
Предисловие Системы управления базами данных (субд) – это программные комплексы, предназначенные для работы со специально организованными файлами (массивами данных, долговременно хранимыми во внешней памяти вычислительных систем), которые называются
| Вид материала | Документы |
- Системы управления базами данных (субд). Назначение и основные функции, 30.4kb.
- Программа курса лекций "Базы данных в научных исследованиях", 49.32kb.
- Система управления базами данных это комплекс программных и языковых средств, необходимых, 150.5kb.
- Лекция 2 Базы данных, 241.25kb.
- Любая программа для обработки данных должна выполнять три основных функции: ввод новых, 298.05kb.
- Вопросы к государственному экзамену по специальности «Информационные системы и технологии», 39.93kb.
- Лекция № Технологии баз данных, 92.24kb.
- Проектирование базы данных, 642.58kb.
- Системы управления базами данных, 313.7kb.
- Программа дисциплины Системы управления базами данных Семестры, 22.73kb.
Рис. 10.2. Конфигурация распределенной базы данных
10.3. Что такое система управления распределенной базой данных?
Система управления распределенной базой данных (СУРБД) управляет хранением и обработкой логически связанных данных в сетевых компьютерных системах, где как данные, так и функции обработки распределяются по нескольким сайтам. Чтобы считаться распределенной, СУБД должна обладать, по крайней мере, следующими функциональными возможностями:
- прикладной интерфейс, обеспечивающий взаимодействие с конечным пользователем или прикладными программами, а также с другими СУБД в рамках распре деленной базы данных;
- проверка достоверности при анализе запросов;
- преобразования для выяснения, какие компоненты запроса являются распределенными, а какие локальными;
- оптимизация запроса, гарантирующая выявление лучшей стратегии доступа (к каким фрагментам БД должен быть обеспечен доступ для выполнения данного запроса, как должно выполняться преобразование данных и как при этом они должны синхронизироваться);
- отображение, позволяющее определить местоположение данных в локальных и удаленных фрагментах;
- интерфейс ввода/вывода, обеспечивающий считывание/запись данных в постоянном месте хранения;
- форматирование, подготавливающее данные для представления их конечному пользователю или для передачи в прикладные программы;
- безопасность, т. е. обеспечение конфиденциальности данных как в локальных, так и в удаленных БД;
- резервное копирование, которое гарантирует доступность и восстанавливаемость базы данных в случае аварии;
- управление параллельным выполнением, обеспечивающее одновременный доступ к данным и гарантирующее целостность данных во всех фрагментах базы данных в данной СУРБД;
- управление транзакциями, обеспечивающее переход данных из одного устойчивого состояния в другое. Сюда включаются синхронизация локальных и удаленных транзакций, а также транзакции между несколькими распределенными сегментами.
Рис. 10.3. Система управления централизованной базой данных
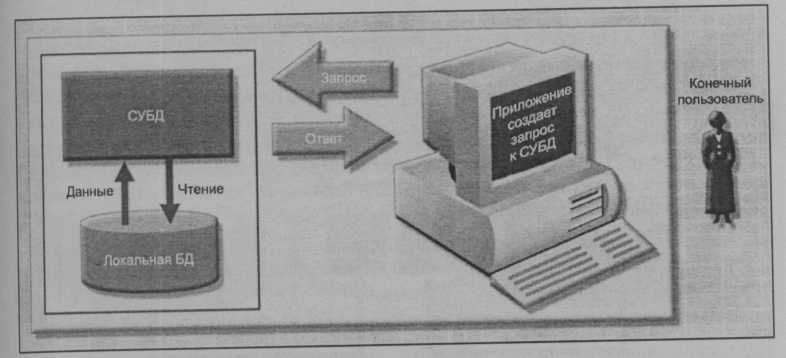
На рис. 10.3 представлена схема управления взаимодействием между конечными пользователями и базой данных в централизованной СУБД. Эту схему можно использовать в качестве основы для сравнения централизованной СУБД и полностью распределенной СУБД (СУРБД).
Из рис. 10.3 следует, что СУБД:
- получает запросы приложения (или конечного пользователя);
- проверяет достоверность, анализирует и разбивает запрос на составные части.
