
Современный интеллектуальный анализ нечетких временных рядов
| Вид материала | Документы |
- Программа дисциплины Анализ финансово-экономических временных рядов для направления, 76.91kb.
- Модификация программного комплекса ас дрм для обработки временных рядов в технике, 125.29kb.
- Рабочая программа дисциплины экономический анализ временных рядов цели и задачи изучения, 118.03kb.
- Программа дисциплины Нелинейные модели временных рядов для направления 521600 Экономика, 66.64kb.
- Статистика временных рядов, 19.49kb.
- Пояснительная записка: Требования к студентам: необходимо знание курсов «Математического, 78.04kb.
- Пояснительная записка: Требования к студентам: необходимо знание курсов «Математического, 49.13kb.
- Программа дисциплины Анализ временных рядов для направления 080100. 68 «Экономика», 259.15kb.
- Оценка производственных функций, 268.17kb.
- Статистический анализ временных рядов, 34.55kb.
СОВРЕМЕННЫЙ ИНТЕЛЛЕКТУАЛЬНЫЙ АНАЛИЗ НЕЧЕТКИХ ВРЕМЕННЫХ РЯДОВ
Ярушкина Н.Г., д.т.н., профессор
Ульяновский государственный технический университет
тел.:(8422)-43-03-23
e-mail: jng@ulstu.ru
1. ВВЕДЕНИЕ
Большинство сложных объектов анализа обладают объективной неопределенностью, что требует дальнейшего расширения инструментария прогностики. Все чаще используются интеллектуальные методы, которые расширяют классическую классификацию прогностических методов и представляют сочетание формализованных процедур обработки информации, полученной по оценкам специалистов-экспертов. Исследования данных и методов анализа в последние десятилетия оформились в виде отдельного направления, называемого Times-Series Data Mining. В работах ряда зарубежных ученых [1, 2, 3] исследованы методы нечеткой регрессии, анализа данных нечетких временных рядов (ВР). Данной теме посвящены также следующие работы [4, 5, 6, 7]. Несмотря на новизну, данное направление прошло ряд этапов в развитии собственной теории.
2. ОСНОВНЫЕ ЭТАПЫ РАЗВИТИЯ ТЕОРИИ НЕЧЕТКИХ ВРЕМЕННЫХ РЯДОВ
- Этап нечеткой регрессии. Первыми были исследованы модели нечеткой регрессии.
- Этап мягких вычислений. Развитие методов мягких вычислений породило большое количество работ, исследующих эффективность мягких вычислений для анализа ВР.
- Этап нечетких временных рядов. Следующим этапом был этап перехода к анализу нечетких временных рядов, а не использования нечетких методов для анализа четких ВР.
- Этап извлечения правил (Data Mining) из нечетких (гранулированных ВР). Развитие методов нечетких баз данных и методов DM для реляционных баз данных позволило перейти к данному этапу.
3. ОПРЕДЕЛЕНИЕ НЕЧЕТКОЙ РЕГРЕССИИ
В 1982 г. Х. Танака [1] рассмотрел модель линейной регрессии с нечетким коэффициентом и использовал методы линейного программирования. В 1987 г. A. Cелминс и П. Даймонд ввели анализ нечеткой регрессии, основанной на методе наименьших квадратов [8, 9]. Большинство работ, посвященных нечеткой регрессии были основаны на следующих базовых определениях.
Пусть дано множество наблюдений:
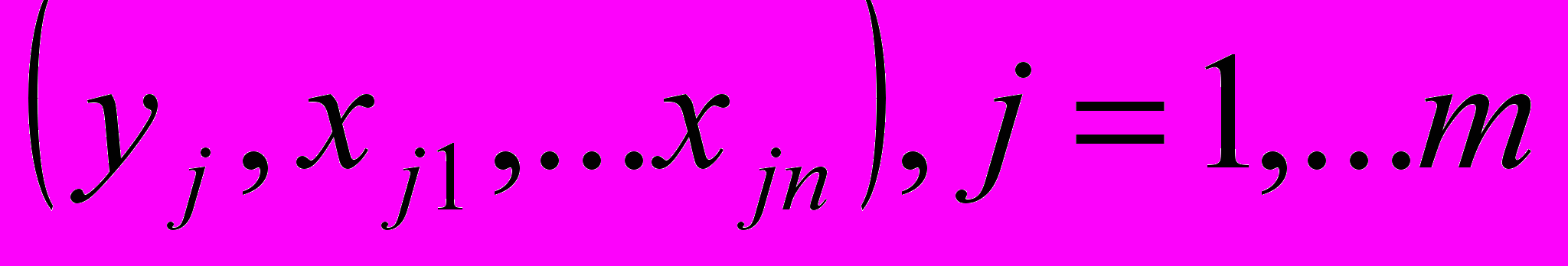 , необходимо найти нечеткую модель по следующей форме:
, необходимо найти нечеткую модель по следующей форме: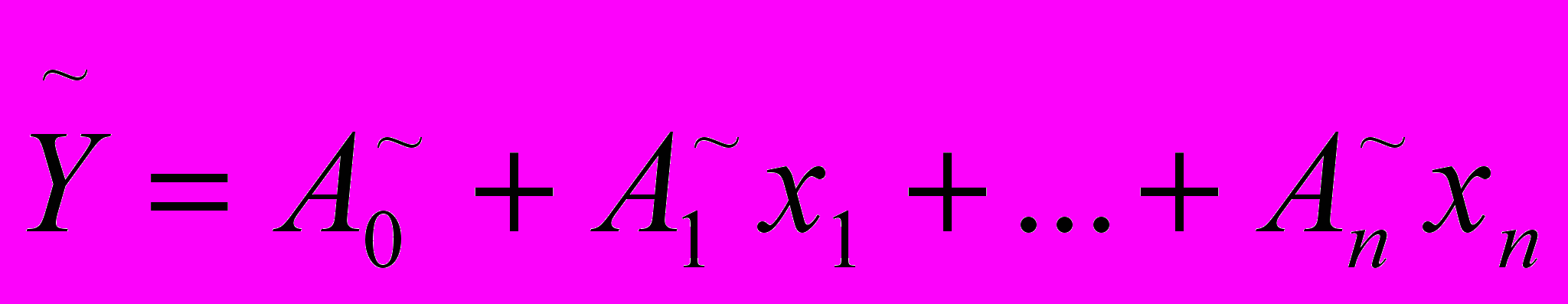
где
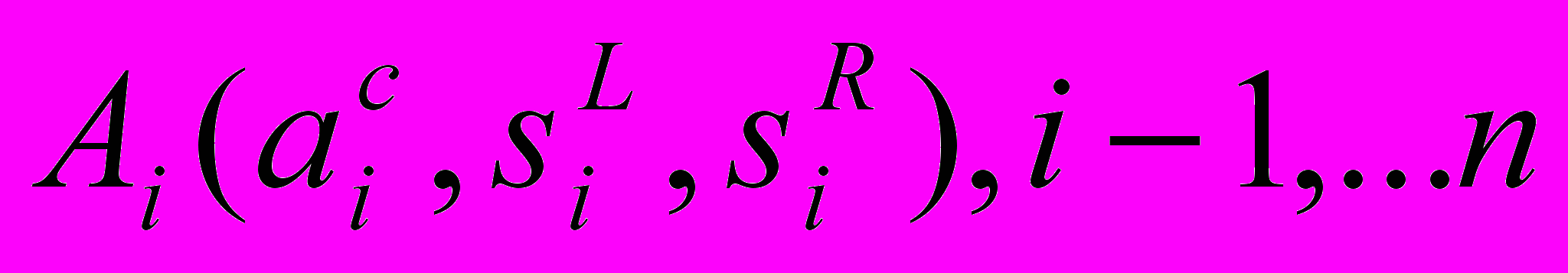 –триангулярные нечеткие числа,
–триангулярные нечеткие числа, 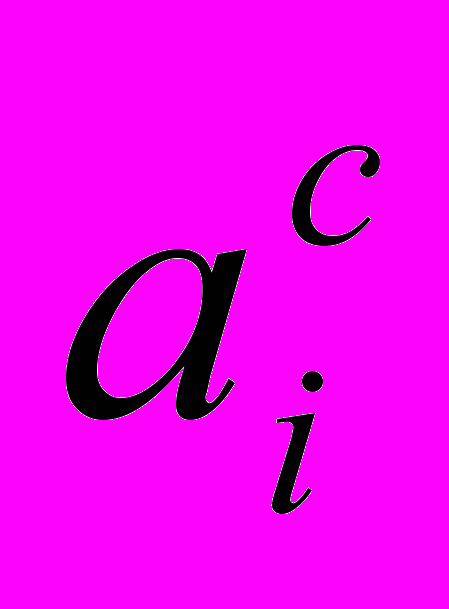 –среднее значение
–среднее значение 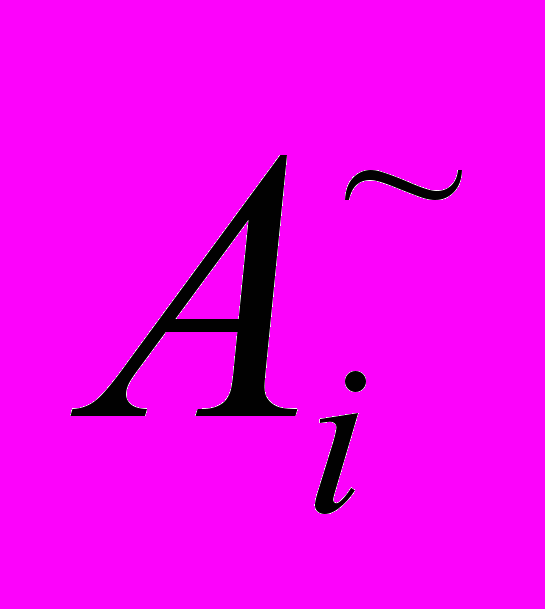 ,
, 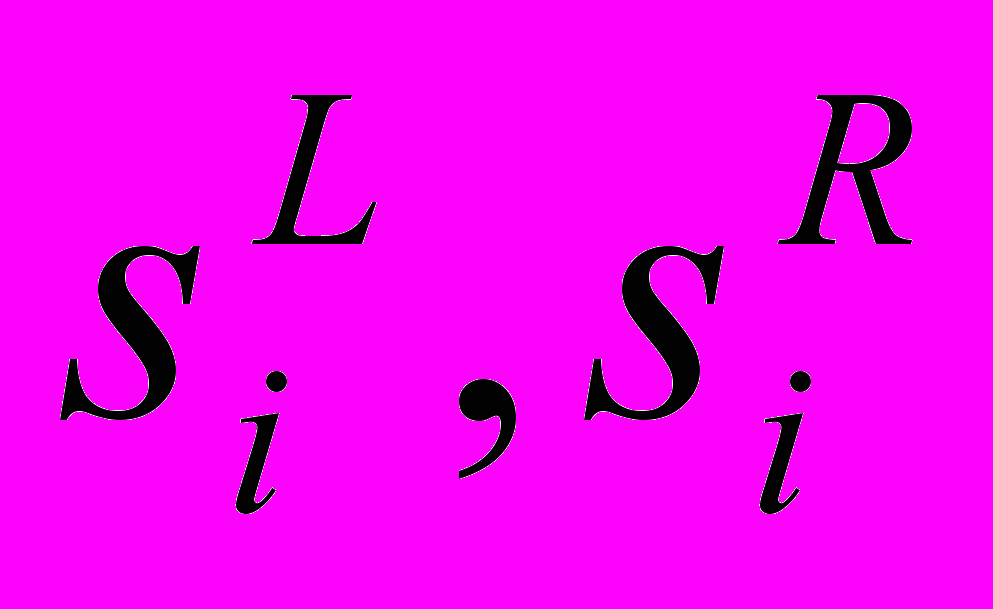 показывают левый и правый разброс соответственно.
показывают левый и правый разброс соответственно.Используются два критерия, чтобы определить нечеткие коэффициенты модели.
1. Для всех наблюдений принадлежность значения yj к его нечеткой оценке
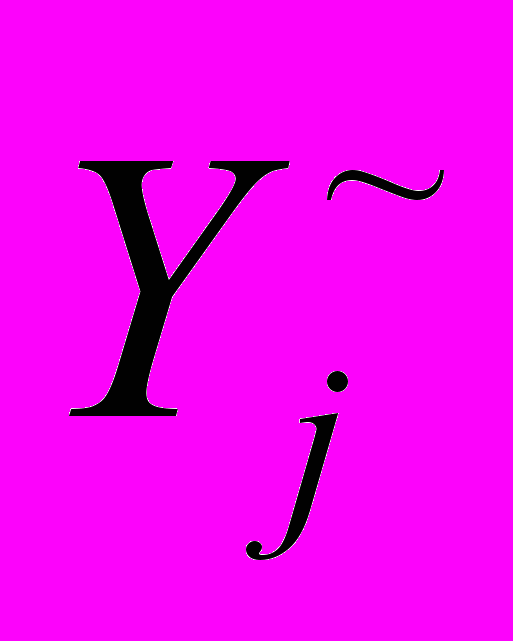 должна быть как минимум
должна быть как минимум 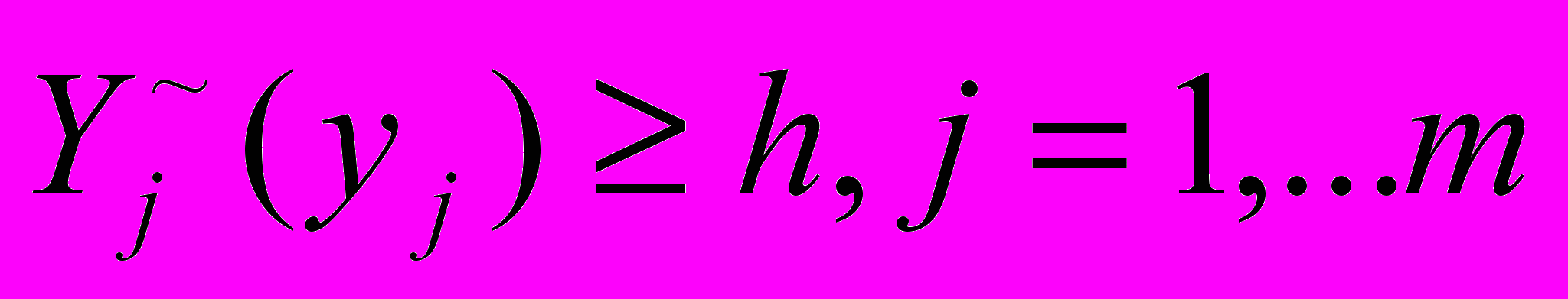 , где h – уровень доверия, выбранный лицом, принимающим решения.
