
Е. В. Информационные модели в задачах геологического и гидродинамического моделирования
| Вид материала | Задача |
- Учебно-методический комплекс курса по выбору "задачи егэ по информатике" (физико-математический, 704.64kb.
- 1. Введение. Основные понятия моделирования Общая характеристика проблем моделирования., 38.29kb.
- Урок по информатике «Информационные модели», 76.56kb.
- Материальные и информационные модели, 27.68kb.
- Математическое моделирование (вопросы к экзамену), 89.87kb.
- Основы моделирования данных, 434.87kb.
- Лекция: Анализ и моделирование функциональной области внедрения ис: Основные понятия, 234.94kb.
- Программа 3 информационные и вычислительные технологии в задачах поддержки принятия, 598.4kb.
- Методика построения функциональной модели. Источники информации. Начало моделирования., 818.27kb.
- О Конкурса асов компьютерного 3D-моделирования среди предприятий, использующих в проектных, 9.87kb.
Биряльцев Е.В.
ИНФОРМАЦИОННЫЕ МОДЕЛИ В ЗАДАЧАХ ГЕОЛОГИЧЕСКОГО
И ГИДРОДИНАМИЧЕСКОГО МОДЕЛИРОВАНИЯ
Е.В. Биряльцев
Программная реализация научных разработок в области моделирования сплошных сред, доведение программных комплексов до уровня современных стандартов корпоративного программного обеспечения ставят множество практических вопросов по управлению информацией. Наибольшее количество вопросов возникает при разработке программного обеспечения геологического и гидродинамического моделирования месторождений природных углеводородов. Программные комплексы моделирования разведки и разработки месторождений оперируют большими объемами данных, имеющих сложную внутреннюю структуру. Нефтедобывающая отрасль традиционно относится к отраслям, насыщенным средствами вычислительной техники, обладающим разнообразием применяемых методов обработки информации и накопившим колоссальные архивы данных за предыдущие десятилетия.
В 2001 г. с целью разработки и программной реализации эффективных алгоритмов управления большими массивами разнородных информационных ресурсов, возникающих в обозначенных задачах, в составе НИИММ была образована Лаборатория технологий баз данных. Ниже описаны основные направления ее деятельности и некоторые полученные результаты.
1. Задачи информационного моделирования. Построение промышленно применяемых программных систем моделирования требует разработки и реализации эффективных алгоритмов управления как исходной информацией для моделирования, так и информацией о построенных моделях. Возникающие при этом задачи не являются чисто техническими, так как для большого количества задач управления информацией не существует в настоящее время стандартных общепризнанных алгоритмов их решения. Единственным хорошо разработанным математическим подходом к описанию структуры информации является реляционная алгебра, трудности которой хорошо известны. Большинство других технологий информационного моделирования, в том числе популярные сейчас объектно-ориентированные технологии, не имеют под собой разработанного математического аппарата.
Можно сказать, что в технологиях баз данных в настоящее время происходит первичное накопление фактов о природе и свойствах информационных объектов, а также делаются полуэмпирические попытки их систематизации. Вместе с тем практика разработки программного обеспечения, оперирующего информационными массивами больших сложности и объема, в том числе при математическом моделировании поведения природно-технических объектов, настоятельно требует эффективного решения разнообразных задач управления информацией. В настоящее время подобные решения можно выработать только на основе глубокого изучения свойств конкретных классов информационных объектов, информационного смысла операций, производимых с ними прикладными алгоритмами, и анализа применимости известных теоретических и практических методик управления информацией.
Задачи информационного моделирования, решаемые Лабораторией, можно разделить на три группы:
– оптимизация физического представления информации;
– логическое моделирование и проецирование логических моделей на физические;
– управление качеством информации и семантическое моделирование.
2. Оптимизация физического представления информации. Его задачей является разработка структуры и состава программных компонентов, в которых будет находиться обрабатываемая информация как во время выполнения программ, так и между сеансами. Физическое моделирование ведется в терминах выбранных языка и среды программирования – мы может говорить о структурах записей, файлов, таблиц, объектов и т. д. Для любой сложной информационной структуры данная задача, взятая сама по себе, в отрыве от обрабатывающих алгоритмов, не имеет однозначного решения. При проектировании физической структуры значительную роль играют и технические ограничения – объемы дисковой и оперативной памяти, мощность процессора.
Можно выделить три группы целевых функций, которые оптимизируются при разработке физической структуры данных – временные характеристики обрабатывающих модулей, объемные характеристики получаемых баз данных и устойчивость структуры данных к изменениям в структуре обрабатываемой информации.
