
М. В. Ломоносова В. И. Добреньков, А. И. Кравченко методы социологического исследования учебник
| Вид материала | Учебник |
- Незарегистрированный брак как социальный механизм формирования брачно-семейных отношений, 370.79kb.
- Новые поступления литературы в библиотеку Ургупс в декабре 2006 года с социология, 276.4kb.
- Рабочий план социологического исследования. Функции и основные элементы программы социологического, 17.2kb.
- Программа социологического исследования. 27 Методы сбора социологической информации, 666.33kb.
- Гергенрейдер Татьяна Владимировна программа А. И. Кравченко «Обществознание», учебник, 53.33kb.
- Правительстве Российской Федерации ; под ред. О. И. Лаврушина. 7-е изд., перераб, 187.02kb.
- Особенности программы исследования кадровой деятельности. Методы социологического анализа, 29.53kb.
- Автор программы: Даудрих Н. И. Рекомендована секцией умс, 522.38kb.
- Программа дисциплины «Модели объяснения и логика социологического исследования» для, 127.71kb.
- Отчет о ходе и результате социологического исследования. Анкета (опросный лист), 138.6kb.
В таблицах случайных чисел все числа включены в таблицу случайным образом. Единицам совокупности присваивают порядковые номера. В таблице выбирают любую начальную точку и, двигаясь в произвольном направлении и произвольно меняя направление движения, выбирают необходимое количество номеров из числа присвоенных, равное заранее установленному объему выборки.
Если мы имеем, скажем, популяцию (т.е. генеральную совокупность) из 1507 элементов и хотим спроектировать выборку из 150, мы можем выбирать любые четыре смежных столбца в таблице случайных чисел. Каждый раз, когда будет появляться число от 0001 до 1507, мы будем считать, что оно обозначает номер отбираемого элемента. Если число появляется более чем один раз, этот номер игнорируется после первого раза. Если мы начнем с первых четырех столбцов в табл. 2.1, спускаясь по столбцам, то в выборку будут включены элементы под номерами 0799,1016,0084, 480 и 1306. Поскольку мы не стремимся умышленно отыскать определенное число, мы можем начать с любого места таблицы и использовать любую систему для движения по таблице.
Сегодня таблицу случайных чисел могут заменить машинные устройства, например компьютер, снабженный специальной программой. Их называют генераторами случайных чисел. При телефонном интервьюировании компьютер, имеющий генератор случайных чисел, может подавать на экран случайным образом отобранные телефонные номера.
2.4.2. Систематический отбор
Систематический отбор является вторым по научной значимости, но первым по популярности употребления видом простого случайного отбора. Его называют еще механическим отбором и считают упрощенным вариантом простого случайного отбора.
100
Примером служат разного рода квартирные выборки: выбираются улицы, на которых интервьюер проводит квартирный опрос. Квартиры выбираются по определенной схеме (крайняя квартира справа от лестницы на последнем этаже первого подъезда и т.д.).
Если под рукой таблицы случайных чисел нет, а генсовокупность относительно невелика14, то можно воспользоваться алфавитным списком, например, персонала предприятия (картотека всегда есть в отделе кадров) или избирательного участка (при опросе по месту жительства). Процедура систематического отбора проста: количество единиц генеральной совокупности, предположим 2000 работников предприятия, делится на количество анкет, скажем 200, и определяется шаг выборки. Он предполагает, что, начиная с любого номера из списка, опрашивается каждый десятый (2000:200 = 10). В формализованном виде данная процедура выглядит так. Из пронумерованного списка через равные интервалы £ отбирается заданное число респондентов. При этом шаг выборки к рассчитывается по простой формуле:
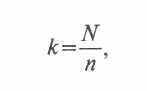
где ^ N— численность генеральной совокупности, п — численность выборочной совокупности.
Таким образом, шаг выборки, а его еще называют «интервалом скачка» или просто «интервалом», — это математический показа-тель, рассчитанный как отношение объема генеральной совокуп-ности к объему выборки. Он показывает, сколько номеров в спис-ке фамилий людей, вошедших в генеральную совокупность, надо пропустить (через сколько перешагнуть), чтобы в итоге получить список выборочной совокупности. Буквально шаг выборки озна-я чает расстояние между соседними фамилиями респондентов, из меренное количеством отбракованных фамилий из списка гене-ральной совокупности (рис. 2.3).
