
Рассматриваемые вопросы: Немного теории
| Вид материала | Диплом |
- Вопросы к экзамену по курсу «Экономическая теория», 48.87kb.
- Основные вопросы, рассматриваемые на конференции, 25.67kb.
- Рассматриваемые вопросы, 929.88kb.
- Правительстве Республики Коми в 2011г. 9 марта 2011 г состоялось заседание, 28.79kb.
- Лекция Предмет философии. Рассматриваемые вопросы, 137.98kb.
- Рассматриваемые вопросы: Создание единого образовательного пространства «вуз-школа», 82.56kb.
- Лекция. Эхокардиография Рассматриваемые вопросы, 636.74kb.
- Тема Рассматриваемые вопросы, количество часов, 37.74kb.
- Вопросы к кандидатскому экзамену по экономической теории, 36.17kb.
- Вопросы, рассматриваемые судом при исполнении приговора, их подсудность и порядок разрешения, 169.58kb.
Новое, хорошо забытое старое. Немного теории на примере модели цифровой дистрибуции применительно к учебному процессу
- что у меня напрочь отсутствует, так это - дипломатические таланты, потому заранее извините за некоторые выражения, которые Шарль Морис Талейран мне бы не простил
- "не стреляйте в пианиста, он играет как умеет", и, прошу, будьте так же снисходительны к моим талантам литературного "научного" изложения - ну не писатель я, мне проще 100 раз сделать, чем 1 раз описать, что и как я делал - не моя это планида, писательство
Тезисы:
- Уровни представления информации (описательный механизм единого информационного поля)
- Информацию нужно распространять индивидуально – каждый пользователь формирует личное информационное пространство (заодно и с воровством покончим)
- Сложная задача индивидуального подхода решается просто – многомерными информационными массивами
- Уровни абстракций при формировании координатного пространства
- На практике это значительно проще, чем в теории
Рассматриваемые вопросы:
1. Немного теории
1. новизна, предтечи и аналоги
2. терминология
3. уровни представления информации
2. Цифровая дистрибуция - теория на практике
1. существующие системы цифровой дистрибуции
2. индивидуальный подход к формированию информационного контента для потребителя
3. В плане информационных технологий
1. как обстоит дело с информатизацией учебного процесса сегодня
2. представление информации как многомерной структуры
3. уровни абстракций при реализации информационного пространства
4. В плане учебного процесса
1. индивидуальный подход к обучению
2. доступность информации
3. структурированность информации
4. новый старый процесс публикаций
1. Немного теории
1.1. Новизна, предтечи и аналоги
Все, что изложено далее, не содержит ничего нового. Прием, с помощью которого индексируется информация (не носители!) применяется не только в Библии, но и в более древних текстах, коим тысячи лет - сложно назвать такое решение "новым". То, что для решения теологических (информационных) задач необходимо применять математику, а не лексические конструкции - знали еще задолго до Аристотеля. Принципы кодирования деталей, узлов, изделий, документации и т.д. кодом (CALS технологии), широко применяемые в промышленности, известны где-то, приблизительно, более тысячи лет - мы этот древнейший прием переносим в информационную среду, не более того. Ссылочная целостность информации? Вспомните, что у вас есть имя (идентификатор объекта), отчество (ссылка на предка) и фамилия (указатель группы) - таким образом можно построить сложнейшее дерево взаимоотношений объектов - тоже явно не "новая" технология построения ссылочной целостности информации.
Предлагаемое нами решение наиболее близко к технологии CALS (Continuous Acquisition and Lifecycle Support) в том, что касается области кодирования изделий. Стандарт ASD S1000D, принятый в странах НАТО, обеспечивает присвоение каждому болтику, каждому шурупчику, присвоение уникального кода. Представьте, из скольких деталей состоит, к примеру, авианосец: и при этом некий шурупчик в табуретке на камбузе имеет свой уникальный код - неплохой стандарт, в плане идентификации объекта, не правда ли? CALS технологии имеют очень давнюю историю развития, это им и помешало, т.к. исторически сложилось так, что применяемый в них код - буквенно-цифровой, а значит - математическими методами, напрямую - не обрабатываемый.
Российский аналог CALS - ИПИ (информационная поддержка изделий) включает в себя стандарт ГОСТ 51.ХХХ - 200*, отличающийся от ASD S1000D тем, что в нем код уже сугубо цифровой - что облегчает его обработку. Но русский стандарт не применяет многомерных построений (да и вообще никаких математических моделей) при вычислении кода.
Технологии OLAP (on-line analytical processing) для работы с данными как раз и применяют многомерные системы, но это аналитический инструмент, а не методика организации данных, как рассмотренные выше CALS и ИПИ. Кстати, данные могут организовываться не только на компьютерах и в сети Интернет, чему Библия яркий пример.
