
Конспект лекций для специальности «Прикладная информатика в экономике»
| Вид материала | Конспект |
- Учебно-методический комплекс для студентов заочного обучения специальности Прикладная, 81.9kb.
- Конспект лекций для специальности «Прикладная информатика в экономике», 535.22kb.
- Конспект лекций для студентов специальности Прикладная информатика (в экономике), 3204.37kb.
- Учебно-методический комплекс для студентов заочного обучения специальности Прикладная, 172.73kb.
- Рабочая учебная программа по Правоведению Для специальности- «Прикладная информатика, 388.83kb.
- Учебно-методический комплекс для студентов заочного обучения специальности Прикладная, 88.44kb.
- Программа по курсу "Математика. Алгебра и геометрия" для специальности 080801 (351400), 143.45kb.
- Учебно-методический комплекс Для специальности 080801 Прикладная информатика (в экономике), 296.07kb.
- Учебно-методический комплекс Для специальности 080801 Прикладная информатика (в экономике), 610.8kb.
- Рабочая программа по дисциплине «Исследование операций в экономике» для специальности, 137.37kb.
4.2. Методы индексирования
Как видно из описаний методов организации ТБД, в них активно используются ключевые слова. Задача выделения в том или ином тексте ключевых слов имеет самостоятельное значение и рассматривается в данном разделе.
Выделение ключевых слов в тексте называется его индексированием. Эта процедура сводится к последовательным действиям:
- выделение из текста всех слов на основании различных разделителей (пробелов, знаков препинания и т.д.). При этом в состав выделенных слов попадают такие, которые не отвечают смыслу ключевого слова, например, союзы, предлоги, числительные и другие служебные слова;
- удаление из полученного списка упомянутых служебных слов. Они известны для каждого естественного языка и заранее включаются в так называемые стоп-словари;
- нормализация оставшихся слов, которая состоит в приведении существительных и прилагательных в единственное число, именительный падеж, глагола – в неопределенную форму, причастий и деепричастий – в неопределенную форму глагола и т.д. Кроме того, средствами морфологического анализа слова возможно выделение его основы и использование ее в качестве ключевого слова. Для этого используются обширные лингвистические данные, и вся эта задача в целом носит прикладной лингвистический характер, а потому в данном пособии не рассматривается. В результате получается список ключевых слов (или их основ), подобный тому, что был использован в приведенных ранее примерах (внимательный читатель заметил, что ключевые слова из справочников отличались местами от тех, которые встречались в исходных текстах);
- для придания бóльшей значимости выделенным словам присваиваются весовые коэффициенты (веса), которые позволяют числовым образом оценить, насколько хорошо данное слово отражает смысл текста в целом. На практике, как правило, применяются не просто списки ключевых слов, как это было сделано в предыдущих примерах, а списки взвешенных ключевых слов. Методы назначения весов могут быть статистическими и позиционными и рассматриваются далее.
Таким образом, приведенные ранее примеры упрощали представление индексов, а также процедуры просмотра и добавления новых текстов в ТБД: на самом деле они включают и используют веса ключевых слов.
В результате описанных действий формируется список индексационных терминов (далее – терминов) – это ключевые слова, снабженные весами.
4.2.1. Позиционные методы назначения весов
На значение веса термина влияют следующие факторы:
- более значимыми являются термины, входящие в заглавие всего текста или его разделов, в начальные абзацы и т.д.;
- повышаются веса терминов, входящих в толковые словари по некоторой предметной области, значимой или совпадающей с предметной областью.
К сожалению, в литературе отсутствуют публикации аналитических зависимостей веса термина и его позиции в тексте. Решение данной задачи выполняется эвристическими методами на усмотрение разработчиков соответствующего программного обеспечения.
4.2.2. Статистические методы назначения весов
Используют частотные параметры терминов tk в тексте Di, которые характеризуют частоту встречаемости того или иного слова в том или ином тексте. Эти параметры называют частотами и обозначают fik, где i – обозначение текста, k – обозначение термина. Следует иметь в виду, что методы используют абсолютную частоту терминов, т.е. число их появлений. Данные методы включают частотные модели; модель, учитывающую различительную силу термина, и ее модификацию; модель, использующую динамическую оценку информативности.
4.2.2.1. Частотные модели
В применение частоты для оценки значимости термина вкладывают следующий смысл: чем чаще используется тот или иной термин, тем теснее он связан с семантикой текста. Этот тезис побуждает связать вес wik термина tk в тексте Di напрямую с частотой, т.е. wik = fik. Однако этого делать нельзя по двум причинам:
- бóльшей частотой могут обладать служебные слова типа предлогов, союзов и т.п., которые не связаны с выражением семантики текста;
- минимальной частотой могут характеризоваться «узкие» термины, которые хорошо отражают семантику текста.
По этим соображениям формула для расчета веса термина приобретает вид:
wik = fik* К,
где К – коэффициент, который рассчитывается по разным зависимостям в соответствии с разновидностью частотных моделей.
Так, модель, использующую текстовую частоту термина, определяет К:
К = IDFk,
где IDFk (Inverse Document Frequency) – обратная частота tk в наборе из n текстов:
IDFk =
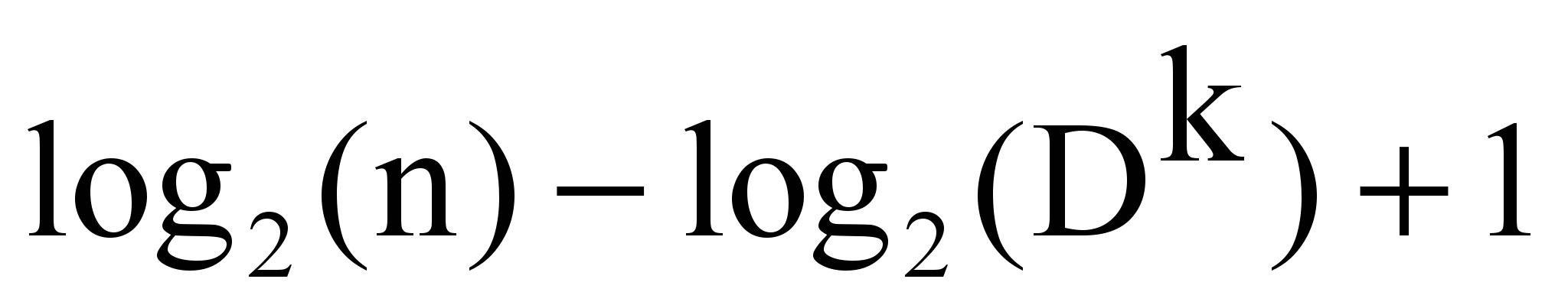 ,
, Dk – текстовая частота - число текстов набора из n, в которых есть tk.