В запрос могут включаться математические и/или логические операции, напри
мер "Выбрать всех клиентов с балансом больше $1000". Запрос может затребовать
данные только из одной таблицы или из нескольких таблиц;
- отображает логические компоненты запроса на физические данные;
- разбивает запрос на несколько операций дискового ввода/вывода;
- осуществляет поиск, определяет местоположение, считывает и проверяет данные;
обеспечивает непротиворечивость, безопасность и целостность данных;
- проверяет соответствие данных заданным условиям (если они определены в за
просе);
-
представляет данные в нужной форме.
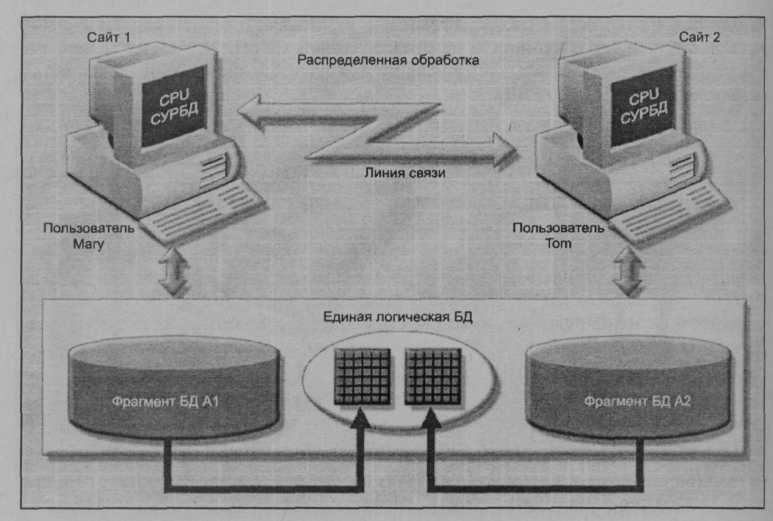
Рис. 10.4. Система управления полностью распределенной базы данных
Все эти действия происходят как бы за сценой, они прозрачны для пользователя.
Система управления полностью распределенной базой данных должна выполнять все функции централизованной СУБД и к тому же обеспечивать функциональные возможности, необходимые для работы с распределенными данными и распределенной обработкой информации. Все функции СУРБД также должны быть прозрачными для пользователя. Прозрачные функции доступа к данным в СУРБД представлены на рис. 10.4.
 Логически единая база данных на рис. 10.4 состоит из двух фрагментов А1 и А2, расположенных на сайтах 1 и 2 соответственно. Пользователь Магу, как и пользователь Тот, могут запрашивать базу данных, как будто она является локальной БД. Оба пользователя "видят" только одну логическую БД и не знают имена фрагментов. На самом деле, конечным пользователям нет необходимости знать ни о том, что БД разделена на отдельные фрагменты, ни о том, где эти фрагменты расположены.
Логически единая база данных на рис. 10.4 состоит из двух фрагментов А1 и А2, расположенных на сайтах 1 и 2 соответственно. Пользователь Магу, как и пользователь Тот, могут запрашивать базу данных, как будто она является локальной БД. Оба пользователя "видят" только одну логическую БД и не знают имена фрагментов. На самом деле, конечным пользователям нет необходимости знать ни о том, что БД разделена на отдельные фрагменты, ни о том, где эти фрагменты расположены.Разделение между обработкой данных и их хранением приводит к нескольким сценариям, в которых с помощью СУБД достигается некоторая степень распределения (обработки или данных, либо и того и другого). Для лучшего понимания различных типов сценариев распределения БД мы должны, прежде всего, определить компоненты системы распределенной базы данных.
