
Предисловие Системы управления базами данных (субд) – это программные комплексы, предназначенные для работы со специально организованными файлами (массивами данных, долговременно хранимыми во внешней памяти вычислительных систем), которые называются
| Вид материала | Документы |
- Системы управления базами данных (субд). Назначение и основные функции, 30.4kb.
- Программа курса лекций "Базы данных в научных исследованиях", 49.32kb.
- Система управления базами данных это комплекс программных и языковых средств, необходимых, 150.5kb.
- Лекция 2 Базы данных, 241.25kb.
- Любая программа для обработки данных должна выполнять три основных функции: ввод новых, 298.05kb.
- Вопросы к государственному экзамену по специальности «Информационные системы и технологии», 39.93kb.
- Лекция № Технологии баз данных, 92.24kb.
- Проектирование базы данных, 642.58kb.
- Системы управления базами данных, 313.7kb.
- Программа дисциплины Системы управления базами данных Семестры, 22.73kb.
Архитектура СУБД
Говоря о том, каким должен быть столь сложный программный продукт, как СУБД, прежде всего необходимо четко обусловить основную концепцию системы, определяющую все последующие этапы ее разработки.
Основные положения этой концепции:
- архитектура СУБД должна обеспечивать, в первую очередь, разграничение пользовательского и системного уровней;
- необходимо дать возможность каждому пользователю иметь свое, отличное от других представление о свойствах хранимых данных.
Тогда начальной стадией проектирования любой конкретной информационной системы должны являться абстрактные описания информационных потребностей каждой группы пользователей, на основе которых генерируется также абстрактное, но уже общее для всей организации описание структур хранимых данных, а СУБД, посредством которой эта ИС будет создаваться и поддерживаться, обязана иметь для этого определенные возможности.
Трехуровневая архитектура базы данных
Как уже указывалось, одним из важнейших аспектов развития СУБД стала идея отделения логической структуры БД и манипуляций данными, необходимых пользователям, от физического представления, требуемого компьютерным оборудованием. И идея эта должна быть заложена в фундамент, на котором будет строиться все здание информационной системы.
В этом подразделе будет рассмотрена та архитектура БД, которая уже четверть века официально признана и с достаточной точностью описывает большинство существующих систем. Однако это не означает, что современный рынок программных продуктов предлагает только-системы, строго следующие этой архитектуре как единственно возможной. Рассматривая конкретные системы управления данными, иногда можно заметить отсутствие поддержки некоторых аспектов данной архитектуры.
Одна и та же БД в зависимости от точки зрения может иметь различные уровни описания. По числу уровней описания данных, поддерживаемых СУБД, различают одно-, двух- и трехуровневые системы. В настоящее время чаще всего поддерживается трехуровневая архитектура описания БД (рис. 2.1), с тремя уровнями абстракции, на которых можно рассматривать базу данных. Такая архитектура включает:
- внешний уровень, на котором пользователи воспринимают данные, где отдельные группы пользователей имеют свое представление (ПП) на базу данных;
- внутренний уровень, на котором СУБД и операционная система воспринимают данные;
- концептуальный уровень представления данных, предназначенный для отображения внешнего уровня на внутренний уровень, а также для обеспечения необходимой их независимости друг от друга; он связан с обобщенным представлением пользователей.
Данная архитектура СУБД вызревала не сразу, а постепенно, в течение ряда лет. Первые предложения поступили в 1971 году от рабочей группы CODASYL (Conference on Data Systems and Languages — Конференция по языкам и системам данных), которая обосновала необходимость использования двухуровневого подхода, построенного на основе выделения системного представления и пользовательских представлений.
В 1975 году Комитет планирования стандартов и норм SPARC (Standards Planning and Requirements Committee) Американского национального института стандартов ANSI (American National Standards Institute) предложил обобщенную структуру систем баз данных, признав необходимость использования трехуровневой архитектуры, которая и была официально признана в 1978 году.
