Проект "пульс": (описание идеи)
| Вид материала | Программа |
- Программа «Школа волонтеров Пульс», 453.36kb.
- Проект посвящен вопросам эксплуатации кц-1 кс «Игринская», 23.57kb.
- Как начинается проект?, 59.12kb.
- Настоящий Проект перспективного развития школы на 2011-2015 годы продолжает основные, 711.77kb.
- Тематическое планирование уроков в 7 классе, 894.98kb.
- Описание современной модели доступного и качественного образования в Хабаровском крае, 55.82kb.
- Конкурс инновационных проектов «Новый Алтай», 29.46kb.
- Анализ требований к проекту сайта (см табл. 9) 18 Согласование выработанной идеи проекта, 590.25kb.
- В. А. Заботина Утверждаю Начальник своуо в. Г. Кобозева Положение конкурс, 38.14kb.
- Программа производства и сбыта Формирование каналов сбыта продукции. Разработка мероприятий, 1030.06kb.
Архитектура потоковой суперЭВМ, построенной на принципах схемной эмуляции.
Сравнительный анализ с известными архитектурами.
Еще раз подчеркну, что целью написания данной статьи есть стремление показать, что использование принципа схемной эмуляции в основе построения системы исполнения, обладает поразительной возможностью к развитию.
И проектирование систем автоматики от простейшей локальной системы до сложнейшей АСУ ТП масштабов предприятия из готовых аппаратно-программных "кубиков", не требующих от пользователя каких-либо знаний даже основ программирования, - это только начало. Притом, что здесь подразумевается уровень таких систем, создание которых традиционными способами потребовало бы немалых интеллектуальных усилий со стороны коллектива, как электронщиков, так и программистов.
Но даже более интересным является то, что предлагаемая к коммерциализации идея позволит проектировать системы принципиально нового уровня, реализация которых с использованием современной парадигмы программирования крайне затруднена или даже не возможна в полном объеме. И здесь, прежде всего, имеется в виду проектирования таких систем Искусственного Интеллекта, как систем понимания, баз знаний, Экспертных Систем и т.д.
Проектирование архитектур многопроцессорных вычислительных систем – это тоже именно та тема, в которой красота и функциональная мощь представляемой идеи раскрывается в полной мере. И это именно та тема, реализация которой традиционными методами уже обнаружила пределы своего развития.
Не вызывает сомнения, что уровень развития собственной базы суперЭВМ служит надежным барометром научно-технического уровня развития страны. Без суперкомпьютеров не возможна конкурентоспособность страны на мировом рынке. По всеобщему признанию, создание высокопроизводительных вычислительных систем входит первую десятку жизненно важных программ ведущих государств мира и определяет национальную безопасность и экономическую независимость государства. В настоящее время усилилось направление компьютерного моделирования и эксперимента, что позволяет форсировать продвижение научно-технической мысли в самых разнообразных отраслях знаний: материаловедении, экономике, биологии, физике, фармакологии, генетике, нанотехнологиях и т.д. Суперкомпьютеры нужны при разведке нефти и газа, предсказания погоды и глобальных климатических изменений, оптимизации транспортных потоков, решении задач аэрокосмической и автомобильной промышленности, энергетики термоядерного синтеза.
Время показало, что копирование западных технологий – путь бесперспективный, только оставляющий нам право пожизненно находится в роли догоняющих. В свою очередь, внедрять новые технологии под видом так любезно предоставляемых нам готовых инвестиционных проектов - значит "посадить" себя на "технологическую иглу" на длительный исторический период. Поэтому со всей уверенностью можно сказать, что только развитие и использование отечественного потенциала изобретений и ноу-хау есть путь единственно верный.
Целью данной статьи является популяризация авторской идеи использования принципов схемной эмуляции в основе системы графического программирования-исполнения. Идея является абсолютно оригинальной и не имеет аналогов в мире. И как я пытался показать – обладает уникальным потенциалом к развитию во многих областях знаний.
Таким образом, реализация (коммерциализация) проекта "Пульс" придаст мощный импульс к развитию таких направлений как системы автоматики, АСУ ТП, интеллектуальные системы и суперЭВМ. Что, в свою очередь, послужит надежной базой для качественного развития большого числа различных отраслей знаний, часть из которых уже перечислена. Это позволит Украине со всей справедливостью занять лидирующие позиции в мире в деле построения постиндустриальной державы, совершить качественный рывок в этом направлении. И это в то время, когда мы пока далеки еще даже от уровня развитого индустриального государства, имея пока имидж сырьевой базы для мировой экономической системы. Именно развитие собственных высокоинтеллектуальных и высокопроизводительных вычислительных систем способны стать локомотивом развития всей отечественной экономики. Другого пути просто нет.
