
Лекция №1. Введение
| Вид материала | Лекция |
- С. В. Шадрина Лекция 5 сентября, 15: 00-16: 30, Введение в геометрию пространства модулей, 5.97kb.
- Первая лекция. Введение 6 Вторая лекция, 30.95kb.
- Текст лекций н. О. Воскресенская Оглавление Лекция 1: Введение в дисциплину. Предмет, 1185.25kb.
- А. И. Мицкевич Догматика Оглавление Введение Лекция, 2083.65kb.
- Лекция введение в экологию (В. И. Торшин), 1146.79kb.
- Конспект лекций н. О. Воскресенская Москва 2008 Оглавление: Лекция Введение в дисциплину, 567.5kb.
- План лекций педиатрический факультет 1 семестр 1 лекция. Введение в анатомию человека., 216.63kb.
- Сидоров Сергей Владимирович Планы лекций Введение в профессионально-педагогическую, 19.81kb.
- Русской Православной Церкви и их особенности. 22 сентября лекция, 30.24kb.
- План лекций: Лекция №1. Введение в тему, общие сведения. Введение, 99.54kb.
Выделение памяти.
Первая такая трудность связана с выделением памяти под объектную переменную. Она заключается в том, что подклассы могут добавлять данные, не присутствующие в родительском классе. Например, класс «Текстовое окно» может иметь поля для текущего положения курсора, буфер для хранения строки и т. д.
class Window class TextWindow : public Window
{ {
int height; char *TextBuf;
int width; int CursorPos;
……………………. ………………………
public public
virtual void cops ( ); virtual void cops ( );
}; };
Window win;
Сколько памяти следует отвести под переменную win, принимая во внимание возможность присвоить ей значение переменной типа TextWindow? Имеется три возможные способа выделения памяти под объектную переменную, а именно:
- Выделить память, достаточную только для базового класса, игнорируя требование памяти для подкласса;
- Выделить максимум памяти, достаточный для любого законного значения, независимо от того, принадлежит ли оно к базовому классу или к любому его подклассу;
- Выделить память только под указатель, а память, необходимую для размещения объектов выделять в динамической области во время выполнения программы.
Выделение минимальной статической памяти.
Выделение минимальной статической памяти возможно в языках, имеющих автоматическое распределение памяти. Очевидно, что такой метод может привести к потере данных.
Х класса Window Y класса TextWindow
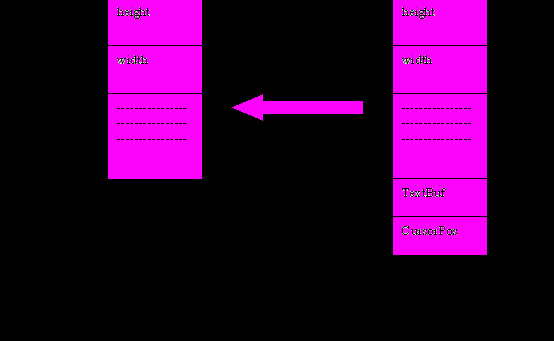
При операции копирования очевидно, что не все значения могут быть скопированы. Копируются только совпадающие поля, а информация, содержащаяся в дополнительных полях, теряется. Кроме того, возникают проблемы с вызовом методов.
Window win;
Window *tWinPtr;
TWindow = new TextWindow;
……………………………………….
win = *tWinPtr \ как выполняется этот оператор? Переменная win размещается в статической области, и пространство для нее выделяется при входе в процедуру. Память для нее выделяется по размер переменной базового класса. Переменная tWinPtr содержит только указатель. Память под значение выделяется динамически при выполнении оператора new. Но к этому времени размер объектов типа TextWindow уже известен, поэтому не возникает проблем при выделении памяти в динамической области. Память, выделенная под переменную win, вмещает только объекты класса Window, в то время как значение, на которое указывает tWinPtr, больше по размеру. Отсюда следует, что не все значения, на которые указывает tWinPtr, могут быть скопированы. Поведение по умолчанию состоит в том, что копируются только совпадающие поля, а информация, содержащаяся в дополнительных полях, теряется. Говорят, что имеет место «срезка», т. к., поля одного объекта срезаются перед присваиванием.
