
Учебное пособие Допущено Министерством образования Российской Федерации в качестве учебного пособия для студентов высших учебных заведений, обучающихся по специальности
| Вид материала | Учебное пособие |
- В. В. Крупица Личность Коллектив Стиль отношений (социально-психологический аспект), 4876.34kb.
- Учебное пособие допущен о министерством образования и науки Российской Федерации, 3988.52kb.
- Учебное пособие Выпуск второй, 4617.34kb.
- М. В. Ломоносова Хрестоматия по истории государства и права зарубежных стран, 11295.75kb.
- В. И. Королева Москва Магистр 2007 Допущено Министерством образования Российской Федерации, 4142.55kb.
- Учебное пособие для вузов, 3736.61kb.
- Учебное пособие для вузов, 7834.87kb.
- И. М. Синяева, В. М. Маслова, В. В. Синяев сфера, 5230.77kb.
- Д. В. Андреев Программирование микроконтроллеров mcs-51, 2064.3kb.
- Т. В. Корнилова экспериментальная психология теория и методы допущено Министерством, 5682.25kb.
5.2. Распределенные базы данных
В

настоящее время существует два класса СУБД: настольные и серверные. Работа с небольшой базой данных, расположенной на персональном компьютере, не подключенном к локальной сети (настольный вариант СУБД), становится уже нехарактерным для настоящего времени.
Компьютеры объединяются в локальные сети.
Даже если разрабатывается БД для небольшой фирмы, всегда есть территориально-удаленные специфичные пользователи.
Распределенная база данных состоит из составных частей, размещенных на разных узлах сети в соответствии с каким-либо критерием (рис. 64).
Распределенные базы данных (РаБД) управляются распределенными системами управления базами данных (РаСУБД). Существуют различные модели распределения данных. РаБД могут работать под управлением одинаковых и неодинаковых СУБД. В первом случае говорят об однородных распределенных системах, во втором – о неоднородных.
Однородные распределенные системы баз имеют в своей основе один продукт СУБД, обычно с единственным языком баз данных (например, SQL с расширениями для управления распределенными данными). Существует множество различных вариантов построения однородной системы РаБД. Например, на некотором узле вычислительной сети может располагаться одна глобально доступная "главная машина СУБД", с которой связаны компоненты для доступа к данным локальных баз данных, размещенные совместно с самими этими базами данных в пределах всей компании (или отдельного ее подразделения в зависимости от масштаба распределения). Более сложные модели могут допускать распределенность самой СУБД, когда каждый ее компонент "на равных правах" имеет доступ к данным любого другого узла.
Неоднородные системы включают два или более существенно различающихся продукта управления данными. Неоднородные системы баз данных можно, в свою очередь, также подразделить на классы в широком диапазоне – от федеративных систем, до различных типов систем мультибаз данных.
Однородные распределенные системы баз данных обычно проектируются методом "сверху вниз", в целом аналогично проектированию централизованных баз данных (создание концептуальной, логической, физической моделей данных).
Неоднородные же, напротив, чаще всего строятся "снизу вверх" с целью создать общую среду управления над существовавшими ранее разрозненными базами данных. Основной проблемой при этом становится объединение схем баз данных, таким образом, чтобы предоставить как новым, так и прежним приложениям доступ и к новым и к прежним ресурсам данных. Процесс создания системы мультибаз данных технически сложен и нетривиален.
При создании однородных распределенных баз данных используется два метода распределения данных: фрагментация и тиражирование.
Фрагментация означает декомпозицию объектов базы данных, таких, как реляционные таблицы, на две или более частей, которые размещаются на разных компьютерных системах.
Проиллюстрируем это понятие примером из [24]. В БД имеется таблица, содержащая данные о сотрудниках, работающих в различных филиалах, или о заказах на продажу. Таблица может быть разделена на фрагменты по географическому или другому характеристическому признаку.
При горизонтальной фрагментации делаются горизонтальные "срезы" в соответствии со значением какого-либо столбца таблицы. Строки данных о сотрудниках могут разбиваться на подмножества, соответствующие филиалам. Данные о продажах фрагментируются по магазинам, где эти продажи производились
При вертикальной фрагментации разбиение таблицы осуществляется не по строкам, а по столбцам. В этом случае некоторая часть информации о каждом сотруднике хранится в одном месте, а другая часть (относящаяся к той же таблице) – в другом.
Независимо от вида фрагментации, поддерживается глобальная схема, представляющая единое описание всех составляющих ее локальных баз данных, позволяющая воссоздать из имеющихся фрагментов логически централизованную таблицу или другую структуру базы данных.
Основным достоинством модели фрагментации является то, что пользователи всех узлов (при исправных коммуникационных средствах) получают информацию с учетом всех последних изменений. Второе достоинство состоит в экономном использовании внешней памяти компьютеров, что позволяет организовывать БД больших объемов.
К недостаткам модели распределенной БД, основанной на фрагментации данных, относится следующее: жесткие требования к производительности и надежности каналов связи, а также большие затраты коммуникационных и вычислительных ресурсов из-за их связывания на все время выполнения транзакций. При интенсивных обращениях к распределенной БД, большом числе взаимодействующих узлов, низкоскоростных и ненадежных каналах связи обработка запросов по этой схеме становится практически невозможной.
Тиражирование (или репликация) означает создание копий некоторых фрагментов базы данных с целью приближения данных к месту их использования. Основное достоинство метода заключается в сокращении сетевого трафика и увеличение производительности системы. Репликаторы представляют множество различных физических копий некоторого объекта базы данных (обычно таблицы), для которых в соответствии с определенными в базе данных правилами поддерживается синхронизация (идентичность) с некоторой "главной" копией. Теоретически значения всех данных в тиражированных объектах должны автоматически и незамедлительно синхронизироваться друг с другом. (На практике это правило обычно несколько ослабляется.) В некоторых системах копии используются исключительно в режиме чтения и обновляются в соответствии с заданным расписанием. В других средах допускается модификация отдельных значений в копиях, и эти изменения распространяются в соответствии с процедурами планирования и координации. Подробнее с различными моделями тиражирования можно ознакомится в [24.]
Основной недостаток метода тиражирования БД заключается в том, что на некотором интервале времени возможно "расхождение" копий БД.
Различные поставщики предлагают множество программных продуктов, позволяющих управлять распределенными ресурсами. При этом в результате общего соглашения определились некоторые характеристики "идеальной" РаСУБД:
- Прозрачность относительно местоположения. Для пользователя не должно быть разницы где физически находятся данные, данные должны "выглядеть" так, если бы они находились на локальном компьютере.
- Гетерогенные системы. СУБД должна работать с данными, которые хранятся на системах с различной архитектурой и с разной производительностью.
- Прозрачность относительно сети. СУБД должны работать одинаково в разнородных сетях: от высокоскоростных ЛВС до телефонных линий.
- Распределенные запросы. У пользователя должна быть возможность строить запросы из любых таблиц, вне зависимости от их реального физического расположения.
- Распределенные изменения. У пользователя должна быть возможность изменять данные в любой таблице, независимо от реального физического расположения таблиц и самого пользователя.
- Распределенные транзакции. СУБД должна выполнять транзакции, выходящие за границы одной вычислительной системы, и при этом поддерживать целостность данных при появлении отказов, как в отдельных системах, так и в сети в целом.
