
Предисловие Системы управления базами данных (субд) – это программные комплексы, предназначенные для работы со специально организованными файлами (массивами данных, долговременно хранимыми во внешней памяти вычислительных систем), которые называются
| Вид материала | Документы |
- Системы управления базами данных (субд). Назначение и основные функции, 30.4kb.
- Программа курса лекций "Базы данных в научных исследованиях", 49.32kb.
- Система управления базами данных это комплекс программных и языковых средств, необходимых, 150.5kb.
- Лекция 2 Базы данных, 241.25kb.
- Любая программа для обработки данных должна выполнять три основных функции: ввод новых, 298.05kb.
- Вопросы к государственному экзамену по специальности «Информационные системы и технологии», 39.93kb.
- Лекция № Технологии баз данных, 92.24kb.
- Проектирование базы данных, 642.58kb.
- Системы управления базами данных, 313.7kb.
- Программа дисциплины Системы управления базами данных Семестры, 22.73kb.
База данных поддерживает прозрачность локального отображения
В запросе необходимо задавать и имя фрагмента, и местоположение. На псевдо-SQL запрос можно записать в таком виде:
SELECT *
FROM El NODE NY
WHERE EMP_DOB < '01-JAN-1940';
UNION SELECT *
FROM E2 NODE ATL
WHERE EMP_DOB < '01-JAN-1940';
UNION SELECT *
FROM E3 NODE MIA
WHERE EMP_DOB < '01-JAN-1940';

Слово NODE указывает местоположение БД, используется только для иллюстрации и не является частью синтаксиса SQL.
В только что приведенном формате запроса видно, как влияет прозрачность распределения на способ взаимодействия конечных пользователей и программистов с БД. Прозрачность распределения обеспечивается словарем распределенных данных (distributed data dictionary, DDD) или каталогом распределенных данных (distributed data catalog, DDC). DDC содержит описание всей базы данных с точки зрения администратора БД. Описание базы данных называется схемой глобального распределения (distributed global schema) и представляет собой глобальную схему базы данных, используемую локальными процессорами транзакций (ТР) для трансляции запросов пользователей в подзапросы (удаленные запросы), которые будут обрабатываться
различными процессорами данных (DP). Каталог DDC сам по себе является распределенным и дублируется на узлах сети. Поэтому необходимо постоянно обслуживать каталог DDC путем обновления всех сайтов.
Помните, что в некоторых реализациях современных СУРБД устанавливаются ограничения на уровень прозрачности. Например, СУРБД может допускать распределение по сайтам базы данных, но не отдельной таблицы. Такое условие означает, что СУБД поддерживает прозрачность местоположения, но не поддерживает прозрачность фрагментации.
10.8. Прозрачность транзакций
Прозрачность транзакций является свойством СУРБД, которое гарантирует, что все транзакции БД будут обеспечивать целостность и непротиворечивость распределенной базы данных. Необходимо помнить, что транзакции СУРБД могут обновлять данные, хранящиеся на различных компьютерах, объединенных в сеть. Свойство прозрачности транзакций гарантирует, что транзакция будет завершена только в том случае, если на всех сайтах базы данных, вовлеченных в транзакцию, будут завершены все части этой транзакции.
В системах распределенных баз данных для управления транзакциями и обеспечения целостности и непротиворечивости базы данных используется сложный механизм. Для того чтобы понять, как происходит управление транзакциями, необходимо знать основные концепции удаленных запросов, удаленных транзакций, распределенных транзакций и распределенных запросов.
10.8.1. Распределенные запросы и распределенные транзакции
Является транзакция распределенной или нет, в любом случае она формируется на базе одного или нескольких запросов. Основное отличие нераспределенных транзакций от распределенных состоит в том, что последние могут обновлять или запрашивать данные на нескольких удаленных сайтах сети'. Для более наглядной иллюстрации концепций распределенных транзакций сначала установим различие между удаленной и распределенной транзакциями с помощью форматов транзакций BEGIN WORK и COMMIT WORK. Чтобы не указывать местоположение данных, предположим, что поддерживается прозрачность местоположения.
Удаленный запрос (remote request), представленный на рис. 10.10, позволяет получить доступ к данным, которые будут обрабатываться одним удаленным процессором базы данных. Другими словами, SQL-оператор (или запрос) может ссылаться на данные, расположенные только на одном удаленном сайте.
Точно так же удаленная транзакция (remote transaction), составленная из нескольких запросов, может получать доступ к данным, размещенным только на одном сайте. Удаленная транзакция представлена на рис. 10.11.
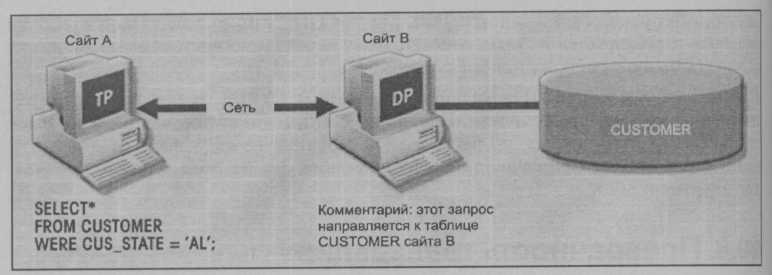
Рис. 10.11. Удаленная транзакция
1
 Для получения дополнительной информации об этих концепциях см. David McGoveran и Colin White, "Clarifying Client-Server", DBMS 3(12), ноябрь 1990, стр. 78-89.
Для получения дополнительной информации об этих концепциях см. David McGoveran и Colin White, "Clarifying Client-Server", DBMS 3(12), ноябрь 1990, стр. 78-89.На рис. 10.11 обратите внимание на следующие особенности удаленной транзакции: П транзакция обновляет таблицы CUSTOMER и INVOICE;
- обе таблицы размещены на Сайте В;
- транзакция может ссылаться только на один процессор данных (DP);
- каждый оператор SQL (или запрос) может ссылаться в данный момент времени
только на один (один и тот же) удаленный процессор данных (DP), и вся транзакция может ссылаться только на один и выполняться только одним удаленным DP.
