Предисловие Системы управления базами данных (субд) – это программные комплексы, предназначенные для работы со специально организованными файлами (массивами данных, долговременно хранимыми во внешней памяти вычислительных систем), которые называются
| Вид материала | Документы |
- Системы управления базами данных (субд). Назначение и основные функции, 30.4kb.
- Программа курса лекций "Базы данных в научных исследованиях", 49.32kb.
- Система управления базами данных это комплекс программных и языковых средств, необходимых, 150.5kb.
- Лекция 2 Базы данных, 241.25kb.
- Любая программа для обработки данных должна выполнять три основных функции: ввод новых, 298.05kb.
- Вопросы к государственному экзамену по специальности «Информационные системы и технологии», 39.93kb.
- Лекция № Технологии баз данных, 92.24kb.
- Проектирование базы данных, 642.58kb.
- Системы управления базами данных, 313.7kb.
- Программа дисциплины Системы управления базами данных Семестры, 22.73kb.
Обзор
В этой главе мы покажем, что обычную базу данных можно разделить на несколько фрагментов. Эти фрагменты могут храниться на различных компьютерах, объединенных в сеть. Обработка данных также может распределяться по нескольким сетевым сайтам, или узлам. База данных, размещенная на нескольких узлах, представляет собой ядро распределенной системы БД.
Разработка и эксплуатация распределенных систем баз данных обусловлена, прежде всего, растущим разбросом бизнес-операций и быстрым развитием современных технологий, сделавших локальные и глобальные сети практичными и надежными. Сетевая распределенная система базы данных очень гибка: ее могут использовать как предприятия малого бизнеса, у которых имеются, например, два магазина в одном городе, так и организации сферы глобального бизнеса.
Хотя разброс базы данных в распределенной системе требует более сложной СУБД, для конечного пользователя работа с системой не должна усложниться. То есть увеличение сложности внутренней структуры распределенной системы базы данных для пользователя должно быть прозрачно.
Система управления распределенной базой данных (СУРБД) рассматривает распределенную базу данных как единую логическую базу данных; следовательно, основные концепции проектирования, которые мы рассмотрели в предыдущих главах, сохраняют свое значение. Однако несмотря на то, что конечным пользователям не нужно беспокоиться о специфических свойствах распределенной базы данных, рассредоточение данных по различным сайтам компьютерной сети несомненно увеличивает сложность системы в целом. Например, при проектировании распределенной базы данных необходимо учитывать местоположение данных и распределение данных по фрагментам БД. В этой главе мы и займемся изучением этих проблемы.
10.1 Этапы развития систем управления распределенными базами данных
Система управления распределенной базой данных (СУРБД) управляет хранением и обработкой логически связанных данных с помощью взаимосвязанных компьютерных систем, в которых как данные, так и функции обработки данных распределены по нескольким сайтам. Чтобы понять, как и чем СУРБД отличается от СУБД, мы кратко проследим развитие инфраструктуры базы данных, определившее современный этап развития СУРБД.
В 70-х годах прошлого века корпорации использовали для обработки информации централизованные системы управления базой данных. Структурированная информация обычно представлялась в виде регулярных отчетов стандартного формата. Такая информация, разработанная с помощью языков программирования третьего поколения (3GL), создавалась специалистами в ответ на точно сформулированные запросы. Таким образом, структурированная информация создавалась централизованными системами.
Доступ к данным осуществлялся через последовательно подключенные неинтеллектуальные терминалы. Централизованный подход был хорош для структурирования информации корпорации, но плохо годился для реагирования на быстро меняющиеся события, требующие немедленного отклика и быстрого доступа к информации. Длительный процесс от запроса информации до ее получения специалистом или пользователем совершенно не устраивал руководство в условиях динамически меняющихся условий. Для оперативного получения информации необходим был быстрый, незапланированный заранее доступ к базе данных с помощью нерегламентированных запросов.