- Безопасность. СУБД должна обеспечить защиту всей распределенной базы от несанкционированного доступа.
- Универсальный доступ. СУБД должна обеспечивать единую методику доступа ко всей корпоративной базе данных.
Следует отметить, что в силу ряда причин ни одно из существующих распределенных СУБД не соответствует "идеалу" в полной мере. Распределенные базы данных являются одним из стратегических направлений развития вычислительной техники, поэтому решение вышеперечисленных задач следует искать на пути разработки новых подходов к обработке распределенных данных.
Доступ к данным в условиях распределенности представляет сложную задачу, требует выделения значительных вычислительных ресурсов и затрат на передачу информации. В рамках решения данной комплексной задачи специалистами IBM была предложена четырехуровневая схема доступа к распределенным данным, такое расчленение проблемы обеспечивает хорошую основу для понимания принципов управления распределенными ресурсами.
У
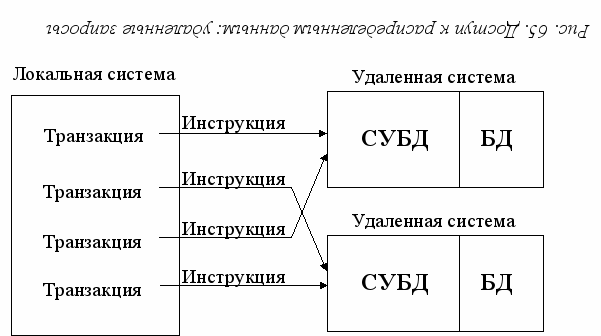
ровень 1. Удаленный запрос.
На данном уровне пользователь может выполнить инструкцию SQL, которая производит доступ или модификацию информации в одной удаленной базе данных (рис. 65).
Пользователь может таким образом обращаться к разным базам данных, но при этом СУБД не поддерживает транзакции, состоящие из нескольких инструкций (согласно терминологии IBM, транзакция – "удаленная единица работы").
Очевидно, что возможности удаленных запросов ограничены, такие запросы полезны в условиях однократного или кратковременного доступа к данным, хранящимся на удаленной станции. При этом обработка данных производится в основном средствами станции, инициирующей запрос.
Уровень 2. Удаленная транзакция. На данном уровне обеспечиваются более сложные транзакции, состоящие из нескольких инструкций SQL (рис. 66)
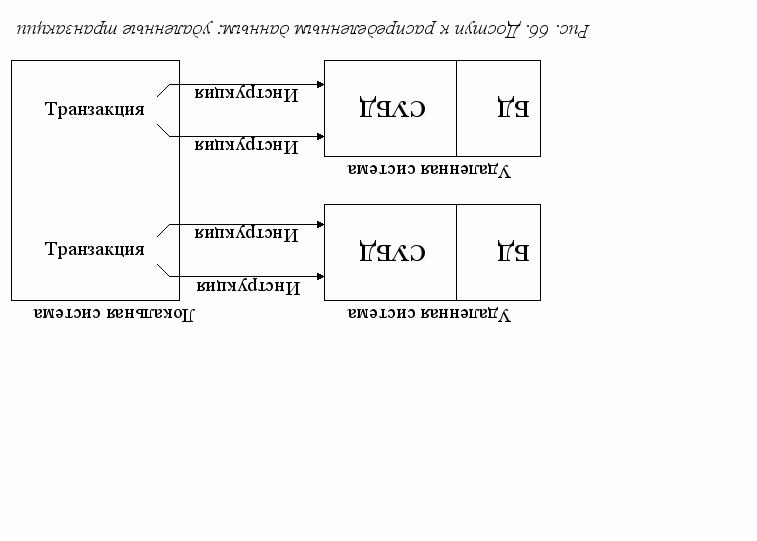
У пользователя появляется возможность задать СУБД последовательность инструкций SQL, осуществляющих доступ и модификацию данных в удаленной базе, а затем выполнить или отменить всю последовательность целиком, как одну транзакцию, которая может быть успешно завершена или целиком отвергнута. При этом все инструкции, составляющие транзакцию, должны быть адресованы к одной базе данных.
Для обеспечения связи СУБД различных типов при удаленных транзакциях часто используются так называемые шлюзовые программы. Некоторые шлюзовые программы не только обеспечивают выполнение удаленных транзакций, но и дают пользователю возможность объединять в одном запросе таблицы из локальной базы данных с таблицами из удаленной базы данных, управляемой СУБД другого типа. Однако эти программы не обеспечивают (и не могут обеспечить) выполнение транзакций, необходимых для реализации более высоких уровней доступа к распределенным данным. Например, шлюзовая программа может обеспечить по отдельности целостность локальной базы данных и целостность удаленной базы данных, но не гарантирует полного выполнения транзакций в разных узлах сети.
У
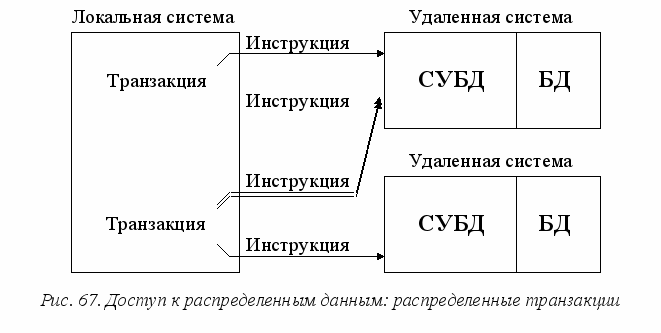
ровень 3. Распределенная транзакция (рис. 67). На данном уровне каждый отдельный пользователь по средством SQL может обращаться с запросом на выборку или модификацию данных к одной базе данных в одной удаленной вычислительной системе. Транзакция, представляющая собой последовательность операторов SQL, может обращаться к двум или более базам данных, которые могут быть расположены в различных системах. При этом СУБД гарантирует целостность транзакций, т. е. то, что все части транзакции во всех участвующих системах будут завершены или целиком отменены. Очевидно, что уровень сложности системы, поддерживающей подобные транзакции должен быть на порядок выше, чем для предыдущих.
Чтобы обеспечить выполнение распределенной транзакции необходимо активное взаимодействия отдельных СУБД, участвующих в транзакции. Данное взаимодействие обычно осуществляется при помощи специального протокола, называемого протоколом двухфазного выполнения, основное назначение которого поддерживать целостность распределенных транзакций без участия пользователя.
У
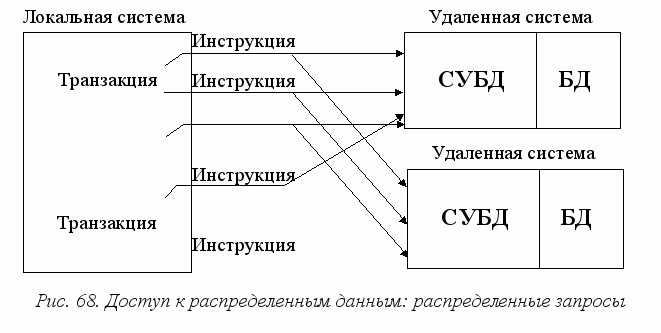 ровень 4. Распределенный запрос (рис. 68). На данном уровне один оператор SQL может обращаться к таблицам из двух или более баз данных, которые расположены в различных вычислительных системах. При этом СУБД отвечает за автоматическое выполнение оператора во всех системах, участвующих в запросе. Транзакция представляет собой последовательность инструкций. Как и на предыдущем уровне, СУБД должна обеспечить целостность распределенной транзакции во всех участвующих системах.
