
Курс лекций Часть I автор: Крапивина И. В. Валуйки 2008
| Вид материала | Курс лекций |
- Г. Валуйки Белгородской области, 647.06kb.
- Курс лекций часть 2 Тюмень 2006 удк 159 01 Михеева Е. М., Фалько Г. В. Психология:, 2034.37kb.
- Курс лекций для студентов идпо специальностей «Юриспруденция», 3911.79kb.
- Курс лекций для студентов идпо специальностей «Юриспруденция», 2986.57kb.
- Курс лекций Часть II учебное пособие рпк «Политехник» Волгоград, 1175.06kb.
- Курс лекций Часть 2 Составитель: кандидат экономических наук Г. Н. Кудрявцева Электроизолятор, 1210.68kb.
- М. К. Мамардашвили Современная европейская философия (XX век) Курс лекций, 421.49kb.
- Краткий курс лекций по медицинской паразитологии Часть Клещи, 643.33kb.
- Курс лекций по дисциплине история экономических учений москва 2008, 5434.7kb.
- Курс лекций москва 2008, 1185.38kb.
3.4. Арифметические операции в позиционных системах счисления
| Арифметические операции в рассматриваемых позиционных системах счисления выполняются по законам, известным из десятичной арифметики. Двоичная система счисления имеет основание 2, и для записи чисел используются всего две цифры 0 и 1 в отличие от десяти цифр десятичной системы счисления. 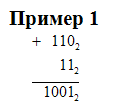 Рассмотрим сложение одноразрядных чисел: 0+0=0, 0+1=1, 1+0=0. Эти равенства справедливы как для двоичной системы, так и для десятичной системы. Чему же равно 1+1? В десятичной системе это 2. Но в двоичной системе нет цифры 2! Известно, что при десятичном сложении 9+1 происходит перенос 1 в старший разряд, так как старше 9 цифры нет. То есть 9+1=10. В двоичной системе старшей цифрой является 1. Следовательно, в двоичной системе 1+1=10, так как при сложении двух единиц происходит переполнение разряда и производится перенос в старший разряд. Переполнение разряда наступает тогда, когда значение числа в нем становится равным или большим основания. Для двоичной системы это число равно 2 (102=210). Рассмотрим сложение одноразрядных чисел: 0+0=0, 0+1=1, 1+0=0. Эти равенства справедливы как для двоичной системы, так и для десятичной системы. Чему же равно 1+1? В десятичной системе это 2. Но в двоичной системе нет цифры 2! Известно, что при десятичном сложении 9+1 происходит перенос 1 в старший разряд, так как старше 9 цифры нет. То есть 9+1=10. В двоичной системе старшей цифрой является 1. Следовательно, в двоичной системе 1+1=10, так как при сложении двух единиц происходит переполнение разряда и производится перенос в старший разряд. Переполнение разряда наступает тогда, когда значение числа в нем становится равным или большим основания. Для двоичной системы это число равно 2 (102=210). |
| Продолжая добавлять единицы, заметим: 102+1=112, 112+1=1002 - произошла "цепная реакция", когда перенос единицы в один разряд вызывает перенос в следующий разряд. Сложение многоразрядных чисел происходит по этим же правилам с учетом возможности переносов из младших разрядов в  старшие. старшие.Вычитание многоразрядных двоичных чисел производится с учетом возможных заёмов из старших разрядов. Действия умножения и деления чисел в двоичной арифметике можно выполнять по общепринятым для позиционных систем правилам. |
| В  основе правил арифметики любой позиционной системы лежат таблицы сложения и умножения одноразрядных чисел. основе правил арифметики любой позиционной системы лежат таблицы сложения и умножения одноразрядных чисел. |
Для двоичной системы счисления:

Аналогичные таблицы составляются для любой позиционной системы счисления. Пользуясь такими таблицами, можно выполнять действия над многозначными числами.
Пример 4. Выполнить действия в пятеричной системе счисления: 3425+235; 2135.55.
Решение
Составим таблицы сложения и умножения для пятеричной системы счисления:

Выполним сложение.


