
Рассматриваемые вопросы: Немного теории
| Вид материала | Диплом |
- Вопросы к экзамену по курсу «Экономическая теория», 48.87kb.
- Основные вопросы, рассматриваемые на конференции, 25.67kb.
- Рассматриваемые вопросы, 929.88kb.
- Правительстве Республики Коми в 2011г. 9 марта 2011 г состоялось заседание, 28.79kb.
- Лекция Предмет философии. Рассматриваемые вопросы, 137.98kb.
- Рассматриваемые вопросы: Создание единого образовательного пространства «вуз-школа», 82.56kb.
- Лекция. Эхокардиография Рассматриваемые вопросы, 636.74kb.
- Тема Рассматриваемые вопросы, количество часов, 37.74kb.
- Вопросы к кандидатскому экзамену по экономической теории, 36.17kb.
- Вопросы, рассматриваемые судом при исполнении приговора, их подсудность и порядок разрешения, 169.58kb.
2. Цифровая дистрибуция - практическое применение теории
2.1.
 Что мы сегодня имеем в плане распространения цифрового контента? Имеем проблему пиратства, воруют. Как не защищай цифровой контент, его все равно – своруют – большая проблема! Владельцы авторских прав сажают в тюрьмы своих потенциальных потребителей, придумывают некие немыслимые защиты и активации, и, все равно - воруют. Ужесточаются законы, создаются партии пиратов, страсти кипят. А ведь решение – очень простое, достаточно только вспомнить, что ничто не ново под солнцем.
Что мы сегодня имеем в плане распространения цифрового контента? Имеем проблему пиратства, воруют. Как не защищай цифровой контент, его все равно – своруют – большая проблема! Владельцы авторских прав сажают в тюрьмы своих потенциальных потребителей, придумывают некие немыслимые защиты и активации, и, все равно - воруют. Ужесточаются законы, создаются партии пиратов, страсти кипят. А ведь решение – очень простое, достаточно только вспомнить, что ничто не ново под солнцем.
Итак, немного об обуви. Средневековые воины, отправляясь в крестовые походы, имели большие проблемы с воровством обуви. Почему? Потому что обувь была универсальной, она не отличалась не только размером, фасоном и кроем – она была одинакова для левой и правой ноги. Да, с одной стороны – удобная стандартизация. С другой стороны, любой мог взять обувку соседа с правой ноги, одеть на левую, и решить свою проблему. Как не прекрасно было столь стандартное решение, но все же, со временем, появился в обуви индивидуальный подход, и, что самое странное – практически исчезла проблема с воровством. Естественно, зачем вам 42-й размер, если нога у вас – 45-й, зачем вам правый ботинок, если вам нужен левый сапог.
Рассмотрим, к примеру, самые популярные на сегодня системы распространения цифрового игрового контента. Все они торгуют стандартными компонентами игр. Сама игра, дополнения (DLC) – они стандартные, как средневековая обувь. Не ворует эти стандартные компоненты только тот, кому просто лень их воровать.
Не углубляясь в подробности, можно смело сделать вывод – современное состояние технологий распространения цифрового контента – где-то на уровне обувной промышленности начала средних веков.
2.2.
Как же решить проблему пиратства, вместе с тем дав потребителю то, что ему надо. Резонный вопрос: а что надо потребителю? Ответ прост и очевиден: ему надо ЕГО операционная система, ему надо ЕГО игра, ЕГО учебный материал, в конце концов, каждому из нас нужна СВОЯ информационная среда.
И если мы сумеем дать каждому человеку то, что нужно именно ЕМУ, то кто и что будет воровать? Вы у меня украдете мои старые домашние тапочки? Очень теплые, очень привычные, старые и драные, но такие удобные, МОИ тапочки - для вас они не представляют не малейшего интереса, вы согласны?
Возражение. Это что, каждому индивидуально поставлять операционную систему, каждому лично писать игру, для каждого персонально подбирать учебный материал? Не слишком ли это сложно? Это, какие же ресурсы нужны?!