Описание структуры данных на любом уровне называется схемой. Существует три различных типа схем базы данных, которые определяются в соответствии с уровнями абстракции трехуровневой архитектуры. На самом высоком уровне имеется несколько внешних схем или подсхем, которые соответствуют разным представлениям данных. На концептуальном уровне описание базы данных называют концептуальной схемой, а на самом низком уровне абстракции — внутренней схемой.
Основным назначением трехуровневой архитектуры является обеспечение независимости от данных. Суть этой независимости заключается в том, что изменения на нижних уровнях никак не влияют на верхние уровни. Различают два типа независимости от данных: логическую и физическую.
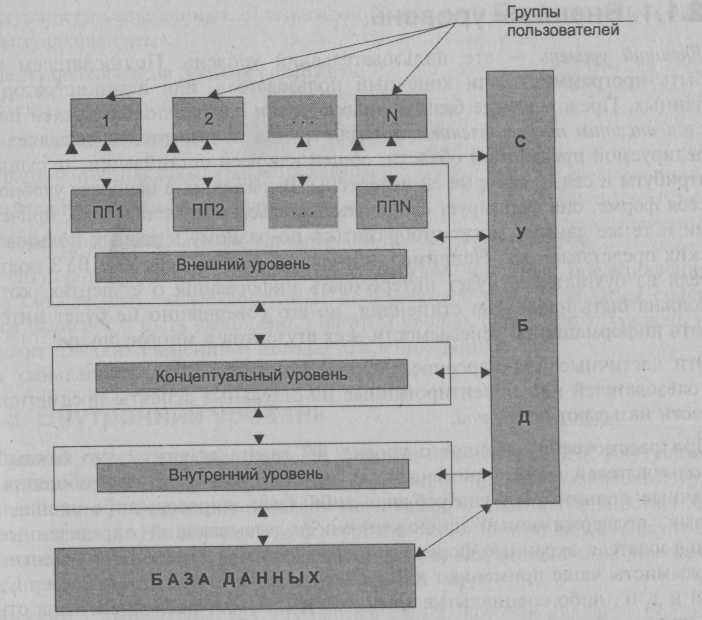
Рис. Трехуровневая архитектура СУБД
Логическая независимость от данных означает полную защищенность внешних схем от изменений, вносимых в концептуальную схему. Такие изменения концептуальной схемы, как добавление или удаление новых сущностей, атрибутов или связей, должны осуществляться без необходимости внесения изменений в уже существующие внешние схемы для других групп пользователей. Таким образом, тем группам пользователей, которых эти изменения не касаются, не потребуется вносить изменения в свои программы.
Физическая независимость от данных означает защищенность концептуальной схемы от изменений, вносимых во внутреннюю схему. Такие изменения внутренней схемы, как использование различных файловых систем или структур хранения, разных устройств хранения, модификация индексов или хеширование, должны осуществляться без необходимости внесения изменений в концептуальную или внешнюю схемы. Пользователем могут быть замечены изменения только в общей производительности системы. Далее рассмотрим каждый из трех названных уровней.
Внешний уровень
Внешний уровень — это пользовательский уровень. Пользователем может быть программист, или конечный пользователь, или администратор базы данных. Представление базы данных с точки зрения пользователей называется внешним представлением. Каждая группа пользователей выделяет в моделируемой предметной области, общей для всей организации, те сущности, атрибуты и связи, которые ей интересны. Выражая их в наиболее удобной для себя форме, она формирует свое пользовательское представление, причем одни и те же данные могут отображаться по-разному в разных пользовательских представлениях. Например, в информационной системе ВУЗ пользователя из бухгалтерии будет интересовать информация о студентах, которым должна быть начислена стипендия, но его совершенно не будет интересовать информация об успеваемости всех студентов и многое другое. Эти частичные или переопределенные описания БД для отдельных групп пользователей или ориентированные на отдельные аспекты предметной области называют подсхемой.
