
Метод Рутисхаузера Первыми транслирующими программа
| Вид материала | Программа |
- Программа исследования, 416.21kb.
- Классный час ко дню космонавтики: "Они были первыми", 402.68kb.
- Темы курсовых работ по курсу «Программирование» для студентов группы биб-11-1 (2011-2012, 85.51kb.
- Практических: 0 Лабораторных:, 21.53kb.
- Расшифровка : Наука в целом (информационные технологии 004), 79.71kb.
- Урока литературы в 9 классе на тему: «Древнерусская литература и современность. Золотое, 43.48kb.
- Рабочая программа учебной дисциплины ф тпу 1-21/01 «утверждаю», 295.08kb.
- Решение. Из анализа схемы следует, что резисторы, 80.22kb.
- 1. Предмет и метод. Основные понятия экономики, 49.49kb.
- Линейных алгебраических уравнений ax=B, где, 66.22kb.
2.3Расширенная классификация грамматик Хомского
В зависимости от вида правил грамматики различают:
тип 0 – грамматики фразовой структуры или грамматики «без ограничений»:
α β, где α V+, β V*– в таких грамматиках допустимо наличие любых правил вывода, что свойственно грамматикам естественных языков;
тип 1 – контекстно-зависимые (неукорачивающие) грамматики:
α β, где α V+, β V*, | α | | β | – в этих грамматиках для правил вида α X β α x β возможность подстановки строки х вместо символа X определяется присутствием подстрок α и β, т. е. контекста, что также свойственно грамматикам естественных языков;
(расширение допускает не более одного правила вида A e, где AVN);
тип 2 – контекстно-свободные грамматики:
A β, где AVN, β V* – поскольку в левой части правила стоит нетерминал, подстановки не зависят от контекста;
тип 3 – регулярная грамматика:
A α, A αB, где A, ВVN, α VT;
(расширение допускает не более одного правила вида S e, но в этом случае аксиома не должна появляться в правых частях правил).
К
 лассификация построена по правилам иерархии, т. е. грамматики типа 3 являются частным случаем грамматик типа 2 и т. п. (см. рисунок 3).
лассификация построена по правилам иерархии, т. е. грамматики типа 3 являются частным случаем грамматик типа 2 и т. п. (см. рисунок 3). Г
Рисунок 3 – Вложение типов
рамматики большинства существующих языков программирования относятся к типу 2, что связано с рекурсивно-вложенной структурой большинства правил продукции таких языков.
Один и тот же язык может быть описан грамматиками различных типов, поэтому тип языка определяется максимально возможным для него типом грамматики. Так грамматика языка описания целых десятичных чисел, приведенная в примере выше, относится к типу 2, хотя этот язык можно описать грамматикой типа 3:
<целое>::= + <цбз>| - <цбз>|0<цбз>| 1<цбз>| 2<цбз>| 3<цбз>|4<цбз>|
5<цбз>| 6<цбз>| 7<цбз>|8<цбз>| 9<цбз>|0|1|2|3|4|5|6|7|8|9
<цбз>::= 0<цбз>| 1<цбз>| 2<цбз>| 3<цбз>|4<цбз>|
5<цбз>| 6<цбз>| 7<цбз>|8<цбз>| 9<цбз>|0|1|2|3|4|5|6|7|8|9.
Следовательно, язык описания целых десятичных чисел относится к типу 3.
Примечание. Существует простой метод проверки регулярности языка, основанный на лемме о разрастании, смысл которой заключается в следующем: в строке регулярного языка всегда можно найти непустую подстроку, повторение которой произвольное количество раз порождает новые строки того же языка.
Пример. Язык описания целых чисел. Из строки «+23» можно построить строки: 22222, 23232323 и т. д. того же языка.
Еще одно свойство языка позволяет сразу определить, что язык не относится к классу регулярных – это самовложение, т. е. наличие правил вида A + α1Aα2, где α1, α2 V+.
Пример. Язык скобок, описываемый правилами: S (S), S SS, S e. Грамматика этого языка является грамматикой с самовложением, принадлежит классу КС и не приводима к регулярной.
Лемма о разрастании КС языков формулируется следующим образом: в строке, принадлежащей КС-языку, всегда можно найти две подстроки с ненулевой суммарной длиной, одновременное повторение которых произвольное количество раз порождает новую строку того же языка.
Пример. Язык скобок. Из строки «()» можно построить строку: ((())) и т. д. того же языка.