ровень 4. Распределенный запрос (рис. 68). На данном уровне один оператор SQL может обращаться к таблицам из двух или более баз данных, которые расположены в различных вычислительных системах. При этом СУБД отвечает за автоматическое выполнение оператора во всех системах, участвующих в запросе. Транзакция представляет собой последовательность инструкций. Как и на предыдущем уровне, СУБД должна обеспечить целостность распределенной транзакции во всех участвующих системах. На уровне распределенных запросов предъявляются повышенные требования к программам оптимизации инструкций. На данном уровне оптимизирующая программа при оценке альтернативных способов обслуживания оператора SQL должна учитывать скорость передачи данных в сети. Например, если локальной СУБД приходится многократно обращаться к некоторой удаленной таблице (допустим при создании объединения), то, эффективнее будет скопировать по сети некоторую часть таблицы целиком, посредством одной операции групповой передачи данных, чем многократно считывать по сети отдельные записи.
Оптимизирующая программа должна также определить, какая СУБД будет эффективнее управлять выполнением оператора. Например, если большая часть таблиц находится в удаленной системе, то, вероятно, было бы эффективнее, чтобы обработку выполняла удаленная СУБД этой системы. Однако при чрезмерной загрузки удаленной системы такое решение может оказаться малоэффективным. В целом, задача оптимизирующей программы становится и более сложной, и более важной. В силу своей сложности в настоящее время распределенные запросы не поддерживаются полностью ни в одной коммерческой СУБД, при этом, работы в этом направлении ведутся активно и следует ожидать прогресса в данном направлении в самое ближайшее время.
Ряд новых направлений открывается в связи с развитием объектно-ориентированных систем, в частности сред, основанных на объектно-реляционном подходе. Пожалуй, наиболее важная область в управлении распределенными объектами – это брокеры объектных запросов (Object Request Broker, ORB). Концепция распределения объектов распространилась не только на среды объектно-ориентированных СУБД, но и почти на любые мыслимые среды информационных систем главным образом благодаря работам, проводимым под эгидой Object Management Group (OMG), которая разработала стандарт общей архитектуры брокера объектных запросов – CORBA (Common Object Request Broker Architecture).
Сильным аргументом в пользу подхода к распределению данных, основанного на серверах (централизованный подход), является то преимущество, которое ему обеспечивает более высокая степень контроля поддерживающих ресурсов данных и реализаций. Этот аргумент может быть усилен в объектно-ориентированной области благодаря подходу, предусматривающему использование брокеров объектных запросов. Иначе говоря, базовая распределенная серверная модель открывает дорогу для семантически более богатой модели с инкапсуляцией методов средствами объектной модели.
Благодаря технологиям CORBA среды управления данными могут быть интегрированы одна с другой в значительной степени таким же образом, как и при серверном подходе. Отличие состоит, однако, в том, что введение с помощью ORB объектно-ориентированного уровня обеспечивает псевдообъектно-ориентированную обстановку не только для погруженных в нее ООСУБД, но и для РСУБД, иерархических систем, сред плоских файлов и других архитектур управления ресурсами данных. В действительности синтезированная над ORB среда и серверы методов поддерживают в системе парадигму управления распределенными объектами независимо от внутренних реализаций.
5.3. Базы данных в Интернет
С появлением Интернет получила дальнейшее развитие архитектура "клиент-сервер". С подключением локальных сетей к Интернет, созданием внутрикорпоративных сетей, появляется возможность с любого рабочего места в организации получить доступ к информационным ресурсам сети.
А
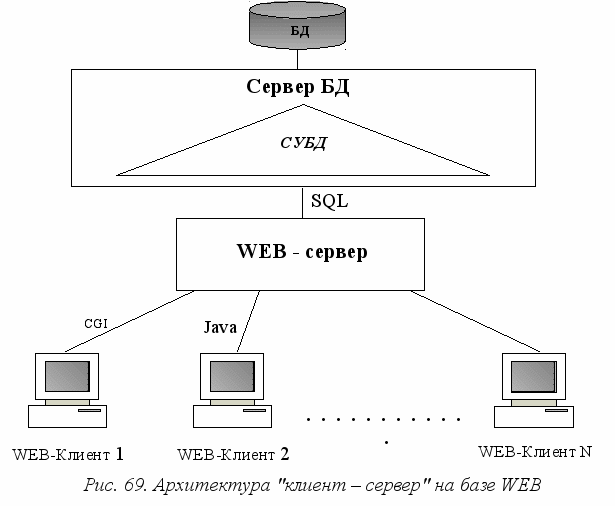
рхитектура "клиент/сервер" на базе Интернет имеет трехуровневую организацию. Пользовательским интерфейсом является Web-браузер, расположенный на персональном компьютере – "тонком" клиенте. Web-браузер взаимодействует с Web-сервером, последний в свою очередь является клиентом для сервера баз данных (рис. 69).
Наиболее часто в качестве сервера БД используется SQL-сервер.
Различают следующие механизмы доступа к БД: на стороне Web-сервера и на стороне Web-клиента.
В первом случае обращение к серверу БД производится следующим путем. Web-клиент заполняет специальную форму запроса к БД и пересылает ее Web-серверу. Программами Web-сервера вызываются внешние по отношению к ним программы в соответствии с соглашениями одного из интерфейсов: СGI или API. Внешние программы пишутся на языках программирования типа С++, Perl, PHP. Программы, написанные в соответствии с интерфейсом СGI, называются СGI-сценариями. Внешние программы взаимодействуют с сервером БД на языке SQL, преобразуя текст запроса в HTML-форме в SQL-запрос. После получения результатов запроса внешняя программа формирует требуемую HTML-страницу, передает ее Web-серверу, который пересылает ее Web-клиенту.
При доступе к БД на стороне клиента основным средством реализации механизма взаимодействия Web-клиента и сервера БД является язык JAVA, на котором пишутся программы (апплеты). JAVA-программы хранятся на Web-сервере. В тексте HTML-документа ставятся в нужных местах ссылки на соответствующие апплеты, при обнаружении которых в процессе работы с гипертекстом происходит автоматическая пересылка JAVA-программы с сервера в среду выполнения браузера и загрузка на выполнение. В диалоговом режиме с пользователем уточняются характеристики запроса. Получив управление JAVA-апплет взаимодействует с сервером БД, в результате чего, полученная из БД информация предоставляется пользователю. Для обращения к серверам баз данных разработан стандарт JDBC.
Из двух рассмотренных механизмов явного предпочтения отдать тому или иному варианту нельзя. Все зависит от целей и условий разработки клиент-серверных программ: зависимость от операционной системы, вида Web-сервера и т.п.
Развитие интернет-технологий стимулирует появление новых направлений в сфере сервиса. Уже никого не удивляют интернет-библиотеки, интернет-магазины, интернет-справочники. Интересным перспективным направлением в сфере сервиса является проект "интеллектуальная квартира". Например, одной из задач программы менеджера такой квартиры является следить за наличием в холодильнике заданного набора продуктов; при необходимости менеджер посылает заказ в интернет-магазин, который впоследствии выполняется.