При рассмотрении внешнего уровня БД важно отметить, что каждый тип пользователей может применять для работы с БД свой язык общения. Конечные пользователи употребляют либо язык запросов, либо специальный язык, поддерживаемый приложениями и вызывающий определенные для пользователя экранные формы и пользовательские меню. Прикладные программисты чаще применяют либо языки высокого уровня, например С, Pascal и т. п., либо специальные языки СУБД. Языки последнего типа относят к языкам четвертого поколения.
Какой бы язык высокого уровня не использовался (он в этом случае называется базовым), он должен включать в себя и подъязык для работы с данными. Система может поддерживать любое количество подъязыков данных, любое количество базовых языков. ]Но язык__£(ЗЬ поддерживается практически всеми системами. Он может использоваться и как встроенный в другие языки, и как отдельный самостоятельный язык запросов.
Концептуальный уровень
Концептуальный уровень является промежуточным уровнем в трехуровневой архитектуре и обеспечивает представление всей информации базы данных в абстрактной форме. Описание базы данных на этом уровне называется концептуальной схемой, которая является результатом концептуального проектирования.
Концептуальное проектирование базы данных включает анализ информационных потребностей пользователей и определение нужных им элементов данных. Таким образом, концептуальная схема — это единое логическое описание всех элементов данных и отношений между ними, логическая структура всей базы данных. Для каждой базы данных имеется только одна концептуальная схема.
Концептуальная схема должна содержать:
- объекты и их атрибуты;
- связи между объектами;
- ограничения, накладываемые на данные;
- семантическую информацию о данных;
- обеспечение безопасности и поддержки целостности данных.
Концептуальный уровень поддерживает каждое внешнее представление, в том смысле, что любые доступные пользователю данные должны содержаться (или могут быть вычислены) на этом уровне. Однако этот уровень не содержит никаких сведений о методах хранения данных.
Внутренний уровень
Внутренний уровень является третьим уровнем архитектуры БД. Внутреннее представление не связано с физическим уровнем, так как физический уровень хранения информации обладает значительной индивидуальностью для каждой системы. На внутреннем же уровне все эти индивидуальности не учитываются, и область хранения представляется как бесконечное линейное адресное пространство.
На нижнем уровне находится внутренняя схема, которая является полным описанием внутренней модели данных. Для каждой базы данных существует только одна внутренняя схема.
Внутренняя схема описывает физическую реализацию базы данных и предназначена для достижения оптимальной производительности и обеспечения экономного использования дискового пространства. Именно на этом уровне осуществляется взаимодействие СУБД с методами доступа операционной системы (вспомогательными функциями хранения и извлечения записей данных) с целью размещения данных на запоминающих устройствах, создания индексов, извлечения данных и т. д.
На внутреннем уровне хранится следующая информация:
- распределение дискового пространства для хранения данных и индексов; П описание подробностей сохранения записей (с указанием реальных размеров сохраняемых элементов данных);
- сведения о размещении записей;
- сведения о сжатии данных и выбранных методах их шифрования. СУБД отвечает за установление соответствия между всеми тремя типами схем разных уровней, а также за проверку их непротиворечивости.
Ниже внутреннего уровня находится физический уровень, который контролируется операционной системой, но под руководством СУБД.
Физический уровень учитывает, каким образом данные будут представлены в машине. Он обеспечивает физический взгляд на базу данных: дисководы, физические адреса, индексы, указатели и т. д. За этот уровень отвечают проектировщики физической базы данных, которые работают только с известными операционной системе элементами. Область их интересов: указатели, реализация последовательного распределения, способы хранения полей внутренних записей на диске. Однако функции СУБД и операционной системы на физическом уровне не вполне четко разделены и могут варьироваться от системы к системе. В одних СУБД используются многие предусмотренные в данной операционной системе методы доступа, тогда как в других применяются только самые основные и реализована собственная файловая организация.
Итак, подведем итоги.