10.4. Компоненты СУРБД
В состав СУРБД должны входить (по крайней мере) следующие компоненты:
- компьютерные рабочие станции (сайты или узлы), формирующие сетевую систему. Система распределенной базы данных должна быть независимой от оборудования;
- компоненты сетевого оборудования и программного обеспечения каждой рабочей станции. Сетевые компоненты позволяют всем сайтам взаимодействовать друг с другом и обмениваться данными. Поскольку эти компоненты (компьютеры, операционные системы, сети и т. д.), скорее всего, поставляются различными производителями, желательно, чтобы функции распределенной БД могли выполняться на различных платформах;
- коммуникационные устройства, которые переносят данные с одной рабочей станции на другую. СУРБД не должна зависеть от средств коммуникации, т. е. она должна поддерживать несколько типов коммуникационных устройств;
- процессор транзакций (transaction processor, ТР), представляющий собой программный компонент, находящийся на каждом компьютере, где выполняется запрос данных. Процессор транзакций получает и обрабатывает данные запроса приложения (удаленные и локальные). Процессор транзакций называют также процессором приложений (application processor, АР) или менеджером транзакций(transaction manager, TM);
- процессор данных (data processor, DP), представляющий собой программный компонент, расположенный на каждом компьютере, где хранятся и извлекаются
данные, расположенные на данном сайте. Процессор данных также называют
менеджером данных (data manager, DM). Процессор данных может даже представлять собой централизованную СУБД.
Рис. 10.5 иллюстрирует расположение и взаимодействие всех компонентов. Связь между ТР и DP, показанная на рис. 10.5, позволяет установить сквозные специфические правила или протоколы, используемые в СУРБД.
Протоколы определяют, как система распределенной базы данных:
- организует интерфейс с сетью для передачи данных и команд между процессорами данных (DP) и процессорами транзакций (ТР);
- синхронизирует все данные, полученные от DP (сторона ТР), и маршрутизирует полученные данные на соответствующие ТР (сторона DP);
- обеспечивает функции общего управления БД в распределенной системе (безопасность, управление параллельным выполнением, создание резервных копий и восстановление).
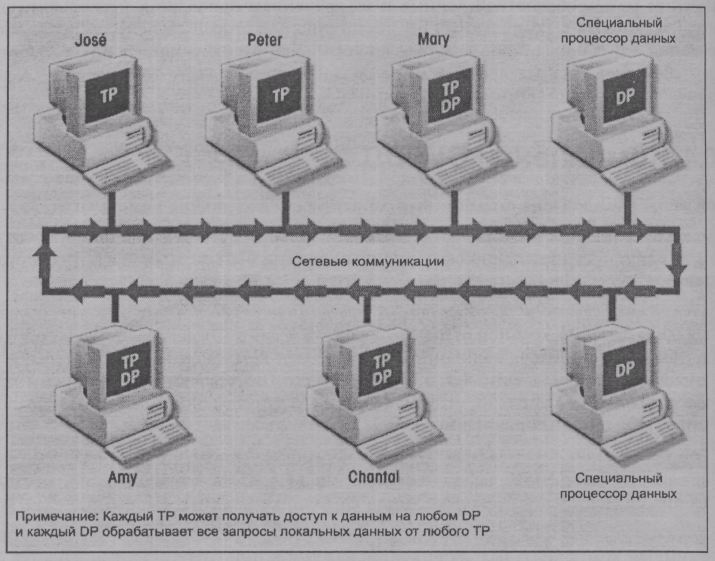
Рис. 10.5. Компоненты системы распределенной базы данных
Процессор данных (DP) и процессор транзакций (ТР) можно добавить в систему, не воздействуя на ее другие компоненты. Процессоры ТР и DP могут размещаться на одном и том же компьютере, позволяя конечным пользователям получать доступ к локальным и удаленным данным, не заботясь об их местонахождении. Теоретически DP может представлять собой независимую централизованную СУБД с соответствующим интерфейсом для поддержки удаленного доступа к другим независимым СУБД в сети.
10.5. Уровни распределения данных и их обработки
Можно классифицировать современные базы данных по способам поддержки ими распределения данных и их обработки. Например, СУБД может хранить данные на
единственном сайте (централизованная БД) или на нескольких сайтах (распределенная БД), а также может поддерживать обработку данных на одном сайте или на нескольких сайтах. В табл. 10.1 представлена простая классификация баз данных в соответствии с распределением данных и процессов их обработки. Типы процессов обработки мы обсудим в последующих разделах этой главы.