Модель, учитывающая соотношение «сигнал-шум», рассчитывает К как:
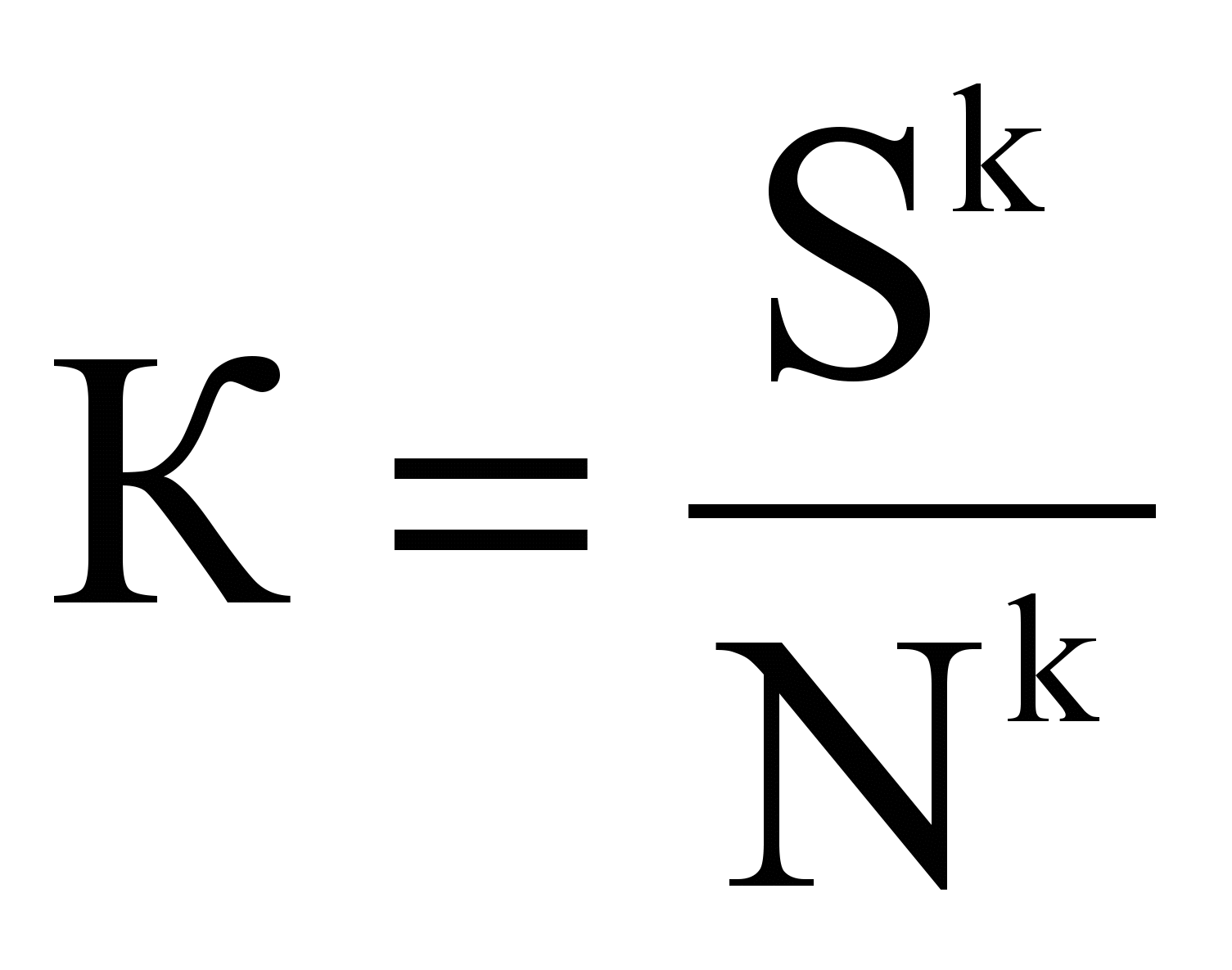 ,
, где Nk – шум термина tk в наборе из n текстов:
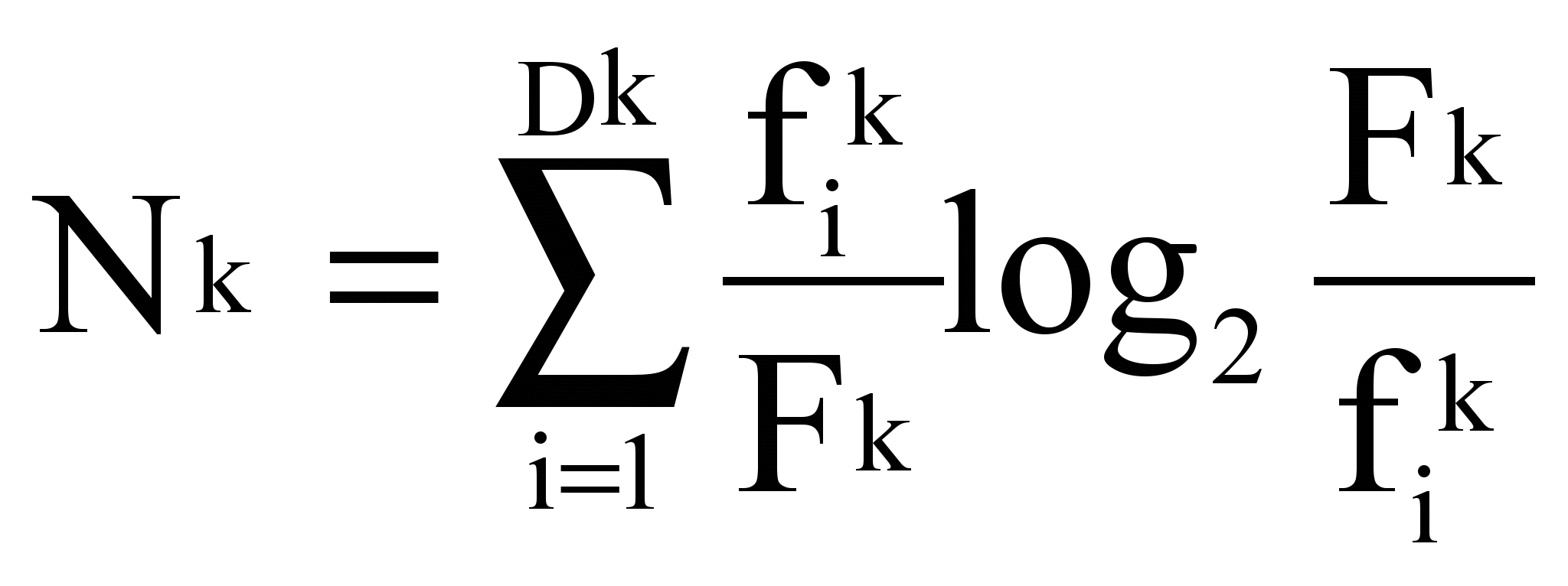 ,
, 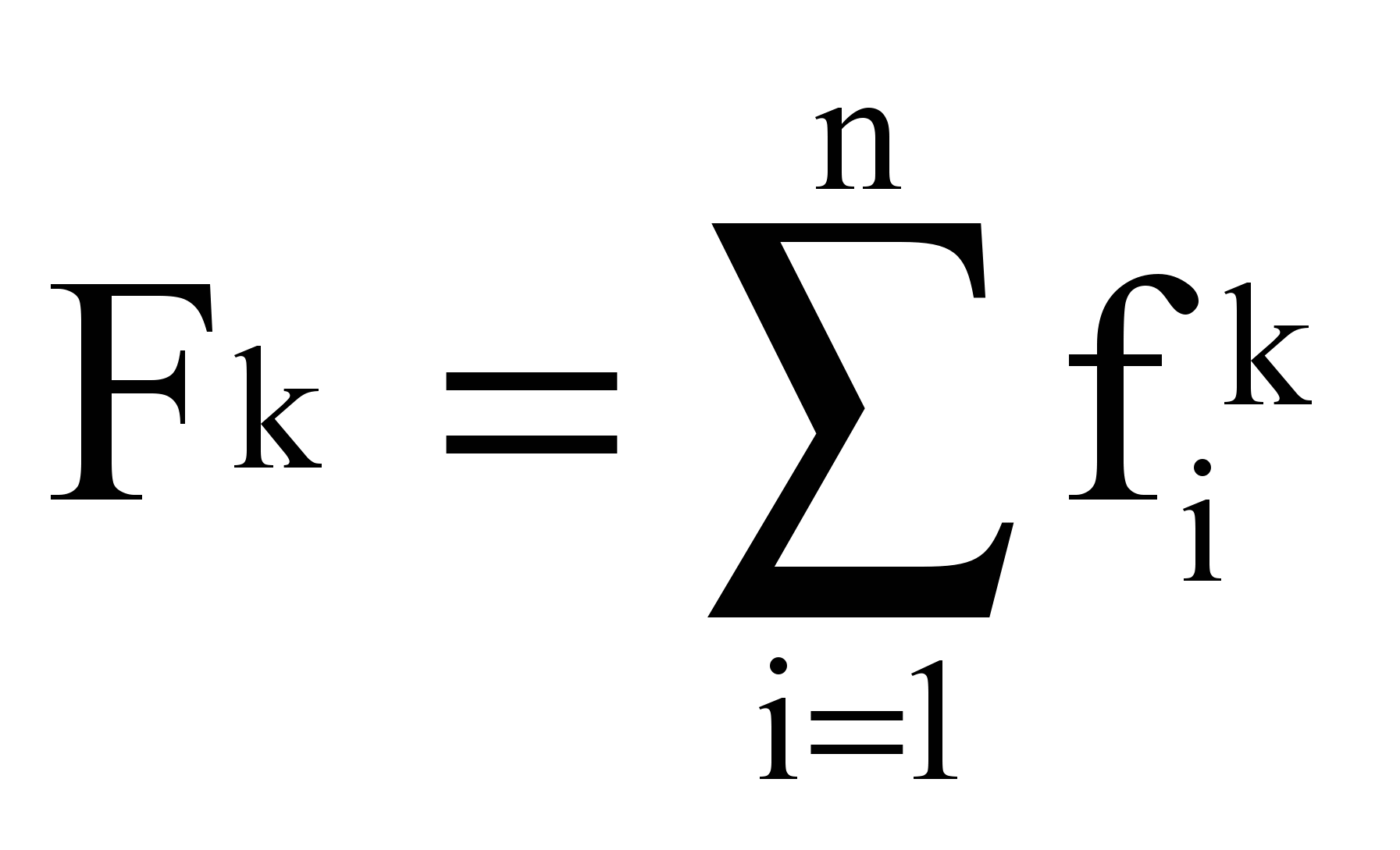 - суммарная частота термина tk в наборе из n текстов,
- суммарная частота термина tk в наборе из n текстов,Sk - сигнал термина tk в наборе из n текстов:
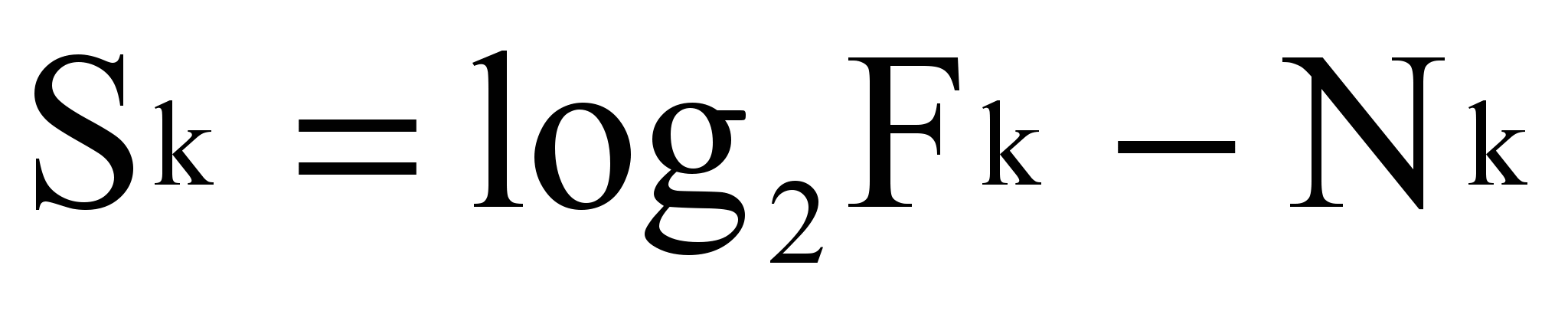 .
