
Лекция 2 Базы данных
| Вид материала | Лекция |
- Лекция 2 10. Полнотекстовые базы данных, 133.46kb.
- Лекция №3 нормализация данных, 107.45kb.
- Лекция Базы данных и субд, 299.04kb.
- Курс лекций "Базы данных и субд" Ульянов В. С. Лекция Язык sql. Создание таблиц и ограничений, 146.46kb.
- 1 научиться создавать таблицу базы данных в режиме таблицы, 54.71kb.
- Ms access Создание базы данных, 34.31kb.
- Курс лекций "Базы данных и субд" Ульянов В. С. Лекция. Манипулирование реляционными, 276.31kb.
- Практическая работа № «Создание базы данных», 21.96kb.
- Лекция Проектирование базы данных, 227.73kb.
- Информационные системы, использующие базы данных: оборудование, программное обеспечение,, 102.98kb.
Лекция 2_8. Базы данных.
Содержание темы: Понятие базы данных (БД). Место БД в системах принятия решений и управления. Возникновение и развитие технологии баз данных. Терминология теории баз данных. Понятие модели данных. Линейная, иерархическая, сетевая и реляционная модели. Понятие "ключевого поля". Концептуальная, логическая и физическая структуры базы данных. Проблемы поддержания целостности данных в БД. Понятие избыточности. Нормализация БД. Классификация БД. Системы создания и ведения БД. Понятие о системах управления базами данных (СУБД). Состав СУБД: ядро, утилиты администратора, интерфейсы пользователя, инструментарий прикладного программиста.
Электронные каталоги и документальные системы как локальные базы данных. Электронные архивы. Виды баз данных: полнотекстовая, реферативная, библиографическая, справочная. Разновидности делопроизводственных баз данных (на основе регистрационной информации; с включением полного текста документов; с включением образов документов). Регистрационные карты документов.
История развития СУБД насчитывает более 30 лет. В 1968 году была введена в эксплуатацию первая промышленная СУБД система IMS фирмы IBM. В 1975 году появился первый стандарт ассоциации по языкам систем обработки данных — Conference of Data System Languages (CODASYL), который определил ряд фундаментальных понятий в теории систем баз данных, которые и до сих пор являются основополагающими для сетевой модели данных.
В дальнейшее развитие теории баз данных большой вклад был сделан американским математиком Э. Ф. Коддом, который является создателем реляционной модели данных. В 1981 году Э. Ф. Кодд получил за создание реляционной модели и реляционной алгебры престижную премию Тьюринга Американской ассоциации по вычислительной технике.
Можно выделить четыре этапа в развитии данного направления в обработке данных. Жестких временных ограничений в этих этапах: они плавно переходят один в другой и даже сосуществуют параллельно.
Первый этап развития СУБД связан с организацией баз данных на больших машинах типа IBM 360/370, ЕС-ЭВМ и мини-ЭВМ типа PDP11 (фирмы Digital Equipment Corporation — DEC), разных моделях HP (фирмы Hewlett Packard).
Особенности этого этапа развития выражаются в следующем:
- Все СУБД базируются на мощных мультипрограммных операционных системах (MVS, SVM, RTE, OSRV, RSX, UNIX), поэтому в основном поддерживается работа с централизованной базой данных в режиме распределенного доступа.
- Функции управления распределением ресурсов в основном осуществляются операционной системой (ОС).
- Поддерживаются языки низкого уровня манипулирования данными, ориентированные на навигационные методы доступа к данным.
- Значительная роль отводится администрированию данных.
- Проводятся работы по обоснованию и формализации реляционной модели данных, и была создана первая система (System R), реализующая идеологию реляционной модели данных.
- Проводятся теоретические работы по оптимизации запросов и управлению распределенным доступом к централизованной БД, было введено понятие транзакции (Транза́кция (англ. transaction) — группа последовательных операций, которая представляет из себя логическую единицу работы с данными. Транзакция может быть выполнена целиком либо успешно, соблюдая целостность данных и независимо от параллельно идущих других транзакций, либо не выполнена вообще и тогда она не должна произвести никакого эффекта).
Второй этап - эпоха персональных компьютеров. Особенности этого этапа следующие:
- Все СУБД были рассчитаны на создание БД в основном с монопольным доступом.