Ввиду постоянного увеличения числа пользователей Интернет большие перспективы развития имеют интернет-СУБД бронирования авиабилетов, билетов на концерты, столиков в ресторанах. В настоящее время, уже не выглядит полной фантастикой интерактивная справочно-информационная система Голливуда, содержащая фильмы, информацию об актерах и режиссерах, поддерживающая интерактивные форумы поклонников, позволяющая участвовать во всевозможных виртуальных шоу.
Контрольные вопросы и задания
- Определить основные понятия архитектуры "клиент-сервер".
- Перечислить функции сервера баз данных.
- Какой принцип является основой архитектуры "клиент-сервер"?
- Нарисовать двухзвенную схему модели "клиент-сервер".
- Охарактеризовать функции стандартного интерактивного приложения.
- Назвать варианты разделения функций между компьютером-сервером и компьютером-клиентом для двухзвенной модели.
- Охарактеризовать модель удаленного доступа к данным (RAD).
- Назвать достоинства и недостатки модели сервера баз данных.
- Какие средства относятся к категории программного обеспечения промежуточного слоя?
- Определить назначение сервера приложений.
- Что такое транзакция?
- Указать функции монитора транзакций.
- Нарисовать схему распределенной базы данных.
- Охарактеризовать однородные распределенные системы.
- Каким методом проектируются неоднородные распределенные системы?
- Указать достоинства и недостатки метода фрагментации данных.
- Описать метод тиражирования данных.
- Перечислить характеристики "идеальной" РаСУБД.
- Охарактеризовать уровни доступа к распределенным данным на примере четырехуровневой схемы.
- Нарисовать модель доступа к данным на базе Интернет.
- Указать основные механизмы доступа к БД в сети Интернет.
- Каковы перспективы развития интернет-технологий в сфере сервиса?
- СОВРЕМЕННОЕ СОСТОЯНИЕ И
Перспективы развития баз данных
Технологии баз данных и смежные с ними области информационных технологий являются одной из наиболее бурно развивающихся отраслей информатики и вычислительной техники, причем темпы развития в последние годы особенно высоки.
Одним из направлений является развитие объектных технологий баз данных. Объектно-ориентированные языки программирования (такие как С++ и Java), объектно-ориентированные средства создания приложений и сетевого программирования стали базовыми технологиями разработки современного программного обеспечения. Идейную поддержку развитию данного направления оказал опубликованный в 1989 году "Манифест объектно-ориентированных систем баз данных", в котором содержались основные требования относительно обязательных свойств объектно-ориентированных баз данных, и, предполагалось, что новые системы должны строиться на базе объектно-ориентированного подхода, и нет особого смысла, так или иначе, использовать реляционный подход. В данном манифесте были приведены также необязательные свойства и открытые возможности объектных систем. В области формирования инфраструктуры объектных систем направляющую роль играет учрежденный в 1989 г. консорциум OMG (Object Management Group), целью которого является разработка и поддержка индустриальных стандартов архитектуры программного обеспечения промежуточного слоя (уровня архитектуры, занимающего промежуточное место между сетевым уровнем и уровнем приложений) для создания распределенных неоднородных объектных интероперабельных систем. Традиционно к промежуточному слою относились средства управления и доступа к данным, средства разработки программ, средства управления распределенными вычислениями (включая поддержку необходимых протоколов взаимодействия), средства поддержки пользовательского интерфейса и др. Такие инфраструктуры использовались как отдельными компаниями (IBM), так и в международных проектах (UNIX – ориентированная интеграционная среда). Применяемые идеи и технологии не позволяли до сих пор решить радикально архитектуру промежуточного слоя. OMG на основе объектной технологии и идеи интероперабельности вводит концепцию промежуточного слоя последовательно, радикально и до конца. Технически интероперабельность компонентов (представляемых объектами) решена введением базовой объектной модели, унифицированного языка спецификации интерфейсов объектов, отделением реализации компонентов от спецификации их интерфейсов, введением общего механизма поддержки интероперабельности объектов (брокера объектных заявок, играющего роль "общей шины", поддерживающей взаимодействие объектов). Тем самым достигается однородность представления компонентов и их взаимодействия. Далее, для формирования информационной архитектуры вводится слой унифицированных (ортогональных) служб, которые используются как при конструировании прикладных систем, так и для формирования функционально законченных средств промежуточного слоя, предлагающих конкретные виды услуг. Существенно, что и службы и средства представляются однородно своими объектными интерфейсами, что позволяет обеспечить их интероперабельность посредством брокера объектных заявок.
Базовый стандарт OMG – CORBA, принятый в 1991 г., получил широкое признание и активно применяется на практике. Наряду с созданием инфраструктуры для эффективного использования объектного подхода в технологиях баз данных архитектура CORBA предоставила один из методов обеспечения дальнейшего применения информационных ресурсов и функциональности унаследованных систем. Идея метода состоит в "объектизации" морально устаревшей системы путем создания для нее "обертки" (Wrapper) с помощью средств языка определения интерфейса IDL стандарта CORBA. Система превращается в обычный стандартный объект и может быть интегрирована в распределенную объектную среду.
К другим активно развиваемым важнейшим стандартам OMG относятся язык UML для объектного анализа и проектирования, стандарт XMI обмена метаданными между CASE-системами, основанный на языке XML.
Развитие производства объектных СУБД потребовало стандартизации модели данных и языковых средств, чтобы обеспечить переносимость приложений и ресурсов данных между объектными системами. Для решения этих задач ведущие поставщики объектных СУБД учредили консорциум ODMG (Object Database Management Group). В базовом стандарте ODMG определяются объектная модель, являющаяся расширением объектной модели CORBA, и язык определения объектов ODL. Был создан ряд чисто "объектных" программных продуктов, соответствующих различным компонентам данного стандарта: Objectivity/DB, GemStone, ObjectStore, POET, Versant и др. Объектно-ориентированная модель является наиболее подходящей платформой для CASE- и CAD-технологий.
Отношение специалистов в области баз данных к объектно-ориентированным базам данных (ООБД) неоднозначно. Главным аргументом сторонников является то, что новая технология позволяет добиться соответствия между программной моделью данных и структурой базы данных, в отличие от фиксированных, жестких структур реляционных таблиц. Кроме того, считается, что многотабличные объединения в реляционной модели существенно снижают производительность баз данных.
С другой стороны, чисто "объектная" модель вызывает много нареканий среди специалистов (в частности, что объектно-ориентированный подход не имеет той мощной математической основы, на которой построена реляционная модель, следствием чего является отсутствие стандартов построения ООБД и стандартизированного языка запросов) и компании-производители объектных СУБД испытывают определенные трудности с продвижением своих продуктов на рынок.
Одновременно с развитием чисто "объектного подхода" разработчики реляционных баз данных развивают объектно-реляционную модель данных. На развитие данного направления повлияли идеи, высказанные в "Манифесте систем баз данных третьего поколения". Авторами были сформулированы основные принципы построения СУБД нового поколения, предполагающие развитие реляционной платформы с применением богатой системы типов и расширением объектно-ориентированными возможностями, в частности о расширении языка SQL базовыми объектными возможностями (SQL:1999). СУБД, поддерживающие объектно-реляционную модель данных, разрабатываются многими ведущими компаниями, производителями программного обеспечения: Informix Universal Database Server (Informix), DB2 Universal Database (IBM), Oracle8 (Oracle). В последнее время появились предложения о расширении SQL средствами интеграции с XML-данными, поддержки языка Java. Предполагается дальнейшее совершенствование стандарта SQL:1999 в рамках проекта SQL3.