. Модель, учитывающая распределение частоты термина, определяет К по формуле:
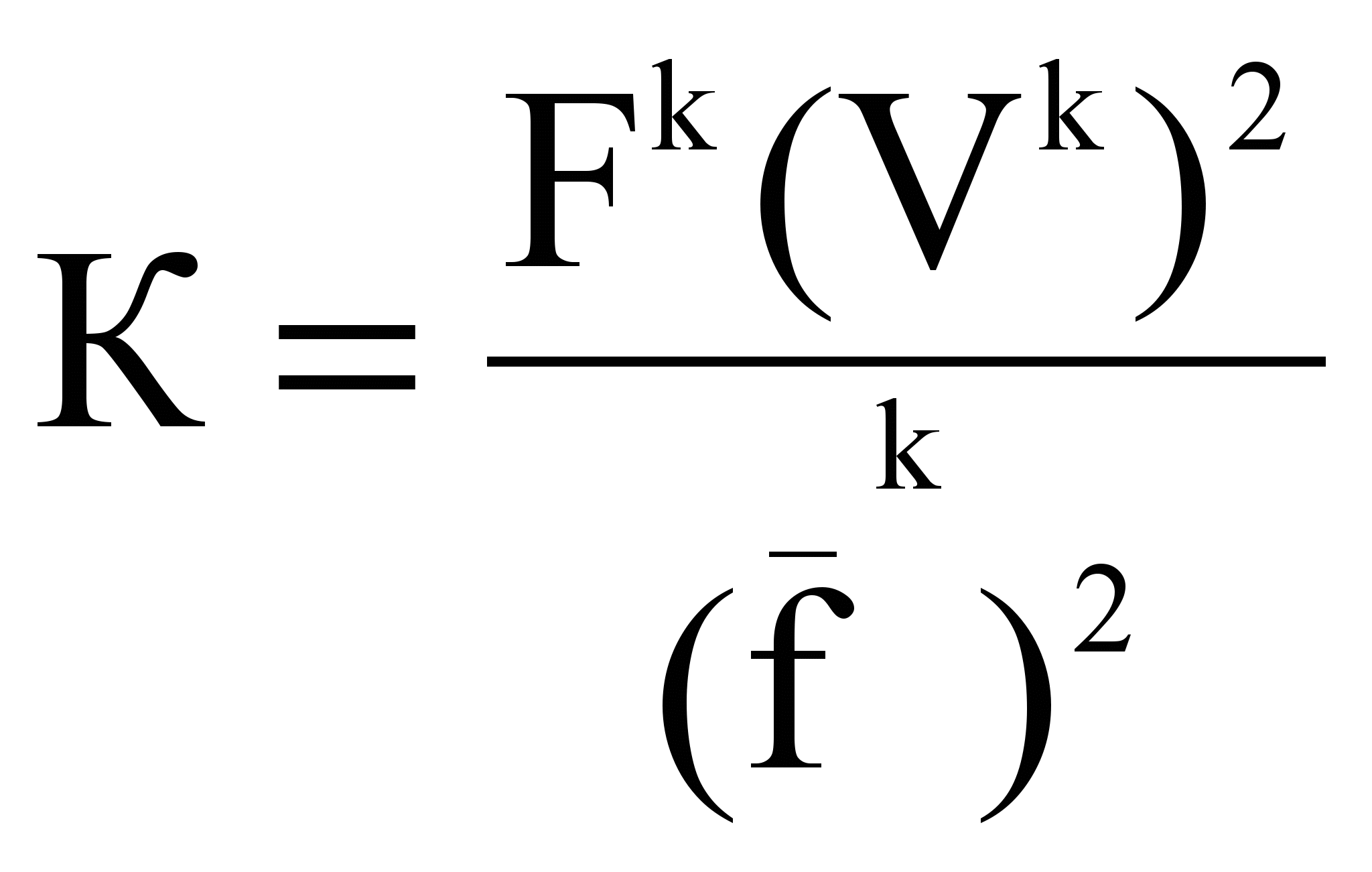 ,
, где
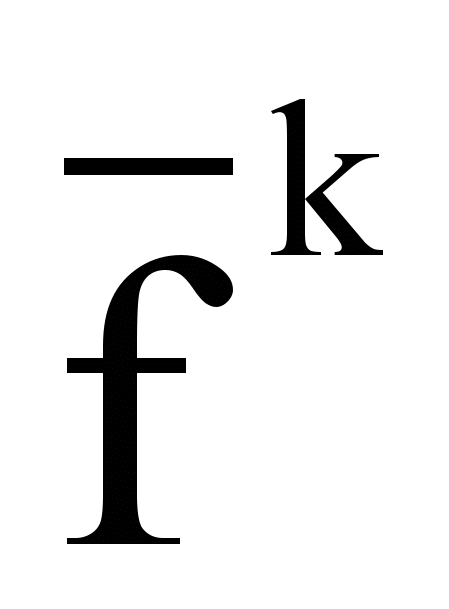 - средняя частота термина tk в наборе из n текстов:
- средняя частота термина tk в наборе из n текстов: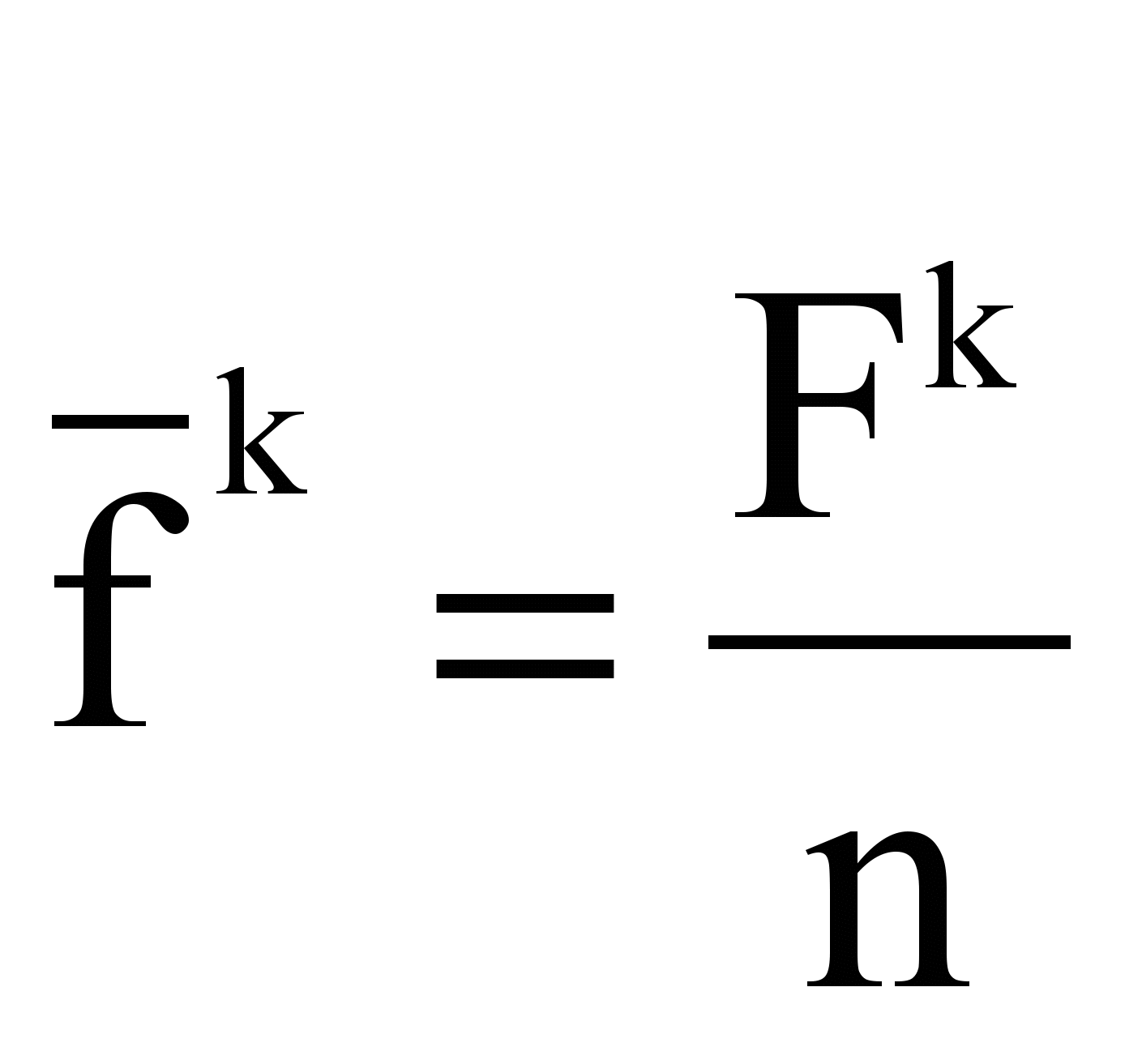 ,
, (Vk)2 - среднеквадратическое уклонение термина tk:
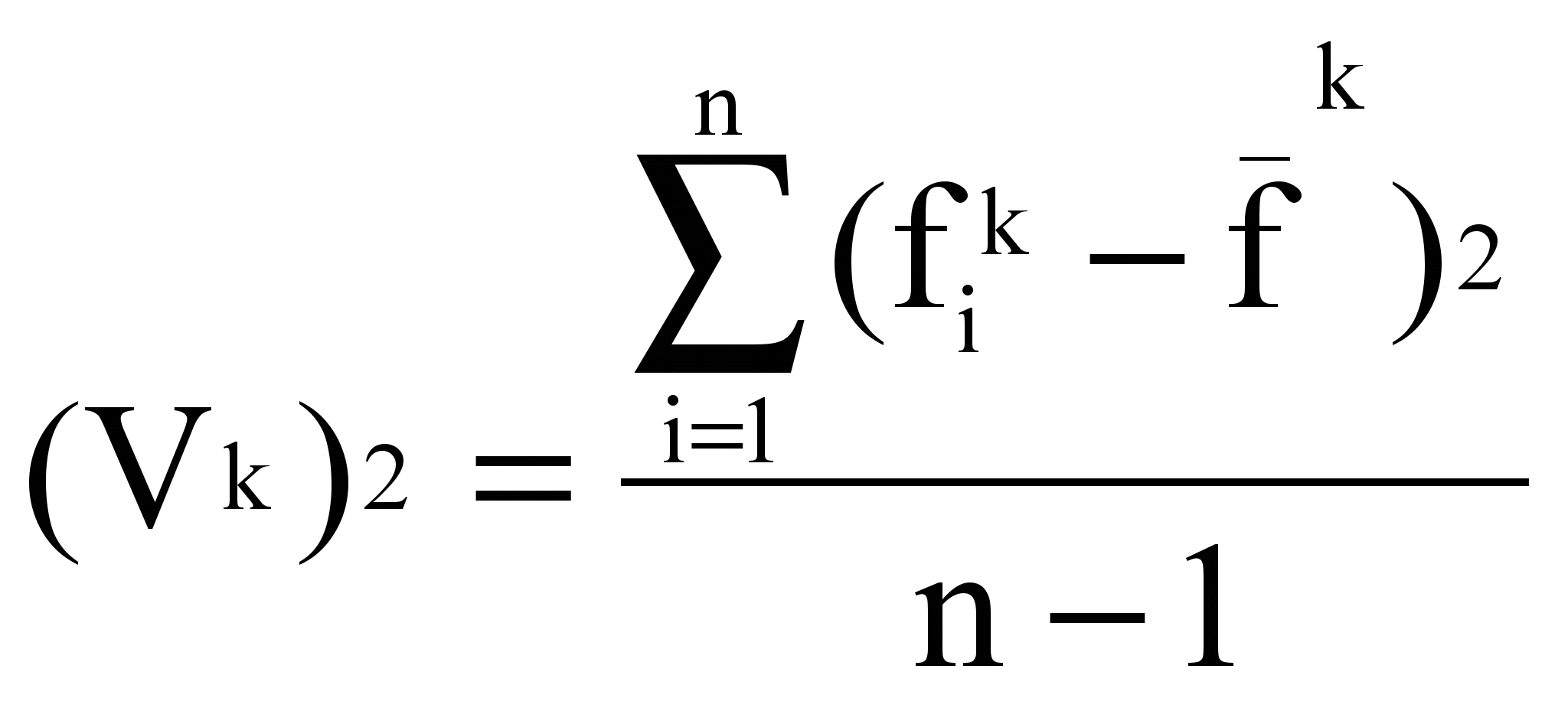 .
. 4.2.2.2. Модель, учитывающая различительную силу термина
В этой модели «хорошим», т.