- Большинство СУБД имели развитый и удобный пользовательский интерфейс. В большинстве существовал интерактивный режим работы с БД как в рамках описания БД, так и в рамках проектирования запросов. Большинство СУБД предлагали развитый и удобный инструментарий для разработки готовых приложений без программирования. Инструментальная среда состояла из готовых элементов приложения в виде шаблонов экранных форм, отчетов, этикеток (Labels), графических конструкторов запросов, которые достаточно просто могли быть собраны в единый комплекс.
- Во всех настольных СУБД поддерживался только внешний уровень представления реляционной модели, то есть только внешний табличный вид структур данных.
- При наличии высокоуровневых языков манипулирования данными типа реляционной алгебры и SQL в настольных СУБД поддерживались низкоуровневые языки манипулирования данными на уровне отдельных строк таблиц.
- В настольных СУБД отсутствовали средства поддержки ссылочной и структурной целостности базы данных. Эти функции должны были выполнять приложения, однако скудость средств разработки приложений иногда не позволяла это сделать, и в этом случае эти функции должны были выполняться пользователем, требуя от него дополнительного контроля при вводе и изменении информации, хранящейся в БД.
- Наличие монопольного режима работы фактически привело к вырождению функций администрирования БД и в связи с этим — к отсутствию инструментальных средств администрирования БД.
- И, наконец, последняя и в настоящий момент весьма положительная особенность — это сравнительно скромные требования к аппаратному обеспечению со стороны настольных СУБД. Вполне работоспособные приложения, разработанные, например, на Clipper, работали на PC 286. Яркие представители этого семейства — очень широко использовавшиеся до недавнего времени СУБД Dbase (DbaseIII+, DbaselV), FoxPro, Clipper, Paradox.
Третий этап - распределенные базы данных. Особенности данного этапа:
- Практически все современные СУБД обеспечивают поддержку полной реляционной модели, а именно:
- структурной целостности — допустимыми являются только данные, представленные в виде отношений реляционной модели;
- языковой целостности, то есть языков манипулирования данными высокого уровня (в основном SQL);
- ссылочной целостности, контроля за соблюдением ссылочной целостности в течение всего времени функционирования системы, и гарантий невозможности со стороны СУБД нарушить эти ограничения.
- структурной целостности — допустимыми являются только данные, представленные в виде отношений реляционной модели;
- Большинство СУБД рассчитаны на многоплатформенную архитектуру, то есть они могут работать на компьютерах с разной архитектурой и под разными операционными системами, при этом для пользователей доступ к данным, управляемым СУБД на разных платформах, практически неразличим.
- Содержат развитые средства администрирования БД с реализацией общей концепции средств защиты данных.
- Все СУБД имеют средства подключения клиентских приложений, разработанных с использованием настольных СУБД, и средства экспорта данных из форматов настольных СУБД второго этапа развития.
- Разработка ряда стандартов в рамках языков описания и манипулирования данными начиная с SQL89, SQL92, SQL99 и технологий по обмену данными между различными СУБД, к которым можно отнести и протокол ODBC (Open DataBase Connectivity), предложенный фирмой Microsoft.
Четвертый этап - появление новой технологии доступа к данным — интранет.
Основное отличие этого подхода от технологии клиент-сервер состоит в том, что:
- Отпадает необходимость использования специализированного клиентского программного обеспечения. Для работы с удаленной базой данных используется стандартный броузер Интернета, например Microsoft Internet Explorer или Netscape Navigator, и для конечного пользователя процесс обращения к данным происходит аналогично скольжению по Всемирной Паутине.
- При этом встроенный в загружаемые пользователем HTML-страницы код, написанный обычно на языке Java, Java-script, Perl и других, отслеживает все действия пользователя и транслирует их в низкоуровневые SQL-запросы к базе данных, выполняя, таким образом, ту работу, которой в технологии клиент-сервер занимается клиентская программа.
- Простые задачи обработки данных, не связанные со сложными алгоритмами, требующими согласованного изменения данных во многих взаимосвязанных объектах, достаточно просто и эффективно могут быть построены по данной архитектуре. В этом случае для подключения нового пользователя к возможности использовать данную задачу не требуется установка дополнительного клиентского программного обеспечения.
Одними из основополагающих в концепции баз данных являются обобщенные категории «данные» и «модель данных».
Понятие «данные» в концепции баз данных — это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Примеры данных: Петров Николай Степанович, $30 и т. д.