Что касается вопроса применения моей идеи к теме Искусственного Интеллекта – то эта большая тема других статей. В данном же разделе я рассмотрю вопрос проектирования архитектуры суперЭВМ, в основу которой положена все та же идея графического исполнения. Но перед этим я приведу краткий обзор существующих, самых интересных на мой взгляд, архитектур. Делаю я это не с какой-то самоцелью, а чтобы именно в сравнительном анализе показать красоту идеи графического исполнения к вопросу проектирования принципиально новой вычислительной архитектуры.
Главные задачи для суперЭВМ – это операции над матрицами большой размерности, что есть ни что иное, как векторные вычисления. И поэтому было бы справедливо предположить, что основу современных суперЭВМ должны составлять именно векторные машины. На ранней стадии развития так и казалось, что наиболее простым решением проблемы могут стать специализированные векторные вычисления. Тем не менее, как прискорбно это не звучало бы, но за все десятилетия развития вычислительной техники по настоящему коммерческой машины подобного класса так и не появилось. Объяснение такому явлению можно найти в том, что архитектура подобной машины должна как можно ближе соответствовать виду решаемого алгоритма. Только вот алгоритмов оказалось слишком много для того, чтобы ухитриться сделать ее архитектуру универсальной.
Поэтому ни один из проектов так и не привел к коммерческой машине. Но результатом неудач стало понимание, что проблема параллельности значительно сложнее. И то, что основу любой задачи, даже самой векторной, все-таки составляют скалярные вычисления. Поэтому, чтобы по-настоящему решить проблему параллельности, следует решать задачу распараллеливания скалярных вычислений.
С другой стороны, результатом больших интеллектуальных усилий, направленных на разрешение проблемы скоростных вычислений, стало все более растущее понимание того, что главным препятствием на пути органичного решения проблемы становится сама идея, лежащая в основе всех современных компьютеров - так называемая архитектура фон Неймана.
I. Архитектура фон Неймана
Архитектура фон Неймана разрабатывалась в свое время для решения совершенно определенной задачи - обеспечения пользователя устройством с запоминаемой программой, предназначенным для выполнения вычислений с целью решения дифференциальных уравнений. И если учесть, что в современном программировании уже давно наблюдается ярко выраженная тенденция решения "не численных" задач, - остается только удивляться, что эта архитектура сохранилась до наших дней.
В то время, когда рабочие характеристики аппаратных средств современных ЭВМ обуславливаются основополагающими принципами модели фон Неймана - параметры программного обеспечения во многом зависят от языков программирования а, следовательно, от класса задач, подлежащих решению. Такая ситуация подпадает под определение феномена, известного как семантический разрыв. И вся нагрузка по уменьшению (заметьте – только по уменьшению!) такого разрыва ложится на компиляторы.
Вкратце приведу основные параметры такого разрыва.
♦ регистры процессора и модульность программ ♦
В частности, считается, что до 20% выполняемых операторов языка высокого уровня – это обращение к подпрограммам – процедурам и функциям.
Это приводит к тому, что эффект высокой скорости регистровых операций снижается стремлением современного программирования к достижению максимальной модульности, приводящей к дроблению каждой программы на большое количество отдельно компилируемых подпрограмм. Наличие большого числа прерываний процессов влечет за собой увеличение частоты загрузки регистров и записи их содержимого в память.
♦ рост объема программных кодов и ненадежность ПО ♦
Семантический разрыв отрицательно сказывается не только на эффективности работы машины, но и на размере программ: располагая ограниченным набором машинных команд для реализации возможностей языка программирования, компилятор вынужден генерировать, а машина интерпретировать большое число дополнительных машинных команд.
Объем машинных кодов, генерируемых компилятором с целью отражения концепции языка программирования высокого уровня в архитектуру используемой машины, обычно значительно превосходит объем кодов, предназначенных для непосредственно решения поставленной задачи.
Что трактуется как "абсорбирование" структуры (данных) в логике программы.
Анализ объектных кодов многочисленных исследований показывает, что до 70% команд перемещения данных между процессором и памятью – это команды подготовки к выполнению работ, предписываемых алгоритмом исходной задачи.