Распределенная транзакция (distributed transaction) позволяет ссылаться на несколько различных (локальных или удаленных) сайтов DP. Хотя каждый простой запрос может
Рис. 10.10. Удаленный запрос
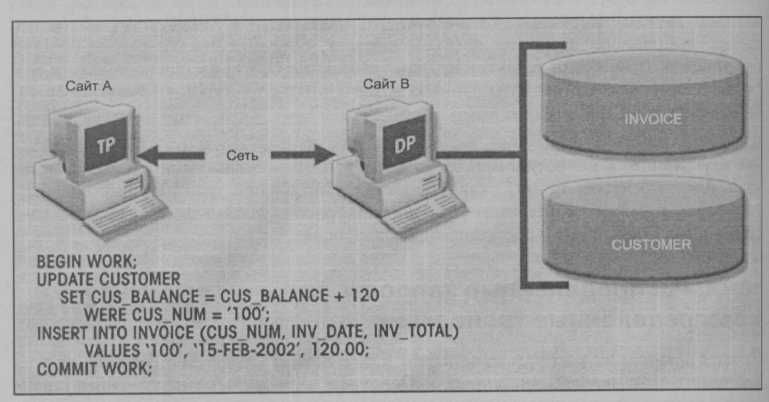
ссылаться только на один удаленный сайт DP, транзакция в целом может ссылаться на несколько сайтов DP, поскольку каждый запрос может ссылаться на различные сайты. Процесс распределенной транзакции представлен на рис. 10.12.
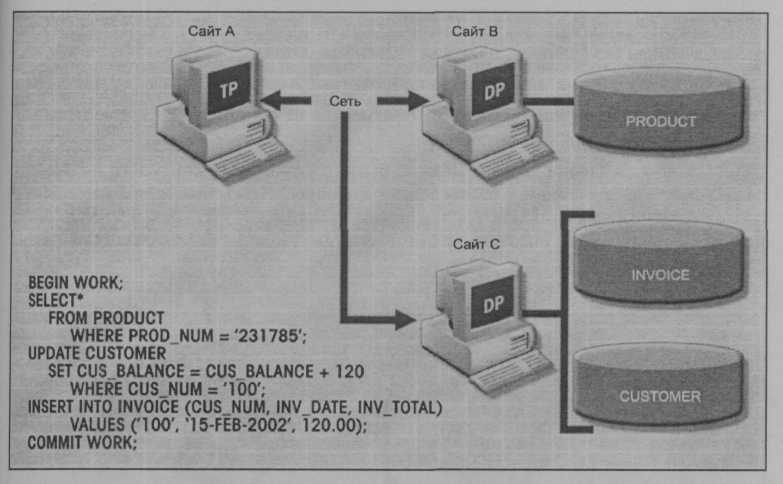
Рис. 10.12. Распределенная транзакция
Обратите внимание на следующие особенности на рис. 10.12: 0 транзакция ссылается на два удаленных сайта (В и С);
- первый запрос (оператор SELECT) обрабатывается процессором данных на удаленном сайте Сайт В, а следующие запросы (UPDATE и INSERT) обрабатываются DP на удаленном сайте (С);
- каждый запрос в один момент времени может получить доступ только к одному удаленному сайту.
Третий пункт может создавать проблемы. Предположим, что таблица PRODUCT разделяется на два фрагмента PRODI и PROD2, расположенные на сайтах В и С соответственно. При этом сценарии предыдущая распределенная транзакция выполняться не будет, поскольку запрос
SELECT * FROM PRODUCT WHERE PROD_NUM = '231785';
не сможет получить доступ к данным на более чем одном удаленном сайте. Поэтому в этом случае СУБД должна обеспечивать поддержку распределенных запросов.
Распределенный запрос (distributed request) позволяет получать данные от нескольких удаленных сайтов с DP. Поскольку каждый запрос может получать доступ к данным, расположенным более чем на одном сайте, транзакция может получать доступ к нескольким сайтам.
Возможность выполнять распределенный запрос предоставляет только полностью распределенная база данных, поскольку здесь мы можем: О разбить базу данных на несколько фрагментов;
□ ссылаться на один или более таких фрагментов из одного запроса, т. е. использовать прозрачность фрагментации.
Размещение и разбиение данных должно быть прозрачно для конечного пользователя. На рис. 10.3 представлен распределенный запрос. Здесь нужно обратить внимание на то, что транзакция для ссылки на две таблицы CUSTOMER и INVOICE использует единственный оператор SELECT. Эти две таблицы расположены на разных сайтах В и С.
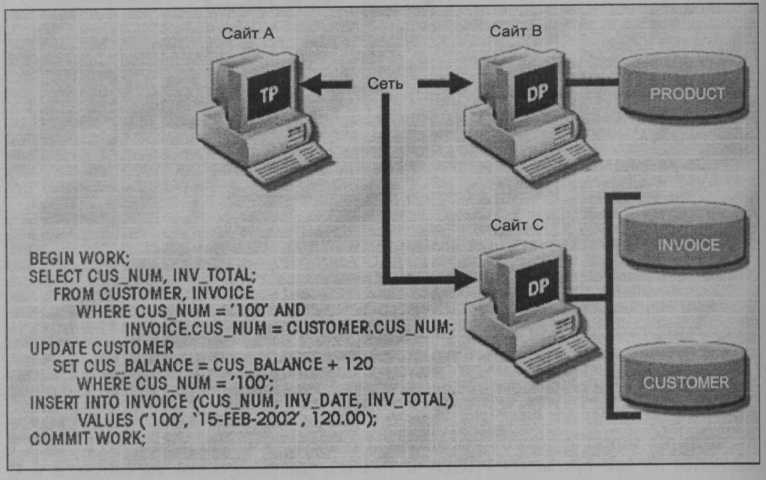
Рис. 10.13. Распределенный запрос
Возможность создания распределенного запроса позволяет в одном запросе обращаться к физически разделенной таблице. Предположим, что таблица CUSTOMER разделена на два фрагмента С1 и С2, расположенные на сайтах В и С соответственно. Теперь допустим, что конечный пользователь хочет получить список всех клиентов, чей баланс превышает $250. Этот запрос проиллюстрирован на рис. 10.14. Полная поддержка прозрачности фрагментов предоставляется только в СУРБД, которые поддерживают распределенные запросы.
Осмысление различных типов запросов к базе данных в распределенных системах поможет понять проблемы прозрачности транзакций. Свойство прозрачности транзакций гарантирует, что все транзакции можно рассматривать как централизованные, а также обеспечивает их сериализуемость (вспомните обсуждение в гл. 9), т. е.
при одновременном выполнении транзакций (независимо от того, являются они распределенными или нет) база данных будет переходить из одного устойчивого состояния в другое. Далее мы рассмотрим управление параллельным выполнением распределенных транзакций.