Банк данных (БнД) — это система специальным образом организованных данных — баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
База данных (БД) — именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области.
Системы поддержки принятия решений —эти системы дают возможность преобразовывать обширную информацию в ясные и полезные выводы. Сбор, обслуживание и анализ больших объемов данных, — это гигантские задачи, которые требуют преодоления серьезных технических трудностей, огромных затрат и адекватных организационных решений.
Система поддержки принятия решений — сложная структура с многочисленными компонентами. Прежде чем создавать систему, которая предоставит такую информацию, нужно рассмотреть и решить три основных вопроса:
- какие данные накапливать и как на концептуальном уровне моделировать данные и управлять их хранением;
- как анализировать данные;
- как эффективно загрузить данные из нескольких независимых источников.
Эти вопросы тесно связаны с такими понятиями: сервер хранилища данных, инструментарий оперативной аналитической обработки и добычи данных и инструменты для пополнения хранилища данных.
- Хранилища данных (data warehouse) содержат информацию, собранную из нескольких оперативных баз данных. Хранилища данных создаются специально и предоставляют накопленные за определенное время сводные и консолидированные данные, которые более приемлемы для анализа, чем детальные индивидуальные записи. Рабочая нагрузка состоит из нестандартных, сложных запросов, которые обращаются к миллионам записей и выполняют огромное количество операций сканирования, соединения и агрегирования. Время ответа на запрос в данном случае важнее, чем пропускная способность.
- Инструментарий оперативной аналитической обработки и добычи данных позволяет проводить развернутый анализ информации.
- Базовые инструменты — средства извлечения, преобразования и загрузки — служат для пополнения хранилища из внешних источников данных.
Структура базы данных тесно связана с понятием модели данных. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных – это совокупность структур данных и операций их обработки. Каждая СУБД поддерживает ту или иную модель данных. Модель задает:
- основную структурную единицу, т.е. определяет логическую структуру данных (так называемая структурная часть модели);
- набор операций для манипулирования этими структурами (манипуляционная часть);
- ограничения целостности (целостная часть) - набор ограничительных правил, накладываемых на данные базы данных.
По способу организации данных СУБД основываются на использовании четырех основных видах моделей:
- Иерархическая
- Сетевая
- Реляционная
- Объектная
Исторически первыми появились иерархическая и сетевая модели, это так называемые ранние модели. Реляционная модель появилась позже.
Иерархическая модель данных (ИБД) - это всевозможные классификаторы, ускоряющие поиск требуемой информации, иерархические функциональные структуры управления. Иерархическая модель является естественной структурой для представления информационных объектов, связанных иерархическими отношениями часть - целое, род - вид, начальник - подчинённый.
Иерархическая модель данных использует представление данных в виде деревьев. Основной структурной единицей иерархической модели данных является дерево. Дерево - это связный неориентированный граф, который не содержит циклов (петель) из замкнутых путей. Граф состоит их набора вершин и дуг. Вершина используется для представления сущностей реального мира. Сущность – это объект реального мира, информацию о котором необходимо хранить в базе данных. Посредством дуги осуществляется представление связей между сущностями. При реализации вершины представляются таблицами.
Обычно при работе с деревом выделяют конкретную вершину, которую определяют как корень дерева. В этом случае дерево становится ориентированным.
Листья – это вершины, которые не имеют поддеревьев.
Тип дерева – задает структуру дерева.
Экземпляр дерева – дерево, структура которого строится строго в соответствии со своим типом дерева.
Д
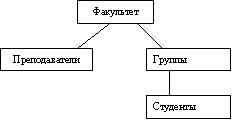 ля иерархической модели данных важным является то, что никакой потомок (узел в дереве) не может иметь более одного предка (узла дерева).
ля иерархической модели данных важным является то, что никакой потомок (узел в дереве) не может иметь более одного предка (узла дерева). Таким образом, иерархическая база данных состоит из упорядоченного набора нескольких экземпляров одного типа дерева. Например, в структуре учебного заведения можно выделить основные сущности, которые изображены в виде вершин графа и дуг, отображающих связи между ними.
О
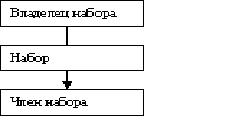 тличие сетевой модели данных (СБД) от иерархической заключается в том, что в сетевой структуре любой элемент данных может быть связан с любым другим, т.е. сетевая модель есть расширение иерархической модели, в которой каждый потомок может иметь любое количество предков.