Открывающиеся, в связи с интенсивным развитием коммуникационных возможностей Интернет, новые направления развития отрасли накопления и доступа к данным приобретают все большее значение. Прочно в обиход пользователей вошли технологии глобальной гипертекстовой системы World Wide Web, которые принципиальным образом изменили в последние годы облик информационной среды общества. "Всемирная паутина" не только эффективно воплотила гипертекстовые и гипермедийные технологии, но и стала одновременно интегратором неоднородных информационных ресурсов, поддерживаемых в других средах (в частности, в средах баз данных), обеспечила возможности для нового этапа развития распределенных систем.
Новые возможности обеспечения интеграции информационных ресурсов Web и баз данных получили дальнейшее развитие с созданием платформы XML (в конце 2000 г. была принята новая спецификация стандарта языка XML). Различные пути использования этих возможностей активно изучаются в последние годы. В частности, возможности использования единой техники доступа к структурированным данным баз данных и слабоструктурированным данным Web.
Перспективным направлением развития взаимодействия Web-технологий и баз данных являются разработки систем баз данных XML. В программе работ по созданию новой версии стандарта языка SQL предусмотрено включение средств интеграции реляционных данных и XML-данных.
Одной из основных тенденций, определяющих современные направления развития технологий баз данных, является стремительный рост популярности хранилищ данных (Data Warehousing), концепция которых была разработана Б. Инмоном. Хранилище данных понимается как логически интегрированный источник данных для систем поддержки принятия решений (DSS) и информационных систем руководителя (EIS), который обеспечивает поддержку принятия стратегических решений в крупной организации на основе хранящихся исторических данных, отражающих деятельность этой организации за продолжительный период времени. Накапливая данные в хранилище, предприятие получает возможность проведения статистических исследований, анализа тенденций и перспектив развития, выявления слабых мест своей деятельности и скрытых резервов. Хранилища данных используются для принятия решений на основе сбора и анализа информации. Их главные пользователи – это менеджеры, служащие планового отдела и отдела маркетинга. Хранилища данных активно применяются в тех областях, где информация о тенденциях бизнеса служит основой для принятия решений, приводящих к значительной экономии средств или приносящих большую прибыль. Например, в крупных производствах – для анализа тенденций в области сбыта, в коммерции – для анализа эффективности мероприятий, направленных на увеличения сбыта и изучения демографических факторов, в финансовых структурах – для анализа факторов, связанных с получением и погашением кредитов клиентами и др. Хранилище данных – не то же самое, что база данных, так как данные, поступившие в хранилище, приобретают статус "неизменных". Вносимые изменения в хранилище носят характер только "пополнения", а не произвольных поэлементных обновлений, как в операционных базах данных, предназначенных для каждодневной деятельности предприятия.
Основные компоненты хранилища:
- Средства наполнения хранилища, представляющие программный комплекс, выполняющий извлечение данных из корпоративных операционных баз данных (OLTP-систем), их обработку и загрузку в хранилища.
- База данных хранилища – реляционная база данных, предназначенная для хранения огромных объемов данных, очень быстрой загрузки и выполнения сложных аналитических запросов.
- Средства анализа данных – программный комплекс, выполняющий статистический и временный анализ и представление результатов в графической форме.
Структура базы данных хранилища данных разрабатывается таким образом, чтобы максимально облегчить анализ информации. В большинстве случаев информация в базе данных может быть представлена в виде N-мерного куба фактов, отражающих деловую активность компании в течение определенного времени.
Принципы организации хранилищ данных могут сыграть важную роль в развитии электронных библиотек. Под электронной библиотекой понимается крупная распределенная гипермедийная и мультимедийная информационная система, позволяющая эффективно использовать разнообразные коллекции электронных документов, обладающая развитыми пользовательскими интерфейсами, обеспечивающая доступ пользователей через глобальные коммуникационные сети.
90-е годы характеризуются развитием технологий управления данными. В бизнес-приложениях наибольший интерес представляет интеграция методов интеллектуального анализа данных с технологией оперативной аналитической обработки данных (OLAP). Системы OLAP обеспечивают аналитикам и руководителям быстрый последовательный интерактивный доступ к внутренней структуре данных и возможность преобразования исходных данных с тем, чтобы они позволяли отразить структуру системы нужным для пользователя образом. Кроме того, OLAP-системы позволяют просматривать данные и выявлять имеющиеся в них закономерности визуально, либо простейшими методами.
В настоящее время поддержка OLAP реализована во многих СУБД и инструментах, поскольку является оптимальным решением для большого класса приложений, где пользователи работают с многомерными данными (то есть с данными, зависящими от нескольких параметров, например от времени, местоположения и других характеристик).
Технологии OLAP и хранилищ данных стимулируют развитие ещё одного направления – темпоральных (временных) баз данных. Темпоральные базы данных дополняют основные данные свойством времени, переносят это свойство в среду самой СУБД, обеспечивают языковые средства для выборки данных по запросам, связанным со временем.
Программные средства, реализующие технологии OLAP и хранилищ данных, выпускаются многими производителями программных продуктов: IBM DB2 OLAP Server, Visual Warehouse (IBM); MetaCube (Informix); Oracle Data Mart Suite (Oracle); группа продуктов Express OLAP. Программные компоненты для поддержки функциональных возможностей OLAP и хранилищ данных предусмотрены в Microsoft SQL Server 2002 (Microsoft). Поддержка временных рядов реализована в продуктах Informix Universal Database Server и Oracle8.
Интеграция со всемирной паутиной систем поддержки принятия решений, крупномасштабных хранилищ данных и прочих развитых информационных систем становится реальностью. В этом направлении следует ожидать развитие существующих и появлений новых стандартов и технологий доступа.
Еще одним из перспективных направлений развития баз данных является развитие дедуктивных баз данных. Эти базы данных основаны на применении аппарата математической логики и средств логического программирования в области систем баз данных. Получение сведений из баз данных осуществляется не путем запросов или аналитической обработки, а путем использования правил вывода и построения цепочек применения этих правил для вывода ответов на запросы. Для этих баз данных существуют языки запросов, отличные от SQL.
Дальнейшее развитие архитектурных подходов информационных систем связано с архитектурой "клиент-сервер". По такому принципу строятся сервисы CORBA, Интернет, современные серверы баз данных.
Развитие архитектуры распределенных систем связано с концепцией промежуточного слоя. Имеются в виду средства программного обеспечения, позволяющие изолировать приложения от сетевых протоколов и особенностей конкретных операционных систем. На принципах промежуточного слоя строятся многие стандартные интерфейсы распределенных систем, например, ODBC, JDBC. Одной из важнейших задач средств промежуточного слоя – обеспечение интероперабельности (способности системы к взаимодействию с другими системами) программных продуктов различных поставщиков.
Новым архитектурным подходом является появления систем баз данных с мобильной архитектурой. Создание миниатюрных мобильных компьютеров, способных поддерживать операционные платформы стационарных компьютеров, развитие сотовой телефонии стимулируют разработки технологии теледоступа к базам данных и мобильных систем баз данных. Основные направление исследований: разработка эффективных методов восстановления баз данных, стратегий кэширования в системах "клиент-сервер" и мобильных системах, обеспечение высокой производительности и масштабируемости систем, исследование новых моделей транзакций для мобильных систем, обработка в таких системах запросов, зависящих от местоположения пользователя, создание персональных информационных систем, предназначенных для индивидуальных информационных систем пользователя и др.