е. имеющим бóльший вес, считается термин, уменьшающий коэффициент подобия текстов. Вес термина здесь также прямо пропорционален его частоте, однако в расчете коэффициента К учитывается роль термина в усилении или уменьшении подобия текстов, что исключает данный метод из числа частотных.
Введем некоторые понятия:
- вектор Vi текста Di: Vi = {(tk, fik)} или Vi = {(tk, wik)};
- коэффициент подобия S(Di, Dj) текстов Di и Dj:
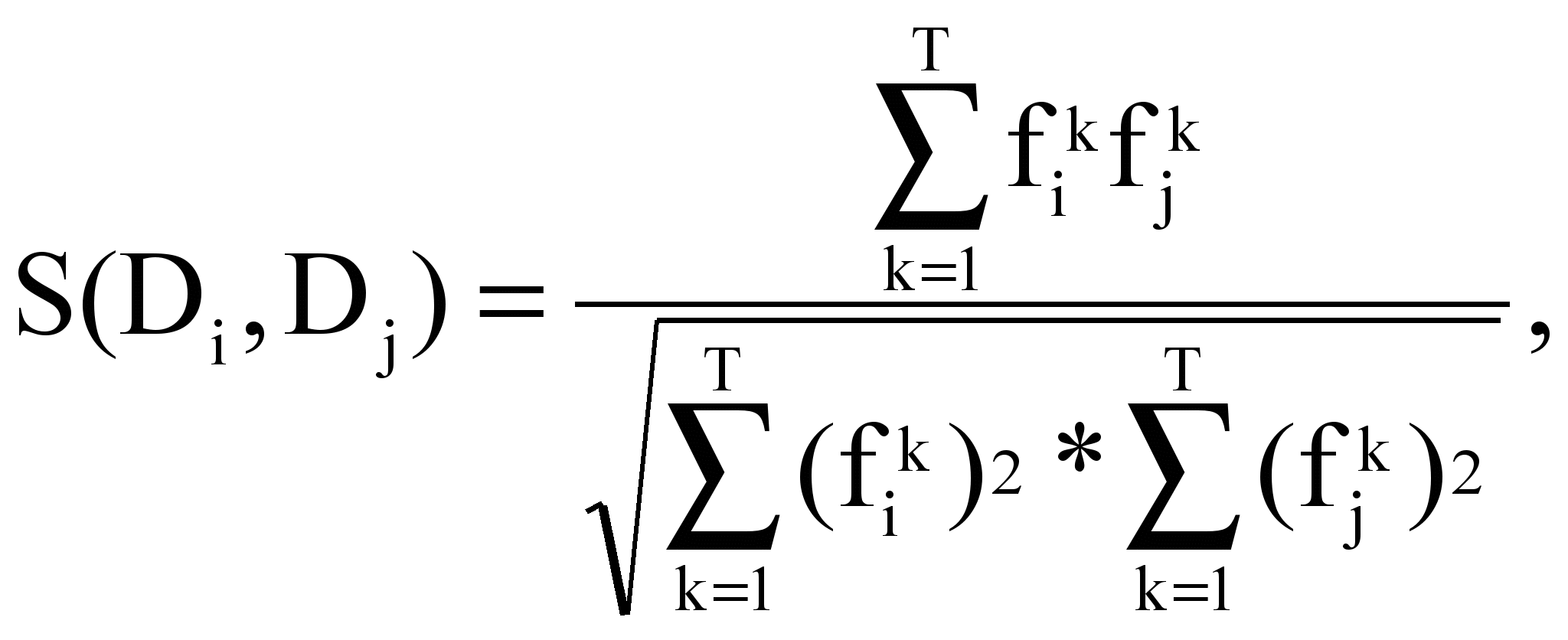
где T = |{tk}| - число индексационных терминов.
Коэффициент подобия принимает значения от 0 до 1: при 0 тексты различны, при 1 – полностью идентичны (по смыслу).