тличие сетевой модели данных (СБД) от иерархической заключается в том, что в сетевой структуре любой элемент данных может быть связан с любым другим, т.е. сетевая модель есть расширение иерархической модели, в которой каждый потомок может иметь любое количество предков. Сетевая модель, так же как и иерархическая, использует графовое и табличное представление. Основная конструкция сетевой модели данных CODASYL – набор. Набор – это поименованное двухуровневое дерево, которое реализует связь между записями двух типов: владельцем набора и членом набора. Разрешаются только связи один ко многим.
Основные свойства набора:
- Набор имеет имя;
- В каждом наборе только один владелец;
- В каждом наборе 0,1 или несколько членов;
- Набор существует, если только существует запись-владелец;
- Экземпляр записи может входить только в один экземпляр набора данного типа;
- В общем случае каждый набор – это вход в БД.
С помощью наборов можно строить многоуровневые деревья и простые сетевые структуры. Так как роль записи жестко не фиксируется, то в одном наборе она может быть членом, а в другом владельцем.
В
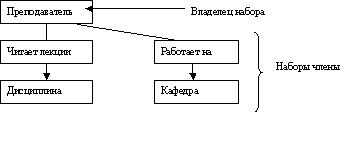 сетевых моделях реальных СУБД запись может иметь любую структуру, например простую линейную, как в реляционных СУБД, либо более сложную, включая массивы, повторяющиеся группы.
сетевых моделях реальных СУБД запись может иметь любую структуру, например простую линейную, как в реляционных СУБД, либо более сложную, включая массивы, повторяющиеся группы. Например, на данном рисунке представлены два набора, владельцем обоих набором является Преподаватель.
Основы реляционной модели данных были впервые изложены в статье Е.Кодда в 1970 г. Эта работа послужила стимулом для большого количества статей и книг, в которых реляционная модель получила дальнейшее развитие. Наиболее распространенная трактовка реляционной модели данных принадлежит К.Дейту. Согласно Дейту, реляционная модель состоит из трех частей:
- Структурной части
- Целостной части
- Манипуляционной части
Структурная часть описывает, какие объекты рассматриваются реляционной моделью. Постулируется, что единственной структурой данных, используемой в реляционной модели, являются нормализованные n-арные отношения.
Целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность внешних ключей.
Манипуляционная часть описывает два эквивалентных способа манипулирования реляционными данными - реляционную алгебру и реляционное исчисление.
В теории реляционных баз данных сформулированы основные принципы, которым должны удовлетворять правильно спроектированные таблицы, составляющие основу базы данных. Первый из этих принципов заключается в том, что все записи таблицы должны быть уникальны, т.е. в ней не должны содержаться две записи, в которых совпадают значения всех полей.
Чтобы в проектируемой таблице не возникало такой проблемы, необходимо ввести в ее структуру поле (или совокупность полей), значение которого (или которых) однозначно идентифицирует объект, информация о котором хранится в базе данных. Такое поле (совокупность полей) называется ключевым полем (или первичным ключом) таблицы реляционной базы данных.
Ключевое поле — это одно или несколько полей, комбинация значений которых однозначно определяет каждую запись в таблице. Таким образом предотвращается дублирование или ввод пустых значений в ключевое поле. Ключевые поля используются для быстрого поиска и связи данных из разных таблиц при помощи запросов, форм и отчетов. Выделяют три типа ключевых полей: счетчик, простой ключ и составной ключ.
Если до сохранения созданной таблицы ключевые поля не были определены, то при сохранении будет выдано сообщение о создании ключевого поля. При нажатии кнопки Да (Yes) будет создано ключевое поле счетчика с именем Код (ID) и типом данных Счетчик (AutoNumber).
Для создания простого ключа достаточно иметь поле, которое содержит уникальные значения (например, коды или номера). Если выбранное поле содержит повторяющиеся или пустые значения, его нельзя определить как ключевое.
Составной ключ необходим в случае, если невозможно гарантировать уникальность записи с помощью одного поля. Он представляет собой комбинацию нескольких полей.