Проверка соответствия строк языку осуществляется специальной программой – распознавателем. Распознаватели могут использоваться для определения языка также как и грамматики. Чем шире класс распознаваемых грамматик, тем сложнее класс соответствующих распознавателей. Доказано, что:
грамматики типа 3 распознаются конечными автоматами;
грамматики типа 2 распознаются автоматами с магазинной памятью;
грамматики типа 1 распознаются линейными ограниченными автоматами;
грамматики типа 0 распознаются машинами Тьюринга.
2.4Распознавание регулярных грамматик
2.4.1Конечный автомат и его программная реализация
Распознаватели регулярных грамматик строятся на конечных автоматах. Конечный автомат – это математическая модель, свойства и поведение которой полностью определяются пятеркой: M = (Q, , δ, q0, F),
где Q – конечное множество состояний;
– конечное множество входных символов;
δ(qi, сk) – функция переходов (qi – текущее состояние, сk – очередной символ);
q0 – начальное состояние;
F = {qj} – подмножество допускающих состояний.
Конечные автоматы – одна из базовых моделей, используемых при проектировании программного и аппаратного обеспечения средств вычислительной техники.
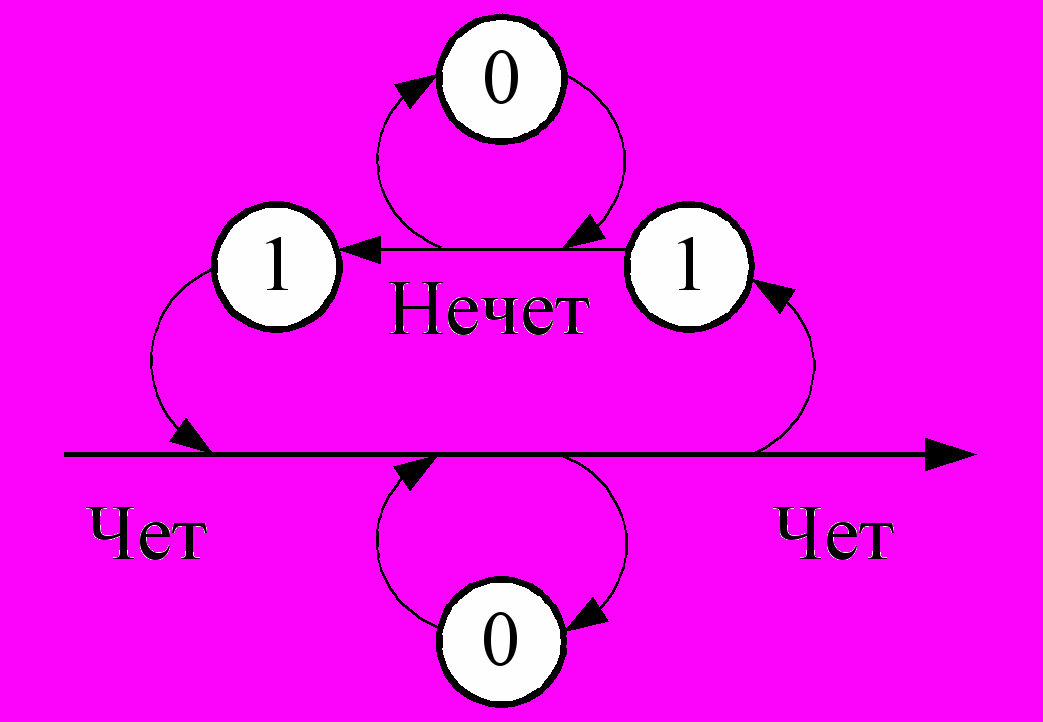
Пример. Автомат «Чет-нечет» описывается следующим образом:
Q = {Чет, Нечет};
= {0, 1};
δ(Чет, 0) = Чет, δ(Нечет, 0) = Нечет, δ(Чет, 1) = Нечет, δ(Нечет, 1) = Чет;
q0 = Чет;
F = {Чет}
Строка «10110» приведет такой автомат в состояние Нечет, т. е. будет отвергнута, а строка «110011» – в состояние Чет, т. е. будет принята.
Для представления функции переходов конечного автомата помимо аналитической формы могут использоваться: таблица (см. таблицу 4), граф переходов состояний (см. рисунок 4) и синтаксическая диаграмма (см. рисунок 5).