Оглянитесь на людей на улице. Практически каждый одет по-своему. Даже строй солдат в одинаковой форме – у одного она выгоревшая на солнце, у другого чуть мешковатая, третий солдат стоптал правый каблук на сапоге, видимо косолапит. Практически вы не встретите одинаковой одежды, нигде, ни у кого. Значит – в материальном мире, имея дело со стандартными элементами окружающего мира, каждый человек с легкостью формирует свою индивидуальную среду обитания.
Почему же, давая людям элементы информационной среды, мы пытаемся вогнать всех в прокрустово ложе? Не возражайте: возможность поменять картинку на экране, это не возможность иметь СВОЮ операционную систему. Как же дать КАЖДОМУ – СВОЮ систему, свою информационную среду? Об этом мы поговорим далее, а пока просто примем наш первый, самый важный вывод: информационная среда человека должна формироваться – ИНДИВИДУАЛЬНО.
3. В плане информационных технологий
3.1. Как обстоит дело с информатизацией учебного процесса сегодня
Прежде чем перейти далее к рассмотрению теоретических основ и практики реализации единого информационного пространства на примере организации учебного процесса, рассмотрим печальную ситуацию действующих ныне «стандартов».
Существуют ли на сегодня информационные системы, обеспечивающие хоть сколько-нибудь приемлемый процесс обучения? Нет, практически таких систем нет. Есть более или менее удачная реализация отдельных компонентов системы – не более того. Заставят преподавателей ссыпать свои файлы в кучки (напоминающие кучи мусора) – и называют это базой учебного материала, или даже «базой знаний». Заведут на сервере пару табличек, приделают к ним убогий интерфейс – вешают гордую надпись: «электронный деканат». Это еще в лучшем случае, бывает и хуже: потратят кучу времени и средств, создадут действительно красиво изложенный и оформленный учебный материал, который… невозможно использовать, т.к. он ни с чем не совместим.
Сейчас делаются отчаянные попытки (SCORM, IEEE 1484, ARIADNE, ADL, …) навести порядок в этих горах мусора, которые гордо именуют «учебным материалом». Последнее достижение – это разработка единого стандарта этикетки, которую надо вешать на каждую кучку файлов, дабы хоть на элементарном уровне обеспечить понимание того, что в эту кучу навалили.

Рис. Кучки с этикетками – «база знаний» по методу «само публикаций».
Отметим, что не только в области образования народ увлекся изобретением "этикеток". В попытке превратить Интернет из кучи мусора в нечто вменяемое, разрабатывается так называемая "семантическая паутина" (Semantic Web), основная особенность которой в том, что на каждый носитель информации будет прилеплена "ну очень большая этикетка", описывающая, что в очередной куче информационного мусора содержится. И все же, не может не радовать, что многие понимают - время "этикеток" - прошло, учитывая как человеческий фактор (народ и из метаданных свалку сотворит), так и мнение Аристотеля о том, что не существует очевидного способа деления мира на концепты, что ставит под сомнение возможность существования онтологии верхнего уровня, критической для семантической паутины.

Рис. Человеческий фактор похоронит любую идею, даже " очень больших и раскрашенных этикеток" .
3.1.1. Интеграция или единое информационное поле
Предположим, что стандарт «на этикетки» благополучно внедрен, успешно используется. Что это даст? Это даст возможность интеграции отдельных подзадач и обеспечит возможность обмена информацией между системами. Это, конечно, в идеальном случае, но этот идеальный случай, увы, никогда не наступит – куча файлов все равно останется просто кучкой, даже если в нее воткнуть этикетку.
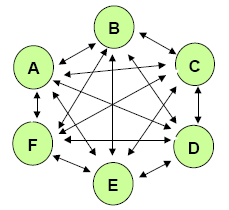
Рис. Вот так выглядит интеграция.
Так как же нам поступить? Как правильно организовать информацию и ее использование? Прежде всего, надо уяснить одно простое понятие: единое информационное пространство. Но аналогии с электромагнитными полями, это явление также иногда называют «информационное поле».