Реализация трехуровневой архитектуры БД требует, чтобы СУБД переводила информацию с одного уровня на другой, то есть преобразовывала адреса и указатели в соответствующие логические имена и отношения и наоборот. Выгодой такого перевода является независимость логического и физического представления данных, но и плата за эту независимость немалая — большая системная задержка.
Для установления соответствия между любыми внешней и внутренней схемами СУБД должна использовать информацию из концептуальной схемы. Концептуальная схема связана с внутренней схемой посредством концептуально-внутреннего отображения. Оно позволяет СУБД найти фактическую запись или набор записей на физическом устройстве хранения, которые образуют логическую запись в концептуальной схеме.
В то же время каждая внешняя схема связана с концептуальной схемой с помощью внешне-концептуального отображения. С его помощью СУБД может отображать имена пользовательского представления на соответствующую часть концептуальной схемы.
Независимость данных- СУБД создает среду, которая может обеспечить независимость данных, существенно упрощая этим работу программистов (независимость данных имеет место, если изменение типа данных вызывает его автоматическое изменение с помощью СУБД во всей базе данных, исключая таким образом, необходимость модифицировать участки программ, которые используют эти данные).
Структурная независимость – имеет место, если изменения в структуре базы данных не влияют на возможность доступа СУБД к данным.
Преимущества и недостатки СУБД
В заключение этой главы еще раз сконцентрируем внимание на основных преимуществах, которыми обладают СУБД.
Наличие интегрированной централизованной базы данных. База данных принадлежит всей организации в целом и может совместно использоваться всеми зарегистрированными пользователями.
Минимизация избыточности данных. При использовании базы данных осуществляется минимизация избыточности данных за счет интеграции файлов, чтобы избежать хранения нескольких копий одного и того же элемента информации. Однако полностью избыточность информации в базах данных не исключается, а лишь контролируется ее степень. В одних случаях ключевые элементы данных необходимо дублировать для моделирования связей, а в других случаях некоторые данные потребуется дублировать из соображений повышения производительности системы.
Непротиворечивость данных и контроль их целостности. Устранение избыточности данных или контроль над ней позволяет сократить риск возникновения противоречивых состояний. Целостность базы данных означает корректность и непротиворечивость хранимых в ней данных.
Повышенная безопасность. Безопасность базы данных заключается в защите базы данных от несанкционированного доступа со стороны пользователей. Интеграция позволяет АБД определить требуемую систему безопасности базы данных, а СУБД — привести ее в действие.
Увеличение гибкости при обслуживании запросов пользователя. Во многих СУБД предусмотрены языки запросов или инструменты для создания отчетов, которые позволяют пользователям задавать непредусмотренные заранее запросы и почти немедленно получать требуемую информацию, не прибегая к помощи программиста.
Сокращение времени разработки приложений. СУБД обеспечивает все низкоуровневые процедуры работы с файлами. Наличие этих процедур позволяет программисту сконцентрироваться на разработке более специальных, необходимых пользователям функций. Во многих СУБД также предусмотрена среда разработки четвертого поколения с инструментами, упрощающими создание приложений баз данных. Результатом является повышение производительности работы программистов и сокращение времени разработки новых приложений.
Независимость прикладных программ от данных. В СУБД описания данных отделены от приложений, а потому приложения защищены от изменений в описаниях данных. Наличие независимости программ от данных значительно упрощает обслуживание и сопровождение приложений, работающих с базой данных.
Многопользовательский режим работы. Во многих СУБД предусмотрена возможность параллельного доступа к базе данных и гарантируется отсутствие конфликтных ситуаций и нарушение целостности данных в подобных ситуациях.
Развитые службы резервного копирования и восстановления. В современных СУБД предусмотрены средства сокращения объема потерь информации от возникновения различных сбоев.
Используя все эти перечисленные возможности СУБД, в мире создано и функционирует огромное количество информационных систем, которые пронизывают все сферы современного общества.
