
Анализ временных рядов появился в эконометрии в середине 1980 год
| Вид материала | Документы |
- Программа дисциплины Анализ финансово-экономических временных рядов для направления, 76.91kb.
- Модификация программного комплекса ас дрм для обработки временных рядов в технике, 125.29kb.
- Рабочая программа дисциплины экономический анализ временных рядов цели и задачи изучения, 118.03kb.
- Современный интеллектуальный анализ нечетких временных рядов, 141.75kb.
- Программа дисциплины Нелинейные модели временных рядов для направления 521600 Экономика, 66.64kb.
- Статистика временных рядов, 19.49kb.
- Пояснительная записка: Требования к студентам: необходимо знание курсов «Математического, 78.04kb.
- Пояснительная записка: Требования к студентам: необходимо знание курсов «Математического, 49.13kb.
- Анализ данных маркетинговых исследований: Корреляционно-регрессионный анализ и анализ, 91.98kb.
- Программа дисциплины Анализ временных рядов для направления 080100. 68 «Экономика», 259.15kb.
Коинтеграционный анализ временных рядов появился в эконометрии в середине 1980 годов и был воспринят многими эконометристами как наиболее важное из последних разработок в эмпирическом моделировании. Базовые идеи и выкладки применения коинтеграционного анализа требуют знания и применения лишь метода наименьших квадратов и опираются на понятия стационарных и нестационарных процессов.
Нестационарность временного ряда всегда была проблемой в эконометрическом анализе. Как было показано в ряде теоретических работ (Филлипс, 1986), в общем случае, статистические характеристики регрессионного анализа, используемые для нестационарных временных рядов, сомнительно.
Если переменные, включаемые в модель в качестве регрессоров, нестационарны, то полученные оценки будут очень плохими. Они не будут обладать свойством состоятельности, т.е. не будут сходиться по вероятности к истинным значениям параметров по мере увеличения выборки. Такие показатели, как коэффициент детерминации
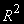 , t-статистики, F-статистики, будут указывать на наличие связи там, где ее на самом деле нет. Такой эффект называют ложной регрессией.
, t-статистики, F-статистики, будут указывать на наличие связи там, где ее на самом деле нет. Такой эффект называют ложной регрессией.Проиллюстрировать этот эффект можно на довольно абсурдном примере:
Пусть
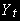 - точки, лежащие на прямой:
- точки, лежащие на прямой: 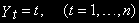
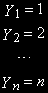
а
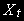 на квадратичной линии:
на квадратичной линии: 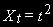
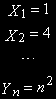
Для n=30 результат регрессии выглядит так:
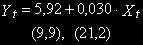
в скобках приведены значения статистики Стьюдента,
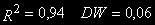 .
.Если не принимать во внимание статистику DW, уравнение регрессии выглядит вполне благополучно, хотя и демонстрирует совершенно ложную зависимость. Свидетельством того, что регрессия неверна, является очень низкий уровень DW.
Этот экстремальный вариант демонстрирует опасность интерпретации регрессии для двух детерминированных трендов.
Не лучше обстоит дело, когда переменные содержат стохастический тренд.
Предположим, что две переменные:
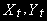 независимо сгенерированны процессами случайного блуждания с независимыми нормально распределенными ошибками.
независимо сгенерированны процессами случайного блуждания с независимыми нормально распределенными ошибками.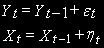
где
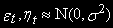 , и
, и  - псевдослучайные числа (стандартные) нормального распределения.
- псевдослучайные числа (стандартные) нормального распределения.Рассмотрим два уравнения регрессии:
(a) Между
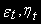 :
: 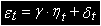
(b)
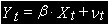
Проведя достаточно много реализаций, например, 50 000, определенного размера (по 50 наблюдений, например, каждая), методом Монте-Карло придем к
, и, оценив соответствующее число раз регрессии, можно получить экспериментальное распределение различных статистик.В случае (а) эмпирическое распределение t-статистики для
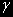 близко к теоретическому распределению Стьюдента.
близко к теоретическому распределению Стьюдента.В случае (b) эмпирическое распределение t-статистики для
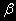 сильно отличается от теоретического распределения Стьюдента, хотя оно симметрично, стандартное отклонение гораздо больше, чем у распределения Стьюдента.