В данной модели К = DVk
где
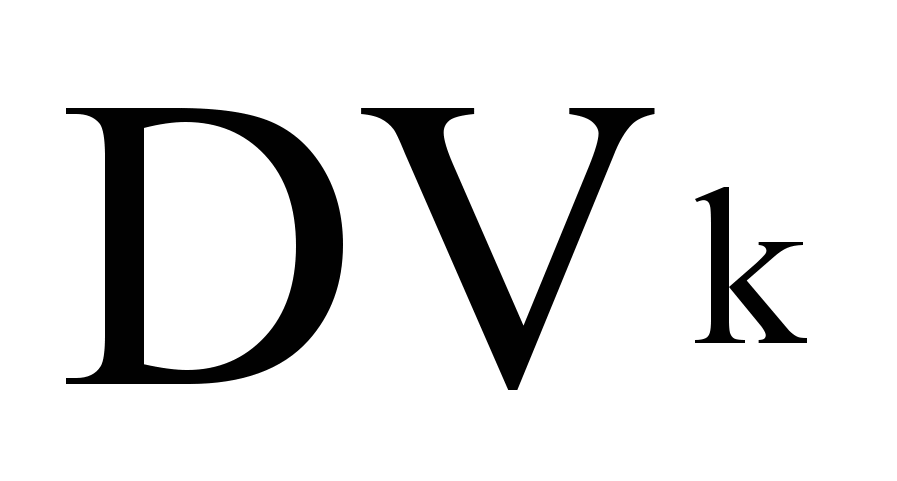 - различительная сила (Difference Volume) термина tk:
- различительная сила (Difference Volume) термина tk: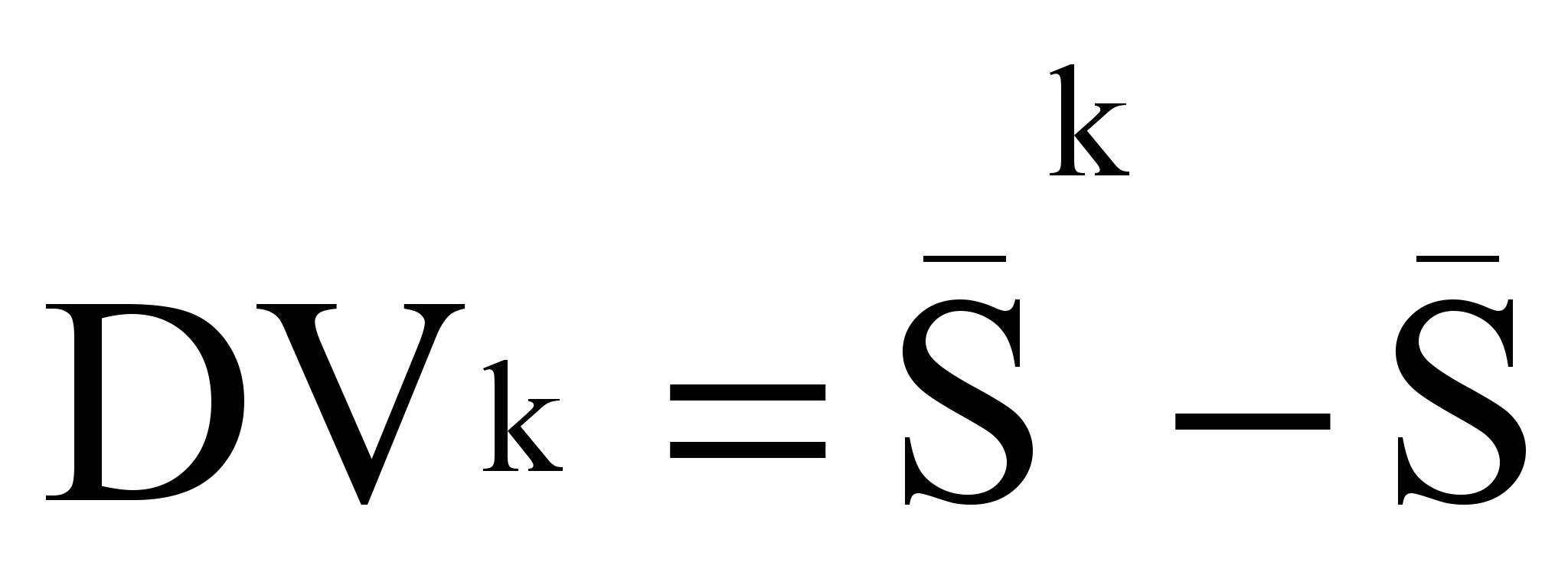 ,
, 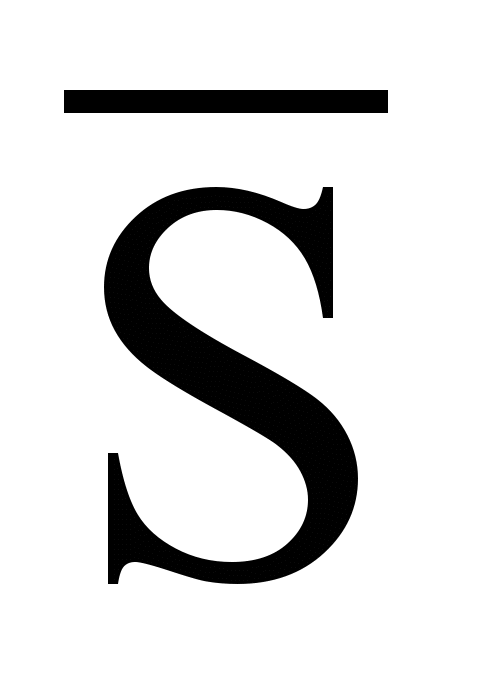 - среднее значение коэффициента попарного подобия текстов данного набора в присутствии термина tk:
- среднее значение коэффициента попарного подобия текстов данного набора в присутствии термина tk: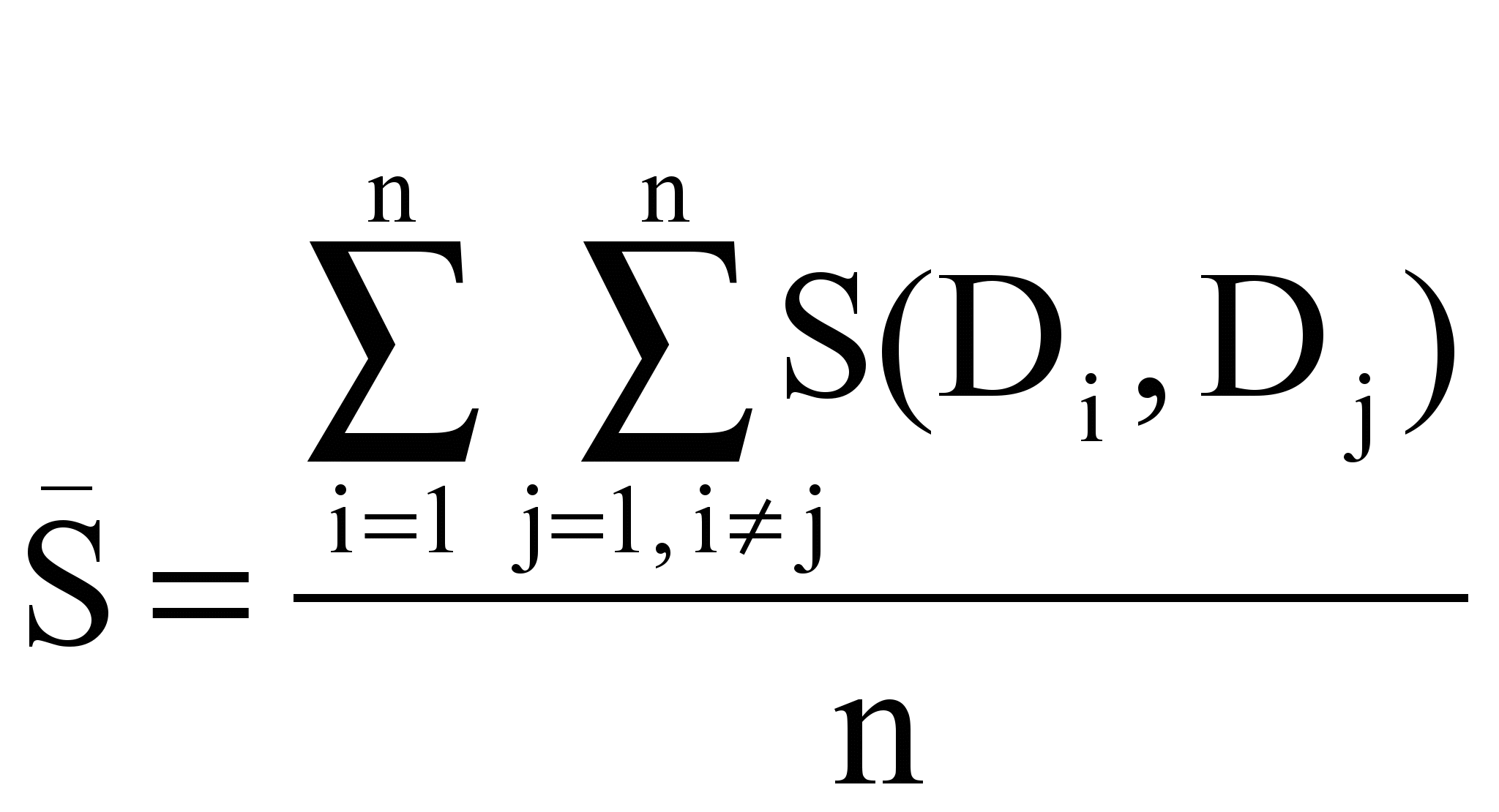 ,
, 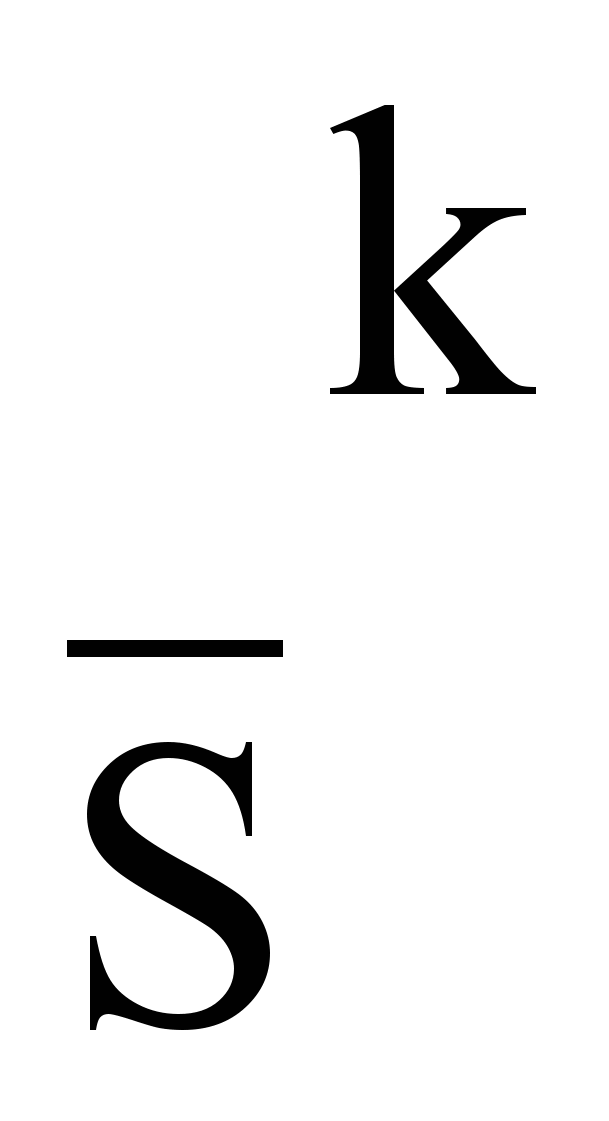 - то же в отсутствие термина tk.