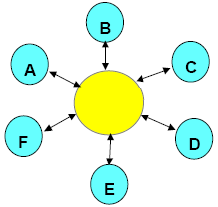
Рис. Так выглядит решение задачи в рамках единого информационного поля.
3.1.2. Что же такое – информационное поле?
Скажите ребенку «баобаб» - и он не поймет вас, если раньше не знал этого понятия. Объясните в доступных понятиях: «это большое, очень толстое дерево» - и у него уже возникнет некая ассоциация, хотя бы приблизительно верная. Так и мы, попробуем объяснить новое понятие посредством привычных образов. Итак, информационное поле – это нечто, похожее на электромагнитное поле. Что есть электромагнитное поле? Нечто не видимое, ощущаемое только по косвенному воздействию на воспринимаемый нами мир. Электромагнитное поле вокруг нас, внутри нас, везде. Из колебаний электромагнитного поля прямо здесь и сейчас можно извлечь сотню каналов телепередач, голоса радиостанций, сигналы спутников, свет звезд и еще много-много чего, и это все – тут, вокруг нас, везде – надо только иметь возможность услышать эти сигналы.
По аналогии с электромагнитным полем, информационное поле так же вокруг нас. Мы видим, слышим, думаем, понимаем – это все и есть «сигналы» информационного поля. Вокруг нас море информации, но услышать мы можем только то, что позволяют наши «датчики». Простой пример, который всегда приводят для иллюстрации: три человека, глухой, обычный и профессиональный музыкант пошли на концерт симфонического оркестра. После концерта их спросили: ну как играл оркестр? Глухой в ответ пожал плечами, он ничего не слышал. Обычный человек игру одобрил, но пожаловался на излишнюю, по его мнению, громкость звука. Музыкант сказал: «во втором акте первая скрипка в си-бемоле откровенно сфальшивила, чем испортила мне настроение на весь вечер». Каждый из них от игры оркестра получил информацию в меру своей способности получать и интерпретировать эту информацию (так же, как в электромагнитном поле каждое устройство способно воспринять только знакомый ему диапазон).
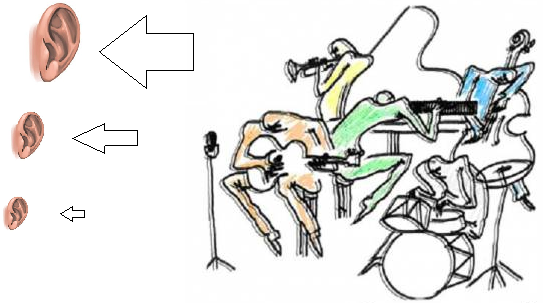
Рис. Оркестр и слушатели – каждый слышит то, что способен воспринять.
3.1.3. Типичные заблуждения в понимании того, что такое информация
Сразу предостерегу от типичного заблуждения: не надо привязывать информацию к носителю, точно так же как и электромагнитное поле. Электромагнитное поле, гравитационное, информационное – они существуют сами по себе, и то, что мы их видим и ощущаем – это только вторичное проявление (причем – у каждого, свое).
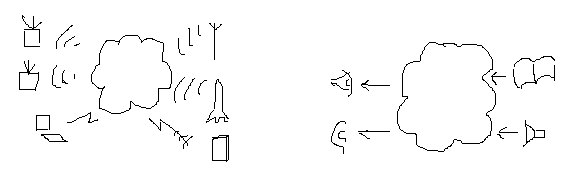
Рис. Аналогия между электромагнитным и информационным полем.
Так же, просто классическим заблуждением, является неверное построение ссылочной целостности информации. Вот очень простой пример:
- Информатика. Базовый курс / Под ред. Симоновича С.В. – СПб., 1998. – 121 с.