Объектная модель данных, интегрируя все возможности реляционной модели, обладает рядом существенных преимуществ по сравнению с последней. Эти преимущества заключаются, прежде всего, в способности естественным образом интегрировать в рамках единого информационного массива разнородные данные. Среди других преимуществ можно выделить возможность создания информационных моделей разнообразных трудно формализуемых предметных областей реального мира, а также существенного повышения аналитических возможностей банков данных, реализованных на основе объектной модели.
Основные преимущества объектной модели данных сводятся к следующему.
- Возможность описывать в рамках единого информационного поля объекты, имеющие разнородную внутреннюю структуру и состав элементов.
- Установление сложных многоуровневых отношений между информационными объектами, в том числе типа “один к одному”, “один ко многим”, “многие к одному” и “многие ко многим”.
- “Вложение” объектов друг в друга, выделение общих свойств объектов на верхних уровнях и учет индивидуальных качеств и свойств объектов на нижних уровнях иерархии.
- Возможность хранить в едином банке данных структурированную информацию и неформализованные данные.
Основными структурными единицами объектной модели являются классы и объекты. Класс – это тип, в соответствии с которым строятся конкретные экземпляры объектов. Объект – это экземпляр конкретного класса. Объект состоит из данных и программного кода.
В последнее время появляется все больше объектных и объектно-ориентированных СУБД, таких как Versant, Jasmine, ODB-Jupiter, Caché и др., которые приобретают все большую популярность и признание.
Одним из основополагающих понятий в технологии баз данных является понятие целостности. Целостность даных означает систему правил, используемых для поддержания связей между записями в связанных таблицах, а также для обеспечения защиты от случайного удаления или изменения связанных данных.
Поддержка целостности в реляционной модели данных в ее классическом понимании включает в себя три аспекта.
- Поддержка структурной целостности - реляционная СУБД должна допускать работу только с однородными структурами данных типа «реляционное отношение». При этом понятие «реляционного отношения» должно удовлетворять всем ограничениям, накладываемым на него в классической теории реляционной БД (отсутствие дубликатов записей, соответственно обязательное наличие первичного ключа).
- Поддержка языковой целостности, которая состоит в том, что реляционная СУБД должна обеспечивать языки описания и манипулирования данными не ниже стандарта SQL. He должны быть доступны иные низкоуровневые средства манипулирования данными, не соответствующие стандарту.
- В-третьих, это поддержка ссылочной целостности (Declarative Referential Integrity, DRI), означает обеспечение одного из следующих принципов взаимосвязи между экземплярами взаимосвязанных отношений:
- записи подчиненного отношения уничтожаются при удалении главной записи, связанной с ними.
- записи основного отношения модифицируются при удалении записи основного отношения, связанного с ними, при этом на месте ключа родительского отношения ставится неопределенное Null значение.
Ссылочная целостность обеспечивает поддержку непротиворечивого состояния БД в процессе модификации данных при выполнении операций добавления или удаления.
Кроме указанных ограничений целостности, которые в общем виде не определяют семантику БД, вводится понятие семантической поддержки целостности. Семантическая поддержка может быть обеспечена двумя путями: декларативным и процедурным путем.
Декларативный путь связан с наличием механизмов в рамках СУБД, обеспечивающих проверку и выполнение ряда декларативно заданных правил-ограничений, называемых чаще всего «бизнес-правилами» (Business Rules). Виды декларативных ограничений целостности:
1. Ограничения целостности атрибута:
- значение по умолчанию,
- задание обязательности или необязательности значений (Null),
- задание условий па значения атрибутов.
2. Ограничения целостности, задаваемые на уровне доменов (при поддержке доменной структуры). Эти ограничения удобны, если в базе данных присутствуют несколько столбцов разных отношений, которые принимают значения из одного и того же множества допустимых значений. Некоторые СУБД поддерживают подобную доменную структуру, то есть разрешают определять отдельно домены, задавать тип данных для каждого домена и задавать соответственно ограничения в виде бизнес-правил для доменов. А для атрибутов задается не примитивный первичный тип данных, а их принадлежность тому или другому домену.
3. Ограничения целостности, задаваемые на уровне отношения. Некоторые семантические правила невозможно преобразовать в выражения, которые будут применимы только к одному столбцу.
4. Ограничения целостности, задаваемые на уровне связи между отношениями:
- задание обязательности связи,
- принципов каскадного удаления и каскадного изменения данных,
- задание поддержки ограничений по мощности связи.