Вместе с тем, в созданном компилятором коде уже практически невозможно выявить соотношения между представлениями операторов программы на языке высокого уровня в самом объектном коде, что делает невозможным проведение какой-либо действенной диагностики на выявление ошибок.
♦ команды и данные ♦
Можно добавить как факт, негативно влияющий на надежность выполнения программ в архитектуре фон Неймана, - отсутствие явного различия между командами и данными. Их идентифицируют неявным способом при выполнении операций. Так, объект, адресуемый командой перехода, определяется как команда; операнды, с которыми имеет дело команда, определяются как данные.
Эти принимаемые по умолчанию соглашения позволяют, к примеру, обращаться с командой как с данными (в частности, модифицировать ее), складывать команду со словом данных или осуществлять переход к слову данных и выполнять его так, как будто биты этого слова представляют команду.
Все это нередко становится причиной сбоев в работе ПО и зависаний, например, при сбое в системе питания, которое может привести к случайному изменению значения Регистра Адреса.
В то же время, назначение данных, в архитектуре фон Неймана, не является их составной частью. Нет, например, никаких средств, позволяющих явно отличить набор битов, представляющих число с плавающей точкой, от набора битов, являющейся строкой символов.
Назначение данных определяется лишь логикой программы. Таким образом, можно заключить, что семантический разрыв существенно влияет на ненадежность программного обеспечения.
♦ параллелизм ♦
Еще одним следствием наличия семантического разрыва выступает несоответствие архитектуры самого процессора с принципами параллелизма операций. Располагая только ограниченным набором машинных команд, конструктор не способен найти применение такому принципу, кроме как частично перекрывать во времени выполнение последовательности команд.
К тому же, параллелизм на уровне команд, который можно найти в потоке команд традиционного компьютера, ограничен. Исследования показали пределы использования процессора даже для суперскалярных микропроцессоров. К примеру, на тесте SPEC92 микропроцессор PowerPC 620 показал, что в среднем исполняется от 0,96 до 1,77 команд за один такт, а 8-ми входовый процессор Alpha не смог исполнить 1,55 команд за такт. К тому же, зависимости по данным и управлению потенциально являются причиной сбоев конвейера микропроцессоров, в которых управление реализовано с помощью сложной логики продвижения команд
♦ мультипроцессорная обработка ♦
Решение мультипроцессорной обработки приводит лишь к частичному успеху из-за проблем, возникающих при ее реализации (перекрытия областей памяти, сложность синхронизации и т.п.), и непосредственно проблем программирования.
Согласно гипотезе Минского (Minsky), ускорение, достигаемое при использовании параллельной системы, пропорционально двоичному логарифму от числа процессоров. То есть, при использовании 1000 процессоров на одной платформе возможное ускорение оказывается равным всего 10 (!).
Другая существенная проблема – трудность декомпозиции задачи на параллельно решаемые подзадачи и сложность реализации в компиляторах средств обнаружения в программах последовательностей команд, подлежащих параллельному выполнению.
Разработчики микропроцессорных кристаллов, путем все большего усложнения регистровых структур, конечно же, пытаются выжать все возможное из исходной архитектуры. Полезность подобных модификаций очевидна. Но кэширование и прочие изменения канонической модели, и даже многопроцессорность, - это лишь полумеры, подтверждающие, что рост быстродействия последовательных ЭВМ, даже устроенных по принципу параллельной структуры, не может продолжаться бесконечно.
I - I. Архитектура многопроцессорной ЭВМ с жесткими связями
К данному классу машин можно отнести однородные многопроцессорные вычислительные структуры (МВС) с общей оперативной памятью и постоянными ("жесткими") межпроцессорными связями.
Казалось бы, что может быть проще: превратить одно процессорную машину в много-процессорную путем добавления на платформу еще нескольких точно таких же процессоров, а то и нескольких десятков (?!). Действительно, с точки зрения электроники это не вызовет каких-либо проблем. Однако на практике, добавление нового процессора в систему может не только увеличить общую производительность, но напротив – даже уменьшить ее. Ведь в этом случае приходится сталкиваться с принципиально новым явлением: информационным и алгоритмическим взаимодействием процессоров. А эффект такого взаимодействия, при некоторых обстоятельствах, может сделать даже двухпроцессорную машину медленнее однопроцессорной.