- Библия, Деяния, глава 25, стих 8
В первом случае мы видим ссылку на носитель (хотя все уверенны, что на информацию), во втором случае – на информацию. Остается только удивляться, как в 1214 году епископ Кентерберийский Стефан Лантгон догадался проиндексировать информацию, изложенную в Библии (подчеркиваю, именно информацию, а не носитель), а современные авторы упорно оперируют ссылками на носители («страница такая-то», «адрес в Интернете такой-то»). Ну и к чему это приводит? К тому, что по любому изданию Библии можно найти информацию, на которое указывает ссылка, а стоит переиздать «Информатику» Семеновича, сдвинув нумерацию страниц – и уже ничего найти, не получится (может только рисунки – их почему-то догадались правильно нумеровать, в отличие от текста).
«Павел Апостол в деянии глаголет, во главе 17, зачало 40: род убо суще Божий, не должниесмынепщевати, подобнубыти Божеству злату, или сребру, или камению и начертанию художну, и смышлению человека» - обратите внимание на цитату из постановления Московского Собора 1667 года. «Деяния, глава 17, зачало 40» - сможете сейчас проверить эту цитату по любому изданию Библии? Конечно! Цитата эта взята из статьи, в которой указано «Текст приводится по изданию: Деяния Московских Соборов 1666 и 1667 гг. М., 1893. с. 273.» - можете проверить информацию по такой ссылке? Только, если у вас есть эта книга, именно это издание 1893 года. Сомнительно, что эта книга у вас есть – вот вам и древние люди, вот вам и современные ученные.
Надо сказать, что Библия не самый лучший пример работы древних людей с информацией. Коран полторы тысячи лет назад (последняя редакция была в 632 году нашей эры) писался сразу с четким делением на Суры и Аяты. Что касается Торы (окончательная редакция – V в. до н.э.) – то это вообще удивительный, до конца не познанный и в наши дни, пример представления информации, в том числе и в области индексации. Достаточно упомянуть, что Исаак Ньютон изучил иврит специально для того, что бы разобраться в структуре построения святых текстов – труды Ньютона на эту тему (объемом более миллиона слов) и сейчас находятся в Кембриджском университете.
Справка. Еще несколько примеров правильно построенных ссылок на информацию.
Из индусских Священных Писаний
Единный, без второго.
Чхандогья упанишада, VI, II, I
Тогда не было не-бытия и не было бытия…
Ригведа, X, CXXIX, 1, 2
Открою тебе То, что должно быть познано;
что, познанное, ведет к бессмертию, безначальное,
высшее, Вечное, Браман.
Бхагаватгита, XIII, 12
Незримый, Он видит, неслышный, Он слышит,
немыслимый, Он мыслит, неисповедимый, Он знает.
Брихадараньяка упанишада, III, VII, 23
Не в видимом пребывает Его образ; никто не зрит его очами.
Шветашвара упанишада, IV, 18.
Его ты познаешь, как то, что существует и не существует…
Мундака упанишада, II, II, 1, 2
Из Священных Писаний парсов
Ахура-Мазде, Единому без второго…
АгунавадГата, XXXVIII, 3
Ахура-Мазда, видящий все.
УштавадГата, XIV, 4
Он без начала, без конца, без союзника и врага,
или подобных Ему, без отца, матери, жены или дитяти,
без места, положения, тела или чего-либо плотского,
без цвета или запаха.
Дезатир, Книга Пророка, ВеликийАбад, 4
Из еврейских Священных Писаний
Я есмь Сущий…
Исход, 3:14
Из христианских Священных Писаний
Да будет Бог все во всем.
Коринфянам. 15:28
Из Священных Писаний Ислама
Бог един.
Коран, 4:169
Из Священных Писаний сикхов
Он един есть. Он все во всем. Своими законами Он поддерживает вселенную.
Сукхамани Гуру, V
Из буддийских Священных Писаний
Ища создателя этого святилища…
Дхаммапада, VII, 95

Рис. Талмуд Вавилонский 1869. Заметна очень сложная структура текста.
