
Е. Б. Замятина Распределенные системы и алгоритмы Курс лекций
| Вид материала | Курс лекций |
СодержаниеЛекция 15. Поиск в пиринговых системах On UserQuery(q) begin |
- Века. Вопросы к семинарам и диспутам. Часть вторая е. И. Замятин. Роман-антиутопия, 78.14kb.
- С. В. Лапина Социология Курс лекций, 2085.17kb.
- Е. В. Беляева Этика Курс лекций, 693.52kb.
- С. В. Лапина Культурология Курс лекций, 3263kb.
- О. В. Свидерская Основы энергосбережения Курс лекций, 2953.76kb.
- С. М. Забелов > П. С. Забелов Административное право Курс лекций, 3268.19kb.
- И. М. Вашко Организация и охрана труда Курс лекций, 2301.17kb.
- И. М. Вашко Организация и охрана труда Курс лекций, 2301.24kb.
- Курс лекций для студентов заочного факультета самара, 1339.16kb.
- Курс, 1-й семестр лекции (51 час), экзамен практикум на ЭВМ (68 часов), зачет (с оценкой), 24.4kb.
Лекция 15. Поиск в пиринговых системах
Пиринговые системы (peer-to-peer, P2P) – это такие компьютерные сети, в которых не используется классическая схема клиент-сервер, разделяющая множество всех узлов на два подмножества – серверов и клиентов. В пиринговой сети все узлы «равны» в том смысле, что каждый из них по отношению к другому (другим) может выполнять функции как клиента, так и сервера. Эти сети называют еще одноранговыми.
Возникновение пиринговых сетей связано с тремя факторами.
1. Процессор обычной клиентской машины мало загружен. Особенно в офисах, где машины используются преимущественно для подготовки документов, для набора текстов и т.п. То же касается и подавляющего большинства домашних компьютеров.
2. Многие пользователи хранят на своих компьютерах коллекции файлов (тексты статей определенной тематики, художественные фотографии и др.), которые могут быть интересны и другим пользователям. Но при этом владельцы этих коллекций не готовы сделать свой компьютер полноценным сервером в сети из-за его недостаточной мощности, необходимости круглосуточной работы, финансовых и других причин.
3. Определенная часть пользователей хотела бы более активно участвовать в «общественной жизни» сети, не ограничиваясь обсуждением различных вопросов на форумах и в чатах. Они готовы участвовать в каком-либо полезном «общем деле».
Пиринговые сети разнообразны. Основной целью одних является обмен музыкальными и видео файлами. В других реализуются проекты поиска лекарства от рака, третьи тренируются во взломе известных шифров на основе распределенных вычислений, четвертые ищут внеземные цивилизации на основе данных, получаемых с радиотелескопов.
С математической точки зрения пиринговая сеть может быть представлена графом неопределенного вида: нет какой-либо стандартной архитектуры сети (например, звезды или кольца). Более того, этот граф – динамический, так как отдельные пользователи включаются в сеть и выходят из ее состава в произвольные моменты времени. Любой пользователь, играющий роль сервера, в любой момент времени может превратиться в клиента на некоторый отрезок времени. Но может и пребывать одновременно в положении и сервера и клиента.
Исследования в области пиринговых сетей начались в связи с успешным функционированием таких систем как Napster, Gnutella и Freenet.
Napster – гибридная система, поскольку использует централизованный индекс для поиска. Система Gnutella – чистая пиринговая система. Ее архитектура такова, что каждый узел с невысокими скоростями коммутации может иметь до четырех соседей, мощные же узлы могут иметь десятки соседей. Понятно, чем больше соседей, тем быстрее может быть поиск. Но здесь имеются такие же технические ограничения, как и в многопроцессорных компьютерах: слишком накладно соединять каждого с каждым. Соединения в системе не направленные (неориентированный граф). Система Gnutella использует поиск в ширину, просматривая сначала все соседние с инициатором узлы. Каждый узел, получивший запрос, распространяет его своим соседям максимум на d шагов.
Преимущество поиска в ширину состоит в том, что просматривая значительную часть сети, он увеличивает вероятность удовлетворения запроса. Недостатком является перегрузка сети лишними сообщениями.
Система Freenet использует поиск в глубину на величину d. Каждый узел отправляет запрос только одному соседу и ждет от него ответа до посылки запроса следующему. Этот метод не отправляет лишних сообщений, но увеличивает время получения ответа.