Синтаксис языка гарантирует, что для переменной win вызываются только методы, определенные для класса Window, но не методы класса TextWindow. Поэтому попытка выполнить оператор win.caps( ) после выполнения оператора присваивания приведет к попытке вызова метода caps из класса TextWindow, что приведет к попытке обработать данные, например, из поля CursorPos, которого не существует в блоке памяти переменной win. Для языка С++ эта проблема решается изменением правил привязки процедуры к вызову виртуального метода, а именно:
- Для указателей и ссылок, когда сообщение вызывает функцию – член, которая в принципе может быть переопределена, вызываемая функция – член определяется динамическим значением получателя.
- Для других переменных связывание вызова виртуальной функции определяется синтаксисом, а не динамическим классом.
Другими словами, во время процесса присваивания значение меняет тип с подкласса на тип надкласса, аналогично тому, как происходит присваивание целочисленной переменной вещественного значения. Отсюда следует, что для автоматических переменных динамический класс всегда совпадает со статическим, поэтому метод никогда не получит доступ к полям данных, которые физически отсутствуют в объекте. В примере метод, выбираемый при вызове win.cops( ), будет принадлежать к классу Window, а не TextWindow, и потеря информации при копировании будет незаметна. Тем не менее, это решение получено за счет некоторой непоследовательности. В выражениях с указателями виртуальные методы связываются динамически. Поэтому эти значения будут вести себя иначе, чем выражения, использующие статические значения. Пример:
Window win;
TextWindow *tWinPtr, *tWin;
………………………………………
tWinPtr = new TextWindow;
win = *tWinPtr;
twin = tWinPtr;
win.cops( );
(*tWin).cops ( );
С первого взгляда кажется, что переменная win и значение, на которое указывает указатель tWin, это одно и то же, важно помнить, что присваивание переменной win изменило тип значения. Из –за этого первое обращение к методу cops будет вызывать функцию – член класса Window, а второе – метод класса TextWindow.
Выделение максимальной статической памяти.
Другое решение этой проблемы заключается в выделении максимального объема памяти, достаточного для размещения любого значения, содержащегося в объекте, независимо от того, относится оно к объявленному классу, или к его подклассам. При таком подходе проблема срезки не возникает. Однако очевидна неэффективность такого подхода, кроме того, размер любого объекта неизвестен до компиляции всей программы. Такой подход и не применяется.
Динамическое выделение памяти.
При динамическом выделении памяти значения объекта не хранятся в статической области памяти. В ней отводится место только для указателей. Собственно значения объектов находятся в динамической памяти. Поскольку все указатели имеют постоянный размер, то проблем при присваивании значения подкласса переменной, объявленной как надкласс, не возникает. Этот подход используется в большинстве ОО – ориентированных языках. Для выделения памяти под объект необходимо использовать процедуру типа new, а для освобождения – процедуру типа free.
Присваивание.
Имеется две интерпретации операции присваивания, а именно:
- Семантика копирования. В операции присваивания полностью копируется значение справа и присваивается левой части. Два значения являются независимыми, и изменение одного из них не влияет на другое.