Остается загадкой, почему сейчас люди оглупели до такой степени, что не различают где информация, а где носитель. Посмотрите на Интернет – это же скопище кое-как проиндексированных носителей, где пользователи пытаются найти информацию (расширив метаданные на носителях - мы не очень-то изменили бы ситуацию). Не улавливаете диссонанс? Интернет – это проиндексированные носители с указанием содержащейся на них информации (в том числе рекламы). По здравому смыслу должно было бы быть наоборот –индексированная информация – с указанием, на каких носителях ее можно найти. Сейчас же информационные системы строятся скорей таким образом, что в них проще информацию потерять среди свалки носителей, чем найти. Чего же тогда удивляться, что сейчас для людей является большой проблемой связать воедино даже 2-3 факта, не говоря уже о построении более сложных рассуждений на основе ссылочной целостности информации.
Первые три вывода
- Информация должна быть независима от носителя
- Информация должна быть структурирована
- Информация должна быть взаимосвязана
Подчеркиваю еще раз – речь идет об информации, не о ее носителях.

Рис. Пример связи носителей и связи информации.
Примечание. В криминальной практике сплошь и рядом криминалисты оперируют именно фактами, подтвержденными документами, показаниями, уликами и т.д. Потому для криминалиста система, построенная на связи фактов, основанных на документах - куда ближе, чем кипа документов с неупорядоченными фактами.
- Представление информации как многомерной структуры
Перейдем к теории, на примере практики.

Сейчас перед каждым учеником практически один и тот же учебник, каждый зритель смотрит один и тот же фильм, миллионы игроков играют в одни и те же игры. Не надо возражать, что к играм изредка выпускают дополнения, а учебники есть разных редакций – в любом случае это продукция-штамповка (fast-food натуральный). Мы же говорим о полностью уникальной конфигурации информационного пространства ДЛЯ КАЖДОГО.
Вам бы понравилось, если бы в магазине была бы только одна и та же одежда? Этакие, пусть даже очень красивые, но совершенно одинаковые, к тому же еще и не вашего размера – комбинезоны.

Давайте наши комбинезоны… извините, элементы информационного пространства разложим на компоненты, скажем – по оси X.
По оси Y будет: на нулевом уровне, тот самый океан информации, в котором плавает черепаха, на которой стоят три слона, на которых лежит плоская земля (шутка!). Если говорить серьезно, то нулевой уровень – это исходный массив информации. Пока мы его рассматриваем как одномерный, укладывающийся в одну линию на ось X. Не будем, пока, углубляться в детали, примем уровень абстракции самый поверхностный – так проще будет понять суть.
Далее, по оси Y, над массивом первичной информации, идут пользователи.
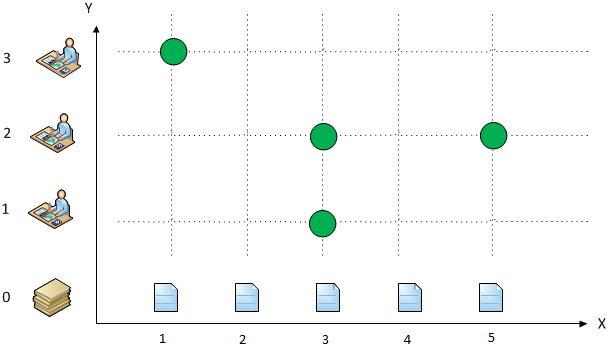
На иллюстрации мы видим, что пользователь 1 свою ИНДИВИДУАЛЬНУЮ информационную среду сформировал (или ему среду сформировал кто-то другой) из элемента исходного массива под номером 3. Пользователь 2 использует элементы 3 и 5, пользователь 3 – только элемент 1 (зеленая точка с координатами X=1,Y=3).
Еще раз подчеркиваю, что мы рассматриваем самый верхний уровень абстракции, не углубляясь в то, чем являются элементы нулевого уровня. Пусть, пока, будем считать, что это учебные предметы, в целом, без рассмотрения глав, страниц, иллюстраций и прочих составляющих.
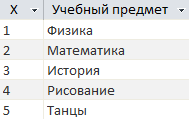
Вот такая простая табличка с расшифровкой значений по оси X.