сильно отличается от теоретического распределения Стьюдента, хотя оно симметрично, стандартное отклонение гораздо больше, чем у распределения Стьюдента.В итоге, если использовать привычные нам таблицы распределения Стьюдента для проверки значимости регрессий для рядов со стохастическими трендами, в 2/3 случаев можно получить, что регрессия будет «хорошей» (коэффициенты значимы). И примерно в 75% случаев будет отвергнута верная гипотеза об отсутствии связи.
Аналогично с другими коэффициентами. Хотя процессы
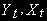 независимы, регрессия (b) с большой вероятностью даст высокий (из-за нестационарности) коэффициент детерминации.
независимы, регрессия (b) с большой вероятностью даст высокий (из-за нестационарности) коэффициент детерминации.Вышеприведенные два примера показывают, почему экономисты не любят строить регрессию для временных рядов со стахостическим или детерминированным трендом. Использование метода наименьших квадратов для оценивания параметров и проверки гипотез является эффективным лишь тогда, когда ряды (процессы) являются стационарными.
Многие экономические переменные перед использованием в регрессионном анализе, подвергаются преобразованиям. Наиболее удобным способом освобождения от тренда, с учетом сказанного, является переход к разностям такого порядка, который обеспечивает стационарность.
Для процессов со стохастическим трендом типа случайного блуждания стационарной будет первая разность:
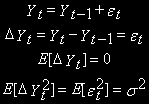
Аналогичный вывод можно сделать для процесса случайного блуждания с дрейфом.
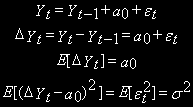
Иногда необходимо переходить к разностям более высокого порядка, чтобы достичь стационарности.
Например, если
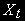 - процесс случайного блуждания
- процесс случайного блуждания 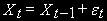 , а
, а 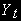 равен:
равен: 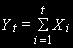 (1)
(1)то лишь вторая разность этого процесса будет стационарной:
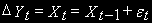 - нестационарна
- нестационарна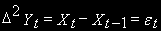 - стационарна.
- стационарна.С позиции этих результатов, особую важность приобретают так называемые интегрированные процессы. Это понятие связано с именами Энгл, Гренджер.
Нестационарный процесс, первые разности которого стационарны, называют интегрированным первого порядка и обозначают I(1).
Стационарный процесс обозначают I(0).
Если k-тые разности случайного процесса стационарны, то его называют интегрированным k-того порядка и обозначают I(k).
Процессы случайного блуждания и случайного блуждания с дрейфом – I(1),
Процесс (1) – интегрированный второго порядка I(2).
С осознанием опасности применения метода наименьших квадратов к нестационарным рядам, появилась необходимость в тестах, которые позволили бы отличить стационарный процесс от нестационарного.
Неформальные методы тестирования стационарности нам уже известны – визуальный анализ графиков автокорреляционной функции и спектральной плотности.
Среди формальных тестов самым известным в настоящее время является тест, разработанный Дики и Фуллером (DF = Dickey-Fuller integration test).
Но в начале о том, как соотносятся стационарность и единичные корни.
Рассмотрим AR(1), причем определим его так:
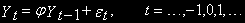
где
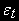 - белый шум.
- белый шум.Этот процесс стационарен, если
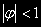 . Это легко доказывается с использованием лагового оператора В.
. Это легко доказывается с использованием лагового оператора В.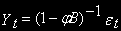 , т.е. бесконечный процесс МА.