Важным аспектом, связанным с эффективностью работы машины, выступает организация межпроцессороного обмена информационными и служебными потоками. Ведь для повышения быстродействия каждого процессора необходимо создавать сверхоперативную локальную память, в которую на определенное время копируются необходимые данные из общей для всех процессоров оперативной памяти. При параллельной работе с общими для нескольких процессоров данными эта информация может оказаться продублированной в нескольких кешах. Это, в свою очередь, приводит к возникновению проблемы когерентности кэш-памяти – поддержание в процессе изменения идентичности всех территориально разнесенных копий информации. Поток взаимных обращений резко растет с ростом числа процессоров, что снижает эффективность кэш-памяти, увеличивая тем самым накладные расходы для всей системы. В конце-концов это приводит к тому, что время подготовки к параллельным вычислениям ставит под сомнение саму обработку. Все это привело к тому, что машины с подобной архитектурой "живучи" при числе процессоров не более, чем в десяток-другой штук.
С другой стороны, для эффективного разрешения проблемы в новую архитектуру необходимо добавить глубоко продуманную аппаратно-программную систему синхронизации работы процессоров. А система управления командами должна иметь достаточно большую размерность, чтобы одновременно управлять несколькими арифметическими устройствами. Это позволит программисту (транслятору) распараллеливать явно параллельные как векторные, так и скалярные выражения.
Чтобы использовать появившееся большое число арифметических устройств, для возможного распараллеливания счета, потребовалось, во-первых, аппаратно просматривать вперед множество команд; во-вторых, динамически планировать загрузку устройств, с учетом информационной зависимости команд, неявно скрытой в последовательной программе. Причина введения динамического управления – это обеспечение параллельного исполнения программы, записанной программистом последовательно. В результате на аппаратуру возлагается задача отыскания таких мест в программе, которые можно было бы распалаллелить на уровне арифметических устройств.
В свою очередь, это может нарушить естественный ход записи команд, потому что при динамическом управлении аппаратура фактически исполняет программу не в той последовательности, в которой она записана. При этом может получиться так, что программист какой-либо командой записал информацию в ячейку памяти или регистр и следующей командой он рассчитывает получить там ее обновленное значение. Однако если аппаратуре удобно начать исполнение какой-либо последующей команды вместе с текущей, то на вход этой команды поступит еще старое содержимое памяти. При этом, наличие условных ветвей в программе значительно снижают эффект использования механизма "заглядывания вперед".
Использование механизмов заглядывания вперед и динамического планирования настолько усложнили аппаратуру, что даже сделало невозможным ассемблерное программирование на таких машинах. И в этом смысле справедливо будет сказать, что архитектуры современных МВС "заточены" исключительно под парадигму современного программирования.
Вот почему МВС с "жесткой" архитектурой имеют органический недостаток: каждая из архитектур имеет наибольшую производительность только для узкого класса задач, которая называется пиковой. При решении задач других классов производительность той же системы может падать на порядок-два.
I - II. Архитектура кластерных структур
Как известно, суперЭВМ слишком дороги. В свою очередь, жизнь потребовала быстрой альтернативы. Вот так и появились кластеры. СуперЭВМ с кластерной архитектурой представляют собой объединение множества традиционных коммерчески доступных процессорных узлов с помощью стандартных сетевых решений. Кластер это множество серверов объеденных в сеть и работают над одной задачей. Объединение серверов в кластер реализуется программно. Существует менеджер кластеров. Устанавливается на основной сервер и управляет всеми остальными узлами кластера. Клиентское программное обеспечение устанавливается на остальные серверы кластера.
Системы данного класса имеют существенные недостатки, связанные с относительно низкой скоростью выполнения процедур межпроцессорного обмена, ограниченного пропускной способностью сети, необходимостью синхронизации взаимосвязанных процессов, каждый из которых выполняется на отдельном процессоре и т.д.
Все это приводит к тому, что реально высокую производительность кластерные суперЭВМ демонстрируют только на решении слабо связанных задач, не требующих интенсивного обмена данными между процессорными узлами. В то время, как при решении сильно связанных задач их реальная производительность не превышает 5-10% от декларируемой пиковой производительности. При этом, увеличение числа процессорных узлов в системе, зачастую приводит даже к снижению производительности всей системы, когда организация параллельного вычислительного процесса начинает требовать уже большего времени, чем непосредственно его исполнение.
К тому же, организация большого числа платформ в единую структуру требует разработки сложнейшего программного обеспечения, зачастую граничащего с уровнем know-how.