Системы управления базой данных, основанные на реляционной модели, могли предоставить инфраструктуру, в которой потребность в незапланированном доступе к информации удовлетворялась с помощью нерегламентированных запросов. Конечным пользователям была предоставлена возможность получения доступа к данным в любой момент времени. К сожалению, ранние реализации реляционных моделей баз данных имели более низкую производительность по сравнению с имеющимися иерархическими и сетевыми моделями.
В 1980-е годы произошли серьезные изменения в социальной и технологической сферах, сильно повлиявшие на разработку и проектирование баз данных:
- географическая децентрализация бизнес-операций;
- рост конкуренции в глобальных масштабах;
- возросшие потребности рынка и запросы пользователей, отдающие предпочтение
децентрализованным системам управления;
- быстрое развитие технологий, приведшее к созданию недорогих микрокомпьютерных систем с возможностями мэйнфреймов. Это привело к быстрому росту числа корпораций, использующих локальные сети в качестве основы компьютеризации бизнеса. Бурному развитию локальных сетей способствовал и рост стоимости систем на основе мэйнфреймов;
- большое число приложений, основанных на СУБД, и необходимость сохранить инвестиции, сделанные в развитие централизованных СУБД, сделали идею распределения данных очень привлекательной.
Эти факторы привели к появлению динамической бизнес-среды, в которой компании могли выживать в условиях пресса конкуреции и быстрого развития технологий. По мере преобразования больших бизнес-структур в небольшие и дешевые, быстро реагирующие на запросы подразделения, использующие распределение операций, стали очевидными два требования к базе данных, входящей в такую структуру:
- возможность быстрого нерегламентированного доступа к данным в контексте
принятия оперативных решений в ответ на возникающие запросы;
- децентрализация управленческих структур, основанная на децентрализации подразделений бизнеса, требует децентрализованного коллективного доступа к распределенной базе данных.
В 1990-е годы влияние этих факторов еще более усилилось. Однако на способы реализации новых подходов сильное влияние оказали и такие важные явления:
- возрастающее признание Интернета и платформы World Wide Web (Сеть, WWW) в качестве платформы для доступа к данным и их распространения. WWW фактически стала хранилищем распределенных данных (мы рассмотрим влияние Интернета на доступ к данным и их распространение в гл. 14);
- повышенное внимание к анализу данных, что привело к появлению специфических технологий анализа информации в БД (data mining) и созданию обширных хранилищ данных (data warehouse).
С этой позиции длительное влияние Сети на проектирование и реализацию распределенных БД неочевидно. Возможно, успех Сети будет стимулировать использование распределенных БД по мере того, как пропускная способность в WWW будет становиться все более узким местом. А может быть, решение проблем с пропускной способностью поможет усилить позиции централизованных БД. В любом случае распределенные базы данных сегодня существуют, и множество их концепций и компонентов скорее всего найдут место в разработке будущих баз данных.
Децентрализованная база данных предпочтительнее централизованной, в которой имеются следующие проблемы:
- ухудшение производительности из-за возрастающего числа мест, удаленных на
большие расстояния;
- высокая стоимость, связанная с обслуживанием и поддержкой центральной базы данных, размещенной на мэйнфрейме;
- недостаточная надежность, связанная с зависимостью от центрального сайта.
Динамичность бизнеса и недостатки централизованных БД привели к появлению приложений, основанных на доступе к распределенным данным из различных мест. Базы данных, которые располагаются на нескольких сайтах, при этом доступ к хранящимся в них данным обеспечивается из различных мест, и называются распределенными базами данных. Распределенная база данных управляется системой управления распределенной базой данных (СУРБД).