, т.е. бесконечный процесс МА.Если
, то 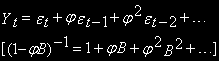
Откуда легко видно, что
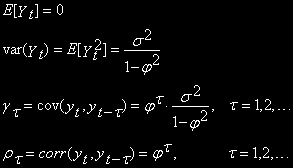
И математическое ожидание, и дисперсия, и автокорреляция не зависят от времени. То есть AR(1) стационарен, если
.Представим это условие стационарности по-другому: запишем уравнение AR(1) через оператор авторегрессии
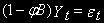
Корнем характеристического уравнения
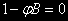 является
является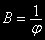
• И условие
эквивалентно требованию о том, чтобы корень был по модулю больше единицы (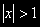 ), что говорит о том, что процесс стационарен;
), что говорит о том, что процесс стационарен;• Если
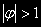 , или, что то же самое,
, или, что то же самое, 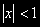 , процесс взрывной;
, процесс взрывной;• Если же
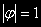 , а это имеет место тогда и только тогда, когда
, а это имеет место тогда и только тогда, когда 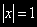 , условие стационарности не выполняется. Имеет место случайное блуждание, в нестационарности которого уже мы убедились.
, условие стационарности не выполняется. Имеет место случайное блуждание, в нестационарности которого уже мы убедились.Тестирование стационарности, таким образом, напрямую связано с определением единичных корней.
3.1 Определение единичных корней методом Дики-Фуллера
Дики и Фуллер (1979,1981) рассматривают процесс AR(1)
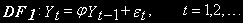 (2)
(2)Нулевая гипотеза
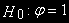 .
.Против альтернативной
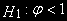 .
.Т.е. нулевая гипотеза предполагает, что
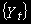 нестационарен будучи случайным блужданием. Согласно альтернативной гипотезе, - стационарный процесс AR(1) [или интегрированный порядка ноль –I(0)],
нестационарен будучи случайным блужданием. Согласно альтернативной гипотезе, - стационарный процесс AR(1) [или интегрированный порядка ноль –I(0)], 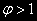 не рассматривается.
не рассматривается.На первый взгляд, можно построить уравнение авторегрессии и проверить гипотезу по критерию Стьюдента. Но, как уже отмечалось, процедура тестирования, базирующаяся на применении метода наименьших квадратов, к нестационарному ряду (а
нестационарен, если 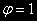 ), может вводить в заблуждение, показывая значимость фактора в то время, как он таким не является.
), может вводить в заблуждение, показывая значимость фактора в то время, как он таким не является.Процедура тестирования должна базироваться на такой модели, которая будет стационарнй при принятии
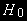 .
.Дики и Фуллер предложили приемлемый и простой метод тестирования
на порядок интеграции, который берет за основу эквивалентное уравнение регрессии: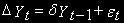 (3)
(3)где
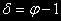
[действительно:
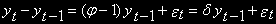 ].
].И строго говоря, DF-тест в качестве
принимает утверждение: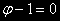
Отсюда его название – unit root test – тест на единичный корень.
Уравнение (3) может быть представлено еще следующим образом:
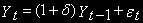
Если в уравнении (2)
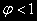 , то в уравнении (3)
, то в уравнении (3) 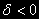 (отрицательно) – означает стационарность процесса.
(отрицательно) – означает стационарность процесса.Тест DF состоит в проверке отрицательности
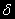 . Отклонение нулевой гипотезы (
. Отклонение нулевой гипотезы (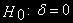 ) в пользу альтернативной (
) в пользу альтернативной (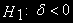 ) означает, что и процесс – I(0)
) означает, что и процесс – I(0)Если
- I(1), как предполагает нулевая гипотеза, уравнение (3) представляет регрессию I(0)–переменной по I(1)-переменной.. Не удивительно, что 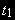 -статистика имеет нестандартное распределение. Для ее использования требуются специальные таблицы. Такие таблицы были получены эмпирически, с использованием метода Монте-Карло. За основу был взят процесс AR(1) с .
-статистика имеет нестандартное распределение. Для ее использования требуются специальные таблицы. Такие таблицы были получены эмпирически, с использованием метода Монте-Карло. За основу был взят процесс AR(1) с .В силу эмпирического скорее, чем теоретического, характера таблиц, они содержат элемент неопределенности – дается не одно, а два теоретических значений – верхнее и нижнее. Если расчетное значение
-статистики меньше, чем нижнее допустимое критическое значение, то гипотеза (нулевая гипотеза о единичном корне) отвергается, и принимается стационарность (цифры в таблице подразумеваются отрицательными). Если же расчетное значение -статистики больше верхнего допустимого значения критической величины, то отвергнута. Между верхними и нижними пределами зона неопределенности.Тест Дики-Фуллера может быть использован для проверки стационарности процессов, порожденных случайным блужданием с дрейфом, т.е. путем проверки уравнения:
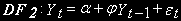 (4)
(4)Техника проверки аналогична. Эквивалентное (4) уравнение:
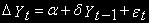
Но с учетом того, что распределение t-статистики для
в этом случае другое, - обозначим его через 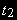 - в основе лежит процесс случайного блуждания с дрейфом, используются другие критические значения.