Эти виды ограничений могут быть выражены заданием обязательности или необязательности значений внешних ключей во взаимосвязанных отношениях.
Избыточные данные могут присутствовать в атрибутах, представляющих одну и ту же концепцию, но по-разному поименованных, или в повторяющихся группах.
Главная цель нормализации базы данных - устранение избыточности и дублирования информации. В идеале при нормализации надо добиться, чтобы любое значение хранилось в базе в одном экземпляре, причем значение это не должно быть получено расчетным путем из других данных, хранящихся в базе.
Теория нормализации реляционных баз данных была разработана в конце 70-х годов 20 века. Согласно ей, выделяются шесть нормальных форм, пять из которых так и называются: первая, вторая, третья, четвертая, пятая нормальная форма, а также нормальная форма Бойса-Кодда, лежащая между третьей и четвертой.
База данных считается нормализованной, если ее таблицы (по крайней мере, большинство таблиц) представлены как минимум в третьей нормальной форме.
Первая нормальная форма:
- запрещает повторяющиеся столбцы (содержащие одинаковую по смыслу информацию)
- запрещает множественные столбцы (содержащие значения типа списка и т.п.)
- требует определить первичный ключ для таблицы, то есть тот столбец или комбинацию столбцов, которые однозначно определяют каждую строку
Вторая нормальная форма требует, чтобы неключевые столбцы таблиц зависели от первичного ключа в целом, но не от его части. Маленькая ремарочка: если таблица находится в первой нормальной форме и первичный ключ у нее состоит из одного столбца, то она автоматически находится и во второй нормальной форме.
Чтобы таблица находилась в третьей нормальной форме, необходимо, чтобы неключевые столбцы в ней не зависели от других неключевых столбцов, а зависели только от первичного ключа. Самая распространенная ситуация в данном контексте - это расчетные столбцы, значения которых можно получить путем каких-либо манипуляций с другими столбцами таблицы. Для приведения таблицы в третью нормальную форму такие столбцы из таблиц надо удалить.
Нормальная форма Бойса-Кодда требует, чтобы в таблице был только один потенциальный первичный ключ. Чаще всего у таблиц, находящихся в третьей нормальной форме, так и бывает, но не всегда. Если обнаружился второй столбец (комбинация столбцов), позволяющий однозначно идентифицировать строку, то для приведения к нормальной форме Бойса-Кодда такие данные надо вынести в отдельную таблицу.
Для приведения таблицы, находящейся в нормальной форме Бойса-Кодда, к четвертой нормальной форме необходимо устранить имеющиеся в ней многозначные зависимости. То есть обеспечить, чтобы вставка / удаление любой строки таблицы не требовала бы вставки / удаления / модификации других строк этой же таблицы.
Таблицу, находящуюся в четвертой нормальной форме и, казалось бы, уже нормализованную до предела, в некоторых случаях еще можно бывает разбить на три или более (но не на две!) таблиц, соединив которые, мы получим исходную таблицу. Получившиеся в результате такой, как правило, весьма искусственной, декомпозиции таблицы и называют находящимися в пятой нормальная форме. Формальное определение пятой нормальной формы таково: это форма, в которой устранены зависимости соединения. В большинстве случаев практической пользы от нормализации таблиц до пятой нормальной формы не наблюдается.
Классификация баз данных:
- По характеру хранимой информации:
— Фактографические (картотеки),
— Документальные (архивы)
- По способу хранения данных:
— Централизованные (хранятся на одном компьютере),
— Распределенные (используются в локальных и глобальных компьютерных сетях).
- По структуре организации данных:
— Табличные (реляционные),
— Иерархические,
Среди наиболее ярких представителей систем управления базами данных можно отметить: Lotus Approach, Microsoft Access, Borland dBase, Borland Paradox, Microsoft Visual FoxPro, Microsoft Visual Basic, а также баз данных Microsoft SQL Server и Oracle, используемые в приложениях, построенных по технологии «клиент-сервер».
Общепринятыми также являются технологи, позволяющие использовать возможности других приложений, например, текстовых процессоров, пакетов построения графиков и т.п., и встроенные версии языков высокого уровня (чаще – диалекты SQL и/или VBA) и средства визуального программирования интерфейсов разрабатываемых приложений. Поэтому уже не имеет существенного значения на каком языке и на основе какого пакета написано конкретное приложение, и какой формат данных в нем используется.