- С
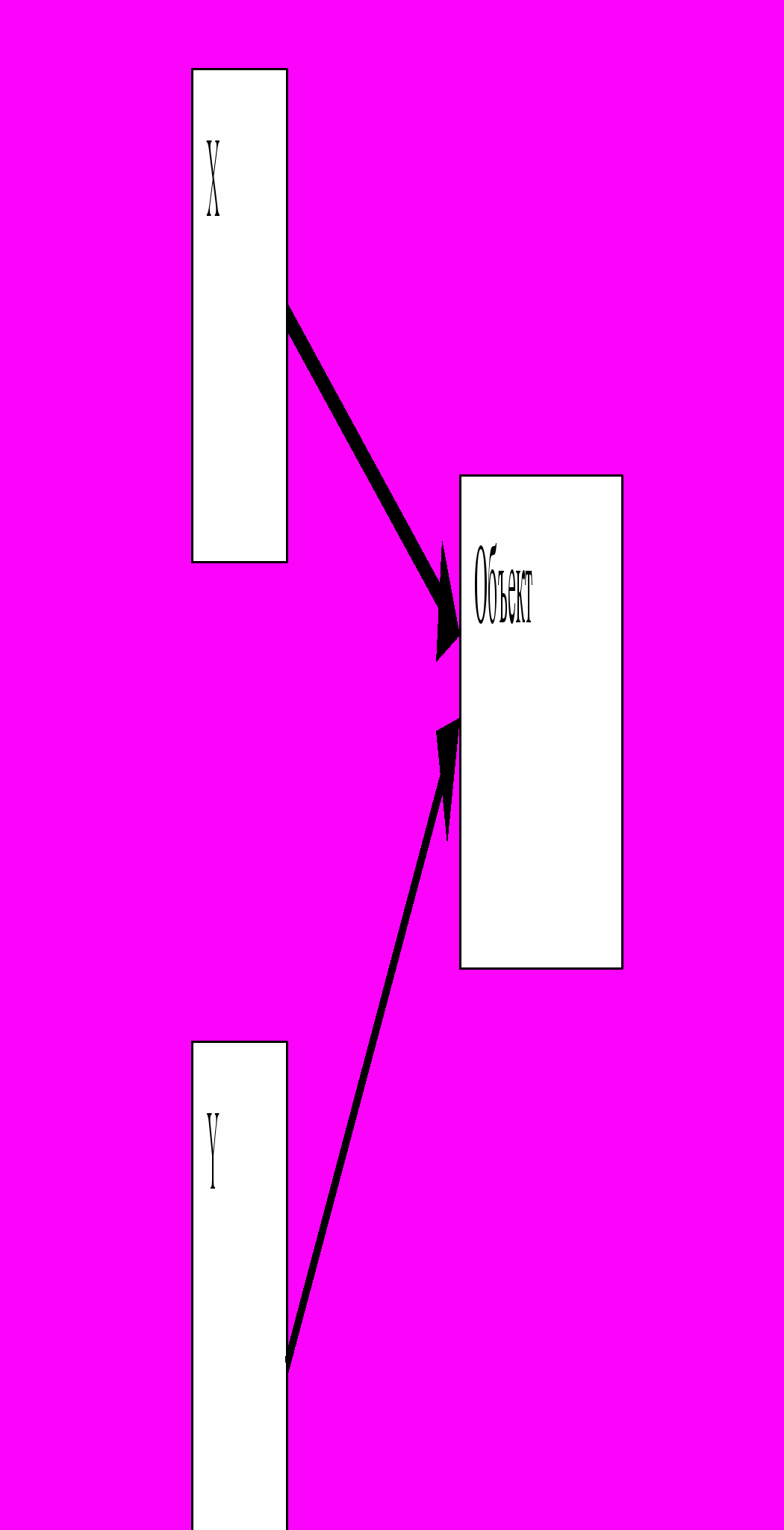
емантика указателей. Операция присваивания изменяет стоящую слева ссылку так, что она указывает на то же, что и правая часть. Тем самым две переменные не только имеют одно и то же значение, но и указывают на один и тот же объект. Изменения в этом объекте отразятся на значении, получаемом в случае разыменования любого из двух указателей.