Рассуждаем так: два плюс три равно 10 (по таблице); 0 пишем, 1 - в уме. Четыре плюс два равно 11 (по таблице), да еще один, 12. 2 пишем, 1 - в уме. Три да один равно 4 (по таблице). Результат - 420.
Выполним умножение.
Рассуждаем так: трижды три - 14 (по таблице); 4 пишем, один - в уме. Трижды один дает 3, да плюс один, - пишем 4. Дважды три (по таблице) - 11; 1 пишем, 1 переносим влево. Окончательный результат - 1144.
Если числа, участвующие в выражении, представлены в разных системах, нужно сначала привести их к одному основанию.
Пример 5. Сложить два числа: 178 и 1716.
Решение
Приведем число 1716 к основанию 8 посредством двоичной системы (пробелами условно обозначено деление на тетрады и триады): 1716=101112=101112=278.
Выполним сложение в восьмеричной системе:

Сделаем проверку, выполнив те же действия в десятичной системе:

Пример 6. Вычислить выражение , записав результат в двоичной системе счисления.
Решение
Приведем числа, участвующие в выражении, в единую систему счисления, например, десятичную:

Выполним указанные действия:
23-81/27=2010.
Запишем результат в двоичной системе счисления: 2010=101002.
Таким образом, арифметические действия в позиционных системах счисления выполняются по общим правилам. Необходимо только помнить, что перенос в следующий разряд при сложении и заем из старшего разряда при вычитании определяются величиной основания системы счисления.
Вопросы для самоконтроля
- Что такое система счисления? Алгоритм перевода из десятичной в недесятичную систему счисления. Примеры.
- Что такое позиционная система счисления? Алгоритм перевода из недесятичной в десятичную систему счисления. Пример. Суммирование в недесятичной системе счисления. Примеры.
- Что такое непозиционная система счисления? Умножение и деление в недесятичной системе счисления. Примеры.
3.5. Кодирование информации
Теория кодирования информации является одним из разделов теоретической информатики. К основным задачам, решаемым в данном разделе, необходимо отнести следующие:
- разработка принципов наиболее экономичного кодирования информации;
- согласование параметров передаваемой информации с особенностями канала связи;
- разработка приемов, обеспечивающих надежность передачи информации по каналам связи, т.е. отсутствие потерь информации.
Как отмечалось при рассмотрении исходных понятий информатики, для представления дискретной информации используется некоторый алфавит. Однако однозначное соответствие между информацией и алфавитом отсутствует. Другими словами, одна и та же информация может быть представлена посредством различных алфавитов. В связи с такой возможностью возникает проблема перехода от одного алфавита к другому, причем, такое преобразование не должно приводить к потере информации. Условимся называть алфавит, с помощью которого представляется информация до преобразования, первичным; алфавит конечного представления – вторичным.
Введем ряд с определений:
Код – (1) правило, описывающее соответствие знаков или их сочетаний одного алфавита знакам или их сочетаниям другого алфавита.
(2) знаки вторичного алфавита, используемые для представления знаков или их сочетаний первичного алфавита.
Кодирование – перевод информации, представленной посредством первичного алфавита, в последовательность кодов.
Декодирование – операция, обратная кодированию, т.е. восстановление информации в первичном алфавите по
полученной последовательности кодов.
Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без каких-либо ее потерь.
Примером обратимого кодирования является представление знаков в телеграфном коде и их восстановление после передачи. Примером кодирования необратимого может служить перевод с одного естественного языка на другой – обратный перевод, вообще говоря, не восстанавливает исходного текста. Безусловно, для практических задач, связанных со знаковым представлением информации, возможность восстановления информации по ее коду является необходимым условием применения кода, поэтому в дальнейшем изложении ограничим себя рассмотрением только обратимого кодирования.
Таким образом, кодирование предшествует передаче и хранению информации. При этом, как указывалось ранее, хранение связано с фиксацией некоторого состояния носителя информации, а передача – с изменением состояния с течением времени (т.е. процессом). Эти состояния или сигналы будем называть элементарными сигналами – именно их совокупность и составляет вторичный алфавит.
Не обсуждая технических сторон передачи и хранения сообщения (т.е. того, каким образом фактически реализованы передача-прием последовательности сигналов или фиксация состояний), попробуем дать математическую постановку задачи кодирования.
Пусть первичный алфавит A содержит N знаков со средней информацией на знак, определенной с учетом вероятностей их появления, I1(A) (нижний индекс отражает то обстоятельство, что рассматривается первое приближение, а верхний индекс в скобках указывает алфавит). Вторичный алфавит B пусть содержит M знаков со средней информационной емкостью I1(A). Пусть также исходное сообщение, представленное в первичном алфавите, содержит n знаков, а закодированное сообщение – m знаков. Если исходное сообщение содержит I(A) информации, а закодированное – I(B), то условие обратимости кодирования, т.е. неисчезновения информации при кодировании, очевидно, может быть записано следующим образом:
I(A)
 I(B), смысл которого в том, что операция обратимого кодирования может увеличить количество формальной информации в сообщении, но не может его уменьшить. Однако каждая из величин в данном неравенстве может быть заменена произведением числа знаков на среднюю информационную емкость знака, т.е.:
I(B), смысл которого в том, что операция обратимого кодирования может увеличить количество формальной информации в сообщении, но не может его уменьшить. Однако каждая из величин в данном неравенстве может быть заменена произведением числа знаков на среднюю информационную емкость знака, т.е.:
Отношение m/n, очевидно, характеризует среднее число знаков вторичного алфавита, которое приходится использовать для кодирования одного знака первичного алфавита – будем называть его длиной кода или длиной кодовой цепочки и обозначим K(B) (верхний индекс указывает алфавит кодов).
В частном случае, когда появление любых знаков вторичного алфавита равновероятно, согласно формуле Хартли I1(B)=log2M, и тогда