Таблица 10.1. Системы баз данных: уровни распределения данных
и процессов их обработки

10.5.1. Обработка и размещение данных на одном сайте
При таком сценарии вся обработка данных выполняется одним процессором (CPU) или главным компьютером (мэйнфреймом, мини-компьютером или персональным компьютером — хост-компьютером), а все данные хранятся на локальном диске хост-комьютера. Обработка не может выполняться на стороне компьютера конечного пользователя. Такой сценарий обычен для большинства СУБД на мэйнфреймах или мини-компьютерах. СУБД размещена на хост-компьютере, к которому можно получать доступ с подключенных к нему терминальных устройств (рис. 10.6). Такая схема также типична для первого поколения однопользовательских баз данных на микрокомпьютерах.
Из рис. 10.6 следует, что функции процессора транзакций (ТР) и процессора данных (DP) встроены в СУБД, размещенную на одном компьютере. СУБД обычно работает под управлением многозадачной операционной системы с разделением времени, позволяющей нескольким процессам выполняться на основном процессоре (host CPU) "одновременно", получая доступ к единому процессору данных. Все операции, связанные с хранением и обработкой данных, выполняются одним центральным процессором.
10.5.2. Обработка данных на нескольких сайтах, размещение данных на одном сайте (MPSD)
Если обработка данных ведется на нескольких сайтах (узлах), а данные хранятся на одном сайте (multiple-site processing, single-site data, MPSD), то несколько процессов обработки данных выполняются на разных компьютерах, которые получают совместный доступ к хранилищу информации.
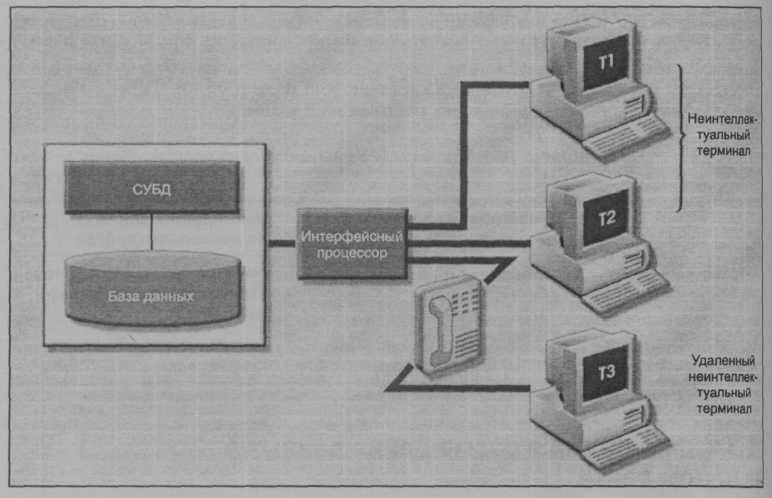
Рис. 10.6. Нераспределенная (централизованная) СУБД
Обычно такой сценарий требует наличия сетевого файл-сервера, на котором выполняются определенные приложения, доступные по локальной сети. Множество многопользовательских бухгалтерских программ, работающих в локальной сети персональных компьютеров, действуют именно по такому сценарию (рис. Ю.7).