- в основе лежит процесс случайного блуждания с дрейфом, используются другие критические значения.Еще одна модификация уравнения DF – включение линейного детерминированного тренда.
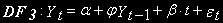 (5)
(5)или
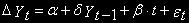
Это уравнение позволяет проверить отсутствие стохастического тренда (
) и существование детерминированного тренда (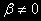 ). Для этого теста составлены свои таблицы критических значений -
). Для этого теста составлены свои таблицы критических значений - 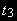 .
.Итак, если
, то •
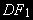 (2) – стационарный процесс AR(1) с нулевым средним,
(2) – стационарный процесс AR(1) с нулевым средним, •
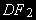 (4) – стационарный процесс AR(1) со средним
(4) – стационарный процесс AR(1) со средним 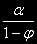 ,
, •
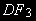 (5) – стационарный процесс AR(1) вокруг линейного тренда, если .
(5) – стационарный процесс AR(1) вокруг линейного тренда, если .ü Если данные генерируются в соответствии с процессом
(2) с , то можно сказать, что - интегрированный процесс первого порядка I(1) и является случайным блужданием без дрейфа.ü Если данные получены согласно
(4) с и ненулевым 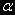 , тогда опять таки I(1), но является случайным блужданием с дрейфом.
, тогда опять таки I(1), но является случайным блужданием с дрейфом.ü Если данные генерируются процессом
(5) с и ненулевым , то - случайное блуждание вдоль ненулевого временного тренда.Если есть основания предполагать, что рассматриваемая переменная нестационарна и имеет тренд, то начать тестирование рекомендуется с регрессии
(5) и соответствующего теста .Недостаток теста DF заключается в том, что тест Дики-Фуллера имеет ограничения:
1. Предположение о том, что переменная следует авторегрессионному процессу первого порядка;
2. Ошибки
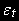 нескоррелированы.
нескоррелированы.Дики и Фуллер предложили использовать в качестве дополнительных (экзогенных переменных) регрессоров переменную в левой части уравнения, взятую с различными лагами (лаги первой разности).
Модифицированный тест DF предусматривает авторегрессионные процессы более высоких порядков и носит название дополнительного (расширенного) теста Дики-Фуллера (AFD – augment Dickey-Fuller test).
Базовые уравнения принимают следующий вид:
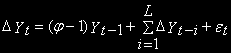
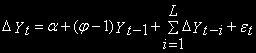
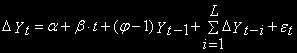
Дополнительная авторегрессионная компонента вводится для того, чтобы убрать автокорреляцию остатков, к которой чувствителен DF-тест. Распределение тестов для этих уравнений асимптотически совпадают с соответствующими тестами DF и используют те же таблицы.
3.2 Концепция коинтеграции
Наличие трендов во временных рядах, пожалуй, можно рассматривать как главную проблему эмпирической эконометрии. Тренды, как стохастические, так и детерминированные, могут стать причиной ложных регрессий.
Но налицо неопровержимый факт: в экономике большая часть временных рядов содержит тренды какого-либо типа. Для избавления от тренда можно выполнить преобразования в виде перехода к разностям такого порядка, которые будут стационарными.
Но это не лучшее решение. Применение оператора взятия, например, первых разностей к переменным приводит к потере долгосрочных свойств процессов, т.к. модель в первых разностях не имеет долгосрочного решения.
Стремление получить модель, которая учитывала бы краткосрочные и долгосрочные особенности процессов и в то же время поддерживала бы стационарность всех переменных, подтолкнуло к пересмотру принципов построения регрессии.
Этот подход основывается на таких экономических данных, которые, будучи нестационарными, могут быть скомбинированы в один ряд, который будет уже стационарным. Ряды, обладающие такой особенностью, называются коинтегрированными рядами .