К временным характеристикам относят такие параметры, как среднее и максимальное время поиска и записи информации для отдельных алгоритмов и для некоторой смеси алгоритмов. Сюда же можно отнести и критерии поведения системы при многопользовательском доступе – зависимость производительности от количества активных пользователей, вероятность блокировок и тупиков.
К объемным характеристикам получаемых баз относятся количество записей, объемы получаемых файлов, требуемые объемы оперативной памяти.
Устойчивость структуры – параметр скорее качественный. Он определяет, какие отклонения от идеального качества обрабатываемой информации допустимы без изменения физической структуры данных.
Названные группы целевых функций имеют почти антагонистический характер, поэтому на практике все или почти все они переводятся в объемные, временные или структурные ограничения, и ищется техническое решение, попадающее в поставленные ограничения.
В связи с широким распространение реляционных баз данных физическое проектирование может вестись в терминах таблиц и их атрибутов, доменов, индексов и т. д. В данном случае к задачам физического проектирования относится решение специфических для реляционного представления данных задачи выявления и устранения так называемых аномалий – ситуаций, когда структурных построений недостаточно для описания известных структурных зависимостей между данными, и необходимо введение дополнительных алгоритмических зависимостей между ними. К их числу относится известный факт сложности адекватного реляционного описания иерархических структур.
Достаточно остро при физическом моделировании информации о сложных природно-технических объектах стоит вопрос физического моделирования нереляционных данных, в частности, пространственно-временных свойств объектов. Строго говоря, пространственные и временные характеристики могут быть описаны реляционной моделью, но такое описание порождает массу аномалий и, как правило, неэффективно по объемным и временным критериям.
Решения задачи физического моделирования нереляционных объектов ищутся в двух направлениях – созданием специализированных баз данных, к которым можно отнести базы данных систем ГИС, САПР, систем виртуальной реальности и т. п., а также расширением реляционной модели специализированными типами данных и операциями над ними. Последний подход начинает в настоящее время превалировать.
Плохо представляется в реляционной модели и версионность данных. Наличие версий атрибутов отношений нарушает первую нормальную форму, а учет версий в реляционной модели приводит к разбиению данных на отдельные отношения вида (атрибут, версия), что резко снижает эффективность работы прикладных алгоритмов. К задаче моделирования версионности примыкает задача моделирования исключений – случаев нарушения кардинальности или ссылочной целостности данных, возникающих крайне редко по сравнению с основной массой данных, но необходимых для практически работающих приложений. Решения таких задач ориентированы в направлении расширения реляционной модели коллекциями и вариантными записями и операциями над ними.
К задачам физического моделирования можно отнести и задачи сжатия информации. Минимизация объемов данных повышением степени нормализации отрицательно влияет на производительность приложений, кроме того, нормализация неэффективна для непрерывно изменяющихся атрибутов. Особенный интерес вызывает применение методов сжатия с потерей качества к пространственно-временным рядам параметров природных и технических объектов. Известно, что методы фрактального и вейвлет-сжатия могут дать коэффициенты сжатия в сотни и тысячи раз при приемлемой потере данных. Использование вышеуказанных методов применительно к базам данных в настоящее время разработано крайне слабо.
3. Логическое моделирование. Предметом логического моделирования информации является формальное описание состава и структуры данных предметной области в терминах этой предметной области. К задачам логического моделирования можно отнести и задачу проекции логической модели на физическую, т. е. установление взаимно однозначной связи между объектами логической модели и соответствующей ей физической модели данных.
Логическое моделирование преследует цель дать достаточное и непротиворечивое описание состава и структуры подмножества характеристик объектов реального мира. Сформированная логическая модель может применяться для разработки алгоритмов поиска данных, их пополнения и аналитической обработки.
В отличие от физического моделирования, где существуют общепризнанные теоретические подходы – реляционная модель, списочные структуры, и т. д., в области логического моделирования идет активный поиск формализмов для представления логических моделей.
Формализм логического моделирования должен удовлетворять следующим требованиям:
– обладать достаточной методологической мощностью для описания логических моделей из различных предметных областей;
– иметь нотацию, допускающую понимание смысла логической модели специалистом-предметником, не имеющим глубокого образования в области информатики;
– быть достаточно строгим для однозначной проекции логических моделей на физические и алгоритмизуемости операций с логической моделью.