Т
 аблица 4 – Функция переходов
аблица 4 – Функция переходов| q | 0 | 1 |
| Чет | Чет | Нечет |
| Нечет | Нечет | Чет |
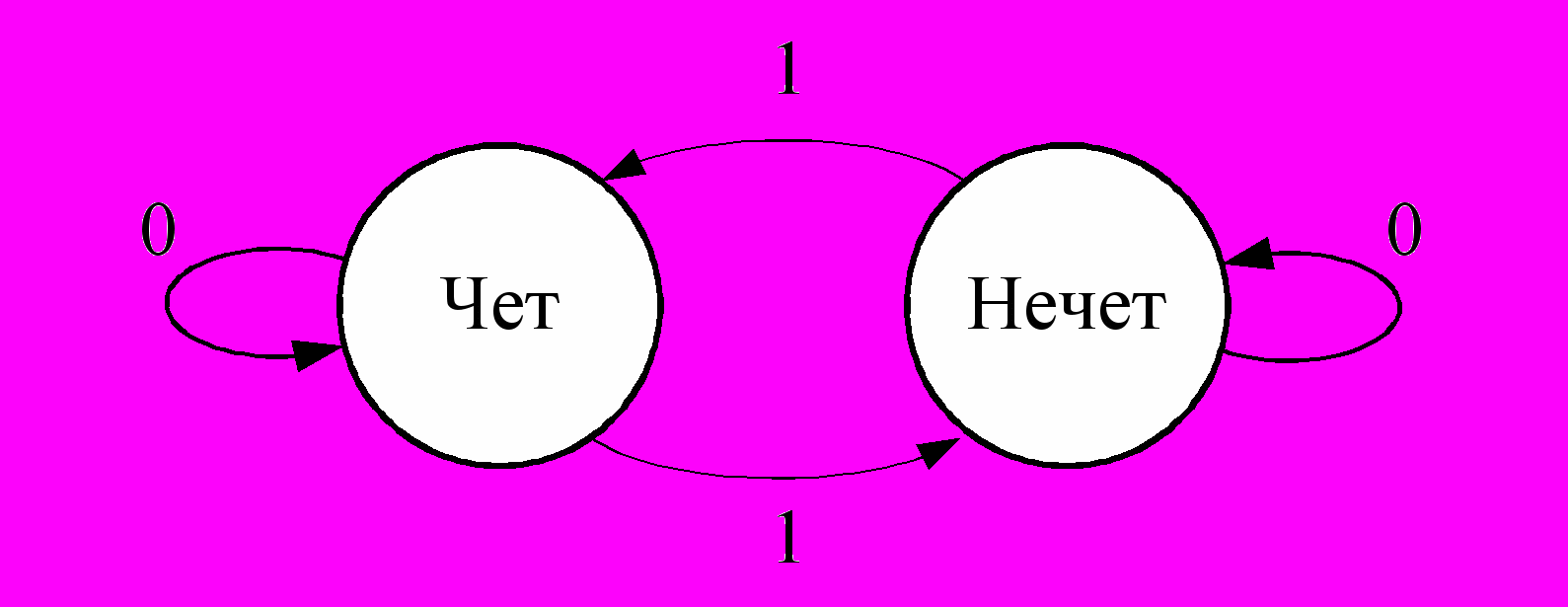
Рисунок 4 – Граф переходов Рисунок 5 – Синтаксическая диаграмма
Разработчик автомата обычно использует представление автомата графом или синтаксической диаграммой. При реализации в виде программы автомат задают таблицей переходов.
Для идентификации завершения строки обычно применяют специальный символ или множество символов, которые включают во входной алфавит и учитывают в таблице. Кроме этого, в таблице также предусматривают реакцию автомата на символы, не включенные в алфавит и не являющиеся завершающими. Появление таких символов в строке однозначно означает, что предложение языка содержит ошибку (см. таблицу 5).
Таблица 5 – Дополненная таблица конечного автомата
| q с | 0 | 1 | Символы завершения | Другие символы |
| Чет | Чет | Нечет | Конец | Ошибка |
| Нечет | Нечет | Чет | Ошибка | Ошибка |
Пусть S – строка на входе автомата;
Ind – номер очередного символа;
q – текущее состояние автомата;
Table – таблица, учитывающая символы завершения и другие символы.
Тогда алгоритм работы автомата можно представить следующим образом.
Ind := 1
q := q0
Цикл-пока q «Ошибка» и q «Конец»
q = Table [q, S[Ind]]
Ind := Ind +1
Все-цикл
Если q = «Конец»
то «Строка принята»
иначе «Строка отвергнута»
Все-если
2.4.2Построение лексических анализаторов
При построении лексических анализаторов конечные автоматы используют для распознавания лексем второго типа (базовых понятий языка). Эти понятия можно описать в рамках самых простых, регулярных грамматик и предложить для них эффективную технику разбора. Отделение сканера от синтаксического анализатора позволяет также сократить время распознавания лексем, так как при этом появляется возможность использования оптимизированных ассемблерных команд, специально предназначенных для сканирования строк.