В конце концов, обратите внимание на штрих-код, который присутствует на всех покупаемых Вами в магазинах товарах. Мы, по сути, ставим такой же штрих-код на единицы информации. И наш код не буквенный, как CALS, и не выставляется по принципу 1-2-3, как в ИПИ, и не является чем-то "он-лайн аналитическим" как OLAP. Наиболее точно, по моему мнению, разновидность нашего кода, который мы присваиваем информационным элементам, я бы назвал "библейским кодом".
Подчеркну еще раз, что мы не применяем ничего нового. Все настолько известно и старо, что остается только удивляться, почему для построения информационных, виртуальных объектов, не применяется то, что уже веками отработанно при построении объектов реального мира.
1.2. Терминология.
Прежде всего – единица информации – это ни в коем случае не бит, не байт и не килобайт. Не будем путать единицу емкости компьютерного носителя информации, с самой информацией.
Ближе всего для рассматриваемой задачи будет определение информации – мем (наука, оперирующая мемами - меметика). Кратко, суть мема иллюстрируется простым примером: «Вася + Маша = Любовь» - надпись на заборе, емкостью один мем. Запись в файле о Васе, это не 20 байт, а один мем. Если кто-то снимет сериал о том, что Вася любит Машу, это тоже будет один мем, не более того.
1.3. Уровни представления информации.
Немного о том, как представляется информация на разных уровнях понимания.
Сразу оговорю, что далее идет очень схематическая, и, отчасти, довольно вольно упрощенная трактовка вопроса уровней представления информации. Вопрос представления информации сложный и многогранный, имеющий весьма глубокие исторические корни, но мы его упростим - до уровня, достаточного для нашей темы.
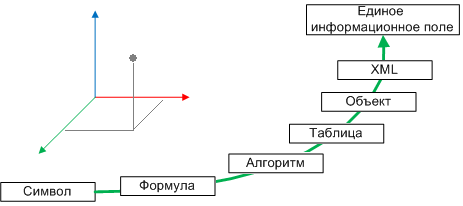
1.3.1. Символ.
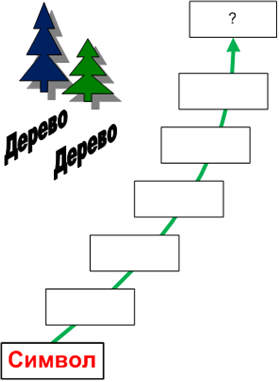
Символ (от греч. symbolon – знак, опознавательная примета) то, что служит условным знаком понятия, явления, идеи.
Ребенок с момента своего рождения воспринимает мир в виде визуальных образов. Для него дерево справа, это один образ, а дерево слева – уже совсем иной образ.
Но по мере взросления дети начинает понимать описательную символьность окружающего мира. Он уже знает, что и один, и другой образ, это «дерево», даже если они внешне сильно отличаются. Или наоборот, не смотря на некоторое сходство один мужчина – это папа, а другой – дядя. Визуальные образы приобретают символьное значение.
1.3.2. Формула
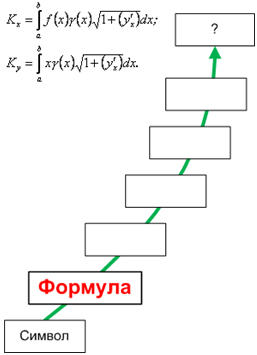
- Комбинация символов, выражающая утверждение.
- Символическая запись химического состава и строения веществ.
Расцвет физики в XVI веке. Огромное желание перенести физическое миропонимание на другие науки, зарождение механицизма (философский метод познания и миропонимания), рассматривавшего мир как механизм.
«Описав мир формулами, мы познаем прошлое и будущее и постигнем суть бытия». Галилей, Ньютон, Лаплас, да и сейчас тысячи и тысячи ученных пытаются «найти формулу». Не суть важно, какую формулу ищут: «всеобщего человеческого счастья», «единого поля», «расчета трения» - важно, что знания и опыт пытаются впихнуть в формулу, как в прокрустово ложе.
Не получается описать формулами все процессы. Более того: почти ничего не получается описать формулами, потому что под ногами писателей формул всегда крутится ненавистное им «если». «Если материал в такой среде, то такая формула, а если в другой среде – то другая формула, иначе – третья формула».
Вот из этого «если» и произошла следующая технология миропонимания: алгоритм.
1.3.3. Алгоритм
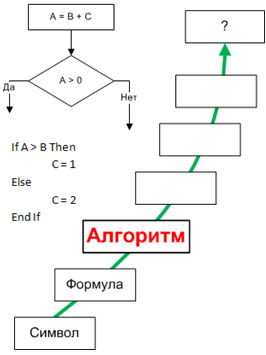
- Способ, предписывающий, как и в какой последовательности получить результат.
С помощью алгоритмов удалось обойти «если». Появились алгоритмические языки, «формулы» нового поколения.