II. Архитектура реконфигурируемых вычислительных структур *
Очевидно, что создание высокопроизводительных вычислительных систем входит в число важнейших программ ведущих государств мира. Без суперкомпьютеров невозможно обеспечить конкурентоспособность страны на мировом рынке, проводить современные научные изыскания в самых различных областях знаний.
Как бы не показалось странным на первый взгляд, но вычислительная мощность компьютерных систем за время их существования выросла, главным образом, далеко не за счет технологического развития. Ведь если со времен первых компьютеров (EDSAC, Кембридж, 1949 год) и до наших дней (суперкомпьютер Hewlett-Packard V2600) время такта выросло с 2 микросекунд до 1,8 наносекунды и прирост составил 1000 раз, то производительность выросла, соответственно, со 100 арифметических операций в секунду до 77 миллиардов. Прирост составляет более чем семьсот миллионов раз. Откуда же тогда взялась такая существенная разница? Ответ очевиден – от использования новых решений в архитектуре компьютеров.
Тем не менее, в настоящее время все отчетливее зреет понимание того, что и развитие архитектурных решений, основанных на принципах фон Неймана, близко к своему пределу. К тому же, эффективно использовать все более усложняющиеся системы становится труднее.
Любой мультипроцессорной архитектуре с жесткими межпроцессорными связями присущ один и тот же органический недостаток: наивысшей производительности, близкой к пиковой, она способна достичь только для какого-то узкого класса задач. И производительность которой имеет свойство падать, уменьшаясь на порядок-два, для задач других классов.
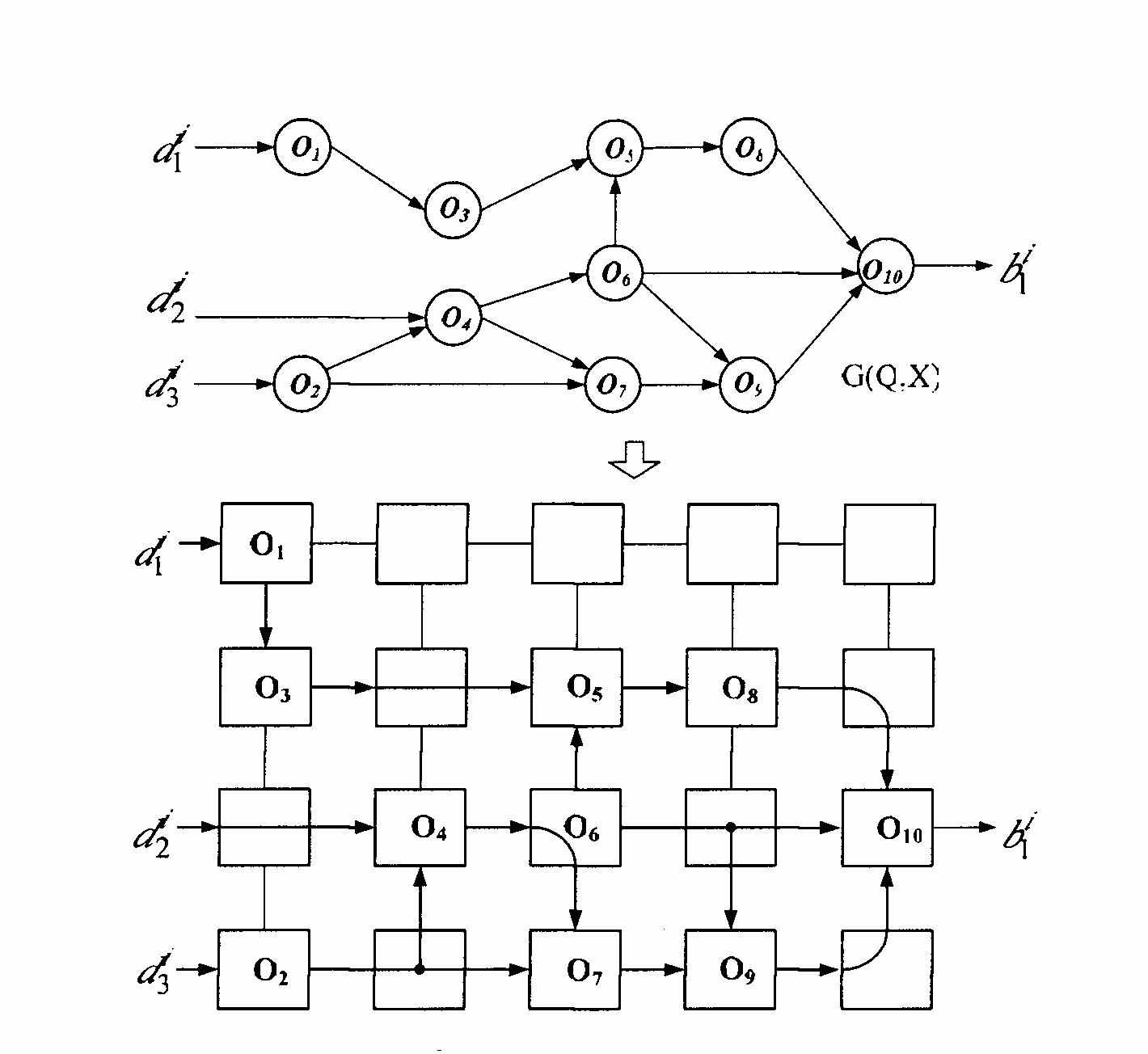
Эта проблема имеет системный характер и является следствием неадекватности каждой конкретной архитектуры вычислительной системы внутренней структуре решаемой задачи. Вообще говоря, любую задачу пользователя можно представить системой S, процессы в которой описаны формой информационного графа (рис. 10а). Граф G(Q,X) содержит множество вершин gi
 Q, каждой из которых приписана некоторая операция Oi, принадлежащая множеству допустимых операций O.
Q, каждой из которых приписана некоторая операция Oi, принадлежащая множеству допустимых операций O. Дуги графа определяют последовательность выполнения операций, приписанных вершинам. Множество входных дуг определяют источник входных данных, выходных – приемник результатов решения.
Дуги графа определяют последовательность выполнения операций, приписанных вершинам. Множество входных дуг определяют источник входных данных, выходных – приемник результатов решения. При исполнении задачи S в среде мультипроцессорной системы (S*), в последней организуется вычислительный процесс, который можно описать информационным графом G*(Q*,X*). Здесь множество вершин Q* определяется множеством процессоров вычислительной системы, а множество дуг X* представляет собой множество каналов коммуникаций между процессорами. В свою очередь, входные и выходные дуги определяются каналами связи с источником входных и приемником выходных данных.