Более того, стандартом «де-факто» стала «быстрая разработка приложений» или RAD (от английского Rapid Application Development), основанная на широко декларируемом в литературе «открытом подходе», то есть необходимость и возможность использования различных прикладных программ и технологий для разработки более гибких и мощных систем обработки данных.
Поэтому в одном ряду с «классическими» СУБД все чаще упоминаются языки программирования Visual Basic 4.0 и Visual C++, которые позволяют быстро создавать необходимые компоненты приложений, критичные по скорости работы, которые трудно, а иногда невозможно разработать средствами «классических» СУБД. Современный подход к управлению базами данных подразумевает также широкое использование технологии «клиент-сервер».
Таким образом, на сегодняшний день разработчик не связан рамками какого-либо конкретного пакета, а в зависимости от поставленной задачи может использовать самые разные приложения. Поэтому, более важным представляется общее направление развития СУБД и других средств разработки приложений в настоящее время.
Программы, с помощью которых пользователи работают с базой данных, называются приложениями. В общем случае с одной базой данных могут работать множество различных приложений.
При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в базе данных, вносимые другими приложениями.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации БД, изображенная на рисунке:
- Уровень внешних моделей — самый верхний уровень, где каждая модель имеет свое «видение» данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров.
- К
 онцептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира.
онцептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира.
- Физический уровень — собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации.
Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных. Это именно то, чего не хватало при использовании файловых систем.
Системой управления базами данных называют программную систему, предназначенную для создания на ЭВМ общей базы данных, используемой для решения множества задач. Подобные системы служат для поддержания базы данных в актуальном состоянии и обеспечивают эффективный доступ пользователей к содержащимся в ней данным в рамках предоставленных пользователям полномочий.
По степени универсальности различают два класса СУБД:
- системы общего назначения;
- специализированные системы.
СУБД общего назначения не ориентированы на какую-либо предметную область или на информационные потребности какой-либо группы пользователей. СУБД общего назначения — это сложные программные комплексы, предназначенные для выполнения всей совокупности функций, связанных с созданием и эксплуатацией базы данных информационной системы.
Каждая система такого рода реализуется как программный продукт, способный функционировать на некоторой модели ЭВМ в определенной операционной системе и поставляется многим пользователям как коммерческое изделие. Такие СУБД обладают средствами настройки на работу с конкретной базой данных. Использование СУБД общего назначения в качестве инструментального средства для создания автоматизированных информационных систем, основанных на технологии баз данных, позволяет существенно сокращать сроки разработки, экономить трудовые ресурсы. Этим СУБД присущи развитые функциональные возможности и даже определенная функциональная избыточность.
Специализированные СУБД создаются в редких случаях при невозможности или нецелесообразности использования СУБД общего назначения.
Используемые в настоящее время СУБД обладают средствами обеспечения целостности данных и надежной безопасности, что дает возможность разработчикам гарантировать большую безопасность данных при меньших затратах сил на низкоуровневое программирование.
Основными СУБД являются:
- dBASE IV компании Borland International;
- Microsoft Access ;
- Microsoft FoxPro;
- Paradox;
- Clipper.
Логически в современной реляционной СУБД можно выделить наиболее внутреннюю часть - ядро СУБД (часто его называют Data Base Engine), компилятор языка БД (обычно SQL), подсистему поддержки времени выполнения, набор утилит. В некоторых системах эти части выделяются явно, в других - нет, но логически такое разделение можно провести во всех СУБД.
Ядро СУБД отвечает за управление данными во внешней памяти, управление буферами оперативной памяти, управление транзакциями и журнализацию. Соответственно можно выделить такие компоненты ядра (по крайней мере, логически, хотя в некоторых системах эти компоненты выделяются явно), как менеджер данных, менеджер буферов, менеджер транзакций и менеджер журнала.
Ядро СУБД обладает собственным интерфейсом, не доступным пользователям напрямую и используемым в программах, производимых компилятором SQL (или в подсистеме поддержки выполнения таких программ), и утилитах БД. Ядро СУБД является основной резидентной частью СУБД. При использовании архитектуры "клиент-сервер" ядро является основным составляющим серверной части системы.
Основная функция компилятора языка БД - компиляция операторов языка БД в некоторую выполняемую программу.