, где h – уровень доверия, выбранный лицом, принимающим решения.2. Общая нечеткость предсказываемого значения зависимой переменной должна быть минимизирована. Это может быть достигнуто минимизацией суммы разбросов нечетких чисел для всех наборов данных. Итак, проблему настройки нечеткой модели с заданными данными
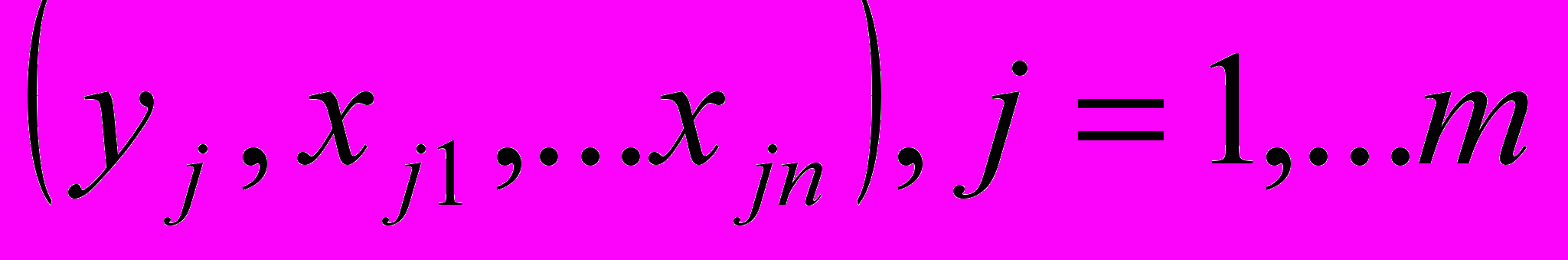 можно решить как эквивалентную задачу линейного программирования: найти
можно решить как эквивалентную задачу линейного программирования: найти 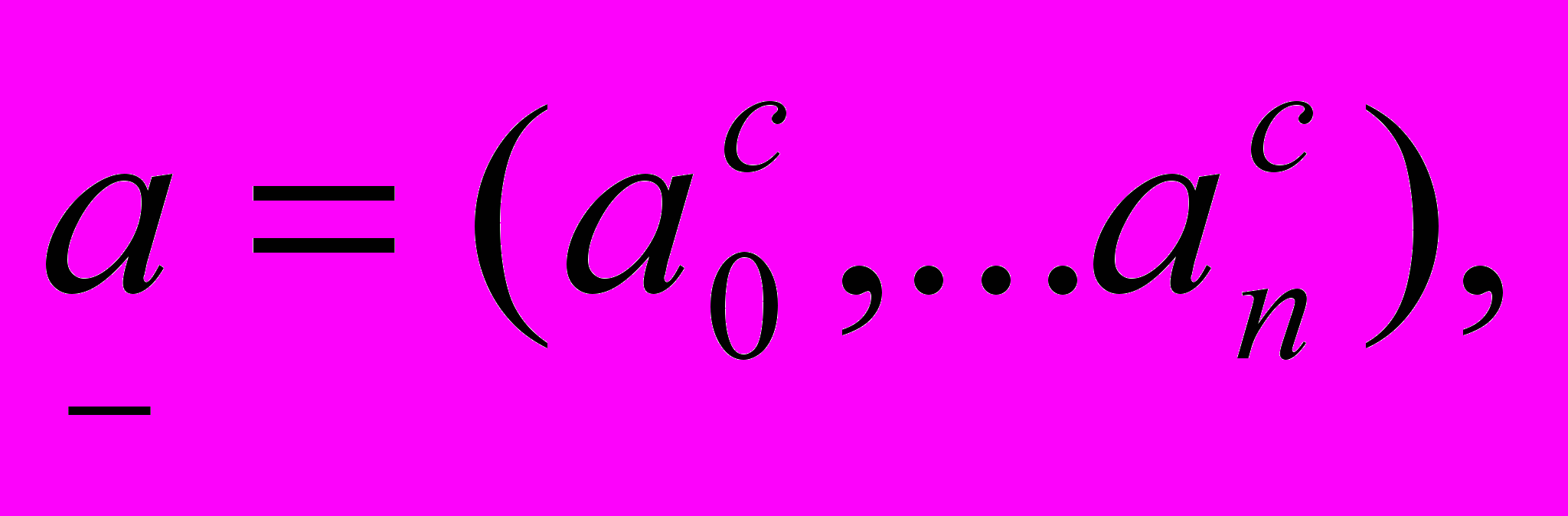
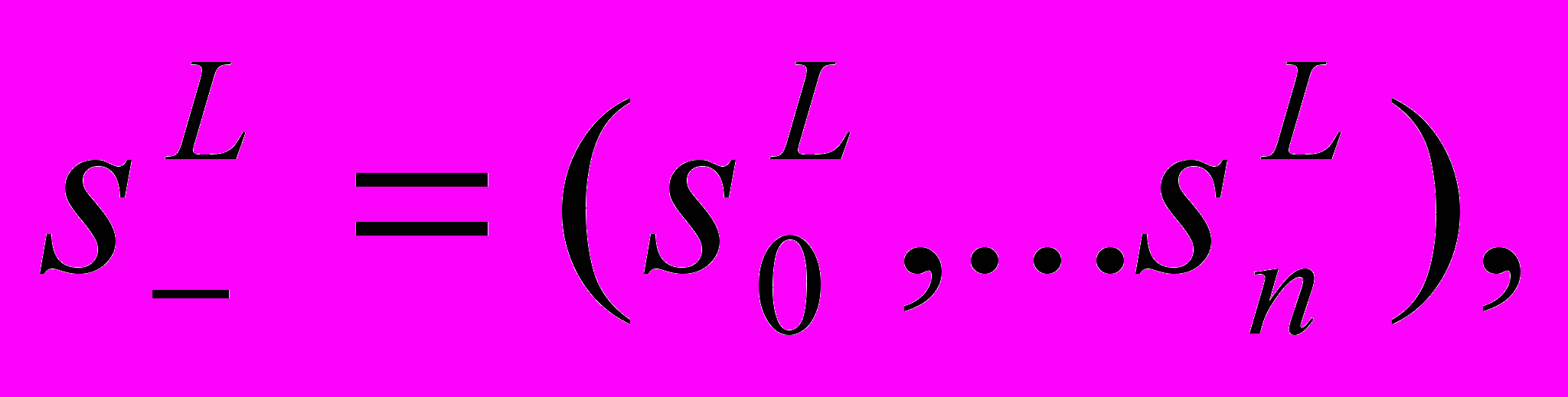
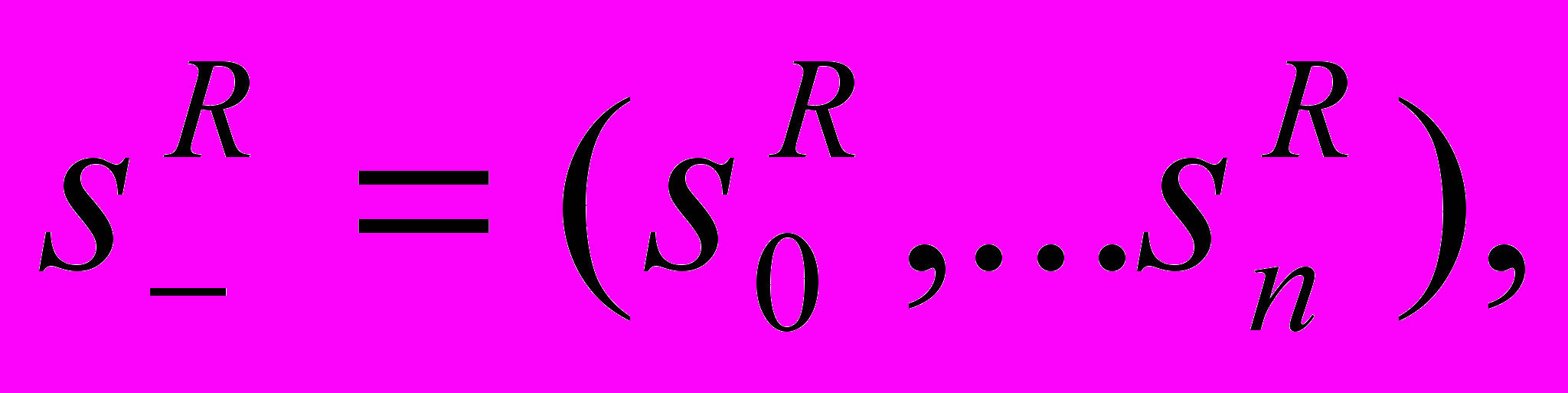 которые минимизируют:
которые минимизируют: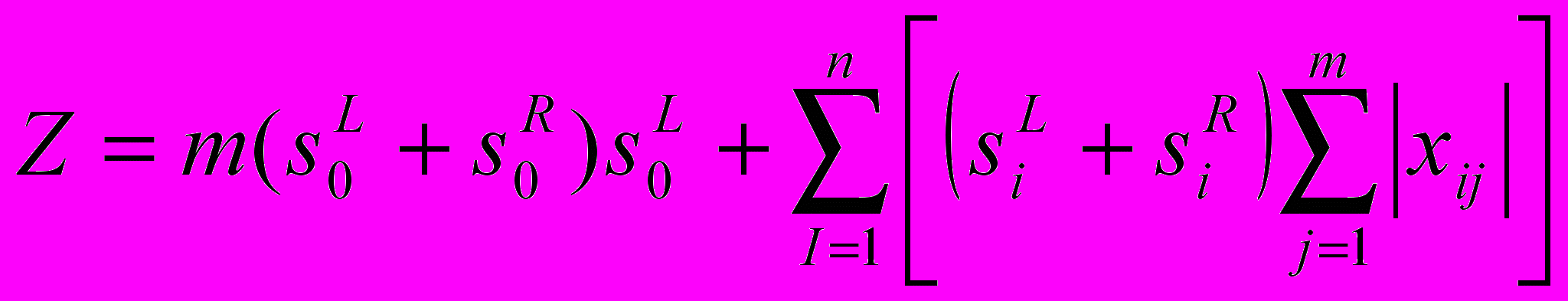 .
.Чтобы оценить качество настройки нечеткой регрессии, используют метод наименьших квадратов ( MSE). Для нечеткой регрессии MSE определяется следующим образом:
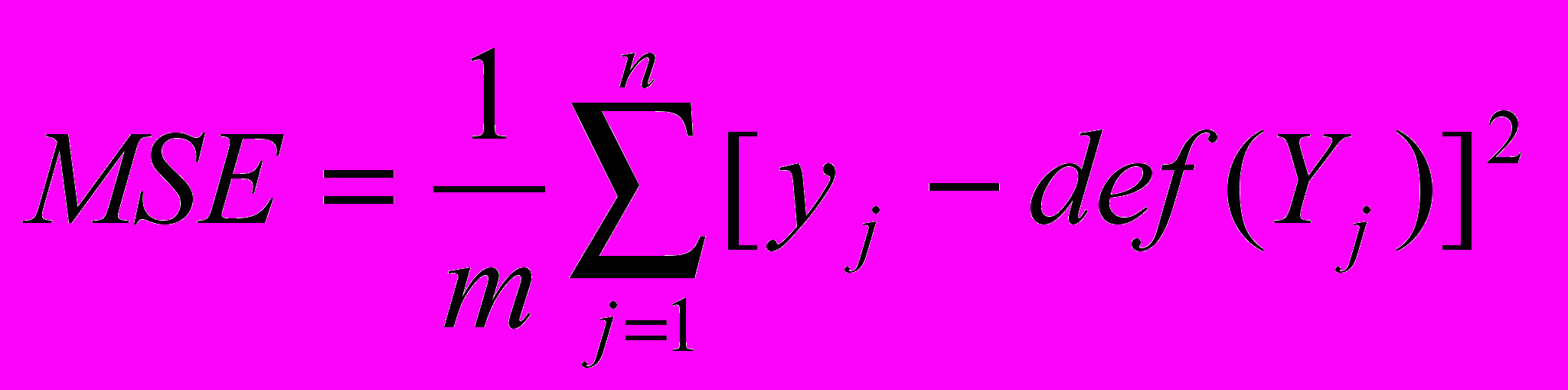 ,
,где
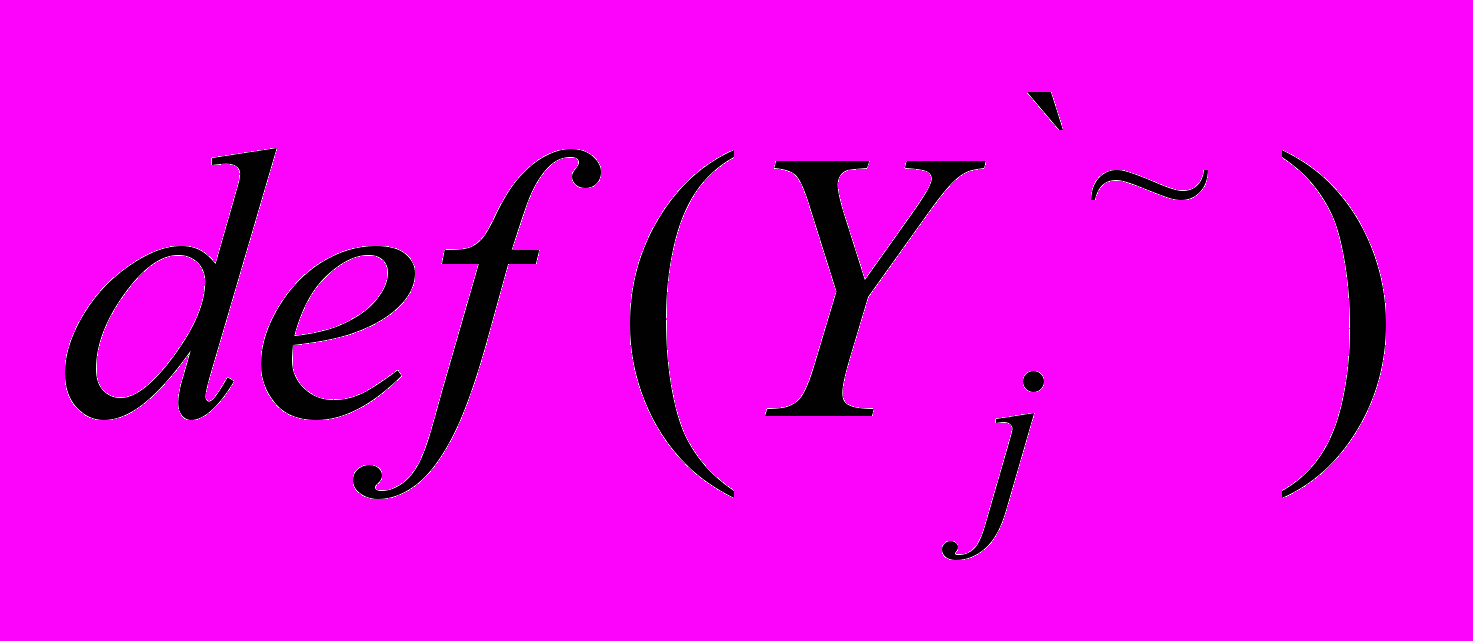 – дефаззифицированное значение зависимой переменной.
