы ИС.
4.1.1. Последовательные файлы
Файлы хранятся в произвольном порядке, например, в порядке их поступления. Не определены ни группы, ни классы файлов, нет справочников или других списков, обеспечивающих доступ к любому файлу.
Для нахождения всех файлов, обладающих некоторой характеристикой, требуется просмотр всего массива файлов. Неэффективность данного метода объясняет его практическое неиспользование.
Пусть, например, имеются тексты, которые хранятся в файлах с именами, соответственно, Ф1, Ф2, Ф3, Ф4, содержащие некоторые ключи Кi (на рисунке схематично показаны текстовые файлы, где в тексте среди слов содержатся ключевые слова):
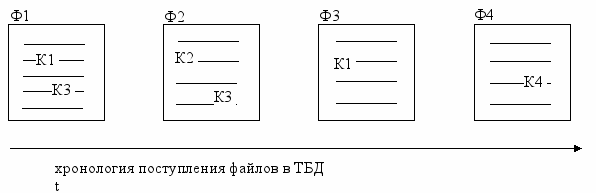
Рассмотрим решение задачи поиска релевантного текста.
Пусть запрос содержит ключевое слово К1, например, компьютер. Тогда алгоритм поиска имеет вид:
- из группы файлов выбирается первый файл Ф1 и соответствующий текст сканируется от начала – ищется совпадение слов текста с заданным ключевым словом;. Поскольку совпадение установлено, сканирование данного файла прекращается, пользователю выдается первый релевантный текст из файла Ф1;
- из группы выбирается файл Ф2 и выполняется его сканирование от начала до конца. Совпадений нет, выполняется переход к анализу файла Ф3;
- из группы файлов выбирается файл Ф3 и соответствующий текст сканируется. Выявляется совпадение, сканирование файла прекращается, и он выдается пользователю как второй релевантный текст. Выполняется переход к анализу файла Ф4;
- из группы выбирается файл Ф4 и выполняется его сканирование от начала до конца. Совпадений нет, делается попытка перехода к анализу следующего файла, а поскольку все файлы просмотрены, алгоритм заканчивает работу.
Подобный метод организации хранения файлов и последующий поиск требуемых данных осуществляется в операционных системах семейства Windows и характеризуется большими временными затратами.
4.1.2. Цепочечные файлы
Файлы разделены на множества так, что все элементы одного множества отождествлены с помощью ключевого слова. По аналогии со структурированными данными можно говорить о подобии текстов, отождествленных с помощью одного ключа. Внутри каждого множества файлы соединены ссылками, а для доступа к первому элементу в цепочке организуются справочники - индексы. В роли ссылок могут выступать, в частности, полные имена файлов.
Пусть ТБД содержит те же файлы, что и в предыдущем примере. Индекс – это структурированный файл вида:
| Ключевое слово | Ссылка |
| К1 | Ф1 |
| К2 | Ф2 |
| К3 | Ф1 |
| К4 | Ф4 |
К
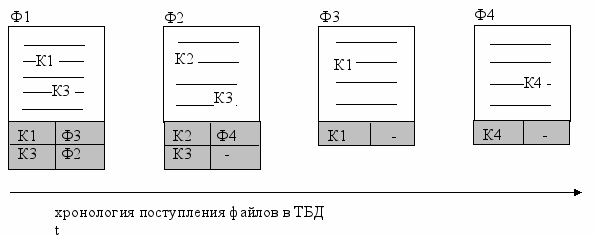 роме того, претерпевают изменения и сами файлы Ф1 – Ф4: они содержат описания цепочек подобных файлов, размещенные, например, в конце самих текстов (показаны заливкой):
роме того, претерпевают изменения и сами файлы Ф1 – Ф4: они содержат описания цепочек подобных файлов, размещенные, например, в конце самих текстов (показаны заливкой): Из рисунка видно, что структура этих описаний соответствует структуре самого индекса: первое поле – это ключевое слово, а второе – ссылка на файл, следующий в цепочке подобных текстов.
Рассмотрим, как решается задача поиска релевантного текста при такой организации.
Пусть запрос по-прежнему содержит ключевое слово К1. Тогда алгоритм просмотра имеет вид:
- по индексу определяется элемент со значением ключевого слова К1;
- по полю ссылки находится имя файла, первого в цепочке файлов, содержащих данное слово – это Ф1; выводится содержимое данного файла;
- по полю ссылки для ключевого слова К1 файла Ф1 определяется имя файла, следующего в цепочке ключевого слова К1, – это Ф3;
- выводится содержимое файла Ф3;
- по полю ссылки для ключевого слова файла Ф3 определяется имя файла, следующего в цепочке ключевого слова К1. Поскольку ссылка пуста, цепочка закончена, и алгоритм прекращает работу.