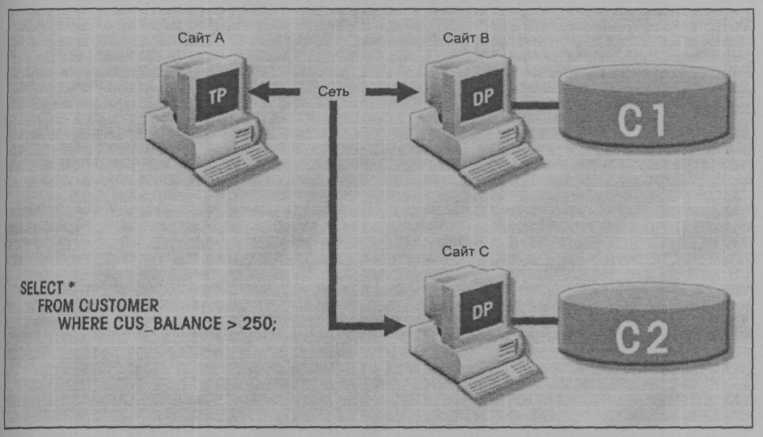
Рис. 10.14. Еще один распределенный запрос
10.8.2. Управление параллельным выполнением в распределенной среде
Управление параллельным выполнением становится особенно значимым в среде распределенной базы данных, поскольку многоместные (на нескольких сайтах) и многопроцессорные операции с большей вероятностью могут привести к противоречивости данных и тупикам, чем одноместные (выполняющиеся на одном сайте) системы. Например, компонент ТР (процессор транзакций) СУРБД должен гарантировать, что все части транзакции на всех сайтах будут завершены до того, как последний оператор COMMIT завершит всю транзакцию в целом.
Предположим, что каждая операция транзакции подтверждалась локальным процессором данных (DP), но один из DP не смог записать результаты транзакции. Это может привести к проблемам (рис. 10.15): транзакция (транзакции) приведет к противоречивому состоянию БД и неизбежным проблемам с целостностью, поскольку мы не можем отменить уже записанные данные! Решение проблемы, представленной на рис. 10.15, состоит в использовании протокола двухфазного подтверждения транзакции (two-phase commit protocol), который мы сейчас подробно обсудим.
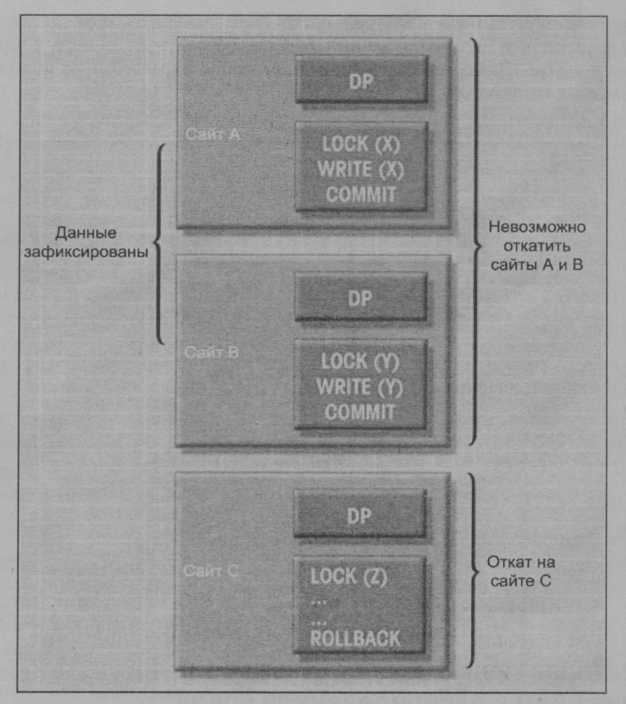
Рис. 10.15. Результат преждевременного завершения транзакции
10.8.3. Протокол двухфазного подтверждения транзакции
Централизованной базе данных необходим только один процессор данных (DP). Все операции с базой данных проводятся на одном сайте и последовательность операций сразу становится известна СУБД. И наоборот, распределенные базы данных позволяют транзакциям осуществлять доступ к данным на нескольких сайтах. Завершающий оператор COMMIT не должен выполняться до тех пор, пока каждый сайт не завершит свою часть транзакции. Протокол двухфазного подтверждения транзакции требует, чтобы каждая запись в журнале транзакций процессора данных выполнялась до фактического обновления фрагмента (см. разд. 9.6). Поэтому протокол двухфазного подтверждения транзакции требует применения протокола DO-UNDO-REDO (выполнить-отменить-повторить) и протокола упреждающей записи.
 Протокол DO-UN DO-REDO используется процессором данных для отката транзак-I ций назад (roll back) и/или отката транзакций вперед (roll forward) на основе записей I в системном журнале транзакций. Протокол DO-UNDO-REDO устанавливает три I типа операций:
Протокол DO-UN DO-REDO используется процессором данных для отката транзак-I ций назад (roll back) и/или отката транзакций вперед (roll forward) на основе записей I в системном журнале транзакций. Протокол DO-UNDO-REDO устанавливает три I типа операций:- DO выполняет операцию и записывает в журнал транзакций значения "перед" и
"после".
- UNDO отменяет операцию с помощью записей в журнале транзакций, сделанных операцией DO.
- REDO вновь выполняет отмененную операцию с помощью записей в журнале, сделанных операцией DO.
Чтобы гарантировать, что операции DO, UNDO и REDO смогут обеспечить корректное выполнение операций при крахе системы, используется протокол упреждающей записи. Протокол упреждающей записи (write-ahead protocol) принуждает фиксировать в журнале запись данных для постоянного хранения перед фактическим выполнением этой операции.
Протокол двухфазного подтверждения транзакции определяет операции между двумя типами узлов: узел-координатор (coordinator) и один или более подчиненных узлов-субординаторов (subordinates), или когорт (cohort). Протокол реализуется в две фазы.
Фаза 1. Подготовка
- Координатор посылает сообщение PREPARE TO COMMIT (подготовка к завершению) всем субординаторам.
- Субординаторы получают сообщение, записывают информацию в журнал транзакций в соответствии с протоколом упреждающей записи и посылают координатору уведомление YES/PREPARED TO COMMIT (да/завершение подготовлено) или NO/NOT PREPARED (нет/завершение не готово).
- Координатор убеждается, что все узлы готовы к завершению, или в противном
случае отменяет действие.
Если все узлы сообщили, что они готовы к завершению (PREPARED TO COMMIT), транзакция переходит в фазу 2. Если один или более узлов отвечают, что они не готовы (N0 или NOT PREPARED), координатор распространяет среди всех субординаторов сообщение ABORT (прекращение).