В ближайшее время возможно появление принципиально новых подходов и направлений в области баз данных. Технической базой для этого могут служить такие прогрессивные технологии повышения производительности, как RAID (Redundat Arrays of Inexpensive disk – эта аббревиатура обычно расшифровывается как "избыточные массивы недорогих дисков"). Сочетание быстро увеличивающейся мощности обработки с возможностью значительно быстрого выполнения операций ввода-вывода в действительности приведет к появлению среды, в которой увеличение производительности обработки транзакций аппаратным путем представляется приемлемым и желательным решением проблемы.
Эксперты определяют следующие основные направления исследований в области баз данных:
- Разработка принципов самонастройки СУБД. Система должна автоматически настраиваться без участия персонала администратора баз данных на основе регистрации информации об условиях ее функционирования.
- Создание новых технологий для крупномасштабных федеративных систем. Примером такой системы является Web. К кругу проблем данного направления относится обработка запросов большой вычислительной сложности.
- Разработка новых подходов к архитектуре систем баз данных. Эксперты полагают, что необходимо пересмотреть 20-летние архитектурные принципы организации системы баз данных в связи с изменением аппаратурных средств. Например, при объеме оперативной памяти в пределах терабайта традиционные подходы оказываются неэффективными.
- Интеграция структурированных и слабоструктурированных данных. Имеется в виду интеграция технологий баз данных и Web-технологий.
Динамика развития технологий баз данных очень высока. Поэтому в ближайшее время возможно появление новых направлений исследований.
В рамках учебного пособия невозможно охарактеризовать все современные составляющие и перспективные направления развития технологий баз данных. Сегодняшние технологии баз данных представляют настолько обширную и разветвленную сферу "как в части их собственных возможностей, так и в отношении многообразия приложений" [24]. Поэтому важнейшим компонентом изучения баз данных является работа с оперативными, энциклопедическими и информационными источниками и Интернет-ресурсами.
Контрольные вопросы и задания
- Дать характеристику объектно-ориентированной технологии баз данных.
- Перечислить чисто "объектные" программные продукты.
- Каковы достоинства и недостатки ООБД?
- Указать тенденции развития реляционных баз данных.
- Каковы перспективы интеграции технологий баз данных и Web-технологий?
- Что такое хранилище данных?
- Перечислить основные компоненты хранилища.
- Дать характеристику OLAP-системам.
- Каковы современные направления и архитектурные подходы в развитии распределенных систем?
- Что такое RAID-технологии?
- Охарактеризовать основные направления исследований в области баз данных.
Заключение
Рассмотренные в настоящем пособии вопросы, относящиеся к проектированию и разработке баз данных, далеко не исчерпывают весь перечень проблем и направлений развития этой отрасли информатики. В настоящее время осуществляются многочисленные исследования в области баз данных, СУБД и построении на их основе информационных систем. Активно разрабатываются новые средства описания и манипулирования данными, а также алгоритмы выполнения операций в СУБД. Требуют новых эффективных решений задачи обеспечения информационной безопасности баз данных, без чего невозможна информационная безопасность и конкретного владельца информации, и организации, и страны в целом.
Дальнейший прогресс в направлении внедрения информационных систем во все сферы деятельности невозможен без разработки и использования распределенных баз данных, совершенствования способов обмена информацией между различными приложениями в глобальных компьютерных сетях. Ведущими мировыми компаниями – разработчиками баз данных предлагаются новые версии своих систем, реализующих все более широкий спектр функций. Осуществляется разработка и принятие новых стандартов в области СУБД.
Однако следует отметить, что все представленные направления развития теории и практики создания баз данных используют в качестве фундаментальной основы знание основных принципов баз данных. Формирование таких знаний и соответствующих практических умений и являлось основной целью данного учебного пособия.
Авторы надеются, что представленный в данном пособии учебный материал был доступным для понимания и интересным при его изучении. Любые замечания и пожелания, направленные на совершенствование данного пособия, а также предложения по подготовке других учебных изданий по вопросам баз данных, информационных систем, разработке и использованию других средств информационных и коммуникационных технологий будут приняты с благодарностью.
библиографический список
- Базы данных: достижения и перспективы на пороге XXI столетия: Пер. с англ. / Под ред. А. Зильбершатца, М. Стоунбрекера и Дж. Ульмана // СУБД. 1996. № 3. С. 103–117
- Баркер Скотт Ф. Профессиональное программирование в Microsoft Access 2002: Пер. с англ. М.: Издательский дом "Вильямс", 2002. 992 с.
- Боровиков В.В. Microsoft Access 2002. Программирование и разработка баз данных и приложений. М.: СОЛОН-Р, 2002. 560 с.
- Брукшир Дж. Гленн. Введение в компьютерные науки. Общий обзор. 6-е изд.: Пер. с англ. М.: Издательский дом "Вильямс", 2001. 688 с.
- Вендров А.М. Проектирование программного обеспечения экономических информационных систем. М.: Финансы и статистика, 2000. 352 с.
- Вендров А.М. CASE-технологии. Современные методы и средства проектирования информационных систем. М.: Финансы и статистика, 1998. 176 с.
- Виллариал Б. . Программирование в Access 2002 в примерах: Пер. с англ. М.: КУДИЦ-ОБРАЗ, 2003. 496 с.
- Григорьев Ю. А., Ревунков Г. И. Банки данных: Учеб. для вузов. М.: Изд-во МГТУ им. Н. Э. Баумана, 2002. 320 с.
- Дарвин Х., Дейт К. Третий манифест: Пер. с англ. // СУБД. 1996. № 1. С. 110–123
- Дейт К. Дж. Введение в системы баз данных. 6-е изд.: Пер. с англ. М.: Издательский дом "Вильямс", 2000. 848 с.
- Дженнингс Р. Использование Microsoft Access 2002. Спец. изд.: Пер. с англ. М.: Издательский дом "Вильямс", 2002. 1012 с.
- Дунаев С. С. Доступ к базам данных и техника работы в сети. Практические приемы современного программирования. М.: Диалог – МИФИ, 1999.
- Зильбершац А, Здоник С. Стратегические направления в системах баз данных: Пер. с англ. // СУБД. 1997. № 4. С. 4–23
- Карпова Т.С. Базы данных: модели, разработка, реализация. СПб.: Питер, 2001. 304 с.
- Когаловский М.Р. Энциклопедия технологий баз данных. М.: Финансы и статистика, 2002. 800 с.
- Корнеев В. В., Гареев А. Ф. и др. Базы данных. Интеллектуальная обработка информации. М.: Изд-во Нолидж, 2001. 496 с.
- Литвин П, Гетц К, Гунделой М. Разработка корпоративных приложений в Access 2002. Для профессионалов. СПб.: Питер; Киев: BHV, 2003. 848 с.
- Мартен Д. Базы данных: практические методы. М.: Радио и связь, 1983. 168 с.
- Мартин Дж.. Организация баз данных в вычислительных системах. М.: Мир, 1980. 662 с.
- Мейер Д. Теория реляционных баз данных. М.: Мир, 1987. 608 с.