Как правило, графы G и G* существенно отличаются один от другого. Объяснение этому можно найти в том, что жесткая архитектура многопроцессорной вычислительной системы S* в большинстве случаев значительно отличается от структуры пользовательской задачи S. В результате, системой S* приходится организовывать некоторый мультипроцедурный процесс, который моделирует систему S, но структурно с ней не совпадает. Результатом такого моделирования становится то, что граф G* оказывается намного сложнее, чем исходный граф G. Все это приводит к существенным потерям времени за счет операций распределения заданий и процедур между процессорами вычислительной системы, очередей, конфликтов и т.д.
Указанного недостатка вычислительной системы с "жесткой" архитектурой можно избежать, если обеспечить возможность ее реконфигурации таким образом, чтобы граф G* вычислительного процесса как можно ближе совпадал с графом G решаемой задачи.
Назревающий кризис толкает исследователей на поиск принципиально новых архитектурных решений, основанных на нефоннеймановских принципах, которые отличались бы логической простотой и регулярностью, пусть даже за счет увеличения общего объема оборудования. При этом усилия части исследователей и разработчиков сосредоточились на проектировании матричных структур с изменяемыми межпроцессорными связями – так называемых реконфигурируемых вычислительных структурах (РВС), которые должны обеспечить высокую производительность вычислительной системы на уровне пиковой для широкого класса задач, а также линейный рост производительности при увеличении числа процессоров в системе.
Суть концепции РВС в том и заключается, чтобы архитектура вычислительной системы имела возможность адаптироваться под структуру решаемой задачи. В отличие от многопроцессорных вычислительных систем с жесткими межпроцессорными связями, а также кластерных систем, архитектура связей реконфигурируемых вычислителей может изменяться в процессе их функционирования. В результате у пользователя появляется возможность адаптации архитектуры вычислительной системы под структуру решаемой задачи. В качестве наиболее подходящей среды реализации идеи используются микросхемы программируемой логики (ПЛИС), как устройств наивысшей степени параллельного действия, известных на сегодняшний день. К тому же применение ПЛИС обеспечивает ускорение вычислительного процесса по сравнению с микропроцессором от 5 до 100 раз вследствие адаптации внутренней вычислительной структуры к информационной структуре решаемой задачи.