В настоящее время существует несколько конкурирующих подходов к логическому моделированию. К числу наиболее известных можно отнести язык UML, развиваемый компанией Ration Rose во главе с Г. Бучем, проект STEP, развиваемый ISO, и подход, основанный на языках описания структуры данных семейства XML, развиваемый большим количеством организаций, в том числе корпорацией Oracle. В последнее время наметилась тенденция к конвергенции трех вышеупомянутых подходов, что дает основания надеяться на появление в ближайшей перспективе универсального и общепризнанного формализма описания логических моделей.
В области информационного моделирования объектов разведки и эксплуатации месторождений нефти и газа существует несколько проектов стандартизации логических моделей предметной области, один из которых, проект POSC, развивается, наряду с другими заинтересованными организациями, комитетом ISO и имеет статус международного стандарта. Начиная с конца 90-х годов 20-го века, на основе стандарта POSC созданы коммерческие программные комплексы в области геологического и гидродинамического моделирования и управления разведкой и разработкой месторождений нефти и газа. Помимо формализма описания логических моделей стандарт предоставляет также базовую логическую модель предметной области и методы ее дополнения и редукции для реализации конкретных обрабатывающих программ. Значительные усилия Лаборатории были направлены на изучение применимости стандарта POSC при программной реализации научных разработок в области моделирования резервуаров природных углеводородов.
Логические модели могут применяться не только на стадии проектирования информационных систем, но и на стадии их функционирования. Наличие логической модели обязательно в таких приложениях, как хранилища данных (в которых они носят название «метаданные»), системы поддержки принятия решений и он-лайнового анализа и в ряде других. Доступ к данным в системах, реализованных с учетом рекомендаций стандарта POSC, также производится через логическую модель данных.
Особенно актуально использование логических моделей для доступа к информации стало в последние несколько лет, после развития Интернет-технологий. Развитие Интернет в сторону бизнес-приложений приводит к необходимости не только стандартизации формальных описаний логических моделей данных, но и к стандартизации элементов семантики, к которым в первую очередь можно отнести стандартизацию классификаторов дискретных признаков и методов измерения непрерывных признаков объектов. В настоящее время осуществляется попытка решения данной проблемы на основе развития языков описания структуры данных семейства XML. Практические разработки Лаборатории выполняются с широким использованием диалектов XML для создания встроенных в систему метаописаний.
4. Семантическое моделирование. Моделирование семантики данных имеет достаточно давнюю историю, но смысл, вкладываемый в понятие «семантическое моделирование», за последние двадцать лет значительно изменился. Если в конце 70-х – начале 80-х годов 20-го века с моделированием семантики данных связывались надежды на создание систем искусственного интеллекта, то с середины 90-х в семантическом моделировании видят в первую очередь возможность интеллектуальной интерактивной обработки больших и сверхбольших массивов данных. К числу технологий, опирающихся на семантическое моделирование, можно отнести системы извлечения данных и очистку данных в хранилищах данных.
В Лаборатории семантическое моделирование развивается применительно к задачам создания и ведения баз данных сложных природно-технических объектов, в первую очередь разрабатываемых месторождений. Основные решаемые задачи:
– разработка методов интеграции информации из различных источников и создание баз данных;
– оценка полноты и непротиворечивости наборов данных;
– методы навигации в больших массивах информации сложной структуры.
Интеграция информации из различных источников сопряжена не только с необходимостью преобразования физических моделей. Гораздо более сложной задачей является установление логической структуры и смысла интегрируемых данных. В большинстве случаев интеграции подлежат наборы с неполным описанием логической модели, отягощенные искажениями информации, связанной с человеко-машинным характером обработки данных. Интеграция таких данных только на основе структурных преобразований информации невозможна или приводит к значительной потери информации.
В Лаборатории разрабатывается ряд подходов, основанных на анализе внутренних статистических закономерностей интегрируемых данных, в частности, избыточности кодирования символьной информации. Статистический анализ данных позволяет с большой долей вероятности восстанавливать искаженные и пропущенные значения, а также делать заключения о целесообразности интеграции конкретного набора данных в общую базу.
Оценка достаточности (полноты) и непротиворечивости сформированных баз данных для решения различных задач, в том числе задач математического моделирования, актуальна, так как реальные данные всегда содержат пропуски или искажения информации. В задачи оценки входит как собственно оценка полноты и непротиворечивости данных, так и поиск значений, с большой долей вероятности искаженных, с целью их исключения или повторного поиска (измерения) реальных значений. Не все задачи данного класса решаются статистическими методами, так как между параметрами могут существовать сложные многозначные функциональные зависимости. Каждый из отдельных параметров может иметь достаточно хорошую статистическую достоверность, но в совокупности картина является недостоверной.