Если, например, оказывается, что переменные являются I(1) - интегрированными первого порядка и привычные методы регрессионного анализа к ним не подходят, то в этом случае используют так называемую коинтеграционную регрессию.
Процессы I(1) являются коинтегрированными первого порядка [С(1,0)], если существует их линейная комбинация, которая является I(0), т.е. стационарна.
То есть Y и X, являющиеся I(1), коинтегрированы, если существует множитель
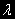 , такой, что
, такой, что 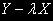 является I(0).
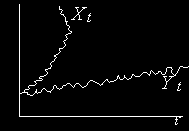
является I(0).Легко изобразить на рисунке два таких нестационарных I(1) процесса, которые связаны друг с другом стационарной линейной комбинацией с
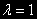 . В этом случае, как бы будут «двигаться параллельно» во времени.
. В этом случае, как бы будут «двигаться параллельно» во времени.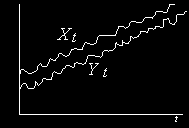
Пример рядов, линейная комбинация которых
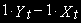 нестационарна.
нестационарна.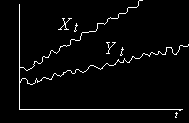
Однако во втором случае можно подобрать такое
, что разность 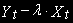 будет стационарной. Например,
будет стационарной. Например, 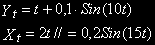

Разность
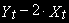 будет стационарной (это можно проверить на компьютере), т.е. при
будет стационарной (это можно проверить на компьютере), т.е. при 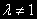 переменные могут и не изменяться во времени одинаково, точнее одна переменная может расти быстрее другой. Но!!!
переменные могут и не изменяться во времени одинаково, точнее одна переменная может расти быстрее другой. Но!!!Очевидно, что коинтегрированными могут быть только такие два временных ряда, которые интегрированы одинакового порядка. Если одна переменная I(1), а другая – I(2), они не могут быть коинтегрированными.
Формальное определение коинтеграции двух переменных, разработанное Энглом и Грейнджером (1987).
Временные ряды
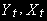 называются коинтегрированными порядка d, b, где
называются коинтегрированными порядка d, b, где 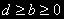 , - обозначается:
, - обозначается: 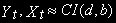 , если:
, если:Оба временных ряда интегрированы порядка d;
Существует линейная комбинация этих переменных
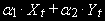 , которая интегрированны порядка (d-b).
, которая интегрированны порядка (d-b). Вектор [
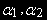 ] называется коинтеграционным вектором.
] называется коинтеграционным вектором. Обобщим это определение для случае n переменных.
Пусть
- вектор размерности [n+1], включающий 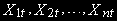 , причем
, причемКаждая переменная
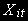 - I(d)
- I(d)Существует (
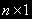 )-мерный вектор такой, что
)-мерный вектор такой, что 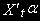 - I(d,b), т.е. - CI(d,b).
- I(d,b), т.е. - CI(d,b).На практике наиболее интересна ситуация, когда ряды трансформированные с помощью коинтегрирующего вектора, стационарны, и d = b, а коинтегрирующий коэффициенты, составляющие коинтегрирующий вектор, могут быть определены на основе долгосрочной зависимости между переменными.
Остановимся на ситуации, когда все
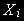 - I(d).
- I(d).Если
- I(1), и долгосрочная зависимость между ними определяется как 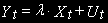 (1)
(1)то коинтегрирующий вектор [
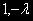 ] и отклонение от долгосрочной траектории
] и отклонение от долгосрочной траектории 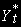 - I(0), т.е. стационарно.
- I(0), т.е. стационарно.Здесь, на этом этапе важно показать, что линейная комбинация
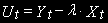 действительно стационарна. Для этого предлагается применить метод Дики-Фуллера к остаткам из коинтеграционной регрессии.
действительно стационарна. Для этого предлагается применить метод Дики-Фуллера к остаткам из коинтеграционной регрессии.Тест Энгла-Грейнджера проводится с помощью регрессии
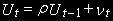
Распределение t-статистики для гипотезы
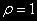 в этой регрессии будет отличаться от распределения DF-статистики, но имеются соответствующие таблицы.