– дефаззифицированное значение зависимой переменной.Большинство работ, посвященные данной тематике, либо уточняли данную схему нечеткой регрессии, либо находили новые приложения для ее успешного применения.
4. ОСНОВНЫЕ ПОНЯТИЯ АВТОРЕГРЕССИИ НЕЧЕТКОГО ВРЕМЕННОГО РЯДА
В отличие от традиционного временного ряда значениями нечеткого ВР являются нечеткие множества, а не действительные числа наблюдений. В [10] К.Сонг и Б.Чиссон первыми дали определение моделей нечетких временных рядов.
Пусть

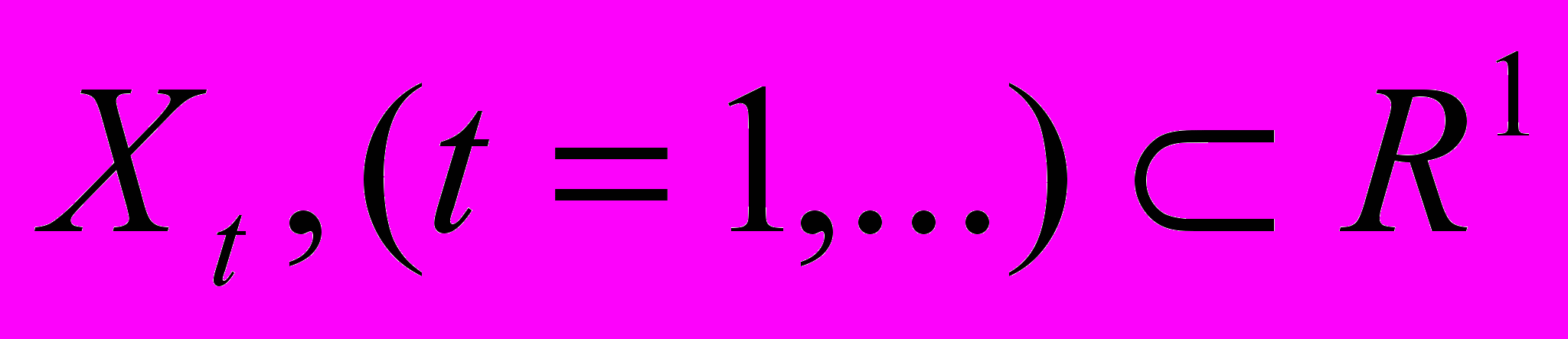 – универсум, на котором определены нечеткие множества yit, (i=1, 2,…) и Yt – коллекция yit, (i=1, 2,…).Тогда Yt, (t=1, 2,…) называется нечетким ВР.
– универсум, на котором определены нечеткие множества yit, (i=1, 2,…) и Yt – коллекция yit, (i=1, 2,…).Тогда Yt, (t=1, 2,…) называется нечетким ВР.На практике в большинстве ВР последовательные наблюдения зависимы:
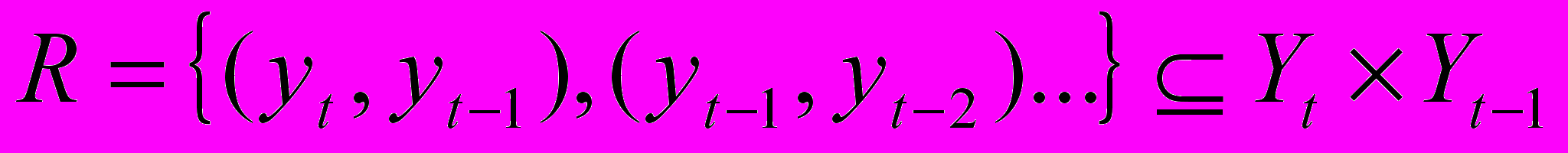 ,
,где Yt, Yt-1 обозначает переменные, а yt, yt-1 – наблюдаемые значения переменных. Наиболее частой моделью зависимости является явная функция отображения:
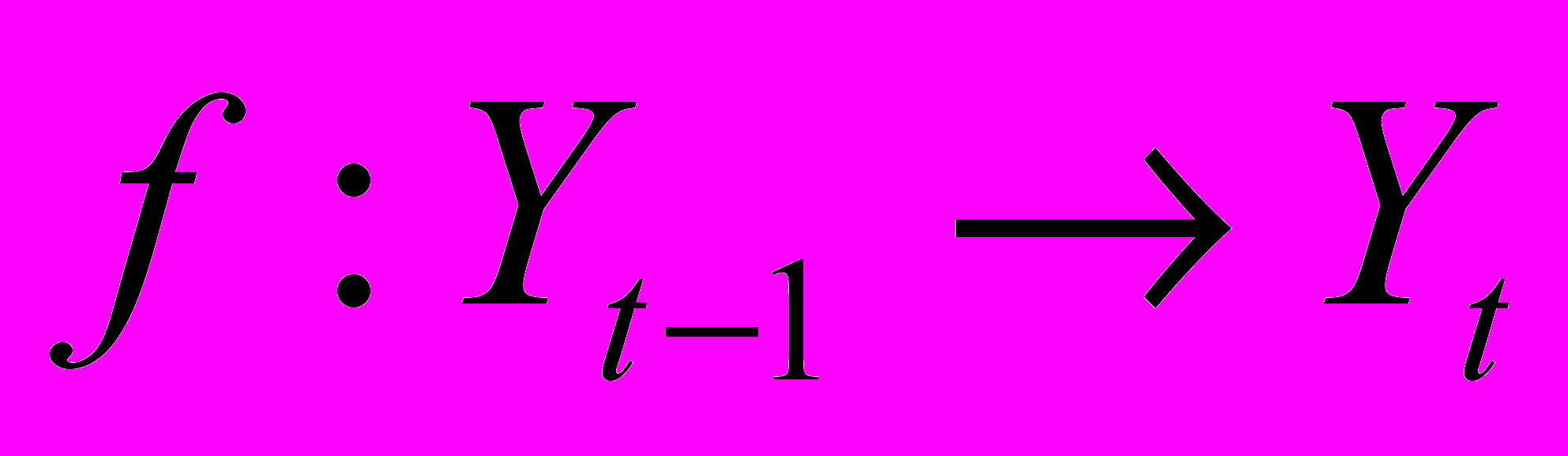
представленная линейной функцией (марковским процессом, модель AR):
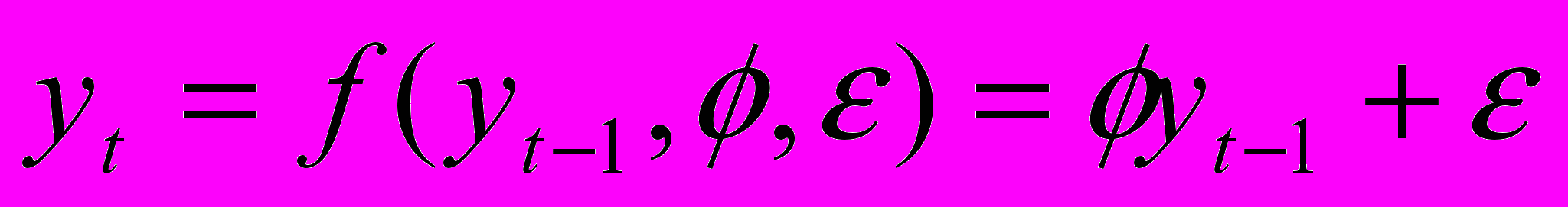 ,
,где
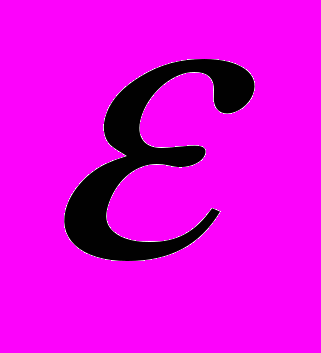 – случайная ошибка, шум.
– случайная ошибка, шум.В случае нечеткого временного ряда в качестве модели авторегрессии используется нечеткое разностное уравнение:
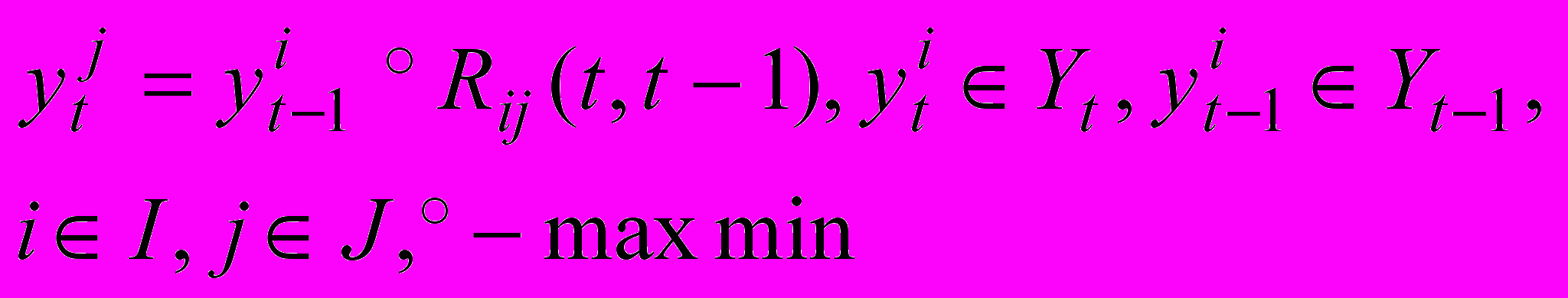
Следовательно,
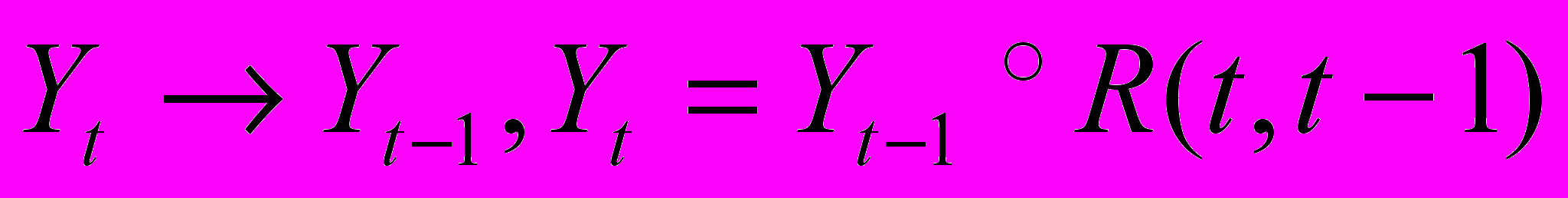 ,
, где
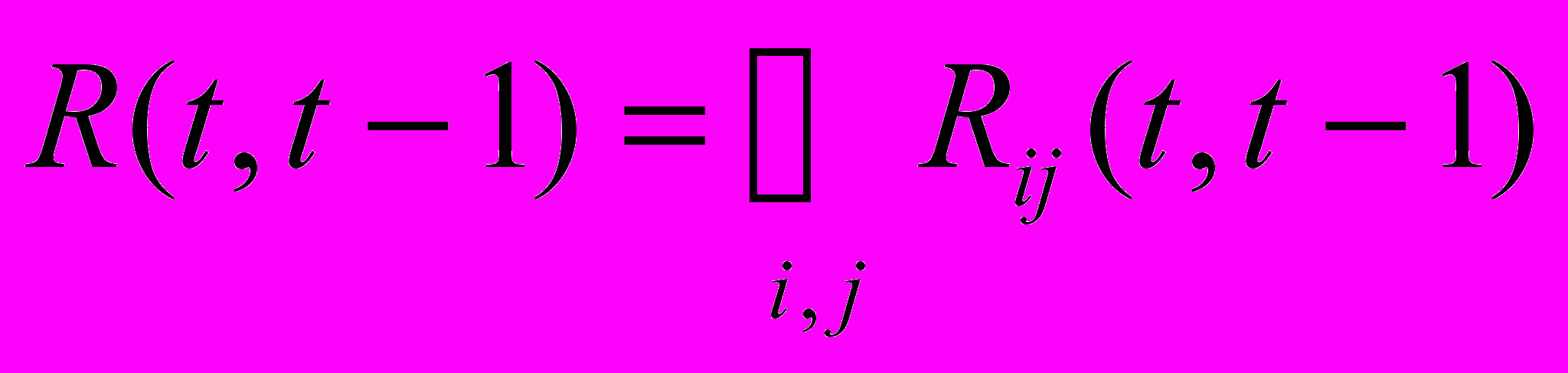 . Уравнение R называют моделью нечеткого ВР первого порядка; данная модель есть важный частный случай общей модели порядка p:
. Уравнение R называют моделью нечеткого ВР первого порядка; данная модель есть важный частный случай общей модели порядка p: ,
,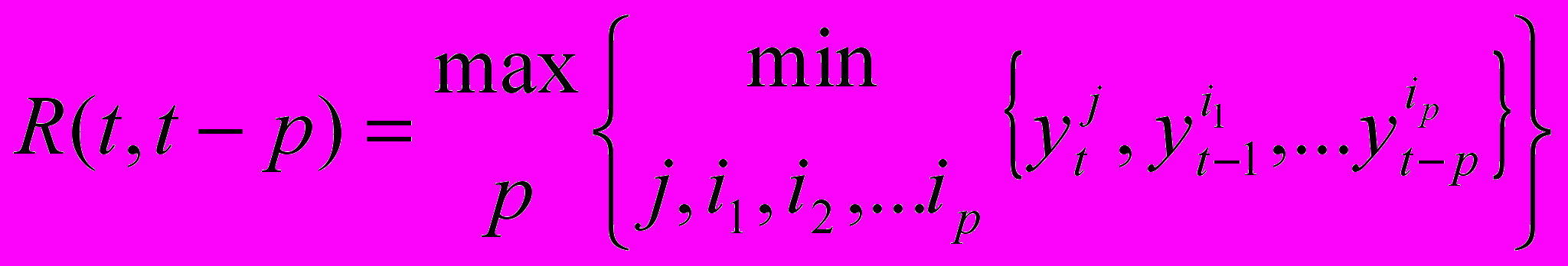
5. ПОНЯТИЕ ГРАНУЛИРОВАННОГО ВРЕМЕННОГО РЯДА
Развитие гранулярных вычислений привело к формированию понятия гранулированного временного ряда. Традиционная сегментация (дискретизация) ВР выполняется методом скользящего окна заданной ширины k на X.