(1.1)
По аналогии с величиной R, характеризующей избыточность языка, можно ввести относительную избыточность кода (Q):

(1.2)
Данная величина показывает, насколько операция кодирования увеличила длину исходного сообщения. Очевидно, чем меньше Q (т.е. чем ближе она к 0 или, что то же, I(B) ближе к I(A)), тем более выгодным оказывается код и более эффективной операция кодирования. Выгодность кодирования при передаче и хранении – это экономический фактор, поскольку более эффективный код позволяет затратить на передачу сообщения меньше энергии, а также времени и, соответственно, меньше занимать линию связи; при хранении используется меньше площади поверхности (объема) носителя. При этом следует сознавать, что выгодность кода не идентична временнóй выгодности всей цепочки кодирование – передача – декодирование; возможна ситуация, когда за использование эффективного кода при передаче придется расплачиваться тем, что операции кодирования и декодирования будут занимать больше времени и иных ресурсов (например, места в памяти технического устройства, если эти операции производятся с его помощью).
Выражение (1.1) пока следует воспринимать как соотношение оценочного характера, из которого неясно, в какой степени при кодировании возможно приближение к равенству его правой и левой частей. По этой причине для теории связи важнейшее значение имеют две теоремы, доказанные Шенноном. Первая – ее мы сейчас рассмотрим – затрагивает ситуацию с кодированием при передаче сообщения по линии связи, в которой отсутствуют помехи, искажающие информацию. Первая теорема Шеннона о передаче информации, которая называется также основной теоремой о кодировании при отсутствии помех, формулируется следующим образом:
При отсутствии помех передачи всегда возможен такой вариант кодирования сообщения, при котором среднее число знаков кода, приходящихся на один знак кодируемого алфавита, будет сколь угодно близко к отношению средних информаций на знак первичного и вторичного алфавитов.
Используя понятие избыточности кода, можно дать более короткую формулировку теоремы:
При отсутствии помех передачи всегда возможен такой вариант кодирования сообщения, при котором избыточность кода будет сколь угодно близкой к нулю.
Данные утверждения являются теоремами и, следовательно, должны доказываться. Мы опустим его, адресовав интересующихся именно доказательной стороной к книге А.М. и И.М.Ягломов. Для нас важно, что теорема открывает принципиальную возможность оптимального кодирования. Однако необходимо сознавать, что из самой теоремы никоим образом не следует, как такое кодирование осуществить практически – для этого должны привлекаться какие-то дополнительные соображения, что и станет предметом нашего последующего обсуждения.
Далее в основном ограничим себя ситуацией, когда M = 2, т.е. для представления кодов в линии связи используется лишь два типа сигналов – с практической точки зрения это наиболее просто реализуемый вариант (например, существование напряжения в проводе (будем называть это импульсом) или его отсутствие (пауза); наличие или отсутствие отверстия на перфокарте или намагниченной области на дискете); подобное кодирование называется двоичным. Знаки двоичного алфавита принято обозначать «0» и «1», но нужно воспринимать их как буквы, а не цифры. Удобство двоичных кодов и в том, что при равных длительностях и вероятностях каждый элементарный сигнал (0 или 1) несет в себе 1 бит информации (log2M = 1); тогда из (1.1), теоремы Шеннона:
I1(A)
 K(2)
K(2)и первая теорема Шеннона получает следующую интерпретацию:
При отсутствии помех передачи средняя длина двоичного кода может быть сколь угодно близкой к средней информации, приходящейся на знак первичного алфавита.
Применение формулы (1.2) для двоичного кодирования дает:
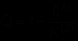
(1.3)
Определение количества переданной информации при двоичном кодировании сводится к простому подсчету числа импульсов (единиц) и пауз (нулей). При этом возникает проблема выделения из потока сигналов (последовательности импульсов и пауз) отдельных кодов. Приемное устройство фиксирует интенсивность и длительность сигналов. Элементарные сигналы (0 и 1) могут иметь одинаковые или разные длительности. Их количество в коде (длина кодовой цепочки), который ставится в соответствие знаку первичного алфавита, также может быть одинаковым (в этом случае код называется равномерным) или разным (неравномерный код). Наконец, коды могут строиться для каждого знака исходного алфавита (алфавитное кодирование) или для их комбинаций (кодирование блоков, слов). В результате при кодировании (алфавитном и словесном) возможны следующие варианты сочетаний:
| | Длительности элементарных сигналов | | Кодировка первичных символов (слов) |
| (1) | одинаковые | | равномерная |
| (2) | одинаковые | | неравномерная |
| (3) | разные | | равномерная |
| (4) | разные | | неравномерная |
В случае использования неравномерного кодирования или сигналов разной длительности (ситуации (2), (3) и (4)) для отделения кода одного знака от другого между ними необходимо передавать специальный сигнал – временной разделитель (признак конца знака) или применять такие коды, которые оказываются уникальными, т.е. несовпадающими с частями других кодов. При равномерном кодировании одинаковыми по длительности сигналами (ситуация (1)) передачи специального разделителя не требуется, поскольку отделение одного кода от другого производится по общей длительности, которая для всех кодов оказывается одинаковой (или одинаковому числу бит при хранении).
Длительность двоичного элементарного импульса (
 ) показывает, сколько времени требуется для передачи 1 бит информации. Очевидно, для передачи информации, в среднем приходящейся на знак первичного алфавита, необходимо время
) показывает, сколько времени требуется для передачи 1 бит информации. Очевидно, для передачи информации, в среднем приходящейся на знак первичного алфавита, необходимо время 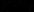 . Таким образом, задачу оптимизации кодирования можно сформулировать в иных терминах: построить такую систему кодирования, чтобы суммарная длительность кодов при передаче (или суммарное число кодов при хранении) данного сообщения была бы наименьшей.
. Таким образом, задачу оптимизации кодирования можно сформулировать в иных терминах: построить такую систему кодирования, чтобы суммарная длительность кодов при передаче (или суммарное число кодов при хранении) данного сообщения была бы наименьшей.3.6. Кодирование целых чисел
3.6.1.Кодирование и обработка в компьютере целых чисел без знака
Будем исходить из того, что для записи числа в устройствах компьютера выделяется фиксированное количество двоичных разрядов. Память компьютера имеет байтовую структуру, однако, размер одной адресуемой ячейки обычно составляет несколько байт. Например, в компьютерах IBM ячейка памяти объединяет 2 байта (16 двоичных разрядов) - такая комбинация связанных соседних ячеек, обрабатываемая совместно, называется машинным словом. Для представления числа в регистре арифметико-логического устройства процессора, где формируется результат операции, имеется еще один дополнительный одноразрядный регистр, который называется регистром переноса и который можно рассматривать в качестве продолжения (т.е. 17-го бита) регистра результата. Назначение этого бита выяснится чуть позже.
Конечный размер разрядной сетки порождает понятие «наибольшее целое число», которого в обычном (немашинном) представлении чисел просто не существует. Если количество разряд ов k и p=2, то (Z2)max = 2k - 1. В частности, при k=16 (Z2)max = 216 - 1 = 1111111111111112 =6553510. Другими словами, целого числа, скажем, 65636 и более в компьютере просто не может существовать и, следовательно, появление в ходе вычислений чисел, превышающих (Z2)max, должно интерпретироваться как ошибка. Минимальным целым числом в беззнаковом представлении, очевидно, является (Z2)min = 0000000000000002 = 010. В языке программирования PASCAL целые числа без знака, для записи которых отводится 2 байта, определены как тип Word. Тип устанавливает способ кодирования числа, количество отводимых для записи ячеек памяти (т.е. разрядность числа), а также перечень допустимых операций при обработке. Выход за границу 65535 возможен только путем увеличения количества разрядов для записи числа, но это порождает новый тип со своим Zmax; например, тип Longint1 с максимальным значением 214748364710, числа которого занимают 4 байта.
Рассмотрим, как с беззнаковыми числами выполняются арифметические операции, не меняющие типа числа; очевидно, к ним относятся сложение и умножение.
Сложение производится согласно таблице сложения, которая для двоичных чисел имеет вид:

В последнем случае в том разряде, где находились слагаемые, оказывается 0, а 1 переносится в старший разряд. Место, где сохраняется переносимая в старший разряд 1 до того, как она будет использована в операции, называется битом переноса.
Пример 1.
Найти сумму 159410 + 1756310 при беззнаковой двоичной кодировке и 16-битном машинном слове. После перевода слагаемых в двоичную систему счисления и выполнения сложения получим (для удобства восприятия 16-ти разрядное число разобьем на группы по четыре разряда):

Пример 2.
Найти сумму 6553410 + 310

В последнем примере в результате сложения получилось число, превышающее максимально возможное; результат ошибочен, о чем свидетельствует появление 1 в регистре переполнения. Возникновение такой ситуации в ходе выполнения программы, написанной на языке, где предусмотрено строгое описание типа переменных, приводит к прекращению работы и выводу сообщения об ошибке. В программах, предназначенных для обработки числовой информации (например, Excel, MathCAD или Calc), при переполнении разрядной сетки производится автоматическое преобразование целого числа в вещественный тип. Таким образом, регистр переноса в данном случае служит индикатором корректности процесса вычислений.
Умножение производится согласно таблице умножения, которая для двоичных чисел имеет предельно простой вид:
0 · 0 = 0
0 · 1 = 0
1 · 0 = 0
1 · 1 = 1
Пример 3.
Найти произведение 1310 × 510

