
Особенности алгоритмов идентификации образов человеком и компьютером Владимир И. Андреев
| Вид материала | Документы |
СодержаниеПервый главный вывод. Второй вывод Третий вывод |
- Конспект учебного занятия Город: Казань оу: «сош №9», 69.27kb.
- «Понятие об алгоритме. Примеры алгоритмов. Свойства алгоритмов. Типы алгоритмов, построение, 84.9kb.
- 9 Метаданные для информационных ресурсов, 274.27kb.
- Курс Vсеместры 9 (осенний) лекции 17 часов Экзамен 9 семестр (осенний), 69.52kb.
- Д. С. Осипенко Понятие алгоритма. Примеры алгоритмов. Свойства алгоритмов. Способы, 96.46kb.
- Развитие системы рыночных правоотношений недвижимости в россии: опыт межотраслевого, 643.2kb.
- Язык описания алгоритмов начертательной геометрии adgl, 70.57kb.
- Дипломная работа, 704.98kb.
- Т. А. Сравнительный анализ образов фауста, мефистофеля и личности карла густава юнга, 137.54kb.
- Комплекс визуальной идентификации как эволюционирующая знаковая система. Стилеобразующие, 159.15kb.
Особенности алгоритмов
идентификации образов человеком и компьютером
Владимир И. Андреев
Россия, Санкт-Петербург
Февраль 16, 2009
В процессе исследования задачи идентификации речевых сигналов на ЭВМ было установлено, что мозгом человека эта задача решается значительно эффективнее.
И возникло естественное предположение, что в мозгу реализован иной алгоритм решения таких задач. Есть основания полагать, что при идентификации сигналов человеческий мозг использует многоступенчатую схему принятия решения, на первом уровне которой работает процедура простого узнавания путем сравнения входных сигналов со всем множеством ранее накопленных в памяти.
На основании этого вывода был предложен трехуровневый алгоритм идентификации включающий следующие этапы принятия решения [1]:
- первый этап: «Узнавание» - сравнение на «полное» совпадение входного сигнала (в некоторой системе описания) со всей информацией в памяти системы о сигналах, подлежащих «распознаванию»;
- второй этап: «Опознавание» - при неоднозначном решении на первом этапе, как процедура выявления искомого класса из подмножества, сокращенного на первом этапе, но уже используя статистические параметры, накопленные в процессе обучения; - третий этап: «Распознавание» – когда в памяти системы вообще нет данного варианта описания, то есть, система не обучена или «недообучена». На этом этапе должны быть использованы все «классические» вероятностно-статистические методы, включая процедуру «обнаружение сигнала на фоне шума».
Автором этой работы была детально исследована модель идентификации первого этапа, реализованная в виде технического блока преобразования речевого сигнала в код и комплекса программ ЭВМ [2].
Технический блок обеспечивал предварительную «компрессию» аналогового сигнала, преобразование его в дискретный код и сопряжение с ЭВМ.
Программный комплекс системы включал две основные программы: «Формирование дифференциальных признаков описания» и «Обучение-узнавание».
Первая программа преобразовывала дискретное представление речевых сигналов в систему двоичных признаков, размерности «m».
Программа «Обучение-узнавание», реализованная в виде логического дешифратора, обеспечивала «ассоциативное» запоминание и поиск описания сигналов в памяти ЭВМ, без перебора всего множества материала обучения, представленного в двоичной метрике описания.
При размерности описания каждого «среза» сигнала, равной «m» двоичных разрядов, в памяти компьютера формировались матрицы «обучения», размерности N х Q,
где: N =
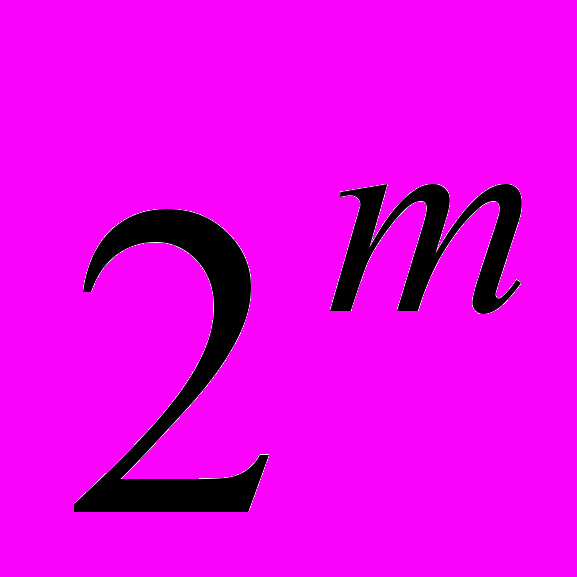 - длина матрицы обучения; Q - ширина матрицы обучения (равная числу классов сигнала).