В С++ присваивание переменной значения какого –либо класса выполняется с помощью рекурсивного копирования соответствующих полей данных. Однако разрешается переназначать оператор присваивания с тем, чтобы получить желаемое действие. В языке С++ присваивание при объявлении может вызвать произвольные конструкторы и не использовать присваивания вообще. Тем самым, оператор типа Complex X = 4; интерпретируется по смыслу следующим образом: Complex X(4);. При инициализации часто используются ссылки, тем самым ситуация напоминает семантику указателей. Например, если идентификатор S - объект типа String, то следующий оператор делает идентификатор t синонимом идентификатора S, так что изменение в одной переменной приводит к изменению другой.
String &t = S;
Переменные – ссылки наиболее часто применяются для реализации передачи параметров по ссылке при вызове процедуры. Это может рассматриваться как разновидность присваивания указателей, где параметру присваивается значение аргумента. Семантика указателей в С++ может быть осуществлена через переменные – указатели. Языки Java и Delphi – Pascal использует семантику указателей для присваивания объектов, причем последний использует семантику копирования для всех других типов данных.
Проверка на равенство.
Вопрос о том, является ли один объект эквивалентным другому, достаточно сложен. Сложность состоит в основном в понимании того, что в данном случае представляет из себя эквивалентность. Как и в случае операции копирования, имеется различие между семантикой копирования и семантикой указателей. Многие языки программирования используют эквивалентность указателей. В этом случае две ссылки на объект считаются эквивалентными, если они указывают на один и тот же объект. Эта форма эквивалентности называется эквивалентностью объектов (Венера одновременно утренняя и вечерняя «звезда»). В других случаях интересуются не столько тем, указывают ли две переменные на идентичный объект, сколько тем, обладают ли два объекта одинаковым значением. При такой интерпретации два объекта считаются эквивалентными, если их битовое представление в памяти одинаково. Для составных объектов типа записей побитное сравнение может оказаться недостаточным. Часто блок памяти для таких типов данных может включать пустые участки, которые не имеют отношения к значениям, хранимым в объекте. Поскольку эти пропуски не должны учитываться при определении равенства, используется второй механизм- поэлементное равенство. При поэлементном сравнении проверяются сопоставляемые элементы на совпадение, применяя это правило рекурсивно, пока не встретятся несовпадающие элементы. В последнем случае производится побитовое сравнение. Если все элементы удовлетворяют проверке, два объекта считаются равными друг другу. Если какие – либо два элемента не совпадают, то объекты не равны друг другу. Такое отношение равенства называют структурной эквивалентностью. ООП привносит свои особенности в проверку на равенство. Например, если при сравнении двух значений как статических типов они оказываются равными, то для динамических типов это не обязательно. Проблема состоит также и в том, что выбор интерпретации для вызываемого сообщения определяется получателем. Поэтому нет гарантии, что такое фундаментальное свойство, как коммутативность, будет сохраняться. Если идентификаторы Х и Y принадлежат к различным классам, то вполне может быть справедливым соотношение Х = Y, а соотношение Y = Х –нет.