По мере внедрения компьютеров, этих безмолвных исполнителей алгоритмов, накатила новая волна вакханалии: «все алгоритмизируем, все опишем алгоритмами, и откроется нам прошлое и будущее, и познаем мы суть бытия».
Достаточно недолго длилось это восхищение алгоритмами (формулы продержались значительно дольше). Оказалось, что победив «если», не учли «накопление информации». Ведь при расчете по алгоритму часто не достаточно просто параметров функции. Нужно МНОГО параметров. Так много, что придуманная конструкция «массив» явно не справлялись.
Пример: подсчитать сумму платежей за период. Формула простейшая A(1) + A(2) + … = B. Алгоритм тоже простой – обычный цикл. А вот значений – могут быть миллионы.
Выход из ситуации с накоплением информации нашли в таблицах.
1.3.4. Таблица
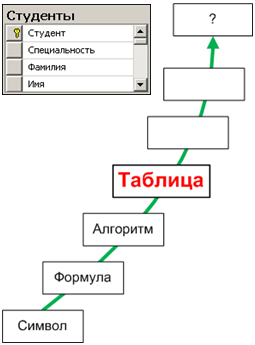
- …по формулам, которые управляются алгоритмом, на основе накопленных в таблицах данных…
Теперь по формулам, которые управляются алгоритмом, на основе накопленных в таблицах данных стало возможно «познать прошлое и будущее, и постичь суть бытия» (надо только побольше данных накопить в таблицах). И все кинулись заполнять таблицы! В таблицы идет все: финансовые транзакции, факты рождения и смерти, каждый наш шаг – все пытаемся записать в таблицы, дабы потом, с помощью алгоритмов и расчетов по хитрым формулам «постичь мир». Но опять наступил облом…
Таблицы хорошо приспособлены к хранению структурированной в простые массивы информации. Если надо увязать данные разных структур в подчиненном отношении, то строятся несколько таблиц и между ними устанавливаются связи – это уже база данных.
1.3.4.1. Таблица (на примере баз данных)
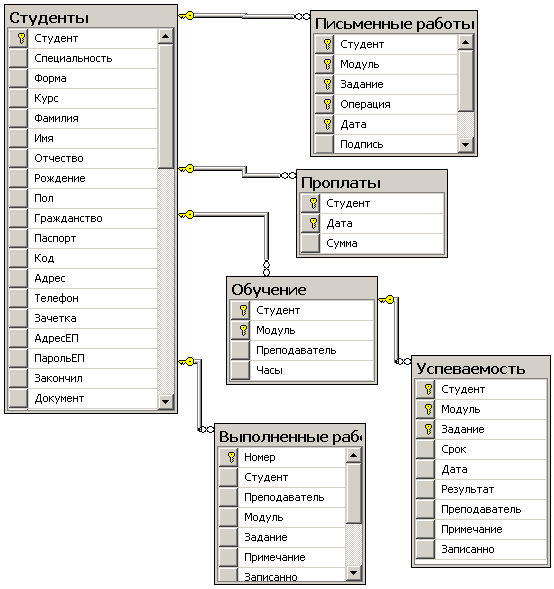
- Даже в довольно не сложных задачах количество таблиц может достигать десятков, сотен и тысяч.
Даже не значительное уточнение в структуре данных приводит к необходимости изменения таблиц (добавление полей и т.д.), что в свою очередь делает необходимым изменение кода, работающего с этими таблицами. Пример: учет персонала. При каждом изменении в списке необходимых для учета данных требуется изменять: структуру базы, формы, отчеты и прочее. Надо добавить, к примеру, «возраст» - выпускается новая версия базы и программного обеспечения.
(Если подразумевается частая корректировка структуры данных, то выходят из положения, делая «разворот таблиц набок», преобразуя структуру в две таблицы [Параметры] и [Значение параметров].Решение интересное, но со своими недостатками.)
Более того: частой практикой является привязка табличных данных к определенному типу SQL сервера вследствие использования специфических для этого сервера функций (например, хранимые процедуры, триггеры). Привязка данных к носителю, это вообще, даже не обсуждаемая несусветная глупость.
Чтобы как-то выкрутиться из все более разрастающегося количества таблиц в задачах, и что еще хуже – все более сложных связях между таблицами – были придуманы объекты.
1.3.5. Объект
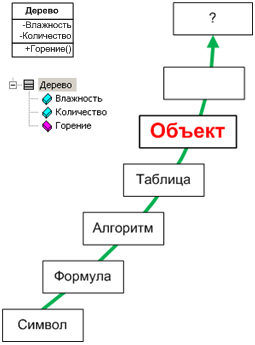
- ОБЪЕКТ - то, что существует вне нас и независимо от нашего сознания, явление внешнего мира.