- длина матрицы обучения; Q - ширина матрицы обучения (равная числу классов сигнала).Алгоритм работы программы следующий.
Входной сигнал в «m» - мерной метрике описания принимался как относительный адрес строки матрицы обучения. Исполнительный адрес получается в результате арифметического сложения базового адреса АБ (адрес начала матрицы обучения) и входного кода описания m. Аисп = АБ + m
На этапе обучения системы в полученной строке матрицы обучения, в разряд, соответствующий i-му номеру класса сигналов, записывается «1», означающая, что данный фрагмент сигнала i-го класса имеет такой вариант представления в метрике признаков описания.
Поскольку каждый реальный сигнал имеет описание, состоящее из К фрагментов (временны´х) параметров, представленных m - мерными кодами, то общее поле обучения содержит К матриц размерности N Q, которые по мере обучения системы заполняются «единицами».
На этапе «узнавания» схема работает аналогично.
По входному сигналу формируется Аисп = АБ + m. Из памяти извлекается строка длиной Q разрядов и проверяется, какие из разрядов «не нулевые».
Номера «ненулевых» разрядов обозначают классы, в которых встречается данный фрагмент входного сигнала.
Решение об «узнавании» всего сигнала принимается после проверки на совпадение всех «К» признаков описания по следующему алгоритму:
- выбираются строки из всех «К» матриц обучения - Х(Q)i - и полученные частные результаты логически перемножаются Х(Q)1 Х(Q)2 ... Х(Q)i Х(Q)k = X(Q)fin.
При этом в результате возможны три варианта ситуаций:
- X(Q)fin = 0 - означающее, что сигнал не принадлежит ни одному из заданных классов или, что система еще не обучена;
- X(Q)fin 0 и, в одном из разрядов строки имеется «1», это означает, что сигнал принадлежит одному конкретному классу – система его «узнала»;
- X(Q)fin 0, но, «1» имеются в нескольких разрядах, что означает - класс сигнала на данном этапе однозначно не определен и требуется перейти на следующий уровень идентификации - опознавание.
В результате испытания модели «Обучения-Узнавания» и анализа полученных результатов, были получены следующие выводы:
Во-первых, процесс накопления информации в памяти ЭВМ идет по закону, близкому к экспоненте и система достаточно быстро «насыщается». Объем информации, запоминаемый системой, значительно меньше, чем поступающий в нее в процессе обучения [2].
Во-вторых, на материале 27 дикторов (мужчин и женщин) было экспериментально установлено, что вероятность «неузнавания» системой сигналов очередного нового диктора убывает по мере обучения системы, изменяясь по закону гиперболы 1/N, где N – количество участвовавших в обучении системы. Следовательно, принципиально, ее можно научить «узнавать» сигналы с любой, наперед заданной, достоверностью.
В-третьих, описанный выше алгоритм «Обучения-Узнавания» обладает следующими свойствами:
- процесс «узнавания» на ЭВМ не требует высокого быстродействия и происходит практически мгновенно, так как решение принимается после нескольких обращений к памяти и операции логического перемножения промежуточных результатов (простейшая функция, легко выполняемая аппаратно или в нейронной сети);
- алгоритм требует памяти большой размерности для организации матриц обучения - полей хранения материала обучения.
Но, как показывает анализ, именно такими свойствами и обладает мозг человека, что и позволяет допустить, что в мозгу человека, видимо, реализована именно такая схема идентификации.
Известно, что в нейронной сети мозга скорость передачи сигналов не превышает тысячи «импульсов» в секунду. Иначе говоря, «быстродействие мозга» на несколько порядков ниже быстродействия обычных компьютеров.
В то же время, информационная емкость мозга очень велика, что и позволяет мозгу осуществлять идентификацию смыслового содержания слов и фраз из словаря в несколько десятков тысяч слов практически мгновенно.
Таким образом, если быть последовательными, следует признать, что наиболее естественно к этим свойствам мозга подходит именно алгоритм узнавания.