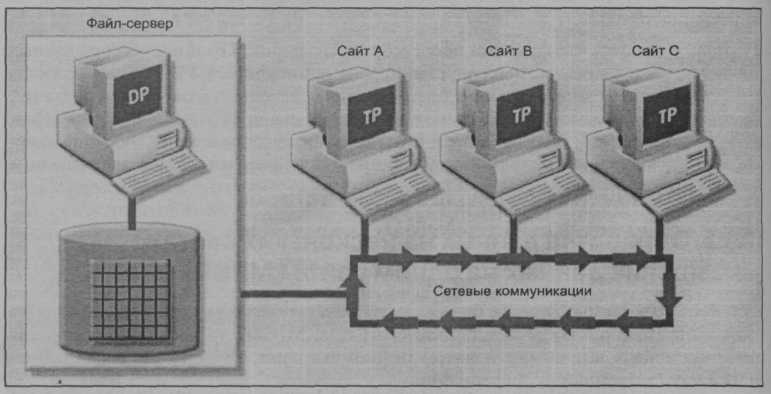
Рис. 10.7. Обработка данных на нескольких сайтах, данные на одном сайте
 На рис. 10.7 необходимо обратить внимание на следующее:
На рис. 10.7 необходимо обратить внимание на следующее:- процессор транзакций на каждой рабочей станции действует только как редиректор (программа переназначения), направляющий всю информацию сетевых запросов на файл-сервер;
- конечный пользователь видит файл-сервер просто как еще один жесткий диск. Поскольку ввод/вывод хранимых данных обрабатывается только файл-сервером, в этом случае возможности распределенной обработки очень ограниченны;
- чтобы получить доступ к данным, конечный пользователь должен напрямую ссылаться на файл-сервер. Все действия по блокировке файлов выполняются на компьютере конечного пользователя;
- функции выборки, поиска и обновления данных выполняются на рабочих станциях, при этом требуется, чтобы весь файл целиком передавался по сети на рабочую станцию для обработки. Это требование приводит к увеличению сетевого трафика, уменьшает время отклика и увеличивает стоимость коммуникаций.
Последнее положение легко продемонстрировать. Предположим, что на файл-сервере хранится таблица CUSTOMER (клиент), содержащая 10 000 строк информации, в 50 из которых сумма баланса больше $1000. Если на сайте А создать такой запрос:
SELECT * FROM CUSTOMER WHERE CUS_BALANCE > 1000
то все 10 000 записей таблицы CUSTOMER будут переданы по сети для расчетов на сайт А.
Один из вариантов сценария обработки данных на нескольких сайтах и размещения данных на одном сайте называется архитектурой клиент/сервер. Эта схема, которую мы будем подробно обсуждать в гл. 12, в целом похожа на схему с файл-сервером, за исключением того, что вся обработка данных выполняется на сайте сервера, что позволяет уменьшить сетевой трафик. Несмотря на то что и в файл-серверной схеме, и в архитектуре клиент/сервер обработка выполняется на нескольких сайтах, распределение обработки имеет место только в схеме клиент/сервер. Обратите внимание, что в схеме с сетевым файл-сервером требуется, чтобы база данных размещалась на одном сайте. В отличие от этого в архитектуре клиент/сервер возможна поддержка распределения данных по нескольким сайтам.
10.5.3. Обработка и размещение данных на нескольких сайтах (MPMD)
Этот сценарий относится к системе управления полностью распределенной базой данных с поддержкой нескольких процессоров данных и процессоров транзакций на нескольких сайтах (multiple-site processing, multiple-site data, MPMD). В зависимости от уровня поддержки различных типов централизованных СУБД, СУРБД подразделяются на гомогенные и гетерогенные.
Гомогенные системы распределенных баз данных объединяют по сети только один тип централизованных СУБД. В этом случае на разных мэйнфреймах, мини-компьютерах
и микрокомпьютерах будут выполняться одинаковые СУБД. В отличие от этого гетерогенные системы распределенных баз данных объединяют по сети различные типы централизованных СУБД (рис. 10.8). Полностью гетерогенная СУРБД поддерживает различные СУБД, которые, возможно, даже используют различные модели данных (реляционные, иерархические или сетевые) и выполняются в разных системах, например, на мэйнфреймах, мини-компьютерах и микрокомпьютерах.