Пусть
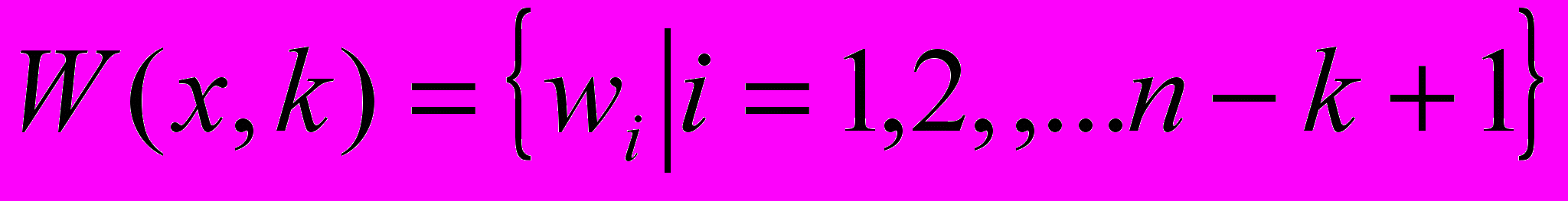 обозначает множество всех k-широких окон на X. Зададим меру, расстояние между двумя подпоследовательностями wi. Если выполнить любым из известных способов кластеризацию таких подпоследовательностей, получим s кластеров: Ci (i =1,2,…,s). Алфавит ={ai|i=1,2,…s} представляет символы образцов ВР. Дискретную версию ВР D(x)={aj1, aj2,…, ajm} называют символьным ВР.
обозначает множество всех k-широких окон на X. Зададим меру, расстояние между двумя подпоследовательностями wi. Если выполнить любым из известных способов кластеризацию таких подпоследовательностей, получим s кластеров: Ci (i =1,2,…,s). Алфавит ={ai|i=1,2,…s} представляет символы образцов ВР. Дискретную версию ВР D(x)={aj1, aj2,…, ajm} называют символьным ВР.Переход к гранулярному ВР предполагает представление вышеописанных кластеров (информационных гранул) нечеткими множествами Ai. Предложен кластерный подход к извлечению нечетких правил из символьных гранулярных ВР.
6. ФОРМАЛИЗОВАННАЯ ПОСТАНОВКА ЗАДАЧИ НЕЧЕТКОЙ КЛАСТЕРИЗАЦИИ
Пусть исследуемая совокупность представляет собой конечное множество элементов A={a1,…,an}, которое получило название множество объектов кластеризации. В рассмотрение вводится конечное множество признаков или атрибутов P={p1,…,pq}, каждый из которых количественно представляет некоторое свойство или характеристику элементов рассматриваемой проблемной области. При этом n есть общее количество объектов данных, а q – общее количество измеримых признаков.
Далее предполагается, что для каждого из объектов кластеризации некоторым образом измерены все признаки множества P в некоторой количественной шкале. Тем самым, каждому из элементов ai A поставлен в соответствие некоторый вектор xi=(x1i, x2i,…, xqi), где xij – количественное значение признака pj P для объекта ai A. Для определенности будем предполагать, что все xij принимают действительные значения. Векторы значений признаков xi=(x1i, x2i,…, xqi) удобно представлять в виде матрицы данных D размерности nq, каждая строка которой равна значению вектора xi.
Задача нечеткого кластерного анализа формулируется следующим образом: на основе исходных данных D определить такое нечеткое разбиение
 или нечеткое покрытие
или нечеткое покрытие  множества A на заданное число c нечетких кластеров Ak, k{2,…,c}, которое доставляет экстремум некоторой целевой функции f(R(A)) среди всех нечетких разбиений или экстремум целевой функции f(J(A)) среди всех нечетких покрытий.
множества A на заданное число c нечетких кластеров Ak, k{2,…,c}, которое доставляет экстремум некоторой целевой функции f(R(A)) среди всех нечетких разбиений или экстремум целевой функции f(J(A)) среди всех нечетких покрытий.Для решения задачи требуется дополнительно уточнить вид целевой функции и тип искомых нечетких кластеров (поиск нечеткого разбиения или покрытия).
7. АНАЛИЗ НЕЧЕТКИХ ВРЕМЕННЫХ РЯДОВ НА ОСНОВЕ ГРАНУЛЯРНЫХ ВЫЧИСЛЕНИЙ
Базовые понятия извлечения знаний из нечетких временных рядов на основе гранулярных вычислений, а также вычислений с о словами и перцептивными оценками CWP (Сomputing with Words and Perceptions) складываются в настоящее время в научное направление: извлечение знаний из нечетких временных рядов на основе гранулярных вычислений. Методология CWP определяет основную задачу анализа нечетких ВР: распознавание образцов – паттернов ВР (восприятий) и извлечения ассоциативных правил в лингвистической форме. Форма правил определяется принципом обобщенных ограничений (Generalized Сonstraints). В состав правил входят переменные, принимающие гранулированные значения.
На основе новой методологии решаются традиционные задачи анализа временных рядов:
сегментация – разбиение ВР на значимые сегменты;
кластеризация – поиск группировок ВР или их паттернов;
классификация – назначение ВР или их паттернам одного их заранее определенных классов;
индексирование – построение индексов для эффективного выполнения запросов к базам данных ВР;
резюмирование (summarization) – формирование краткого описания ВР, содержащего существенные черты с точки зрения решаемой задачи;
обнаружение аномалий – поиск новых, не типичных паттернов;