Ошибки подобного рода хорошо проявляются при математическом моделировании поведения природно-технических объектов в виде аномального поведения рассчитываемых величин. В настоящее время совместно с Лабораторией моделирования разработки нефтяных месторождений ведутся работы по созданию методов комплексной оценки достоверности баз данных на основе применения геологических и фильтрационных моделей резервуара.
К задачам оценки полноты и достоверности примыкают задачи навигации в больших базах данных, в которых существенную роль играет специфика человеческого восприятия информации в различных формах. Известно, что кратковременная память человека может оперировать одновременно с количеством абстрактных объектов, не превосходящих десяти. При работе с большими базами данных человек сталкивается в информационными массивами объемом в миллионы записей, понять и проанализировать которые он не в состоянии. Вместе с тем хорошо известно, что человек способен запоминать и сравнивать и анализировать зрительные образы, содержащие очень большое количество отдельных элементов. Основываясь на этих особенностях человеческого восприятия, в Лаборатории ведутся работы по созданию прототипов графического интерфейса к большим базам данных.
Перечисленные задачи Лаборатория решает в выполняемых договорах с бюджетными и коммерческими организациями, а также в рамках грантов РФФИ.
5. Логическая модель хранения геометрии нерегулярных 3-D сеток для задач геологического моделирования. В системах геологического и гидродинамического моделирования широко используется представления пространственных образований – геологических тел и их совокупностей – в виде сеток – трехмерных наборов элементарных объемов (ячеек). Такое представление необходимо для численного моделирования как геометрии тел, так и распределения в их объеме различных физических и геологических параметров.
Выделяют два основных вида сеток – регулярные и нерегулярные. Регулярная сетка является массивом размерности, соответствующей размерности моделируемого пространства. Значения координат вершин любой из ячеек сетки являются функциями от индексов массива. Геометрию такой сетки можно не хранить, если функция достаточно проста, например, линейная, что характерно для широко распространенного случая равномерных сеток.
В последнее время в практике моделирования все большее распространения приобретают нерегулярные сетки, характерной особенностью которых является невозможность вычисления координат вершин ячеек по их индексу. Для таких сеток возникает необходимость эффективного, с точки зрения занимаемого объема и времени выполнения характерных операций, представления логической модели хранения геометрической информации.
В общем случае логическая модель геометрии ячейки сетки включает в себя сущности <узел>, <дуга> и <сторона> [1], между которыми существуют многочисленные связи типа «многие-ко-многим». ER-диаграмма модели представлена на рис. 1. Большая сложность общей логической модели и значительный объем хранимых данных требуют изыскания путей упрощения общей логической модели с учетом семантики геологических моделей и характером решаемых задач.

Рис. 1. Логическая модель ячейки нерегулярной сетки
Для геологических моделей характерно применение сеток, состоящих из шестигранных ячеек, ребра которых являются прямолинейными отрезками. Ячейки в основном плотно прилегают друг к другу. Для таких сеток нет необходимости хранить все сущности ячейки (грани, ребра и вершины), так как они однозначно восстанавливаются из упорядоченного набора вершин шестигранника. На такой модели основан метод хранения сетки в виде набора вершин, широко применяемый в системах геологического и гидродинамического моделирования [2]. Эта модель является достаточно экономичной по объему хранимой информации и составляет 24 атрибута на шестигранную ячейку.
Наиболее часто встречающейся задачей при интерактивной работе с сеточными данными является визуализация некоторого подмножества ячеек. Алгоритм решения этой задачи следующий:
 (1)
(1)В современных программно-технических моделирующих комплексах первая задача решается сервером базы данных, вторая – клиентом и третья – графическим контроллером рабочего места.
При хранении информации о геометрии сетки в реляционных клиент-серверных СУБД с использованием модели хранения вершин возникает ряд технических трудностей. В клиент–серверных технологиях узким местом является сеть передачи данных между сервером и клиентом. Экспериментальные оценки показывают, что скорость обмена данными для подобных задач между клиентом и сервером в сети Ethernet 10Mbod не превышает двух тысяч записей в секунду. Для характерных размеров сеток в 1 млн. ячеек время передачи данных клиенту составит около 10 минут, что для интерактивных задач совершенно недопустимо.