Но поскольку за все приходится платить, хотелось бы перечислить и то, что входит в платежную корзину в этой ситуации, иными словами, напомнить и о тех сложностях, которые влечет за собой использование СУБД.
Требуемая высокая квалификация работников. Чтобы воспользоваться всеми преимуществами СУБД, проектировщики и разработчики баз данных, администраторы данных и администраторы баз данных, а также конечные пользователи должны хорошо понимать функциональные возможности СУБД. Непонимание принципов работы системы может привести к неудачным результатам проектирования, что будет иметь самые серьезные последствия для всей организации.
Расход значительной части ресурсов непосредственно на нужды СУБД, а не на прикладную задачу. Сложность и широта функциональных возможностей СУБД приводит к тому, что она может занимать много места на диске и требовать большого объема оперативной памяти для эффективной работы.
Стоимость СУБД. В зависимости от имеющейся вычислительной среды и требуемых функциональных возможностей, стоимость СУБД может варьироваться в очень широких пределах.
Повышенные требования к техническому и программному обеспечению. Для удовлетворения требований, предъявляемых к дисковым накопителям со стороны СУБД и базы данных, может возникнуть необходимость в приобретении дополнительных устройств хранения информации. Более того, для достижения требуемой производительности может понадобиться более мощный компьютер. Несмотря на это, в некоторых ситуациях стоимость СУБД и дополнительного аппаратного обеспечения может оказаться несущественной по сравнению со стоимостью преобразования существующих приложений для работы с новой СУБД и новым аппаратным обеспечением.
Производительность. СУБД предназначены для решения общих задач и обслуживания сразу нескольких приложений, а не какого-то одного из них. В результате многие приложения в новой среде будут работать не так быстро, как прежде в файловой системе.
Последствия сбоев. Централизация ресурсов повышает уязвимость системы. Поскольку работа всех пользователей и приложений зависит от готовности к работе СУБД, выход из строя одного из ее компонентов может привести к полному прекращению работы всей организации.
Данные и модели данных
Семантика данных
Восприятие мира можно соотнести с последовательностью различных, хотя иногда и взаимосвязанных, явлений. С давних времен человечество пыталось описать эти явления вне зависимости от того, достигалось их полное понимание или нет. Будем называть такое описание данными. Данные соответствуют дискретным зарегистрированным фактам относительно явлений, в результате чего мы получаем информацию о реальном мире.
Информация — это приращение знаний, которое может быть выведено на основе данных.
Слово «данные» происходит от латинского «datum», буквально означающего «факт». Тем не менее данные не всегда соответствуют конкретным или действительным фактам. Иногда они неточны или описывают нечто, не имеющее место в реальной действительности (идею). Будем называть данными описание любого явления (или идеи), которое представляется достаточно ценным для того, чтобы его сформулировать и точно зафиксировать.
Традиционно фиксация данных осуществляется с помощью конкретного средства общения (например, с помощью языка или изображений) на конкретном (полу-) постоянном носителе (например, камне или бумаге). Деятельность по регистрации данных прослеживается во времени: пещерная живопись доисторических времен, древнегреческие письмена на камне и египетские на папирусе. Чаще всего данные описываются на естественном языке и фиксируются на бумаге. Обычно данные (факты) и их интерпретация (семантика) фиксируются совместно, так как естественный язык достаточно гибок для представления того и другого. Примером может служить утверждение «его рост 173 см». Здесь «173»— данное, а его семантика—«рост в сантиметрах».
Соответственно двум понятиям «информация» и «данные» различают два аспекта рассмотрения вопросов – инфологический и датологический.
В инфологическом аспекте рассматриваются вопросы, связанные со смысловым содержанием данных независимо от способов их представления в памяти системы. На этом этапе решаются следующие вопросы:
1 О каких объектах или являниях реального мира требуется накапливать и обрабатывать информацию в системе?
2 Какие их основные характеристики и взаимосвязи между собой будут учитываться?