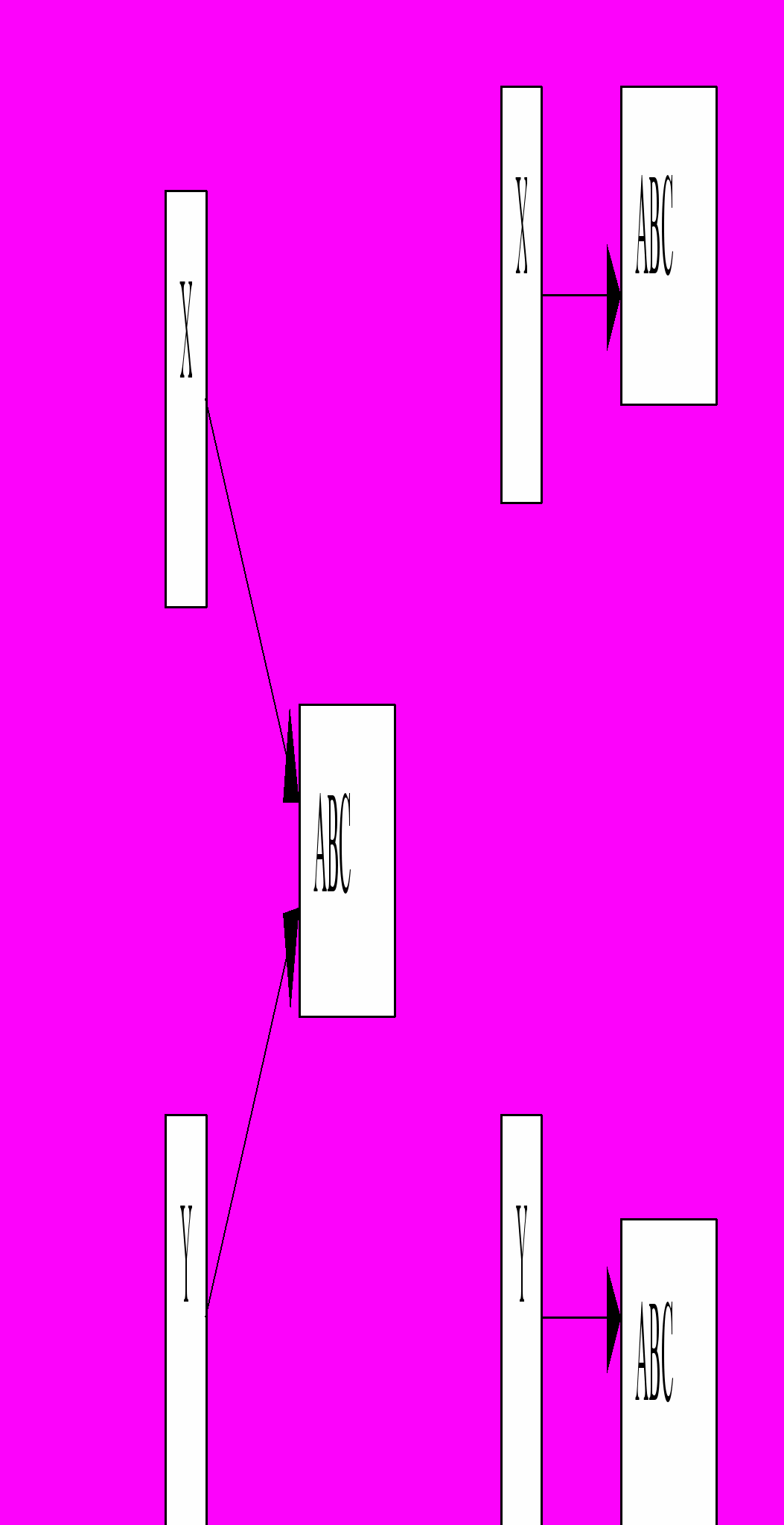
Идентичность Равенство
Преобразование типов.
Для языков программирования с автоматическими типами данных нельзя присваивать значения типа надкласса переменной, объявленной как объект подкласса. Значение, о котором компилятору известно, что оно имеет тип Window, нельзя присвоить переменной, описанной как TextWindow. Причины такого ограничения очевидны. В операторе присваивания источник должен полностью заполнить объект назначения. Порожденные классы содержат все, что содержат родительские классы исходя из принципа наследования. Следовательно, порожденный класс имеет тот же размер, или, как правило, больший, чем предок, но никогда не меньший. Присваивание значения объекта надкласса объекту подкласса может оставить некоторые его поля незаполненными, т. е., они окажутся неопределенными после такого присваивания. Тем не менее, в некоторых случаях желательно нарушать это правило. Чаще всего такие ситуации возникают, когда заранее точно известно, что значение, хотя и содержится в объекте надкласса, на самом деле является объектом более специализированного класса. Тогда можно перехитрить систему проверки типов данных, хотя это и нехорошо. В языке С++ это можно проделать с помощью конструкции, называемой приведением типа данных. Приведение типа заставляет компилятор преобразовывать значения из одного типа в другой. Наиболее часто этот подход используется в случае указателей, когда осуществляется только логическая замена, а не физическое преобразование. Приведение типов осуществляется с помощью системы RTTI.