10.1.1 Преимущества СУРБД
Система управления распределенной базой данных по сравнению с традиционными системами обладает рядом преимуществ:
- данные располагаются близко к наиболее востребованному сайту. Данные в распре
деленной БД распределяются в соответствии с потребностями предприятия;
- быстрый доступ к данным. Конечные пользователи часто работают только с неко
торым подмножеством данных компании. При этом подмножество может хра
ниться локально, и система базы данных обеспечит более оперативный доступ к
данным, чем централизованная БД, где данные хранятся удаленно;
- быстрая обработка данных. Система распределенной БД обеспечивает возможность обработки данных на нескольких сайтах, тем самым распределяя нагрузку системы;
- возможность роста. К сети можно добавлять новые сайты, не влияя при этом на работу других сайтов. Такая гибкость позволяет компаниям расширяться быстро и относительно просто;
- улучшение взаимодействия. Поскольку локальные сайты невелики по размеру и расположены ближе к клиентам, они обеспечивают лучшее взаимодействие между подразделениями компании, а также между клиентами и компанией в целом. Быстрая и надежная связь зачастую, помогает улучшить работу всей информаци- < онной системы. Например, при обработке локальных счетов можно использовать данные отдела сбыта напрямую, а не ждать данных из центрального офиса;
- уменьшение стоимости операций. Выгоднее добавлять рабочие станции к сети,
чем модернизировать систему, основанную на мэйнфрейме. При этом стоимость
выделенных линий связи и программного обеспечения мэйнфрейма пропорционально уменьшается. Разработка может оказаться дешевле и быстрее на недорогих персональных компьютерах, чем на мэйнфрейме. На самом деле, большинство корпораций запрещают выполнять разработки на мэйнфреймах. Эти машины,
конечно же, не устраняются из поля зрения баз данных, их мощь необходима.
Тем не менее, существование сетей персональных компьютеров позволяет распределять нагрузку более рационально и оставлять за мэйнфреймами решение более специализированных задач;
- дружественный интерфейс пользователя. Персональные компьютеры и рабочие
станции обычно имеют удобный графический интерфейс пользователя (GUI,
Graphical User Inteface). Графический интерфейс упрощает работу конечных
пользователей и их обучение;
- уменьшение опасности сбоя. В централизованной системе выход мэйнфрейма из
строя приведет к остановке всех операций. В отличие от этого, распределенная
система позволяет переместить операции с вышедшего из строя компьютера на
другой. Нагрузка системы распределяется между другими рабочими станциями системы, поскольку одно из преимуществ распределенной системы состоит в том, что данные хранятся на нескольких сайтах;
системы, поскольку одно из преимуществ распределенной системы состоит в том, что данные хранятся на нескольких сайтах;
- независимость от узла обработки данных. Конечный пользователь получает до
ступ к любой имеющейся копии данных, а запрос конечного пользователя обра
батывается любым узлом в месте расположения данных. Другими словами, за
просы не зависят от конкретного узла обработки данных: любой доступный узел
может обработать запрос пользователя.
10.1.2 Недостатки СУРБД
К сожалению, современные системы управления распределенной базой данных обладают и рядом недостатков.
- Сложность управления и контроля. Управление распределенными данными —
более трудная задача, чем управление централизованными данными. Приложения должны определять местонахождение данных и уметь затем связывать во
едино информацию, полученную с разных мест. Администраторы БД должны
иметь возможность координировать действия базы данных, чтобы предотвратить
ухудшение качества БД из-за аномалий данных. Управление транзакциями, параллельным выполнением, безопасность, резервное копирование, восстановление, оптимизация запросов, выбор путей доступа и т. д. — всему этому необходимо уделять особое внимание. Другими словами, синхронизация действий всех
компонентов распределенной базы данных — очень непростая задача.
- Безопасность. Если данные расположены в нескольких местах, то возможность
ошибок в обеспечении безопасности возрастает. Ответственность за управление
данными распределяется между различными людьми, находящимися в разных
местах, а локальные сети все же не обладают такой изощренной системой безопасности, как централизованные системы, основанные на мэйнфреймах.