Но, как может мозг, при наличии в коре мозга всего 1010 нейронов, хранить всю поступающую информацию, если только один зрительный канал человека в течение 80 лет жизни принимает около 1016 - 1017 бит информации?
Остальные органы чувств добавляют еще лишь незначительную часть от объема информации зрительного канала, но и одного потока зрительного канала вполне достаточно, чтобы переполнить емкость мозга. Но, этого не происходит, и мозг успешно справляется с задачей. Каким образом?
Чтобы показать, реальность схемы идентификации мозгом входных сигналов, путем детерминированного узнавания, покажем, что возможна такая схема организации памяти, при которой информационная емкость системы (в частности, мозга) на несколько порядков превышает число отдельных элементов памяти (нейронов в коре головного мозга) и даже во много раз превышает объем информации, поступающей в мозг на протяжении всей жизни.
Известно, что нейроны - элементы нервной системы и мозга, имеют один выход (аксон) и множество входов. В коре головного мозга они образуют сети, состоящие из многих совокупностей, так называемых «ансамблей». Нейроны в таких ансамблях могут иметь до сотен входов (синапсов), через которые они устанавливают связи друг с другом и с другими ансамблями.
Полагаем, что процесс обучения и накопления информации в мозгу заключается в том, что в нейронных сетях в процессе развития организма, при многократном повторении входных сигналов (обучении), образуются и закрепляются новые синаптические связи и нейрон, видимо, таким образом накапливает информацию. Следовательно, нейрон головного мозга это вовсе не аналог одного элемента памяти компьютера, как считалось ранее.
Нейроны коры головного мозга это целые сети, которые способны при большом числе синапсов (входов нейрона) запоминать, накапливать и хранить в одном нейроне тысячи бит информации. Покажем возможность реализации нейронной сети мозга, на примере аналогичной сети - схемы организации памяти на магнитных (ферритовых) сердечниках в старых ЭВМ (см. рис.).
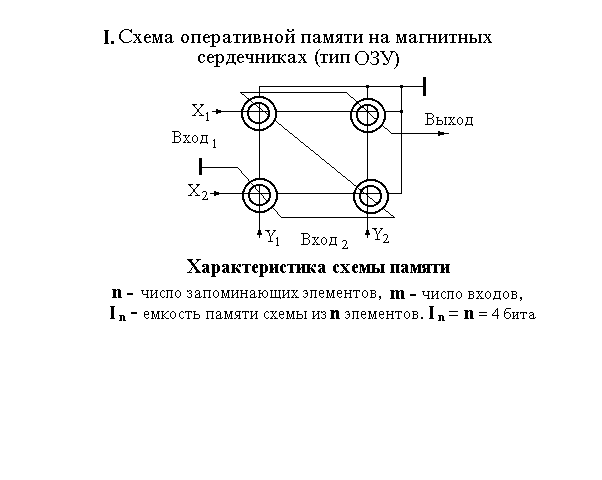
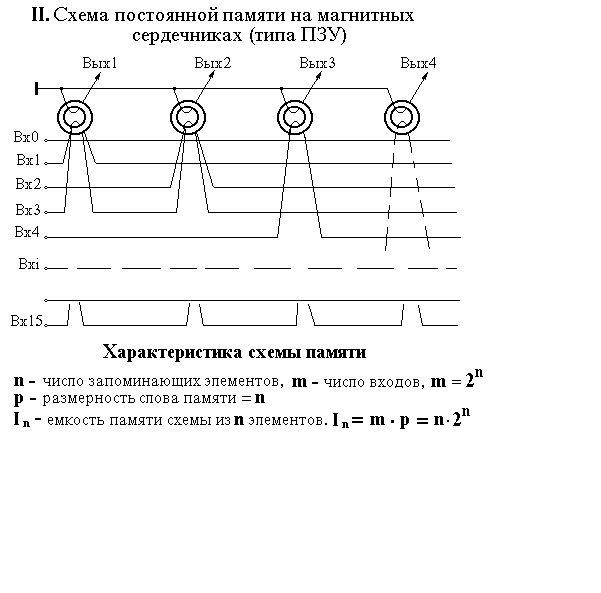
Рис. 1 Варианты организации памяти в ЭВМ
Левая схема - организация «оперативной» (ОЗУ) памяти «матричного типа», позволявшая записывать, считывать и стирать любую информацию.