Ожегов. Толковый словарь русского языка
Наиболее распространенная на сегодня модель организации данных. Даже сами базы данных, будь то реляционные или любые иные, на логическом уровне построены как иерархии объектов. Наследование позволяет реализовать связи, к тому же объединив в одно целое данные и методы их обработки. Долгое время считалось, что с помощью объектной модели можно описать все-все (знакомое уже: «стоит все описать через объекты, и познаем мир»).
Алгоритмические языки уже стали «не просто так», а «объектно-ориентированными». Эта мода «на объекты» превратилась в полный маразм, когда задачи, которые и «близко не стояли» около объектов – стали называть «объектными» и «модульными», потому что «так модно».
1.3.5.1. Объектная модель
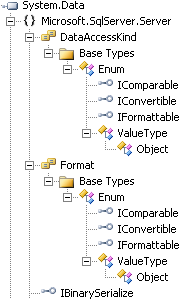
- Объекты – это красиво.
- Если применение их узкоспециализированное,
в области программирования,
и не в очень больших проектах.
До 100 типов объектов – еще терпимо, до 1000 различный типов объектов – еще возможно, но далее – начинается тот же кавардак, что и с базой в 1000 таблиц.
Всякие программы управления проектами, депозитарии объектов – это уже, что называется, «припарки». Как правило, 5-7 уровней наследования объектов – это уже предел для «вменяемого» кода.
У объектов проявились так же всякого рода «технические сложности».
Различные «сборщики мусора» теоретически справляются с «потерянными» объектами, но только – теоретически. В общем – карточный домик объектов стал потихоньку рушится по мере усложнения задач. И это – в области программирования. А если речь о реальном мире? Попробуйте описать объект «кирпич» с учетом всех его свойств, методов и наследований.
1.3.6. XML (ExtensibleMarkupLanguage)
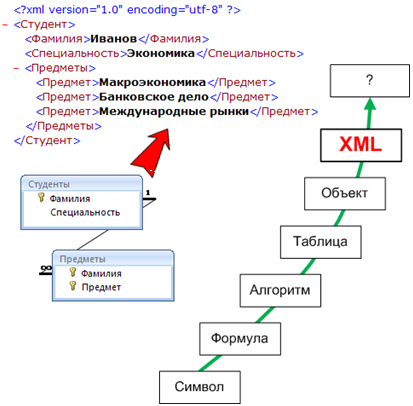
Самое новое, самое модное, самое интересное изобретение в плане инструментария представления данных – это XML (ExtensibleMarkupLanguage – Расширяемый Язык Разметки). Ну, конечно же, уже по традиции, с помощью этого инструмента мы, наконец «познаем и опишем все-все». Документы у нас уже в XML формате (переименуйте .docx в .zip и убедитесь сами), стандарты всего на свете в XML, пихаем этот бедный XML, где надо и не надо. Например, если раньше был просто INI файл у программы, то теперь параметры новой версии все той же программы уже в XML. Зачем? Модно!
Что же такое XML? Задуманный в паре с XSL, DTD и т.д. как формат описания представления, он оказался достаточно удобным и очень наглядным хранилищем информации.
1.3.6.1. XML – текстовый файл
Увы, увы, увы… Столь удачный с точки зрения структуры, XML оказался обычной текстовкой.
Теперь представьте удобства работы с текстовым файлом объемом, к примеру, в гигабайт. Да, можно описать структуру XML в базе данных - но тогда это будет уже база данных, а не XML - круг замкнулся, текстовый файл XML оказался тупиковой ветвью развития (хотя и до сих пор весьма популярной в некоторых кругах).
1.3.7. Что дальше? Единое информационное поле
Реализуем:
- 1. эффективный механизм при работе с большими объемами – как в базах данных
- 2. механизм представления информационных структур как объектная модель (наследование, …)
- 3. в едином потоке подчиненность, последовательность и вложенность объектов как XML формат
Что такое информационное поле и как оно работает мы и рассмотрим на примере цифровой дистрибуции применительно к учебному процессу.
1.3.7.1. Новое, хорошо забытое старое - о черепахе и слонах.

Прежде, чем мы перейдем к практике, напомню, что мир все так же, как и прежде, стоит на трех слонах: физике (науке о материи), теологии (по нашему, по современному, науке об информации) и математике (инструменте познания материи и, внимание!, информации!!!). И все эти три слона покоятся на черепахе, еще у древних индусов символизирующую философию - систему миропонимания, образ мудрости. Ну а черепаха плывет в безбрежном океане мироздания - напоминаю, на всякий случай.
Таким образом, обратите внимание, что много тысяч лет назад индусы уже знали, что информацию необходимо постигать с помощью математики. Не лингвистики, не синтаксических конструкций, не семантики - анализа отношений между языковыми выражениям. Математика, математика и еще раз математика - и не будем думать, что мы умней древних индусов.