Основной проблемой реляционных СУБД является то, что языки этих систем (а это, как правило, SQL) являются непроцедурными, т.е. в операторе такого языка специфицируется некоторое действие над БД, но эта спецификация не процедура, она лишь описывает в некоторой форме условия совершения желаемого действия. Поэтому компилятор должен решить, каким образом выполнять оператор языка, прежде чем произвести программу. Применяются достаточно сложные методы оптимизации операторов.
Результатом компиляции является выполняемая программа, представляемая в некоторых системах в машинных кодах, но более часто в выполняемом внутреннем машинно-независимом коде. В последнем случае реальное выполнение оператора производится с привлечением подсистемы поддержки времени выполнения, представляющей собой, по сути дела, интерпретатор этого внутреннего языка.
Наконец, в отдельные утилиты БД обычно выделяют такие процедуры, которые слишком накладно выполнять с использованием языка БД, например, загрузка и разгрузка БД, сбор статистики, глобальная проверка целостности БД и т.д. Утилиты программируются с использованием интерфейса ядра СУБД, а иногда даже с проникновением внутрь ядра.
Виртуальная среда, обеспечивающая быстрый и надежный доступ к ресурсам из любой точки планеты, явилась катализатором развития различных форм электронного бизнеса. Одними из первых оценили преимущества Интернет компании, специализирующиеся на производстве и продаже различного рода баз данных. Созданием подобных баз с начала 80-х годов занималось множество зарубежных корпораций, главным продуктом которых была информация.
Существовали фактографические базы данных, содержащие фактические сведения (прежде всего статистику), библиографическую информацию (сведения о документах) и полнотекстовые (полные тексты книг и статей из газет, журналов и сборников).
Российские коммерческие полнотекстовые базы данных
Научная Электронная Библиотека (elibrary.ru): включены полные тексты книг и журналов, публикуемых известнейшими зарубежными издательствами, среди которых Blackwell, Kluwer, Elsevier, Springer, Royal Society of Chemistry, ISI (Институт научной информации), а также полтора десятка российских академических журналов. В общей сложности в библиотеку включено более 3700 названий журналов, содержащих, в общей сложности, более 5 миллионов статей.
Интегрум-Техно (www.integrum.ru или www.integrum.com): среди представленных баз данных архивы центральной, региональной и зарубежной прессы, сообщения агентств новостей, текстовые транскрипты передач радио и телевидения, тексты законов, данные Госкомстата России, электронные каталоги библиотек, сведения о патентах, адресные справочники, фотоархив и многие другие источники. Всего в настоящее время представлено более 4.5 тысяч баз данных, в совокупности включающих порядка 230 миллионов документов.
Публичная библиотека (www.public.ru): проект предназначен прежде всего для библиотек, которым предлагается оформить подписку на электронные версии российских центральных и региональных периодических изданий. Публичная библиотека дает возможность бесплатного библиографического поиска - "Открытый доступ" и возможность пользования полными текстами статей - "Профессиональный поиск". В настоящее время интерфейс поисковой системы и большинство модулей нуждаются в серьезной доработке. Интерес в данном проекте представляют архивы периодики за старые годы: некоторые издания представлены в виде полных текстов с 1990 года.
EastView (www.eastview.com или www.ebiblioteka.ru): Находясь в зарубежной собственности, EastView, тем не менее, концентрирует основное внимание на российских источниках. В составе базы данных центральные и региональные российские газеты, государственные стандарты, журналы Российской Академии наук, художественно-публицистические (толстые) журналы России, карты, статистические источники, материалы агентств новостей, а также периодика Украины и некоторых стран СНГ.
Всего на настоящее время в базу данных включены полные тексты более чем 500 российских газет и журналов, а также более 70 украинских периодических изданий. Система по умолчанию имеет англоязычный интерфейс, а описания источников приводятся в транслитерации. В ряде случаев можно получить вариант записей на русском языке.
Для библиотекарей и лиц из числа профессорско-преподавательского состава предоставляется бесплатный пробный доступ сроком на 30-дней.
Индивидуальные регистрационные карты служат выполнению нескольких задач:
- обеспечивают сбор данных;
- обеспечивают удовлетворение требований органов контрольно-разрешительной системы для сбора информации;
- способствуют эффективной и полной обработке данных, их анализу и отчётности по результатам; способствуют обмену данными по безопасности среди проектной группы и других подразделений организации.