частотный анализ – поиск часто проявляющихся паттернов;
прогнозирование – прогноз очередного значения на базе истории ВР;
извлечение ассоциативных правил – поиск правил, относящихся к паттернам ВР.
В соответствии с методологией CWP основные направления работ сгруппированы в следующие классы:
- Уточнение (Precisiation) паттернов, основанных на восприятии;
- Обработка ВР на основе принципа обобщенных ограничений;
- Извлечение ассоциативных правил;
- Преобразование ассоциаций на основе принципа обобщенных ограничений;
- Использование экспертных знаний в системах поддержки принятия решений.
При анализе ВР эксперт представляет свои суждения с помощью нечетких понятий, относящихся ко многим объектам:
- временные области: интервалы времени (несколько дней), абсолютная или относительная позиция на временной шкале (близкое будущее), периодические или сезонные интервалы (неделя до Рождества);
- ранг значений ВР (высокая цена, очень низкий уровень производства);
- набор паттернов ВР (быстро растущий, слегка выпуклый);
- набор ВР, их атрибутов, как элементов системы( фондовый индекс новой компании);
- набор отношений между ВР, атрибутами или элементами (тесно связанный);
- множество значений возможности или вероятности (непохоже, очень возможно).
Традиционное выделение паттернов было связано с определением участков с постоянным знаком первой и второй производной: возрастающий и выпуклый, убывающий и гладкий и т.д. Различные шкалы и методы гранулярных вычислений Заде использовались для описания паттернов линейных трендов: рост, падение, резкий рост, медленное падение и т.д. Параметрические методы выпукло-гладкой модификации линейных функций и нечеткая грануляция выпукло-гладких паттернов позволили получить лингвистическое описание для ВР, подобное следующему: медленно убывающий и строго гладкий. В результате исследований создана онтология различных паттернов ВР, в том числе для колебаний и хаоса: осцилляция, разрушение и др. Для описания паттернов в одной из работ [11] был предложен и язык описания паттернов: Shape Definition Language (SDL).
8. ОСНОВНЫЕ ОПРЕДЕЛЕНИЯ АНАЛИЗА НЕЧЕТКИХ ВРЕМЕННЫХ РЯДОВ
Центральным понятием в использовании теории нечетких множеств в анализе ВР является понятие нечеткого временного ряда (НВР). Нечетким временным рядом называется упорядоченная последовательность наблюдений, если значения, которые принимает некоторая величина в момент времени, выражена с помощью нечеткой метки.
Для описания развития моделируемого процесса в лингвистических терминах введем понятие временного ряда нечетких тенденций. Выделим далее базовые операции обработки нечетких тенденций.
Определение 1. Нечеткая тенденция (НТ). Пусть
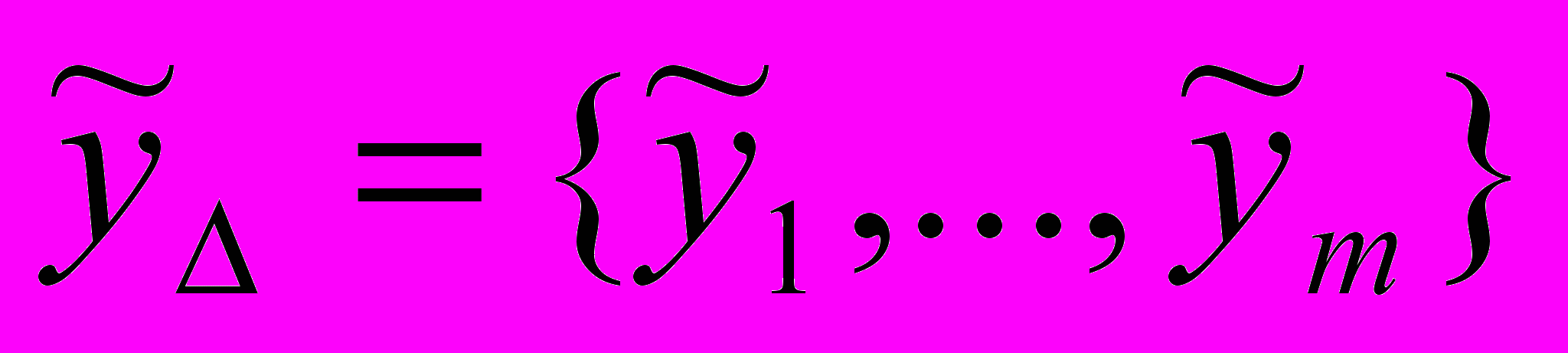 – нечеткий временной ряд лингвистической переменной (
– нечеткий временной ряд лингвистической переменной (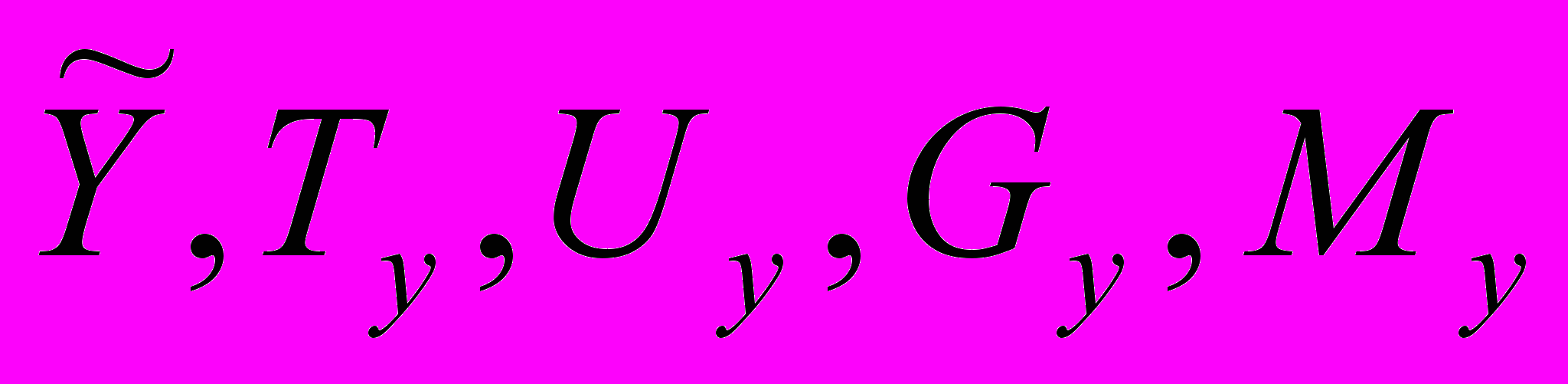 ),
), 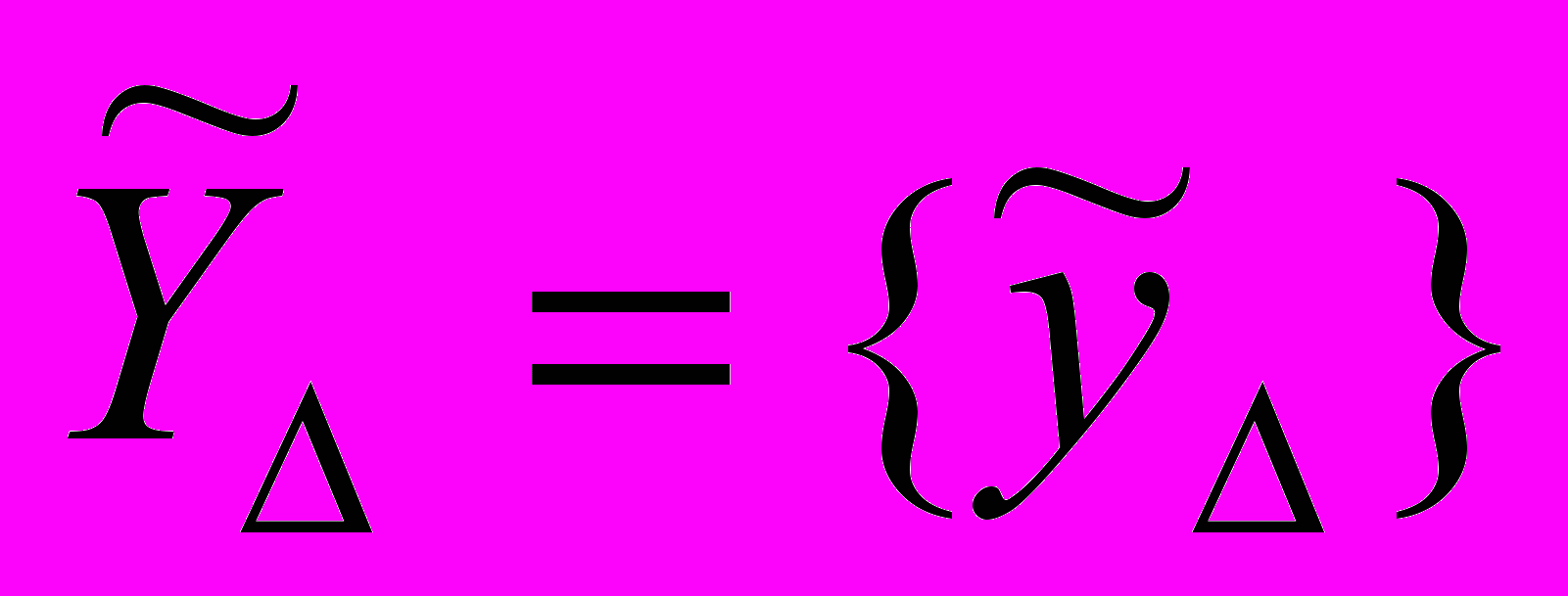 – множество нечетких временных рядов одинаковой длины. Тогда нечеткая тенденция , определенная на
– множество нечетких временных рядов одинаковой длины. Тогда нечеткая тенденция , определенная на 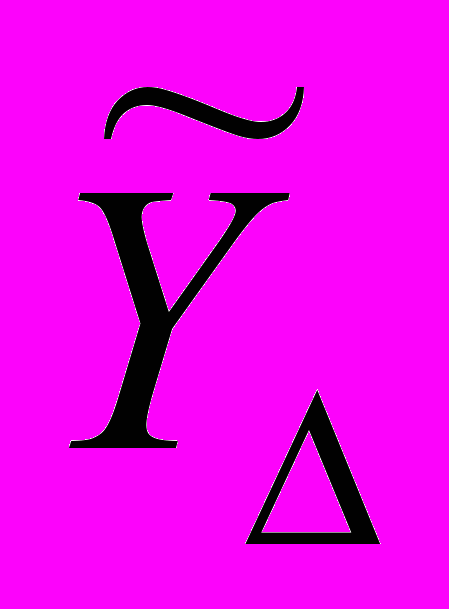 , есть совокупность упорядоченных пар
, есть совокупность упорядоченных пар 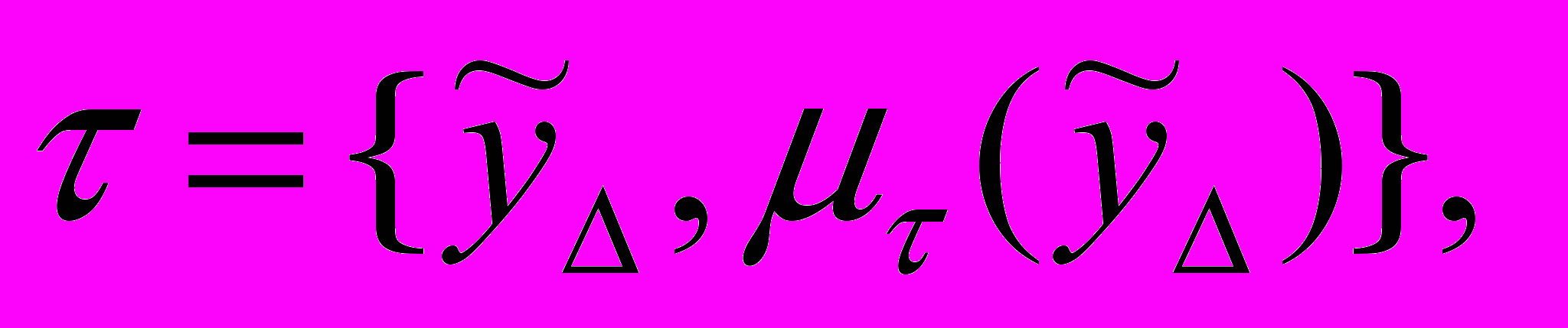 где
где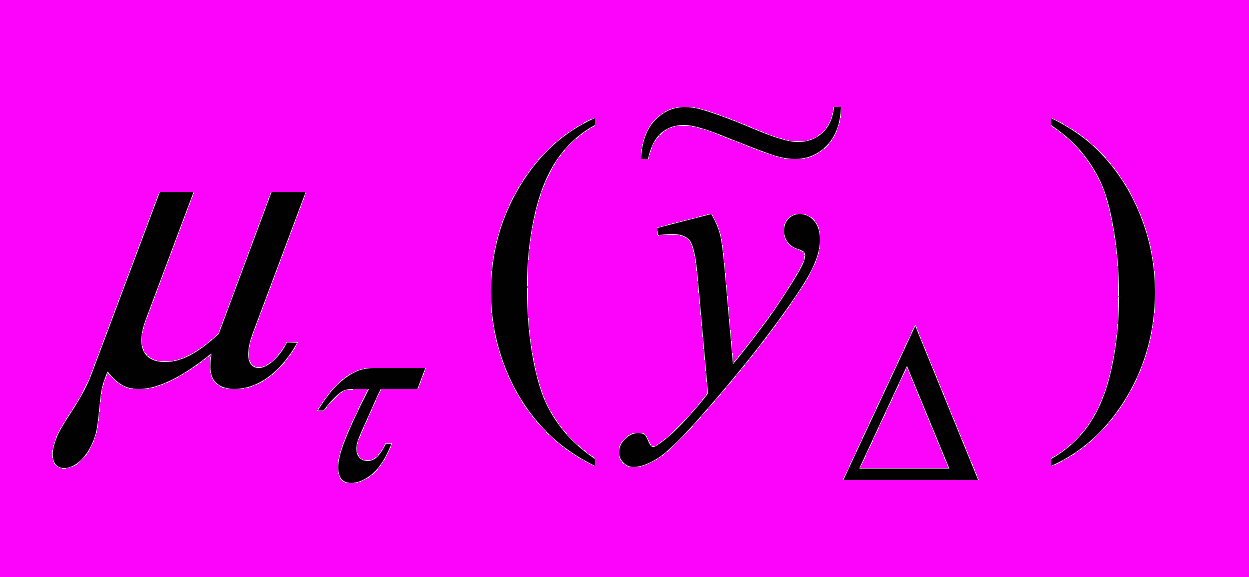 представляет собой степень принадлежности
представляет собой степень принадлежности 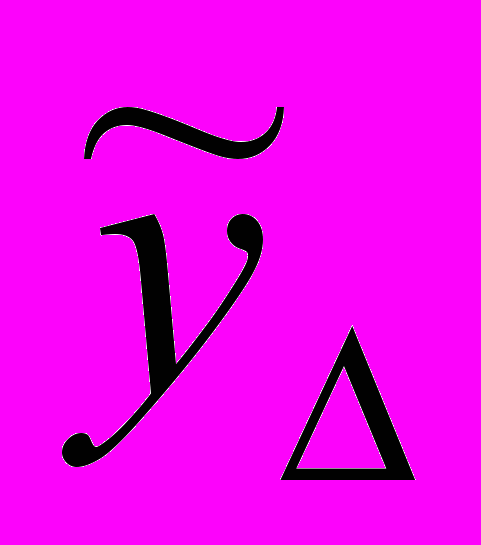 к НТ.
к НТ.Если говорить о тенденции как лингвистической переменной, терм-множеством, которой является множество различных тенденций наблюдаемых на ВР, а универсумом – множество всевозможных функций, нечеткая тенденция определяется как
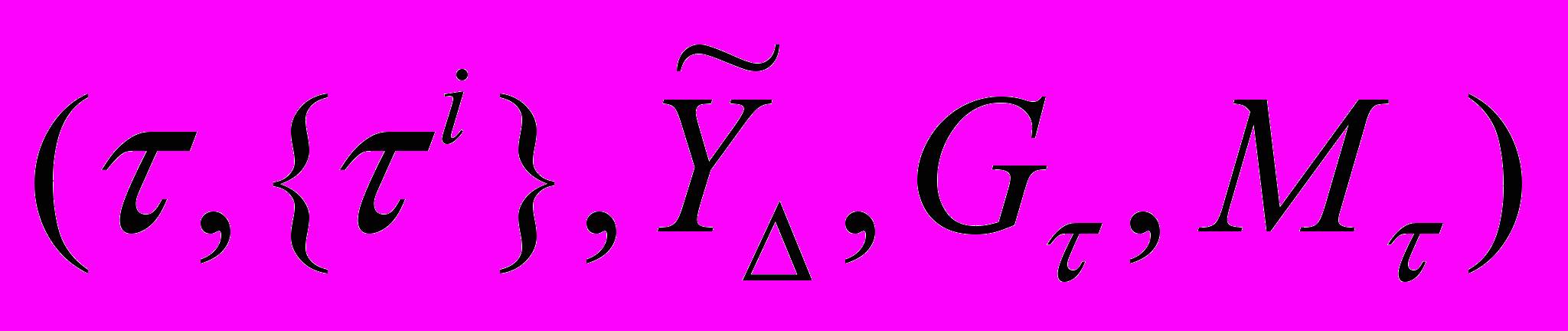 , i=1..p, где p – количество видов НТ, определенных на ВР;
, i=1..p, где p – количество видов НТ, определенных на ВР; 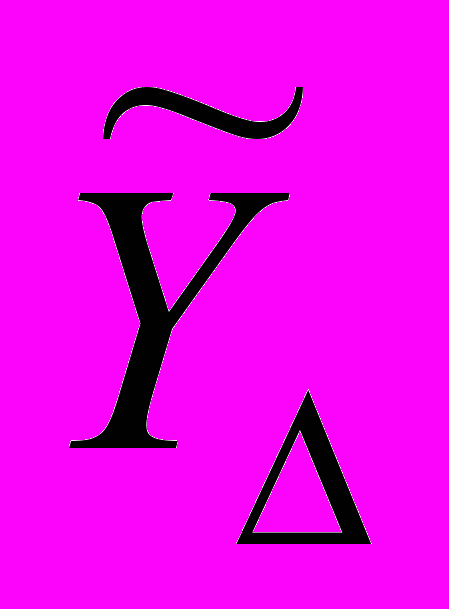 – множество НВР переменной длины.
– множество НВР переменной длины.Определяя нечеткую тенденцию на всех интервалах [t-m+1, t] ВР и позиционируя начало или окончание интервала к временной шкале, получим временной ряд нечеткой тенденции.