Фаза 2. Последний оператор COMMIT
Координатор оповещает всех субординаторов, рассылая сообщение COMMIT, и
ожидает ответ.
- Каждый субординатор, получив сообщение COMMIT, обновляет базу данных в
соответствии с протоколом DO.
- Субординаторы отвечают координатору сообщением C0MMITED (завершено)
или NOT COMMITED (не завершено).
Если один или более субординаторов не выполнили операцию завершения, координатор рассылает сообщение ABORT и тем самым инициирует операцию UNDO (отмену всех изменений).
Цель протокола двухфазного подтверждения транзакции состоит в обеспечении корректного завершения всеми узлами своих частей транзакции; в противном случае транзакция отменяется. Если один или более узлов не выполняют операцию завершения, то необходимая информация по восстановлению БД будет находиться в журнале транзакций и база данных может быть восстановлена с помощью протокола DO-UNDO-REDO (помните, что информация журнала обновляется на основе протокола упреждающей записи).
10.9. Прозрачность производительности и оптимизация запроса
Одна из основных функций базы данных состоит в обеспечении доступа к данным. Поскольку в централизованной БД все данные размещаются на одном сайте, СУБД должна оценивать каждый запрос к данным и находить наиболее эффективный способ получения доступа к локальным данным. В отличие от этого СУРБД позволяет разбивать базу данных на несколько фрагментов, в связи с чем транслироать запросы становится сложнее, поскольку СУРБД должна решать, к какому из фрагментов БД необходимо обеспечить доступ. Кроме того, данные могут дублироваться на нескольких сайтах. Дублирование (репликация) данных еще более усложняет проблему доступа к данным, поскольку в этом случае СУРБД должна решать, к какой из копий данных необходимо обеспечить доступ. Для устранения подобных проблем и обеспечения приемлемой производительности базы данных СУРБД использует технологию оптимизации запросов.
Целью программы оптимизации запросов является минимизация общих затрат, связанных с выполнением запроса. Затраты на выполнение запроса зависят от перечисленных ниже факторов.
- Затраты на время доступа (ввод/вывод) при получении доступа к физическим
данным, хранящимся на диске.
- Затраты на коммуникацию, связанную с передачей данных между узлами в системе распределенной базы данных.
- Затраты на использование центрального процессора (CPU), связанные с накладными расходами на управление распределенными транзакциями.
Хотя затраты часто разделяют на коммуникационные затраты и затраты на обработку, на самом деле их очень трудно отделить друг от друга. Не все алгоритмы оптимизации используют одинаковые параметры и не все алгоритмы присваивают одинаковые веса этим параметрам. Например, некоторые алгоритмы минимизируют общее время, другие минимизируют время коммуникации, а третьи не принимают в расчет время работы центрального процессора, считая эти затраты незначительными по сравнению с другими расходами.
Чтобы оценить оптимизацию запроса, помните, что процессор транзакций (ТР) должен получить данные от процессора данных (DP), синхронизировать их, скомпоновать ответ и представить его конечному пользователю или приложению. Хотя этот процесс является стандартным, необходимо учитывать, что отдельный запрос может выполняться на одном из нескольких сайтов. Время отклика удаленных сай -тов не всегда легко предопределить, поскольку некоторые узлы могут выполнить свою часть запроса быстрее других.
Одно из наиболее важных свойств оптимизации запроса в системе распределенной базы данных состоит в том, что она должна обеспечить прозрачность распределения, а также прозрачность реплики (точной копии). Прозрачность распределения мы пояснили ранее в этой главе. Прозрачность реплики (replica transparency) связана с возможностью СУРБД скрывать существование нескольких копий данных от пользователя.
Большинство алгоритмов оптимизации запросов основаны на двух принципах:
- выбор оптимального порядка выполнения;
- выбор сайтов, к которым необходимо получить доступ для минимизации стоимости коммуникации.
На основе этих двух принципов алгоритм оптимизации можно оценить по режиму его работы или расчетному времени оптимизации.
Режим работы может быть ручным и автоматическим. Автоматическая оптимизация запроса означает, что СУРБД сама находит наиболее эффективный путь доступа без вмешательства пользователя. Ручная оптимизация запроса предполагает, что оптимизация и исполнение определяются конечным пользователем или программистом. Автоматическая оптимизация запроса, очевидно, более предпочтительна с точки зрения пользователя, однако при этом возрастают непроизводительные издержки СУРБД.
Алгоритмы оптимизации запроса можно классифицировать по времени выполнения оптимизации. По этому показателю алгоритмы подразделяются на статические и динамические.
- Статическая оптимизация запроса выполняется во время компиляции. Другими словами, наилучшая стратегия оптимизации избирается во время компиляции запроса СУБД. Такой подход применяется в том случае, если SQL-операторы встроены в процедурный язык программирования, например, COBOL или Pascal. Когда программа передается СУБД для компиляции, создается план доступа к базе данных. При выполнении программы СУБД использует этот план для доступа к базе данных.
- Динамическая оптимизация запроса производится на этапе его выполнения. Стратегия доступа к базе данных определяется при выполнении программы. Поэтому стратегия доступа динамически определяется СУБД на основе самой последней информации о базе данных. Хотя динамическая оптимизация запроса является более эффективной, затраты на нее определяются стоимостью выполнения всех ее процессов. Наилучшая стратегия определяется всякий раз при выполнении запроса, а это может происходить несколько раз в одной программе.
Наконец, технологии оптимизации запросов подразделяются в зависимости от те; информации, используемой для оптимизации запроса. Например, оптимизация запросов может быть основана на статистических алгоритмах или на алгоритмах, использующих определенные правила.
- Статистические алгоритмы оптимизации запроса. В этом случае используется
статистическая информация о базе данных, представляющая собой такие характеристики БД, как ее размер, число записей, среднее время доступа, число обработанных запросов, число пользователей с правами доступа и т. д. Эта статистическая информация затем используется СУБД для определения наилучшей
стратегии.
- Статистическая информация контролируется СУБД и создается в двух разных
режимах: динамическом и ручном. В динамическом режиме создания статистики
СУРБД автоматически оценивает и обновляет статистику после каждого доступа
к данным. В ручном режиме создания статистики ее необходимо обновлять периодически при помощи специальных утилит, таких, например, как RUNSTAT.
компании IBM, которая используется, например, в OS/2 Database Manager.