Можно сказать, что идея РВС в настоящее время завоевывает все большее число сторонников и более того, воспринимается многими именно той "фишкой", которая ляжет в основу архитектуры ЭВМ нового типа. Тем не менее, как на мой взгляд, "всенародная любовь" эта является скорее вынужденной, что можно объяснить просто отсутствием должной альтернативы, чем совершенством имеющегося метода. Потому как у изначально красивой идеи, на этапе реализации обнаружилось немало системных проблем.
Поэтому показательным выглядит то, что несмотря на большое число исследований в области реконфигурируемых структур, они до сих пор так и не нашли широкого применения. В том числе это объясняется специфичностью и достаточной сложностью программирования таких систем, наличием нестандартных и сложнейших средств программирования, а также требованием к нестандартному мышлению программиста. Процесс разработки реконфигурируемых структур трудоемкий, требующий от пользователя больших временных затрат, а также специальных знаний и, по сути, квалификации схемотехника. По степени сложности программирование РВС сопоставимо с разработкой новой вычислительной среды. Отчего использование таких систем для решения часто меняющихся задач оказывается малоэффективным.
В то же время, преимущество идеи реконфигурирования в полной мере проявилось пока на решениях только некоторых классов параллельных задач, таких как потоковые, в которых большие массивы данных обрабатываются по одному и тому же алгоритму – обработки сигналов, криптографии и т.п. Так что о широком классе решаемых задач говорить пока тоже рановато. В особенности, если учесть, что современные приложения зачастую образуют сложную иерархию параллельно-последовательных процессов, да еще и меняющихся во времени.
Таким образом, регулярность вычислительной структуры еще не является залогом ее высокой производительности на широком классе задач. Необходимым условием следует считать также возможность ее реконфигурации, чтобы граф G* вычислительного процесса как можно ближе совпадал с графом G решаемой задачи.
Суть концепции РВС в том и заключается, чтобы архитектура вычислительной системы имела возможность адаптироваться под структуру решаемой задачи. В отличие от многопроцессорных вычислительных систем с жесткими межпроцессорными связями, а также кластерных систем, архитектура связей реконфигурируемых вычислителей может изменяться в процессе их функционирования. В результате у пользователя появляется возможность адаптации архитектуры вычислительной системы под структуру решаемой задачи.
В отличие от традиционных методов организации параллельных вычислений РВС ориентируются на абсолютно параллельную форму алгоритма задачи – ее информационный граф. Под информационным графом понимается граф, вершинам которого соответствуют арифметико-логические операции над операндами. Дуги информационного графа соответствуют информационной зависимости между вершинами и, по сути, определяют порядок соединения вычислителей.
Таким образом, идея концепции РВС заключается в аппаратной реализации всех операций, предписанных вершинами информационного графа, и всех каналов передачи данных между вершинами, соответствующих дугам графа. Такое решение задачи принято называть структурным.
Наиболее наглядно идею РВС можно продемонстрировать на примере т.н. однородной мультимикроконвейерной вычислительной среды, представляющую собой матрицу однотипных (как правило однобитных) процессоров.
Суть этого подхода заключается в создании мультиконвейера с жесткой архитектурой и обеспечении коммутационных возможностей за счет придания каждому процессору дополнительных функций транзитной передачи информации. В такую структуру можно отобразить любой граф алгоритма G(Q,X), как показано на рис. 10
При этом, как можно заметить из рисунка, часть процессоров будет занята неэффективной работой транзита входной информации к другим узлам структуры, а часть процессоров не будут заняты никакими процессами вообще. К тому же, транзит информации через процессоры вносит дополнительные временные задержки при прохождении данных через мультиконвейер, снижая тем самым темп конвейерной обработки. Кроме того, процесс отображения исходного графа в матричную структуру с жесткой архитектурой является нетривиальной задачей. Очевидным есть и то, что в такой структуре невозможно поместить граф реальной задачи, состоящий из сотен, тысяч и миллионов вершин. Эффективность рассматриваемой архитектуры можно было бы увеличить, применив полнодоступный коммутатор, обеспечивающий возможность полнодоступной коммутации между всеми процессорами мультимикроконвейера. Однако, аппаратные затраты на его реализацию будут недопустимо велики, потому как пропорциональны квадрату числа процессоров.