Определение 2. Временной ряд нечеткой тенденции (ВРНТ). Пусть
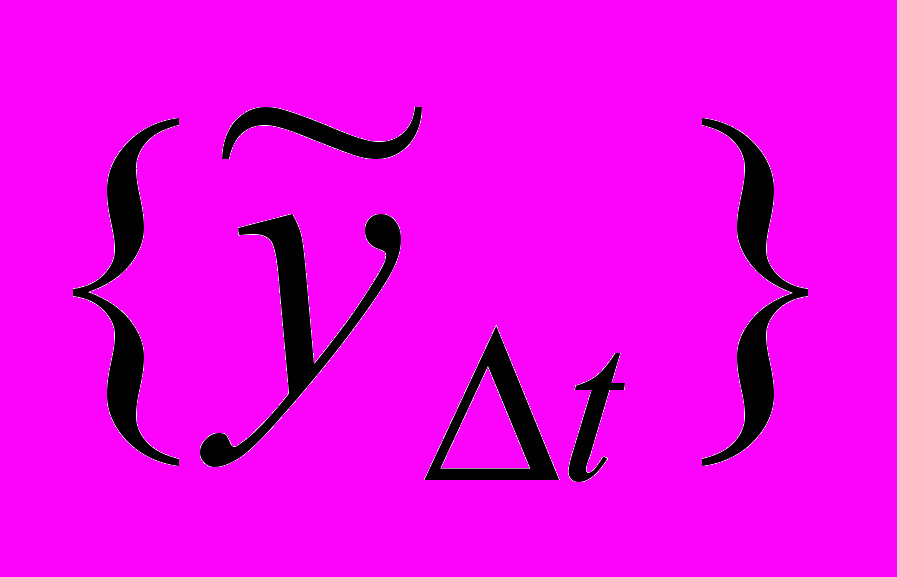 – множество нечетких временных рядов длиной m, где
– множество нечетких временных рядов длиной m, где 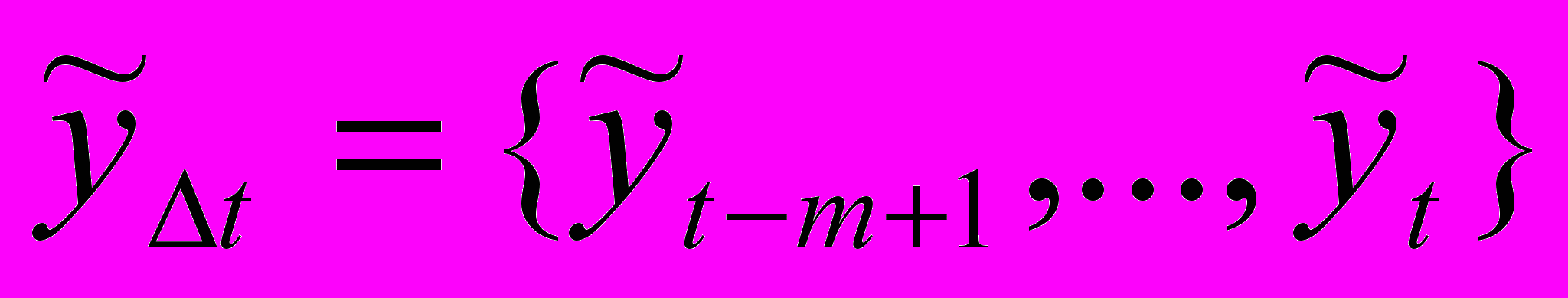 ,
, 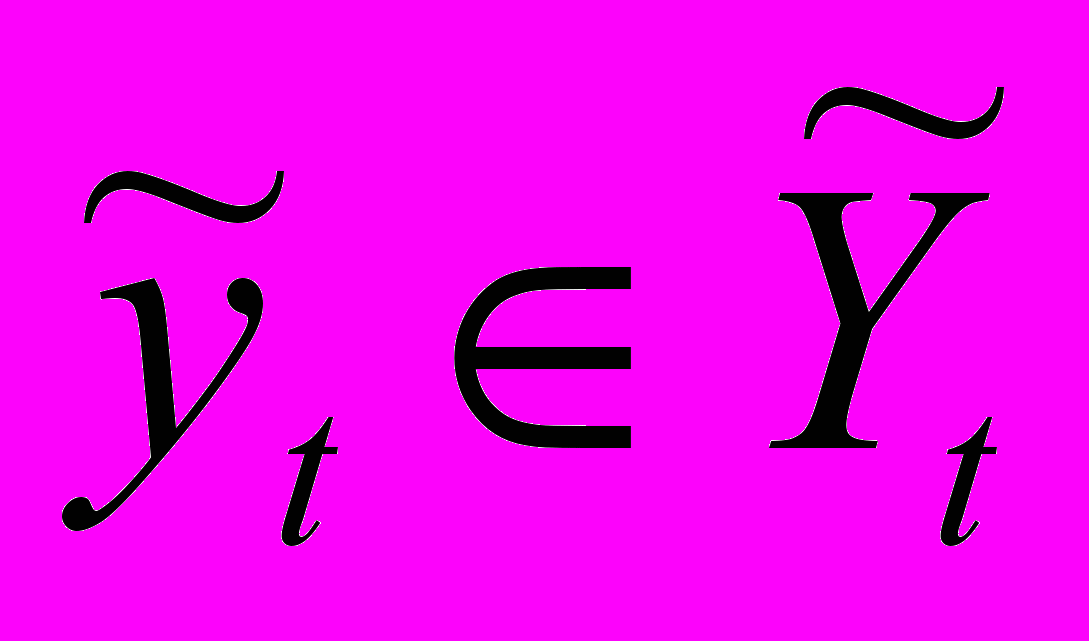 . Тогда временной ряд нечеткой тенденции есть упорядоченное во времени нечеткое множество:
. Тогда временной ряд нечеткой тенденции есть упорядоченное во времени нечеткое множество: 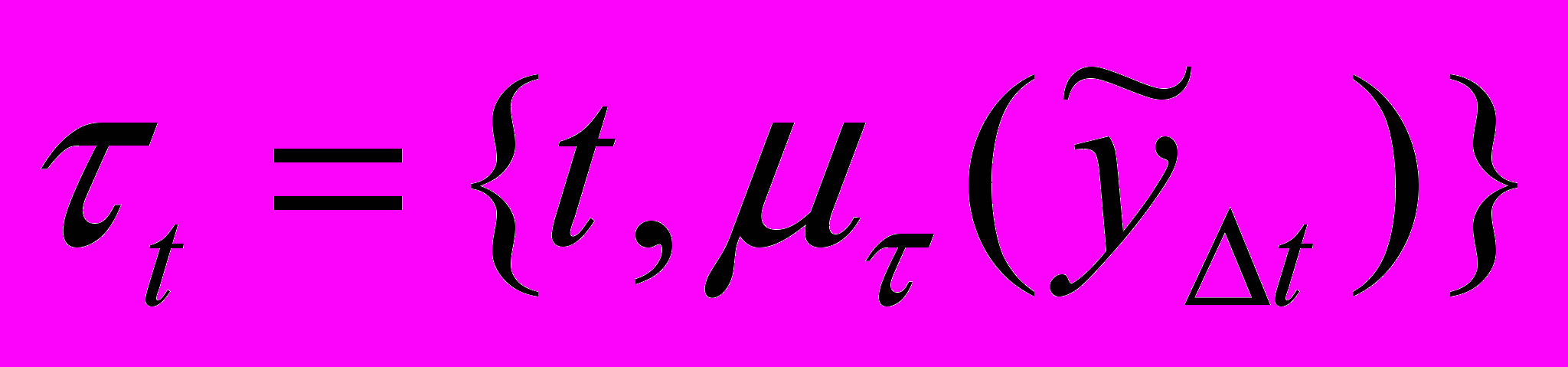 .
.Для лингвистической переменной «тенденция» временной ряд определяется совокупностью значений всех видов нечетких тенденций:
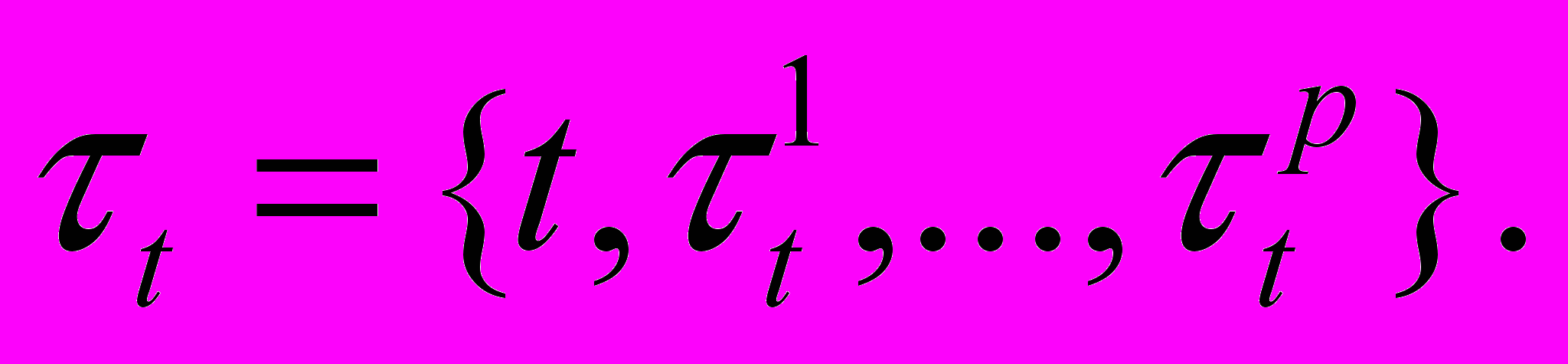
В предположении о развитии системы как результата предыдущих состояний, допускаем наличие зависимости НТ от значений тенденций в предыдущие моменты времени.
9. МОДЕЛЬ НЕЧЕТКОЙ ТЕНДЕНЦИИ
Моделью нечетких тенденций (МНТ) с характеризующими параметрами (n, p, m, l) обозначим совокупность компонент и уравнений:
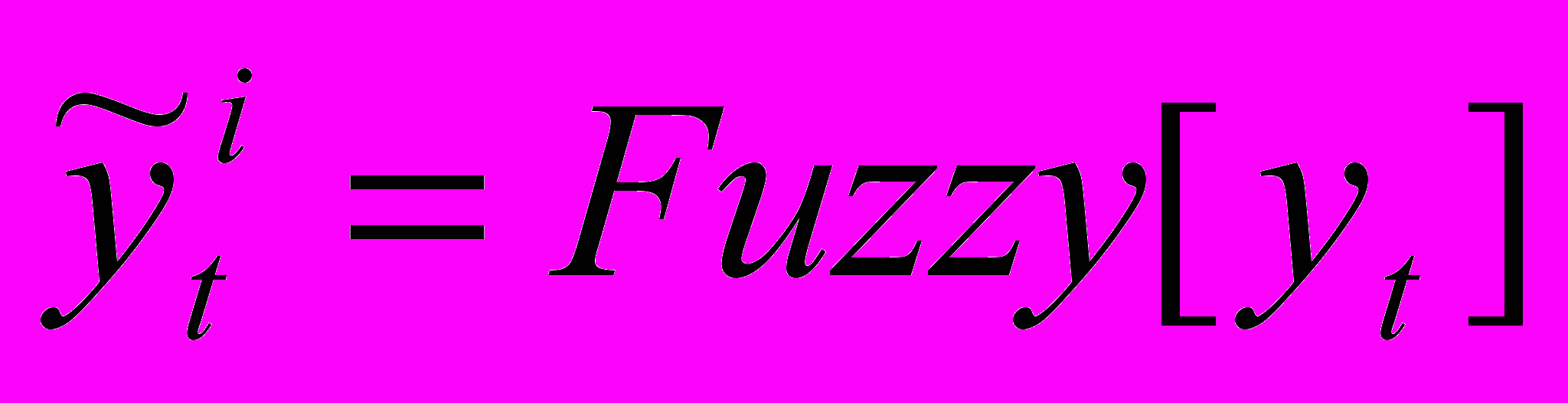 ,
, 
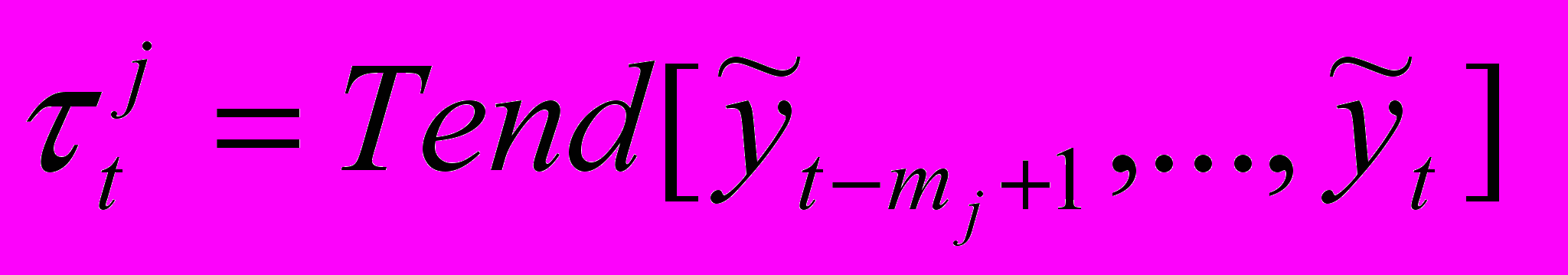 ,
, 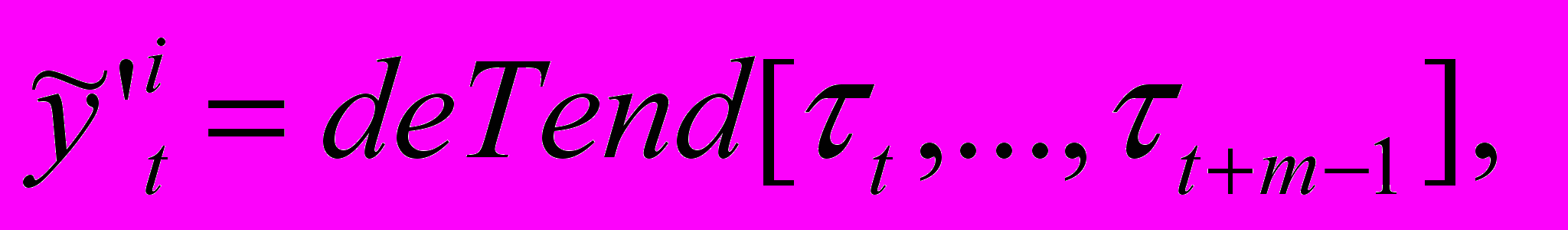
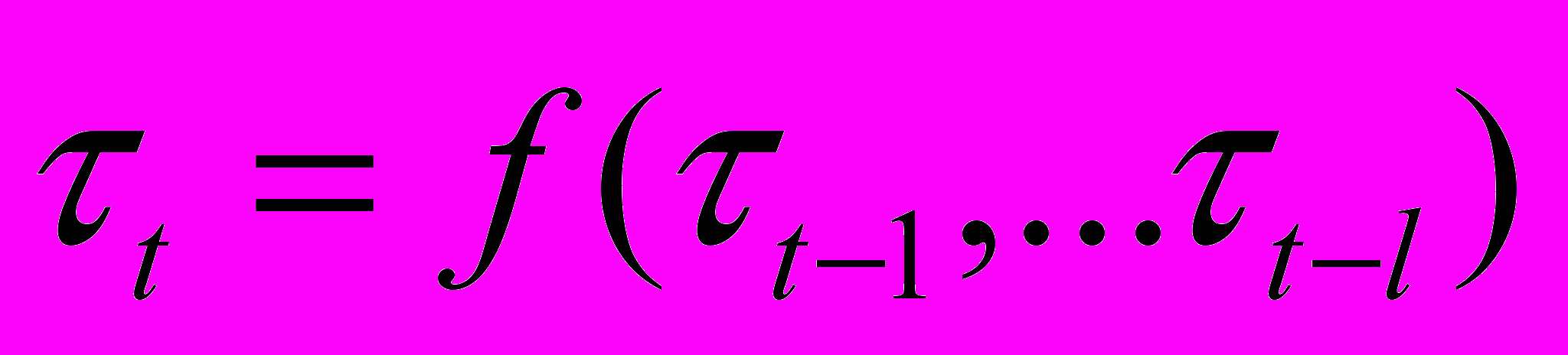 ,
, 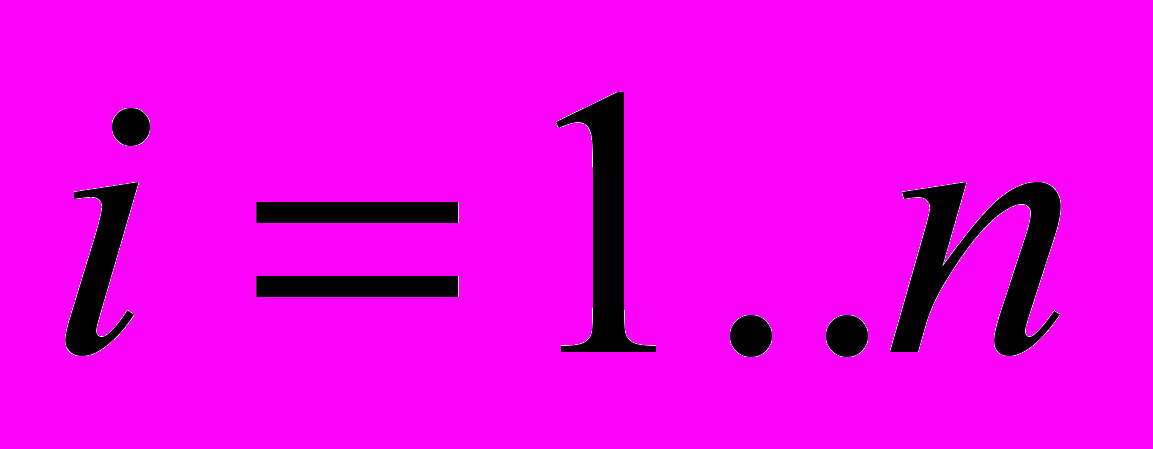 ,
, 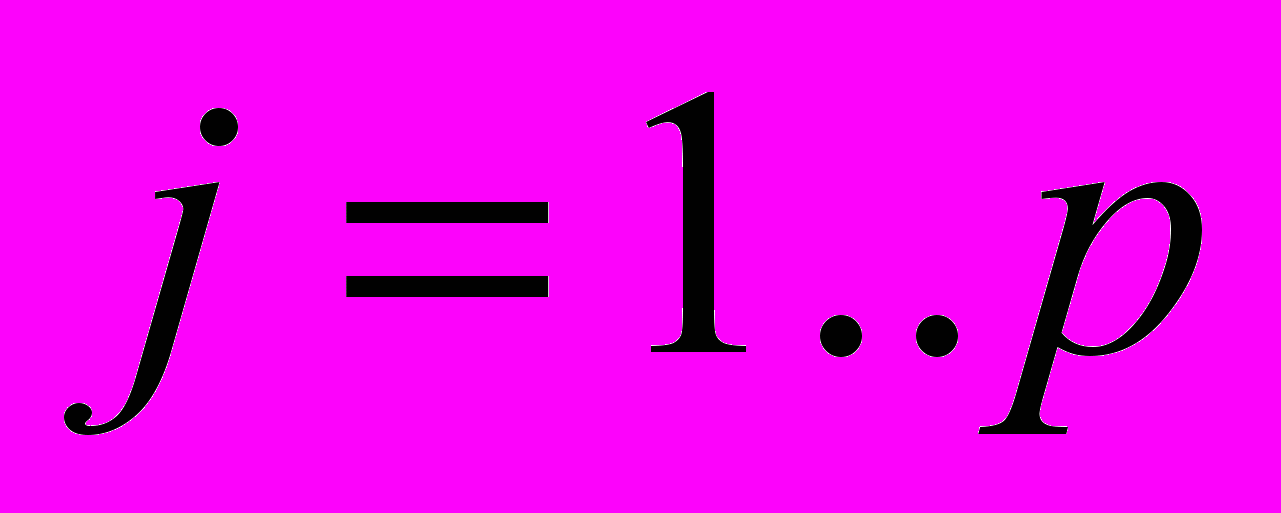 ,
,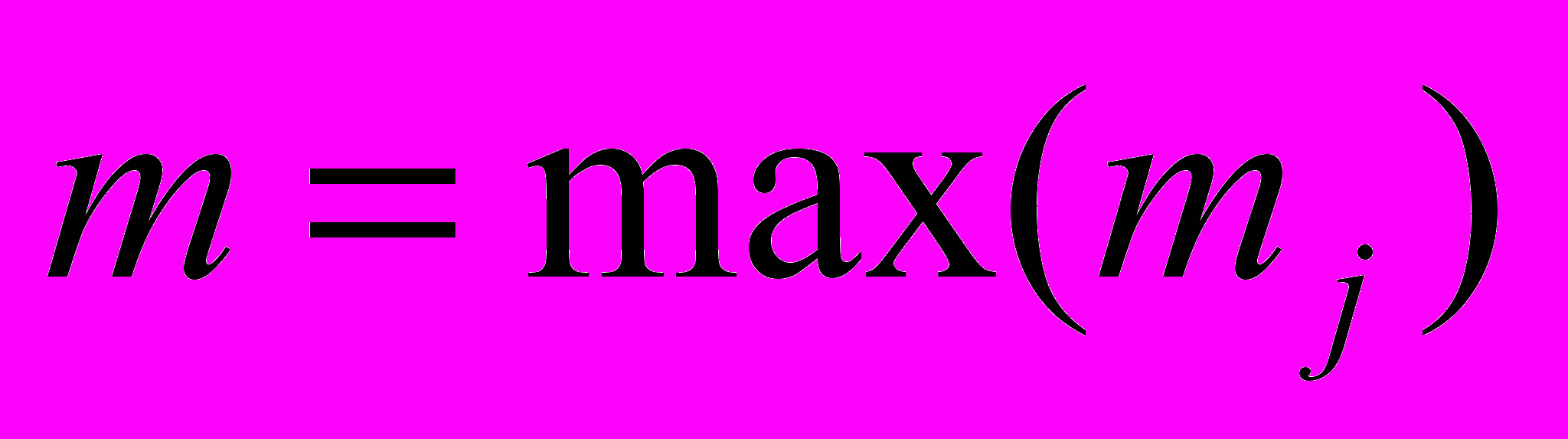 ,
,где