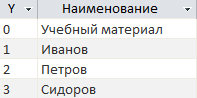
Не менее простая расшифровка по Y, без акцентирования внимания на том, кто такой Петров, где он учится и сколько ему лет. Подробностями биографии Петрова мы займемся позже.
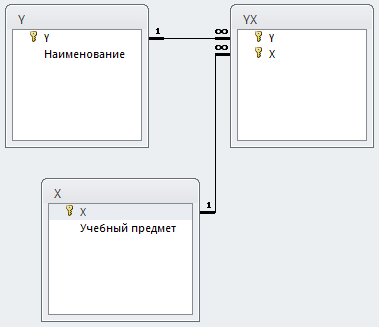
Если бы мы создавали классическую реляционную структуру, то добавили бы таблицу [YX], связывающую учебные предметы с учениками.
Внимание! Мы НЕ создаем реляционную базу – мы создаем модель многомерного информационного поля, поэтому результат объединения [X] и [Y] будет не три таблицы, а одна таблица, назовем ее условно [Matrix].
Обращаю ваше внимание на то, что мы используем таблицы чисто условно, для наглядности. При практической реализации могут применяться таблицы, но это не обязательно. Информация должна иметь координаты, и не важно, сделано это с помощью SQL сервера или файловой системы, либо еще каким-то образом. Привязка информации к координатам может быть реализована вообще без применения компьютеров – об этом, на примере Библии и прочих святых писаний, мы говорили ранее. Сейчас, просто примите к сведению, что мы работаем не с таблицей, а с координатами, представленными в виде таблицы MicrosoftAccess. С тем же успехом мы могли бы работать и с листиком бумаги.
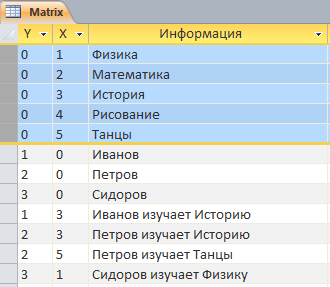
Первые 5 записей – это координаты информации об учебных предметах. Пока у нас от предметов есть только названия, пока.
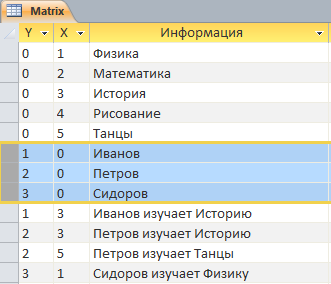
Следующие три координаты описывают наших учащихся, пока только фамилии.
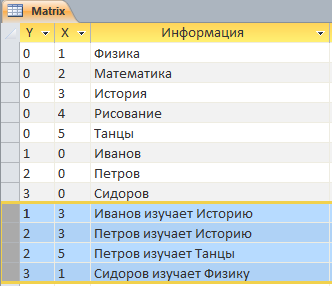
Последние четыре строки – координаты информации об индивидуальных учебных планах – кто что изучает.
Итак, в одном массиве мы получили всю необходимую нам на данный момент информацию. Каждый элемент информации имеет уникальные координаты, увязанные в общее пространство.
Возражение. Это, какого же размера получится таблица при рабочей базе!
Пусть не смущает размер таблицы – никто ее вручную обрабатывать не собирается, для этого есть математический аппарат. А вот ему, математическому аппарату, мы сильно жизнь облегчаем, разложив информацию «по полочкам», т.е. по координатам.
Примечание. Первичные документы по ДТП в масштабах всей страны – это массив из 6-и координат, загружаемый в год примерно 15-ю миллионами единиц информации – и ничего, не самые мощные сервера легко обрабатывают такую задачку.
- Уровни абстракций при реализации информационного пространства
«Физика», «Иванов» - конечно, это не тот уровень представления информации, который удовлетворит нас. Нам нужно больше информации о Физике и об Иванове.