4.1.3. Инвертированные файлы
Этот способ организации текстовых файлов является развитием предыдущего: в справочник включаются все адресные ссылки, соответствующие тому или иному ключевому слову. Одновременно адресные ссылки исключаются из самих текстовых файлов. Тогда ТБД из предыдущего раздела при данной организации хранения будет иметь в составе следующие составляющие:
- текстовые файлы Ф1, Ф2, Ф3, Ф4 вида:
- индекс вида:
| Ключевое слово | Ссылки |
| К1 | Ф2, Ф3 |
| К2 | Ф2 |
| К3 | Ф1, Ф2 |
| К4 | Ф4 |
Как видно, поле Ссылки индекса содержит список ссылок на все файлы, содержащие то или иное ключевое слово.
Рассмотрим решение задачи поиска релевантного текста.
Пусть запрос содержит ключевое слово К1. Тогда алгоритм просмотра имеет вид:
- по индексу определяется строка, содержащая данное ключевое слово; по полю Ссылки выбираются имена файлов ТБД, которые характеризуются данным ключевым словом, – это файлы с именами Ф2 и Ф3;
- средствами файловой системы выполняется поиск и вывод текстов файлов пользователю. Алгоритм заканчивает работу.
Рассмотренный метод позволяет легко решать задачи поиска по сложным запросам.
Пусть запрос содержит ключевые слова К1, К3, связанные оператором «или», т.е. пользователю требуется найти тексты, содержащие либо слово К1, либо слово К3. Используя предыдущий алгоритм, находим файлы, релевантные запросу:
для К1 – {Ф1, Ф3};
для К3 – {Ф1, Ф2}.
Тогда множество файлов, удовлетворяющих запросу в целом, соответствует объединению полученных множеств:
К1К3 {Ф1, Ф3}{Ф1, Ф2} = {Ф1, Ф2, Ф3}.
Пусть запрос содержит ключевые слова К1, К3, связанные оператором «и», т.е. пользователю требуется найти тексты, содержащие одновременно слова К1 и К3. Используя известный алгоритм, находим файлы, релевантные запросу:
для К1 – {Ф1, Ф3};
для К3 – {Ф1, Ф2}.
Тогда множество файлов, удовлетворяющих запросу в целом, соответствует пересечению полученных множеств:
К1К3 {Ф1, Ф3}{Ф1, Ф2} = {Ф1}.
4.1.4. Кластерные файлы
Тексты делятся на группы - кластеры родственных текстов, для чего исследуется подобие ключевых слов, характеризующих каждый текст. Тогда в один кластер включаются тексты, которые оказались подобны друг другу. Внутри кластера тексты могут быть организованы любым из рассмотренных ранее способов. Каждый кластер описывается множеством ключевых слов, которые входят в состав профиля кластера (формально определяется далее). В описание включается также адресная ссылка на соответствующий кластер. При хранении кластер может отождествляться с папкой (в терминологии операционной системы Windows’xx).
Пусть ТБД содержит файлы Ф1 – Ф4, которые входят в состав двух кластеров С1 и С2 следующим образом: С1 = {Ф2, Ф4}, С2 = {Ф1, Ф2, Ф3}. Профили П1 и П2 кластеров С1 и С2, соответственно, имеют в составе ключевые слова: П1 = {К2, К4}, П2 = {К1, К3}. Файлы внутри кластеров имеют последовательную организацию.
Тогда ТБД имеет в составе следующие компоненты:
- описание кластеров в виде индекса, где в графе Ссылка заданы адреса кластеров (т.е. имена папок), а в графу Ключевое слово включен список ключевых слов, формирующих профили кластеров;
| Ключевое слово | Ссылка |
| К1 | С2 |
| К2 | С1 |
| К3 | С2 |
| К4 | С1 |
- текстовые файлы Ф1 – Ф4, распределенные по кластерам С1 и С2:
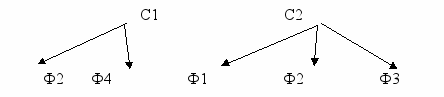
Рассмотрим решение задачи поиска релевантного текста.
Пусть запрос содержит ключевое слово К1. Тогда алгоритм просмотра:
- по индексу находится элемент с заданным ключом;
- по полю Ссылка определяется нахождение кластера, содержащего требуемый текст, – это кластер С2;
- в кластере С2 ищется текст (тексты) с нужным ключевым словом. При этом применяются методы поиска, рассмотренные ранее для последовательной организации. Такими текстами являются тексты в файлах Ф1 и Ф3.
Следует отметить, что наиболее употребляемыми из рассмотренных методов являются инвертированные и кластерные файлы, поэтому дальнейшее изложение ориентировано на эти способы хранения текстовых файлов.