Янг и Гарсиа-Молина предложили улучшить протокол Gnutella применением одной из трех техник. Первая – итеративное углубление, при которой многократно применяется поиск в ширину с увеличивающимся значением di . Вторая – направленный поиск в ширину, при котором запросы направляются не всем соседям, а только соседям из «полезного» множества. При этом каждый узел должен хранить некоторую информацию о соседях, характеризующую их «полезность». Третья техника – локальное индексирование. При этом каждый узел хранит индексы для данных на узлах, находящихся от него на некотором расстоянии k.
Большинство существующих систем поддерживают только «булевы» запросы. Каждый файл характеризуется его метаданными (например, набором ключевых слов) и запрос формируется как набор ключевых слов. Вследствие этого результат поиска может быть двухвариантным: «найдено», «не найдено».
П.Калнис, В.Нг, Б.Ой, К.-Л.Тан исследовали проблему нечетких запросов, таких, например, как «для данного примера найти m наиболее соответствующих ему образов». Такие запросы часто используются в системах поиска изображений, поскольку человеку трудно точно выразить содержание некоторого изображения ключевыми словами. В связи с этим нельзя создать централизованный индекс, каждый узел (в области распространения запроса) вернет m результатов, и инициатор запроса сам вынужден будет отыскивать глобальный результат. Разумеется, это связано с пересылкой большого числа бесполезных сообщений.
Поскольку запросы являются нечеткими, то и ответы всегда приближенные. Это означает, что если два запроса являются подобными (но не в точности одинаковыми), то и найденные множества из m наиболее соответствующих каждому из них ответов, с большой вероятностью будут совпадать или во многом пересекаться (т.е. содержать одни и те же ответы).
Авторы вводят в рассмотрение систему FuzzyPeer класса P2P, поддерживающую подобные запросы. В этой системе некоторые запросы «берут паузу», т.е. не распространяются дальше, оставаясь внутри некоторого множества узлов. Такие запросы называют «замороженными».
Замороженные запросы получают ответы из потока ответов, проходящих через эти узлы, инициированного оставшимися «действующими» запросами. При тщательном выборе множества «замороженных» запросов, получающих ответы из упомянутого потока данных, можно получить результаты, качество которых и время ответа будут на приемлемом уровне, даже если система перегружена.
Участие узлов в системе FuzzyPeer динамично – они могут подключаться к системе в любой момент времени. Также они могут и покидать систему. В системе имеются специальные серверы Si , поддерживающие эту динамику. Когда узел хочет включиться в систему, сервер определяет, с какими другими узлами он будет соседствовать. Затем запускается протокол соединения, подобный протоколу Gnutella. Если не считать серверов Si , система является полностью распределенной.
Серверы участвуют только в формировании и изменении системы, но не участвуют в передаче и обработке запросов.
Работа в FuzzyPeer происходит следующим образом.
Примем для рассматриваемого примера сети (рис. 31) d = 3. Узлы имеют от одного до трех соседей. Время ожидания узлом ответа ограничим величиной Tmax . Архитектура сети формируется тремя серверами S1 , S2 и S3 . Они задают связи между узлами и присваивают им имена. Сферы влияния серверов показаны пунктирными линиями.
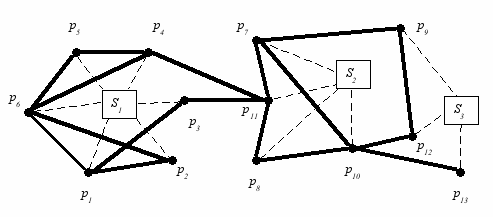
Рис. 31. Пиринговая сеть
Пусть пользователь на узле p1 генерирует запрос q1 = «для данного примера найти 8 наиболее соответствующих ему изображений». Этот узел распространяет запрос среди непосредственных соседей, p2 , p3 и p6 . Они производят поиск в своих базах данных и выдают идентификаторы восьмерки наиболее подходящих изображений, одновременно с величинами различий (должна существовать некая метрика в пространстве изображений).
Одновременно, узлы p2 , p3 и p6 распространяют запрос q1 среди своих соседей. В частности, может случиться, что некоторые из узлов p2 , p3 и p6 являются соседями друг друга. Например, p2 и p6 . Тогда p2 направит запрос q1 соседу p6 . Узел p6 проигнорирует этот запрос ввиду дублирования (такой запрос узлу p6 уже поступал).