Алфавит автомата лексического анализатора – все множество однобайтовых ( ASCII) или двухбайтовых (Unicode) символов. При записи правил обычно используются обобщающие нетерминалы вида «Буквы», «Цифры». В процессе распознавания может формироваться описываемый объект, например, литерал или идентификатор.
Пример. Распознаватель целых чисел. Синтаксическая диаграмма синтаксиса языка описывается синтаксической диаграммой (см. рисунок 6).

1 – начало разбора; 2 – распознан знак; 3 – целое; К – завершение разбора
Рисунок 6 – Синтаксическая диаграмма
По диаграмме строим таблицу переходов (см. таблицу 6), обозначая состояние ошибки символом «E». В таблице переходов указываем подпрограммы обработки, которые должны быть выполнены при осуществлении указанного перехода. При выполнении этих подпрограмм формируются указанные значения.
Таблица 6 – Таблица переходов
| | Знак | Цифра | Разделитель | Другие |
| 1 | 2, А1 | 3, А2 | Е, Д1 | Е, Д4 |
| 2 | Е, Д2 | 3, А2 | Е, Д3 | Е, Д4 |
| 3 | К, А3 | 3, А2 | К, А3 | Е, Д4 |
а) Подпрограммы обработки:
A0: Инициализация: Целое := 0; Знак_числа := «+».
А1: Знак_числа := Знак
А2: Целое := Целое*10 + Цифра
А3: Если Знак_числа = «-» то Целое := -Целое Все-если
б) Диагностические сообщения:
Д1: «Строка не является десятичным числом»;
Д2: «Два знака рядом»;
Д3: «В строке отсутствуют цифры»,
Д4: «В строке встречаются недопустимые символы»
Обозначим: S – строка на входе автомата; Ind – номер очередного символа; q – текущее состояние автомата; Table – таблица, учитывающая символы завершения и другие символы.
Тогда алгоритм сканера-распознавателя можно представить следующим образом.
Ind := 1
q := 1
Выполнить А0
Цикл-пока q «Е» и q «К»
Если S[Ind] = «+» или S[Ind] = «-»,
то j := 1
иначе Если S[Ind] «0» и S[Ind] «9»,
то j := 2,
иначе j := 3
Все-если
Все-если
Выполнить Ai := Table [q, j]. A()
q := Table [q, j]
Ind := Ind +1
Все-цикл
Если q = «К»
то Выполнить А3
Вывести сообщение «Это число»
иначе Вывести сообщение Дi
Все-если
2.4.3Построение синтаксических анализаторов
Синтаксические анализаторы регулярных языков на вход получают строку лексем.
Пример. Синтаксический анализатор списка описания целых скаляров, массивов и функций (упрощенный вариант), например: int xaf, y22[5], zrr[2][4], re[N], fun(), *g;
После лексического анализа входная строка представлена в алфавите:
V – идентификатор; N – целочисленная константа; служебные символы: «[ ] ( ) , ; *».
Функцию переходов зададим синтаксической диаграммой (см. рисунок 7).
Рисунок 7 – Синтаксическая диаграмма
По диаграмме построим таблицу автомата (см. таблицу 7).
Таблица 7 –Таблица переходов
| | V | N | * | ( | ) | [ | ] | , | ; | Другие |
| 1 | 3 | E | 2 | E | E | E | E | E | E | E |
| 2 | 3 | E | E | E | E | E | E | E | E | E |
| 3 | E | E | E | 4 | E | 6 | E | 1 | К | E |
| 4 | E | E | E | E | 5 | E | E | E | E | E |
| 5 | E | E | E | E | E | E | E | 1 | К | E |
| 6 | E | 7 | E | E | E | E | E | E | E | E |
| 7 | E | E | E | E | E | E | 8 | E | E | E |
| 8 | E | E | E | E | E | 6 | E | 1 | К | E |
Алгоритм распознавателя:
Ind := 1
q := 1
Цикл-пока q «Е» и q «К»
q := Table [q, Pos(S[Ind], «VN*()[];»)]
Ind := Ind +1
Все-цикл
Если q = «К»
то Выполнить А3
Вывести сообщение «Это число»
иначе Вывести сообщение Дi
Все-если