- Алгоритм оптимизации запроса на основе правил основан на наборе определенны
пользователем правил, определяющих наилучшую стратегию запросов. Эти правила устанавливаются конечными пользователями или администратором базы
данных и, как правило, носят очень общий характер.
10.10. Проектирование распределенной
базы данных
Является база данных распределенной или нет, принципы проектирования и основные концепции, описанные в гл. 2, остаются теми же. Однако при проектировании распределенной БД возникают три новые проблемы.
- Как разбивать базу данных на фрагменты?
- Какие фрагменты необходимо дублировать (реплицировать или тиражировать)?
- Где расположить эти фрагменты и реплики?
Фрагментация данных и репликация данных относятся к первым двум указанным проблемам, а размещение данных — к третьей.
10.11. Фрагментация данных
Фрагментация данных допускает разбиение одного объекта на два или более сегмента или фрагмента. Объект может представлять собой пользовательскую базу данных, системную базу данных или таблицу. Каждый фрагмент может храниться на любом сайте компьютерной сети. Информация о фрагментации данных хранится в каталоге распределенных данных (distributed data catalog, DDC), к которому процессор транзакций (ТР) может получить доступ при обработке запросов пользователя.
Обсуждающиеся здесь стратегии фрагментации данных действуют на уровне таблиц и заключаются в разбиении таблицы на логические фрагменты. Мы исследуем три типа стратегий фрагментации данных: горизонтальная, вертикальная и смешанная. (Отметим, что фрагментированную таблицу в любой момент можно снова объединить посредством комбинации операций объединения (union) и соединения (join).)
- Горизонтальная фрагментация. При этом таблица (отношение, relation) подразделяется на подмножества (фрагменты) кортежей (строк). Каждый фрагмент хранится на отдельном узле (сайте) и каждый фрагмент имеет уникальные строки.
Однако все уникальные строки имеют одинаковые атрибуты (столбцы). Иначе
говоря, каждый фрагмент эквивалентен оператору SELECT с модифицирующим выражением WHERE по единственному атрибуту.
- Вертикальная фрагментация. Такой тип фрагментации подразумевает разделение
отношения (таблицы) на подмножества атрибутов (столбцов). Каждое подмножество (фрагмент) хранится на отдельном узле и каждый фрагмент имеет уникальные столбцы — за исключением ключевого столбца, который имеется во всех фрагментах. Это эквивалентно применению оператора PROJECT.
- Смешанная фрагментация. Эта фрагментация представляет собой комбинацию
вертикальной и горизонтальной стратегий. Другими словами, таблица может разделяться на несколько горизонтальных множеств (строк), каждая из которых разделяется на множество атрибутов (столбцов).
Для иллюстрации стратегий фрагментации мы используем таблицу CUSTOMER (клиент) компании XYZ, представленную на рис. 10.16. В таблице есть атрибуты CUS_NUM, CUS_NAME, CUS_ADDRESS, CUS_STATE, CUS_LIMIT, CUS_BAL, CUS_RATING и CUS_DUE.
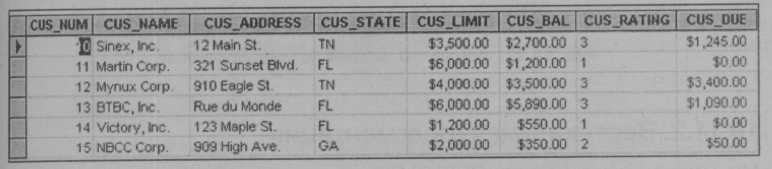
Рис. 10.16. Пример таблицы CUSTOMER
10.11.1. Горизонтальная фрагментация
Предположим, что руководству компании XYZ необходима информация о клиентах по всем трем штатам, но каждому подразделению компании (TN — Теннеси, FL — Флорида и GA — Джорджия) необходима информация только по своим локальным клиентам. На основе этого было принято решение распределить данные по штатам. Поэтому для реализации структуры, представленной в табл. 10.3, выбрали горизонтальную фрагментацию.
Таблица 10.3. Горизонтальная фрагментация таблицы CUSTOMER по штат

Каждый горизонтальный фрагмент может иметь свое число строк, но ДОЛЖЕН иметь те же атрибуты, что и остальные фрагменты. После фрагментации мы получим три таблицы, представленные на рис. 10.17.
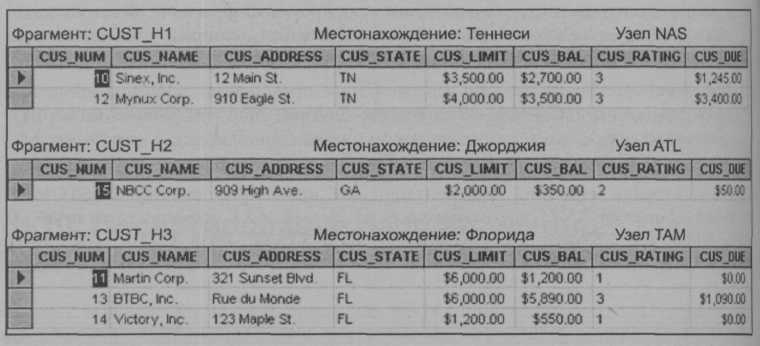
Рис. 10.17. фрагменты таблицы по местоположению
10.11.2. Вертикальная фрагментация
Мы можем разбить таблицу CUSTOMER на вертикальные фрагменты, представляющие собой наборы атрибутов. Например, предположим, что у компании есть два подразделения: отдел обслуживания и отдел приема платежей. Каждое подразделение расположено в отдельном здании и каждому подразделению необходима информация только по нескольким атрибутам таблицы CUSTOMER. Разделение по фрагментам для такого варианта представлено в табл. 10.4.
Таблица 10.4. Вертикальная фрагментация таблицы CUSTOMER

Таблица 10.4.(окончание)

Каждый вертикальный фрагмент имеет одинаковое количество строк, но включает в себя различные атрибуты, зависящие от ключевого столбца. Результаты вертикальной фрагментации представлены на рис. 10.18. Обратите внимание, что ключевой атрибут (CUSNUM) является общим и для фрагмента CUST_V1, и для фрагмента CUST_V2.