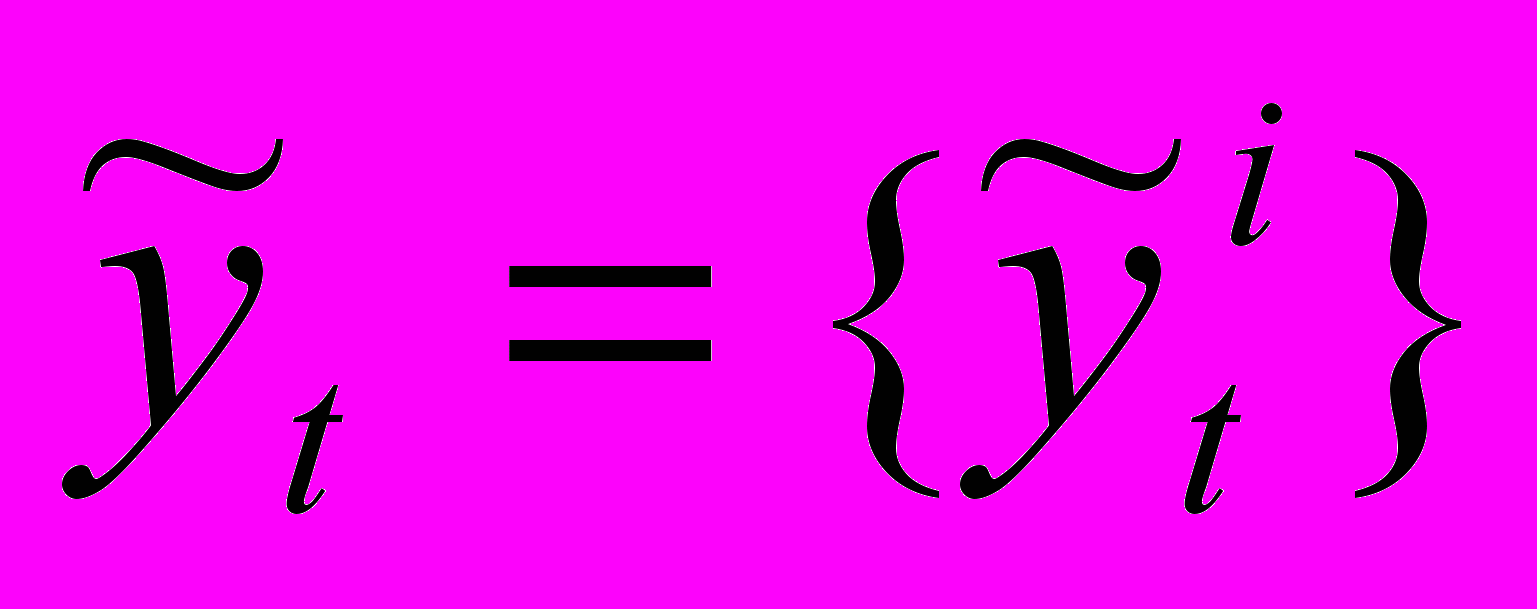 – НВР; n – количество термов нечеткого временного ряда; Fuzzy – функционал фаззификации; t={tj} – временной ряд нечеткой тенденции; p – количество термов нечеткой тенденции; mj – интервал определения нечеткой тенденции; Tend – функционал распознавания НТ; f – функциональная зависимость;
– НВР; n – количество термов нечеткого временного ряда; Fuzzy – функционал фаззификации; t={tj} – временной ряд нечеткой тенденции; p – количество термов нечеткой тенденции; mj – интервал определения нечеткой тенденции; Tend – функционал распознавания НТ; f – функциональная зависимость; 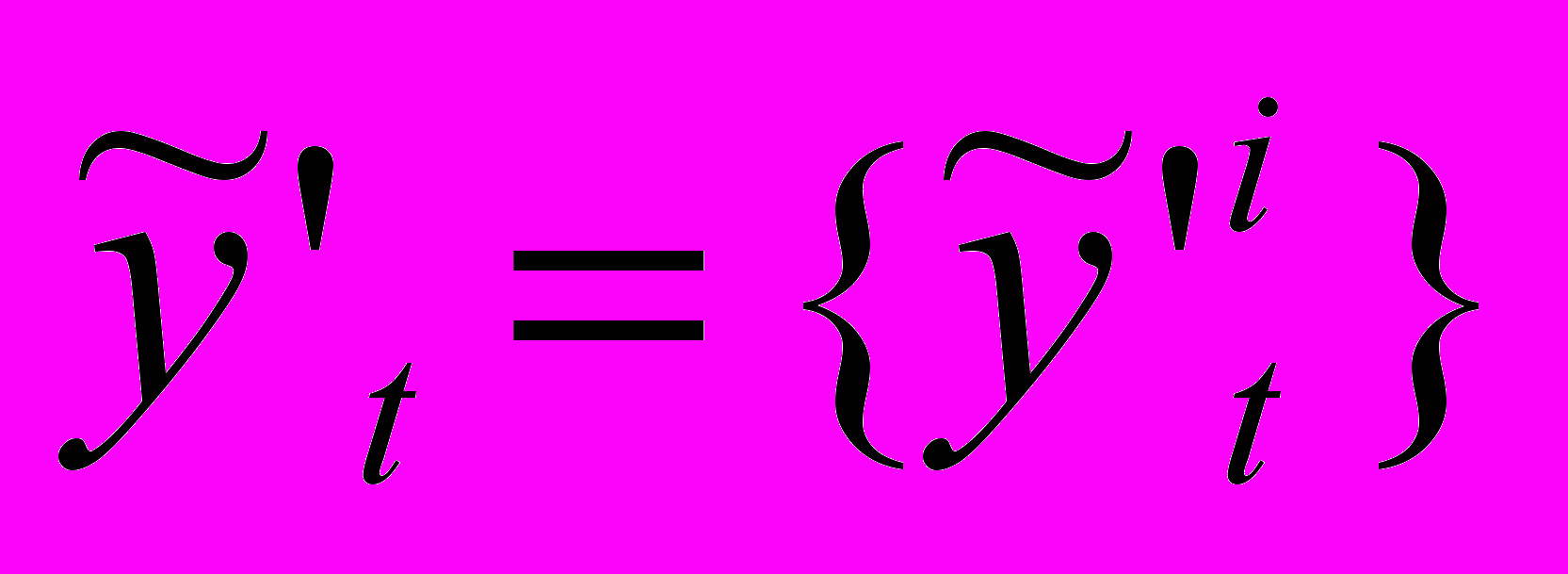 – нечеткий временной ряд, полученный из ВРНТ; deTend – функционал получения нечеткого временного ряда из оценки нечеткой тенденции;
– нечеткий временной ряд, полученный из ВРНТ; deTend – функционал получения нечеткого временного ряда из оценки нечеткой тенденции; 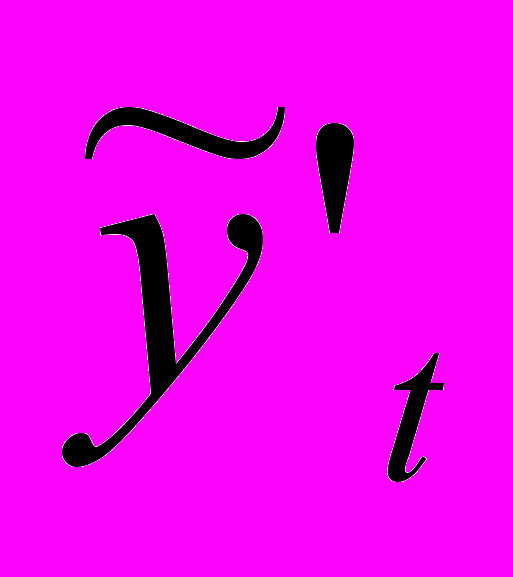 – дефаззифицированный ВР; deFuzzy – функционал получения четкого ВР из НВР.
– дефаззифицированный ВР; deFuzzy – функционал получения четкого ВР из НВР.В результате экспертного построения нечеткой тенденции могут возникнуть отклонения между исходным временным рядом и смоделированным. Обозначим данные отклонения как ошибки построения:
– ошибка построения НВР:
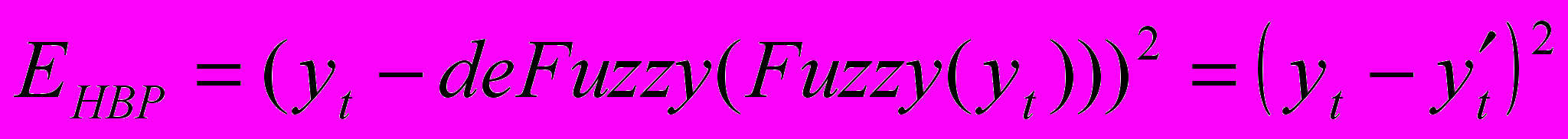 .