в этой регрессии будет отличаться от распределения DF-статистики, но имеются соответствующие таблицы.Нулевой гипотезой, следовательно, является отсутствие коинтеграции (отсутствие стационарности,
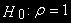 )
)Если гипотеза об отсутствии коинтеграции отвергается, то полученные результаты не являются ложной регрессией.
После этого можно оценить модель исправления ошибок, которая делает переменные коинтегрированными. В этой модели (регрессии) используются первые разности исходных переменных и остатки из коинтеграционной регрессии, которые будут представлять корректирующий член модели исправления ошибок.
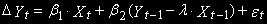 (2)
(2)Здесь зависимая переменная
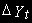 и регрессоры
и регрессоры 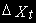 и
и 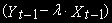 - I(0). И поэтому нет опасности получения ошибочной (ложной) регрессии из-за наличия стохастического или детерминированного тренда в данных. В такой регрессии t-статистики и F-статистики будут иметь обычные асимптотические распределения и можно использовать их для проверки гипотез о модели. (но не стоит пытаться проверять гипотезы с помощью статистик, полученных в коинтеграционной регрессии).
- I(0). И поэтому нет опасности получения ошибочной (ложной) регрессии из-за наличия стохастического или детерминированного тренда в данных. В такой регрессии t-статистики и F-статистики будут иметь обычные асимптотические распределения и можно использовать их для проверки гипотез о модели. (но не стоит пытаться проверять гипотезы с помощью статистик, полученных в коинтеграционной регрессии).До появления метода Энгла-Грейрджера исследователи, не подозревая о том, часто получали ложные регрессии, или же оценивали регрессии в новых разностях, что, хотя и приводило к стационарности переменных, но не давало возможности учитывать стационарный корректирующий член, т.е. регрессионная модель была неверно специфицирована (проблема пропущенной переменной). Тем самым подчеркивается роль корректирующего элемента (предполагается, что если в предыдущий период переменная Y отклонилась от своего долгосрочного значения, то член
корректирует динамику в нужном направлении).Модель включает долгосрочное решение и механизм корректировки (исправления) ошибки, если
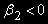 .
. Возможны различные варианты сочетания и коинтеграции в рассмотренной модели (2).
1. Если
~ I(1), а ~ I(0), то ut ~ I(1), и переменные и коинтегрированы.2. Если
~ I(1), а ~ I(1), то возможно, что ut ~ I(0) и переменные и коинтегрированы, только если коинтегрирующий вектор равен [λ,-1].3. Если
~ I(0), а ~I(0), то ut ~ I(0), и о коинтеграции нельзя ничего сказать.4. Если
~ I(0), а ~ I(1), то ut ~ I(1), и переменные и некоинтегри-рованны.Следовательно, в долгосрочной зависимости между двумя переменными обе должны быть интегрированы одного порядка, чтобы ряд ошибок был I(0).
Стационарность ошибок особенно важна, если строится модель, предусматривающая механизм исправления ошибки.
Задача существенно усложняется, если количество переменных, включаемых в долгосрочную зависимость, увеличиваются.
Рассмотрим случай трех переменных:
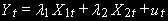 (3)
(3)В этом случае допускается, чтобы порядок интеграции у переменных был разным, а ряд ошибок был при этом стационарным.
Пусть
~ I(0), 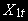 ~ I(1)
~ I(1) 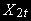 ~ I(1). По аналогии с предыдущим анализом, можно ожидать, что ut ~ I(1). Может, однако, случиться, что
~ I(1). По аналогии с предыдущим анализом, можно ожидать, что ut ~ I(1). Может, однако, случиться, что 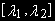 составляет коинтегрирующий вектор для и , и тогда линейная комбинация
составляет коинтегрирующий вектор для и , и тогда линейная комбинация 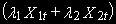 ~ I(0), т.к. и ~ I(1) интегрированы одного порядка. В этом случае
~ I(0), т.к. и ~ I(1) интегрированы одного порядка. В этом случае 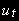 будет стационарна, т.к. ~ I(0) и ~ I(0). В экономике более распространена ситуация, когда ~ I(1), ~ I(2) и ~ I(2). Несмотря на разные порядки интеграции, переменная ошибок будет стационарной, т.к. ~ I(1). Т.е. если , ~ СI(2) с коинтегрирующим вектором .