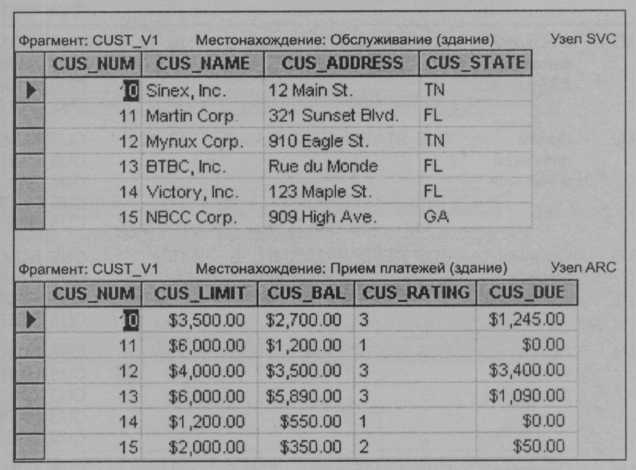
Рис. 10.18. Содержимое таблиц при вертикальной фрагментации
10.11.3. Смешанная фрагментация
Структура компании XYZ требует, чтобы данные таблицы CUSTOMER были фраг-ментированы горизонтально, отражая деление компании на местные филиалы, и в то же время в рамках филиала данные необходимо фрагментировать вертикально, чтобы выделить подразделения (обслуживание и платежи). Другими словами, таблицу CUSTOMER необходимо фрагментировать по смешанной стратегии.
Смешанная фрагментация представляет собой двухступенчатую процедуру. Сначала мы проводим горизонтальную фрагментацию на каждом сайте на основе разбиения компании по филиалам (CUS_STATE). Горизонтальная фрагментация представляет набор кортежей клиентов (горизонтальные фрагменты), расположенных на каждом сайте. Поскольку подразделения расположены в разных помещениях, мы используем вертикальную фрагментацию в рамках каждого горизонтального фрагмента для разбиения атрибутов, что обеспечит каждое подразделение необходимой ему информацией. Смешанная фрагментация приводит к результатам, представленным в табл. 10.5.
Таблица 10.5. Смешанная фрагментация таблицы CUSTOMER
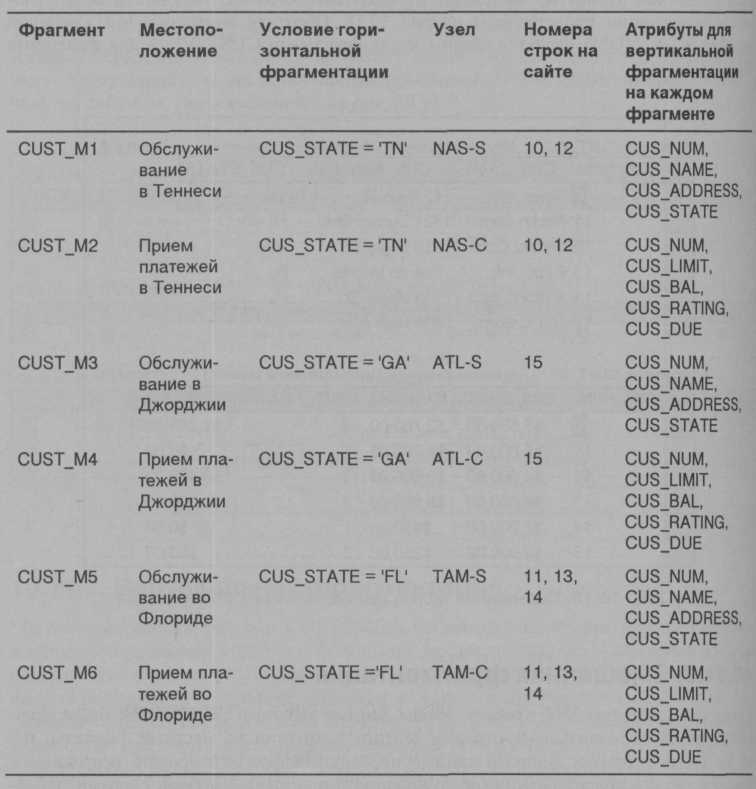
Каждый фрагмент, представленный в табл. 10.5, содержит данные о клиентах по штату и, внутри каждого штата, — по локальным подразделениям, чтобы удовлетворить требования подразделений. Таблицы, соответствующие фрагментам, перечисленным в табл. 10.5, представлены на рис. 10.19.

Рис. 10.19. Содержимое таблиц после смешанной фрагментации
10.12. Репликация данных
Репликация данных связана с хранением копий данных в сети компьютеров на нескольких сайтах, предназначенных для специальных операций с данными. Поскольку копии фрагментов повышают уровень доступности данных и уменьшают время отклика, репликация поможет уменьшить общие затраты на коммуникации при выполнении запросов.
Предположим, что база данных А разделена на два фрагмента А1 и А2. Внутри реплицированной и распределенной базы данных возможен сценарий, представленный на рис. 10.20: фрагмент А1 хранится на сайтах S1 и S2, в то время как фрагмент А2 хранится на сайтах S2 и S3.
Реплицированные данные подчиняются правилу взаимной непротиворечивости. Правило взаимной непротиворечивости (mutual consistency rule) требует, чтобы все копии фрагментов данных были идентичны. Поэтому для обеспечения непротиворечивости данных в репликах СУРБД должна гарантировать, что обновление БД выполняется на всех сайтах, где есть реплики данных.
Хотя репликация обладает некоторыми преимуществами, она влечет за собой и некоторые дополнительные накладные расходы, поскольку система должна обслуживать каждую копию данных. Для иллюстрации появления таких накладных расходов рассмотрим процессы, которые СУРБД должна выполнить при работе с базой данных.
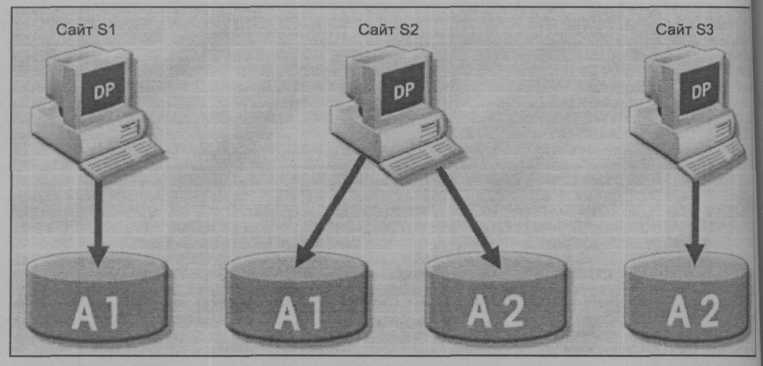
Рис. 10.20. Репликация данных
- Если БД фрагментирована, то СУРБД для получения доступа к соответствующему фрагменту должна разбивать запрос на подзапросы.