Лекция №11. Полиморфизм.
В ОО – языках программирования полиморфизм является естественным следствием следующих их свойств:
- Отношения «быть экземпляром»;
- Механизма пересылки сообщений;
- Наследования;
- Принципа подстановки.
Одно из важнейших достоинств ОО – подхода состоит в возможности комбинирования этих свойств.
Чистый полиморфизм имеет место, когда одна и та же функция применяется к аргументам различных типов. В этом случае имеется один код, но несколько его интерпретаций.
Другая форма полиморфизма называется перегрузкой и заключается в наличии множества различных функций, т. е., кодов, с одним и тем же именем. Между этими полюсами находятся переопределяемые и отложенные методы.
Полиморфные переменные.
Полиморфизм в ОО – языках программирования возможен только за счет существования полиморфных переменных (кроме случаев перегрузки). Полиморфная переменная содержит значения, относящиеся к различным типам данных. Полиморфные переменные реализуют принцип подстановки. Другими словами: хотя для такой переменной и имеется ожидаемый тип данных, фактический тип может быть подтипом ожидаемого типа.
В языках программирования С++, Java, Delphi – Pascal создание подклассов рассматривается как порождение подтипов данных. Полиморфизм в этих языках существует благодаря различию между декларированным классом и фактическим (динамическим) классом значения, которое содержится в переменной. Это достигается через отношение «быть подклассом». Переменная может содержать значение объявленного типа или любого его подтипа. В языках Java и Delphi – Pascal это справедливо для всех переменных, связанных с базовым классом Object, в языке С++ полиморфные переменные существуют только как указатели и ссылки. Когда указатели не используются, динамический класс переменной всегда приводится к ее статическому классу.
Перегрузка.
Говорят, что имя функции перегружено, если имеется более одного кода, связанного с этим именем. Перегрузка является обязательной частью переопределения методов, но эти термины не идентичны, и перегрузка может происходить и без переопределения. При перегрузке полиморфным является имя функции – оно многозначно. Пусть есть некоторая функция сложения (+). Сложение может выполняться над целыми числами, или над вещественными, однако пользователи думают об этой операции как об едином действии – сложении. В этом примере важно отметить, что происходит не только перегрузка, но и явно, или неявно имеет место приведение типов. Приведение происходит, когда значения одного типа преобразуются в значения другого. Например, если разрешены арифметические действия со смешанными операндами, то сложение двух значений может интерпретироваться несколькими способами:
- Имеются четыре различные функции, которые соответствуют операндам I+I, I+F, F+I, F+F. Здесь есть перегрузка, но нет приведения типов.
- Есть две различные функции: I+I и F+F. Для операций F+I и I+F целые значения приводятся к вещественным. В этом случае имеет место комбинация перегрузки и приведения типов.
- Есть только одна функция сложения: F+F. Все аргументы приводятся к вещественному типу данных. В этом случае нет перегрузки, а есть только приведение типа.
Все ОО – языки разрешают использовать методы с одинаковыми именами в несвязанных между собой классах. В этом случае привязка перегруженного метода производится за счет информации о классе, к которому относится получатель сообщения. Перегрузка может выполняться и в параметрическом виде. В этом случае методам в одном и том же контексте разрешается использовать совместно одно и то же имя, а неоднозначность снимается за счет анализа сигнатур. Параметрическая перегрузка допустима в языках C++ и Java, например, в случае функций – конструкторов в С++. Любой метод может быть параметрически перегружен, если его сигнатура такова, что выбор однозначно производится на этапе компиляции.
Переопределение.