- то же в отсутствие термина tk.Недостатком данной модели является то, что для вычисления средних попарных подобий текстов из набора n текстов требуется n2 операций. Модификация этого метода использует понятие пространства текстов и его характеристик - профиля и плотности пространства текстов.
Пространство текстов – множество текстов, каждый из которых характеризуется вектором. Профиль П пространства из n текстов – это виртуальный текст, вектор которого VП определяется как:
VП = {(tПk, fПk)},
где {tпk} =
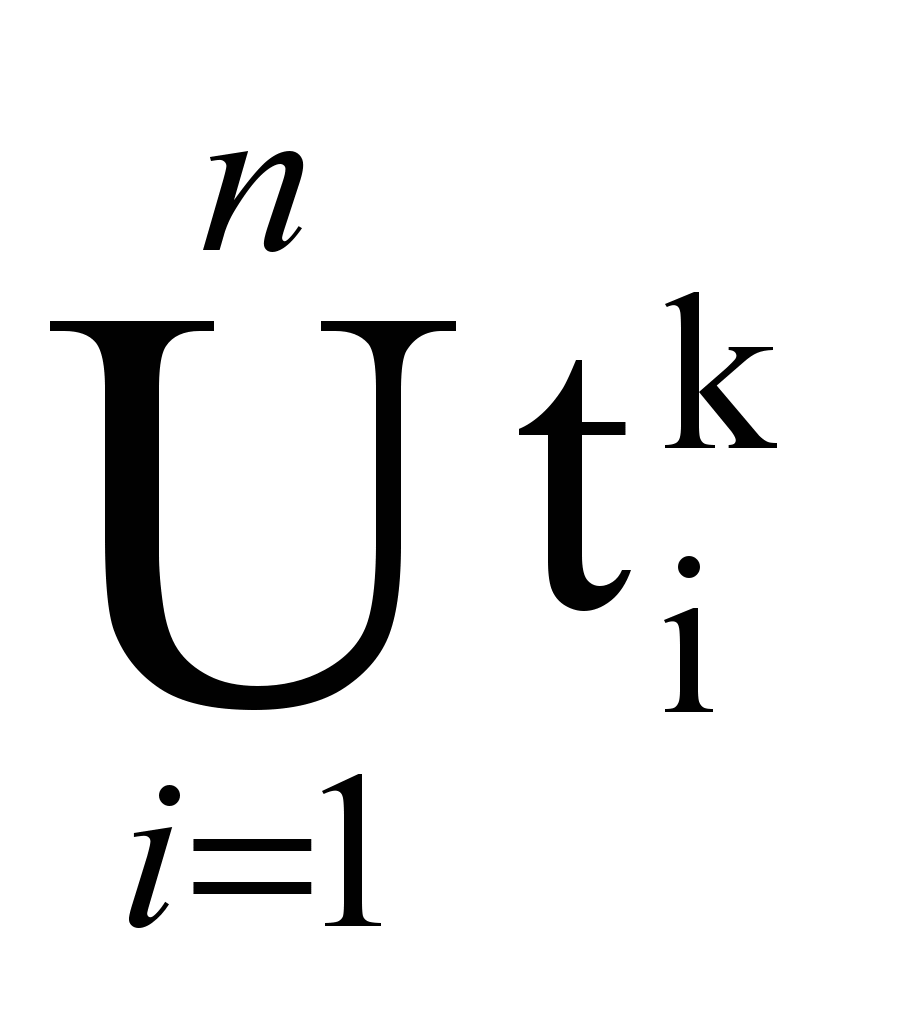 , т.е.множество {tпk} индексационных терминов есть объединение индексационных терминов текстов набора,
, т.е.множество {tпk} индексационных терминов есть объединение индексационных терминов текстов набора, 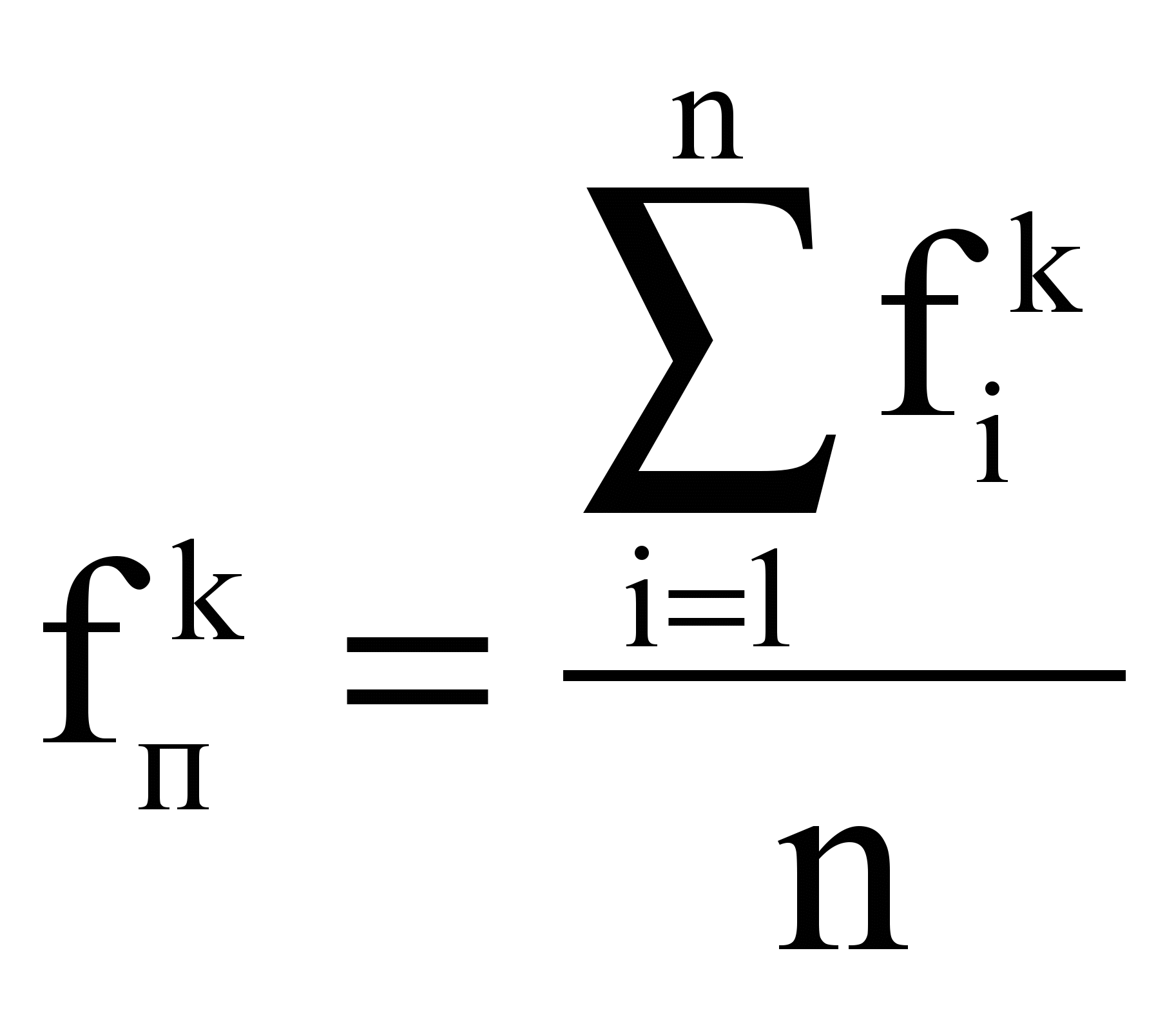 , т.е. частоты терминов есть усредненные частоты терминов по текстам набора.