- Если БД реплицирована, то СУРБД должна принимать решение, к какой копии
необходимо обеспечить доступ. Операция чтения (Read) выбирает ближайшую
копию, которая годится для данной транзакции. Операция записи (Write) в соответствии с правилом взаимной непротиворечивости должна выбирать и обновлять все копии данных.
- Процессор транзакций (ТР) посылает данные на обработку на каждый выбранный процессор данных (DP).
- DP получает данные, обрабатывает каждый запрос и отсылает данные обратно на ТР.
- ТР объединяет все ответы DP.
Проблема еще больше усложнится, если мы примем во внимание такие дополнительные факторы, как топологию сети и ее пропускную способность.
Возможны три варианта репликации БД: база данных может быть полностью реплицированной, частично реплицированной и не реплицированной.
- Полностью реплицированная база данных хранит на множестве сайтов несколько копий каждого фрагмента БД. В этом случае все фрагменты БД реплицированы.
Полностью реплицированная БД может оказаться неудобной в использовании из-за больших накладных расходов.
- Частично реплицированная база данных хранит на множестве сайтов несколько копий некоторых фрагментов БД. Большинство СУРБД допускают работу именно с частично реплицированными БД.
- Нереплицированная база данных хранит каждый фрагмент БД на отдельном сайте. В этом случае дублированные фрагменты БД отсутствуют.
На репликацию БД влияет несколько факторов: D размер БД;
- частота использования БД;
- затраты (эффективность, непроизводительные издержки программного обеспечения и управления), связанные с синхронизацией транзакций и их частей при обеспечении должной отказоустойчивости, связанной с репликацией данных.
Если частота обращения к удаленным данным очень высока, а база данных большая, то репликация данных может уменьшить затраты на обработку запросов. Информация о репликации данных хранится в каталоге распределения данных (DDC), содержимое которого ТР использует, чтобы принять решение — к какой копии фрагмента БД необходимо обеспечить доступ. Репликация данных позволяет восстановить утерянные данные.
10.13. Распределение данных
Распределение данных (data allocation) представляет собой процесс принятия решения о месте хранения данных. Выделяют следующие типы стратегии распределения данных:
- централизованное распределение данных — вся база данных хранится на одном сайте;
- секционированное распределение данных, при котором база данных разбивается на несколько разъединенных частей (фрагментов) и хранится на нескольких сайтах;
- ратинированное распределение данных предполагает хранение одной или более копий фрагментов БД на нескольких сайтах.
Распределение данных по компьютерной сети достигается с помощью сегментирования данных, репликации данных или с помощью комбинации этих методов. Распределение данных тесно связано с методами фрагментации БД. По большей части распределение данных связано с решением одной проблемы: какие данные необходимо разместить и где.
Алгоритмы распределения данных должны учитывать различные факторы, а именно:
- производительность и доступность данных;
- размер, число строк и число отношений, которые данная сущность имеет с другими сущностями;
- типы транзакций, применяемые в БД, атрибуты, доступ к которым осуществляется в этих транзакциях, и т. д.
Некоторые алгоритмы используют внешние данные, например, топологию сети или пропускную способность сети. Оптимального или универсального алгоритма пока нет, хотя в настоящее время их реализовано очень много.
10.14. Сравнение СУРБД и архитектуры "клиент/сервер"
Поскольку в настоящее время установилась тенденция к развитию распределенных баз данных, многие поставщики БД применяют обозначение клиент/сервер для указания возможности распределения данных. Однако это обозначение не всегда точно отражает характеристики архитектуры "клиент/сервер".
Архитектура "клиент/сервер" связана со способом взаимодействия компьютеров, формирующих систему. Основными составляющими элементами архитектуры "клиент/сервер" являются пользователь ресурсов, или клиент, и поставщик ресурсов, или сервер. Архитектуру "клиент/сервер" можно использовать при реализации СУБД, в которой клиентом является процессор транзакций (ТР), а сервером - процессор данных (DP).
Взаимодействие клиента и сервера в СУРБД тщательно планируется. Клиент (ТР) взаимодействует с конечным пользователем и посылает запрос на сервер (DP). Сервер получает, планирует и выполняет запрос, выбирая только те записи, которые необходимы клиенту. Затем сервер посылает информацию клиенту, но только когда клиент их затребует.
Приложения "клиент/сервер" обладают рядом достоинств:
П решения "клиент/сервер" дешевле, чем альтернативные микрокомпьютерные решения или системы на базе мэйнфреймов;
- решения "клиент/сервер" предоставляют конечному пользователю графический
интерфейс микрокомпьютеров, что увеличивает функциональные возможности
упрощает работу;
- опытных пользователей персонального компьютера гораздо больше, чем тех, кто
имеет опыт работы с мэйнфреймом;
- с помощью персонального компьютера легко организовать рабочее место;
- на рынке персональных компьютеров много доступных средств анализа данных и
создания запросов, предназначенных для облегчения взаимодействия с множеством СУБД;
- при переносе разработки приложений с мэйнфреймов на мощные персональные
компьютеры есть значительный выигрыш в стоимости.
Клиент/серверные приложения, к сожалению, имеют и целый ряд недостатков:
- архитектура "клиент/сервер" порождает более сложную инфраструктуру, в которой зачастую трудно управлять различными платформами (локальными сетями, операционными системами и т. д.);
- увеличение числа пользователей и обрабатывающих сайтов часто вызывает проблемы безопасности;
- инфраструктура "клиент/сервер" позволяет обеспечить доступ к данным гораздо большему числу пользователей. Это требует от пользователя достаточно полного знания компьютеров и программного обеспечения. Необходимость обучения увеличивает стоимость обслуживания такой инфраструктуры.
Более подробно с концепциями, компонентами и управлением в архитектуре "клиент/сервер" мы познакомим вас в гл. 12.
10.15. Двенадцать правил Дейта для распределенных баз данных
Ни одно исследование распределенных баз данных не может претендовать на полноту без цитирования двенадцати правил К. Дейта (С. J. Date) для распределенных баз данных2. Правила Дейта описывают полностью распределенные базы данных, и хотя ни одна из современных баз данных не соответствует всем этим правилам, они, тем не менее, играют очень важную роль при разработке распределенных БД. Вот эти правила.
- Независимость локального сайта. Каждый локальный сайт может действовать как независимая, автономная централизованная СУБД. Каждый сайт отвечает за безопасность, управление параллельным выполнением, резервное копирование и восстановление данных.