Правая схема - реализация «постоянной» (ПЗУ) памяти ЭВМ, позволявшая только считывать информацию, «записанную» в нее при создании.
Как явствует из алгоритмов работы, вторая схема более «примитивна», так как может выполнять лишь одну функцию - хранить информацию и выдавать ее по запросу. Но, она более экономична с точки зрения затрат энергии и расхода элементов памяти.
В ОЗУ объем информации равен количеству элементов памяти - n, а количество информации, которое может храниться во второй системе (ПЗУ) на тех же n элементах, равно n
 .
. Как показывают исследования функциональных возможностей мозга, именно такими свойствами он и обладает. У мозга низкие энергозатраты и информация в мозгу хранится постоянно (оперативно не стирается). А это подтверждает возможность организации нейронной сети мозга по функциональным возможностям подобной схеме организации ПЗУ ЭВМ.
На основании этого вывода произведем оценку информационной емкости памяти мозга по той же методике, что и оценка памяти ПЗУ.
Предполагая организацию сети нейронов в коре мозга аналогичной организации (ПЗУ), считаем, что запоминание и хранение информации осуществляется ансамблями по n нейронов в ансамбле.
Каждый ансамбль может хранить объем информации
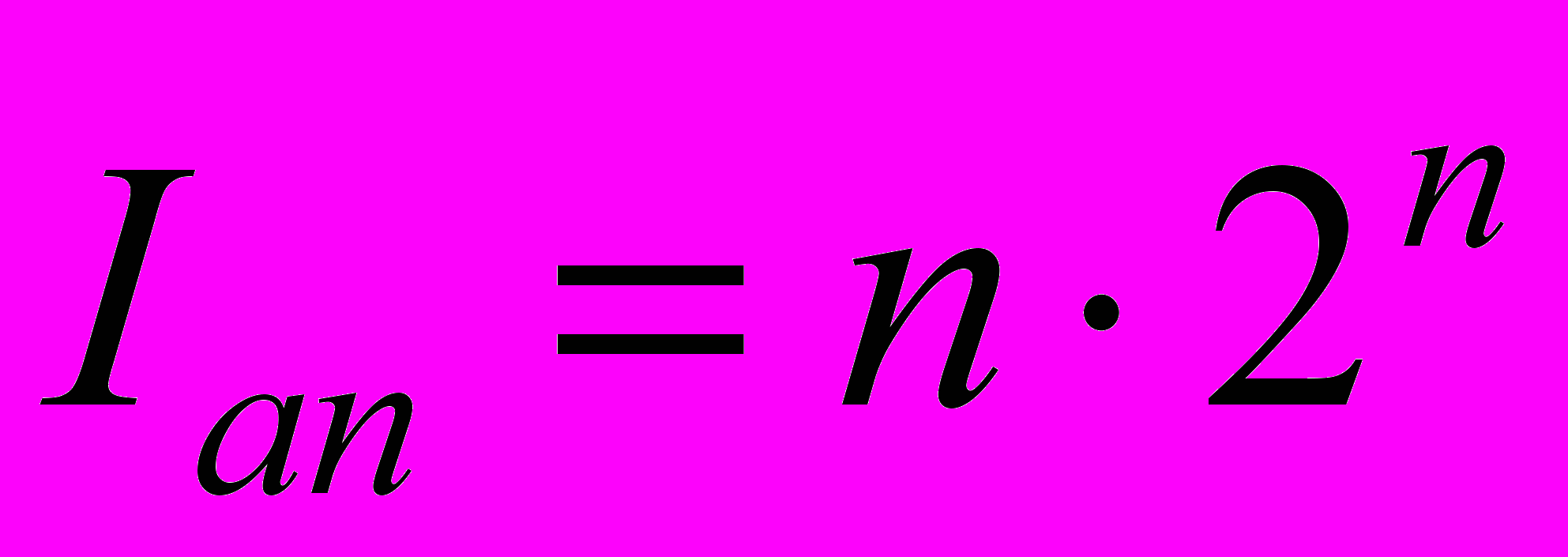 , бит.