, т.е. частоты терминов есть усредненные частоты терминов по текстам набора. Плотность Q пространства текстов:
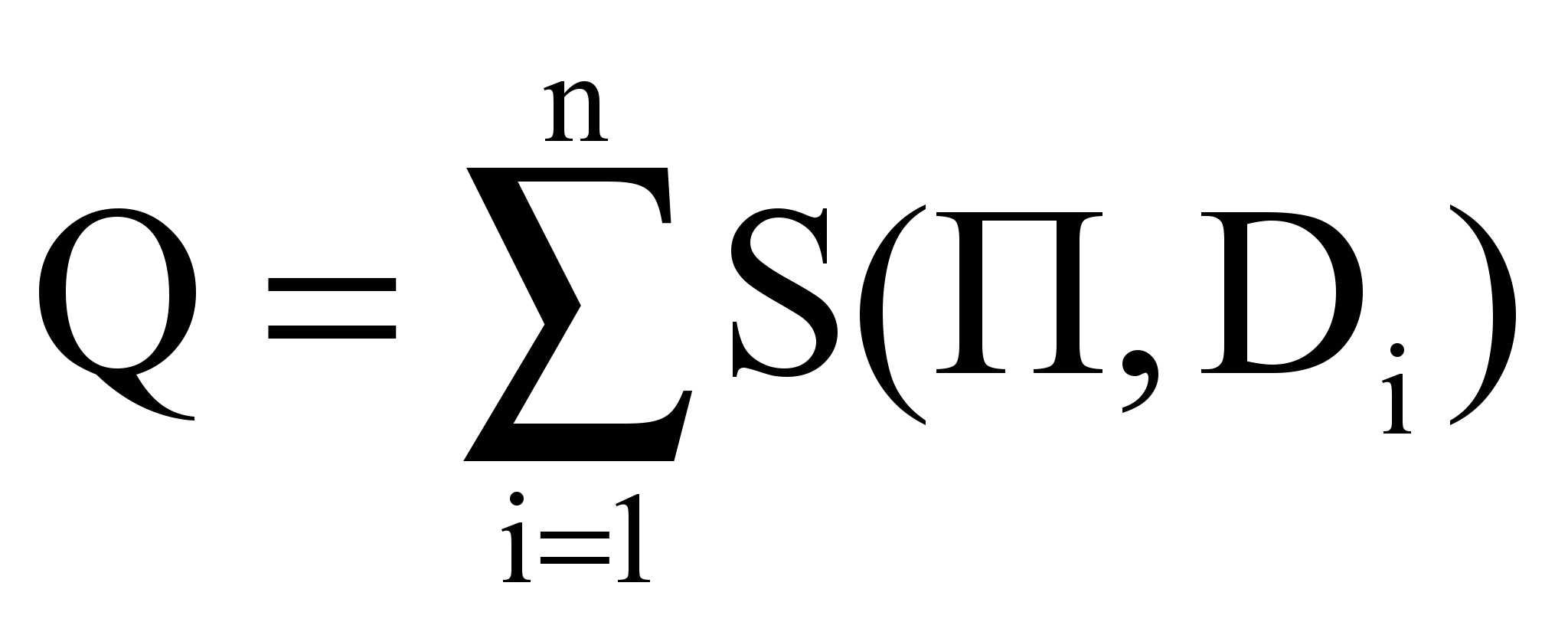 ,
,где S(П,Di) – коэффициент подобия профиля и текста Di:
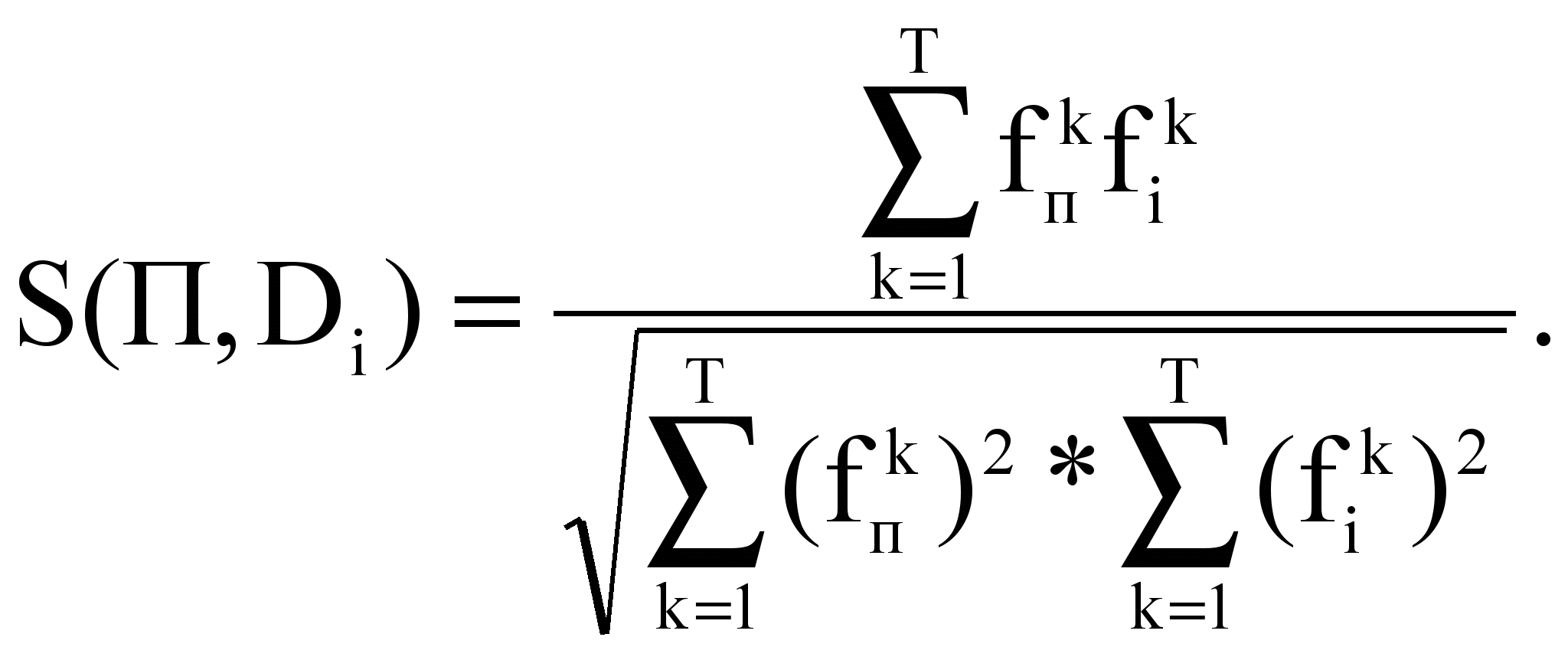
Чем больше Q, тем больше сходство между текстами набора.
С использованием плотности пространства Q можно по другому определить различительную силу DVk термина tk:
DVk = Qk – Q,
где Qk – плотность пространства текстов, когда термин tk исключен из всех текстов набора n,
Q - плотность пространства текстов в присутствии термина tk.
4.2.2.3. Модель, использующая динамическую оценку информативности
Вес wik термина tk в тексте Di определяется как:
wik = IVik,
где IVik – информативность (Information Value) термина tk в тексте Di, принимает значения от 0 до 2.
И
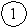 нформативность того или иного термина определяется экспериментально, а первоначально всем терминам приписываются одинаковые значения информативности, например, равные 1 (точка на рисунке). Таким образом, начальными условиями для динамического назначения информативности для каждого tik являются: IVik = 1 и xik = 0. Тогда в случае полезности термина в процессе его использования его информативность увеличивается, а в случае бесполезности – уменьшается, причем указанные изменения имеют синусоидальный характер.
нформативность того или иного термина определяется экспериментально, а первоначально всем терминам приписываются одинаковые значения информативности, например, равные 1 (точка на рисунке). Таким образом, начальными условиями для динамического назначения информативности для каждого tik являются: IVik = 1 и xik = 0. Тогда в случае полезности термина в процессе его использования его информативность увеличивается, а в случае бесполезности – уменьшается, причем указанные изменения имеют синусоидальный характер.