Поскольку расстояние распространения запроса ограничено величиной d = 3, то узлы p9 , p10 , p12 и p13 запросов не получат. Узел p5 , получивший запрос q1 через узел p6 , через этот же узел и будет возвращать ответ. Узел p1 ожидает время Tmax . В течение этого времени он принимает приходящие ответы. По окончании срока все опоздавшие ответы игнорируются.
Иногда на некоторых узлах пиринговой сети может возникать перегрузка.
Положим, как и ранее, узел p1 направил в сеть запрос q1 . Запрос еще не выполнен, а узел p2 также направляет в сеть запрос q2 , очень похожий на запрос q1 , но не тождественный ему, q2 q1 . Запрос q2 направляется соседям p2 , в том числе и узлу p6 . Поскольку узел p6 еще не завершил обработку запроса q1 , на узле p6 возникает перегрузка: узел должен обрабатывать два запроса. Может случиться, что из-за увеличивающейся задержки на узле за время Tmax не будет обработан и первый запрос, q1 . Таким образом, оба запроса могут получить отказ.
В сети FuzzyPeer вместо того, чтобы обрабатывать запрос q2 , его «замораживают».
Когда запрос q1 проходит через узел p6 , он инициирует поток ответов Flow(q1). Все ответы от p4 , p5 и p11 , которым транслировался этот запрос, включаются в поток Flow(q1). Когда запрос q2 также достигает узла p6 , он идентифицируется как «похожий» на запрос q1 . Вследствие этого, он не распространяется дальше, а «замораживается» внутри узла p6 до прохождения обратного потока Flow(q1).
Узел p6 возвращает результаты, находящиеся в потоке Flow(q1), не только инициатору – узлу p1 , но и узлу p2 . Основанием для таких действий является предположение о том, что если запросы близки, то и ответы должны быть близкими в пределах некоторой метрики. Конечно, для каждого приближенного запроса qi можно отыскивать свой (персональный) приближенный ответ f(qi). Тогда для запросов qj qi , но qj qi , приближенные ответы могут несколько отличаться друг от друга: f(qj) f(qi), f(qj) f(qi). Но если, опять же в смысле некоторой метрики, ответ f(qi) является удовлетворительным для запроса qj , то почему бы им не воспользоваться и уменьшить работу по поиску?
Предложенный метод может быть записан в виде следующего распределенного алгоритма статического «замораживания» запросов.
Переменные – атрибуты запроса q:
frozen: boolean {запрос заморожен или не заморожен} init false,
steps: integer {ограничение на количество шагов}, init ,
counter: integer {количество пройденных шагов} init 0;
Кроме этого, идентификатор this используется, как и выше, для обозначения узла текущего процесса.
On UserQuery(q)
begin
С вероятностью Pf : frozen := true, steps := hf
Инициировать поток ответов Aq
Распространить q
end
On QueryReceived(q) {от соседнего узла получен запрос}
begin
counter := counter + 1;
if frozen & (steps = counter)
then
begin
Заморозить q;
Присоединить q к наиболее подходящему потоку ответов, если такой поток существует
end
else
begin
if frozen then вычислить ответ и вернуть его обратно
if counter < max_steps then распространить q
end
end
On ResultReceived(rq) {от соседнего узла получен ответ}
begin
for каждого запроса qi , присоединенного к q do
if нет циклических зависимостей среди замороженных запросов
then
begin
Создать копию ответа rq как ответ rqi ;
Направить rqi как ответ rqi на запрос qi
end;
if this = инициатор запроса q
then Добавить rq к потоку ответов Aq
else Направить rq обратно в качестве ответа
end
Алгоритм использует два параметра: вероятность Pf замораживания запроса и число steps шагов, которые должен сделать запрос q до того, как его заморозят. Узел-инициатор принимает решение с вероятностью Pf о том, следует ли заморозить новый запрос. Затем запрос q распространяется как обычно.
Предположим, что q был избран для замораживания, и через steps шагов он достигает узла pi . Алгоритм приостанавливает распространение запроса q на данном направлении, проверяет все активные потоки ответов на узле pi , и присоединяет q к наиболее «подходящему» из них. Если же потоков нет, то происходит только приостановка запроса. Запрос будет заморожен на всех узлах, находящихся на расстоянии steps от узла-инициатора p.
Когда ответ попадает в поток, алгоритм ищет любые присоединенные к потоку запросы. Для каждого запроса создается экземпляр этого ответа и направляется на узел, отправивший запрос.