Основываясь на технологиях визуализации, применяемых в современных графических контроллерах, и особенностях визуализируемой информации, можно ввести дополнительный этап обработки информации – удаление заведомо невидимых граней, каковыми являются смежные грани визуализируемых ячеек. Алгоритм визуализации в данном случае будет следующим:
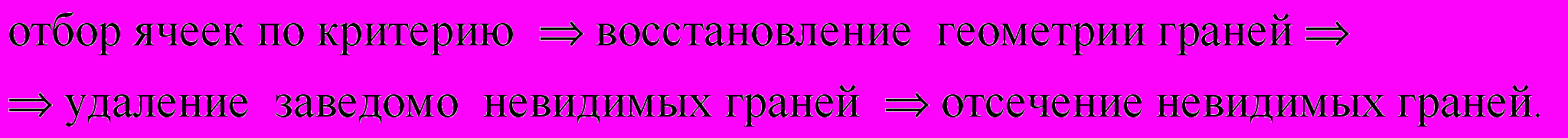 (2)
(2)Предварительное удаление заведомо невидимых граней эффективно даже при использовании специализированных графических контроллеров со встроенной поддержкой рендеринга, так как контроллер освобождается от большого объема расчетов с заведомо бесполезной информацией. Вынесение этапа удаления заведомо невидимых граней на сервер и передача для визуализации на клиента только несмежных граней позволит для плотных геометрий значительно сократить объем передаваемой информации.
В данном методе объем передаваемой информации будет пропорционален площади поверхности визуализируемого тела, тогда как в случае (1) он пропорционален объему тела. Для характерных размеров сетки в 1 млн. ячеек сокращение объема передаваемых строк составит около 100 раз с вполне приемлемым временем 5 сек на сопоставимых технических средствах. Для реальных геологических тел отношение несколько меньше за счет сложной формы, но также достаточно велико. Пример представлен на рис. 2.

Рис. 2. Каркасное представление нерегулярной сетки с удаленными заведомо невидимыми гранями (слева) и без их удаления (справа)
Техническая реализация предложенной методики на модели с хранением вершин наталкивается на другую сложность. Восстановление граней сетки и определение среди них заведомо невидимых является достаточно сложной вычислительной процедурой, в которых производится сравнение агрегатов атрибутов. В реляционных базах данных это исключает эффективное использование индексов для поиска информации, что приводит к увеличению времени на обработку данных. Кроме того, хранимые процедуры сервера БД работают в режиме интерпретации, что также делает нежелательным вынесение сколько-нибудь сложных вычислений на сервер БД.
Можно предложить другую модель хранения геометрии ячеек, свободную от указанных недостатков и основанную на выделении граней как основного логического объекта. Грани в такой модели являются упорядоченным массивом координат вершин граней, хранящихся в виде последовательного списка. Ячейки представляются неупорядоченным множеством ссылок на грани, при этом смежные грани ячеек определяются на этапе записи данных в базу так, что смежная грань записывается один раз. Данная модель имеет средний объем хранимой информации о геометрии около 36 атрибутов на ячейку.
Последовательность операций в данном случае будет следующей:
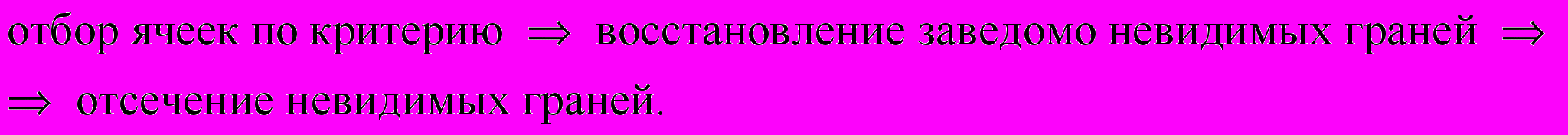 (3)
(3)Алгоритм (3) в отличие от алгоритма (2) не использует априорную информацию о форме ячеек и может использоваться в случае ячеек другой формы.
Предлагаемая модель хранения геометрии позволяет решить задачу исключения заведомо невидимых граней ячеек с использованием исключительно реляционных запросов вида:
select face_id, count(face_id) from face … where … having count(face_id) = 1 (4)
Выполнение подобных sql-запросов производится встроенными высокоэффективными процедурами с использованием индексов. Проведенные экспериментальные оценки на сервере с процессором P-IV 1.5 GHz, работающем под управлением Oracle 9.x., показывают время выполнения запроса (4) из массива граней, соответствующих 1 млн. ячеек, в диапазоне от 3 до 5-ти секунд.