101
Другой пример. Предположим, что нам нужно спроектировать выборку численностью 100 из списка 5000 студентов какого-то вуза. Если мы намерены использовать систематическую выборку, то должны вначале рассчитать интервал выборки делением числа элементов в списке на размер выборки. В данном случае, разделив 5000 имен на требуемый размер выборки 100 ед., мы получим интервал (шаг) выборки 50. Так что мы будем систематически двигаться по списку и отбирать каждого пятидесятого студента (отобрав таким образом 100 имен). Определение того места в списке, с которого мы начнем, проводится случайным образом, по таблице случайных чисел (это называется случайным стартом). Таким образом, если случайно выбрана точка старта под номером 31, то в выборку будут включены студенты, стоящие под номерами 31, 81, 131, 181 и т.д.
Итак, в основу систематической выборки положены не вероятностные процедуры, а алфавитные списки, картотеки, схемы, которые обеспечивают равновероятное попадание в выборку всех единиц генеральной совокупности.
Несмотря на свои преимущества, систематическая выборка может иногда иметь своим результатом предубежденную выборку. Такая ситуация возникает, например, когда элементы размещены в списке, ранжированном по каким-то характеристикам. В этой ситуации определение места начала случайного отбора будет влиять на средние характеристики всей выборки. Например, если студенты расставлены в списке в соответствии со средним оценочным баллом от высшего к низшему, систематическая выборка, включающая студентов, стоящих в списке под номерами 1,51,101, будет иметь более низкий средний балл, чем выборка, включаю-Щая студентов под номерами 50, 100 и 150. Каждая новая выборка будет давать другой средний балл, который представляет собой предубежденную картину студенческой популяции.
102
2.4.3. Районированная и стратифицированная выборки
Если генеральная совокупность велика, а такое в эмпирическом исследовании случается очень часто, то приходится разделять обследуемую совокупность на более или менее однородные части, а затем осуществлять отбор единиц внутри этих частей. Такую раздробленную на части выборку правильнее всего было бы называть расслоенной. Однако в русском языке подобный термин не утвердился, видимо, как не соответствующий нормам правильного произношения.
Поскольку в отечественной социологии очень много иностранных слов — и это правильно с точки зрения унификации научной терминологии, приведения ее к международным стандартам, — то слову «расслоенная» попытались найти эквивалент. В числе претендентов оказались две наилучшие кандидатуры, а именно термины «районированная» и «стратифицированная».
В русском языке первое слово явно тяготеет к географическому языковому ареалу и обозначает территориальную зону. Поскольку генеральную совокупность, особенно очень большую, например население всей страны, можно разбивать в том числе и по региональному признаку, в отечественной литературе утвердился термин «районированная выборка». Но наряду с тем генеральную совокупность можно расслаивать и по стратам (полу, возрасту, доходам и т.д.), получая в качестве критерия уже не географический район, а социальную группу.
В итоге сложилась практика различения двух разновидностей расслоенной выборки. Если деление происходит по стратам (социальным группам), то выборку именуют стратифицированной, если по экономико-географическим районам, то —районированной.
В литературе (да и в маркетинговой практике) два термина — районированная и стратифицированная выборки — нередко счи- таются эквивалентными. Происходит это потому, что в основе той и другой лежит одна и та же процедура расслоения, а расслаивать в социологии можно двояко: либо по социальным группам (тогда речь идет о социальной структуре и стратификации как ее част-ном виде), либо по географическим районам. Когда объединяют оба понятия в одно, как правило, дают обобщающее определение подобной выборки, например, такое:
^ Районированная выборка — вид выборки, при котором отбору предшествует процедура районирования (расслоения, стратификации), т.е. разделения исходной совокупности на статистически или качественно однородные подсовокупности, называемые слоями,
103
стратами или типичными группами. Отбор единиц, который может носить как случайный, так и направленный характер, производится независимо из каждого слоя, поэтому районированная выборка равносильна ряду выборок, извлеченных из меньших совокупностей-страт15.
В этом определении исходное понятие «районированная выборка» без ущерба для дела можно заменить на «стратифицированную выборку». Таким образом, одинаково правильно будет как разделять одну выборку на две самостоятельные разновидности, районированную и стратифицированную, так и подавать их как единое целое. За единство двух приемов выступает практика социологических исследований. Оказывается, в крупномасштабных проектах социологи начинают с районированной выборки, а затем переходят на стратифицированную. Так, например, в обследованиях Центра «Социо-Экспресс» Института социологии РАН в основе построения районированной выборки лежат десять экономико-географических зон, в каждой из которых выделяются крупные города (численностью свыше 500 тыс. населения), средние города (50-500 тыс.), малые города (до 50 тыс.) или поселки городского типа, а также сельские населенные пункты. Внутри отобранных городов респондентов отбирают случайным методом. Репрезентативность контролируется по региональным пропорциям численности населения, пропорциям между городским и сельским населением, пропорциям между населением указанных типов населенных пунктов16.