- Недостаточная стандартизация. Несмотря на то что распределенные базы данных зависят от эффективности коммуникаций, пока не существует стандартный протокол обмена информацией на уровне баз данных. (Хотя TCP/IP является фактически стандартным протоколом на уровне сетей, отсутствует стандарт протокола на уровне приложений.) Фактически для протоколов распределенных баз данных имеется множество стандартов, как для коммуникаций, так и для управления доступом к данным. К примеру, производители баз данных предлагают различные (зачастую несовместимые) способы управления и обработки распределенных данных в СУРБД. Следовательно, прежде чем пользователи смогут воспользоваться всеми преимуществами распределенных баз данных, им придется подождать (и поспособствовать этому!) появления стандартных протоколов обмена данными.
- Повышенные требования к условиям хранения данных. В распределенных БД не
сколько копий данных необходимо размещать на нескольких сайтах, что требует
дополнительных ресурсов (место на жестком диске). Этот недостаток не столь
существенен, поскольку стоимость хранения информации на жестких дисках быстро уменьшается.
- Сложность управления средой данных. Организовать доступ к диску и хранение
данных в распределенной среде сложнее, чем в централизованной схеме. Поэто
му управление такой средой данных становится более сложным как с точки зре
ния человеческих ресурсов, так и с точки зрения программного обеспечения.
- Повышение стоимости обучения. Стоимость обучения в распределенной модели.
как правило, выше, чем в централизованной, и часто сравнима со стоимостью
оборудования.
В настоящее время распределенные БД с успехом эксплуатируются, но время, когда можно будет в полной мере использовать гибкость и мощь, которой они теоретически обладают, наступит еще не скоро. Присущая распределенным базам данных сложность требует безотлагательной разработки стандартов на протоколы управления транзакциями, параллельное выполнение, безопасность, резервное копирование и восстановление, оптимизацию, выбор путей доступа и т. д. На такие проблемы следует обратить самое пристальное внимание и постараться решить их до повсеместного распространения технологий СУРБД.
В оставшейся части этой главы мы исследуем основные компоненты и концепции распределенной БД. Поскольку распределенные БД, как правило, основаны на реляционной модели, при их обсуждении мы будем использовать терминологию реляционных баз данных.
10.2. Распределенная обработка данных и распределенные базы данных
При распределенной обработке данных (distributed processing) логические процессы базы данных распределяются среди двух или более физически независимых сайтов. объединенных в сеть. Например, распределенная обработка может выполнять ввод/вывод данных, выборку данных и проверку данных на одном компьютере, а затем на другом компьютере выпускать отчет на основе полученной информации.
Среда распределенной обработки данных схематически представлена на рис. 10.1. На этом рисунке показано, что система распределенной обработки данных разделяет рутинные процессы между тремя сайтами, связанными в единую сеть. Хотя база данных размещена только на одном сайте (Майами), каждый сайт может получать доступ к данным и обновлять базу данных. База данных расположена на компьютере А, который называется сервером базы данных.