Таким образом, умножение двоичных чисел сводится к операциям сдвига на один двоичный разряд влево и повторения первого сомножителя в тех разрядах, где второй сомножитель содержит 1, и сдвига без повторения в разрядах с 0. Сдвиг всегда чередуется со сложением из-за ограниченности числа регистров, которые имеются в процессоре для размещения операндов. Другими словами, реализации отдельной операции умножения в процессоре не требуется.
Как и в операции сложения, при умножении чисел с ограниченной разрядной сеткой может возникнуть переполнение. Решается проблема рассмотренными выше способами.
3.6.2. Кодирование и обработка в компьютере целых чисел со знаком
Кодирование целых чисел, имеющих знак, можно осуществить двумя способами. В первом варианте один (старший) разряд машинном слове отводится для записи знака числа; при этом условились кодировать знак «+» нулем, знак «–» - единицей. Под запись самого числа, очевидно, остается 15 двоичных разрядов, что обеспечивает наибольшее значение числа Zmax = 215 - 1 = 3276710. Такое представление чисел называется прямым кодом. Однако его применение усложняет порядок обработки чисел; например, операция сложения двух чисел с разными знаками должна быть заменена операцией вычитания меньшего из большего с последующим присвоением результату знака большего по модулю числа. Другими словами, операция сопровождается большим количеством проверок условий и выработкой признаков, в соответствии с которыми выбирается то или иное действие.
Альтернативным вариантом является представление чисел со знаком в дополнительном коде. Идея построения дополнительного кода достаточно проста: на оси целых положительных чисел, помещающихся в машинное слово (0÷65535), сместим положение «0» на середину интервала; числа, попадающие в первую половину (0÷32767) будем считать положительными, а числа из второй половины (32768÷65535) - отрицательными. В этом случае судить о знаке числа можно будет по его величине и в явном виде выделение знака не потребуется. Например, 1000000000000012 = 3276910 является кодом отрицательного числа, а 0000000000000012 = 110 - кодом положительного. Принадлежность к интервалу кодов положительных или отрицательных чисел видна по состоянию старшего бита - у кодов положительных чисел его значение «0», отрицательных - «1». Это напоминает представление со знаком, но не является таковым, поскольку используется другой принцип кодирования. Его применение позволяет заменить вычитание чисел их суммированием в дополнительном коде. Мы убедимся в этом чуть позднее после того, как обсудим способ построения дополнительного кода целых чисел.
Дополнением (D) k-разрядного целого числа Z в системе счисления p называется величина D (Zp , k) = pk - Z.
Данную формулу можно представить в ином виде: D(Zp, k) = ((pk - 1) - Z) + 1. Число pk- 1 согласно (4.8), состоит из k наибольших в данной системе счисления цифр (p - 1), например, 999910, FFF16 или 11111112. Поэтому (pk - 1) - Z можно получить путем дополнения до p-1 каждой цифры числа Z и последующим прибавлением к последнему разряду 1.
Пример 4.
Построить дополнение числа 27810. В данном случае p = 10, k = 3.
D(27810 , 3) = {<9-2><9-7><9-8>}+1, т.е. 721+1=722.
Важным свойством дополнения является то, что его сумма с исходным числом в заданной разрядной сетке будет равна 0. В рассмотренном примере:

В разряде тысяч 1 должна быть отброшена, поскольку она выходит за отведенную разрядную сетку.
Так как в двоичной системе счисления дополнением 1 является 0, а дополнением 0 является 1, построение D(Z2 , k) сводится к инверсии данного числа, т.е. замена нулей единицами и единиц нулями, и прибавлением 1 к последнему разряду. Другими словами, дополнение двоичного числа формируется в два этапа:
- строится инвертированное представление исходного числа;
- к инвертированному представлению прибавляется 1 по правилам двоичной арифметики.
Дополнительный код (DK) двоичных целых чисел строится по следующим правилам:
- для Z2
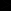 0 дополнительный код совпадает с самим числом (DK = Z2);
0 дополнительный код совпадает с самим числом (DK = Z2);
- для Z2<0 дополнительный код совпадает с дополнением модуля числа, т.е. DK = D(|Z2| ,k).
Пример 5.
Построить дополнительные двоичные коды чисел (a) 310 и (b) –310.
| (a) т.к. Z>0, | | DK | | 0000 0000 0000 0011 |
| (b) т.к. Z<0 | | (1) модуль числа | | 0000 0000 0000 0011 |
| | | (2) инверсия числа | | 1111 1111 1111 1100 |
| | | (3) DK | | 1111 1111 1111 1101 |
Проверка:

Вновь убеждаемся, что
DK(Z) + DK(–Z) = 0
Сопоставление прямых и дополнительных кодов представлено в виде таблицы:

Видно, что общее количество кодов совпадает и, следовательно, одинаковым будет количество кодируемых чисел в обоих способах. Точнее, дополнительных кодов оказывается на один больше, чем прямых, и интервал целых чисел со знаком при их размещении в 2-байтном машинном слове составляет [–32768; 32767] - именно такими являются граничные значения целых чисел типа Integer в языке PASCAL, что свидетельствует об использовании дополнительного кодирования в представлении чисел. Перевод в дополнительный код происходит автоматически при вводе чисел; в таком виде числа хранятся в ОЗУ и затем участвуют в арифметических операциях. При этом, как уже было сказано, операция вычитания двух чисел как самостоятельная отсутствует – она заменяется сложением первого числа с дополнительным кодом второго, т.е. просто сложением содержимого двух ячеек памяти. Убедимся в правомочности этого.
Пример 6.
Найти значение (27 – 3)10 в двоичной кодировке.

В данном случае появление 1 в регистре переполнения не интерпретируется как ошибка вычислений, поскольку на ее отсутствие указывают знаки чисел и результата. Порядок проверок и анализа корректности операций сложения-вычитания (Z = Z(1) + Z(2)) можно представить в виде таблицы:
| Старший бит Z(1) | Старший бит Z(2) | Старший бит Z | Регистр переполнения | Комментарий |
| 0 | 0 | 0 | 0 | Сложение двух положительных чисел без переполнения. Результат корректен. |
| 0 | 0 | 1 | 0 | Переполнение при сложении двух положительных чисел. Результат некорректен. |
| 1 | 1 | 1 | 1 | Сложение двух отрицательных чисел без переполнения. Результат корректен. |
| 1 | 1 | 0 | 1 | Переполнение при сложении двух положительных чисел. Результат некорректен. |
| 0 | 1 | 0 | 1 | Сложение чисел с разными знаками; Z(1)>|Z(2)|. Результат корректен. |
| 0 | 1 | 1 | 0 | Сложение чисел с разными знаками; Z(1)<|Z(2)|. Результат корректен. |
Необходимо уточнить, что при выполнении вычитания отрицательного числа оно из дополнительного кода переводится в прямой, и вновь вместо вычитания производится сложение.
Подобным же образом число из дополнительного кода переводится в прямой при выполнении операции умножения; перемножаются всегда положительные числа по рассмотренным выше правилам; знаковый бит результата, очевидно, будет содержать 0, если знаки чисел одинаковы, и 1 при противоположных знаках.

Над множеством целых чисел со знаком операция деления не определена, поскольку в общем случае ее результатом будет вещественное число. Однако допустимыми являются операции целочисленного деления и нахождения остатка от целочисленного деления (те, что мы немного ранее обозначили div и mod). Точнее, значения обеих величин находятся одновременно в одной процедуре, которая в конечном счете сводится к последовательности вычитаний или, еще точнее, сложений с дополнительным кодом делителя. Примем обозначения: Z(1) – делимое; Z(2) – делитель; L – результат целочисленного деления Z(1) на Z(2); R – остаток от целочисленного деления Z(1) на Z(2). Эти величины связаны между собой довольно очевидным соотношением:
Z(1) = L· Z(2) + R,
из которого следует алгоритм нахождения значений L и R для заданных Z(1) и Z(2); его блок-схема для положительных Z(1) на Z(2) представлена на рис. 4.7.
Таким образом, операции div и mod, как, впрочем, и операция умножения, реализуются программно, т.е. сводятся к последовательности небольшого числа более простых действий. При этом уровень программной реализации может быть различным. Если реализация выполнена на уровне команд центрального процессора, то эти операции оказываются доступны из любого приложения (любой прикладной программы). Если же в системе команд процессора эти микропрограммы отсутствуют, их приходится описывать в виде процедур в самих приложениях и, следовательно, они будут доступны только в этих приложениях.