В международной практике не используется русское слово «район» как географическая зона (ареал, регион, часть территории), поэтому здесь не встретишь и термина «районированная выборка». Вместо него употребляют термин «стратифицированная выборка», подразумевая, что, разбивая единое целое на части, не обязательно точно указывать, что они собой представляют — группы или районы.
В таком случае стратифицированная выборка (stratified sampling) — вероятностная выборка, обеспечивающая равномерное представительство в выборочной совокупности различных частей, типов, групп и слоев населения.
В английском языке слово «стратификация» мало чем отличается от слов «расслоение», «разделение», «разбиение». Это социологи придали стратификации социальный смысл, а в геологии, 104
откуда мы позаимствовали термин, стратификация означает вертикальное расслоение земли на однородные пласты. Ни классов, ни доходов, ни социальных групп здесь нет.
Надо учитывать и другой нюанс. Дело в том, что в зарубежных словарях, прежде всего американских и главным образом ведущих, все, что связано с территориальным признаком, в том числе и расслоение по районам, относится к квотной выборке. К примеру, в знаменитом Оксфордском словаре социологии на термин «stratified sampling» стоит отсылка: см. sampling. Открываем с. 576—577 и читаем о том, что в случае стратифицированной вероятностной {random) выборки речь идет о разбиении совокупности на подгруппы, т.е. страты, например мужчин и женщин, а о районированной выборке в нашем понимании не говорится ни слова. Близкий к районам термин «local areas» употребляется Гордоном Маршаллом (а он считается знатоком в этом деле) только в связи: 1) с первой стадией многоступенчатого отбора, 2) с квотной выборкой17.
Возвращаясь от лингвистических тонкостей к методическим, подчеркнем вот еще что: отбор единиц, который может носить как случайный, так и направленный характер, производится независимо из каждого слоя или района, поэтому районированно-стра-тифицированная выборка (если можно так выразиться) равносильна ряду выборок, извлеченных из меньших совокупностей-страт (районов).
^ Стратифицированная случайная выборка (в узком значении) основана на выборке по каждой страте отдельно. Это повышает точность результатов либо уменьшает время, силы и стоимость исследования, допуская меньшие размеры выборки при заданном уровне точности. Например, известно, что бедность наиболее часто встречается среди пожилых, безработных и в монородительских семьях. Исследуя проблемы бедности, можно с равным успехом выбрать в качестве объекта любую из трех страт. В отобранных районах или стратах выбор единиц обследования проводится по вероятностному методу.
Основная цель всякого расслоения — повышение точности выборочных оценок. Слои выделяются таким образом, чтобы дисперсия изучаемых переменных внутри слоев была значительно меньше, чем между ними. При расслоении вариация между слоями не входит в среднюю ошибку выборки, а компенсируется самой процедурой выделения слоев. Поэтому расслоение позволяет5 добиться более высокой степени точности оценок по сравнению
105
с простым случайным отбором. Если каждый слой представляет собой статистически однородную группу, то для любого из них даже выборка малого объема позволит получить достаточно точные оценки, которые, будучи объединены, дадут хорошую оценку для всей совокупности.
Различают стратификацию одномерную и многомерную в зависимости от того, один или несколько признаков положены в основу разделения совокупности. Эти признаки должны иметь тесную связь с изучаемыми переменными, от их выбора в высокой степени зависит эффективность расслоения.
2.4.4. Гнездовая выборка
Противоположность районированной и стратифицированной выборке составляет гнездовая выборка.
Гнездовая выборка — вид выборки, при котором отбираемые объекты представляют собой группы или гнезда (кластеры) более мелких единиц. Гнездом называют единицу отбора высшей ступени, состоящую из более мелких единиц низшей ступени. В выборку могут быть включены как все единицы низшего уровня, так и их часть. Число единиц, образующих гнездо, называют его размером.
В качестве гнезд выступают населенные пункты, районы, дома, подъезды, предприятия, цехи, бригады.