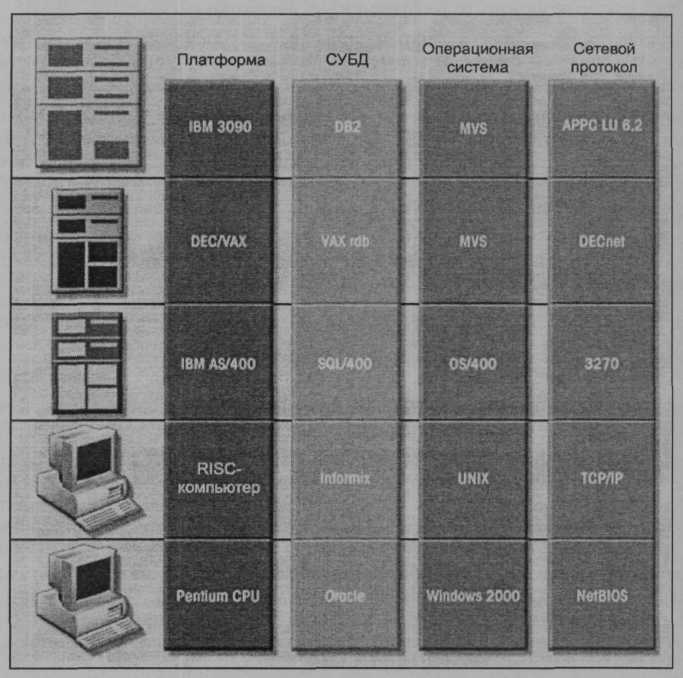
Рис. 10.8. Гетерогенная система управления распределенной базой данных
Ни одна из современных СУРБД не обеспечивает полную поддержку сценария, представленного на рис. Ю.8, и не предоставляет для этого соответствующие инфраструктуры. Некоторые реализации СУРБД обеспечивают поддержку нескольких аппаратных платформ, операционных систем и сетей и позволяют выполнять доступ к данным другой СУБД. Однако в подобных СУРБД все еще имеется множество ограничений. Например:
- удаленный доступ предоставляется на уровне "только чтение" и не обеспечивает возможность записи данных;
- ограничивается количество удаленных таблиц, доступных в одной транзакции;
- ограничивается число отдельных баз данных, к которым можно получить доступ;
- ограничиваются модели баз данных, к которым можно получать доступ. То есть, например, доступ может осуществляться только к реляционным базам данных, но не к сетевым или иерархическим.
Представленный список ни в коем случае нельзя считать окончательным. Технология СУРБД продолжает быстро развиваться, и все время открываются новые возможности. Управление данными на нескольких сайтах приводит к возникновению множества проблем, которые необходимо выявлять и понимать. Поэтому далее мы рассмотрим лишь несколько ключевых свойств систем управления распределенными базами данных.
10.6. Прозрачные свойства распределенной базы данных
Система распределенной базы данных обладает целым рядом функциональных характеристик, которые можно назвать прозрачными (невидимыми пользователю). Прозрачные свойства СУРБД обладают общей особенностью, позволяя конечному пользователю считать себя монопольным пользователем системы. Другими словами, пользователь полагает, что он работает с централизованной СУБД, и при этом все сложности работы с распределенной БД скрыты от него (прозрачны).
К прозрачным свойствам СУРБД относятся:
- прозрачность распределения (distribution transparency), позволяющая считать распределенную БД единой логической базой данных. Если СУРБД обеспечивает
прозрачность распределения, то пользователя совершенно не интересует:
- что данные разделяются по нескольким сайтам;
- что данные дублируются на нескольких сайтах;
- где размещены данные.
- прозрачность транзакции (transaction transparency), которая позволяет транзакции
обновлять данные на нескольких сетевых сайтах. Свойство прозрачности транзакции гарантирует, что данная транзакция будет либо выполнена полностью,
либо отменена, что должно обеспечить целостность данных;
- прозрачность ошибок (failure transparency), которая гарантирует, что система будет продолжать выполнение операций в случае неисправности какого-либо узла (сайта). Функции, не выполненные по причине сбоя, будут завершены на других узлах ;
- прозрачность производительности (performance transparency), которая позволяет системе функционировать как централизованной СУБД. Качество работы системы не должно ухудшаться из-за того, что она работает на различных сетевых платформах. Прозрачность производительности также гарантирует, что система будет находить наиболее эффективный и выгодный путь доступа к удаленным данным;
- прозрачность гетерогенности (heterogeneity transparency), которая позволяет объединять несколько различных локальных СУБД (реляционных, сетевых и иерархических) в единую или глобальную схему. СУРБД отвечает за перевод запросов
данных из глобальной в локальную схему СУБД.