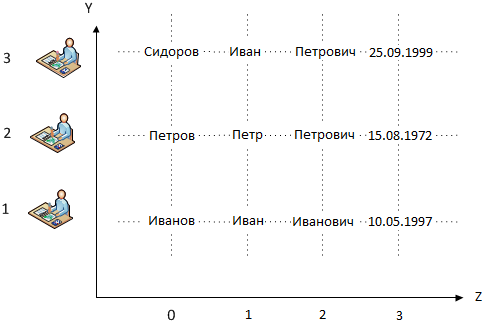
Добавим координату Z, где представим об учениках больше информации. На срезе координаты Z=1 имеем имена. Если сделаем выборку при Z=3 –получим даты рождений. Таким образом, информация о дне рождения Петрова имеет уникальные координаты в системе 0,2,3 (X,Y,Z).
Возражение. Это же обычная кодировка! И да, и нет. CALS-стандарты не оперируют кодами, как координатами. Код, к примеру, «A1-A-29-10-00-010-941A-Z» - это только код, а не координата информации, обрабатываемая математикой.
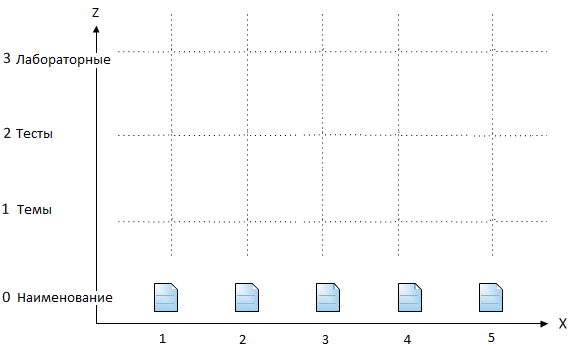
Добавив координату Zк учебному материалу, мы не получаем непосредственно информацию, а только опускаемся на один уровень абстракции ниже. В учебных материалах одной координатой Zне обойтись.
Надо заметить, что на практике не всегда для каждого уровня абстракции порождается отдельная система координат. Если структура данных не сложная и достаточно стабильная, то применяется смещение. Например, объекты тем имеют область на координате Zот 1 до 99, объекты тестов – от 100 до 199, лабораторные – 200-299. Таким образом, к примеру, авторы тем могут располагаться на оси Zна уровне Z=2, оглавление тем имеет Z=5. При этом авторы тестов будут иметь координату Z=101.
Объединив две трехмерные структуры в единое пространство координат, получим новую структуру, расшифровку которой можно проиллюстрировать следующей кодовой таблицей:
| Расшифровка координат (кодов) | |||
| Y | X | Z | Расшифровка |
| 0 | n | 0 | Наименование учебного предмета |
| 0 | n | 1 | Автор учебного предмета |
| 0 | n | 2 | План |
| 0 | n | 3 | Тема |
| 0 | n | 4 | Тест |
| n | 0 | 0 | Фамилия студента |
| n | 0 | 1 | Имя |
| n | 0 | 2 | Отчество |
| n | n | 0 | Какой предмет изучает студент |
Для тех, кому сложно представить многомерные структуры, проще будет интерпретировать данную таблицу как набор кодов. Например:
0-100-0 – это будет код наименования учебного предмета под кодом 100
0-100-1 – информация об авторах учебного предмета под кодом 100
200-0-0 – код фамилии студента, имеющего личный номер в системе 200
200-0-2 – код информации об отчестве студента под номером 200
200-100-0 – код информации о том, что студент 200 изучает учебный предмет 100
Но, еще раз обращаю внимание, что данные коды не есть нечто подобное SCORM или CALS – это, прежде всего, координаты, предназначенные для математической обработки и описывающие логическую структуру.
Конечно, описанный пример весьма схематичен и примитивен. На практике бывает и больше координат, и более сложные комбинации кодов. Но не нужно думать, что сложности подобных систем запредельные. Например: реально работающая система, которая описывает 3D игровой мир площадью в несколько сот квадратных километров с весьма сложными моделями и искусственным интеллектом, содержащая более 200 тысяч объектов – это всего 6 координат и 21 параметр.