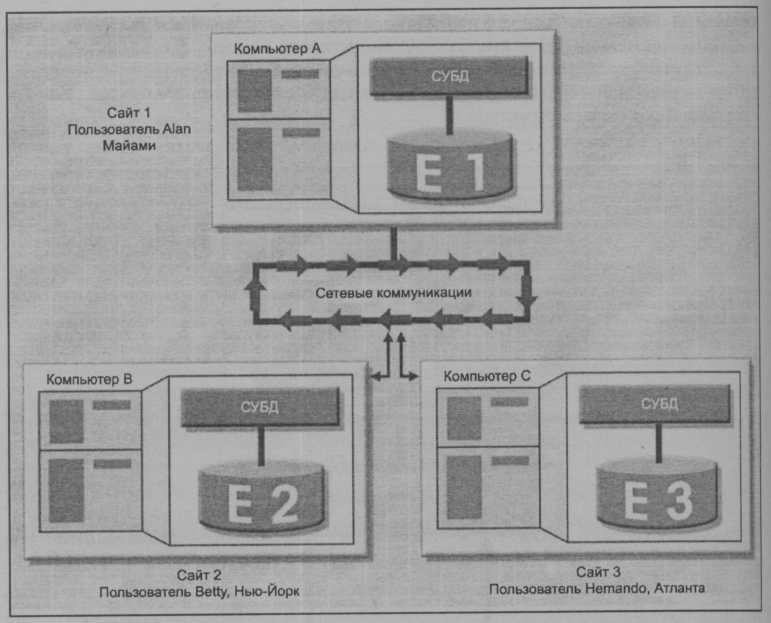
В отличие от этого распределенная база данных (distributed database) размещает логически связанную базу данных на двух или более физически независимых сайтах, связанных между собой по компьютерной сети. Система распределенной обработки использует базу данных, размещенную на отдельном сайте, а процессы обработки информации разделяются между несколькими сайтами. В распределенных системах база данных состоит из нескольких частей, которые называются фрагментами базы данных. Фрагменты БД располагаются на разных сайтах. Пример конфигурации распределенной базы данных представлен на рис. Ю.2.
База данных на рис. Ю.2 разделена на три фрагмента (El, Е2 и ЕЗ), расположенных на различных сайтах. Компьютеры соединяются друг с другом посредством локальной сети. В полностью распределенных базах данных пользователям Betty, Hernando к Alan не обязательно знать имя или местоположение каждого фрагмента для того, чтобы получить доступ к БД. К тому же пользователи могут работать на других сайгах (не только Майами, Нью-Йорк или Атланта) и получать доступ к базе данных как к логически единой структуре.
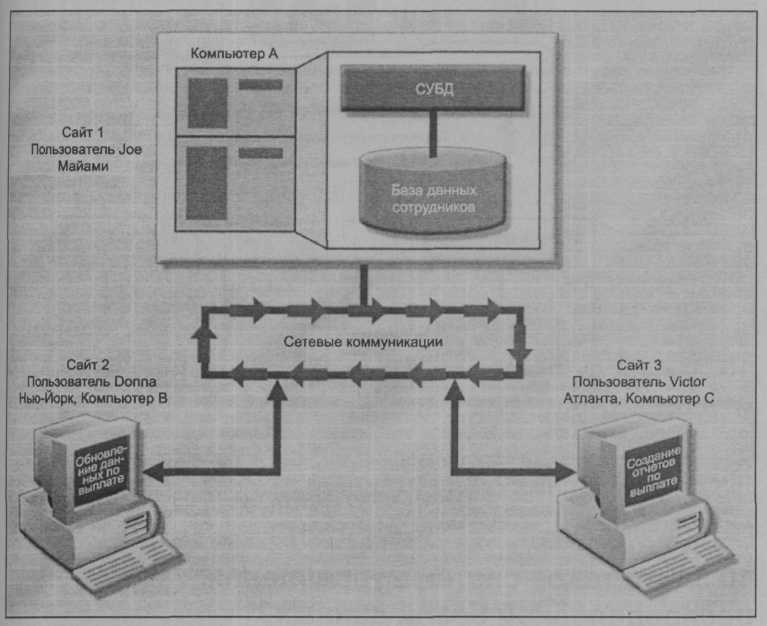
Рис. 10.1. Среда распределенной обработки данных
Если сравнить рис. 10.1 и 10.2, то необходимо обратить внимание на следующее:
- распределенная обработка данных не требует распределенной базы данных, но распределенная база данных обязательно требует распределенной обработки информации;
- распределенная обработка данных основана на единственной базе данных, размещенной на одном компьютере. Для того чтобы управлять распределенными данными, копии функций обработки базы данных или их некоторая часть должны быть распространены по всем сайтам, где хранятся данные;
- и при распределенной обработке данных, и в распределенных базах данных для связывания всех компонентов необходима локальная сеть.