 IV IV=1+sin(x)
IV IV=1+sin(x)
 2
2

 1
1  0 -/2 0 /2 x
0 -/2 0 /2 xУвеличение (+) или уменьшение (-) информативности выполняется по формуле
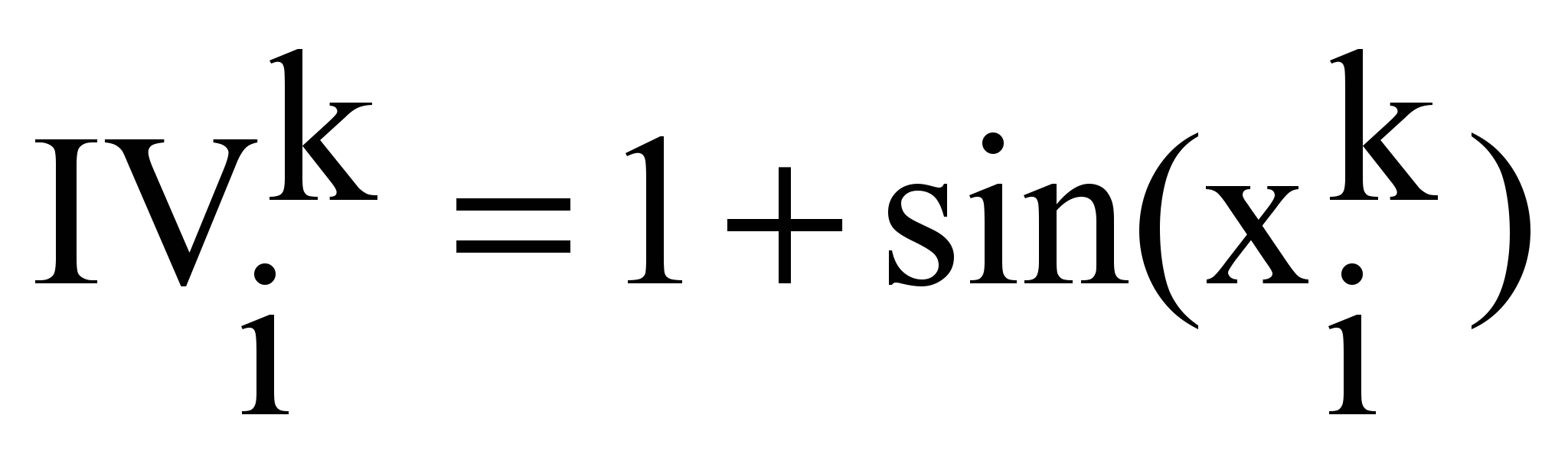 ,
, где
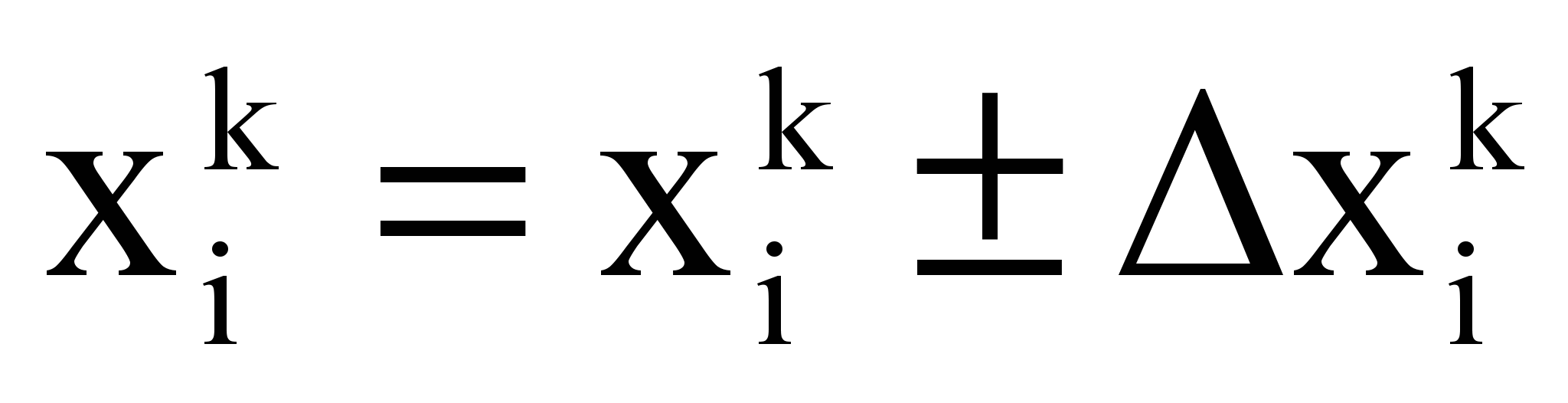 ,
,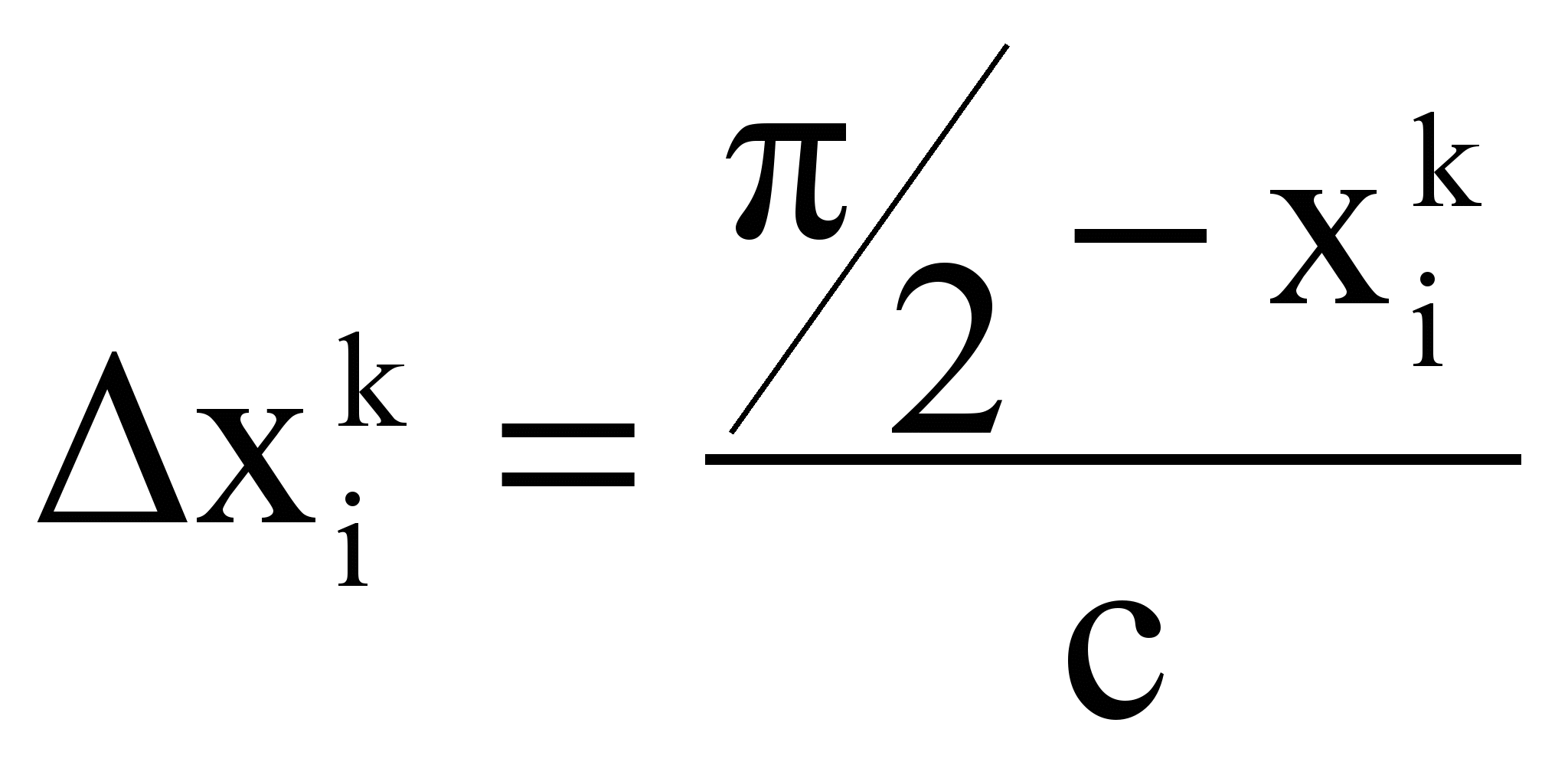 ;
;c – константа, имеющая смысл: число экспериментов для установления информативности термина.
Таким образом, в результате индексирования набора из n текстов (любым из рассмотренных методов) формируется справочник со структурой:
| Термин tk | Текст Di | |||
| Ф1 | Ф2 | ... | Фn | |
| t1 | w11 | w21 | | wn1 |
| t2 | w12 | w22 | | wn2 |
| ... | | | | |
| tT | w1T | w2T | | wnT |
Такие справочники характерны для инвертированных файлов.