- Михеева В.Д., Харитонова И.А.. Microsoft Access 2002. СПб.: БВХ-Петербург, 2002. 1040 с.
- Послед Б.С. Access 2002. Приложения баз данных: Лекции и упражнения. СПб., 2002. 656 с.
- Риордан Р.М. Программирование в Microsoft SQL Server 2000. Шаг за шагом: Практ. пособ. / Пер. с англ. М.: Изд-во ЭКОМ, 2002. 608 с.
- Саймон А.Р. Стратегические технологии баз данных: менеджмент на 2000 год: Пер. с англ. / Под ред. и с предисл. М.Р. Когаловского. М.: Финансы и статистика, 1999. 479 с.
- Слама Д., Гарбис Д., Рассел П. Корпоративные системы на основе CORBA : Учеб. пособ.: Пер. с англ. М.: Издательский дом "Вильямс", 2000. 368 с.
- Ульман Дж., Уидом Дж. Введение в системы баз данных. М.: Изд- во "Лори", 2000. 789 с.
- Ульман Дж. Основы систем баз данных / Пер. с англ. М.: Финансы и статистика, 1983. 334 с.
- Федоров А., Елманова Н. Базы данных для всех. М.: КомпьютерПресс, 2001. 256 с.
- Хансен Г., Хансен Дж. Базы данных: разработка и управление: Пер. с англ. М.: ЗАО "Издательство БИНОМ", 2000. 704 с.
- Харитонова И., Вольман Н. Программирование в Access 2002: учебный курс. СПб.: Питер, 2002. 480 с.
- Хомоненко А.Д., Цыганков В.М., Мальцев М.Г. Базы данных: Учебник для высших учебных заведений / Под ред. проф. А.Д. Хомоненко. СПб.: Корона принт, 2000. 416 с.
- Цаленко М. Ш. Моделирование семантики в базах данных. М.: Наука, 1989. 288 с.
ПРИЛОЖЕНИЕ 1
Информационные ресурсы Internet
ACM SIGMOD (Московская секция группы ACM): c.ru/sigmod/
ACM SIGWEB : rg/sigweb/
IEEE CS (Московский центр): ter.org.ru/
ISO: h
ODMG: org/
OMG: rg/
РГНФ (Российский гуманитарный научный фонд):
u/
РФФИ (Российский фонд фундаментальных исследований):
ru/
Исследовательские группы в области баз данных: rg/sigmod/researchDepts/index.phpl
Календарь событий ACM: rg/sig_conferences/
rg/events/
Электронный магазин стандартов: ansi.org/
Электронная библиотека ACM: rg/dl/
Электронная библиотека IEEE CS:
ter.org/epub
DB2 Magazine Homepage: g.com/
DBWorld: sc.edu/dbworld
D-LIB (On-Line): org/
ComputerWord Россия (журнал): u/cwr/
Директор информационной службы (журнал): u/
Открытые системы (журнал): u/os/
СУБД (журнал): u/dbms/
Исследовательская группа СИНТЕЗ Института проблем информатики РАН: c.ru/synthesis/
Репозитарий материалов по базам данных ЦИТ МГУ: rum.ru/database/
Список серверов, поддерживающих публикации по базам данных: rg/sigmod/publications.phpl
приложение 2
Словарь терминов
Атрибут – столбец реляционной таблицы
Атомарное значение – значение, не являющееся множеством значений или повторяющейся группой
База данных – совокупность взаимосвязанных, совместно используемых, управляемых данных, характеризующая актуальное состояние некоторой предметной области
Внешний ключ – набор атрибутов одной реляционной таблицы, являющийся ключом другой реляционной таблицы. Применяется для создания связей между таблицами
Данные – представление фактов о предметной области в форме, допускающей их обработку и хранение на компьютерах, восприятие человеком
Дерево – иерархическая структура данных
Домен отношения – множество всех возможных значений некоторого атрибута отношения
Жизненный цикл базы данных – процесс проектирования, реализации и поддержания системы базы данных
Журнал СУБД – отдельная база данных (часть основной базы данных), используемая для записи информации обо всех изменениях базы данных
Запрос – специальным образом описанное требование, определяющее производимые с данными в базе данных манипуляции: выборку, удаление, изменение, вставку данных
Завершение транзакции – процесс, в результате которого все операции, входящие в состав транзакции, успешно завершены
Защита данных – средства предотвращения несанкционированного доступа к базе данных
Избыточность данных – дублирование данных в базе данных
Индекс – средство ускорения операций поиска записей в таблицах
Клиент – компьютер (программа), использующий ресурс вычислительной сети
Ключ отношения или первичный ключ – атрибут отношения, однозначно определяющий каждый кортеж
Курсор – указатель, используемый для перемещения по наборам записей при их обработке
Кортеж – строка реляционной таблицы
Мэйнфрейм – многопользовательская централизованная вычислительная система
Метаданные – данные о данных, описывающие их структуру, формат представления, методы доступа, место хранения, семантику, хранящиеся в словаре данных
Модель представления данных – логическая структура данных
Нормальная форма – правила структурирования реляционных таблиц во избежание аномалий
Нормализация – процесс преобразования реляционных таблиц путем ликвидации повторяющихся групп и иных противоречий в хранении данных с целью приведения таблиц к виду, позволяющему осуществлять непротиворечивое и корректное редактирование данных
Отношение – двумерная таблица
Ограничение целостности – условия, которым должны удовлетворять хранимые в базе данные
Откат транзакции – процесс, в результате которого все уже выполненные операции, входящие в состав транзакции, отменяются, а все объекты базы данных, затронутые этими операциями, возвращаются в исходное состояние
Представление – объект базы данных, являющийся виртуальной таблицей, предоставляющей данные из одной или нескольких реальных таблиц. Представление не содержит данных, а только описывает их источник
Приложение – программа, предназначенная для решения некоторой совокупности задач или типовой инструментарий
Рабочая станция – персональный компьютер, являющийся рабочим местом пользователя в сети
Реляционная алгебра – теоретический процедурный язык манипуляции реляционными таблицами
Реляционное исчисление – теоретический непроцедурный язык определения запросов к реляционным таблицам
Реляционная модель данных – модель данных, представляющая данные в виде таблиц
Репликация – копирование информации из одной базы данных в несколько других, выполняемое как единовременно, так и по заданному расписанию
Роль – совокупность прав на доступ к тому или иному объекту баз данных
Связь – взаимоотношение между атрибутами двух таблиц. Связь между двумя таблицами устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой таблицы
Семантическая модель – модель, фиксирующая значения сущностей и отношений реального мира
Сервер базы данных – 1. СУБД с архитектурой "клиент-сервер". 2. Компьютер в сети, на котором поддерживается БД
Сервер –. программа (компьютер), предоставляющая некоторые услуги по запросам других программ (компьютеров), называемых клиентами
Сеть – совокупность компьютеров, объединенных средствами передачи данных
Словарь данных – подсистема базы данных, предназначенная для централизованного хранения информации о структурах данных, типах данных, взаимосвязях файлов базы данных друг с другом, кодах защиты и т. п.