3 Какие вводимые в ИС понятия об объектах и явлениях, их характеристиках и взаимосвязях требуют уточнения?
Т.е. на этапе инфологического проектирования выделяется часть реального мира, определяющая информационные потребности системы т.е. ее предметная область.
В даталогическом аспекте рассматриваются вопросы представления данных в памяти инф.системы. При датол.проектировании системы, исходя из возможностей имеющихся средств восприятия, хранения и обработки информации, разрабатываются соответствующие формы представления информации в системе посредством данных, а также приводятся модели и методы представления и преобразования данных, формируются правила смысловой интерпретации данных.
Интеллектуальное средство, позволяющее реализовать интерпретацию данных в соответствии с указанными требованиями, будем называть моделью данных.
Модель данных—это средство абстракции, которое дает возможность увидеть «лес» (информационное содержание данных), а не «отдельные деревья» (конкретные значения данных).
Модель базы данных это совокупность логических конструкций, используемых для представления структуры данных и отношений между ними внутри БД. Модели баз данных можно подразделить на две категории: концептуальные модели и модели реализации(датологические).
- концептуальная (понятийная) модель нацелена на логическую природу представления данных. Поэтому в ней основное внимание уделяется тому, что представлено в БД, а не как это представлено. К концептуальным моделям относится модель «Сущность-связь»
- в отличие от концептуальной модели, модель реализации ставит во главу угла способ представления данных в БД или то как реализовать структуры данных, чтобы получить представление о том, что мы моделируем. К моделям реализации относятся иерархическая модель, сетевая, реляционная и объектно-ориентированная.
| | | | | Модели данных | | |||||||||||||||||||||
| | | | | | | | | | ||||||||||||||||||
| | | | | | | | | | | | ||||||||||||||||
| | Инфологические модели | Даталогические модели | Физические модели | | | |||||||||||||||||||||
| | | | | | | | | | | | | | ||||||||||||||
| Диаграммы Бахмана | Модель сущность связь (ЕК) | Документальные модели | Фактографические модели | Основанные на файловых структурах | Основанные на странично-сегментной организации | |||||||||||||||||||||
| | | | | | | | | |||||||||||||||||||
| | | | | | | | | г | ||||||||||||||||||
| | | | | | | | | | | | ||||||||||||||||
| Ориентированные на формат документа | Дескрип-торные | гезаурусные модели | Теоретико-графовые | Теоретико-множественные | Объе ориенктно-тиро-ные | |||||||||||||||||||||
| | | | | | | | | | | |||||||||||||||||
| | | | | | | | | | | | ||||||||||||||||
| | | | | | | | | | ||||||||||||||||||
| | | | | | | | | | | | ||||||||||||||||
| | | | | Иерархическа | я | Сетевая | Реляционная а | Бинарных ссоциаций | | |||||||||||||||||
Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
Кроме трех рассмотренных уровней абстракции при проектировании БД существует еще один уровень, предшествующий им. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или семантическими, и отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей.
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения,
а даталогические модели уже поддерживаются конкретной СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, основанные на языках разметки документов, связаны прежде всего со стандартным общим языком разметки — SGMLе), который был утвержден в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескрипторпые модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имел жесткую структуру и описывал документ в соотствии с теми характеристиками. Которые требуются для работы с документами в разрабатываемой документальной БД.
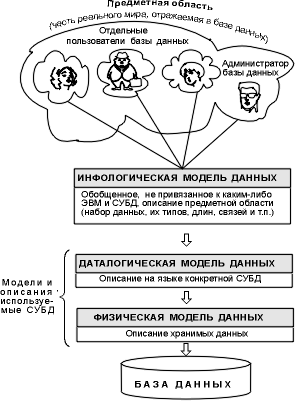
Рис. 1.. Уровни моделей данных
Такая человеко-ориентированная модель полностью независима от физических параметров среды хранения данных. В конце концов этой средой может быть память человека, а не ЭВМ. Поэтому инфологическая модель не должна изменяться до тех пор, пока какие-то изменения в реальном мире не потребуют изменения в ней некоторого определения, чтобы эта модель продолжала отражать предметную область.