будет стационарна, т.к. ~ I(0) и ~ I(0). В экономике более распространена ситуация, когда ~ I(1), ~ I(2) и ~ I(2). Несмотря на разные порядки интеграции, переменная ошибок будет стационарной, т.к. ~ I(1). Т.е. если , ~ СI(2) с коинтегрирующим вектором .3.3 Тестирование коинтеграции (Энгла-Грейнджера)
Алгоритм тестирования разработан Энглом и Грейнджером.
Шаг 1.
Проверка порядка интеграций, включаемых в предполагаемую нами долгосрочную зависимость (например, типа уравнения (1)).
Если долгосрочная зависимость связывает только две переменные, обе должны иметь одинаковый порядок интеграции.
Если количество объясняющих переменных больше, чем одна, порядок интеграции зависимой переменной не может быть выше, чем порядок интеграции любой из объясняющих переменных, порядок интеграции которых одинаков и выше, чем порядок интеграции зависимой переменной.
Шаг 2.
Выясняется, известен ли коинтеграционный вектор, или его нужно найти.
Иногда коинтеграционный вектор известен a priori (ситуация А). Но чаще долгосрочную зависимость представляют в форме (1) или (3), и коинтеграционный вектор [1, -λ] или
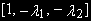 соответственно. Коэффициенты этих векторов рассчитываются с помощью МНК (ситуация B).
соответственно. Коэффициенты этих векторов рассчитываются с помощью МНК (ситуация B).В общем случае определяется долгосрочная зависимость:
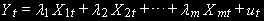 (4)
(4)Коинтеграционный вектор
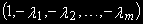 находится МНК. Ошибки , полученные из коинтеграционного уравнения (4), проверяем на стационарность, используя тест Дики-Фуллера:
находится МНК. Ошибки , полученные из коинтеграционного уравнения (4), проверяем на стационарность, используя тест Дики-Фуллера: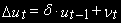
или расширенный тест D-F:
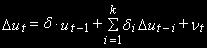
Важное различие между ситуацией A и ситуацией B состоит в том, что в ситуации B при расчете коинтеграционных коэффициентов распределение t-статистики Стьюдента зависит от количества оцениваемых коэффициентов.
В интеграционном и коинтеграционном тестах с известным вектором коинтеграции, количество коэффициентов, которые нужно оценить, равно нулю. Так критические значения теста можно взять в таблице 1 приложения.
Если нужно найти m коэффициентов коинтеграционного вектора, можно пользоваться таблицей 2 (или таблицей 3, если в уравнении есть константа).
Для быстрой проверки гипотезы тестирования коинтеграция может быть использовано довольно простое эмпирическое правило, предложенное Banerjee (1986). В основе этого теста (правила) лежит коинтеграционный тест Дарбина-Уотсона:
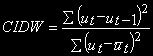 ,
,где
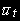 - среднее арифметическое .
- среднее арифметическое .Если CIDW, рассчитанный для остатков уравнения (4), меньше, чем коэффициент детерминации
для этого уравнения, гипотеза о коинтеграции, скорее всего, неверна, иначе 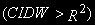 - коинтеграция может иметь место. Можем установить в этом случае, что если обычная статистика DW, рассчитанная для ошибок статистической модели, представляющей долгосрочную зависимость, близка к 2, то, скорее всего, коинтеграция переменных подтверждается.
- коинтеграция может иметь место. Можем установить в этом случае, что если обычная статистика DW, рассчитанная для ошибок статистической модели, представляющей долгосрочную зависимость, близка к 2, то, скорее всего, коинтеграция переменных подтверждается.Известен и широко распространен еще один метод нахождения стационарных комбинаций – метод Йохансена. Этот метод служит также для тестирования стационарности найденных линейных комбинаций, и, по сути, распространяет методику Дики-Фуллера на случай векторной авторегрессии, т.е. такой модели, в которой несколько зависимых переменных и зависят они от собственных лагов и от лагов других переменных.