Гнездовой отбор обладает большими организационными преимуществами — проще осуществлять отбор и обследование нескольких компактных групп, чем десятков или сотен отдельных единиц. Технические преимущества гнездового отбора особенно ощутимы при построении территориальной выборки. Отбор небольшого числа территориальных сегментов (населенных пунктов, районов, жилых кварталов и т.п.), затем выборочный или сплошной опрос проживающего в них населения существенно уменьшают стоимость исследования и сроки проведения.
Процедурно такой метод применить легче, чем вероятностный либо районированный. Проблемы, которые возникают здесь, связаны с определением величины гнезда, количеством гнезд, которые надо обследовать, их размещением в генеральной совокупности.
Основные рекомендации при выборе гнезд сводятся к тому, чтобы различия между гнездами были бы по возможности более неоднородными. Это правило прямо противоположно основному принципу расслоения, в соответствии с которым выигрыш в точности тем больше, чем более однородными будут выделенные
106
слои. Другая рекомендация касается выбора размера гнезд: большое число малых гнезд предпочтительнее малого числа крупных18.
^ Пример стратифицированной выборки. Первое исследование по уровню жизни населения проведено в конце 60-х гг. XX в. группой исследователей (под рук. Н.М.Римашевской) из Центрального экономико-математического института АН СССР в городе Таганроге19. Проект назван Таганрог-1. Исследование в конце 70-х гг. названо Таганрог-2, а в 1988-1989 гг. названо Таганрог-3. Это город на юге России с населением около 300 тыс. человек. Семья — это группа лиц, живущих вместе на одной жилой площади, ведущих совместное хозяйство и находящихся в отношениях родства, брака или опекунства. В 1989 г. в Таганроге около 10% населения имели душевые доходы ниже 75 руб., т.е. были бедными. Основой выборки служили данные о структуре жилого фонда и числе проживающих. На первом этапе город поделен на районы, на втором вычислялись доли разных типов жилья с разным уровнем его оплаты и коммунальными удобствами. На третьем этапе жилой фонд делился по числу квартир в домах. Для каждой страты — района, типа застройки, размера жилья — заводился лист с адресами и числом квартир. Так планировалась выборка и организовывался отбор домохозяйств в Таганроге-2. Использовалась трехуровневая процедура территориального стратифицированного отбора.
^ Пример районированной выборки. Эмпирической основой работы «Динамика социальной структуры красноярского региона» явились социологические исследования, проведенные сотрудниками Красноярского государственного университета под руководством проф. В.Г.Немировского: 1) опрос 1488 жителей Красноярского края в мае 1991 г.; 2) опрос 1240 жителей края в июне 1992 г.; 3) опрос 1050 жителей края в мае 1995 г.; 4) опрос 1820 жителей края в апреле 1998 г.; 5) опрос 1460 жителей края в январе 1999 г. Каждое исследование проводилось по общекраевой выборке методом формализованного интервью. Использовалась многоступенчатая, районированная выборка, сформированная в соответствии с половозрастной структурой населения края. В процессе построения выборки на первой ступени генеральная совокупность делилась на ряд слоев в зависимости от места жительства респондента: в городской (в крае 27 городов) и сельской местности (последняя подразделяется на 41 административный район); размера населенного пункта: жители крупного города (Красноярск), сред-
107
него города, малого города, сельскохозяйственных районов, районов с преобладанием лесной промышленности. Затем осуществлялся типологический отбор районов и городов в каждом из выделенных слоев. На второй ступени отбора проводилось районирование уже внутри населенных пунктов или сельских районов. Так, в городах выделялись административные, промышленные, «спальные» районы, места индивидуальной застройки. В сельской местности признаком расслоения служил размер населенного пункта — райцентр, село, деревня. В следующей ступени проводился квотный отбор. В рамках конкретной территориальной зоны анкетер должен был опросить определенное число лиц с заданными социально-демократическими характеристиками20.