В последующих разделах мы подробно рассмотрим свойства прозрачности распределения, прозрачности транзакций и прозрачности производительности.
10.7. Прозрачность распределения
Прозрачность распределения позволяет управлять физически разнесенной базой данных так, как если бы она была централизованной БД. Уровень прозрачности, обеспечиваемый СУРБД зависит от системы. Различают три уровня прозрачности:
- прозрачность фрагментации. Это наивысший уровень прозрачности. Конечный пользователь или программист может ничего не знать о разделении базы данных. Поэтому при доступе к данным не задаются ни имя фрагмента, ни его местоположение;
- прозрачность местоположения имеет место, когда конечный пользователь или
программист должен задавать имя фрагмента БД, но местоположение фрагмента
задавать не нужно;
- прозрачность локального отображения. При этом конечный пользователь или программист должен определять как имя фрагмента БД, так и его местоположение.
Свойства прозрачности сведены в табл. 10.2.
Таблица 10.2. Свойства прозрачности

Можно спросить, почему в табл. 10.2 не упомянута ситуация, при которой в столбце "имя фрагмента" указано "Нет", а в столбце "местоположение" — "Да". Причина проста: невозможна ситуация, при которой существует местоположение, не соответствующее какому-нибудь фрагменту (если не нужно задавать фрагмент, то, очевидно, нет нужды задавать и его местоположение).
Для иллюстрации использования различных уровней прозрачности предположим, что имеется таблица EMPLOYEE (сотрудник), в которой есть атрибуты EMP_NAME, EMP_DOB, EMP_ADDRESS, EMP_DEPARTMENT и EMP_SALARY. Данные атрибута EMPLOYEE распределены по трем местам: Нью-Йорк, Атланта и
Майами. Таблица разделяется на три части; т. е. данные о сотрудниках в Нью-Йорке хранятся во фрагменте Е1, о сотрудниках Атланты — во фрагменте Е2, а о сотрудниках Майами — во фрагменте ЕЗ (рис. 10.9).
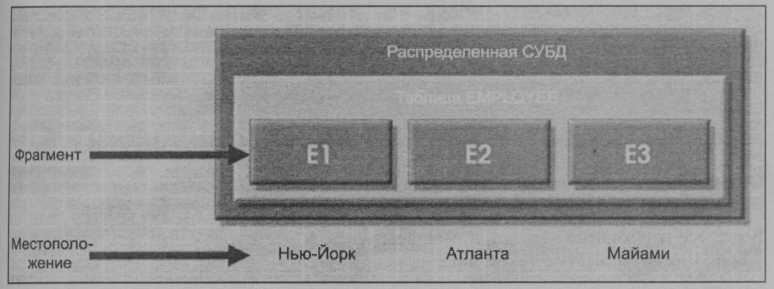
Рис. 10.9. Расположение фрагментов
Теперь предположим, что конечный пользователь хочет получить список всех сотрудников с датой рождения до 1 января 1940 года. Чтобы обратить внимание именно на проблемы прозрачности, предположим, что таблица EMPLOYEE фрагментирована и каждый фрагмент уникален (условие уникальности фрагмента указывает на то, что все без исключения строки уникальны, независимо от того, в каком фрагменте они находятся). Наконец, предположим, что ни одна часть базы данных не дублируется на каком-либо другом сайте сети.
В зависимости от уровня прозрачности распределения мы рассмотрим три случая.
Случай 1.
База данных поддерживает прозрачность фрагментации
Запрос соответствует формату запроса к нераспределенной БД, т. е. в нем не определяются имя фрагмента и его местоположение. Запрос выборки выглядит так:
SELECT *
FROM EMPLOYEE
WHERE EMP_DOB < '01-JAN-1940';
Случай 2.
База данных поддерживает прозрачность местоположения
В запросе необходимо определять имя фрагмента, местоположение фрагмента не
задается:
SELECT * FROM El WHERE EMP_DOB < '01-JAN-1940';
UNION SELECT * FROM E2
WHERE EMP_DOB < '01-JAN-1940';
UNION SELECT * FROM E3
WHERE EMP_DOB < ' 01-JAN-1940' ;