, бит. Число ансамблей Nan в общем поле памяти из Nn нейронов будет
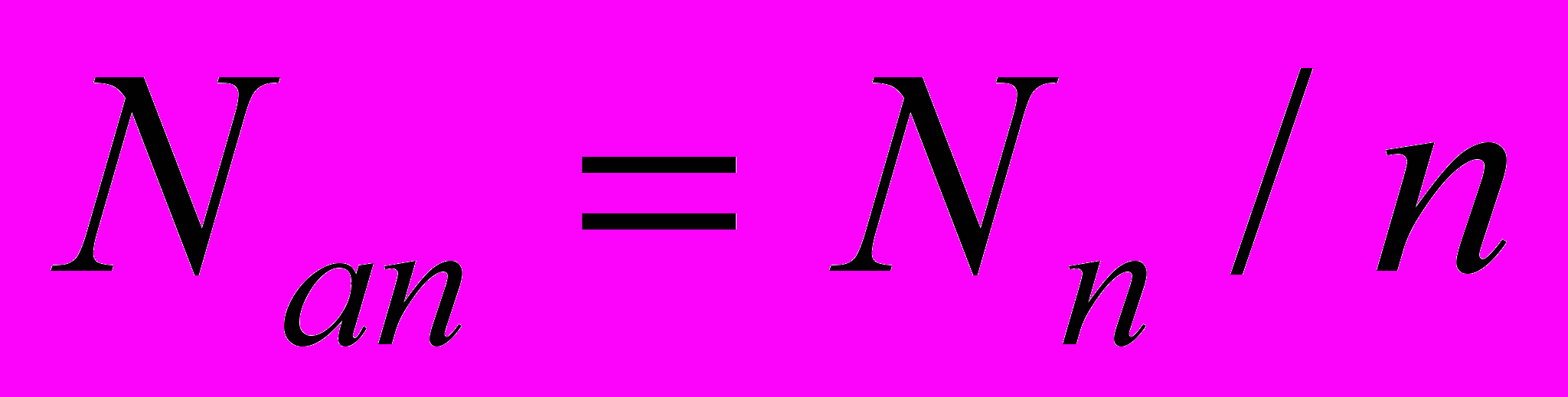 (1)
(1)Суммарная емкость данных, которые могут быть запомнены в поле памяти
 , определится как
, определится как 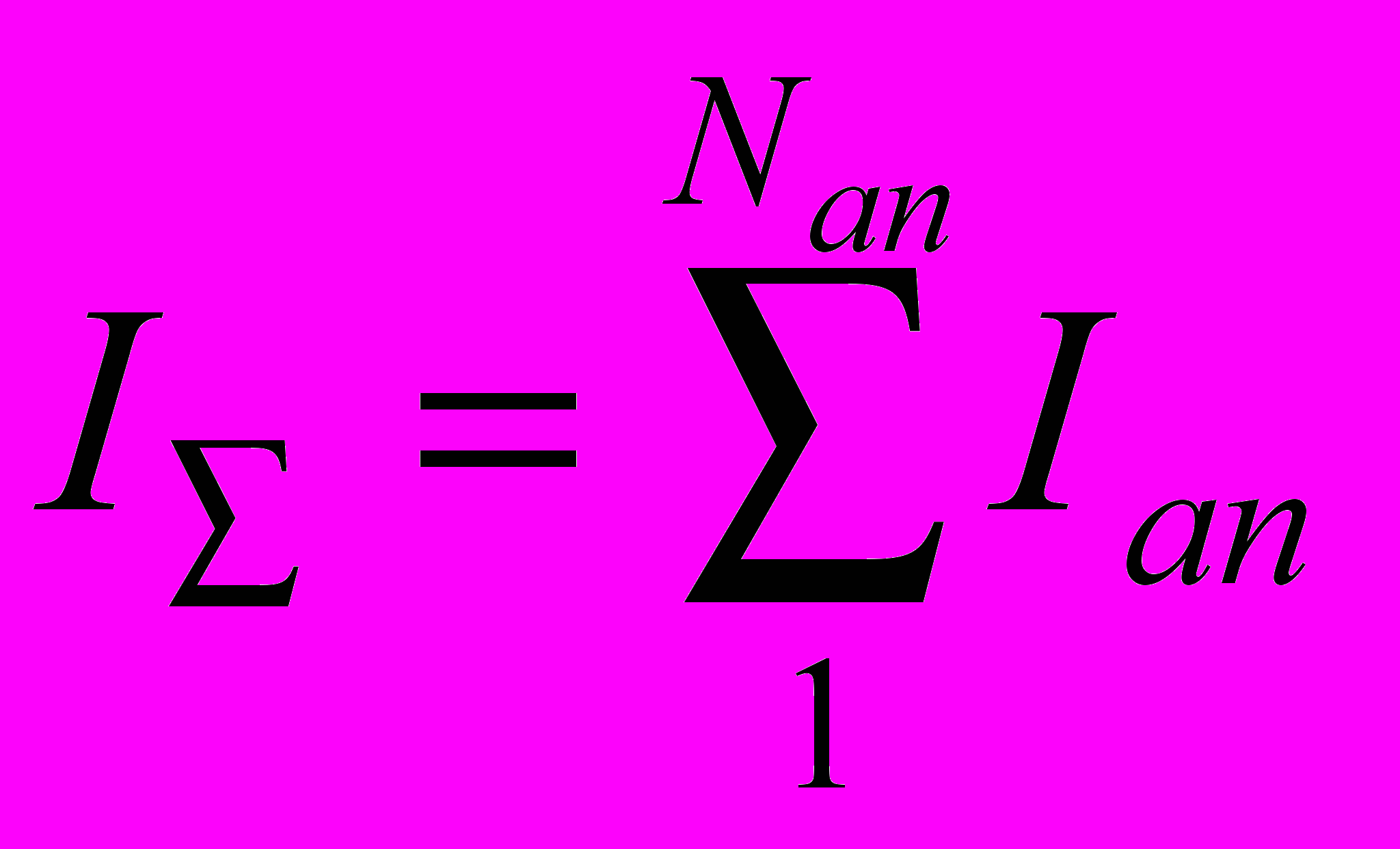 (2)
(2)Предположив, для простоты, что все ансамбли имеют одинаковую размерность, получим возможную емкость памяти в следующем виде
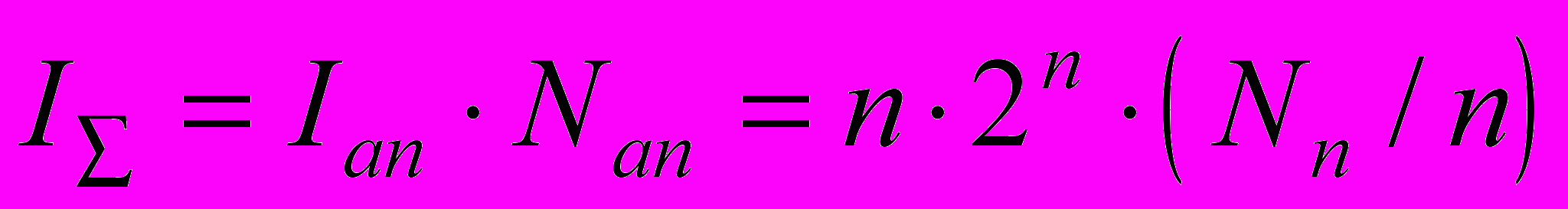 и окончательно
и окончательно 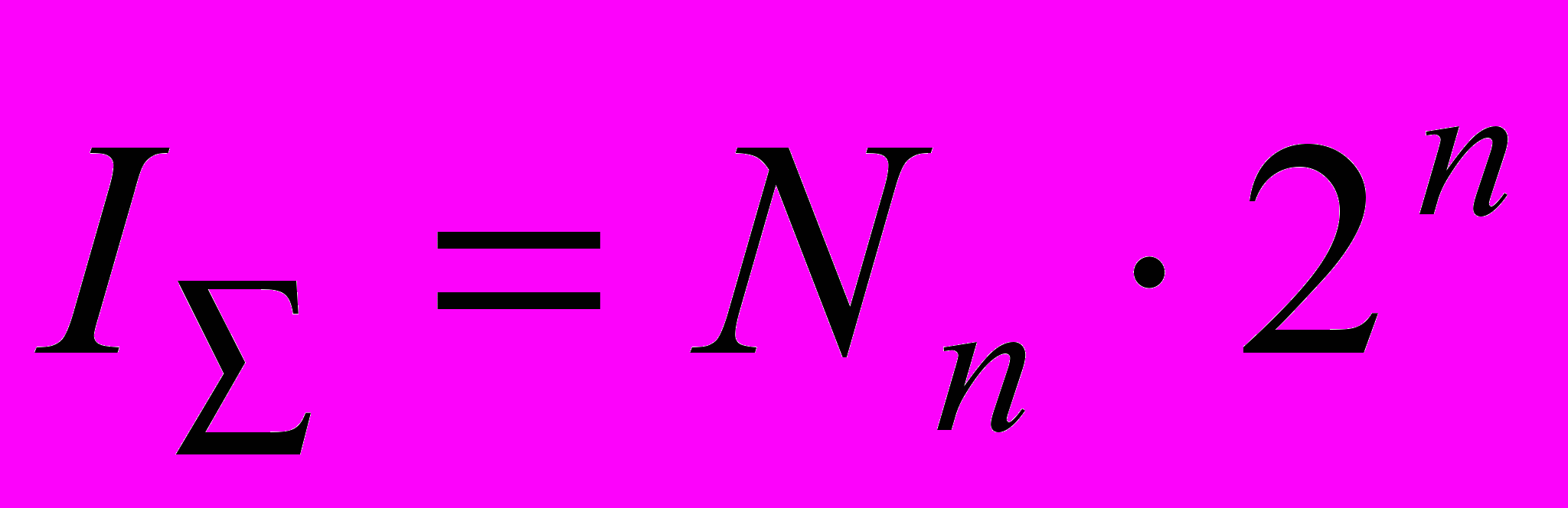 (3)
(3)Принимая, что общее число нейронов в коре мозга 1010, допускаем, что для запоминания информации используется только 1 % нейронов, то есть Nn = 108.
Будем считать, что остальные 99 % нейронов мозга участвуют в логической обработке, осуществляя «дешифрацию» входных сигналов и организуя связи ансамблей нейронов памяти с аналитической областью мозга.
Тогда, при Nn = 108 и размерности ансамбля n = 20, емкость памяти составит
I = 108 220 108 106 1014 бит.
Однако в реальной структуре мозга известны ансамбли из 100 и более нейронов. Поэтому, с учетом такой возможности ансамблей мозга, реальная емкость мозга может достигать величины 1020 - 1030 бит, что в миллионы раз больше, чем это требуется для хранения информации, получаемой человеком в течение жизни всеми органами чувств.