При гнездовой выборке (которую иногда называют также кластерной21) определяются группы или гнезда элементов и составляются их списки. Затем из этого списка единиц выборки проектируется выборка. Потом только для этих единиц идентифицируются и отбираются элементы. Возьмем, например, составление опросного списка на 1000 человек (размер выборки) для изучения общественного мнения населения города. Поскольку мы не располагаем списком всех жителей города, мы могли бы начать с получения карты города, чтобы определить все его кварталы и составить их список. Этот список кварталов становится остовом выборки, из которого случайным образом или систематически проводится выборка кварталов. Затем будет спроектирована выборка жилых домов из каждого квартала. Затем будет установлена связь с семьями, проживающими в отобранных домах, и в каждой семье кто-то будет проинтервьюирован для опросного листа. Предположим, что имеется 500 кварталов и из них случайным образом отобрано 25. В этих 25 кварталах идентифицированы 4000 семей. Связь будет установлена с четвертью этих семей, потому что требуется выборка из 1000 индивидов. Эти 1000 семей будут отобраны случайным или систематическим образом.
^ Пример гнездовой выборки. Исследование Т. Б. Бердниковой и МАЛямина «Социальные последствия трансформации собственности»22, проведенное в 1999 г., охватывало 500 респондентов в Белгородском, Губкинском, Корочанском и Ровеньском районах Белгородской области. Отбор респондентов осуществлялся методом гнездовой двухступенчатой выборки. В качестве гнезд (клас-
108
теров) или групп выделялись районы Белгородской области. На первом этапе проведен отбор гнезд в соответствии с требованиями минимальных различий между ними и максимальной неоднородности составляющих их единиц. В рамках самих гнезд отбор респондентов осуществлялся по методу многоступенчатой квотной выборки, репрезентативной по отношению к социально-демографической структуре работников предприятий различных форм собственности. Квотными признаками выступали: пол, возраст, место проживания. Опрос руководителей проводился по той же методике, но квотными признаками выборки в данном случае были: пол, возраст, образование, стаж работы. Отбор респондентов для экспертного опроса проводился по методу случайной выборки по следующим критериям: род деятельности, наличие специального опыта, участие в приватизации и акционировании.
^ Пример кластерной выборки. В исследовании, проведенном B.C. Журавлевым23 в 1999 г. в школах и училищах Екатеринбурга была использована многоступенчатая выборка с применением на первой ступени кластерной выборки. Были отобраны учебные заведения Екатеринбурга, находящиеся в «опасных» районах в непосредственной близости от вокзалов, парков и лесопарков и т.д. Опрашивались учащиеся профессионального училища, школ и гимназии города. Внутри кластеров отбор стратифицировался. В каждом кластере опрашивалось по 100 респондентов. Генеральная совокупность насчитывает 80 тыс. человек. Объем выборочной совокупности составил 500 человек, что достаточно для получения репрезентативных данных, учитывая однородность генеральной совокупности и небольшой вариационный размах.
2.5. Методы невероятностной (неслучайной) выборки
Неслучайная (невероятностная) выборка — это способ отбора единиц, при котором мы не можем заранее рассчитать вероятность попадания каждого элемента в состав выборочной совокупности, что, разумеется, не дает возможности рассчитать, насколько правильна (репрезентативна) выборка. По этой причине предпочтение обычно отдается вероятностной выборке, хотя иногда по условиям исследования оказывается единственно возможным провести неслучайную выборку.
109
Таким образом, можно заранее сказать, что по содержательным критериям невероятностная (она же целевая и целенаправленная) выборка не хуже вероятностной, а может быть, и лучше. Ее недостатки: невозможность установить степень репрезентативности и более высокая стоимость (с точки зрения затрат она обычно превосходит вероятностную на несколько порядков). Но есть и преимущества — более глубокое, качественное и всестороннее раскрытие предмета по сравнению с вероятностной.
^ Известны следующие разновидности неслучайной выборки: квотная выборка, метод снежного кома, метод основного массива, метод стихийного отбора.
Несомненно, принцип отбора единиц в неслучайной выборке отличается от традиционного. Рассмотрим, чем именно.
Как и для вероятностного способа отбора, основная цель неслучайного отбора состоит в получении совокупности, репрезентирующей изучаемый объект. Однако в отличие от вероятностной выборки статистические выводы обо всем множестве объектов в этом случае делать не совсем правомерно. Эти выводы могут с большей или меньшей степенью вероятности распространяться лишь на генеральную совокупность (которая не всегда совпадает с объектом исследования).
Выделяют два основных вида неслучайного отбора:
♦ направленный отбор (другие названия — целенаправленный, целевой, выбор по усмотрению);
♦ стихийный.
Направленный отбор характеризуется выбором единиц по какому-либо заранее определенному принципу. Наиболее распространенными формами направленного отбора считаются: выбор типичных объектов (методов типичных представителей), метод «снежного кома» и выбор квотами.