Механизмы переопределения были рассмотрены выше (уточнение и замещение). В общем случае: в некотором классе имеется определенный для конкретного сообщения общий метод, который наследуется и используется подклассами. Однако, по крайней мере, в одном подклассе определен метод с тем же именем. Это перекрывает доступ к общему методу для экземпляров данного подкласса (или, в случае уточнения, делает доступ к этому методу многоступенчатым). В этом случае говорят, что второй метод переопределяет первый. Переопределение часто происходит прозрачно для пользователя класса, и как в случае перегрузки, две функции представляются семантически как одна сущность.
Отложенные методы.
Отложенный метод, иногда называемый абстрактным методом, а в С++ - чисто виртуальным методом, может рассматриваться как обобщение переопределения. В обоих случаях поведение надкласса изменяется для подкласса. Для отложенного метода поведение не определено. Любые реальные, содержательные действия задаются в подклассе. Одним из преимуществ отложенных методов является то, что можно мысленно наделить нужными действиями абстракцию сколь угодно высокого уровня. Например, можно определить класс «Фигура», и в нем объявить метод «показать». Далее можно определить подклассы «Окружность», «Линия», «Прямоугольник», и в каждом из них определить метод «показать», отображающий эти фигуры. Однако метод с этим именем, объявленный в родительском классе, ничего не может отобразить в силу отсутствия конкретной информации. Тем не менее, присутствие метода «показать» в классе «Фигура» позволяет связать функциональность (рисование) только один раз с этим классом, а не вводить три независимые концепции для трех подклассов. Кроме того, в ОО – языках программирования с автоматическими типами данных можно послать сообщение объекту, только если компилятор в состоянии определить, что действительно имеется метод, соответствующий селектору сообщений. Пусть, например, необходимо определить полиморфную переменную типа «Фигура», которая в различные моменты времени будет содержать фигуры различного типа. Это допустимо в соответствии с принципом подстановки. Тем не менее, компилятор позволяет использовать метод «показать» для переменной, только если он сможет гарантировать, что сообщение будет распознаваться в фактическом классе переменной. Присоединение метода «показать» к базовому классу «Фигура» эффективно обеспечивает такую гарантию, даже если этот метод для этого класса на самом деле нигде не выполняется.
Обобщенные функции и шаблоны.
Еще один тип полиморфизма обеспечивается за счет так называемых обобщенных функций, или шаблонов. Аргументом обобщенной функции (класса) является тип, который используется при ее (его) параметризации. Очевидна аналогия с обычными функциями: последние реализуют необходимый алгоритм без задания конкретных числовых значений. Языки со строгим контролем данных, вообще говоря, не разрешают создавать, например, связный список элементов, тип которых не указан в явном виде. Обобщенные функции обеспечивают такую возможность. Для обобщенных функций или классов аргументом является тип данных. Он может использоваться внутри определения класса, как если бы он уже был определен, хотя никакие свойства этого типа данных не известны компилятору при считывании описания класса. Далее при определении конкретного объекта параметр – тип связывается с реальным типом данных. Например, в языке С++ связный список может быть представлен в следующем виде:
template
{
public:
void Add(T);
T firstElement ();
T value;
List
};
Здесь идентификатор Т используется как обозначение типа. Каждый экземпляр класса List содержит значение типа Т и указатель на следующий элемент. Add добавляет новый элемент в список. Первый элемент в списке возвращается функцией firstElement. Для создания экземпляра класса необходимо обеспечить тип данных для параметра Т. Следующие команды создают список целых чисел и список вещественных чисел:
List
List
Функции, включая функции – члены класса, также могут иметь описания – шаблоны. Например, нахождение длины списка независимо от типа, может иметь вид:
template
{
if (aList == 0) then return 0;
return 1 + length(aList.nextElement);
};
Полиморфизм в различных языках.
В языке Delphi – Pascal все переменные потенциально полиморфны при неявном предположении, что все подклассы представляют из себя подтипы. Все переменные хранят значения или объявленного класса, или его подкласса. Поддерживаются абстрактные методы, но не абстрактные классы, т. е., можно создать объект, класс которого имеет все еще не переопределенные абстрактные методы.