Степень реляционной таблицы – число атрибутов реляционной таблицы
Сущность – объект любой природы, данные о котором хранятся в базе данных
Схема отношения – список имен атрибутов отношения
Транзакция – последовательность операций над базой данных, отслеживаемое СУБД от начала до завершения как единое целое. Транзакции все вместе либо выполняются, либо отменяются
Транзитивная зависимость – функциональная зависимость, при которой неключевой атрибут функционально зависит от одного или более неключевых атрибутов
Файл-сервер – компьютер, предназначенный для организации управления файлами в сети
Функциональная зависимость атрибута В от атрибута А – такая зависимость атрибутов, при которой каждому значению атрибута А соответствует одно значение атрибута В
Хранимая процедура – программа обработки данных, хранящаяся и выполняемая на компьютере-сервере
Целостность – свойство базы данных, означающее, что она содержит полную, непротиворечивую и адекватно отражающую предметную область информацию
Экземпляр – действительные значения записей, выраженные в структуре данных
ПРИЛОЖЕНИЕ 3
Список сокращений
АБД – администратор базы данных
БД – база данных
ЖЦ – жизненный цикл
ИТ – информационные технологии
ИС – информационная система
ПО – программное обеспечение
РаБД – распределенная база данных
СУБД – система управления базами данных
ООБД – объектно-ориентированная база данных
ACM (Association for Computing Machinery) – Международная ассоциация по вычислительной технике
ACM SIGMOD (ACM Special Interest Group on Management of Data) – группа ACM по управлению данными
ADM (Architected Data Mart) - развиваемая витрина данных
ANSI (American National Standards Institute) – Американский национальный институт стандартов
ANSI/SPARC (ANSI/Systems Planning and Requirements Commitee) – Американский национальный институт стандартов / Комитет системного планирования и управления
AS (Application Server) – модель сервера приложений
API (Application Programming Interface) – интерфейс прикладного программирования
CAD (Computer Aided Design) – система автоматизации проектирования
CASE (Computer Aided Software Engineering) – автоматизация разработки программного обеспечения
CGI (Common Gateway Interface) – интерфейс взаимодействия Web-сервера с внешними программами
CIM (Computer Integrated Manufacturing) – автоматизированное интегрированное производство.
CODASYL (Conference on Data Systems Languages) – Ассоциация по языкам систем данных
CORBA (Common Object Request Broker Architecture) – стандарт архитектуры неоднородных распределенных интероперабельных объектных сред
DBMS (Database Management System) – система управления базами данных
DBS (Database Server) – модель сервера БД
DBTG (Data Base Task Group) – группа задач баз данных
DDL (Data Definition Language) – язык определения данных
DDM (Distributed Data Mart) – распределенная витрина данных
DDW (Distributed Data Warehouse) – распределенное хранилище данных
DML (Data Manipulation Language) – язык обработки данных
DSS (Decision Support System) – полнофункциональная система анализа и исследования данных, система поддержки принятия решений
EDW (Enterprise Data Warehouse) - хранилище данных предприятия
EDMA (Enterprise Data Mart Architecture) – архитектура витрин данных предприятия
EIS (Executive Information System) – информационная система руководителя предприятия (система оперативного мониторинга)
E/R (Entity-Relationship) – "сущность-связь"
ERD (Entity-Relationship Diagram) – диаграмма "сущность-связь"
FDM (Federated Data Mart) – объединенная витрина данных
FDW (Federated Data Warehouse) – объединенное хранилище данных
HTML (HyperText Markup Language) – стандартный язык для создания страниц Интернет
IDL (Interface Definition Language) – декларативный язык для определения интерфейсов объектов независимо от языков их реализации
IEEE (Institute of Electrical and Electronics Engineers) – Институт инженеров по электротехнике и электронике (крупнейшее международное профессиональное общество)
IEEE CS (IEEE Computer Society) – компьютерное общество IEEE
IMS (Information Management System) – система управления информацией (одна из первых СУБД)
ISO (International Organization for Standardization) – Международная организация по стандартизации
IVE (Industrial Virtual Enterprise) – индустриальное виртуальное предприятие
ITSM (IT Servise Management) – модель управления IT-услугами
JDBC (Java Database Connectivity) – Java-интерфейс для установки связи с базами данных
ODBC (Open Database Connectivity) – открытый интерфейс установки связи с базами данных
ODBS (Open Database Connectivity) – открытое соединение баз данных
ODL (Object Description language) – объектный язык
ODMG (Object Data Management Group) – индустриальный консорциум для выработки стандарта объектно-ориентированных СУБД
OLAP (Online Analytical Processing) – технологии интерактивной аналитической обработки данных в системах баз данных
OMG (Object Management Group) – индустриальный консорциум для выработки стандарта архитектуры неоднородных объектных интероперабельных распределенных систем
ORD (Object Request Broker) – брокер объектных ресурсов
QBE (Query By Example) – запрос по образцу
QUEL (Query Language) – язык запросов
RDA (Remote Data Access) – модель удаленного доступа к БД
RM/T (Relational Model/Tasmania) – расширенная реляционная модель
RPC (Remote Procedure Call) – удаленный вызов процедур
SGML (Standart Generalized Markup Language) – общий язык разметки
SQL (Structured Query Language) – структурированный язык запросов
TCP/IP (Transmission Control Protocol/Internet Protocol) – протокол управления передачей/протокол Интернет
TPM (Transaction Processing Monitor) – монитор обработки приложений
UML (Unified Modeling Language) – язык, предназначенный для спецификации, визуализации, конструирования и документирования систем программного обеспечения на основе объектно-ориентированных методов
XMI (XML Metadata Interchange) – индустриальный стандарт языка обмена метаданными между индустриальными средствами объектного анализа и проектирования
XML (Extensible Markup Language) – новый стандарт языка разметки для Web- документов (второго поколения)
ПРИЛОЖЕНИЕ 4
Темы рефератов
- Основные направления научных исследований в области систем баз данных.
- Стандарты баз данных, их назначения и виды.
- История создания языка SQL и его стандартизация.
- Объектные технологии баз данных и стандарт ODMG.
- Геоинформационные системы (ГИС). Стандарты, перспективы развития технологий ГИС.
- Темпоральные базы данных.
- Дедуктивные базы данных.
- Консорциум OMG и основные направления его деятельности.
- Интеграция Web-технологий и технологий баз данных.
- Многомерный анализ данных и технология OLAP.
- Дореляционные структуры данных.
- Основные направления развития реляционных баз данных.
- Выбор и оценка СУБД.
- Роль метаданных в информационных системах.
- Базы данных в мобильных системах.
- Хранилища данных.
- XML: состояние и перспективы.
- CASE-средства разработки информационных систем.
- Распределенные технологии в информационных системах.
- Технологии разработки цифровых библиотек.
- Концепции построения систем автоматизации документооборота.
- Модели транзакций.
- Защита данных в базах данных.
- Механизмы доступа к данным.
- Средства разработки приложений.
Лучко Олег Николаевич
Морарь Елена Витальевна
Червенчук Игорь Владимирович
Базы данных
Учебное пособие
Редактор Л. Г. Сигитова
Изд. № 113
Раб. программа
п.п. 2.1.1-2.1.18
Лицензия ЛР № 021278 от 06.04.98 г.
Подписано в печать . Формат 6084 1/16.
Бумага типограф. Оперативный способ печати.
Усл. печ.л. 9,76. Уч.-изд.л. 9,3. Тираж 200 экз.
Заказ №
Издательско-полиграфический центр ОГИС
644099, Омск, Красногвардейская, 9