.– ошибка построения ВРНТ:
 .
.– ошибка построения ВР:
 .
.Так выбор функций принадлежности и ее параметров, метода дефаззификации определяет разницу между исходным ВР и преобразованным из НВР. Выбор видов тенденций и методов обуславливает несоответствие исходного нечеткого ряда к полученному НВР из ВРНТ.
Модель нечетких тенденций можно привести к разностному уравнению четкого ВР:
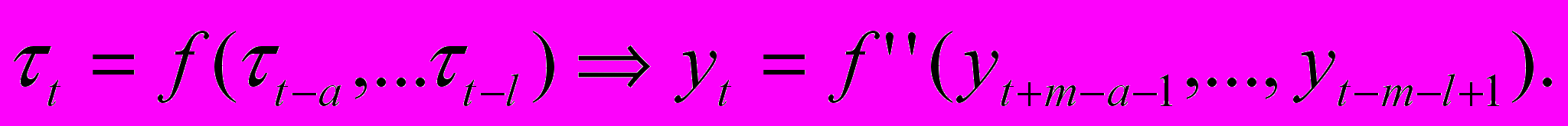
10. ОСОБЕННОСТИ ПРОЦЕССА РАСПОЗНАВАНИЯ НЕЧЕТКИХ ТЕНДЕНЦИЙ
Построение модели временных рядов – это итеративный процесс идентификации, оценки и проверки модели. Идентификация модели нечетких тенденций заключается в описании нечетких переменных и построении соответствующих функционалов. На этапе оценки для модели выбирается инструмент нахождения функциональной зависимости и оценивается параметры выбранной функции по обучающей выборке. При диагностике проверяется способность модели к аппроксимации и экстраполяции.
Опишем нечеткую тенденцию в виде последовательности нечетких меток, формирующих правила распознавания, что позволит одновременно описать и дать формулу расчета степени принадлежности четкого ряда к тенденции. Совокупность всех правил определения видов НТ составляет первый уровень общей системы логического вывода МНТ, которая реализует функционал Tend для получения временного ряда нечетких тенденций (в формализованном виде):

Множество правил уравнения МНТ составляет второй уровень вывода:
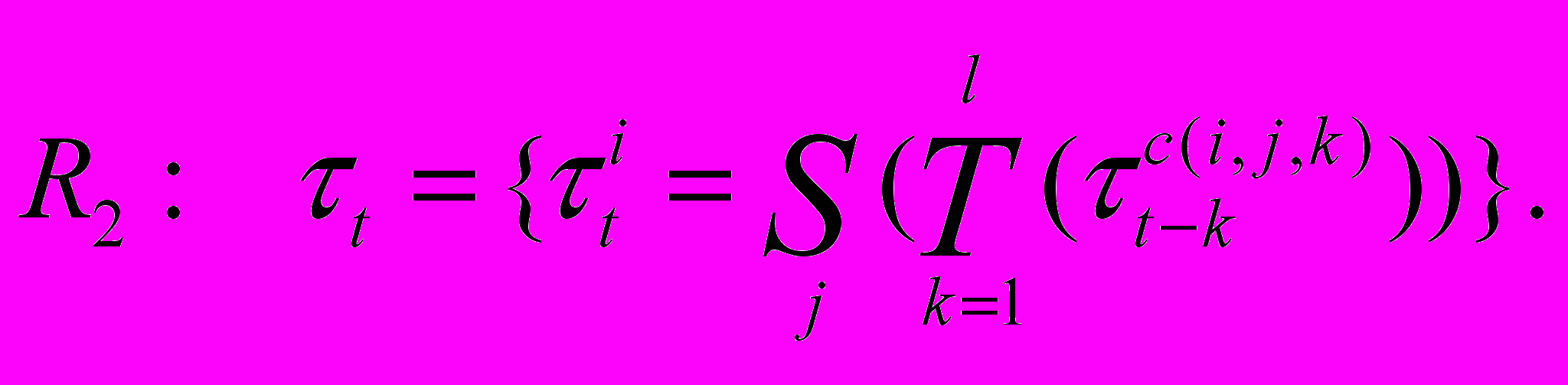
Для анализа и построения четкого ВР по нечеткой модели (функционал deTend) каждому виду нечеткой тенденции сопоставим нечеткий временной ряд, имеющий наибольшую степень принадлежности. Множество таких правил, реализующее функционал преобразования ВРНТ в НВР deTend, формирует третий уровень:
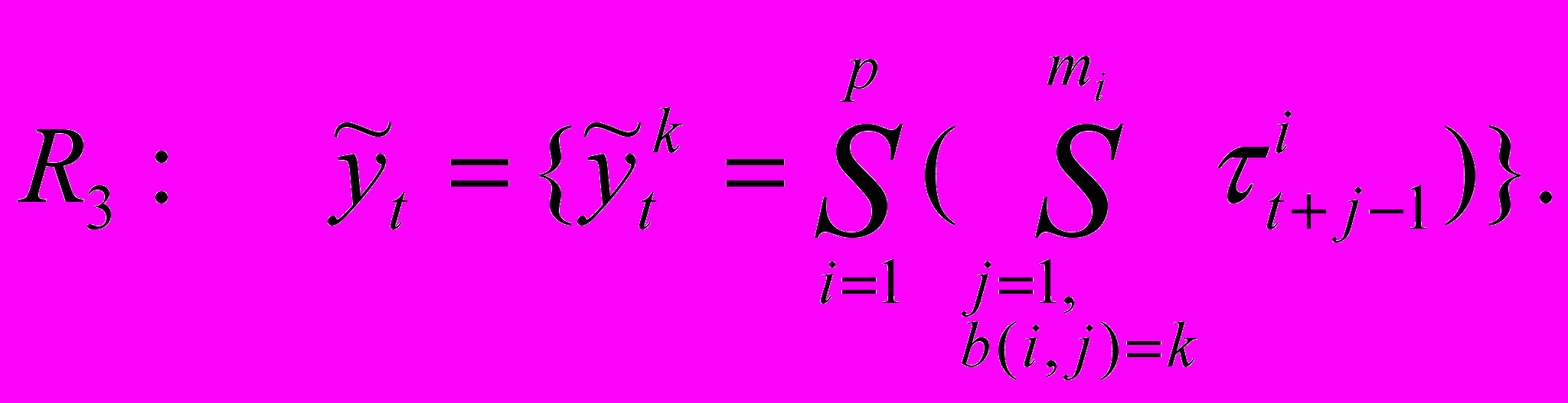
Таким образом, модель нечеткой тенденции полностью реализуется многоуровневой системой логических отношений: R1R2R3, где выходы в виде нечетких переменных одного набора правил подаются на входы следующего набора правил без дефаззификации и фаззификации. Преобразования в нечеткие и четкие значения происходит только в отношениях R1 и R3 соответственно.
11. ИСПОЛЬЗОВАНИЕ НЕЧЕТКОЙ НЕЙРОННОЙ СЕТИ ДЛЯ РАСПОЗНАВАНИЯ НЕЧЕТКИХ ТЕНДЕНЦИЙ
В качестве инструмента построения функциональной зависимости (уровень R2) в виде нечетких отношений воспользуемся аппаратом нечетких нейронных сетей (ННС). Для этого введем классические нечеткие нейроны, в которых операции сложения и умножения заменяются триангулярными нормами:
И-нейрон
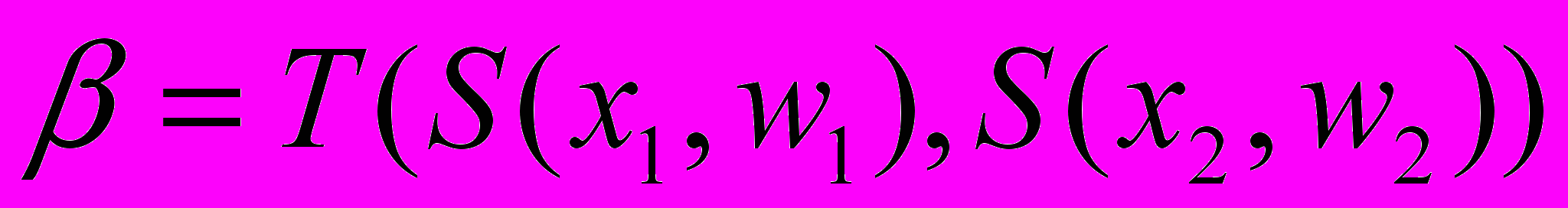 : импликация предпосылок правила;
: импликация предпосылок правила;ИЛИ-нейрон
 : агрегация правил.
: агрегация правил.Интерпретация нечетких нейронных сетей в лингвистической форме приводит к записям:
если (x1 или w1) и (x2 или w2), то ,
если (1 и z1) или (2 и z2), то .
Веса w и z можно рассматривать как степени влияния соответствующего входа на выход.
На основе таких нейронов можно построить сеть логического вывода по Мамдани для нахождения нечеткой тенденции, добавив в R2 весовые коэффициенты. Каждому виду НТ соответствует своя сеть. Нечеткая нейронная сеть состоит из двух слоев (если считать за слой нейроны): слой конъюнкции нечетких входов и слой дизъюнкции правил. Формально такую сеть можно выразить следующим образом:
 ,
, 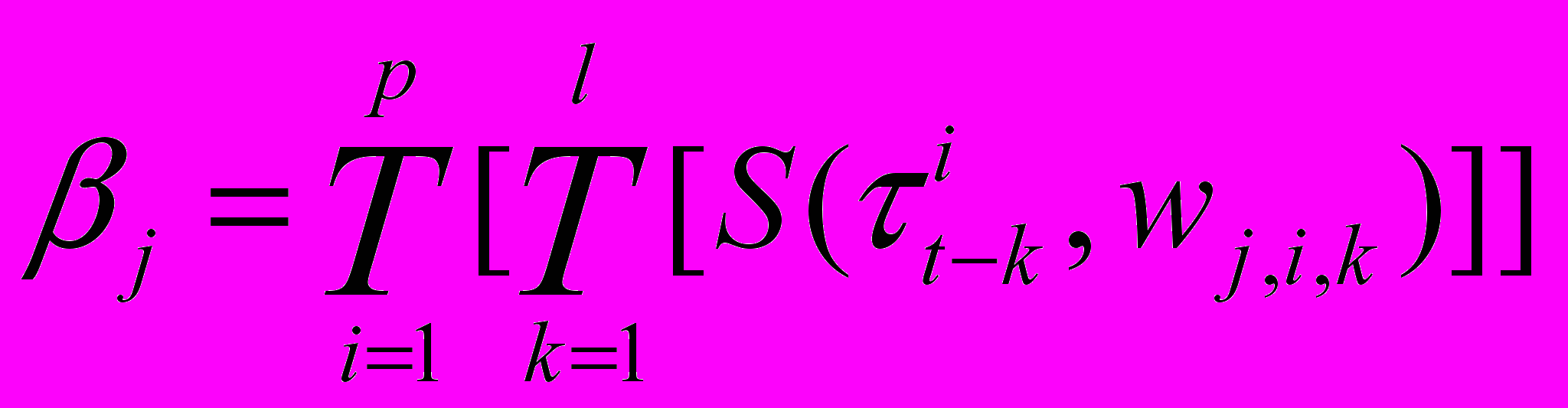 ,
,где ’– значение, рассчитанное для некоторого вида тенденции; T– оператор конъюнкции; S – оператор дизъюнкции; r – количество правил; l, p – параметры модели нечетких тенденций. Основная идея обучения ННС состоит в итерационной процедуре оптимизации весов (zj, wj,i,k) и устранении незначимых связей (сокращении сети), в результате которого формируется необходимый состав и количество правил.
12. ЗАКЛЮЧЕНИЕ
Наряду с традиционными понятиями регрессии для анализа временных рядов целесообразно использовать понятие нечеткой тенденции, сформированное на основе современных гранулярных вычислений.
Литература
- Tanaka H., Uejima S., Asai K. Linear Regression Analysis with Fuzzy Model// IEEE Transactions on Systems, Man and Cybernetics. – 1982. – Vol. 12. – P.903-907.
- Kacprzyk J., Wilbik A., Zadrozny S. Linguistic Summarization of Time Series by Using the Choquet Integral// Proceedings of 12th Fuzzy Systems Association World Congress (IFSA’2007, Cancun, Mexico, June 18-21, 2007) Theoretical Advances and Applications of Fuzzy Logic.- New York: Springer Verlag, 2007.
- Pedrycz W., Smith M.H. Granular Сorrelation Analysis in Data Mining// Proceedings of IEEE International Fuzzy Systems Conference, Korea. – 1999. – Vol.III. – IH-1240.
- Батыршин И.З., Недосекин А.О., Стецко А.А., Тарасов В.Б., Язенин А.В., Ярушкина Н.Г. Нечеткие гибридные системы. Теория и практика/ Под ред. Н.Г. Ярушкиной. – М.: Физматлит, 2007.
- Ярушкина Н.Г. Основы теории нечетких и гибридных систем. – М.: Финансы и статистика, 2004. .
- Ковалев С.М. Гибридные нечетко-темпоральные модели временных рядов в задачах анализа и идентификации слабо формализованных процессов// Интегрированные модели и мягкие вычисления в искусственном интеллекте. Труды IV-й Международной научно-практической конференции (Коломна, 28-30 мая 2007 г.). – Т.1. – М.: Физматлит, 2007. – С.26-41.
- Юнусов Т.Р., Ярушкина Н.Г., Афанасьева Т.В. Моделирование трафика терминал-сервера на основе анализа нечетких тенденций временных рядов// Программные продукты и системы. – 2007. – №4. – С.15-19.
- Celmins A. Least Squares Model Fitting to Fuzzy Vector Data// Fuzzy Sets and Systems. – 1987. – Vol.22. – P.260-269.
- Diamond P. Least Squares Fitting of Several Fuzzy Variables// Proceedings of Second IFSA Congress, Tokyo. – 1987. – P.20-25.
- Song Q., Chisson B. Fuzzy Time Series and its Models// Fuzzy Sets and Systems. – 2004. – №54. – P.269-277.
- Agrawal R., Psaila G., Wimmers E., Zait M. Quering Shapes of Histories// Proceedings of VLDB’95, Zurich, Switzerland. – 1995. – P.502-514.