Следовательно, имеющиеся данные о количестве нейронов в коре мозга при описанной схеме хранения информации вполне могут обеспечить информационную емкость для хранения не только всей информации, поступающей через все органы чувств на протяжении жизни человека, но и некой «дородовой» (наследственной) информации, иногда проявляющейся у некоторых людей в виде «памяти» о событиях, в которых данный человек принципиально не мог присутствовать.
Какие выводы можно сделать в завершение проведенного анализа?
Первый главный вывод. Рассмотренную схему идентификации сигналов в мозгу человека можно считать реальностью.
Мозг, в отличие от компьютера, работает по другому алгоритму. Он ничего не вычисляет, а только запоминает новую информацию и извлекает из памяти то, что ему было уже когда-то предъявлено ранее.
Мозг - это не арифмометр, а огромный дешифратор, приводящий входные сигналы от разных органов к однообразной структуре, в комплексе с запоминающим устройством, по схеме ассоциативной «записи», хранения и поиска информации.
Второй вывод. Для успешной реализации технических систем идентификации образов любого типа, они должны строиться по аналогии с мозгом и на первом этапе должен использоваться алгоритм «узнавания» по описанной схеме.
Третий вывод. Используя трехуровневую схему идентификации, включая уровень вероятностно-статистического «распознавания», можно построить систему, способную к самообучению (самосовершенствованию).
Сигнал, «неузнанный» технической системой на первом уровне, после его «распознавания» на третьем уровне, может быть запомнен в поле памяти «обучения». Повысив свой уровень «обученности», в дальнейшем система идентификации будет реже обращаться к высшему уровню принятия решения, на основе длительной и сложной процедуры.
Литература
1. Андреев В.И. Концептуальная модель автоматической классификации речевых сигналов. Тезисы XI Всесоюзной школы-семинара АРСО-11. Ереван 1983. с.385.
2. Андреев В.И. Некоторые свойства автоматической распознающей системы, построенной по принципу узнавания речевых сигналов. Тезисы докладов и сообщений 12-го Всесоюзного семинара “Автоматическое распознавание слуховых образов”. Киев-Одесса 1982. Ч.1, с.6-8.