Остальные модели, показанные на рис. 1., являются компьютеро-ориентированными. С их помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным лишь по их именам, не заботясь о физическом расположении этих данных. Нужные данные отыскиваются СУБД на внешних запоминающих устройствах по физической модели данных.
Так как указанный доступ осуществляется с помощью конкретной СУБД, то модели должны быть описаны на языке описания данных этой СУБД. Такое описание, создаваемое АБД по инфологической модели данных, называют даталогической моделью данных.
Трехуровневая архитектура (инфологический, даталогический и физический уровни) позволяет обеспечить независимость хранимых данных от использующих их программ. АБД может при необходимости переписать хранимые данные на другие носители информации и (или) реорганизовать их физическую структуру, изменив лишь физическую модель данных. АБД может подключить к системе любое число новых пользователей (новых приложений), дополнив, если надо, даталогическую модель. Указанные изменения физической и даталогической моделей не будут замечены существующими пользователями системы (окажутся "прозрачными" для них), так же как не будут замечены и новые пользователи. Следовательно, независимость данных обеспечивает возможность развития системы баз данных без разрушения существующих приложений
Сильно типизированные—это модели, в которых предполагается, что все данные должны быть отнесены к какой-либо категории. Если данные нельзя отнести ни к одной из них, то их следует с помощью искусственных приемов привести к той или иной категории. Некоторые модели строятся в предположении, что допустимые категории предопределены и не могут изменяться динамически.
Пример:
| Тип авто | Кузов | Двигатель | Привод | вес | пасс | вто |
| легковой | седан | 1800 | передний | 900 | 5 | ваз199 |
| легковой | хетчбэк | 1100 | передний | 600 | 4 | газ |
| грузовой | пикап | 2000 | задний | 3000 | 2 | газель |
Слабо типизированные модели не связаны никакими предположениями относительно категорий. Категории используются в той степени, в какой это целесообразно в каждом конкретном случае.
Пример
| Тип авто | вес |
| легковой | 900 |
| грузовой | 3000 |
В сильно типизированных моделях «мир» пытаются поместить в «смирительную рубашку». Такие модели весьма негибки, и их применение затрудняет передачу тонких семантических различий. Рассмотрим, например категорию СЛУЖАЩИЙ. В строго типизированной модели данных эта категория должна быть гомогенной, т. е. все объекты, принадлежащие этой категории, должны иметь однотипные свойства, структуру и т.д. Между тем женатые и неженатые, временные и постоянные, находящиеся на сдельной и повременной оплате служащие характеризуются по-разному.
Вместе с тем сильно типизированные модели данных обладают большими достоинствами. Они позволяют построить абстракции свойств данных и исследовать их в терминах категорий. Иными словами, можно построить теорию, основывающуюся на категориях, которые фактически инкапсулируют свойства конкретных данных.
Отдельные свойства категорий наследуются принадлежащими к ним данными. Кроме того, устраняется дублирование имен:
имена подобных объектов и их свойств могут быть абстрагированы соответственно в имя категории и имя свойства категории. Например, путем присвоения категории имени СЛУЖАЩИЙ, а свойству категории—имени Возраст устраняется повторение имен в каждой тройке <СЛУЖАЩИИ, Возраст, значение~>.
Еще одно преимущество сильно типизированных моделей данных непосредственно определяется их основным свойством, а именно тем, что все данные должны быть отнесены к какой-либо категории. Таким образом, очевидную противоречивость данных можно устранить, поскольку семантически близкие данные будут рассматриваться как близкие и в модели (они относятся к одной категории). Это не всегда имеет место в слабо типизированных моделях данных. Гибкость последних позволяет отводить факту весьма различные места в общей структуре фактов. Если факты противоречивы, но далеки по представлению, обнаружить противоречивость очень трудно.