- Независимость от центрального сайта. Ни один сайт в сети не зависит от центрального или какого-либо другого сайта. Все сайты имеют равные возможности.
- Независимость от сбоев. Функционирование системы не зависит от сбоя на каком-либо узле. Система продолжает выполнение операций даже при неисправности узла или при расширении сети.
- Прозрачность местоположения. Пользователь не обязан знать местоположение данных, чтобы осуществлять их поиск.
- Прозрачность фрагментации. Пользователь видит единую логическую базу данных. Фрагментация базы данных прозрачна для пользователя. Пользователю нет
необходимости знать имена фрагментов БД для получения доступа к ним.
- Прозрачность репликации. Пользователь видит единую логическую базу данных.
СУРБД предоставляет доступ к фрагментам данных прозрачно (невидимо) для
пользователя. СУРБД управляет всеми фрагментами так, что пользователь этого не замечает.
- Распределенная обработка запросов. Распределенная обработка запросов может выполняться на нескольких сайтах процессоров данных (DP). Оптимизацию запросов СУРБД выполняет опять-таки прозрачно для пользователя.
- Распределенная обработка транзакций. Транзакции могут обновлять данные на
нескольких различных сайтах. Выполнение транзакции происходит прозрачно
для пользователя на нескольких сайтах DP.
2
 См. Date, С. J. "Twelve Rules for Distributed Database", Computer Word, 8 июня 1987, 2(23),стр. 77-81.
См. Date, С. J. "Twelve Rules for Distributed Database", Computer Word, 8 июня 1987, 2(23),стр. 77-81.9. Независимость от оборудования. Система должна выполняться на любой аппаратной платформе.
- Независимость от операционной системы. Система должна выполняться в любой
операционной системе.
- Независимость от сети. Система должна работать на любой сетевой платформе.
- Независимость от базы данных. Система должна поддерживать любую базу данных
Резюме
В распределенных базах данных логически связанные данные хранятся на двух или более физически независимых сайтах, связанных компьютерной сетью. База данных разделяется на фрагменты, причем разбиение может быть горизонтальным (наборы строк) или вертикальным (наборы атрибутов). Каждый фрагмент может размещаться на различных узлах сети (сайтах).
Распределенная обработка состоит в разделении логической обработки базы данных между двумя или более узлами сети. Распределенные базы данных требуют распределенной обработки. Система управления распределенной базой данных (СУРБД) управляет обработкой и хранением логически связанных данных во взаимосвязанных компьютерных системах.
К основным компонентам СУРБД относятся процессор транзакций (ТР) и процессор данных (DP). Процессор транзакций представляет собой программный компонент. размещенный на каждом компьютерном узле сети, который запрашивает информацию. Процессор данных представляет собой программный компонент, расположенный на каждом компьютере, где хранятся данные и осуществляется их поиск.
Современные системы баз данных классифицируются по уровню распределения данных и процессов обработки. При этом выделяются три основные категории систем базы данных: (1) обработка и размещение данных на одном сайте, (2) обработка данных на нескольких сайтах и размещение их на одном сайте, (3) обработка и размещение данных на нескольких сайтах.
Гомогенные системы распределенных баз данных объединяют в сети только один тип СУБД. Гетерогенные системы распределенных баз данных объединяют в сети несколько различных типов СУБД.
СУРБД обладают набором прозрачных для пользователя свойств: распределения, транзакций, сбоев, гетерогенности и производительности. Все прозрачные свойства преследуют одинаковую цель: чтобы работа с распределенной базой данных выглядела так же, как с централизованной БД, т. е. конечный пользователь видит данные как составную часть единой логической базы данных и не должен задумываться о сложности реализации такой системы.
Прозрачность распределения позволяет управлять физически рассеянной базой данных так, как будто бы она была централизованной БД. Существуют три уровня прозрачности распределения: фрагментации, местоположения и локального отображения.
Прозрачность транзакций гарантирует, что выполнение распределенных транзакций обеспечит целостность и непротиворечивость распределенной БД.
Прозрачность сбоев гарантирует непрерывность функционирования СУРБД, если на одном или более узлов происходит сбой.
Прозрачность производительности гарантирует, что система будет работать как цен-1рализованная СУБД, и что общая производительность системы не зависит от распределения данных по нескольким удаленным сайтам.
Прозрачность гетерогенности гарантирует, что СУБД будет объединять несколько различных типов локальных СУБД в единую общую, или глобальную, схему базы
данных..
Транзакция состоит из одного или более запросов к БД. Нераспределенная транзакция обновляет или запрашивает данные на единственном сайте. Распределенная транзакция может обновлять и запрашивать данные с нескольких сайтов.
В сети распределенных баз данных необходимо управление параллельным выполнением. Для обеспечения завершения всех фрагментов транзакции используется протокол двухфазного подтверждения транзакции.
Распределенная СУБД (СУРБД) оценивает каждый запрос с тем, чтобы определить оптимальный путь доступа в распределенной базе данных. СУРБД должна оптимизировать запрос с целью уменьшения затрат на доступ, коммуникации и загрузку центрального процессора (CPU), связанных с выполнением запроса.
При проектировании распределенных БД необходимо принимать в расчет фрагментацию и репликацию данных. Проектировщик должен решать, каким образом необходимо разместить каждый фрагмент или реплику с тем, чтобы уменьшить время отклика и гарантировать доступность данных для конечного пользователя.
База данных может быть реплицирована (тиражирована) по нескольким сайтам в компьютерной сети. Репликация фрагментов БД ставит своей целью повышение доступности данных и уменьшение времени доступа к ним. БД может быть полностью реплицированной, частично реплицированной или нереплицированной. Для определения местоположения фрагментов БД или реплик разрабатываются стратегии распределения данных.
Поставщики баз данных часто обозначают свое программное обеспечение как клиент/серверный продукт. Обозначение "архитектура «клиент/сервер»" связано со способом, которым два компьютера взаимодействуют через компьютерную сеть, формируя систему. Клиент/серверные системы приобрели широкую популярность в последние несколько лет в основном благодаря увеличению мощности мини-компьютеров, росту локальных сетей и сравнительно невысокой стоимости таких систем по сравнению с подобными решениями на базе мэйнфреймов.
Основные термины
Автоматическая оптимизация запросов — automatic query optimization
Алгоритм оптимизации запроса, основанный на правилах — rule-based query optimization algorithm
Алгоритм оптимизации, основанный на статистике — statistically based query optimization algorithm
Архитектура "клиент/сервер" — client/server architecture