Язык Java поддерживает как иерархию подклассов, так и иерархию подтипов. Переменные могут быть объявлены либо через класс, либо через интерфейс. Все переменные являются полиморфными. Абстрактные методы должны переопределяться в подклассах. Класс, включающий в себя хотя бы один абстрактный метод, должен быть объявлен как абстрактный. Не разрешается создавать экземпляры абстрактных классов.
В языке С++ истинные полиморфные переменные возникают только при использовании указателей или ссылок. Когда обычной переменной присваивается значение типа подкласса, то динамический класс вынужденно приводится так, чтобы совпадать со статическим типом переменной. Однако при использовании указателей или ссылок значение сохраняет свой динамический тип. Например:
class ONE class TWO : public ONE
{ {
public: public:
virtual int value ( ) virtual int value ( )
{ {
return 1; return 2;
} }
}; };
Класс ONE определяет виртуальный метод, возвращающий значение 1. Этот метод переопределяется в классе TWO на метод, возвращающий значение 2. Далее определяются следующие функции:
void directAssign (ONE x)
{
printf(“Непосредственное значение = %d\n”, x.value ( ) );
};
void byPointer (ONE * x)
{
printf(“Значение по указателю = %d\n”,x value ( ) );
};
void byReference (ONE & x)
{
printf(“ Значение по ссылке = %d\n” ,x.value ( ) );
};
Эти функции используют в качестве аргумента значение класса ONE, которое передается соответственно по значению, через указатель и по ссылке. При выполнении этой функции с аргументом класса TWO для первой функции параметр преобразуется к классу ONE, и в результате будет напечатано значение 1. Две другие функции допускают полиморфный аргумент и в обоих случаях переданное значение сохранит свой динамический тип данных и будет напечатано 2. Если удалить квалификатор virtual из описания метода в классе ONE, но сохранить его в классе TWO, то результат 1 будет напечатан во всех трех случаях. Без ключевого слова virtual динамический тип переменной игнорируется, когда переменная используется как получатель соответствующего сообщения. Таким образом, не всякое переопределение виртуально.
Язык С++ позволяет нескольким функциям иметь одно и то же имя внутри любого контекста до тех пор, пока их сигнатуры различаются в достаточной степени для однозначного определения компилятором. Такая ситуация может возникнуть при использовании нескольких конструкторов одного и того же класса. Правила для снятия двусмысленности с перегруженных функций являются довольно тонкими, в особенности, если разрешено автоматическое приведение типов данных. Отложенный, или чисто виртуальный метод в языке С++ должен быть описан в явном виде с ключевым словом virtual. Тело отложенного метода не определяется, вместо этого функции присваивается значение 0. Создавать экземпляры класса, содержащего чисто виртуальные методы, не разрешается. Подклассы должны переопределять виртуальные методы. Переопределение чисто виртуального метода должно произойти при описании его потомков, для которых создаются реальные объекты.
Лекция №12. Внутренняя структура объектов.
Общее понимание проблем, возникающих при реализации ОО – языков программирования, а также различных способов решения этих проблем помогают лучше понять ОО – технологии.
В широком смысле имеются два подхода к реализации языков программирования высокого уровня: компиляторы и интерпретаторы. Компилятор переводит программу пользователя в машинный код процессора, на котором и будет выполняться программа. Вызов компилятора осуществляется как процесс, не зависящий от выполнения программы. Интерпретатор обязательно присутствует в памяти во время выполнения программы и является собственно той системой, которая реально выполняет программу. В общем случае, программа, оттранслированная компилятором, будет выполняться быстрее, чем программа, выполняемая под управлением интерпретатора. Однако, при возникновении ошибки времени выполнения откомпилированная программа обычно локализует такую ошибку с точностью до соответствующего оператора ассемблера (в лучшем случае). Интерпретатор обычно показывает такую ошибку на уровне оператора исходного текста. Таким образом, имеются достоинства и недостатки у обоих методов.